

The AI Powered Workflow for Automated Content Tagging and Metadata Enrichment
To download this as a free PDF eBook and explore many others, please visit the AugVation webstore:
Introduction
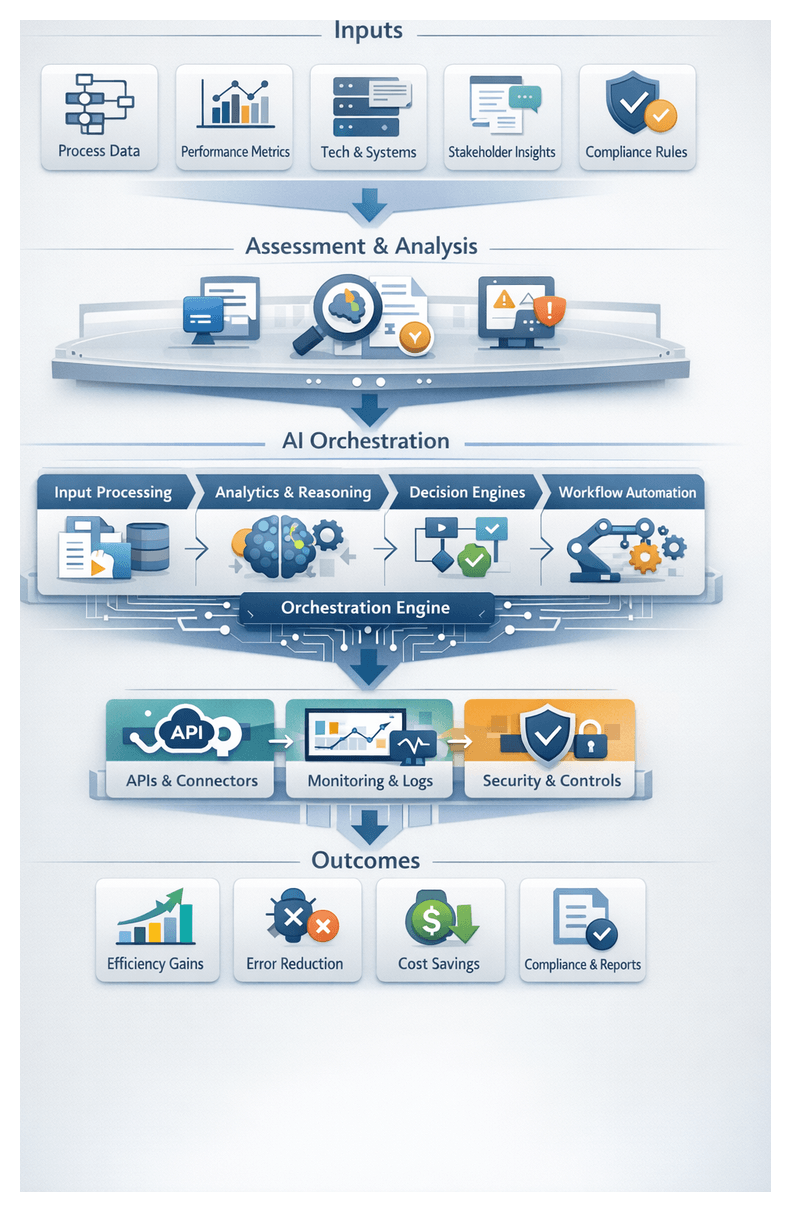
Operational Challenges and Strategic Imperatives
The media and entertainment industry is experiencing an unprecedented surge in digital content, with video hours, high-resolution images, and audio files doubling annually. Production studios, broadcasters, streaming platforms, and user-generated channels all contribute to a heterogeneous asset landscape. Disparate naming conventions, quality standards, and metadata schemas fragment repositories, undermining content discovery, licensing compliance, and audience engagement. The proliferation of formats—from ultra-high-definition video and immersive 360-degree footage to short-form social clips and interactive media—introduces diverse technical parameters and processing requirements that strain manual workflows.
Inconsistent or missing metadata impairs recommendation engines, search filters, and rights management systems, leading to compliance risks, revenue leakage, and viewer frustration. Manual tagging processes fail to scale, creating backlogs that delay distribution and introduce subjective discrepancies. In an era of on-demand streaming and personalized experiences, audiences expect immediate access to relevant content. The absence of a unified, automated pipeline for metadata generation translates into missed monetization opportunities—such as targeted advertising and dynamic packaging—and hinders global operations across production, syndication, and distribution channels.
Core Objectives of an AI-Driven Tagging Workflow
An automated, AI-driven metadata workflow addresses these challenges by ingesting raw media, extracting and standardizing technical and contextual attributes, enriching tags with semantic insights, and integrating results into content management systems. The primary objectives are to:
- Ensure reliable discovery and retrieval through consistent metadata standards.
- Accelerate time to market by automating repetitive tagging tasks.
- Enhance content monetization with targeted recommendations driven by semantic insights.
- Reduce compliance risk via automated rights and attributes classification.
- Support scalable operations across global production, syndication, and distribution networks.
Fundamental Prerequisites and Inputs
Successful implementation requires alignment of technical infrastructure, data assets, and governance policies. Key inputs include:
- Media Asset Sources: High-resolution video feeds, audio files, images, and textual transcripts from production cameras, post-production systems, and user-generated channels.
- Technical Infrastructure: Scalable storage and compute platforms—on-premises GPU clusters or cloud services such as AWS Rekognition and Google Cloud Vision—with high-throughput network connectivity.
- Existing Metadata Repositories: Legacy catalog systems and digital asset management platforms that supply initial tag sets and taxonomy definitions.
- Domain Taxonomies: Industry-specific vocabularies, controlled schemas, and hierarchical templates that guide accurate classification.
- AI Model Library: Pre-trained vision, audio, and language models, including services like IBM Watson Natural Language Understanding and OpenAI APIs.
- Integration Endpoints: Well-defined API schemas, event buses, or message queues for seamless orchestration between ingestion, AI services, and content management systems.
- Security and Compliance: Authentication controls, encryption protocols, and audit trails to protect sensitive content and adhere to regulatory standards.
- Governance Policies: Metadata standards, quality thresholds, and exception handling procedures that define acceptance criteria and human review triggers.
Organizational readiness demands cross-functional alignment among production, post-production, metadata governance, and IT teams. Consistent naming conventions, file validation rules, and sample annotations expedite AI calibration. A structured change-management plan ensures automation integrates smoothly without disrupting existing workflows or compromising editorial quality.
Structured, End-to-End Workflow Design
A cohesive workflow unifies ingestion, preprocessing, tagging, enrichment, and distribution modules, reducing manual handoffs and enforcing uniform standards. Core principles include:
- API-First Coordination: Event triggers and message brokers (Kafka, RabbitMQ) notify orchestration engines such as Apache Airflow to sequence tasks.
- Schema Enforcement: Metadata validation agents inspect AI-generated tags against controlled vocabularies, quarantining or auto-correcting non-conforming entries.
- Error Handling and Audit Trails: Retry policies, fallback routes, and centralized logging capture task status, enabling rapid troubleshooting and compliance reporting.
- Modular Scalability: Independent services for ingestion, preprocessing, tagging, enrichment, and CMS integration, each containerized and auto-scaled to meet demand.
- Human-In-The-Loop: Role-based review queues route low-confidence or conflicting tags to editorial teams via collaboration platforms and dashboards.
- Real-Time and Batch Processing: Event-driven pipelines for live content and scheduled jobs for archive enrichment, sharing compute and storage resources effectively.
This architecture isolates failures, supports incremental deployments, and accommodates new AI services—multilingual transcription, face recognition, or emotion analysis—by wiring them into existing event triggers and data flows.
AI Technologies Powering Metadata Automation
AI capabilities transform raw assets into rich, searchable metadata through:
Computer Vision for Visual Understanding
- Object detection and localization using deep convolutional networks.
- Scene classification and context labeling.
- Facial recognition against identity registries.
- Optical character recognition (OCR) for on-screen text.
- Activity and gesture analysis for temporal tagging.
Natural Language Processing for Textual Insight
- Speech-to-text transcription with encoder-decoder and hybrid acoustic-linguistic models.
- Named entity recognition to identify people, places, and organizations.
- Sentiment and emotion analysis.
- Keyword extraction and summarization.
- Language detection and translation for multilingual catalogs.
Multimodal AI Integration
- Cross-modal embeddings that unify visual, audio, and textual features.
- Temporal alignment of transcripts and video frames.
- Contextual reasoning to link faces with spoken names or on-screen text to dialogue.
- Fusion models using transformer or graph neural network architectures.
Knowledge Graphs and Semantic Enrichment
- Entity linking to industry taxonomies and public knowledge bases.
- Relationship extraction for co-occurrence and narrative dependencies.
- Concept clustering under thematic classifications.
- Schema validation via rule-based inference and W3C SHACL engines.
Dynamic Metadata Generation
- Incremental tagging to process new frames or transcripts.
- Rule-based augmentation for composite tags like “High Action.”
- Versioned metadata management for auditing and rollback.
AI Agent Orchestration and Workflow Integration
- Event-driven triggers with message brokers and event buses.
- Task queues and parallel processing across compute clusters.
- Error detection, retry logic, and circuit breakers.
- API choreography with defined schemas and contracts.
Unified monitoring dashboards enable dynamic scaling decisions to meet SLAs and track processing metrics.
Supporting Infrastructure and Data Management
- Object storage for media chunks with lifecycle policies.
- Feature stores for visual descriptors, text embeddings, and semantic vectors.
- Metadata catalogs centralizing tag definitions and schema versions.
- Elastic compute clusters orchestrated via Kubernetes or similar frameworks.
Compliance systems enforce security and access controls across all storage and compute resources.
Outputs, Dependencies, and Handoffs Across Pipeline Stages
The workflow produces stage-specific artifacts and orchestrates their handoffs to maintain traceability:
Content Acquisition and Ingestion
- Primary outputs: Raw media packages, ingestion manifests with checksums and access controls, initial metadata records.
- Dependencies: SFTP/HTTPS, authentication services, object storage endpoints, and Google Cloud Video Intelligence for format validation.
- Handoff: Orchestration triggers deliver media URIs and manifests to preprocessing engines.
Preprocessing and Quality Assurance
- Primary outputs: Transcoded files (H.264, ProRes), normalized audio, QA reports on signal-to-noise ratios and color histograms.
- Dependencies: Encoding engines like FFmpeg or Encoding.com, noise-reduction algorithms, and AWS Elemental MediaConvert.
- Handoff: Metadata connectors trigger taxonomy definition tools such as Protégé.
Taxonomy and Schema Definition
- Primary outputs: Controlled vocabularies, JSON-LD schema files, field definitions, and sample metadata payloads.
- Dependencies: Industry standards (EBUCore, IPTC), ontology management platforms, and SHACL validation services.
- Handoff: Versioned schemas are injected into model training configurations.
AI Model Selection and Training
- Primary outputs: Trained model binaries or containers, hyperparameter configurations, evaluation reports (precision, recall, F1).
- Dependencies: GPU clusters, data versioning systems, annotation tools like Labelbox, and Kubeflow.
- Handoff: Model artifacts register in MLflow or Amazon SageMaker Model Registry for orchestration.
AI Agent Orchestration Design
- Primary outputs: Workflow definitions, task queue configurations, retry policies, and runbooks.
- Dependencies: Kafka or RabbitMQ, function-as-a-service platforms, API gateways, and Prometheus or Datadog.
- Handoff: Deployed orchestration triggers invoke AI agents with model endpoints and asset pointers.
Automated Content Tagging and Classification
- Primary outputs: Metadata payloads with bounding boxes, sentiment scores, timestamped scene markers, and confidence metrics.
- Dependencies: AWS Rekognition, NLP engines like spaCy, and ensemble classification services.
- Handoff: Metadata streams publish to message buses for semantic enrichment.
Metadata Enrichment and Semantic Analysis
- Primary outputs: Knowledge graph triples (RDF), personalized tag scores, and concept linkage maps.
- Dependencies: Neo4j, Wikidata, sentiment analyzers, and AWS Personalize.
- Handoff: Enriched metadata synchronizes with CMS via connector scripts.
Integration with Content Management Systems
- Primary outputs: CMS entries with embedded metadata, audit logs, and reconciliation reports.
- Dependencies: CMS APIs such as Adobe Experience Manager, middleware connectors, and conflict resolution engines.
- Handoff: Quality control workflows queue entries for human review.
Validation, Quality Control, and Human-in-the-Loop
- Primary outputs: Approved metadata records, exception logs, reviewer comments, and compliance certificates.
- Dependencies: Review platforms, anomaly detection services, and governance frameworks.
- Handoff: Validation outcomes feed monitoring dashboards and trigger remediation.
Monitoring, Feedback, and Continuous Improvement
- Primary outputs: Analytics dashboards, error rate reports, engagement metrics, and retraining job definitions.
- Dependencies: Logging infrastructures, data lakes, anomaly detection models, and scheduler services.
- Handoff: Prioritized feedback datasets commit to training repositories for iterative model refinement.
Governance, Quality Control, and Continuous Improvement
Ongoing oversight ensures metadata accuracy and relevance. Processes include statistical sampling, anomaly detection, and human review via dashboards. Reviewer feedback feeds back into model retraining and taxonomy updates, closing the loop between AI predictions and domain expertise. Governance policies enforce access controls, audit logs, and data retention rules across the pipeline. Performance monitoring of throughput, latency, and accuracy metrics informs capacity planning and SLA management. By embedding continuous feedback mechanisms and adhering to structured governance, media enterprises maintain metadata integrity and position themselves for future innovation in content discovery and monetization.
Chapter 1: Content Acquisition and Ingestion
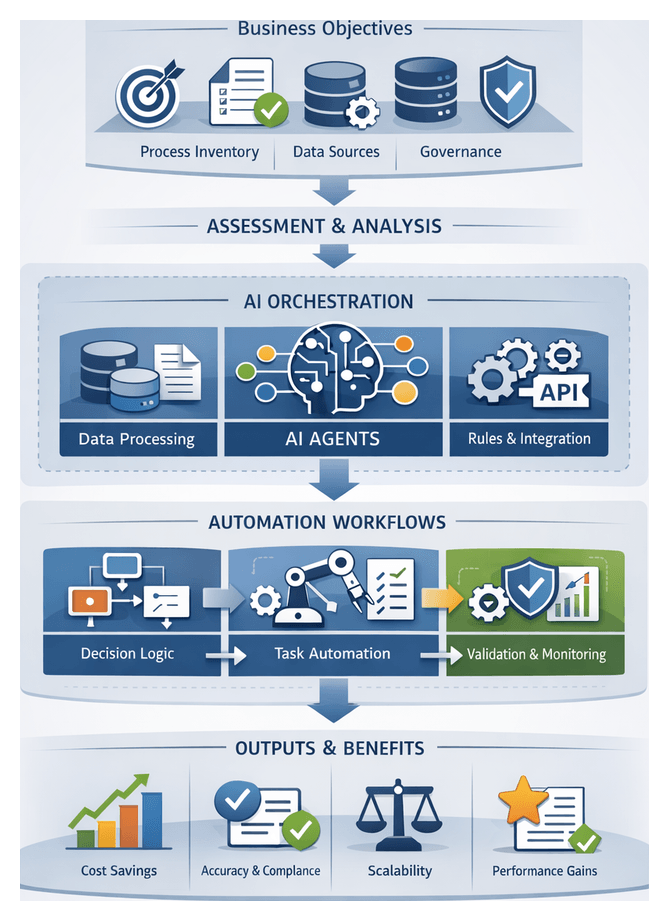
Purpose and Scope
The acquisition stage defines the entry point for all media assets entering the end-to-end tagging and metadata pipeline. Its objectives are to capture, consolidate, and securely onboard raw content from on-set feeds, live streams, user uploads, third-party packages, and digitized archives. By enforcing uniform naming conventions, timecode alignment, and directory structures, this stage safeguards against data loss, version conflicts, and metadata gaps that can compromise downstream AI-driven processing.
Key goals include registering each asset, routing it through security and compliance checks, monitoring transfer integrity in real time, and orchestrating a transparent handoff to preprocessing systems. These measures accelerate time-to-insight, reduce manual intervention, and establish a harmonized stream of media ready for AI-driven tagging and enrichment.
Inputs and Prerequisites
Raw Media Sources
- On-set Production Feeds: High-resolution camera outputs delivered via SDI/IP or bonded cellular links, including timecode-embedded video, raw audio, and camera metadata.
- Live Broadcast and Streaming: Satellite or cloud streams using RTMP, RTSP, or MPEG-DASH protocols for low-latency capture.
- User-Generated and Partner Uploads: Files submitted through web portals or mobile apps, varying in resolution, codec, and naming.
- Third-Party Syndication Packages: Standardized containers (MXF, GXF) with sidecar XML, EDL, or JSON metadata.
- Legacy Archives and Tape Digitization: Bulk transfers from LTO libraries or tape decks, converted to modern formats via high-throughput ingest hardware.
Accepted File Formats and Codecs
- Video Containers: MXF, MOV, MP4, AVI, GXF
- Video Codecs: ProRes (422, 4444), DNxHD, H.264, H.265/HEVC
- Audio Formats: WAV (24-bit PCM), AIFF, AAC
- Image Stills: JPEG2000, TIFF, DPX
- Sidecar Metadata: XML (EBUCore, MPEG-7), JSON, CSV
- Transcript Files: SRT, VTT, TTML
Security and Compliance
- Secure Transfer Protocols: SFTP, HTTPS with TLS 1.2 , or managed solutions like IBM Aspera and Signiant.
- Authentication and Access Control: OAuth2, JWT tokens, mutual TLS, and scoped API keys.
- Encryption at Rest and In Transit: AES-256 encryption, TLS for network transfers, and integration with enterprise KMS.
- Integrity Verification: MD5 or SHA-256 checksums with automated validation.
- Audit Trails and Logging: Immutable logs for transfers, integrity checks, and user actions, retained for regulatory compliance.
Infrastructure and Integrations
- Network and Storage: Dedicated links or VPN tunnels, edge capture nodes connected to Amazon S3, Azure Blob Storage, or Google Cloud Storage with lifecycle and tiering policies.
- Authentication and APIs: RESTful endpoints secured by IAM, webhook or event triggers via AWS EventBridge, Azure Event Grid, or Google Pub/Sub.
- Monitoring and Alerting: Telemetry agents feeding dashboards that track bandwidth, transfer rates, storage utilization, and SLA compliance.
Governance and Policies
- Data Ownership: Clear stewardship and approval workflows for each incoming asset.
