

The AI Agent Workflow Orchestration Handbook
To download this as a free PDF eBook and explore many others, please visit the AugVation webstore:
Introduction
Understanding Data Fragmentation and Operational Silos
Large enterprises often contend with isolated information repositories and labor-intensive transitions that undermine efficiency and agility. Data silos arise when relational databases and ERP systems store structured records without cross-system interfaces, while unstructured silos embed critical business content in emails, documents, or multimedia. Streaming silos capture real-time events from IoT sensors or messaging queues that may not feed into centralized stores. Shadow IT—including departmental spreadsheets, bespoke scripts, and local databases—further fragments visibility, and third-party platforms introduce contractual and format inconsistencies.
Manual handoffs compound these challenges. Users transfer data via email attachments and shared drives, risking version confusion and unauthorized access. Copy-and-paste operations between spreadsheets and systems spawn transcription errors, while printed reports, faxed documents, and verbal instructions create delays, misplacement hazards, and untraceable decisions. The resulting latency, error rates, and compliance exposures degrade decision quality, distort reporting, and consume valuable labor hours that could fuel innovation.
Addressing these issues begins with a structured assessment to inventory data sources, map process touchpoints, and evaluate quality and accessibility. Engaging stakeholders through interviews and workshops grounds the diagnosis in real-world pain points, while performance metrics on exception rates and reconciliation efforts quantify the impact. A clear view of system inventories, architecture diagrams, standard operating procedures, and governance policies establishes the foundation for prioritizing high-impact integration and automation initiatives.
- Comprehensive Visibility—A holistic map of applications, data flows, and human interactions reveals interdependencies and hidden risks.
- Risk Mitigation—Identifying compliance gaps, data quality issues, and points of failure reduces regulatory exposure.
- Prioritization—Resource allocation targets processes with the greatest inefficiencies and manual effort.
- Stakeholder Alignment—Process owners, data stewards, and IT teams unite around a shared diagnostic framework.
Key deliverables from this diagnostic stage include a structured data source catalog, a process touchpoint map, a gap analysis report highlighting integration challenges, a prioritization matrix ranking workflows by impact and feasibility, and baseline performance metrics to benchmark future improvements.
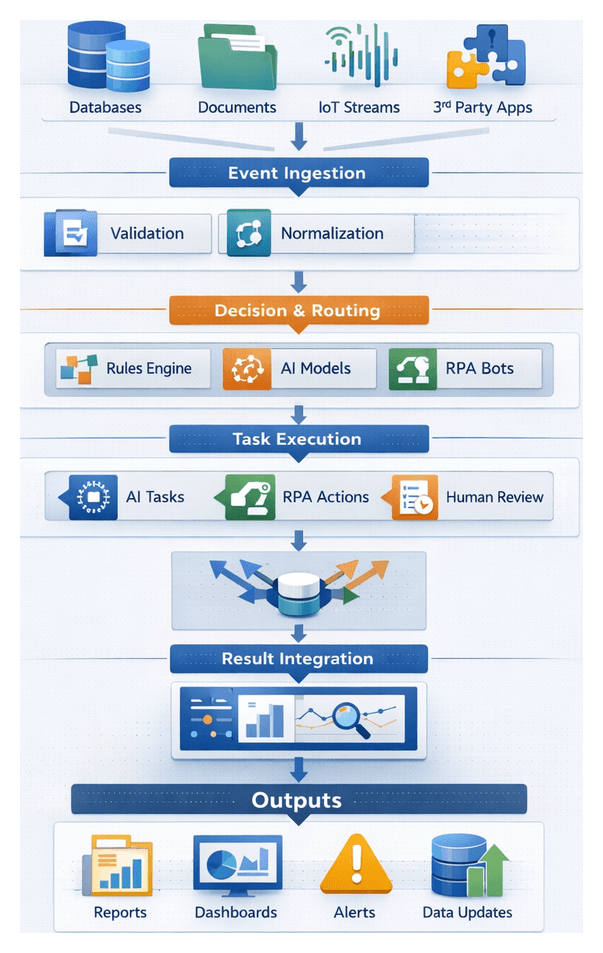
Establishing a Unified AI-Driven Orchestration Framework
To transform fragmented workflows into cohesive, end-to-end processes, enterprises must adopt an orchestration framework that aligns diverse services, AI models, bots, and human actors under consistent, transparent controls. A robust design embraces event-driven architecture, standardized interfaces, centralized visibility, dynamic routing, and extensible integrations.
Core Principles
- Event-Driven Architecture—Workflows launch in response to data arrivals, user requests, or system conditions.
- Standardized Interfaces—APIs, message queues, and publish-subscribe channels provide uniform access points.
- Centralized Visibility—A unified dashboard aggregates logs, metrics, and alerts for real-time oversight.
- Dynamic Routing—Rules engines evaluate context to direct tasks to optimal agents or fallback handlers.
- Extensible Integration—Plugin architectures enable new services to join without reworking the core engine.
Typical Workflow Sequence
- Event Ingestion: Captured via webhooks, file watchers, or message brokers.
- Pre-Processing Validation: Schema checks, authentication, and prerequisite verifications.
- Routing Decision: A rules engine evaluates metadata (for example, priority or region) to select execution paths.
- Task Dispatch: Jobs queue or invoke AI inference endpoints, RPA bots, or human task portals.
- Concurrent Coordination: Parallel tasks synchronize via barrier patterns or join nodes.
- Result Aggregation: Outputs merge, transform, and forward to subsequent stages or datastores.
- Monitoring and Alerting: Latency, success rates, and resource utilization feed dashboards and remediation scripts.
- Completion and Audit Logging: Execution paths and parameters persist for compliance and analysis.
Coordination Mechanisms
- Priority Queuing: Tags determine execution order and resource allocation.
- Load Balancing: Distributed consumers or serverless functions adapt to demand surges.
- Heartbeat Protocols: Agents report status; missed heartbeats trigger automated failover.
- Locking and Concurrency Controls: Optimistic or pessimistic locks prevent resource conflicts.
- Timeout Strategies: Configurable timeouts detect hung tasks for reroute or retry.
Integration Touchpoints and System Roles
- Orchestration Engine: Central coordinator for workflows, state, and routing. Examples include Apache Airflow and Azure Logic Apps.
- AI Inference Services: Specialized endpoints for natural language understanding, image recognition, and predictive analytics.
- RPA Agents: Bots interfacing with legacy systems via UI automation or APIs, deployed through UiPath or Automation Anywhere.
- Virtual Agents and Chatbots: Conversational interfaces for user queries, escalating to humans when needed.
- Human Task Queues: Portals for manual review, decision-making, or exception handling.
- Data Stores and Knowledge Repositories: Databases, data lakes, and semantic stores housing structured, unstructured, and enriched content.
- Monitoring and Logging Services: Telemetry collection and audit trails for governance.
Error Handling and Dynamic Rerouting
- Retry Policies: Automatic retries with back-off for transient failures.
- Fallback Routes: Alternative agents or degraded handlers when primaries fail.
- Compensation Transactions: Rollback actions in multi-step workflows to maintain consistency.
- Alert Escalation: Persistent errors prompt notifications to operations or messaging platforms.
- Dead-Letter Queues: Unprocessable messages move to holding areas for manual investigation.
By centralizing control, organizations achieve elastic resource utilization, uniform execution standards, reduced integration overhead, and accelerated time to market. Operational teams gain end-to-end visibility, governance functions enforce compliance, and business stakeholders enjoy faster, more reliable outcomes.
Integrating AI Agents into Enterprise Workflows
Embedding AI agents into orchestration layers transforms static pipelines into adaptive, intelligent workflows. These agents leverage machine learning models, natural language understanding, robotic process automation, decision-support systems, generative AI, and computer vision to automate tasks, collaborate with humans, and self-optimize.
Core AI Capabilities
- Natural Language Understanding: Agents parse text and speech to extract intents and entities using solutions like IBM Watson Assistant or Google Dialogflow, enabling automated ticket triage and self-service knowledge delivery.
- Robotic Process Automation: Bots deployed via UiPath or Automation Anywhere perform rule-driven tasks on legacy systems without modifying underlying applications.
- Predictive and Prescriptive Analytics: Machine learning models forecast trends, detect anomalies, and recommend actions for pricing, maintenance, and fraud prevention.
- Generative AI: Large language models such as OpenAI’s GPT and Azure OpenAI draft text, generate code snippets, and propose strategic scenarios.
- Computer Vision: Vision-enabled agents automate visual inspection and document digitization via AWS Rekognition, enhancing quality control and security monitoring.
Supporting Infrastructure
Robust systems provide orchestration, data management, security, and monitoring to ensure reliability, scalability, and compliance.
- Orchestration Frameworks: Visual pipelines, retry logic, and conditional branches powered by Apache Airflow, AWS Step Functions, or Google Cloud Workflows.
- Data Platforms and APIs: Data lakes on Amazon S3 or Azure Data Lake Store, real-time streaming with Apache Kafka, and API gateways exposing master data and business logic.
- Security and Compliance: Identity and access management via Okta or Azure Active Directory, encryption at rest and in transit, key management, and continuous compliance monitoring for standards such as GDPR, HIPAA, or PCI DSS.
- Monitoring and Logging: Centralized log aggregation with Elastic Stack or Splunk, dashboards tracking throughput, errors, and resource usage, and automated remediation triggers.
Collaborative Dynamics with Human Stakeholders
- Human-in-the-Loop Controls: Agents present recommendations with confidence scores for human review in high-impact decisions like loan approvals or medical diagnoses.
- Task Routing and Escalation: Ambiguous or exception-laden tasks route automatically to designated operators or supervisors.
- Interactive Interfaces: Conversational agents integrated into Microsoft Teams, Slack, or custom portals allow users to initiate workflows, query status, and intervene as needed.
- Training and Feedback Loops: Human corrections feed versioned datasets into model retraining pipelines, reducing manual interventions over time.