- Naming Conventions and Metadata Templates: Standard identifiers, language codes, and region tags linked to schema validation.
- Retention and Archival Policies: Defined schedules for raw masters, sidecar metadata, and disposal.
- Embargo and Compliance Controls: Automated gating for NDA or time-release content.
- Service Level Agreements: Documented targets for transfer throughput, availability, and error resolution.
Workflow Actions and System Interactions
Source Integration and Orchestration
Connector modules handle authentication, protocol conversion, rate limiting, and retries for SFTP servers, object storage APIs, RESTful feeds, and live ingestion points. They poll or listen for new assets, emitting ingestion events to a central orchestrator backed by a durable queue. Priority flags allow urgent or live feeds to bypass standard backlog.
Secure Transfer and Validation
Workers establish encrypted channels (SSH or TLS) to stream files into a landing zone while computing continuous SHA-256 checksums. Mismatches trigger exponential back-off retries. Transfer metrics—throughput, duration, and errors—are logged for real-time monitoring and alerts.
Profiling and Preliminary Metadata
- Format Verification: Tools such as FFmpeg inspect container type, codecs, bitrate, and resolution.
- Integrity Checks: Verification of index tables and detection of truncated frames.
- Security Scans: Malware detection against signature databases.
- Thumbnail Generation: Keyframe extraction for visual previews.
Cataloging and Event-Driven Handoffs
Assets are assigned GUIDs and registered with storage URIs in the media catalog. Profiling metadata and source context are persisted, with schema validation enforcing uniformity. A successful ingest publishes an AssetIngested event to the message bus, including GUID, URI, metadata summary, and any exception flags. Downstream preprocessing services subscribe to these events to begin automated workflows.
Error Handling, Scalability, and Compliance
- Retry and Dead-Letter Queues: Transient failures trigger retries; assets exceeding thresholds move to exception queues.
- Automated Escalations: Critical failures notify human operators through workflow dashboards.
- Elastic Worker Pools: Parallel transfers, micro-batch chunking, and adaptive scaling ensure low latency and high throughput.
- Audit Trail: Immutable logs of authentication checks, transfers, profiling outcomes, catalog entries, and event publications support regulatory audits.
AI-Driven Capabilities
- Format Detection and Transcoding with Google Cloud Video Intelligence API for container and codec recognition, routing unsupported formats to AWS Elemental MediaConvert.
- Visual and Audio Metadata Extraction using Amazon Rekognition and Microsoft Azure Video Indexer to capture scene duration, dominant colors, spoken keywords, and on-screen text.
- Automated Tagging via image classification and speech-to-text with IBM Watson Visual Recognition and Google Speech-to-Text, applying confidence thresholds and queuing low-confidence tags for review.
- Scene Boundary Detection and Keyframe Sampling through shot segmentation endpoints in the Video Intelligence API, generating representative frames for asset previews.
- Content Fingerprinting and Deduplication with ACRCloud for perceptual hashing and audio fingerprinting to merge or flag duplicates.
- Language Detection and Transcription using AWS Transcribe for speaker diarization, language codes, and time-aligned transcripts, with fallbacks to human linguists when confidence is low.
- Technical Quality Scoring via deep learning anomaly detectors to assess noise, clipping, and artifacts, integrated with Grafana dashboards for alerting.
- Metadata Normalization by NLP-driven harmonization agents that standardize terminology, date formats, and measurement units before writing to the canonical catalog.
- Error Detection and Feedback Loop capturing ingestion anomalies and human corrections to refine AI model performance over time.
Outputs, Dependencies, and Handoff Mechanisms
Key Outputs
- Raw Asset References: Immutable objects in AWS S3, Google Cloud Storage, or Azure Blob Storage with GUIDs.
- Metadata Records: Structured catalog entries in relational or NoSQL databases capturing technical attributes and checksums.
- Audit Logs and Validation Reports: Detailed records of transfer protocols, checksums, security scans, and schema compliance.
- Event Notifications: JSON payloads published to Kafka, SNS/SQS, or RabbitMQ containing assetId, storageUri, metadata pointers, and ingestion status.
Dependencies and Integration Points
- Secure Transport: SDKs or CLI tools for Aspera FASP, SFTP, HTTPS multipart uploads, and FFmpeg streaming.
- Object Storage APIs: S3-compatible, Google Cloud Storage client libraries, and Azure SDKs for upload and bucket management.
- Catalog Services: RESTful interfaces to MAM platforms or custom catalogs backed by PostgreSQL, MongoDB, or Elasticsearch.
- Validation Scanners: REST or CLI integration with antivirus engines and compliance tools.
- Messaging Infrastructure: Producer libraries for Apache Kafka, AWS SNS/SQS, or RabbitMQ clients.
- Identity and Access Management: SSO via OAuth or SAML, token-based microservice policies, and role-based permissions.
- Monitoring and Logging: Data pipelines to Splunk, ELK, or Prometheus/Grafana for metrics and log analytics.
Handoff to Preprocessing
- Event-Driven Triggers: AssetIngested events with assetId, storageUri, metadata endpoint, timestamp, and validation status.
- RESTful Invocation: Optional API calls returning HTTP 202 and job tickets for progress polling.
- Catalog State Transitions: Lifecycle fields moving from “Pending Ingest” to “Ready for Preprocessing” for polling or CDC-based detection.
- Queue Buffering: Durable queues in Amazon SQS or RabbitMQ to manage back-pressure and retries.
- Metadata Contracts: Mandatory fields for preprocessing, with remediation workflows for incomplete records.
- SLA Monitoring: Alerts on handoff latency and error rates to meet processing targets.
By unifying secure ingestion, AI-driven analysis, and event-driven orchestration, this stage delivers validated, richly annotated assets with traceable audit trails and seamless downstream integration. This foundation enables scalable, efficient preprocessing, quality assurance, and semantic enrichment across the media lifecycle.
Chapter 2: Preprocessing and Quality Assurance
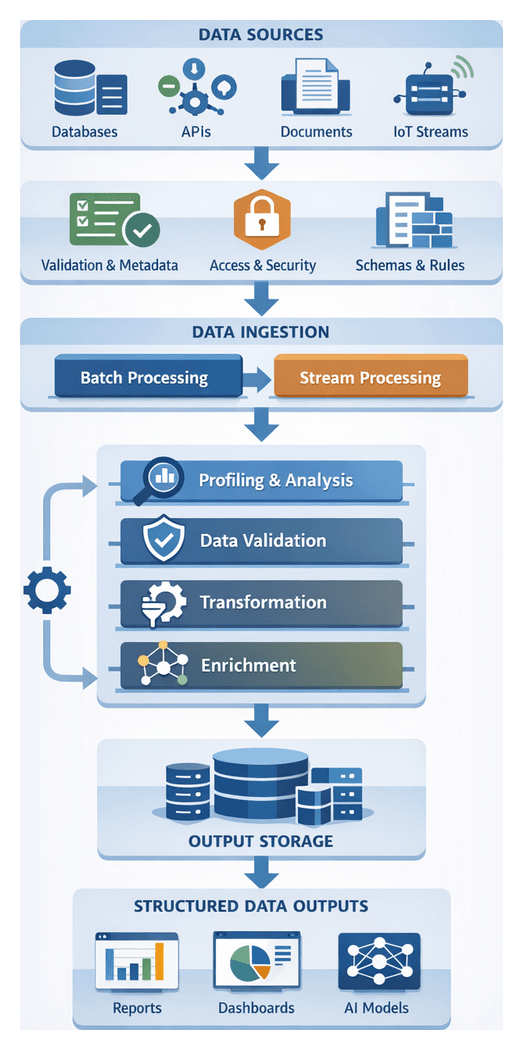
Purpose and Context
The Preprocessing and Quality Assurance stage transforms heterogeneous raw media into standardized, high-quality assets ready for AI-driven metadata tagging. By applying cleansing operations, format conversions, AI-based enhancements and rigorous checks, this stage eliminates noise, enforces uniform technical specifications, and embeds critical metadata. In the fast-growing media landscape—with high-resolution video, immersive audio, and diverse user-generated content—assets often arrive with inconsistent codecs, variable lighting and audio artifacts. Effective preprocessing mitigates these challenges through domain-specific normalization routines and well-defined quality thresholds, ensuring downstream models for computer vision, speech transcription and sentiment analysis operate on reliable inputs.
Strategic Benefits
- Consistency: Uniform file formats, codecs and quality levels reduce model errors and labeling discrepancies.
- Efficiency: Automated transcoding, denoising and normalization accelerate workflows and lower manual effort.
- Accuracy: Clean, high-quality inputs maximize performance of AI engines, improving metadata precision.
- Scalability: A repeatable, event-driven pipeline handles growing asset volumes without bottlenecks.
- Governance: Embedded policy checks enforce legal, contractual and brand standards, minimizing downstream risk.
Inputs and Prerequisites
Successful preprocessing requires clearly defined inputs, environment configurations and governance policies. Key prerequisites include:
- Raw Media Assets: Video files (MP4, MOV, MKV with H.264, H.265, ProRes), audio tracks (WAV, FLAC, MP3, AAC), image sequences (JPEG, PNG, TIFF), and text transcripts/subtitles (SRT, VTT, XML).
- Format Specifications: Target resolutions (1080p, 4K, 8K), frame rates (24, 25, 30, 60 fps), bitrate ranges, color spaces (Rec.709, Rec.2020, DCI-P3) and bit depths (8-, 10-, 12-bit).
- Quality Thresholds: Minimum signal-to-noise ratios for audio, luminance and chrominance noise floors, completeness metrics (frame counts, audio durations, subtitle sync), and maximum error rates (dropped frames, artifacts, desyncs).
- Upstream Metadata: Initial asset identifiers, source tags, DRM flags, access controls, language codes and locale indicators from ingestion.
- Technical Environment: GPU-accelerated nodes or CPU clusters, FFmpeg, AWS Elemental MediaConvert, TensorFlow, PyTorch, catalog APIs, object storage and compliance with GDPR/CCPA.
- Governance Policies: Privacy consents, copyright clearances, brand guidelines, watermark requirements and audit-ready logs for traceability.
Workflow Actions and Architecture
This stage orchestrates modular services, AI processors and human checkpoints via event-driven triggers and distributed queues. Key flow actions include:
- Orchestration and Intake: Ingestion events trigger retrieval of metadata from the catalog, integrity validation via checksum and signature checks, asset classification, and task enqueuing into pipelines coordinated by systems like Apache Airflow or AWS Step Functions.
- Quality Gatekeeping: Lightweight pre-checks using FFmpeg extract container metadata for codec, resolution and duration. Non-conforming assets route to exception queues for human review; approved assets advance with annotated headers.
- Transcoding and Standardization: Containerized jobs via AWS Elemental MediaConvert or Bitmovin Encoder convert video to H.264/H.265 MP4, audio to 44.1 kHz WAV, split subtitle streams and generate thumbnails. Completion events trigger downstream AI tasks.
- Noise Reduction and Enhancement: Video denoising through convolutional neural filters and GAN-based super-resolution; audio noise suppression via spectral subtraction. Color correction, stabilization and dynamic range adjustments improve consistency.
- Scene Segmentation: AI models—such as Google Cloud Video Intelligence or OpenCV extensions—detect shot boundaries, extract key frames, and generate context clips with time buffers.
- Anomaly Detection and Quality Scoring: Autoencoder and CNN models identify missing frames, audio dropouts, flicker and compression artifacts. Engines like Amazon Rekognition Video and Microsoft Video Indexer assign numerical quality ratings and flag assets below thresholds.
- Metadata Extraction: OCR via IBM Watson Visual Recognition or Azure Cognitive Services OCR, speech-to-text with Google Cloud Speech-to-Text or AWS Transcribe, and basic object recognition feed preliminary tags into NoSQL stores.
- Error Handling and Retries: Centralized error handlers capture logs, apply retry policies, route persistent failures to human operators, and trigger notifications via Slack or email integrations.
- Coordination and Handoff: Messaging via Apache Kafka or Google Cloud Pub/Sub links microservices. Upon completion, standardized assets, manifests and metadata are published to storage and catalog services for taxonomy definition.
AI-Driven Capabilities and System Roles
- Scene Segmentation Models: Detect shot boundaries and extract representative key frames for indexing and QC.
- Anomaly Detection Engines: Identify visual and audio defects, score quality and trigger exception workflows.
- Audio Enhancement Modules: Perform noise reduction, loudness normalization and clipping detection to optimize speech clarity.
- Metadata Extraction Services: Generate on-screen text via OCR, named entities via NER and basic object labels for preliminary cataloging.
- Transcoding Orchestrators: Integrate with FFmpeg, AWS Elemental MediaConvert and Bitmovin Encoder to enforce format standards and adjust encoding parameters dynamically.
- Normalization Classifiers: Apply VFR to CFR conversion, sample rate standardization and color space remapping based on format detection models.
- Visual Enhancement Models: Use GANs and autoencoders for color correction, super-resolution and denoising, with versioned outputs for rollback.
- Error Management Agents: Monitor repeat failures, classify errors, and manage retries or human escalations.
- Resource Management Systems: Autoscale GPUs and CPUs on Kubernetes, optimize infrastructure cost and forecast demand.
- Logging and Monitoring Frameworks: Aggregate logs in Elasticsearch or Splunk, visualize metrics in Grafana or Kibana, and alert on anomalies.
- Governance Engines: Enforce retention, access controls and redaction policies based on AI-classified content sensitivity.
Outputs
- Standardized Media Assets: Transcoded video (H.264/H.265 MP4, ProRes), audio (WAV/AIFF), and stills (JPEG/PNG) produced via FFmpeg or AWS Elemental MediaConvert.
- Quality Assurance Reports: JSON/XML summaries of noise levels, SNR, color histograms and pass/fail indicators from OpenCV and Clarifai models.
- Error and Exception Logs: Timestamped entries with asset IDs, error codes and stack traces for traceability.
- Integrity Manifests: MD5/SHA-256 checksums and file size assertions accompanying each output file.
- Preview Proxies: Low-res video/audio files, thumbnails and waveform images for rapid human review.
- Normalization Profiles: Versioned records of preprocessing parameters (color space, deinterlacing, loudness settings) stored in Git or Artifactory.
- Preliminary Metadata Annotations: Technical attributes—duration, frame count, aspect ratio, channel layout—exported in sidecar files.
- Anomaly Flags: Time-coded indicators of defects directing manual review effort.
Key Dependencies
- Compute Infrastructure: CPU/GPU clusters orchestrated by Kubernetes, NVIDIA Video SDK for hardware-accelerated processing.
- Transcoding Engines: FFmpeg, GStreamer pipelines and proprietary encoders invoked via REST APIs.
- AI Models and Inference Servers: TensorFlow Serving and TorchServe hosting segmentation, anomaly detection and enhancement models.
- Storage and Catalog Services: Amazon S3, Google Cloud Storage or on-premises DAM platforms for asset and metadata management.
- Logging and Monitoring: Elasticsearch/Splunk for logs; Grafana/Kibana for dashboards and alerts.
- Security and Compliance: Encryption, IAM controls, secure API gateways and data retention policies aligned with GDPR/CCPA.
- Configuration Repositories: Git or Artifactory for normalization profiles, schema templates and quality definitions.
- Workflow Orchestration: Apache Airflow or AWS Step Functions coordinating event triggers, task queues and retry policies.
- Human Review Interfaces: Web dashboards with authentication, session locking and annotation tools for quality engineers.
Downstream Handoffs
- Asset Transfer: Normalized files and manifests deposited in ingestion buckets accessible to taxonomy and labeling services.
- Catalog Registration: Automated ingestion of preliminary metadata and QA results into the catalog, triggering taxonomy definition workflows.
- QA Report Provisioning: Detailed reports delivered to ML engineers for schema refinement and model retraining.
- Flagged Asset Notifications: Anomaly-flagged items routed to human-in-the-loop queues; post-review corrections are fed back or passed forward with exception notes.
- Profile Synchronization: Shared normalization parameter sets ensure consistency between preprocessing and model training data.
- Event Triggers: Completion notifications initiate taxonomy workshops, supplying assets, metrics and metadata to stakeholders.
- APIs for Training: RESTful or GraphQL endpoints expose preprocessed assets and metadata for automated model training pipelines.
- Documentation and Audit Logs: Comprehensive records of preprocessing activities, decisions and dependencies archived for compliance and continuous improvement.
Chapter 3: Taxonomy and Metadata Schema Definition
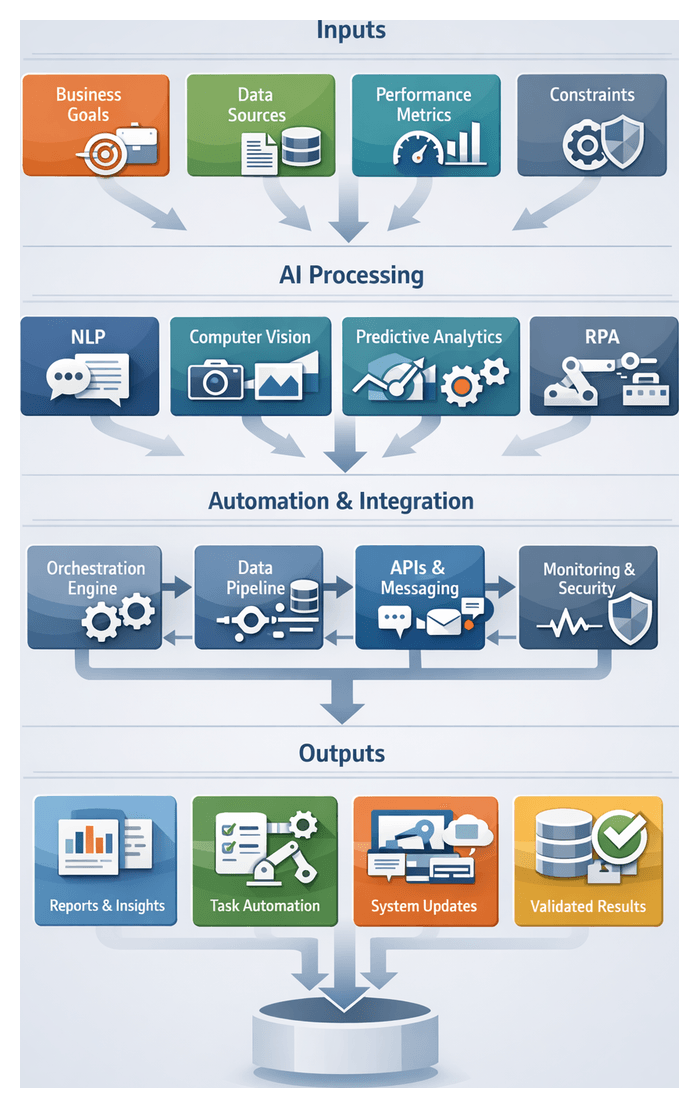
Purpose and Scope
The Taxonomy and Metadata Schema Definition stage establishes the semantic foundation that all tagging, enrichment, and discovery processes will rely on. By translating business objectives and industry standards into a hierarchical ontology and extensible metadata templates, organizations ensure consistent classification and seamless integration across production, distribution, and syndication workflows. Rapid expansion of media libraries—driven by streaming services, user-generated content, and global syndication—has revealed the pitfalls of ad hoc metadata practices. Inconsistent terminology, overlapping categories, and missing descriptors hinder content discoverability and elevate manual curation costs. A formal taxonomy and schema address these challenges by providing:
- A hierarchical ontology capturing genres, subgenres, formats, and contextual attributes.
- Controlled vocabularies and standardized fields for uniform metadata entry and accurate search, recommendation, and analytics.
- Alignment with frameworks such as Schema.org, EBUCore, and IPTC’s NewsML-G2 to support interoperability.
- Governance policies, versioning, and extension mechanisms for scalability and compliance with data privacy regulations like GDPR and CCPA.
By defining clear input requirements and schema constraints, organizations reduce downstream rework, streamline integration with third-party platforms, and enable advanced functions such as automated recommendation engines and audience segmentation.
Inputs and Stakeholder Collaboration
Successful taxonomy design depends on a comprehensive set of inputs and active engagement from diverse stakeholders. Early workshops and iterative feedback loops reconcile competing requirements and ensure the schema’s relevance and usability.
Key Inputs
- Industry Standards: Frameworks like Schema.org, EBUCore, and IPTC’s NewsML-G2 provide reusable classes and properties to accelerate interoperability.
- Organizational Requirements: Business rules, content strategies, and use cases specified by editorial, marketing, and programming teams.
- Existing Metadata Audit: An inventory of current fields, controlled lists, and attribute values highlighting gaps and inconsistencies.
- Technical Constraints: Integration requirements for CMS, DAM, and streaming platforms, including API schemas, data formats (XML, JSON, RDF), and performance SLAs.
- Governance Policies: Data stewardship guidelines, role-based permissions, approval workflows, and change management procedures.
- Tooling: Ontology editors and collaborative platforms such as Protégé, PoolParty Taxonomy Manager, and GraphDB.
Stakeholder Roles
- Content Strategists define genres, themes, and promotional tags.
- Production Teams specify technical metadata like codecs, resolution, and file formats.
- Legal and Rights Managers embed licensing windows, geographic restrictions, and attribution metadata.
- Data Scientists advise on taxonomy facets for segmentation, recommendation, and reporting.
- IT Architects validate schema compatibility with existing APIs, pipelines, and identity systems.
- UX and Customer Experience contribute search patterns, filter preferences, and navigation labels.
Structured governance—through a steering committee and taxonomy review board—defines decision rights, review cycles, and escalation paths. Training sessions and sandbox environments ensure metadata authors and integrators adopt the schema effectively.
Workflow Overview
The definition stage follows a structured sequence of collaborative workshops, technical processes, and governance checkpoints. These actions transform high-level requirements into a formally articulated taxonomy and controlled vocabularies that guide AI-driven tagging pipelines.
1. Governance Alignment
A steering committee of content operations, metadata governance, and AI engineering representatives convenes to approve the project charter. This charter specifies objectives for coverage and granularity, roles and responsibilities, KPIs (schema adoption rate, classification accuracy), and decision-making processes. Approved scope and timelines are communicated via the enterprise message bus to trigger task assignment and ensure auditability.
2. Requirements Capture Workshops
Facilitated sessions gather detailed use cases and edge cases from content producers, rights managers, distribution partners, legal officers, and AI engineers. Real-time collaboration tools record term suggestions, relationships, and property definitions. Outputs include a requirements matrix mapping stakeholder needs to taxonomy constructs.
3. Ontology and Vocabulary Drafting
Taxonomy architects draft hierarchical class structures (Genre Subgenre Theme), define attributes (Release Year, Production Country), specify relationships (isPartOf, hasContributor), and create controlled lists for fields like language codes and region identifiers. Tools such as Protégé and GraphDB facilitate RDF/OWL model creation with documented definitions and examples. The draft triggers an OntologyDraftReady event for reviewers.
4. Iterative Review and Validation
Parallel review streams—semantic, compliance, and technical—examine definitions, policies, and downstream compatibility. Feedback is consolidated via a collaboration platform into a master change log. Critical issues generate RevisionRequired events, returning the draft to architects. Automated version control tracks all edits.
5. Approval and Publication
The steering committee reviews key schema highlights, resolved concerns, impact analyses, and deployment timelines. Upon approval via a digital governance portal, a SchemaApproved event is published, the taxonomy version is tagged in the repository, and artifacts are published to the schema registry.
6. Technical Implementation
Integration engineers export the ontology in machine-readable formats (JSON-LD, RDF/XML), load vocabularies into a centralized metadata service or knowledge graph, update API contracts, configure access controls, and execute integration tests with sample assets. Continuous integration pipelines validate syntax and consistency, alerting teams to any failures.
7. Versioning and Event-Driven Coordination
The schema lifecycle—Draft, Review, Approval, Deployment, Deprecation, Archival—is managed through governance events (TermDeprecated, SchemaVersionRetired) on the event bus. An AI orchestrator listens for SchemaApproved to retrieve the new schema, reload controlled vocabularies in model pipelines, update enrichment agents, and promote the taxonomy into production tagging clusters after successful validation.
8. Handover to Model Training
The finalized schema is handed off to AI model training and orchestration teams with access credentials, API documentation, release notes, and sample scripts. A TaxonomyDeployed event signifies readiness for live tagging, enabling AI engineers to integrate the new taxonomy into fine-tuning and retraining workflows.
AI-Driven Capabilities
AI accelerates taxonomy design by automating pattern discovery, term suggestion, validation, and continuous evolution.
- Ontological Pattern Discovery uses unsupervised clustering and topic modeling to reveal latent concept groupings within existing metadata.
- Term Suggestion and Expansion leverages NLP pipelines with Amazon Comprehend and Google Cloud Natural Language API to propose synonyms and domain entities via NER and embedding similarity.
- Schema Validation employs rule-based engines and machine learning classifiers to enforce naming conventions, cardinality rules, and mapping accuracy against sample assets.
- Semantic Similarity and Concept Clustering applies transformer embeddings from platforms like IBM Watson Knowledge Studio and clustering algorithms to refine taxonomy structure based on semantic distance.
- Continuous Learning integrates real-time catalog updates and user feedback via Azure Text Analytics, retraining models periodically to surface emerging concepts and trends.
These AI components—Pattern Discovery Engine, Term Suggestion Module, Validation Engine, Semantic Analyzer, and Continuous Learning Orchestrator—enable data-driven, scalable creation and maintenance of a robust semantic framework.
Outputs and Integration Handoff
The completed taxonomy and schema definition stage yields structured artifacts and establishes dependencies to support downstream tagging, enrichment, and model training.
- Versioned Taxonomy Ontologies: Hierarchical concept hierarchies stored in a centralized registry for traceability.
- Controlled Vocabularies and Glossaries: Defined terms with definitions, synonyms, preferred labels, and provenance.
- Schema Templates: Metadata blueprints specifying required and optional attributes, data types, and validation constraints.
- Mapping Specifications: Crosswalk documents aligning internal terms with external standards like IPTC, Dublin Core, or Schema.org.
- API Definitions: OpenAPI-compliant endpoints exposing taxonomy lookups, term suggestions, and validation operations.
- Governance Reports: Change logs and approval records documenting term additions, deprecations, and structural updates.
Dependencies
- Domain Experts from editorial, legal, marketing, and production teams for term validation and relevance.
- Metadata Management Platforms such as PoolParty and Ontotext GraphDB for ontology hosting, version control, and API exposure.
- Asset Management Systems like Adobe Experience Manager Assets and Mosaiq for sample retrieval and metadata synchronization.
- Security and Access Controls via enterprise identity providers to enforce role-based permissions.
- Project Management Tools such as JIRA and Confluence for tracking requests, reviews, and approvals.
Handoff to Model Training
- API-Driven Retrieval: Training pipelines consume taxonomy and schema via RESTful or gRPC endpoints.
- Annotation Tool Integration: Platforms like Prodigy and Labelbox import term lists and templates for accurate labeling.
- Workflow Configuration: Labeling tasks and dataset splits defined according to metadata blueprints and relationship constraints.
- Sample Asset Sets: Preprocessed media collections, enriched with provisional metadata for early validation.
- Version Alignment: Training manifests reference taxonomy versions to ensure reproducibility and support rollback.
- Documentation: Ontology diagrams, term usage guidelines, and API integration instructions shared with data science and DevOps teams.
This robust handoff protocol ensures that supervised learning pipelines are fed with consistent, high-quality labels and that semantic integrity is maintained across the content tagging life cycle.
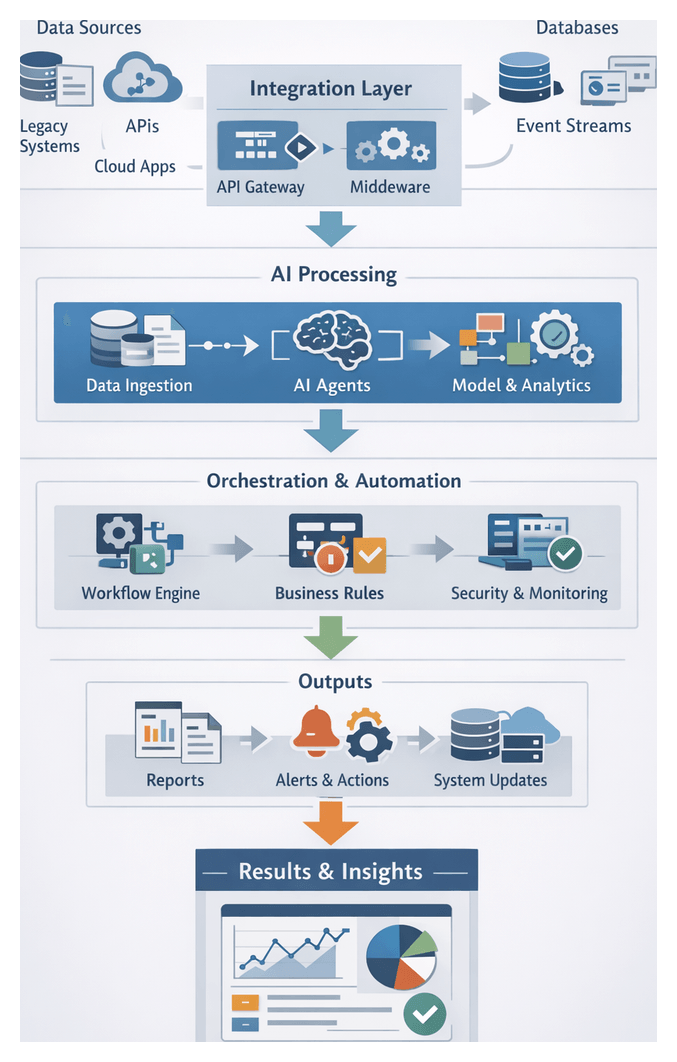
Chapter 4: AI Model Selection and Training
Model Training Purpose and Scope
The model selection and training stage translates business requirements and domain taxonomies into scalable AI solutions for automated content tagging and metadata enrichment. By aligning NLP, computer vision, and multimodal models with enterprise ontologies, teams establish performance baselines for scene detection, object recognition, sentiment analysis, and other tagging tasks. This approach ensures metadata consistency and accuracy across expansive video, audio, and text libraries, directly impacting content discoverability, monetization, and user engagement.
Data Inputs and Environment Prerequisites
Essential Data Inputs
- Annotated Corpora: Text datasets with transcripts, subtitles, and descriptive annotations aligned to the target taxonomy.
- Domain Sample Videos and Frames: Curated clips and key frames paired with bounding boxes, object labels, and action annotations.
- Audio Excerpts with Transcriptions: Dialogue, ambient sounds, and musical scores annotated with speaker identities and emotion labels.
- Taxonomy Definitions: Hierarchical schemas and controlled vocabularies guiding output classes during training and inference.
- Baseline Metadata Records: Existing tags, ratings, and engagement signals for transfer learning.
- Performance Benchmarks and SLAs: Historical metrics and error rate requirements for automated hyperparameter tuning in Amazon SageMaker and Google Cloud AI Platform.
- Compute Environment Specifications: GPU and CPU cluster details supporting distributed training workflows.
- Data Privacy and Compliance Guidelines: Licensing constraints and PII handling policies enforced by frameworks like Hugging Face.
- Stakeholder Requirements: Accuracy thresholds, supported languages, and content rating criteria from editorial, legal, and production teams.
Prerequisites and Conditions
- Preprocessed Assets: Format normalization, noise reduction, and quality scoring as outlined in earlier pipeline stages.
- Validated Taxonomy: Finalized metadata schema approved by domain experts to prevent model confusion.
- Sufficient Data Volume and Diversity: Minimum tens of thousands of labeled segments or frames covering varied accents, dialects, and scene contexts.
- Defined Data Split Strategy: Training, validation, and test partitions respecting content ownership and preventing data leakage.
- Reserved Compute Resources: Availability of GPU instances or on-premise servers, scheduled to.optimize cost and utilization.
- Monitoring and Logging: Telemetry agents integrated with platforms such as NVIDIA Clara for real-time visibility.
- Security and Access Controls: Role-based access control, encryption at rest and in transit, and secure code repository governance.
- Baseline Model Inventory: Catalog of pretrained checkpoints and transfer learning candidates to accelerate experimentation.
- Governance Workflows: Approval processes for bias assessment, model proposal reviews, and release sign-offs.
Workflow Actions and Integrations
The training workflow orchestrates a sequence of activities—from initial evaluation through final validation—using system-to-system integrations and human reviews. This structured flow ensures repeatable, auditable, and scalable model development.
Phase 1: Model Evaluation
- Data Retrieval: Query the metadata repository via RESTful APIs authenticated with OAuth to fetch training datasets.
- Baseline Model Loading: Fetch pretrained networks from the TensorFlow Model Garden or Hugging Face registry, orchestrated by Kubeflow.
- Automated Benchmarking: Execute inference on validation data and store metrics in MLflow.
- Stakeholder Review: Notify ML engineers and data scientists via messaging integrations for performance approval or rejection.
Phase 2: Transfer Learning and Hyperparameter Optimization
- Job Submission: Launch fine-tuning tasks on Amazon SageMaker or Google Cloud AI Platform with specified container images and dataset URIs.
- Preprocessing Pipeline: Execute DAGs in Apache Airflow, standardizing inputs, augmenting images, and tokenizing text, with events streamed via Apache Kafka.
- Hyperparameter Sweeps: Coordinate searches through Azure Machine Learning or Weights & Biases, reporting trial metrics back to the experiment tracker.
- Autoscaling: Use Kubernetes autoscaler policies defined in Infrastructure as Code to adjust compute nodes dynamically.
Phase 3: Iterative Training and Validation
- Continuous Retraining: Schedule nightly retraining cycles using cron jobs in the orchestration framework.
- Cross-Validation: Partition data into folds to evaluate model generalization, comparing results against historical benchmarks.
- Anomaly Detection: Apply statistical tests to identify performance drift, triggering alerts via the monitoring service.
- Human-in-the-Loop: Generate review tasks in ticketing systems when drift exceeds thresholds, enabling expert sample annotation and pipeline re-ingestion.
Phase 4: Versioning and Artifact Management
- Artifact Packaging: Bundle model weights, architecture definitions, and metadata into versioned container images.
- Registry Publication: Push containers to the model registry with metadata stored in a relational database.
- Deployment Descriptor Update: Tag the new model for production rollout via configuration management services.
- Audit Logging: Record parameters, metrics, and lineage in a secure ledger for compliance and forensics.
Phase 5: Final Quality Gate
- Benchmark Tests: Run end-to-end evaluations for inference latency, adversarial robustness, and bias checks.
- Dashboard Generation: Synthesize performance, fairness, and resource consumption metrics into centralized dashboards.
- Approval Workflow: Route dashboards for digital signatures; record acceptance or remedial actions.
- Release Flagging: Set flags in the configuration store to trigger downstream agent orchestration design.
Integration relies on event-driven architectures, uniform API orchestration, centralized metadata stores, and an observability stack ensuring security and governance across inter-service interactions.
AI Capabilities and Supporting Roles
Advanced AI functions and system roles coalesce to form an enterprise-grade training pipeline. These capabilities reduce manual experimentation, improve accuracy, and embed governance.
AI-Driven Capabilities
- Neural Architecture Search: Automated discovery of optimal network topologies through reinforcement or gradient-based search.
- Meta-Learning: Initialization strategies leveraging prior outcomes to accelerate adaptation to new content styles.
- Transfer Learning: Seamless import of PyTorch or TensorFlow checkpoints for domain-specific fine-tuning.
- Hyperparameter Optimization: Bayesian and evolutionary strategies executed by Ray Tune and Weights & Biases.
- Data Augmentation: Customized pipelines with Albumentations and GAN-driven synthetic data generation for rare scenarios.
- Ensemble and Distillation: Model fusion techniques and knowledge distillation to balance accuracy with inference efficiency.
- Interpretability: Saliency maps and attention visualizations for compliance audits.
- Multi-Modal Fusion: Cross-modal embeddings combining visual, textual, and audio features for contextual tagging.
System Roles and Responsibilities
- Training Orchestrator: Coordinates containerized jobs on Kubernetes, automating event-driven triggers from taxonomy updates.
- Data Pipeline Manager: Secures ingestion and preprocessing, ensuring reproducibility and lineage tracking.
- Feature Store: Serves precomputed embeddings and descriptors, providing low-latency feature access.
- Hyperparameter Tuner: Allocates resources dynamically and integrates search algorithms via Azure Machine Learning and Weights & Biases.
- Experiment Tracker: Logs configurations and metrics in MLflow, enabling comparative analytics and reproducibility.
- Validation Engine: Automates QA tests, adversarial checks, and performance alerts.
- Model Registry and Governance Agent: Manages artifact storage, approval workflows, and audit trails.
- Resource Manager: Provisions and scales GPU/CPU clusters, enforcing cost optimization and tenant isolation.
- Security and Compliance Agent: Enforces RBAC, encryption standards, and immutable audit logging.
- Collaboration Interface: Delivers real-time notifications and dashboards to stakeholders, capturing feedback for continuous improvement.