Governance, Error Management, and Scaling
- Policy Enforcement: Centralized engines codify data access rules, fairness constraints, and ethical guidelines for runtime validation.
- Exception Handling: Standardized error schemas, retry policies, and escalation protocols within the orchestration layer.
- Version Control and Auditing: Agent code, configurations, and models tracked via Git repositories with automated deployment and rollback capabilities.
- Elastic Scaling: Container orchestration platforms like Kubernetes instantiate additional agents based on queue depths and custom metrics.
Measuring Impact and Continuous Improvement
- Quantitative Metrics: Cycle times, error rates, cost savings, and user satisfaction compared against pre-deployment benchmarks.
- Qualitative Assessments: End-user and stakeholder feedback to surface usability gaps and compliance concerns.
- A/B Testing and Experimentation: Parallel agent configurations or model versions to identify optimal strategies before full rollout.
- Retraining and Rule Refinement: Production data integrated into training pipelines to address model drift and emerging patterns.
- Scalability Planning: Infrastructure utilization reviews and forecasts guide capacity planning for future expansion.
Structural Foundations: Outputs, Dependencies, and Handoffs
To translate conceptual designs into actionable guidance, the Structural phase of the AI Agent Workflow Handbook produces core artifacts, maps interdependencies, and codifies handoff protocols. These deliverables enable coherent progression from architectural patterns to implementation and training.
Primary Outputs
- Structural Blueprint: Visual and textual representation of chapter sequencing, section objectives, and narrative flow from data ingestion to optimization.
- Dependency Matrix: Tabular mapping of prerequisite knowledge, data sources, technology versions, and inter-chapter linkages.
- Navigation Framework: Cross-references, index entries, and lookup conventions for rapid discovery of topics in tools such as Apache Airflow, Camunda, or Kubeflow.
- Handoff Guidelines: Templates, checklists, and repository links for transferring narrative drafts, diagrams, code samples, and validation scripts to downstream teams, referencing platforms like AWS Step Functions and UiPath.
Dependency Considerations
- Content Dependencies: Narrative assumes awareness of preceding topics, such as intent extraction before task planning.
- Technical Dependencies: Sample code and API examples require specific library versions cataloged in the technology stack appendix.
- Data Dependencies: Realistic sample datasets, configuration files, and synthetic streams with defined schemas ensure reproducibility.
- Compliance Dependencies: Chapters flagged for GDPR or HIPAA review before publication.
Handoff Mechanisms
- Artifact Packaging: Standardized packages containing drafts, diagrams, code, and metadata for versioning and review status.
- Review Gates: Automated checks for style compliance, hyperlink integrity, code execution, and glossary alignment.
- Repository Transfer: Committed to a central content repository with role-based access; downstream teams pull artifacts per branch policies.
- Integration Workshops: Collaborative sessions among authors, solution architects, and development leads to align patterns before coding.
Clear roles and responsibilities—documented in a RACI matrix—assign accountability for artifact creation, editorial review, technical validation, and consumption by implementation teams. By formalizing outputs, dependencies, and handoff protocols, the handbook becomes a living blueprint, guiding enterprises from strategy to operational AI-driven workflows across diverse organizational contexts.
Chapter 1: Data Ingestion and Integration
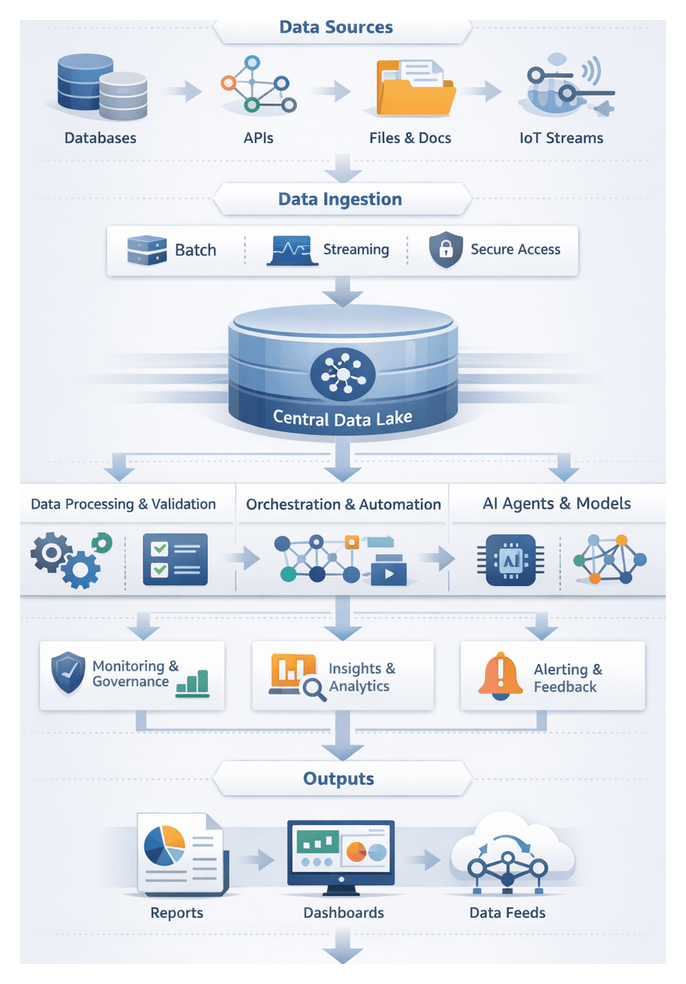
Purpose and Context
In enterprise environments, data ingestion and integration establish a reliable single source of truth for AI-driven workflows. By consolidating raw inputs from transactional systems, IoT devices, third-party APIs and unstructured repositories into a central data lake, organizations eliminate silos, reduce manual effort and accelerate time-to-insight. In regulated industries, this stage also enforces traceability, compliance and auditability.
Data Sources and Characteristics
Incoming data typically falls into four categories:
- Structured Systems: Relational databases (Oracle, SQL Server), data warehouses and ERP platforms.
- Semi-Structured Repositories: JSON, XML and CSV files in object stores or content management systems.
- Unstructured Stores: Documents, emails, images and multimedia requiring indexing and metadata extraction.
- Streaming Event Streams: High-velocity data from IoT sensors, logs and message queues via Apache Kafka or Amazon Kinesis.
Prerequisites for Ingestion
- Secure Connectivity: VPN tunnels or private links, firewall rules and VPC configurations.
- Access Controls: Role-based permissions, token authentication and credential storage via HashiCorp Vault.
- Schema Registry: Centralized definitions with Apache Avro Schema Registry or AWS Glue Data Catalog.
- Governance Policies: Data ownership, retention and compliance rules (GDPR, HIPAA, SOC 2) enforced with automated checks.
Ingestion Patterns
- Batch Ingestion: Off-peak loads using Informatica or Talend.
- Micro-Batch Processing: Frequent small batches via Fivetran or Stitch.
- Real-Time Streaming: Continuous feeds with Apache Kafka or Amazon Kinesis.
- Change Data Capture: Delta captures using Debezium or AWS Database Migration Service.
Tools and Frameworks
- Integration Services: Azure Data Factory, Google Cloud Dataflow, AWS Glue.
- Orchestration: Apache Airflow.
- Event Streaming: Apache Kafka, Amazon Kinesis.
- Data Lakes: Amazon S3, Azure Data Lake Storage, Google Cloud Storage.
- Metadata & Lineage: OpenLineage, Apache Atlas.
Validation, Security and Compliance
- Schema conformity, data type checks, null/range validations and referential integrity tests.
- Statistical profiling to detect anomalies.
- Encryption in transit (TLS/SSL) and at rest (AES-256).
- Masking and tokenization of sensitive fields.
- Audit logging and compliance mechanisms to enforce GDPR, HIPAA and other regulations.
Cohesive Orchestration Framework
Background
Enterprises often operate in silos of specialized tools, causing latency, duplicated effort and governance gaps. The shift from batch workflows to event-driven, AI-augmented pipelines demands a unified orchestration layer to coordinate AI agents, legacy systems and cloud services end to end.
Framework Definition
A cohesive orchestration framework sequences, monitors and governs interactions by abstracting service interfaces into reusable primitives. Key functions include:
- Routing tasks based on business rules, priority and resource availability.
- State management with retries, compensating actions and transactional integrity.
- Centralized monitoring and audit trails for visibility and compliance.
- Governance enforcement for security, privacy and regulatory policies.
Core Benefits
Consistency of Execution
- Standardized workflows and centralized business rules.
- Replayable processes for debugging and root-cause analysis.
Scalability of Operations
- Dynamic task routing and parallel execution.
- Auto-scaling orchestration using AWS Step Functions or Apache Airflow.
Error Reduction and Resilience
- Built-in retry policies and compensating transactions.
- Centralized exception handling and audit logs for compliance.
Interaction Patterns
- Triggering Events: User actions, inbound messages, scheduled polls or alerts.
- Task Routing: Dispatching tasks to AI agents or compute clusters via queues.
- Data Handoff: Standardized schemas and payloads managed within workflows.
- State Management: Checkpoints, parallel branches and timed waits.
- Monitoring & Feedback: Dashboards, metrics and alerting for SLA breaches.
- Completion: Final output packages for downstream consumers.
Implementation Considerations
- Governance & Ownership: Establish a center of excellence to manage workflows and rules.
- Tool Selection: Evaluate platforms like Apache Airflow, AWS Step Functions and AgentLinkAI.
- Standard Interfaces: Use OpenAPI or gRPC and schema registries for message validation.
- Security & Compliance: IAM, encryption and audit logging for workflows.
- Incremental Adoption: Pilot key services before scaling scope.
- Change Management: Train teams and integrate workflow testing into DevOps pipelines.
Future-Proofing
- Onboard emerging AI services like multimodal models or streaming analysis engines.
- Apply global business rules consistently across legacy, cloud and edge environments.
- Prototype new processes in sandboxes before production deployment.