Artifacts, Dependencies, and Handoff Protocols
Output Artifacts
- Model binaries and weight files in SavedModel or ONNX formats.
- Evaluation reports detailing accuracy, recall, F1 score, and AUC.
- Hyperparameter tuning logs from Amazon SageMaker and Weights & Biases.
- Serialized preprocessing pipelines, tokenizers, and feature extractors.
- Model cards documenting purpose, provenance, limitations, and version history.
- Container images and Kubernetes manifests for scalable inference deployment.
- Versioned dataset snapshots in Amazon S3 or Google Cloud Storage.
Dependencies and Resources
- Compute clusters with GPUs/TPUs on Google Cloud AI Platform or managed EC2 GPU fleets.
- Distributed training frameworks such as TensorFlow and PyTorch.
- Feature store and data lake integration for consistent schema enforcement.
- Cataloging and registry services via MLflow or the Amazon SageMaker Model Registry.
- Hyperparameter optimization platforms like Optuna and SageMaker Automatic Model Tuning.
- Orchestration engines such as Kubeflow Pipelines and Apache Airflow.
- Security frameworks for identity and access management, encryption, and audit logging.
- Registry Event Triggers: Notifications via Apache Kafka or AWS SNS to downstream orchestration services.
- Inference Endpoint Deployment: Configuration of REST or gRPC services on Amazon SageMaker Endpoints or Google Cloud Run.
- API Contract Definitions: OpenAPI or Protocol Buffer specifications for input/output schemas and authentication.
- Resource Tagging: Propagation of labels for environment, version, and ownership to support policy enforcement.
- Access Controls: Role-based permissions granting AI agents model artifact access.
- Documentation Handover: Publication of model cards and usage guidelines to a centralized knowledge base.
Version Control and Documentation
- Git and data-version control tags aligning code commits with dataset snapshots.
- Automated model card generation capturing training context and performance summaries.
- Changelog tracking for systematic recording of iterative changes and impact assessments.
Validation and Quality Assurance
- Automated Regression Tests: Compare new outputs against established baselines.
- Bias and Fairness Assessments: Evaluate performance across demographic and content slices.
- Drift Detection: Monitor statistical deviations in input feature distributions.
Integration Testing
- Contract Testing: Validate API schema adherence and error handling conventions.
- Load Testing: Assess inference latency and throughput under simulated peak loads.
- Resilience Verification: Test fallback and retry logic for model endpoint failures.
By unifying these processes—data preparation, model evaluation, iterative training, artifact management, and rigorous validation—teams establish a robust framework that propels trained models seamlessly into AI-driven tagging orchestration, delivering consistent, high-fidelity metadata at enterprise scale.
Chapter 5: AI Agent Orchestration and Workflow Design
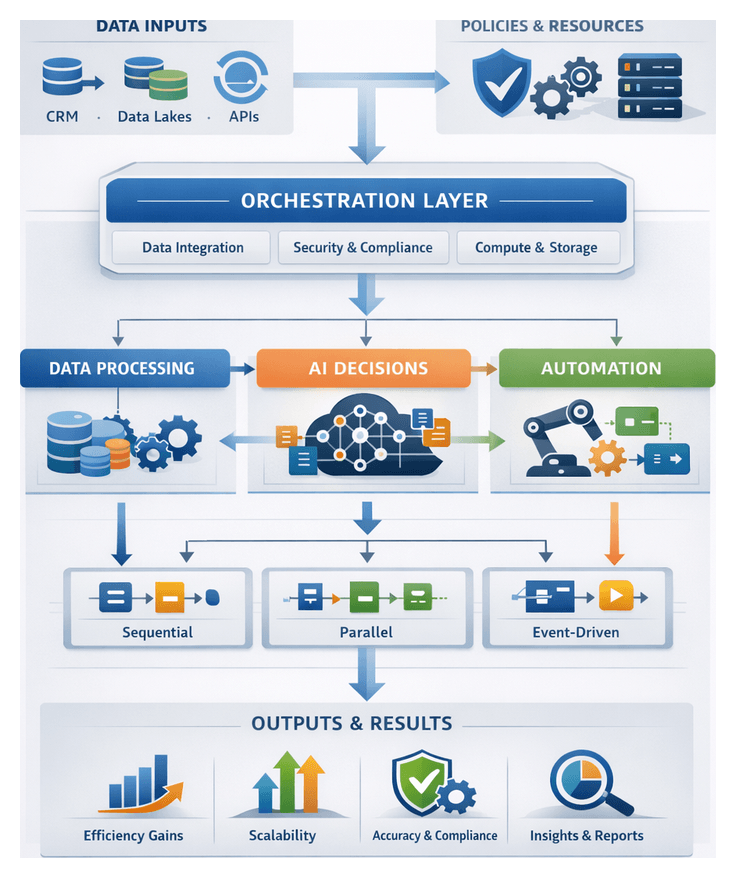
Purpose and Context of the Orchestration Stage
The orchestration stage establishes a unified control layer that coordinates specialized AI agents, external services, and system components into a seamless, end-to-end pipeline for automated content tagging and metadata enrichment. By defining clear execution paths, event triggers, and handoff protocols, this stage transforms independently trained computer vision, natural language processing, audio analysis, and semantic enrichment models into a scalable workflow capable of processing vast media libraries with minimal manual intervention.
Entertainment and media organizations manage extensive catalogs of video, audio, and image assets that must be accurately tagged and classified to support content discovery, personalization, and monetization strategies. Traditional manual approaches cannot scale to millions of hours of footage or continuous user-generated streams. The orchestration layer addresses challenges such as data transfer latency, parallel execution conflicts, inconsistent metadata outputs, and compliance requirements by enforcing standardized protocols for task initiation, handoff, error recovery, and auditability.
Prerequisites and Inputs
The orchestration design relies on a comprehensive set of organizational standards, model artifacts, and infrastructural components collected from earlier solution planning phases. Key inputs include:
- Trained AI model artifacts for computer vision, NLP, audio analysis, and multimodal inference, along with associated metadata schema definitions.
- Event definitions and messaging schemas detailing content arrival, preprocessing completion, and taxonomy updates.
- API specifications for AI agent endpoints, including input/output contract definitions, authentication mechanisms, and rate limits.
- Container images, compute cluster profiles, service quotas, and storage allocations informed by performance benchmarks and service-level objectives.
- Security and compliance policies governing data classification, encryption requirements, access control matrices, and audit logging standards.
- Governance guidelines for version control, CI/CD pipelines, release management protocols, and documentation requirements.
- Monitoring and logging specifications for capturing workflow metrics, error traces, and audit events in real time.
- Test harnesses, integration test suites, and acceptance criteria documents designed to validate orchestration logic in sandbox environments.
Infrastructure Requirements
Successful deployment demands a robust infrastructure foundation:
- A messaging backbone such as Apache Kafka or RabbitMQ for event pub/sub and task queueing.
- An API gateway and identity management services to secure agent invocations and enforce role-based access controls.
- Container orchestration platforms like Kubernetes or serverless frameworks to host and scale AI workloads.
- Centralized configuration management tools for environment parameterization, secrets injection, and feature flag support.
- Monitoring and logging infrastructure, including time-series databases and dashboards built with Prometheus and Grafana, alongside distributed tracing via Jaeger.
Governance and Compliance
Orchestration workflows must adhere to enterprise and industry regulations:
- Source control repositories for workflow definitions, infrastructure as code, and API contract schemas.
- Automated CI/CD pipelines that validate workflows, run integration tests, and promote changes across development, staging, and production environments.
- Release management protocols specifying rollback procedures, change approval boards, and version tagging conventions.
- Security guidelines for data classification, encryption at rest and in transit, and least-privilege access enforced via AWS IAM or Azure Active Directory.
- Audit logging specifications that capture user activity, service interactions, and policy violations for forensic analysis.
API and Schema Definitions
Clear API contracts and message formats prevent integration mismatches:
- OpenAPI or GraphQL definitions detailing request payloads, response structures, and error codes.
- Event schema documents in JSON Schema, Avro, or Protocol Buffers to enforce payload validation.
- Authentication and authorization protocols such as OAuth 2.0 or mutual TLS for secure API access.
Performance and Error Management
To meet operational targets, the orchestration design must include:
- Key performance indicators such as task execution times, queue latencies, and throughput thresholds.
- Retry policies, circuit breaker configurations, and dead-letter queue definitions for robust error handling.
- Incident response playbooks outlining notification channels, on-call rosters, and escalation procedures.
Workflow Design and Execution Flow
The orchestration framework implements an event-driven pipeline where validated events initiate AI-driven tasks according to parameterized workflow templates. Each stage in the flow is defined by trigger definitions, branching logic, and retry policies that ensure resilience and flexibility.
Event Ingestion and Validation
The process begins with capturing events that indicate new or updated media assets. Sources include content management systems, media repositories, manual approvals, or scheduled jobs. Upon receipt, the orchestration engine validates events against schema definitions and required metadata fields. Invalid or incomplete messages are diverted to an exception queue for remediation.
Task Orchestration and Trigger Management
Validated events are mapped to specific workflows based on routing rules. Workflow templates—defined as directed acyclic graphs using frameworks such as Apache Airflow or Prefect—specify task sequences, branching conditions, and retry behaviors. Triggers may be time-based, event-based, or conditional on asset attributes. The orchestrator issues REST or gRPC calls to microservices hosting AI models, taxonomy services, and metadata repositories.
Parallel Processing Streams
To maximize throughput, independent processing streams execute concurrently:
- Vision Stream: Object recognition, scene detection, and facial analysis via computer vision models.
- NLP Stream: Transcript analysis, entity extraction, and topic tagging through natural language processing.
- Audio Stream: Sentiment scoring, speaker diarization, and acoustic event detection on audio tracks.
- Enrichment Stream: Integration with external knowledge graphs and recommendation engines for semantic relationships.
Each stream operates on separate task queues, converging at a synchronization gate where intermediate results merge for downstream processing.
Dynamic Agent Delegation
The orchestrator leverages metadata attributes, performance metrics, and resource availability to assign tasks to optimal compute resources. High-resolution video may be directed to GPU-accelerated clusters, while short-form content runs on CPU instances. Service discovery provided by Kubernetes ensures agent endpoints are located dynamically, and autoscaling policies adjust capacity based on queue depth and resource utilization.
Error Handling and Recovery Mechanisms
Robust error management prevents task failures from cascading across the pipeline. Layers of fault tolerance include:
- Automated retries with exponential backoff for transient errors.
- Fallback agents or simplified algorithms when primary services are unavailable.
- Dead-letter queues capturing persistent failures with error context.
- Integration with Prometheus and alert routers to notify engineering teams of critical issues.
State Management and Handoff Coordination
A centralized state store records task statuses, input/output payload references, and timestamps to support idempotency and restartability. Standardized handoff interfaces package enriched metadata with provenance information before dispatching to subsequent stages.
Scalability and Autoscaling Integration
Autoscaling frameworks respond to workload fluctuations by adjusting the number of orchestrator and agent instances. Scaling triggers include Kubernetes pod metrics, message queue depths, and custom performance indicators derived from Apache Kafka consumer lag or inference latencies.
Governance, Security, and Observability
Policy engines and service meshes enforce role-based access controls, encrypt data in transit and at rest, and audit every task invocation and configuration change. Observability stacks capture metrics, distributed traces, and structured logs, with dashboards displaying end-to-end processing times, success rates, and SLA compliance.
Final Aggregation and Handoff
Upon completion of parallel streams, the orchestrator consolidates metadata—tags, confidence scores, semantic annotations, and provenance details—into a unified record. A standardized API call or event publication signals the automated classification stage to ingest enriched tags into the media asset repository.
AI Roles and Capabilities
The orchestration layer comprises modular AI agents and governance engines, each fulfilling specialized functions under central coordination. These roles ensure efficient task delegation, fault tolerance, human oversight, and continuous optimization.
- Central Orchestration Engine: Acts as the command center, parsing and routing events, scheduling tasks via DAG frameworks such as Apache Airflow or Prefect, and enforcing policies for data retention, privacy, and audit logging.
- Event-Driven Trigger Manager: Listens to event streams from platforms like AWS Step Functions or Google Cloud Pub/Sub, enriches payloads with contextual data, prioritizes tasks using ML-based models, and fans out events to parallel pipelines.
- Dynamic Task Delegation Agent: Selects optimal AI models and compute resources based on metadata characteristics, historical performance, and resource availability. Implements load balancing and elastic scaling through reinforcement learning strategies and fallback orchestration.
- Error Handling and Self-Healing Components: Detects anomalies using statistical analysis, initiates automated retries, reprovisions failed components, and escalates persistent issues to human operators with diagnostic context.
- Conversational AI and Human-in-the-Loop Interfaces: Provides chat-based supervision and exception management via platforms like Google Dialogflow. Enables asset queries, approval workflows, interactive pipeline control, and captures intervention metadata for governance.
- Logging, Monitoring, and Analytics Agents: Collects telemetry data for real-time dashboards, applies predictive analytics to forecast capacity needs, correlates enrichment results with business KPIs, and triggers alerts for anomaly detection.
- API Gateway and Integration Brokers: Facilitates interoperability between REST, gRPC, and message queue protocols. Validates metadata schemas, enforces security policies, and implements adaptive rate limiting using service mesh features from Istio or Kong.
- Governance and Policy Enforcement Modules: Tracks data lineage, applies rule-based validation for PII masking and retention schedules, generates compliance reports, and adapts policies through reinforcement learning to reflect evolving regulations.
Outputs, Dependencies, and Handoff to Tagging
Completion of the orchestration stage yields a suite of artifacts, external service dependencies, and handoff protocols that drive downstream tagging and classification engines.
Primary Outputs
- Workflow Definition Artifacts in JSON or YAML outlining task sequences, branching logic, retry policies, and timeouts.
- Agent Configuration Packages bundling model endpoints, parameter files, and runtime dependencies for consistent deployments.
- Event and Message Schemas in JSON Schema, Avro, or Protocol Buffers for payload validation.
- Operational Dashboards integrated into Apache Airflow or Prefect to visualize workflow topologies, pending tasks, and resource assignments.
- Execution Logs and Metrics captured by centralized logging services and dashboards built on Prometheus and Grafana for performance analysis.
- Error and Exception Reports summarizing failed tasks, error codes, and stack traces for rapid triage.
- State Snapshots and Checkpoints that preserve in-flight events and partial results for fault recovery and warm restarts.
- Audit Trails and Compliance Records providing immutable logs of event flows, human approvals, and configuration changes.
Key Dependencies
- Message Brokers such as Apache Kafka or RabbitMQ for event transport and task queuing.
- API Gateway and Service Mesh solutions like Istio or Kong for load balancing, service discovery, and security enforcement.
- Container Orchestration via Kubernetes or Amazon EKS to schedule agent containers and manage autoscaling.
- Compute and GPU Resources managed by cluster schedulers or Kubernetes operators to optimize inference performance.
- Metadata Repository and Configuration Store implemented with Apache Cassandra or HashiCorp Vault for secure key management and schema storage.
- Identity and Access Management through AWS IAM or Azure Active Directory for authentication and authorization.
- Monitoring and Alerting Systems such as Prometheus and Grafana for SLA monitoring and incident notifications.
- Logging and Tracing Infrastructure leveraging the ELK Stack or Lightstep for distributed log aggregation and root-cause analysis.
- Secrets Management via HashiCorp Vault for storing API keys, certificates, and credentials.
- Network and Security Policies enforcing zero-trust frameworks, VPNs, and firewall rules to secure inter-service communication.
Handoff to Automated Tagging and Classification
- Task Queues with Payload Envelopes using Amazon SQS or RabbitMQ, containing asset references, taxonomy identifiers, and invocation instructions.
- Model Endpoint References listing URIs for inference services hosted on AWS SageMaker or microservice endpoints, along with credentials and API schemas.
- Contextual Metadata Tags including initial enrichment attributes like production date, content type, and geolocation to guide classification rules.
- Execution Parameters such as retry limits, concurrency settings, and sampling thresholds optimized for cost and accuracy.
- Flow Control Signals implementing back-pressure, token buckets, and throttling configurations to prevent downstream overloads.
- Validation Schemas and Quality Gates using JSON Schema or OpenAPI definitions to verify tagged metadata before acceptance.
- Security Tokens like JWTs or OAuth 2.0 scopes scoped for downstream classification stages.
- Notification Hooks via webhooks or callback URLs for status updates and completion events integrated into monitoring dashboards.
This integrated set of outputs, dependencies, and handoff protocols constitutes the connective tissue that binds AI-driven agents into a unified, scalable, and auditable metadata enrichment system. By packaging rich context, enforcing governance, and maintaining full observability, the orchestration stage ensures that downstream tagging and classification execute accurately and reliably at scale.
Chapter 6: Automated Content Tagging and Classification
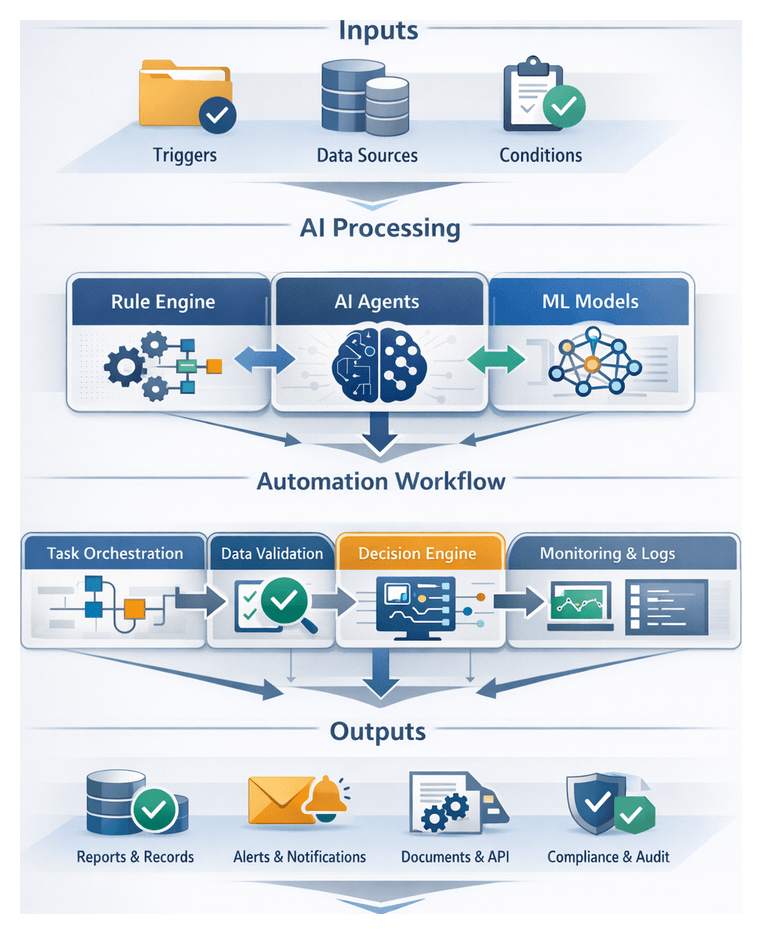
Stage Purpose and Inputs
Purpose and Objectives
The Automated Content Tagging and Classification stage systematically analyzes video, audio, text, and image assets to assign descriptive tags and classification labels. Leveraging computer vision, natural language processing, audio analysis, and ensemble learning, it generates consistent, taxonomy-compliant metadata that powers search indexing, personalized recommendations, targeted advertising, and automated workflows. Each tag is accompanied by a confidence score, enabling dynamic validation policies and human-in-the-loop review.