- Scale across geographies while maintaining governance.
AI Agents in Enterprise Workflows
Definition and Role
AI agents are autonomous software entities that perform tasks, make decisions and interact with systems or users based on objectives and learning capabilities. They bridge unstructured data, legacy applications, modern APIs and human stakeholders to enable dynamic, self-optimizing workflows.
Key Capabilities
- Autonomous Decision-Making: ML models and rule engines select actions without human input.
- Adaptive Learning: Continuous feedback loops refine models and strategies.
- Conversational Interaction: NLU and generation via chatbots and voice interfaces.
- Multi-Modal Processing: Combining text, images, video and sensor data.
- Integration Frameworks: Built-in connectors for legacy, SaaS and cloud services.
- Error Detection & Recovery: Monitoring, retry logic and compensating transactions.
Integration Architecture
- Central orchestration layer for task routing and prioritization.
- Standard communication protocols: RESTful APIs, message queues or event streams.
- Role-based security, OAuth and encryption.
- Modular microservices or containerized agents.
- Data management with versioned model registries.
Technical Components
- Orchestration Platforms: Apache Airflow, Kubeflow, Azure Logic Apps, AWS Step Functions.
- Agent Frameworks: Rasa, LangChain, OpenAI API, Ray RLlib.
- Monitoring & Logging: Prometheus, ELK Stack.
Deployment Strategies
- API-First: Expose agents via REST or GraphQL endpoints.
- Event-Driven: Trigger agents with Kafka or RabbitMQ.
- Containerized Microservices: Kubernetes orchestration for scaling.
- Edge Deployment: Lightweight agents on devices with offline processing.
- Hybrid Integration: On-premises components combined with cloud services.
Organizational Roles
- Solution Architects design integration and security models.
- Data Engineers prepare datasets and ensure quality.
- ML Engineers develop and retrain models.
- DevOps/AI Ops automate deployments and monitoring.
- Business Analysts define requirements and validate outcomes.
- Security Officers enforce compliance and governance.
Business Impact
- Operational efficiency gains of up to 70 percent through automation.
- Enhanced customer experience with 24/7 virtual support.
- Data-driven insights for proactive decision-making.
- Cost optimization via dynamic resource allocation.
- Risk mitigation through built-in governance and audit trails.
Challenges and Mitigation
- Legacy Constraints: Use API wrappers, middleware or RPA overlays to bridge outdated systems.
- Data Silos & Quality: Centralize data lakes, enforce governance and validation checks.
- Model Drift: Implement continuous monitoring, automated retraining and audits.
- Security Risks: Adopt zero-trust, encryption and regular penetration testing.
- Change Management: Communicate benefits, provide training and establish governance committees.
Best Practices
- Modular agent design for rapid updates as new models emerge.
- Unified observability across infrastructure and agents.
- Explainable AI techniques to build trust and meet regulations.
- Cross-functional collaboration through shared tools and feedback loops.
- Align agent objectives with measurable business outcomes.
Outputs and Handoff Mechanisms
Core Data Artifacts
- Landing zones with raw data snapshots.
- Staging tables applying standardized schemas.
- Master records merging entities from multiple sources.
- Curated views optimized for analytics.
- Data catalogs documenting schemas, quality scores and business context.
Schema Registries and Formats
- Apache Parquet for columnar analytics.
- Avro for compact binary serialization.
- ORC for Hadoop integration.
- JSON for semi-structured exchange.
- CSV for tabular snapshots.
- Relational tables in Snowflake or Databricks.
Metadata and Lineage
- AWS Glue Data Catalog or Apache Atlas for asset indexing.
- Lineage graphs capturing dependencies and transformations.
- Quality dashboards with validation results and anomaly alerts.
- Versioned scripts in Git for traceability.
- Data contracts outlining schemas, SLAs and refresh schedules.
Upstream Dependencies
- API availability from third-party providers.
- Batch extract schedules from Oracle or SQL Server.
- Streaming pipelines via Apache Kafka or Confluent Platform.
- Connectivity to Amazon S3, Azure Blob or Google Cloud Storage.
- Identity provider configurations and network performance.
Quality Gate Dependencies
- Schema validation engines enforcing types and nullability.
- Data cleansing for deduplication and normalization.
- Anomaly detection routines surfacing outliers.
- Business rule validators for referential integrity.
- Monitoring alerts triggering remediation workflows.
Handoff Mechanisms
- Batch transfers to secure FTP or shared cloud storage.
- Event notifications via Amazon SQS, Azure Service Bus or RabbitMQ.
- Real-time streaming with Kafka topics or AWS Kinesis Data Streams.
- RESTful APIs exposing JSON or Protobuf payloads.
- Database views or materialized tables for SQL access.
Orchestration and Notification
- Apache Airflow for DAG scheduling.
- Prefect for dynamic workflows.
- Dagster with type-aware pipelines.
- Azure Data Factory for hybrid ETL orchestration.
- AWS Step Functions coordinating Lambda and data tasks.
SLAs and Data Contracts
- Data freshness windows: real-time, hourly or daily updates.
- Throughput and latency targets for batch and streaming.
- Error tolerance thresholds and remediation timeframes.
- Schema change management and deprecation policies.
- Access controls and encryption requirements for sensitive data.
Security and Compliance at Handoff
- PII masking or tokenization before export.
- TLS encryption in transit and AES-256 at rest.
- RBAC enforced via IAM policies.
- Audit logging of exports, API calls and user actions.
- Regular compliance scans aligned to GDPR, HIPAA or SOC 2.
Example: Banking Customer Data Pipeline
Customer transactions flow from core banking, credit bureaus and web portals into a unified profile dataset enriched with risk scores. Nightly extracts, Kafka streams and API calls feed a Snowflake materialized view. Orchestration by Apache Airflow ensures refresh within two hours and masks sensitive account numbers before downstream consumption.
Best Practices for Seamless Handoff
- Standardize self-describing formats and enforce schema evolution policies.
- Maintain comprehensive metadata and lineage visibility.
- Automate validation and remediation before handoff.
- Use event-driven triggers to minimize latency.
- Define clear SLAs, data contracts and compliance rules with consumers.
- Monitor handoff performance and errors with dashboards and alerts.
Chapter 2: Natural Language Understanding and Intent Extraction
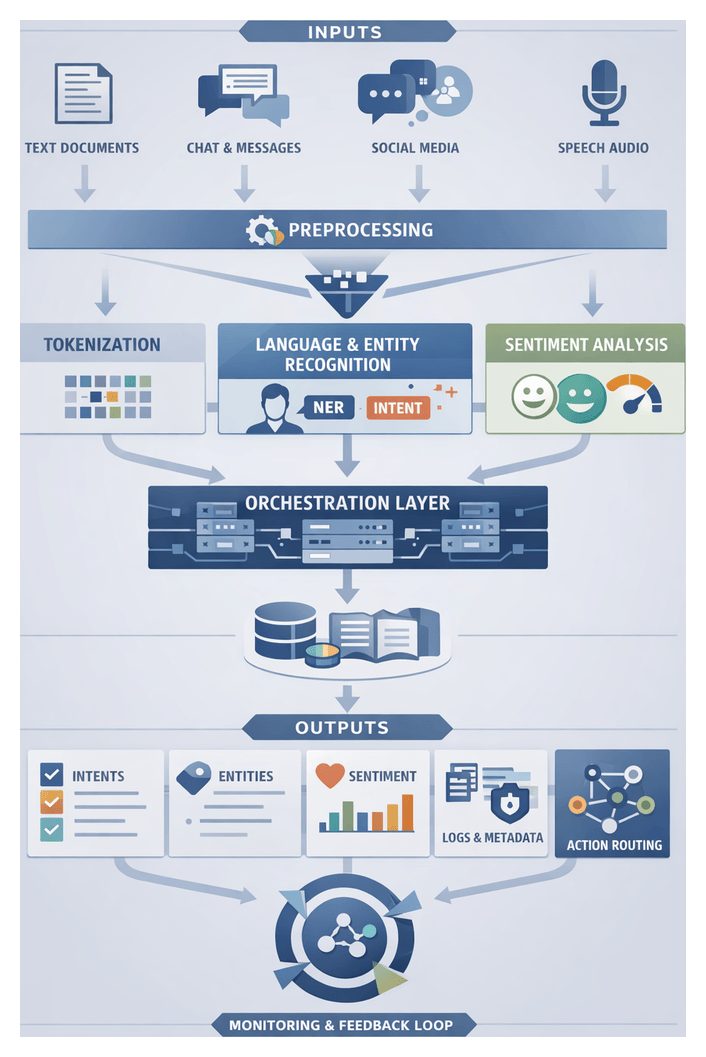
Purpose and Scope of the NLU and Extraction Stage
The natural language understanding (NLU) and intent extraction stage transforms diverse unstructured inputs—text documents, chat logs, social media posts, and speech recordings—into normalized, annotated representations. By detecting semantics, intent, entities, and sentiment, this stage provides the structured insights required for reliable downstream automation, decision support, and conversational interfaces. High fidelity here is crucial: errors propagate through orchestration frameworks, impacting response accuracy, compliance, and user satisfaction. In enterprise environments, organized workflows must process streaming and batch inputs at scale, ensuring consistent formatting, language identification, metadata enrichment, and secure handling before routing data to planning and execution modules.
Input Types, Preprocessing, and Metadata Enrichment
Data Sources and Formats
- Text Documents: Emails, PDFs, Word files, and web pages require character encoding normalization, markup removal, and metadata extraction.
- Chat and Messaging Logs: Exchanges from Slack or Microsoft Teams preserve context and timestamps for multi-turn dialogues.
- Social Media Content: Posts from Twitter, Facebook, or LinkedIn involve handling slang, abbreviations, and embedded media.
- Speech Recordings: Audio from call centers or voice assistants is fed through speech-to-text services such as Google Cloud Speech-to-Text, Amazon Transcribe, or Microsoft Azure Speech Services.