Use Case Scenarios
- Content Discovery and Recommendation: Scene-level insights drive recommendation engines, boosting viewer retention through personalized suggestions.
- Advertising and Brand Safety: Object and logo detection via Amazon Rekognition or Google Cloud Vision API enforces brand guidelines and ad placement rules.
- Regulatory Compliance: Automated detection of explicit content, violence, or hate speech tags assets for human review and policy enforcement.
- Closed Captioning and Subtitling: NLP-driven keyword extraction using AWS Comprehend or the OpenAI API facilitates dynamic subtitle generation and segment labeling.
- Rights Management and Syndication: Metadata on cast, crew, and licensing automates syndication workflows and royalty tracking.
- Asset Monetization and Cataloguing: Retailers and broadcasters assemble content bundles and targeted ads using enriched metadata.
Scale and Performance Considerations
To handle petabyte-scale libraries and real-time streams, design for horizontal scalability, batch and stream processing, and cost optimization. Co-locate compute near storage or deploy edge nodes for low-latency tagging of high-resolution assets. Implement auto-scaling policies on platforms such as Kubernetes or AWS Fargate, and integrate performance monitoring tools to track throughput, service latencies, and queue backlogs.
Required Inputs and Preconditions
- Preprocessed Media Assets: Standardized video (MP4, MOV), audio (AAC, WAV), and transcripts (WebVTT, SRT) from the quality assurance stage.
- Taxonomy Definitions: Controlled vocabularies, hierarchical category trees, and schema templates accessible via API or registry.
- Trained AI Models: Computer vision services such as Azure Computer Vision, NLP engines like Google Cloud Natural Language, and ensemble classifiers for multimodal fusion.
- Configuration Parameters: Confidence thresholds, resource quotas, batch sizing, and failover policies.
- Infrastructure Endpoints: Object storage (AWS S3, Google Cloud Storage), message brokers (Apache Kafka, RabbitMQ), metadata service APIs, and authentication systems.
- Governance Policies: Data privacy, compliance (GDPR, CCPA), monitoring frameworks, and human-in-the-loop review protocols.
- Stakeholder Sign-Off: Approvals from taxonomy owners, data engineers, AI practitioners, security officers, product managers, and operations teams.
Workflow Actions and Flow
The tagging workflow orchestrates event-driven triggers, microservices, and AI agents through a sequence of coordinated steps. Clear handoffs and communication protocols minimize latency and support parallel execution across distributed systems.
- 1. Event Trigger and Asset Retrieval: The orchestrator (for example, Apache Airflow) consumes an event from Kafka or RabbitMQ, validates eligibility, fetches media and transcripts from AWS S3 or Google Cloud Storage, and retrieves taxonomy schemas via API. A “Ready for Tagging” event then enqueues AI processing tasks.
- 2. Preprocessing Validation and Segmentation: A media processing microservice performs frame extraction or shot boundary detection, applies quality checks, and flags segments below thresholds for retry or human review.
- 3. Vision-Based Analysis: Computer vision agents using AWS Rekognition, Google Cloud Vision API, or Azure Computer Vision perform scene classification, object detection, face recognition, and OCR. Outputs include bounding boxes, confidence scores, and actor matches to talent databases.
- 4. Textual Analysis: NLP agents generate or ingest transcripts via IBM Watson Speech to Text or Azure Speech Services. Using AWS Comprehend or transformer models from OpenAI, they extract entities, topics, sentiment scores, and align speaker diarization metadata.
- 5. Ensemble Fusion and Tag Aggregation: A fusion engine normalizes confidence scores, applies taxonomy rules to merge tags, resolves duplicates (for instance “car” vs. “automobile”), and flags low-confidence or conflicting tags for escalation.
- 6. Contextual Enrichment: Graph-based agents link entities to external sources (IMDb, cultural databases), detect temporal patterns (narrative arcs, motifs), and incorporate personalization signals from engagement models.
- 7. Quality Assurance and Exception Handling: A monitoring service triggers alerts on SLA breaches or confidence anomalies, applies conflict resolution rules, and logs audit trails. Exceptional tasks route to human review interfaces (for example, JIRA or AgentLink AI dashboards).
- 8. Metadata Packaging and Handoff: Enriched metadata is compiled into JSON payloads conforming to schema definitions, validated for completeness, and dispatched via event topics or REST callbacks to downstream semantic enrichment or CMS connectors.
- 9. Performance Optimization: Dynamic task allocation on Kubernetes or serverless functions, in-memory caching of models and taxonomies, batch inference, and backpressure mechanisms ensure scalable, cost-effective processing.
- 10. Observability: Centralized logging (Elasticsearch, Splunk), metrics dashboards (Grafana, Prometheus), and distributed tracing with unique trace IDs provide end-to-end visibility for debugging and continuous improvement.
AI Capabilities and System Roles
AI-driven tagging pipelines combine specialized agents and infrastructure components to deliver accurate, consistent metadata. Key capabilities span computer vision, NLP, audio analysis, multimodal fusion, model serving, governance, and developer tools.
- Computer Vision: Deep learning models such as ResNet or EfficientNet detect objects, scenes, faces, logos, and perform OCR. Services include Google Cloud Vision and Clarifai, with roles like object recognition, scene segmentation, face identification, and text extraction.
- Natural Language Processing: Speech-to-text conversion by IBM Watson or Azure Speech Services, followed by named entity recognition, sentiment analysis, and topic modeling using LDA or transformer embeddings from OpenAI GPT.
- Audio Analysis: Acoustic scene classification, music recognition via Audd.io, speaker diarization, and audio quality assessment enrich metadata with ambient and speech characteristics.
- Multimodal Fusion: A confidence aggregator and conflict resolution engine align outputs across modalities, apply governance rules, and produce cohesive tag sets through a fusion orchestrator.
- Model Serving Infrastructure: Platforms such as Amazon SageMaker and MLflow host models with auto-scaling GPU/CPU clusters, API gateways for authentication, and versioned model registries.
- Schema Validation and Metadata Registry: Validation agents enforce controlled vocabularies using enterprise platforms like Collibra or Alation, ensuring tag conformity and ontology integrity.
- Human-in-the-Loop: Low-confidence annotations feed into review dashboards (JIRA, Labelbox, Prod.ly), with feedback ingested for active learning and model retraining cycles.
- Monitoring and Governance: Metrics collectors, alerting engines, and audit logging services underpin compliance with data privacy regulations (GDPR, CCPA) and organizational policies enforced by policy engines.
- Developer Tools: REST and gRPC APIs, SDKs, and API sandboxes streamline integration. Feature toggles enable canary deployments of new models or taxonomy updates.
- Scalability and Cost Optimization: Spot instance orchestration, pipeline prioritization, and cost analytics dashboards optimize resource usage. Geo-distributed deployments and disaster recovery ensure high availability.
- Modular Microservices: A service registry, dependency graph manager, and hot-swap deployment mechanism support vendor-agnostic AI modules and seamless upgrades.
- Privacy-Preserving AI: PII detection, anonymization services (face blurring, voice masking), and compliance monitors protect sensitive data.
- Syndication and Edge Processing: Feed generation engines produce EIDR or MPEG-7 exports. Edge inference appliances sync model updates and buffer requests during outages.
Outputs, Dependencies, and Handoffs
Key Outputs
- Enriched Metadata Records: JSON payloads with scene-level annotations, timecode-indexed labels, sentiment scores, and custom taxonomy attributes.
- Confidence Scores: Normalized metrics (0.0–1.0) for each tag, guiding human review thresholds.
- Temporal and Spatial Indexes: Timestamps and coordinates for objects and scene boundaries supporting interactive applications.
- Taxonomy Mapping Artifacts: Lookup tables mapping raw model outputs to canonical terms for traceability.
- Error Reports: Standardized diagnostics capturing asset IDs, error codes, and retry counts.
- Audit and Provenance Logs: Immutable records of processing steps, model versions, and parameters.
- Operational Metrics: Latency, throughput, resource utilization, and queue depths feeding monitoring systems.
- Model Inference Services: Endpoints such as Google Cloud Vision API and OpenAI or containerized pods on Kubernetes.
- Taxonomy and Schema Repositories: API-hosted vocabularies and schema definitions accessed via GraphQL or REST.
- Feature Store: REST or gRPC services providing embeddings and enrichment features.
- Message Bus: Apache Kafka or AWS Kinesis for event streaming and task coordination.
- Storage and Asset Catalog: Object storage (Amazon S3) or DAM systems for media files and sidecar metadata.
- Orchestration Engine: Workflow platforms like Apache Airflow or Prefect managing dependencies and retries.
- Authentication and Security: OAuth 2.0, service accounts, and key management for secure access.
- Monitoring and Alerting: Telemetry to Prometheus, Grafana, or Datadog with alerting on anomalies.
Handoff Mechanisms
- Event-Driven Messaging: Publishing metadata to topics consumed by semantic enrichment or CMS stages, including asset IDs, JSON records, timestamps, and correlation IDs.
- API Callbacks: RESTful delivery to enrichment endpoints conforming to OpenAPI schemas with status codes indicating success or retry instructions.
- Database Writes: Metadata store updates with change data capture for downstream polling.
- Sidecar Files: XML or JSON files alongside media assets signaling readiness for ingestion.
- Governance Controls: Versioned metadata forwarding only after schema validation and confidence checks; quarantined records route to review queues.
- Notifications: Email, chat, or incident system alerts containing error context and links to logs.
Best Practices
- Define versioned JSON schema contracts and validate payloads early.
- Implement idempotent operations with deduplication keys.
- Enforce backpressure and rate limits via message brokers or API gateways.
- Monitor end-to-end metrics such as tagging latency and failure rates.
- Use feature toggles for controlled rollouts of new models or taxonomies.
- Document interfaces, event schemas, and runbooks in a shared repository.
Resilience and Observability
- Retry policies with exponential backoff and dead-letter queues for persistent errors.
- Circuit breakers to protect dependent services and prevent cascading failures.
- Structured logging with standardized fields for root cause analysis.
- Distributed tracing to visualize end-to-end request flows and identify latency hotspots.
- Automated health checks exposing readiness and liveness probes for containerized services.
Chapter 7: Metadata Enrichment and Semantic Analysis
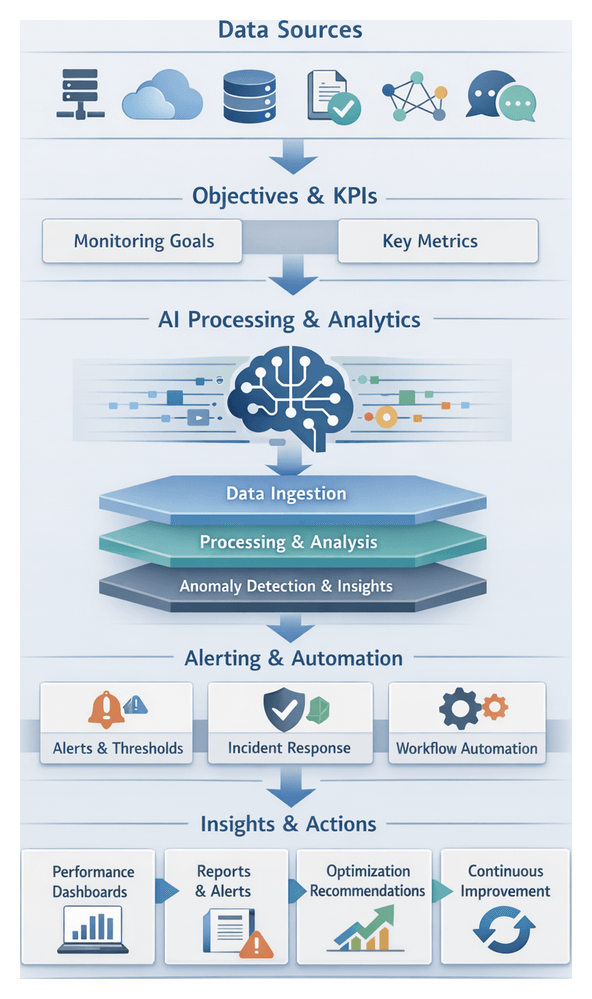
Purpose and Foundational Inputs
In a media landscape where assets proliferate daily and audiences expect personalized, context-rich experiences, metadata enrichment and semantic analysis transform flat tags into interconnected, meaningful data that powers search, recommendations, localization, and analytics. This stage bridges automated tagging with human expertise and user behavior signals, generating metadata that reflects narrative themes, emotional tone, and cultural context.
- Enhanced Discoverability: Semantic links enable contextual queries—such as “family dramas set in wartime”—delivering precise results across vast catalogs.
- Personalization and Recommendations: Sentiment scores and engagement metrics inform engines that match content to individual preferences and emotional triggers.
- Content Intelligence: Deep insights into emerging themes, sentiment shifts, and content gaps guide editorial strategies, marketing campaigns, and rights management.
- Localization and Cultural Adaptation: Knowledge graphs map idioms and references to equivalent concepts in target markets, streamlining translation and subtitling.
- Automation of Downstream Processes: Rich metadata drives closed caption generation, highlight reel creation, and dynamic ad insertion without manual intervention.
Achieving these outcomes requires a robust set of inputs and operational prerequisites:
- Initial Tag Sets: Primary labels—genre, cast, location, objects—serve as seed data, with confidence scores guiding resource allocation for deeper analysis.
- Taxonomy and Schema Definitions: Controlled vocabularies and hierarchical ontologies—aligned with standards like IPTC or EIDR—ensure uniform terminology and consistent metadata structure.
- Knowledge Graphs and Ontologies: External sources such as Neo4j, AWS Neptune, or GraphDB provide real-world entity relationships that enrich semantic links.
- User Engagement Signals: View counts, watch durations, skip rates, and social interactions from analytics platforms inform sentiment clustering and dynamic tagging.
- External Data Sources: Filmography from IMDb, music metadata from MusicBrainz, and cultural data from DBpedia supplement internal taxonomies for comprehensive coverage.
- Trained AI Models: Frameworks like TensorFlow, PyTorch, and APIs from OpenAI power entity extraction, sentiment analysis, and embedding generation.
- Governance Policies and Compliance: GDPR, CCPA, and rights clearance agreements govern data usage, retention, and auditing throughout the enrichment process.
- Technical Infrastructure and APIs: Scalable compute, storage, message queues, and secure API endpoints enable real-time graph queries, model inference, and asynchronous processing.
Workflow and AI-Driven Processes
Graph-Based Knowledge Integration
The workflow begins by extracting explicit and implicit relationships from transcripts, scene descriptions, and initial tags. Event triggers—such as new metadata batches in Amazon S3 or topics in Apache Kafka—invoke serverless functions that call Amazon Comprehend or Google Cloud NLP to detect named entities, relation pairs, and sentiment.
- Normalization: Extracted triples are aligned with the controlled vocabulary in the taxonomy registry.
- Graph Ingestion: Structured (subject, predicate, object) triples are published to a graph ingestion topic for downstream consumption.
- Graph Augmentation: A microservice batches incoming triples and merges them into a central knowledge graph powered by Neo4j or AWS Neptune, resolving duplicates via Cypher or Gremlin scripts.
- Contextual Enrichment: APIs to IMDb or Wikipedia fetch unique identifiers and descriptions, while full-text indexes support low-latency semantic queries.
Concept Clustering and Topic Modeling
Building on the knowledge graph, embedding models compute vector representations for entities and metadata. Workloads on Kubernetes clusters leverage TensorFlow or PyTorch for community detection (Louvain, k-means) and topic modeling (LDA, NMF).
- Embedding Generation: Sentence-Transformers and custom BERT variants encode node labels and descriptions into fixed-length vectors.
- Clustering Execution: Algorithms group assets and concepts into coherent clusters, with labels proposed via frequency analysis of representative tags.
- Vector Indexing: Services like Pinecone or Elasticsearch index embeddings for similarity search and rapid retrieval.
- Validation: Cluster stability and coherence metrics guide scheduling frequency and parameter tuning.
Sentiment and Emotion Enrichment
Deep sentiment analysis characterizes mood and emotional arcs within media assets. Transcripts, social media buzz, and review text are processed via Google Cloud Natural Language or AWS Comprehend. Fine-tuned models deployed with Kubeflow or MLflow capture nuanced affective cues.
- Sentiment Scoring: Polarity and emotion labels (joy, anger, surprise) are assigned to scenes and dialogue.
- Temporal Tracking: Time-series databases such as Amazon Timestream store sentiment trends for trailer generation and emotional heatmaps.
Personalization and Recommendation Engines
Real-time user engagement signals—clickstreams, playback events, ratings—feed into personalization modules that recalibrate semantic weights and influence recommendations.
- Data Ingestion: Apache Flink or AWS Kinesis normalize event streams into sessions.
- Weight Calculation: A scoring algorithm updates node and edge weights in the knowledge graph based on engagement intensity.
- Collaborative and Neural Models: AWS Personalize and TensorFlow Extended pipelines train collaborative filtering and attention-based sequence models that integrate text and graph embeddings.
- Real-Time Inference: Streaming APIs on Kubernetes serve personalized rankings with low latency.
Semantic Similarity and Vector Search
To support retrieval by meaning rather than keywords, embedding models from OpenAI or custom BERT variants generate vectors for text and metadata. Approximate nearest neighbor searches are handled by FAISS or Milvus.
- Hybrid Ranking: Vector scores are combined with inverted index results from Elasticsearch to balance semantic proximity and lexical relevance.
Multilingual and Metadata Governance
Cross-lingual consistency is achieved through neural machine translation and language-agnostic embeddings.
- Translation Services: Google Translate and AWS Translate convert tags and descriptions using domain-specific glossaries.