- Transcripts: Engine-generated transcripts include speaker diarization metadata, confidence scores, and timestamps.
Text Normalization and Audio Preprocessing
Standardizing inputs prevents inconsistencies in downstream analysis. Common preprocessing tasks include:
- Character Encoding: Converting all text to UTF-8.
- Punctuation and Casing: Retaining or removing punctuation; normalizing case; applying lemmatization and stop-word filters with libraries such as the Hugging Face Tokenizers or the OpenNLP toolkit.
- Tokenization and Segmentation: Breaking text into tokens and sentences.
- Domain Entity Patterns: Standardizing dates, currencies, and product codes via rule-based patterns.
- Audio Quality: Ensuring minimum sampling rates (16 kHz ), applying noise reduction, echo cancellation, and using pyannote.audio for speaker diarization.
Language and Domain Identification
Accurate detection of input language and domain context enables routing to specialized models. Tools like spaCy and fastText provide general-purpose language identification, while custom classifiers and glossaries refine processing for sectors such as healthcare, finance, or legal. Domain tags guide vocabulary adaptation, sentiment thresholds, and entity schemas.
Contextual Metadata and Conversation History
- Session Tracking: Persisting prior exchanges to resolve references.
- User Profiles: Incorporating language preferences, region, and entitlements.
- Channel Indicators: Noting origin (mobile, web, voice) to adjust formality and noise expectations.
- Temporal and Geospatial Context: Annotating timestamps and location data for compliance and location-based services.
Security, Compliance, and Governance Prerequisites
Enterprise-grade NLU workflows must enforce rigorous controls to protect sensitive data and ensure regulatory compliance.
- Data Encryption: Securing audio, transcripts, and annotations in transit and at rest to meet GDPR, HIPAA, or PCI DSS standards.
- Access Controls: Enforcing role-based permissions via LDAP, SAML, or OAuth integrations.
- Pseudonymization and Masking: Redacting PII or replacing with pseudonyms when appropriate.
- Audit Logging: Capturing model versions, processing steps, and user access for traceability.
- Governance Roles: Defining data owners, model custodians, and platform engineers responsible for data quality, model drift monitoring, and infrastructure reliability.
Entity Recognition and Intent Extraction Workflow
Capturing precise elements—customer names, product codes, dates—and interpreting user intent—such as order placement or support requests—requires coordinated sub-processes. This workflow generates structured insights that feed into planning and execution engines, reducing manual triage and improving routing accuracy.
Core Components
- Preprocessing Engine: Normalizes inputs and applies language detection.
- Tokenization Service: Segments text into tokens, handles compound words and emoticons.
- NER Module: Identifies entities using models such as spaCy or Amazon Comprehend.
- Intent Classifier: Fine-tuned transformer models via the Hugging Face Inference API.
- Sentiment Analysis: Services like Google Cloud Natural Language evaluate emotional tone.
- Orchestration Layer: Coordinates execution, handles retries, aggregates results, and logs outcomes.
- Knowledge Base: Supplies domain vocabularies, disambiguation rules, and contextual metadata.
High-Level Sequence of Actions
- Input Reception: Tagging with metadata—channel ID, user profile, session history—from message queues or APIs.
- Preprocessing: Applying normalization rules, expanding contractions, and filtering noise.
- Parallel Tokenization and POS Tagging: Issuing requests to multiple language models for code-mixed inputs, reconciling by confidence.
- NER Invocation: Extracting labeled spans with confidence metrics.
- Intent Classification: Assigning intent labels and probabilities.
- Sentiment Analysis: Evaluating overall polarity and emotion scores.
- Entity-Intent Correlation: Validating combinations against domain rules; low-confidence cases trigger fallbacks.
- Disambiguation: Resolving ambiguous entities via semantic graphs or heuristics.
- Handoff: Packaging results into a standardized schema and routing to task planners.
- Logging and Feedback: Recording metrics, errors, and confidence distributions for continuous improvement.
Orchestration, Error Handling, and Fallback Strategies
Coordination Patterns
- Circuit Breakers and Retries: Managing transient failures with exponential backoff.
- Parallel vs. Sequential Execution: Balancing latency and debugging complexity.
- Dynamic Routing Rules: Applying business logic to VIP customers or high-priority contexts.
- Human-in-the-Loop Triggers: Escalating ambiguous cases to case management systems.
- Contextual State Management: Tracking multi-turn dialogue in session caches or vector stores.
Error Handling and Fallback Mechanisms
- Secondary Model Invocation: Calling domain-specialized NER or intent classifiers on low-confidence segments.
- Pattern-Based Extraction: Using regex for critical entities like invoice numbers.
- Human Review Escalation: Generating tickets when automated methods fail thresholds.
- Graceful Degradation: Proceeding with highest-confidence data, flagging missing elements for downstream handling.
Output Specifications and Handoff to Planning Modules
Core Output Artifacts
- Intent Results: Primary label, ranked alternatives, and confidence scores.
- Entity Sets: Named entities with types, spans, and confidences.
- Sentiment and Emotion: Polarity, scores, and optional emotion breakdown.
- Slots and Dialogue State: Extracted slot-value pairs and session context.
- Normalized Text: Tokenized, cleaned input with language metadata.
- Processing Metadata: Timestamps, model and schema versions, error flags.
Data Schemas and Integration Patterns
Outputs conform to JSON schemas—request_id, timestamp, language, intent, entities, sentiment, slots, metadata—or alternative formats like Protocol Buffers. Handoff mechanisms include:
- Event-Driven Messages: Publishing to topics on Apache Kafka or RabbitMQ.
- RESTful Calls: Pushing JSON payloads to task planners with retry logic.
- Shared Stores: Writing records to data lakes or databases for Change Data Capture.
- Serverless Invocation: Triggering AWS Lambda or Azure Functions to initiate planning workflows.
Versioning, Traceability, and Auditing
- Model and Schema Tags: Embedding version identifiers in outputs.
- Correlation IDs: Tracing requests across ingestion, NLU, and execution.
- Audit Trails: Persisting raw inputs, processed outputs, and logs for forensic analysis.
- Access Logs: Recording administrative changes under role-based access control.
Infrastructure, Monitoring, and Lifecycle Management
Supporting Platforms and Orchestration Engines
- Data Platforms: Amazon Redshift, Google BigQuery.
- Message Queues: Apache Kafka, RabbitMQ.
- APIs and Gateways: REST or gRPC endpoints with authentication and rate limiting.
- Container Orchestration: Red Hat OpenShift, Amazon EKS.
- Knowledge Stores: Milvus, Pinecone.
- Observability: Prometheus, Grafana, Elastic Stack.
- Secrets Management: HashiCorp Vault.
- Policy Engines: Open Policy Agent.
- Workflow Engines: Apache Airflow, Kubeflow Pipelines, Temporal, Argo Workflows, commercial iPaaS like Mulesoft and IBM App Connect.
Continuous Monitoring and Optimization
Dashboards track throughput, latency, confidence distributions, and error rates. Alerts trigger on SLA breaches or recurring misclassifications. Logged data feeds into MLOps pipelines that automate retraining, model versioning, and rule refinement, ensuring workflows adapt to evolving language and domain requirements.
Agent Lifecycle and Continuous Improvement
- Version Control: Storing logic, artifacts, and configurations as code with changelogs.
- Automated Testing: Integrating unit, integration, and performance tests in CI/CD.
- Canary Deployments: Rolling out updates to a subset of traffic before full release.
- Retraining and Data Refresh: Scheduling model updates based on fresh, labeled data.
- Feedback Loops: Capturing user feedback and error reports for prioritizing enhancements.
- Scalability Planning: Designing stateless agents and autoscaling policies to meet variable loads.
Business Impact and Governance
By embedding rigorous controls, standardized schemas, and robust orchestration, enterprises achieve operational efficiency, error reduction, and enhanced customer experiences. Clear governance roles and audit trails support compliance with regulations such as GDPR, HIPAA, and PCI DSS. Continuous monitoring and lifecycle practices ensure that NLU and intent extraction remain aligned with business objectives, delivering measurable ROI through reduced cycle times, cost optimization, and sustained competitive differentiation.
Chapter 3: Task Decomposition and Workflow Planning
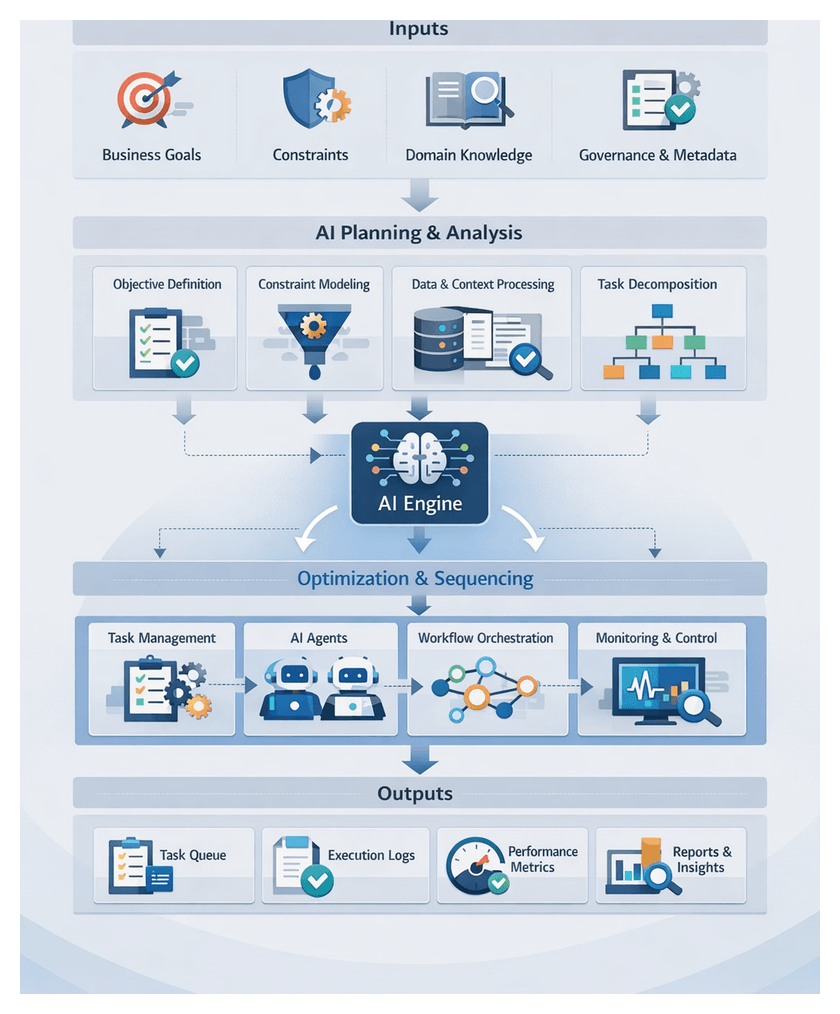
Defining Goals and Gathering Planning Metadata
SMART Objectives and Strategic Use Cases
Effective AI-driven orchestration begins with clear, SMART (Specific, Measurable, Achievable, Relevant, Time-bound) objectives that translate high-level strategies into actionable use cases. Project sponsors and business analysts collaborate to define business drivers—such as revenue growth, cost reduction, compliance mandates or customer satisfaction targets—and map each to one or more use cases. These use cases specify actors, triggers, expected outcomes and acceptance criteria, forming the foundation for task planners to align every downstream task with measurable impact.
- Business drivers justifying AI orchestration investment
- Target stakeholder and end-user groups
- Performance improvement or ROI metrics
- Regulatory or compliance requirements
- Delivery time horizons and milestones
Constraints, Context and Domain Knowledge
Real-world initiatives face constraints—budget limits, resource availability, data privacy regulations, legacy system interoperability and organizational policies—that shape feasible solutions. Capturing these constraints and associated success criteria ensures planning engines can enforce quantitative targets (throughput rates, error thresholds) and qualitative measures (customer feedback scores, audit checklists).
- Financial boundaries, funding phases and cost centers
- Technical dependencies on platforms, APIs and middleware
- Data retention, classification and privacy policies
- Service level agreements and uptime requirements
- Quality benchmarks and defect tolerance levels
Embedding domain context prevents AI agents from missing critical nuances. Essential elements include ontologies, historical performance data, process maps, glossaries and industry-specific regulations. These artifacts guide decomposition algorithms to produce tasks that respect domain-specific rules and constraints.
Governance, Version Control and Metadata Repository
Establishing governance sign-offs and maintaining versioned metadata are vital for accountability and traceability. Stakeholders—project sponsors, data stewards, compliance officers and technical leads—review and approve goals, constraints and metadata definitions through documented workflows. A centralized metadata registry captures each iteration of objectives, assumptions and system requirements, facilitating impact analysis when changes occur.
- Stakeholder roles, review cycles and documented approval workflows
- Risk assessments, mitigation plans and change control processes
- Collaboration tools with version control and metadata schemas
- Tagged artifacts with timestamps, authorship and change summaries
- Automated synchronization between planning and execution repositories
Decomposition Parameters and Success Metrics
With goals, constraints and context in place, planning engines require parameters for optimal task granularity—balancing parallelism and coordination overhead. Defining minimum and maximum task sizes, dependency depths and parallelism thresholds guides decomposition algorithms. Planning metadata should also include performance indicators and feedback loop configurations to measure planning efficacy and inform iterative refinement.
- Maximum subtasks per objective and preferred execution durations
- Resource affinity constraints and data locality preferences
- Batch sizes, concurrency limits and streaming thresholds
- Target throughput rates, acceptable latencies and error tolerances
- Dashboards, automated alerts and bi-directional reporting APIs
By assembling validated objectives, constraints, domain context, governance approvals, versioned metadata and performance specifications into a planning repository, enterprises create a blueprint for scalable, error-resilient AI workflows.
Sequencing Tasks in the Planning Workflow
Dependency Graphs and Sequence Modeling
Sequencing transforms decomposed tasks into an ordered plan, addressing dependencies and parallelization opportunities. Planners construct a directed acyclic graph (DAG), where nodes represent tasks and edges denote prerequisites. Metadata—inputs, outputs, expected durations, retry policies and resource requirements—feeds into graph construction, enabling the orchestration engine to identify valid execution orders and parallel branches.
- Prerequisite relationships derived from data flows, API chains and business rules
- Resource annotations for CPU, memory, licenses or specialized hardware
- Priority weights based on business importance and SLA commitments
- Runtime estimates propagated to compute critical path durations
Static, Dynamic and Hybrid Sequencing
Static sequencing produces a fixed order at design time, ideal for predictable processes. Dynamic sequencing adapts in real time to data arrival, system load or external events. Hybrid approaches establish checkpoints where dynamic evaluation can adjust upcoming segments without reordering completed work.
- Static sequencing offers simplicity, repeatability and auditability
- Dynamic sequencing excels amid variable data and service latencies
- Hybrid models balance stability with adaptive responsiveness
Planning Engines and Optimization Algorithms
Modern orchestration frameworks—such as Apache Airflow, Prefect and Argo Workflows—provide APIs for defining DAGs, dependencies and scheduling policies. Under the hood, planners apply topological sorting, critical path method (CPM), constraint solvers and heuristic refinements to generate optimal sequences that respect resource and policy constraints.
- Topological sorting for initial dependency-compliant order
- Critical path analysis to identify duration-influencing tasks
- Heuristics to reorder non-critical tasks for increased parallelism
- Constraint solving to enforce resource limits and SLAs
Error Handling, Parallelization and Validation
Runtime anomalies—network latency, outages or data issues—require robust replanning protocols. Failure detection monitors status codes and logs; compensating actions handle side effects; graph pruning and on-the-fly reanalysis generate revised sequences; and notification triggers inform operators of significant changes.
- Independent subgraph extraction for parallel execution
- Granularity tuning to balance overhead and concurrency
- Resource contention avoidance and data locality optimization
- Backpressure management to throttle dispatch under load
Before handoff, planners validate dependency integrity, resource availability, policy compliance and sequence viability through dry-runs or simulations. Successful sequencing produces output artifacts—ordered task lists, dependency manifests, configuration payloads and dashboard updates—that are handed off via API calls, message queues or shared data tables to execution agents.
Integrating AI Agents into Enterprise Operations
Roles and Capabilities of AI Agents
AI agents automate complex workflows by performing specialized roles:
- Data Collection and Fusion—Ingest, validate and normalize structured and unstructured inputs.
- Natural Language Interaction—Understand user intents and entities with models like OpenAI GPT-4.
- Task Decomposition and Planning—Break down objectives and allocate resources using rule engines and optimization libraries like OR-Tools.
- Orchestration and Coordination—Monitor execution, manage retries and enforce load-balancing policies.
- Decision Support and Recommendation—Generate insights with predictive models built on TensorFlow or PyTorch.
- Action Execution—Automate UIs or APIs with RPA tools such as UiPath.
Supporting Systems and Orchestration Patterns
AI agents integrate with enterprise platforms via APIs, messaging and secure authentication:
- Enterprise Service Bus—Routes events and enforces security policies.
- API Gateways—Expose agent services with throttling and analytics.
- Data Lakes and Warehouses—Store raw and processed data for continuous learning.
- Event Streaming—Use platforms like Apache Kafka for reactive workflows.
Common orchestration patterns include centralized orchestrators, decentralized peer coordination, microservice-driven meshes with engines such as Apache Airflow or Azure Logic Apps, and event-driven workflows that respond to domain events in real time.
Best Practices and Real-World Example
Key implementation considerations:
- Governance—Define policies for model validation, version control and audit logging.
- Security—Enforce role-based access, encryption and secure credential management.
- Observability—Use tools like Prometheus or Azure Monitor for end-to-end visibility and alerts.
- Performance—Profile models, tune inference and scale infrastructure dynamically.
- Change Management—Communicate updates, train stakeholders and document new capabilities.
In customer onboarding, a bot built with Azure Bot Service collects applicant data, planning agents sequence credit checks and compliance reviews, and RPA bots from UiPath provision accounts on legacy systems. Orchestration agents monitor progress and escalate exceptions, reducing onboarding time from days to hours and improving accuracy and customer satisfaction.
Task Queue Outputs and Dependency Handoffs
Core Output Artifacts
The planning stage emits artifacts that drive execution:
- Task Queue Definition—List of tasks with unique identifiers, descriptions, parameters, priority levels and estimated resources.
- Dependency Graph—DAG capturing nodes with payload references, edge conditions and synchronization points.
- Scheduling Hints—Preferred execution windows, concurrency limits and affinity labels for orchestration engines like Apache Airflow.
- Validation Reports—Input schema checks, business rule compliance confirmations and anomaly logs with remediation guidance.
Upstream Dependencies and Validation
Reliable outputs depend on clean inputs from data ingestion, natural language understanding and business rule systems. Planning engines may leverage confidence scores from Google Cloud Natural Language API, refer to a central knowledge store for context resolution and synchronize rule sets to prevent compliance violations.
Handoff Mechanisms and Best Practices
Execution agents receive tasks via:
- Orchestration APIs and Message Buses—Publish tasks to queues or topics in Apache Kafka or AWS EventBridge for asynchronous pickup.
- Webhooks—Emit HTTP callbacks for real-time delivery with authentication and retry logic.
- Shared Storage—Stage large payloads in object storage, with agents retrieving file references from task definitions.
- Logging and Acknowledgment—Record delivery attempts, receive agent acknowledgments or negative acknowledgments, and integrate with monitoring platforms to trigger alerts.
- Design idempotent tasks to simplify retries.
- Embed schema versions in payloads for backward compatibility.
- Enforce data contracts defining mandatory fields and type constraints.