- Cross-Lingual Embeddings: Models like LaBSE and XLM-R enable clustering and search across languages.
- Governance and Quality Control: Apache Atlas and anomaly detection models enforce policy rules, flag outliers, and maintain audit trails.
Orchestration, Monitoring and Human-in-the-Loop
Event-driven orchestration decouples services and ensures reliability. A central orchestrator manages topics — relationship extraction, graph ingestion, clustering results, personalization updates — validated by a schema registry and replayable for recovery or retraining.
- Workflow Tools: Apache Airflow or Dagster define directed graphs with retry logic and exception paths.
- Error Handling: Circuit breakers, exponential backoff, and dead-letter queues segregate failed messages for manual inspection.
- Monitoring: Prometheus and Grafana track throughput, latency, and data drift; alerting notifies teams of anomalies.
- Human Feedback: Anomaly detectors flag low-confidence relationships and cluster labels for expert review, with feedback events retriggering model retraining.
Outputs, Dependencies and Handoffs
Enriched Metadata Artifacts
- JSON-LD packages embedding linked data elements and schema references
- RDF triple files in Turtle or N-Triples for graph databases
- Avro or Protobuf schemas for high-throughput messaging
- CSV or Parquet extracts for analytics platforms
Semantic Graph Updates
- Batch update files with node and edge definitions
- Streaming change logs in Apache Kafka topics
- Graph snapshots for versioning and rollback
Quality, Confidence and Provenance Reports
- Confidence score tables for each relationship and concept
- Provenance logs with model versions, timestamps, and source references
- Anomaly detection summaries for human review
- Audit-ready exports for compliance and SLA tracking
Derived Datasets for Continuous Improvement
- Labeled edge sets for graph embedding retraining
- Concept co-occurrence matrices for taxonomy refinement
- User signal snapshots linked to semantic tags
- Knowledge bases: Wikidata, DBpedia, Neo4j, AWS Neptune, proprietary graphs via REST APIs
- AI models: spaCy, transformer-based APIs, sentiment microservices, Kubeflow pipelines
- Storage and messaging: Amazon S3, Google Cloud Storage, Apache Kafka, AWS Kinesis, relational and NoSQL databases, data lakes
- Governance and security: access control services, encryption key management, data lineage tools
Handoffs to Downstream Systems
Content Management Systems
- Pull endpoints ingesting JSON-LD payloads
- Webhook notifications for new metadata packages
- Off-peak batch import jobs to update assets
Digital Asset Management Systems
- API-driven metadata updates in platforms like Adobe Experience Manager
- Automated reconciliation merging enriched results into existing records
- Notification streams triggering rendition generation based on new attributes
Search Index and Discovery Layers
- Real-time pipelines consuming RDF triples and JSON-LD to enrich search schemas
- Schema update notifications adjusting facets and autocomplete suggestions
- Delta indexing strategies to optimize reindexing performance
Recommendation and Personalization Engines
- Streaming APIs supplying graph embeddings and content vectors
- Batch transfers of concept affinity scores for model training
- Event triggers initiating retraining upon semantic shifts
Analytics and Reporting Platforms
- Scheduled ETL jobs loading confidence scores into data warehouses
- Streaming dashboards receiving real-time enrichment metrics
- Automated alerts when data quality falls below SLAs
Chapter 8: Integration with Content Management Systems
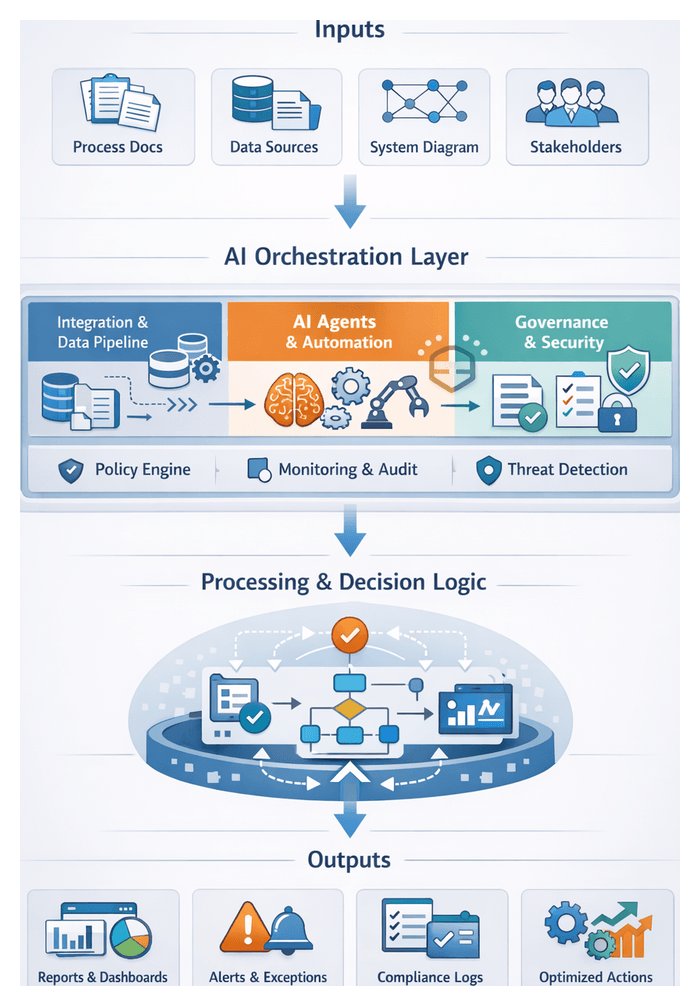
Stage Purpose and Industry Context
The integration stage serves as the essential bridge between AI-driven metadata enrichment and enterprise content management systems (CMS) and digital asset management (DAM) platforms. By automating synchronization of semantic tags, taxonomy classifications, confidence scores, and custom attributes, organizations eliminate data silos, reduce manual errors, and ensure uniform asset discoverability across production, syndication, and archival pipelines. In large-scale media environments—spanning marketing portals, editorial dashboards, rights management repositories, and third-party distribution networks—this stage underpins search optimization, personalized delivery, and cross-platform syndication.
Key objectives include consistent metadata alignment, automated data transfers with minimal manual intervention, version control with conflict resolution and rollback capabilities, audit trails for compliance, and support for real-time or scheduled updates that integrate seamlessly with publishing workflows. Embedding AI-powered workflows within existing CMS frameworks—such as Sitecore, Drupal, WordPress, or Contentful—unlocks improved asset discovery, streamlined publishing pipelines, enhanced personalization, scalable metadata management, and stronger governance posture.
Prerequisites and Inputs
Successful integration demands a well-defined set of inputs and conditions to prepare downstream CMS environments for enriched metadata ingestion without schema mismatches or data loss:
- Enriched Metadata Payloads: Standardized JSON or XML exports containing asset identifiers, taxonomy tags, semantic relationships, confidence scores, timestamps, and custom properties.
- Connector Specifications: API endpoint documentation, authentication methods, data mapping templates, field transformations, rate limits, and error codes—for example, the Contentful Delivery API guide or the Adobe Experience Manager Cloud Service API reference.
- API Credentials and Security Tokens: OAuth2 tokens, API keys, client certificates, and role-based access controls managed in secrets systems like HashiCorp Vault, with automated rotation policies aligned to SOC 2 or ISO 27001 frameworks.
- Network and Connectivity: Secure, low-latency connections via firewall rules, VPN or private links, SSL/TLS certificates, and throughput planning to support high-volume data transfers between orchestration platforms and CMS infrastructure.
- Schema Compatibility and Versioning: Alignment of metadata schema versions between AI enrichment services and CMS, plus a versioning strategy to handle evolution, backward compatibility, and field deprecation.
- Governance and Compliance Policies: Data retention, archival, encryption at rest, audit logging, and role definitions for data stewards, administrators, and compliance officers overseeing integration workflows.
- Operational Runbooks and Error-Handling Protocols: Automated retry strategies, alert escalation paths, and guidelines for manual intervention during API throttling, data validation failures, or network outages.
Integration Workflow and Coordination
Connector Discovery and Registration
An orchestration engine begins by loading connector definitions from a governance registry. Each connector record specifies the target CMS name and version, REST or GraphQL endpoints, HTTP methods for CRUD operations, field-level mapping rules, transformation scripts, and error-handling policies. Connectors for platforms such as Adobe Experience Manager and Contentful are registered with a connector manager service, exposing a registry API for runtime invocation.
Event-Driven Orchestration
Integration tasks are triggered by events emitted at the end of the semantic enrichment stage. A message broker like Apache Kafka or a cloud queue such as AWS SQS transports events containing asset identifiers, destination CMS targets, and priority flags. The orchestration engine enqueues tasks in a distributed work queue, where parallel workers pick up tasks and execute connector sequences.
Data Transformation and Mapping
Workers retrieve enriched payloads from secure metadata stores—such as Amazon S3 or Azure Blob Storage—and apply mapping rules from connector definitions. Transformation activities include renaming fields, flattening nested structures, selecting top-N concepts, normalizing dates and numerics, and enforcing controlled vocabularies. These steps are implemented as lightweight scripts or containerized microservices within the orchestration environment.
API Orchestration and Conflict Resolution
- Check for asset existence with a HEAD or GET request using the unique identifier.
- If the asset exists, issue a PATCH or PUT operation to update metadata selectively; otherwise, create the resource via POST and store the returned CMS identifier.
- Resolve concurrent update conflicts using ETag or version tokens for optimistic concurrency control.
Transient errors (HTTP 429 or 5xx) trigger retry handlers with exponential back-off. Persistent errors (HTTP 4xx) route records to quarantine queues, annotate governance registries with failure reasons, and notify operators via messaging channels.
AI-Driven Capabilities and System Roles
Data Mapping and Schema Alignment
- Schema Inference Engine: A graph neural network analyzes source metadata structures and CMS schema definitions to propose field correspondences, accelerating connector setup for custom taxonomies and nested objects.
- Field Normalization Model: An NLP transformer canonicalizes attribute names—such as “release_date,” “publish date,” or “air_date”—to match CMS schema conventions.
- Ontology Alignment Service: Leveraging embeddings from IBM Watson Knowledge Studio, this service maps controlled vocabulary terms to CMS taxonomy categories for consistent classification.
Intelligent API Adapters and Conflict Detection
- Dynamic Payload Generator: An AI agent constructs JSON or XML payloads by interpreting mapping rules and knowledge graph configurations, handling complex nested structures.
- Rate-Limit Compliance Engine: A reinforcement learning model adjusts request pacing and batch sizes based on historical API performance metrics to avoid throttling.
- Schema Evolution Tracker: An anomaly detection component monitors CMS API schemas for changes—such as new required fields or deprecations—and triggers connector updates.
- Duplicate Detection Model: A clustering algorithm groups metadata instances referring to the same asset and computes similarity scores to flag divergent attributes.
- Resolution Policy Engine: A reinforcement-learned rule system decides conflict outcomes—favoring latest timestamps, highest confidence scores, or expert-approved values.
- Merge Suggestion Agent: An NLP summarizer generates human-readable merge recommendations when automated resolution confidence is low.
Validation, Harmonization, and Enrichment
- Schema Validator: A rule engine checks data types, mandatory fields, string lengths, and value ranges against CMS schema requirements.
- Vocabulary Compliance Checker: An AI model cross-references tags against approved lists and suggests replacements for unrecognized terms.
- Contextual Anomaly Detector: A statistical model identifies outliers in metadata distributions, such as anomalous ratings or sentiment tags.
- Knowledge Graph Enricher: SPARQL query generation models retrieve related entities from knowledge bases like Wikidata to append genre or cast associations.
- Sentiment and Tone Analyzer: An NLP service tags assets by mood—”uplifting,” “dramatic,” or “informative”—to support nuanced recommendations.
- Audience Segmentation Engine: Machine learning clusters user interaction signals and back-propagates preferences into asset metadata for targeted delivery rules.
Real-Time Synchronization and Observability
- Event-Driven Task Scheduler: Built on platforms like Apache Kafka and AWS Step Functions, this scheduler triggers connector executions for new metadata batches or resolved validation errors.
- Transactional Orchestrator: A state machine ensures multi-step API calls succeed or rollback collectively using compensating transactions to maintain consistency.
- Idempotency Manager: Assigns unique request identifiers and tracks processed events to prevent duplicate updates during retries or network disruptions.
- Anomaly Detection Service: A time-series model ingests connector latency, error rates, and payload sizes to surface deviations and trigger alerts.
- Predictive Scaling Model: A capacity-planning engine forecasts API usage spikes—such as new content releases—and allocates cloud resources proactively.
- Audit Trail Generator: An AI agent compiles change events into human-readable timelines, supporting compliance audits and regulatory reporting.
Error Handling, Scalability, and Security
- Smart Retry Scheduler: A reinforcement learning component adjusts retry intervals based on error types—transient network faults, rate limit breaches, or validation errors—to optimize recovery time.
- Dynamic Backoff Algorithm: Balances swift recovery with the risk of overwhelming CMS endpoints by adapting wait times between retries.
- Fallback Routing Engine: Automatically switches to alternate ingestion endpoints or mirror sites when primary APIs fail, ensuring availability.
- Distributed Queue Manager: Partitions tasks across worker nodes based on asset type and priority, dynamically reassigning work in response to node load.
- Batching Optimizer: Analyzes throughput metrics to determine optimal batch sizes for API calls, maximizing efficiency without triggering rate limits.
- Cache Invalidation Service: Predicts usage patterns to invalidate stale metadata caches in the CMS, ensuring end users access up-to-date information.
- Access Control Mediator: Verifies tokens and enforces role-based permissions for API operations to prevent unauthorized metadata changes.
- Data Lineage Tracker: Records the origin of each metadata attribute—model version, timestamp, processing node—for complete traceability.
- PII Detection and Redaction Engine: An NLP classifier identifies and masks personally identifiable information in descriptive fields to comply with privacy regulations like GDPR.
Outputs, Dependencies, and Handoffs
Integration Outputs
- Synchronized asset records in each target CMS, complete with unique identifiers, version history, and associated metadata.
- Enriched metadata documents stored as JSON or XML schema artifacts conforming to CMS specifications.
- Search index updates—Elasticsearch or built-in CMS indexes—reflecting new tags for instant discoverability.
- Thumbnail and preview assets—static images, short video clips, waveform images—enhancing browsing experiences.
- Audit and transformation logs capturing API calls, data mappings, ETag versions, and latency metrics.
- Error reports and retry queues for records with schema mismatches, network timeouts, or validation failures.
- Versioned metadata snapshots for governance, rollback, and change comparison.
System Dependencies
- Authentication and authorization infrastructure—OAuth, API keys, or certificate-based access with role-based controls.
- Connector configurations for platforms like Sitecore, Contentful, and Adobe Experience Manager.
- Secure network layer, firewall rules, and proxy settings connecting AI orchestration platforms to CMS endpoints.
- Schema registries and ontology services maintaining current taxonomy definitions and controlled vocabularies.
- Transformation middleware—Mulesoft or Dell Boomi—to route payloads, handle conditional logic, and abstract API complexities.
- Monitoring and logging platforms—ELK stack or Splunk—with alerts for critical failures or SLA breaches.
- Governance frameworks enforcing data retention, PII masking, and regulatory compliance (GDPR, CCPA).
Handoff Mechanisms
- Event-driven notifications—webhooks or message queues (Apache Kafka, AWS SQS)—trigger downstream validation and human review workflows.
- Automated validation engines subscribe to synchronization events to perform schema conformance checks and completeness assessments.
- Review queues in platforms like Contentful or custom dashboards deliver flagged records to editors and subject matter experts.
- Search and discovery indexes refresh incrementally to ensure newly tagged assets are immediately searchable via faceted search and recommendation engines.
- Analytics and reporting pipelines stream performance metrics—throughput, error rates, record latency—into BI tools such as Tableau or Power BI for operational dashboards and SLA monitoring.
- Production deployment hooks—Jenkins or GitLab CI/CD—publish updated content bundles to staging or live environments.
- Archival scheduling forwards metadata snapshots to long-term storage or data lakes for audit trails and historical analysis of metadata evolution.
Chapter 9: Validation, Quality Control, and Human-in-the-Loop

Stage Purpose and Inputs
The validation, quality control, and human-in-the-loop stage serves as the critical checkpoint in an AI-driven metadata enrichment workflow. It intercepts errors, verifies the integrity of generated metadata, and incorporates human expertise when automation alone cannot capture nuanced context. This process preserves accuracy, maintains compliance with editorial, legal, and brand guidelines, and supports discoverability, personalization, and monetization goals across large-scale media libraries.
- Verify metadata accuracy against editorial and semantic standards.
- Detect anomalies and inconsistencies in automated tags, including low-confidence and novel entries.
- Incorporate human judgment for ambiguous or domain-specific classifications.
- Ensure auditability and traceability for regulatory and contractual compliance.
- Provide feedback loops to inform AI model retraining and taxonomy updates.
Key inputs include sampled metadata sets selected via stratified, random, or risk-based sampling; documented review guidelines detailing classification rules and quality benchmarks; exception criteria that trigger human review; governance policies governing audit trails and escalation paths; and system logs capturing automated alerts and anomaly reports. Human review assignments are managed through task queues tailored to reviewer expertise, language skills, and domain knowledge. User engagement signals—such as search logs and post-release feedback—also feed into sampling and prioritization strategies.
Effective operation of this stage depends on several prerequisites: a robust taxonomy and metadata schema; an orchestration layer that supports task assignment, review interfaces, batch operations, and status tracking; configured sampling strategies and exception detection mechanisms; accessible governance policies and review guidelines; feedback integration processes that update metadata repositories and model training pipelines; and security controls for data privacy and access management. When these conditions are satisfied, the workflow delivers enterprise-grade metadata quality, adaptability, and stakeholder trust.
Workflow Actions and Flow
The validation stage orchestrates a sequence of actions that blend automated AI components with human judgment, creating a closed-loop process for continuous improvement. This workflow ensures that metadata meets governance standards before it flows to downstream systems.
Automated Sampling and Prioritization
An AI-driven sampling service selects representative or high-risk metadata records for review based on confidence scores, anomaly detection, business impact, or emergent taxonomy terms. Low-confidence tags—typically below a dynamic threshold—novel entities, or high-visibility assets are prioritized. The sampling engine publishes batch review requests via message queues such as Apache Kafka, ensuring reliable delivery to downstream orchestration components.
Review Queue Creation and Assignment
A workflow engine—leveraging platforms like Apache Airflow or AWS Step Functions—reads sampling outputs and interacts with review management systems to generate structured task queues. Each task includes asset previews, metadata proposals, and relevant exception criteria as defined in governance policies. Tasks are grouped by domain expertise—such as visual tagging, linguistic review, or compliance—and distributed to reviewers through platforms like Labelbox or Amazon SageMaker Ground Truth, balancing skill, availability, and performance metrics.