- Monitor end-to-end latency to detect bottlenecks.
- Automate final validation of upstream dependencies before handoff.
- Implement circuit breakers to escalate repeated failures.
By defining comprehensive output structures, validating dependencies and employing reliable handoff mechanisms, organizations ensure that planning outputs form a dependable foundation for scalable, resilient AI agent execution.
Chapter 4: Agent Orchestration and Coordination
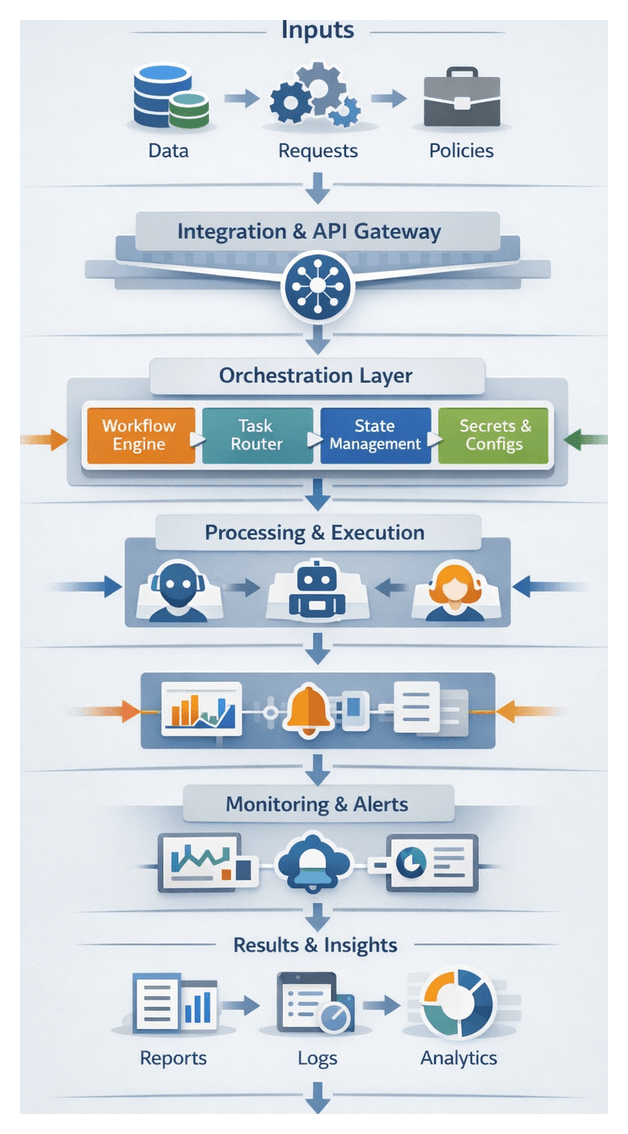
Building a Unified AI Orchestration Framework
Operational Context and Challenges
Enterprises deploy a diverse set of AI agents, robotic process automation bots, and human workflows across multiple departments. Without a unified control layer, these capabilities operate in isolation, leading to data inconsistencies, variable reliability, and fragmented governance. Custom integrations and manual handoffs introduce latency, errors, and maintenance overhead, undermining agility and inflating total cost of ownership.
- Data inconsistency: disparate tools transform or interpret data differently, requiring manual reconciliation.
- Variable reliability: inconsistent error recovery strategies cause silent failures or process interruptions.
- Lack of visibility: stakeholders cannot trace requests end to end, impeding troubleshooting and compliance.
- Scalability constraints: each integration path must be scaled and maintained separately, multiplying effort.
- Compliance risk: decentralized policies create gaps in audit trails and regulatory adherence.
Design Principles
A cohesive orchestration framework addresses these challenges through a set of guiding principles:
- Unified control plane: a single interface for deploying, monitoring, and managing workflows across AI and RPA components.
- Declarative workflows: high-level definitions of task sequences, dependencies, and routing logic.
- Event-driven interactions: loose coupling via a central event bus or message queue, enabling asynchronous execution and scalability.
- Resilient error handling: standardized retry policies, circuit breakers, and compensating transactions for uniform failure recovery.
- Policy-based governance: central enforcement of security, compliance, and data retention policies with role-based access control.
- Observability by default: integrated logging, metrics, and tracing to provide end-to-end transparency.
Core Components
- Workflow Engine: interprets workflow definitions, schedules tasks, and manages state transitions.
- Message Bus: durable event broker such as Apache Kafka or RabbitMQ for high-throughput messaging.
- Task Router: evaluates routing rules to assign tasks to the appropriate AI agent, RPA bot, or human operator based on capacity, priority, and SLAs.
- State Store: persists workflow context and audit records to enable recovery and compliance reporting.
- API Gateway: provides secure entry points for external triggers, webhooks, and third-party integrations.
- Monitoring and Alerting Module: aggregates logs, metrics, and traces, raising alerts on anomalies.
- Secrets and Configuration Manager: centralizes credentials, feature flags, and configuration parameters for consistent access.
Coordinating Human and Automated Tasks
The framework supports both synchronous AI-driven tasks and asynchronous human approvals. Automated work items enter task queues, preserving dependencies and allowing agents to process them independently. Human tasks surface through user interfaces or notifications, with built-in escalation rules for overdue items. Integration with identity and access management enforces role-based permissions, ensuring only authorized individuals can approve or amend critical decisions.
Maintaining Consistency and Resilience
Consistency is achieved through idempotent operations and compensating actions. Retry logic with exponential backoff addresses transient failures, while circuit breakers isolate unhealthy services. Multi-step transactions employ saga patterns to orchestrate local transactions with compensation steps, preserving data integrity without monolithic two-phase commits.
Security and Governance
Centralized orchestration enforces security and compliance controls at a single point. Role-based access restricts workflow visibility and actions. Data encryption in transit and at rest protects sensitive payloads. Audit trails capture every state transition and decision, supporting regulatory reporting. Policy-as-code frameworks such as Open Policy Agent validate workflows against organizational policies before deployment.
Scalability and Elasticity
Control plane components and worker agents scale on demand via container orchestration platforms like Kubernetes. Serverless functions such as AWS Lambda and Azure Functions execute short-lived tasks without provisioning servers. Auto-scaling policies respond to queue depth or latency spikes, maintaining SLAs while optimizing resource utilization.
Scheduling and Routing Task Assignments
Purpose and Business Impact
The scheduling and routing layer forms the operational backbone of an AI orchestration framework. It assigns incoming tasks to the most appropriate agents based on business priorities, resource availability, and performance objectives. By codifying assignment logic and enforcing routing constraints, organizations achieve consistent throughput, predictable service levels, and end-to-end traceability.
- Operational efficiency: automated load balancing reduces idle time and prevents resource saturation.
- Scalability: dynamic workload distribution adapts to growing task volumes and new agent types.
- Reliability: built-in retry and escalation mechanisms mitigate transient errors and agent outages.
- Compliance: policy-driven routing enforces regulatory and data-sovereignty requirements.
- Business agility: priority schemes and policies can be updated rapidly without code changes.
Key Inputs and Metadata Requirements
- Task Descriptors: metadata including task type, priority, deadlines, and constraints (data locality, compliance tiers).
- Agent Registry: directory of agent capabilities, supported formats, concurrency limits, and health status via heartbeat messages.
- Business Policies: definitions of priority rules, affinity constraints, escalation protocols, and compliance filters.
- Resource Telemetry: real-time metrics on CPU, GPU, memory, and queue lengths to prevent overload.
- Historical Performance Data: execution logs and throughput statistics supporting predictive scheduling.
- Temporal Constraints: business hours, maintenance windows, and batch schedules governing execution timing.
Prerequisites and System Conditions
- Standardized Task Handshake: a versioned schema for task metadata transmission ensures consistency across components.
- Agent Registration Mechanism: service discovery using platforms like Apache ZooKeeper or custom registries in Kubeflow.
- Policy Engine: runtime rule evaluation supporting dynamic updates without downtime.
- Monitoring and Alerting Infrastructure: dashboards and automated alerts for queue backlogs and policy violations.
- Security and Authentication: encrypted channels and fine-grained access controls for metadata and telemetry.
- Scalable Messaging Fabric: queuing or streaming platforms such as Apache Kafka or AWS SQS to buffer tasks and absorb traffic bursts.
Scheduling Logic Patterns
- Priority Queue Scheduling: multiple tiers with preemption of lower-priority tasks for strict SLA use cases.
- Round-Robin Allocation: even distribution of homogeneous tasks across identical agents.
- Weighted Fair Queuing: proportional task shares based on agent capacity or business importance.
- Deadline-Aware Scheduling: urgency calculation to prioritize tasks with imminent deadlines.
- Load-Aware Dynamic Scheduling: real-time telemetry drives assignment away from overloaded agents.
Routing Rules and Constraints
- Capability Matching: filtering agents by declared roles such as text classification or image recognition.
- Data Locality and Compliance: enforcing data-sovereignty mandates by routing tasks to approved regions.
- Affinity and Anti-Affinity: grouping related tasks for cache efficiency or spreading them for fault tolerance.
- Escalation Paths: fallback agents, human queues, or alternate pipelines when standard processing fails.
- Concurrent Execution Limits: respecting per-agent caps to preserve performance guarantees.
Integration with Adjacent Stages
- Ingests enriched task definitions from the planning stage, including constraints and context.
- Queries the monitoring layer for real-time agent health and load metrics.
- Dispatches tasks via agent-specific queues or direct HTTP/gRPC calls.
- Records assignment decisions in execution registries and audit logs for traceability.
- Handles completion and failure updates, re-queuing tasks according to retry and escalation policies.
Coordination Rules and System Integration Roles
Coordination Rule Framework
Coordination rules externalize orchestration logic, defining task sequencing, resource assignment, error handling, and branching based on data inputs or external events.
- Sequencing Rules: enforce task dependencies, ensuring prerequisites complete before downstream steps.
- Parallelism and Synchronization Rules: govern concurrent execution and join barriers for consistency.
- Error Handling and Retry Policies: specify backoff intervals, maximum attempts, and escalation to human operators.
- Resource Allocation Rules: allocate compute, storage, or specialized hardware based on priorities and cost constraints.
- Event-Driven Triggers: enable dynamic branching in response to API callbacks, message events, or alerts.
Rule Authoring and Management
- Rule Engine Selection: platforms like Drools provide decision tables and event processing for dynamic policy evaluation.
- Version Control: store rule definitions in source repositories for audit trails, peer reviews, and rollback capabilities.
- Testing and Simulation: validate rules against synthetic and historical scenarios before production deployment.
- Approval Workflows: integrate rule changes into formal change management with role-based approvals.
- Execution Monitoring: capture metrics on rule firing frequencies, latency, and exception rates for visibility.
- API Gateway: unified entry point enforcing authentication, rate limits, and payload validation.
- Message Broker: event buses such as Apache Kafka or AgentLinkAI for scalable, asynchronous communication.
- Enterprise Service Bus: protocol translation and data transformation across legacy systems and enterprise applications.
- Adapter Layer: connectors normalizing calls to SQL, NoSQL, file systems, cloud storage, and third-party APIs.
- Event Router: rule-based filtering and enrichment of events such as anomaly detections or performance alerts.
- Monitoring and Logging Service: aggregation of trace logs, metrics, and audit records for real-time visibility.
Integration Patterns
- Request-Reply: synchronous interactions for low-latency inference requests.
- Publish-Subscribe: broadcasting updates and notifications to multiple subscribers.
- CQRS: separating read and write paths for performance optimization.
- Saga Pattern: coordinating distributed transactions with compensating actions on failure.
- Sidecar Architecture: deploying integration proxies alongside AI agent containers for cross-cutting concerns.
Security and Compliance Responsibilities
- Authentication and Authorization: implement OAuth2, JWT, or mutual TLS for service identity and access control.
- Data Encryption: enforce TLS for data in transit and AES-256 at rest.
- Data Masking and Tokenization: protect PII and financial data within integration payloads.
- Audit Logging: record message payloads, timestamps, and actor identities for compliance audits.
- Policy Enforcement: validate requests against data residency and privacy regulations before routing.
Monitoring and Auditing Integrations
- Health Checks and Heartbeats: periodic probes validate endpoint connectivity and response times.
- End-to-End Tracing: correlate transaction IDs across distributed components for root-cause analysis.
- Throughput and Error Metrics: track message volumes, queue lengths, and retry counts for capacity planning.
- Compliance Reports: automated extraction of audit trails and policy violation incidents.
- SLA Management: define objectives and monitor adherence, triggering notifications for at-risk obligations.
Best Practices and Organizational Alignment
- Maintain a centralized repository for coordination rules and integration configurations with clear ownership.
- Adopt continuous integration pipelines that validate rule changes and integration code through automated tests and security scans.
- Design modular rule sets and adapters to enable reuse and reduce coupling.
- Regularly review and prune outdated rules and connectors to minimize technical debt.
- Engage AI engineers, DevOps, security, and business process owners in defining coordination policies and integration standards.
Monitoring, Alerting, and Dynamic Rerouting
Monitoring Outputs and Telemetry Sources
The monitoring stage provides continuous visibility into workflow execution, resource utilization, and service health through structured logs, real-time metrics, alerts, and audit trails. Key telemetry sources include:
- Infrastructure Monitoring Agents: tools such as Prometheus collect node-level CPU, memory, disk I/O, and network metrics.
- Application Performance Instrumentation: libraries like OpenTelemetry produce distributed traces and method-level metrics.
- Log Aggregation Services: platforms such as Grafana Loki and Splunk centralize logs for search and analysis.
- Event Streams: messaging systems like Apache Kafka capture task completions, errors, and audit events in real time.
- External Service Health Endpoints: SaaS status APIs supply uptime and response-time metrics.
Alerting Mechanisms and Thresholds
- Metric-Based Alerts: trigger when metrics cross thresholds, such as CPU utilization above 80 percent.
- Log-Based Alerts: pattern matching or anomaly detection on log streams to detect repeated failures or exceptions.
- Synthetic Transaction Alerts: periodic probes simulate end-to-end workflows and flag failures or latency deviations.
- Composite Alerts: combine multiple conditions, for example, rising API error rates alongside database latency.
Alerts route to notification channels such as email, Slack, Microsoft Teams, or incident management tools like PagerDuty, including contextual metadata and recommended remediation steps.
Dynamic Rerouting Policies and Triggers
Dynamic rerouting policies use monitoring outputs to redirect tasks to alternative agents or service instances, ensuring continuous workflow progress. Policy components include:
- Condition Evaluation: detect alert states or metric anomalies that meet rerouting criteria.
- Alternative Path Definitions: specify fallback agents, redundant endpoints, or quarantine queues.
- Priority and Weighting: assign weights to alternative paths based on reliability scores.
- Escalation Tiers: multi-stage rerouting from local retries to human intervention.
- Cool-Down Intervals: prevent oscillation by enforcing minimum residence times on new paths.
Primary triggers include real-time rule engines such as Kubeflow Pipelines for millisecond-latency rerouting, and scheduled reconciliation checks that rebalance workflows based on aggregated metrics.
Handoff to Recovery and Execution Agents
- Updated Task Metadata: tasks carry new routing instructions, retry counts, and reroute timestamps.
- Recovery Task Queues: isolated queues store tasks for manual review or delayed processing.
- Execution Reports: agents publish receipts with status, latency, and resource consumption metrics.
- Incident Tickets: systems like ServiceNow generate structured records when automated recovery fails.
Integrations with Third-Party Monitoring Tools
- Cloud-Native Monitoring: services such as AWS CloudWatch, Azure Monitor, and Google Cloud Operations.
- End-User Experience Monitoring: solutions like Dynatrace and Datadog combining RUM and synthetic checks.
- Logging and Analysis: Elastic Stack for search, visualization, and ML-driven anomaly detection.
- Incident Management: platforms like PagerDuty and Opsgenie for on-call scheduling and escalation policies.
Using Monitoring Outputs for Continuous Improvement
- Model Tuning: feedback loops from performance metrics drive retraining cycles and rule refinements.
- Compliance Reporting: audit trails and alert histories support regulatory reviews.
- Capacity Planning: resource utilization dashboards inform scaling decisions.
- Strategic Reporting: aggregated metrics quantify ROI, SLA compliance, and incident reduction.
Business Impact of Monitoring and Self-Healing
Effective monitoring and dynamic rerouting prevent silent failures, reduce mean time to detection, and maintain service reliability under fluctuating loads. By embedding self-healing capabilities, enterprises minimize manual intervention, optimize resource utilization, and enhance customer trust in AI-driven solutions.
Chapter 5: Automated Action Execution with RPA Agents
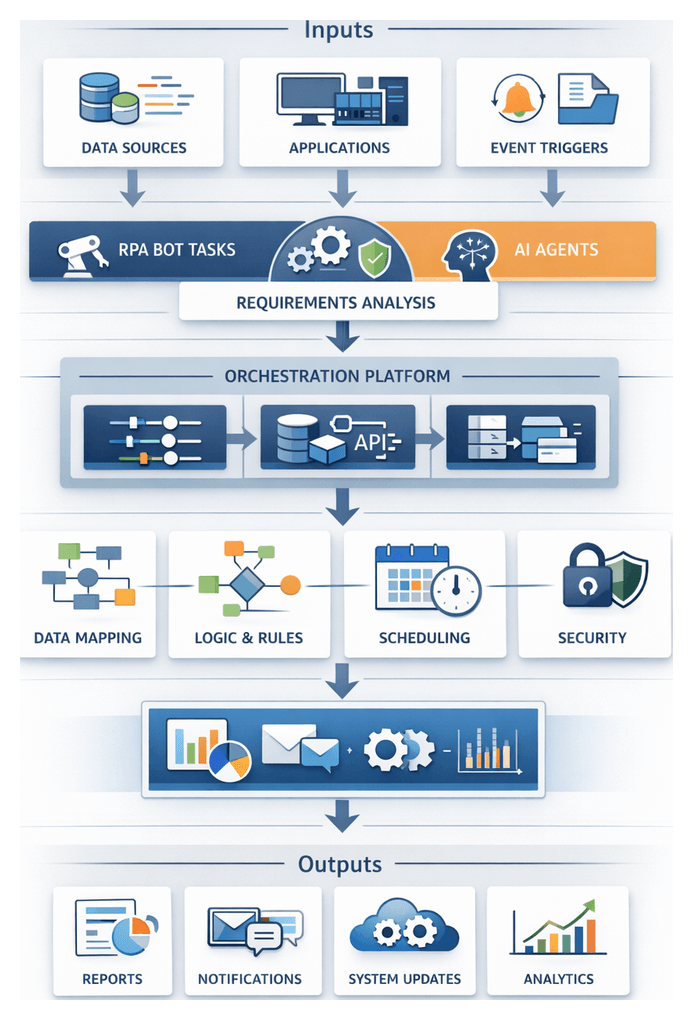
Defining Automation Requirements for RPA and AI Agents
Enterprises embarking on robotic process automation (RPA) and AI-driven workflows must begin with rigorous requirements identification to ensure automation aligns with business objectives and technical constraints. This phase clarifies the scope of tasks—repetitive, rule-based activities suited for RPA and context-rich processes requiring AI agents—across legacy, cloud, and digital applications. Teams document target systems, data exchanges, event triggers, and security prerequisites to minimize implementation risk, accelerate deployment, and support scalable maintenance.
Industry trends such as regulatory compliance, 24×7 operations, and escalating transaction volumes drive the need for precise input definitions. Process complexity, fueled by hybrid architectures and manual handoffs, increases error rates and latency. Well-scoped requirements reduce scope creep, prevent runtime failures, and establish a solid foundation for orchestration and agent integration.