Human Review and Annotation
Reviewers access tasks via a web interface that presents metadata proposals alongside asset previews. They accept, modify, or reject tags based on documented guidelines. The interface supports bulk operations, anomaly highlighting through rule-based or statistical detectors, and the addition of comments for complex decisions. Version control mechanisms track every change, and time-tracking logs feed reviewer performance dashboards.
Feedback Ingestion and AI Model Update
Upon task completion, feedback events flow through an event bus such as AWS EventBridge or Azure Event Grid. A feedback ingestion agent aggregates corrections, aligns free-form reviewer inputs with controlled vocabularies, and updates the metadata repository with final validation statuses. Reviewer-curated labels trigger incremental learning pipelines—utilizing services like Amazon SageMaker or Google Cloud AI Platform—fine-tuning computer vision and NLP models when sufficient feedback accumulates.
Exception Handling and Escalation
Complex or ambiguous cases—such as brand compliance or sensitive content—are flagged for escalation to subject-matter experts. The orchestration engine routes these tasks, including reviewer comments and AI confidence metrics, to expert queues. Experts collaborate through integrated channels and record final decisions, enabling the workflow to resume automated feedback ingestion.
Approval and Release to Production
Validated metadata records are packaged with asset identifiers, reviewer sign-offs, and policy references. An approval agent updates central repositories and notifies downstream systems—such as content management, recommendation engines, and syndication services—via notification services like Amazon SNS. Release events are logged for auditability, and metrics feed executive dashboards tracking cycle times and SLA compliance.
Reporting, Analytics, and Continuous Improvement
Reporting agents compile metrics on review pass rates by content type, average review times, exception volumes, and model improvement trends. These insights feed business intelligence tools and dashboards for operations managers, AI engineers, and governance teams. Key integration patterns—API orchestration, event-driven triggers, message queues, and data synchronization—ensure seamless coordination among systems. Governance checks enforce taxonomy adherence and regulatory requirements throughout the workflow.
AI Capabilities and System Roles
Advanced AI components and supporting systems work together to optimize the validation stage, balancing automated precision with human oversight.
- Sampling Algorithms use active learning and risk models to select low-confidence, anomalous, or high-impact assets. Tools like Amazon SageMaker Ground Truth support dynamic samplers.
- Anomaly Detection engines combine rule-based validation—enforcing controlled vocabularies and inter-tag consistency—with statistical outlier detection using isolation forests or autoencoders. Solutions such as Azure Content Moderator integrate as microservices to flag violations.
- Feedback Ingestion Agents capture every metadata correction, harmonize labels with taxonomy schemas, and trigger retraining pipelines via platforms like Labelbox and Appen.
- Human-in-the-Loop Orchestration Engines coordinate task assignment, workload balancing, and audit logging. Amazon SageMaker Ground Truth and custom workflows on Apache Airflow provide APIs for HITL integration.
- Quality Scoring Modules aggregate AI confidence scores and reviewer agreement metrics to produce unified quality dashboards. These modules enable real-time monitoring of tag accuracy and model performance.
- Exception Routing Systems use rule-driven paths, notification engines, and escalation tracking—managed by platforms such as IBM Cloud Pak for Business Automation—to ensure timely resolution of high-risk metadata issues.
- Continuous Learning Modules orchestrate data collection, training orchestration, and validation testing. Managed services on Amazon SageMaker and Google Cloud AI Platform enable seamless model lifecycle management to prevent drift.
- Governance Engines enforce policy rules, access controls, and immutable audit logs. Integrated with identity providers and policy stores, these systems maintain compliance and transparent audit trails.
Outputs, Dependencies, and Handoff
The validation stage produces deliverables that underpin downstream monitoring and continuous improvement:
- Validated Metadata Records stamped with validation status, reviewer IDs, timestamps, and annotations.
- Exception and Error Logs detailing failed validations, error codes, and original asset references.
- Quality Scoring Reports breaking down precision, recall, and consistency across models and taxonomy categories.
- Human Feedback Annotations captured for model retraining and taxonomy refinement.
- Audit Trail Documentation recording automated checks, human interventions, and policy enforcement.
- Review Queue Metrics indicating workload, review times, throughput, and backlog trends.
- Integration Status Indicators flagging readiness for handoff or additional governance approval.
Key dependencies include corporate governance frameworks, review platforms, sampling and anomaly detection services, taxonomy and schema management, centralized logging infrastructures, notification and collaboration channels, data storage with version control, and human resource management systems for reviewer capacity planning.
Validated metadata is handed off to monitoring and feedback systems through event-driven notifications, API-based transfers, and data lake integration. Governance checkpoints verify compliance before release tokens enable publication to content management systems. Continuous improvement triggers initiate retraining pipelines when quality thresholds are breached. Operational dashboards receive real-time KPIs—such as review turnaround, pass rates, and taxonomy drift alerts—ensuring agility and scalability.
End-to-end traceability is maintained through lineage metadata capturing model version identifiers, transformation steps, reviewer identities, timestamps, and audit log references. This documentation supports root-cause analysis, regulatory audits, and alignment with subsequent monitoring and continuous optimization activities.
Chapter 10: Monitoring, Feedback, and Continuous Improvement
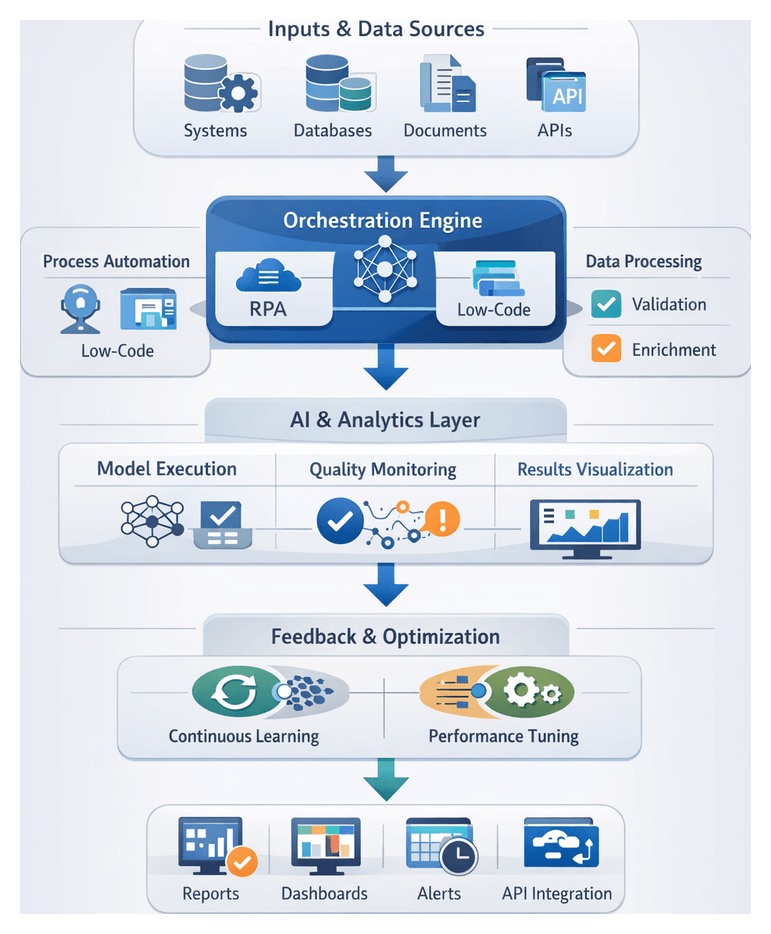
Stage Purpose and Inputs
The monitoring, feedback, and continuous improvement stage closes the loop on an AI-driven media tagging workflow by providing ongoing visibility into system health, metadata quality, and user satisfaction. As media libraries expand and discoverability expectations rise, this stage uses structured monitoring of performance logs, error conditions, and real-world signals to identify issues, trigger model retraining, and refine taxonomies. By embedding continuous feedback, organizations prevent model drift, maintain high tagging accuracy, and adapt rapidly to evolving business goals.
Core Inputs
- Performance logs capturing processing times, throughput rates, and execution latencies
- Error reports detailing failed tagging events and system anomalies
- User feedback metrics from engagement analytics, search success rates, and manual corrections
- Telemetry data from infrastructure monitors, network trackers, and storage health sensors
- Model performance metrics including precision, recall, F1 scores, and drift indicators
- Business KPIs such as content discovery rates, user satisfaction scores, and monetization impact
- Resource utilization statistics covering CPU/GPU usage and memory consumption
- Threshold and benchmark definitions establishing acceptable performance levels
- Governance and compliance guidelines for data retention, privacy, and auditing
Prerequisites and Conditions
A mature data-driven culture and an integrated technology stack are essential. Stakeholders must agree on key performance indicators and logging standards, deploy metrics aggregation services, and implement robust instrumentation with frameworks such as OpenTelemetry or Prometheus. Centralized log aggregation via platforms like Splunk or Azure Monitor enables real-time dashboards and alerting. Data lakes powered by AWS Lake Formation or BigQuery support cross-correlation of metadata, model training datasets, and usage logs. Clear governance policies safeguard integrity and compliance, while defined roles among engineering, data science, and operations ensure rapid issue resolution and iterative enhancement.
Workflow Actions and Flow
This stage orchestrates automated and human-assisted processes that collect operational data, compute metrics, trigger alerts, and feed insights back into the training pipeline. Integration of logging frameworks, analytics engines, and feedback interfaces ensures anomalies are detected quickly, user signals are synthesized effectively, and retraining cycles are managed systematically.
Data Collection and Ingestion
- Log aggregation: Stream application logs, inference traces, and API request data into a centralized service such as Amazon CloudWatch or the ELK stack.
- Metric extraction: Use a metrics engine like Prometheus to parse logs and compute time-series metrics—latency, throughput, error rates, and confidence scores.
- User feedback capture: Collect explicit ratings and implicit signals (dwell time, click-through rates) via CMS or front-end APIs.
- Error handling: Route exceptions and human-reported issues into a ticketing system such as Jira.
Real-Time Metrics and Visualization
- Streaming analytics: Process metric streams with frameworks like Apache Kafka Streams or AWS Kinesis Data Analytics to compute rolling aggregates and anomaly scores.
- Anomaly detection: Apply statistical methods or machine learning models to flag deviations, feeding events into the alert subsystem.
- Dashboard rendering: Visualize KPIs in tools such as Grafana or Datadog, with role-based access controls.
Alerting, Notification, and Escalation
- Rule evaluation: Continuously assess alert rules for drift, latency breaches, or quality slumps.
- Multi-channel notification: Dispatch alerts via email, SMS, Slack, Microsoft Teams, and tools like PagerDuty.
- Automated escalation: Invoke on-call rotations and higher-level notifications if alerts go unacknowledged.
- Suppression and deduplication: Group related alerts to prevent fatigue.
Human-in-the-Loop Feedback
- Review queues: Present low-confidence predictions and user-flagged content to human reviewers.
- Annotation updates: Version corrections and enriched labels in an annotation database.
- Quality refinement: Adjust confidence thresholds and taxonomy weights based on aggregated feedback.
- Governance workflows: Route taxonomy or threshold changes through approval gates.
Automated Retraining and Model Update Triggers
- Drift detection: Monitor feature distribution divergence to trigger retraining events.
- Threshold breaches: Schedule retraining when performance metrics fall below benchmarks.
- Periodic cycles: Conduct scheduled retraining (monthly or quarterly) to address gradual changes.
- Orchestration: Use platforms like Apache Airflow or Kubeflow Pipelines to manage retraining DAGs.
Versioning, Deployment, and Rollback
- Model registry: Catalog artifacts in systems such as MLflow Model Registry or Amazon SageMaker.
- Canary and A/B testing: Stage new models to subsets of traffic and compare performance.
- Blue–green deployments: Switch between environments to validate model updates.
- Automated rollback: Revert to stable models if regressions occur.
Feedback Loop to Model Training
- Metadata tagging: Associate enriched asset metadata with model versions for comparative analysis.
- Baseline reset: Reinitialize metrics after new deployments.
- Governance updates: Document changes and outcomes in the governance portal.
- Cycle scheduling: Automate the next round of monitoring audits and retraining triggers.
AI Capabilities and System Roles
Advanced AI functions and supporting systems form an adaptive ecosystem that prevents model drift, optimizes tagging accuracy, and ensures metadata integrity. Key capabilities include anomaly detection, performance analytics, feedback processing, retraining orchestration, governance enforcement, and taxonomy evolution.
Anomaly Detection and Drift Analysis
- Unsupervised models: Autoencoders and isolation forests detect out-of-distribution samples.
- Statistical control: Page-Hinkley tests and Gaussian monitoring track metric thresholds.
- Time series analysis: Tools like Prophet identify trends and seasonal shifts.
Performance Analytics and Visualization
- Metric aggregation: Compute precision, recall, F1, latency, and throughput.
- Dimensional analysis: Break down performance by genre, format, or language.
- Trend detection: Use moving averages and change-point algorithms to spot gradual degradation.
Human Feedback Ingestion and Processing
- Natural language understanding: Parse reviewer comments with transformer-based models.
- Clustering and topic modeling: Apply LDA to group systemic feedback issues.
- Active learning prioritization: Select samples for review based on confidence scores.
Automated Retraining Scheduling and Orchestration
- Dataset versioning: Tag snapshots of training data, including corrected labels.
- Hyperparameter optimization: Integrate Bayesian search methods.
- Pipeline orchestration: Define and execute DAGs with conditional triggers.
Governance, Compliance, and Audit Trails
- Lineage tracking: Record origins of training samples and annotation revisions.
- Policy enforcement: Verify adherence to GDPR, CCPA, and internal rules before deployment.
- Change notifications: Alert stakeholders to significant drift or taxonomy updates.
Adaptive Taxonomy Evolution
- Term suggestion: Identify emerging keywords via NLP pipelines.
- Hierarchy optimization: Use graph algorithms on co-occurrence patterns.
- Impact simulation: Predict the effect of schema changes on performance.
Outputs, Dependencies, and Handoffs
This stage transforms raw data into artifacts and signals that feed downstream systems, including training pipelines, orchestration engines, BI tools, and reporting dashboards.
Primary Outputs
- Performance dashboards and time-series KPI reports via Amazon CloudWatch, Datadog, or Azure Monitor.
- Error and anomaly logs stored in Splunk or Google Cloud Logging.
- User feedback datasets in feedback lakes or data warehouses.
- Retraining triggers and schedules managed by systems like TFX or MLflow.
- Updated model artifacts with metadata, hyperparameters, and evaluation reports.
- Real-time alert notifications via PagerDuty, Slack, or Teams.
- Audit and compliance records supporting governance reviews.
Key Dependencies
- Data lakes on Amazon S3, Google Cloud Storage, or Azure Data Lake Gen2.
- Telemetry platforms like CloudWatch, Datadog, Splunk, or Grafana.
- Model registries in MLflow or SageMaker.
- Feature stores such as Feast or Tecton.
- MLOps orchestrators like Kubeflow Pipelines, Airflow, or AWS Step Functions.
- Knowledge base and taxonomy services for semantic context.
- Notification systems including PagerDuty, ServiceNow, Slack, and Teams.
- Governance frameworks enforcing RBAC and data privacy compliance.
Handoff Mechanisms
- Retraining invocation: Events published to EventBridge, Pub/Sub, or Kafka trigger orchestrators.
- Model promotion: Artifacts registered and promoted in model registries with metadata tags.
- Dashboard updates: BI tools like Tableau or Looker refresh reports and notify stakeholders.
- Taxonomy change requests: Structured proposals forwarded to governance teams.
- Configuration updates: Pull requests to GitOps-driven repositories for orchestration adjustments.
- Incident tracking: Automated ticket creation in incident management systems with diagnostic context.
- Compliance submissions: Audit logs and change records stored for regulatory review.
- BI integration: Metrics ingested into Snowflake or Redshift for cross-functional analysis.
By integrating real-time observability, structured feedback, and automated retraining triggers, organizations create a resilient, adaptive workflow that continuously enhances metadata accuracy and operational efficiency—ensuring sustained competitive advantage in a metadata-driven media landscape.
Conclusion

End-to-End AI-Powered Metadata Workflow
The AI-driven metadata enrichment pipeline transforms raw media assets into richly annotated, discoverable content through ten integrated stages. Each phase feeds the next via clear input/output contracts, orchestration triggers, and governance checkpoints. This unified approach ensures consistent metadata, rapid processing, and scalable operations for modern entertainment enterprises.
- Content Acquisition and Ingestion: Secure transfer of raw footage, archives, and user-generated media into cloud or on-prem storage, producing a validated catalog ready for processing.
- Preprocessing and Quality Assurance: Noise reduction, transcoding, normalization, and quality scoring standardize assets and generate error logs that inform downstream analysis.
- Taxonomy and Metadata Schema Definition: Domain experts establish controlled vocabularies, ontologies, and validation rules that serve as the single source of truth for tagging.
- AI Model Selection and Training: NLP, computer vision, and multimodal models are fine-tuned on annotated corpora, versioned, and benchmarked for accuracy and performance.
- AI Agent Orchestration and Workflow Design: Event-driven frameworks coordinate parallel processing streams, manage task queues, and implement error-handling paths using tools such as AWS Step Functions.
- Automated Content Tagging and Classification: Agents analyze frames, transcripts, and taxonomy references to assign labels—scene elements, objects, sentiment, and contextual attributes—via services like Amazon Rekognition and the Google Cloud Vision API.
- Metadata Enrichment and Semantic Analysis: Knowledge graph integration and relationship extraction deepen initial tags, driven by platforms such as Neo4j and NLP engines like OpenAI GPT or IBM Watson Natural Language Understanding.
- Integration with Content Management Systems: Enriched metadata is synchronized to DAM and CMS platforms via connector code and API orchestrations, enabling immediate discoverability and syndication readiness.
- Validation, Quality Control, and Human-in-the-Loop: Anomaly detectors and review queues guide human experts to inspect exceptions. Corrections feed back into confidence thresholds and tagging rules.
- Monitoring, Feedback, and Continuous Improvement: Real-time metrics, user feedback, and error reports drive dashboards and retraining schedules, closing the loop on model and process refinement.
This modular, microservice-based architecture leverages event streams (for example, via Apache Kafka), container orchestration, and governance policies to automate repetitive tasks, maintain traceability, and enable dynamic scaling. Standardized schemas ensure uniform labeling, while hybrid automation—with human-in-the-loop oversight—addresses edge cases without slowing high-volume pipelines. Detailed audit logs and performance metrics support compliance and continuous optimization, laying the foundation for enduring operational excellence.
Operational Benefits
Increased Throughput and Velocity
Event-driven triggers immediately launch preprocessing and AI inference pipelines, eliminating manual handoffs. Parallelized AI agents—computer vision, NLP, and multimodal classifiers—run concurrently, compressing end-to-end latency. Orchestration engines coordinate retries and downstream tasks, sustaining high-velocity processing even under peak workloads.
Consistent Quality and Governance
A central metadata registry enforces mandatory fields and controlled vocabularies. Automated validation via API calls routes out-of-vocabulary tags to human reviewers. Provenance metadata—including timestamps, model versions, and reviewer IDs—feeds audit trails and dashboards, ensuring accountability and continuous rule refinement.
Elastic Scalability and Resource Optimization
Compute clusters autoscale based on ingestion rates and inference demand. A model registry dynamically assigns GPU or CPU instances according to priority and cost constraints. Cost analytics engines surface underutilized resources and recommend rightsizing strategies, balancing performance with budget efficiency.
Accelerated Time-to-Value
A CI/CD pipeline automates model deployment, rolling out updates without downtime. Real-time dashboards track tagging rates, confidence scores, and review backlogs, alerting teams to anomalies. Modular workflow design allows rapid integration of new media formats—VR, 360-degree video, and live streams—without core rearchitecture.
Collaborative Ecosystem Integration
A unified metadata service exposes RESTful APIs for production, marketing, legal, and distribution systems. Role-based access controls and automated notifications ensure that stakeholders receive relevant updates—such as regional content ratings—on schedule. Connectors translate internal schemas into partner formats, closing the orchestration loop for syndication and distribution.
Combined, these efficiencies drive stronger audience engagement, faster content monetization, and reduced operational overhead across the media lifecycle.
Strategic Impact and Business Value
Enhancing Content Discoverability
Rich metadata reduces search friction and uncovers long-tail content. Semantic entity extraction via OpenAI GPT and IBM Watson Natural Language Understanding processes transcripts for character names, plot arcs, and sentiment. Frame-level annotations from the Google Cloud Vision API and Amazon Rekognition enable visual filters, while knowledge graphs in Neo4j support faceted navigation and contextual recommendations.
Unlocking Monetization Opportunities
Detailed tags power dynamic ad insertion, content licensing automation, and personalized promotions. Scene classification for brand safety and sentiment alignment optimizes CPMs. Automated rights metadata accelerates syndication packaging, while scene detection and chapter marking speed highlight reel and trailer production.
Elevating Audience Engagement
Hyper-personalized recommendations leverage multilayered metadata—genre, mood, character arcs, and user signals—to build custom watchlists. AI-generated captions and translations broaden accessibility. Semantic metadata triggers context-aware AR filters and second-screen experiences, while clipping agents surface shareable moments for social advocacy.
Synergy with Enterprise Systems
Centralized metadata repositories, DAM/CMS platforms, orchestration frameworks, and BI systems operate in concert. Connectors integrate with Adobe Experience Manager, WordPress, and other platforms, ensuring metadata evolves with user behavior and market trends. Continuous analytics drive taxonomy refinement and model retraining.
Future-Ready Innovation
The modular architecture adapts to emerging formats—VR, live streaming, and user-generated content. Rapid deployment of new AI capabilities, from deepfake detection to sentiment forecasting, ensures sustained differentiation. This strategic alignment of technology and business objectives unlocks growth pathways and competitive leadership.
Deliverables, Dependencies, and Handoffs
The conclusion of the AI-powered workflow yields a comprehensive suite of artifacts, supported by clear dependencies and handoff procedures to downstream teams.
Core Deliverables and Artifacts
- Executive summary report with metrics on accuracy, throughput, cost savings, and ROI.
- Technical architecture blueprint detailing component interactions, API schemas, and data flows.
- Versioned model binaries, validation results, and hyperparameter configurations.
- Workflow definitions for orchestration engines, encoding retries, parallelization, and triggers.
- Controlled vocabularies, ontology files, and schema documentation.
- Connector and adapter source code for CMS/DAM synchronization.
- Automated validation test suites and human-in-the-loop review simulations.
- Monitoring dashboards, KPIs, and alert configurations.
- Governance and compliance policies, audit trails, and lineage records.
- Training and onboarding materials, including labs and user guides.
Key Dependencies
- Access to raw media libraries, transcripts, and external knowledge bases.
- Compute infrastructure with GPU and batch processing capabilities, autoscaling policies.
- Stable API services and SLAs for AI agents, CMS, and metadata registries.
- Security frameworks for identity, encryption, and audit logging.
- Governance committees and taxonomy stewards for schema updates.
- CI/CD pipelines, container registries, and infrastructure-as-code repositories.
- Monitoring and logging platforms for metrics collection and alert routing.
- Skilled teams of data engineers, AI specialists, taxonomy experts, and DevOps personnel.
Handoffs to Downstream Teams
- Technical Operations: Infrastructure-as-code templates, container images, orchestration definitions, monitoring dashboards, and runbooks for incident management.
- Data Science and Model Maintenance: Versioned model artifacts, training datasets, performance logs, feedback loop configurations, and experiment documentation.
- Business and Content Strategy: Executive reports, ROI analyses, and dashboards highlighting discoverability, engagement, and monetization metrics.
- Governance and Compliance: Audit logs, lineage records, policy documents, schema change controls, and risk assessments.
- Content Management and Editorial: API credentials, connector configurations, sample asset bundles, and onboarding workshops.
- Continuous Improvement and Innovation: Insights on bottlenecks, sandbox environments, experimentation frameworks, and A/B testing templates.
By delivering these artifacts with their associated dependencies and structured handoffs, organizations transition from proof-of-concept to high-velocity production, maintaining governance standards, driving continuous innovation, and realizing the full strategic value of AI-powered metadata enrichment.
Appendix
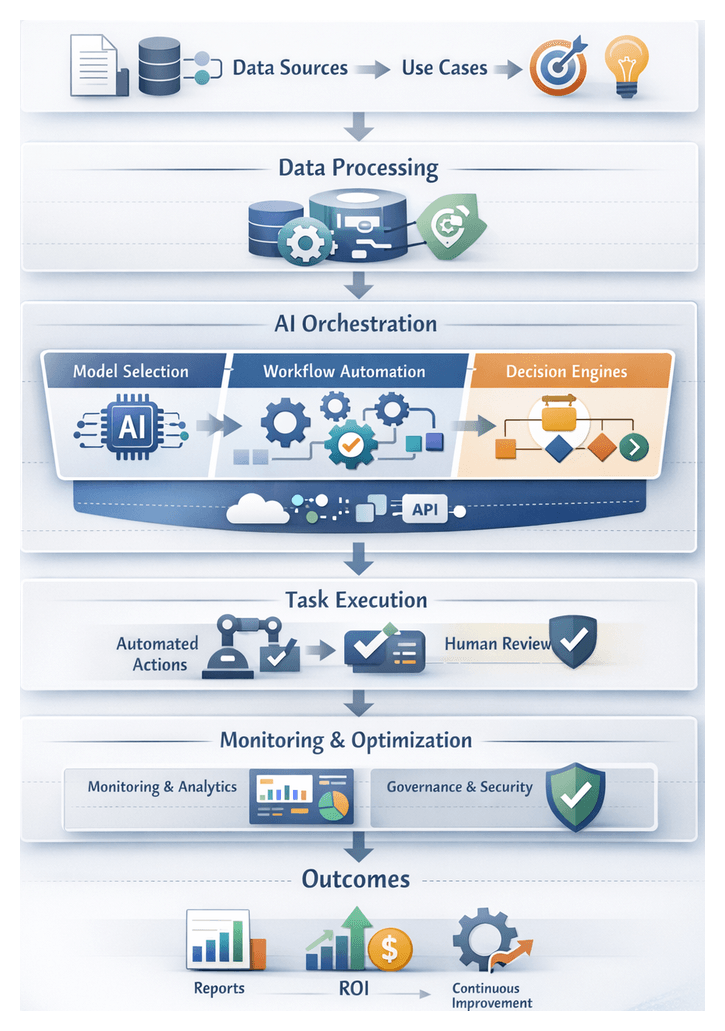
Orchestrator and AI Agents
The orchestrator serves as the central coordinator for AI-driven content tagging and metadata enrichment workflows. It interprets high-level process definitions, schedules operations, enforces dependencies, and applies governance policies. By maintaining a global view of asset lifecycles, the orchestrator manages retries, monitors service-level objectives, and publishes events along the pipeline. Typical functions include receiving asset arrival events, scheduling ingestion, preprocessing, tagging, enrichment, and integration tasks, implementing error-handling with dead-letter queues, and scaling execution based on queue depth.
AI agents are specialized processing units that subscribe to orchestrator-issued tasks, execute model or service calls, and return structured outputs. Vision agents handle object detection, scene segmentation, and facial recognition. NLP agents perform speech-to-text transcription, named entity recognition, and sentiment analysis. Audio agents analyze acoustic features, speaker diarization, and music identification. Validation agents enforce schema compliance and confidence thresholds. Orchestration agents coordinate parallel streams and manage inter-agent communication.
Together, the orchestrator and agents create a modular, scalable system where each component focuses on discrete AI functions while the orchestrator ensures reliable handoffs and governance across stages.
Metadata Schemas, Taxonomies, and Handoff Protocols
Consistent metadata classification relies on a well-defined schema and controlled taxonomy. Schema templates specify required and optional fields, data types, value constraints, and cardinality rules. Controlled vocabularies enumerate approved terms and synonyms, while hierarchical ontologies establish parent-child relationships and attribute inheritance. Governance policies manage versioning, backward compatibility, and mappings to industry standards such as schema.org, IPTC, and EBUCore for cross-platform interoperability.
Handoff protocols define data contracts, events, and interfaces for transferring assets and metadata between stages. Standardized event payloads (e.g., AssetIngested, PreprocessingComplete, TaggingComplete) travel over message queues or APIs (RESTful, gRPC). Metadata manifests attach URIs, checksums, and schema version identifiers. Governance validators enforce payload conformity before triggering downstream tasks, decoupling stages and enabling independent scaling and fault isolation.
AI Capability Mapping by Workflow Stage
This mapping outlines core AI functions, techniques, and system roles at each stage of the end-to-end tagging and enrichment pipeline. It guides solution architects and data scientists in deploying automation, human oversight, and governance.
- Stage 1: Content Acquisition and Ingestion: Computer vision models detect formats and codecs. Google Cloud Video Intelligence API and FFmpeg wrappers automate classification. NLP engines such as AWS Transcribe and Google Speech-to-Text generate transcripts. Fingerprinting services like ACRCloud deduplicate content. Anomaly detection monitors transfer integrity.
- Stage 2: Preprocessing and Quality Assurance: Shot and scene segmentation via CNN-based models or Google Cloud Video Intelligence API. Audio denoising with TensorFlow or PyTorch networks. Visual super-resolution with GANs. OCR for on-screen text. Quality scoring using autoencoders.
- Stage 3: Taxonomy and Metadata Schema Definition: Unsupervised clustering and topic modeling (LDA) discover ontological patterns. Word embeddings (word2vec, BERT) suggest terms. Rule engines validate semantic consistency. AI diff tools automate schema versioning. Knowledge graph editors like Protégé support collaborative ontology editing.
- Stage 4: Model Selection and Training: Neural architecture search (NAS) and meta-learning recommend models. Transfer learning with TensorFlow Hub or Hugging Face. Hyperparameter tuning via Optuna or Ray Tune. Data augmentation pipelines generate synthetic variations. Bias detection and interpretability tools ensure fairness.
- Stage 5: AI Orchestration and Workflow Design: Event-driven orchestration using Apache Kafka, RabbitMQ, or Apache Airflow. Reinforcement-learning schedulers for dynamic task delegation. Self-healing through error detection and fallback agents. Conversational interfaces built on Dialogflow enable human-in-the-loop interventions. Policy agents enforce compliance rules.
- Stage 6: Automated Tagging and Classification: Vision tagging via Amazon Rekognition or custom CNNs. NLP tagging with Google Cloud Natural Language API or Amazon Comprehend. Audio event detection enriches mood and context. Multimodal ensemble classifiers fuse outputs. Real-time tag streaming over gRPC or WebSockets.
- Stage 7: Metadata Enrichment and Semantic Analysis: Knowledge graph augmentation in Neo4j or Amazon Neptune. Concept clustering via graph embeddings. Sentiment scoring for mood-based filters. Vector similarity search with FAISS or Pinecone. Personalization signals feed recommendation engines.
- Stage 8: CMS Integration: AI-assisted schema mapping and payload transformation. Adaptive API orchestration with throttling and retries. Conflict detection and automated resolution using machine learning classifiers. Governance engines enforce privacy and embargo rules. Real-time webhooks update CMS platforms.
- Stage 9: Validation and Human-in-the-Loop: Active learning samplers in Amazon SageMaker Ground Truth prioritize low-confidence records. Anomaly detectors flag schema violations. Feedback agents parse reviewer comments for retraining. Quality dashboards track inter-annotator agreement and compliance.
- Stage 10: Monitoring and Continuous Improvement: Drift detection models monitor feature distributions. Performance analytics compute accuracy trends and resource metrics in real time via Grafana and Prometheus. Automated alerting agents manage thresholds and escalations. Retraining pipelines trigger via MLOps platforms like MLflow or Kubeflow Pipelines. NLP and graph algorithms propose taxonomy evolution.
Workflow Variations and Edge Cases
Live Streaming and Real-Time Events
- Segmented ingestion with low-latency message queues for per-segment tagging.
- Progressive model invocation: lightweight models for instant tags, deeper analysis asynchronously.
- Sliding window analysis to maintain temporal context and smooth tag transitions.
- Adaptive confidence thresholds based on segment quality metrics.
- Manual override triggers and broadcast control integration for high-profile events.
User-Generated Content
- Dynamic preprocessing pipelines that apply transcoding or noise reduction when assets fail quality thresholds.
- Speech-to-text fallback for missing transcripts, supplemented by computer vision for landmark and face recognition.
- Filename and title inference engines for provisional asset naming.
- Community taxonomy extension modules that mine social media for emerging slang and trends.
Multilingual and Cross-Cultural Metadata
- Language detection agents route text and audio to language-specific pipelines using Google Cloud Translation or AWS Translate.
- Multilingual transformer models (XLM-R) process multiple languages in a single instance.
- Localized taxonomies with synonyms and cultural equivalents.
- Script-aware OCR for non-Latin character sets.
Legacy and Nonstandard Formats
- Integrated format detection that routes proprietary codecs to transcoding tools like FFmpeg or AWS Elemental MediaConvert.
- Timecode alignment modules for burned-in tape timecodes.
- Sidecar metadata reconciliation merging EDL or XML with AI-generated tags.
- Lineage tracking of format conversions to ensure provenance.
Exception Handling and Autoscaling
- Retry with exponential backoff for transient errors.
- Fallback models for degraded modes (e.g., rule-based keyword extraction).
- Dead-letter queues and dashboard alerts for manual remediation.
- Queue-based autoscaling of worker instances and predictive pre-provisioning of GPU clusters.
Specialized Domains and Offline Processing
- Dynamic schema plugins load domain-specific taxonomy extensions at runtime.
- Transfer learning fine-tunes models on niche corpora (sports, medical imaging).
- Edge processing on remote sites with store-and-forward queues and sync conflict resolution.
Privacy, Compliance, and Sensitive Content
- PII detection and redaction before processing.
- Consent tokens and gating policies to enforce usage scopes.
- Age classification and mature content flags with manual compliance review.
Metadata Fusion and Multi-CMS Integration
- Schema merging agents reconcile structured sidecars with unstructured tags based on hierarchy rules.
- Central orchestrator routes metadata to multiple CMS targets with bi-directional synchronization.
- Staging and production isolation for connector configurations across environments.
AI Tools and Platforms
Vision and Video Analysis
- Google Cloud Video Intelligence API
- Amazon Rekognition
- Microsoft Azure Video Indexer
- IBM Watson Visual Recognition
- ACRCloud
Speech and Natural Language Processing
- Google Speech-to-Text
- AWS Transcribe
- IBM Watson Speech to Text
- Google Cloud Natural Language API
- Amazon Comprehend
- OpenAI API
Graph and Knowledge Management
Orchestration and Workflow Management
Machine Learning Platforms and MLOps
Annotation and Human-in-the-Loop
Media Processing and Transfer
Content Management Systems
Observability, Logging, and CI/CD
Data Warehouses and Lakes
Training Data Platforms and Open-Source Frameworks
Edge and Event Streaming
Standards and References
- schema.org
- IPTC Photo Metadata Standards
- EBUCore Metadata Standard
- Dublin Core Metadata Initiative
- GDPR Resource
- CCPA Overview
By mastering these components—ranging from orchestrator logic, agent specialization, metadata schemas, and AI capability mapping through to handling variations, edge cases, and leveraging industry-leading tools—organizations can build resilient, scalable, and compliant AI-powered content tagging workflows. This shared framework aligns technology with business objectives to enhance discoverability, monetization, and audience engagement across diverse media ecosystems.
The AugVation family of websites helps entrepreneurs, professionals, and teams apply AI in practical, real-world ways—through curated tools, proven workflows, and implementation-focused education. Explore the ecosystem below to find the right platform for your goals.
Ecosystem Directory
AugVation — The central hub for AI-enhanced digital products, guides, templates, and implementation toolkits.
Resource Link AI — A curated directory of AI tools, solution workflows, reviews, and practical learning resources.
Agent Link AI — AI agents and intelligent automation: orchestrated workflows, agent frameworks, and operational efficiency systems.
Business Link AI — AI for business strategy and operations: frameworks, use cases, and adoption guidance for leaders.
Content Link AI — AI-powered content creation and SEO: writing, publishing, multimedia, and scalable distribution workflows.
Design Link AI — AI for design and branding: creative tools, visual workflows, UX/UI acceleration, and design automation.
Developer Link AI — AI for builders: dev tools, APIs, frameworks, deployment strategies, and integration best practices.
Marketing Link AI — AI-driven marketing: automation, personalization, analytics, ad optimization, and performance growth.
Productivity Link AI — AI productivity systems: task efficiency, collaboration, knowledge workflows, and smarter daily execution.
Sales Link AI — AI for sales: lead generation, sales intelligence, conversation insights, CRM enhancement, and revenue optimization.
Want the fastest path? Start at AugVation to access the latest resources, then explore the rest of the ecosystem from there.