Key Objectives
- Clarify process boundaries, automation scope, and performance targets
- Catalog applications, interfaces, APIs, and integration points
- Define data mappings, transformation logic, and validation rules
- Establish triggers, schedules, exception scenarios, and dependencies
- Document security controls, compliance requirements, and access policies
- Align stakeholders on deliverables, timelines, and success metrics
Stakeholder Roles and Collaboration
Cross-functional teams drive comprehensive requirements gathering. Process owners and subject matter experts detail current workflows, exceptions, and performance goals. IT architects assess system architectures, API availability, and network constraints. Security and compliance teams validate data privacy, credential management, and audit logging standards. Business analysts translate workflows into actionable RPA and AI specifications, while automation developers confirm feasibility within tool constraints. Early alignment prevents rework and ensures the design reflects operational realities.
Landscape Assessment and Target Interfaces
Teams employ process mining, operational dashboards, and user interviews to quantify task frequency, duration, and exception rates. System inventories reveal legacy mainframes, web portals, SaaS platforms, desktop productivity tools, and messaging systems. Interface details—screen layouts and control hierarchies for UI automation, REST or SOAP API schemas, file formats, and database connection parameters—inform technology choices: UI scraping, direct integration, or hybrid approaches.
Data Mapping and Transformation
Automation often shuttles data between heterogeneous systems. Detailed mapping activities specify how source fields correspond to target fields, including type conversions, default values, conditional logic, and cleansing rules. Documentation includes sample inputs, expected outputs, validation checks, and error thresholds to handle missing or malformed data gracefully.
Trigger Conditions and Scheduling
Defining clear triggers ensures bots and AI agents act when business conditions warrant. Triggers may be file-based (monitoring directories or cloud storage), message-driven (enterprise messaging systems), schedule-based (cron expressions or business calendars), manual (secure portals), or hybrid combinations. Precise definitions prevent unwanted runs, align timing with downstream processes, and optimize resource utilization.
Security, Compliance, and Change Management
Automated agents require secure credential handling via vaults or credential services and operate under least-privilege access controls. Compliance obligations—data residency, encryption standards, auditability—shape input processing and logging. Before development, confirm process stability, freeze application versions, and embed change management protocols to manage UI redesigns or API updates. Regular reviews and regression testing underlie maintainable automation.
Documentation and Readiness Criteria
The requirements phase culminates in a formal Automation Requirements Specification (ARS) that includes process flow diagrams, application catalogs, data mapping tables, trigger definitions, security checklists, and testing strategies. Stakeholder sign-off on the ARS signals readiness to advance into design, development, and orchestration.
Designing a Unified Orchestration Framework
Orchestration frameworks coordinate AI agents, RPA bots, data pipelines, and microservices into cohesive, end-to-end workflows. By centralizing control logic, enterprises eliminate brittle point-to-point integrations, enforce error-handling policies, and enable scalable, repeatable architectures.
Flow Patterns and Interaction Models
Common orchestration patterns include:
- Linear sequences for straightforward pipelines
- Parallel branching for concurrent task execution
- Event-driven triggers reacting to file arrivals or anomaly signals from AI models
- Conditional routing based on business rules or AI-driven classifications
Tools like Apache Airflow and Prefect offer declarative pipelines and operators for AI and data tasks.
Coordination Planes
- Control Plane: Manages workflow definitions, schedules, retry policies, and access controls.
- Data Plane: Transfers inputs and outputs via APIs, message queues, or file systems with integrity and traceability.
- Execution Plane: Hosts agents, containers, or microservices executing tasks under orchestration directives.
Frameworks such as Camunda abstract these layers, enabling seamless integration of custom AI microservices via gRPC or REST adapters.
Building Blocks
- Workflow Designer: Visual or code-based process definition environment.
- Task Executors: Workers interfacing with databases, message brokers, RPA platforms, and AI services.
- Event Bus: Publish-subscribe infrastructure propagating state changes and triggers.
- Monitoring Dashboard: Real-time console for pipeline health, task performance, and SLA adherence.
- Audit Trail: Persistent execution records for compliance and root-cause analysis.
Open-source solutions like Kubeflow or commercial platforms such as MuleSoft can assemble these components according to security and governance requirements.
Case Example: AI-Powered Order Processing
- New orders publish events to the orchestration event bus.
- An NLU service validates customer identity.
- Conditional routing directs high-risk orders to a fraud detection microservice.
- Approved orders trigger RPA bots built with UiPath, Automation Anywhere, or Blue Prism to interact with legacy ERP systems.
- Parallel tasks update CRM records and dispatch confirmation emails.
- Exceptions invoke a human review workflow via a virtual agent.
This cohesive flow reduces manual errors, ensures consistency, and provides a clear audit trail.
Adoption Considerations
- Governance: Define roles and permissions for workflow management.
- Service Catalog: Maintain a registry of AI components, data sources, and RPA endpoints.
- Version Control: Apply CI/CD to workflow definitions with testing and systematic rollouts.
- Observability: Integrate metrics and logs into incident management tools.
- Training and Change Management: Equip teams to author, monitor, and troubleshoot orchestrated workflows.
Integrating AI Agents into Enterprise Processes
Integrating AI agents into existing enterprise processes embeds autonomous, learning-driven capabilities within operational workflows. This conjunction of cognitive automation and RPA extends automation to dynamic, context-rich activities.
Agent Typologies
- Autonomous Process Agents: Monitor event streams and initiate workflows, for example supply chain agents generating procurement requests.
- Conversational Virtual Agents: Engage users via chat or voice; platforms like Rasa and Google Dialogflow power scalable deployments.
- Data Enrichment Agents: Augment datasets via external APIs and knowledge graphs using Amazon Neptune or Neo4j.
- Analytical and Predictive Agents: Apply machine learning models via OpenAI APIs or Azure Machine Learning to generate forecasts and risk assessments.
- RPA Agents: Automate interactions with legacy systems and batch processes using UiPath, Automation Anywhere, or Blue Prism.
Supporting Architecture
- Orchestration Engine: Coordinates tasks via APIs from frameworks like those listed on AgentLinkAI.
- Integration Layer: Middleware exposing REST, gRPC, or messaging interfaces; message brokers such as Apache Kafka or RabbitMQ.
- Data Platform: Unified repository via AWS SageMaker or Google Cloud AI Platform.
- Knowledge Management: Semantic stores and vector databases like Coveo and Pinecone.
- Security and Governance: IAM, encryption, and audit logs managed with Splunk or the ELK Stack.
- Monitoring and Observability: Telemetry captured by Prometheus, Grafana, or Datadog.
Integration Patterns
- Event-Driven Architecture: Agents subscribe to event streams for loose coupling.
- Request-Response APIs: Synchronous interactions for real-time tasks.
- Command Messaging: Orchestrator publishes commands to message buses with correlation IDs.
- Service Mesh: Istio or Linkerd secure and observe microservice communications.
- Adapter-Based Connections: Adapters bridge legacy systems via UI automation or custom connectors.
Lifecycle Management
- Dynamic Provisioning: Container orchestration (e.g., Kubernetes) scales agent instances on demand.
- Versioning and Rollouts: Blue-green and canary deployments ensure safe updates.
- Health Checks: Self-assessments trigger automated restarts.
- Configuration Management: Centralized settings via HashiCorp Consul or AWS Systems Manager.
- Logging and Traceability: Audit logs capture decisions and data flows.
Security and Ethical Considerations
- IAM: Service identities, OAuth tokens, and mTLS certificates enforce least privilege.
- Data Privacy: GDPR and CCPA compliance via data masking and anonymization.
- Ethical AI: Bias mitigation, model explainability, and decision rationale logging.
- Continuous Compliance: Automated audits and alerts for policy deviations.
Strategic Impact
- Throughput: Agents process tasks 24/7, freeing human resources.
- Accuracy: Consistent business rule application reduces errors.
- Responsiveness: Event-driven agents swift reaction to critical incidents.
- Personalization: Recommendation and conversational bots engage customers at scale.
- Innovation: Modular agents accelerate new workflow assembly.
Execution Monitoring and Next-Stage Handoffs
Execution logs generated by RPA bots and AI agents capture the details, metrics, and outcomes of automated tasks. Standardizing log schemas and establishing robust storage, monitoring, and handoff mechanisms ensure traceability, compliance, and seamless data flow into subsequent AI-driven stages.
Log Artifact Taxonomy
- Execution Trace Logs: Timestamped records of UI interactions, API calls, and data events.
- Performance Metrics: Statistics on task durations, throughput, and resource utilization.
- Error and Exception Logs: Structured records with codes, stack traces, and retry actions.
- Audit Trails: Immutable chains of custody linking transactions to credentials and contexts.
- Transaction Summaries: High-level overviews of process sequences and statuses.
Standardizing Schemas
- Timestamp: ISO-8601
- Agent Identifier: e.g., UiPath Robot ID
- Transaction ID: Unique key for end-to-end correlation
- Step Name and Status Code: SUCCESS, ERROR, RETRY
- Payload References and Performance Data
- Error Details and Remediation Guidance
Compliance with these schemas simplifies integration with centralized platforms like Splunk or the ELK Stack.
Storage, Retention, and Access Control
- Retention Policies: Align with regulatory mandates and cost considerations.
- Archival: Tiered storage with Amazon S3 or Azure Blob Storage.
- Access Controls: Role-based restrictions for security and compliance teams.
- Indexing: Metadata tagging for efficient search and root-cause analysis.
Monitoring and Alerting
- Event-Driven Alerts: Threshold-based notifications via email, Microsoft Teams, or Slack.
- Dashboards: Interactive views in Microsoft Power BI or Tableau.
- Health Checks: Automated jobs verifying log freshness and volume.
- Incident Management: Ticket creation in ServiceNow with embedded log excerpts.
Downstream Dependencies and Handoffs
Log artifacts feed into knowledge bases, decision support engines, compliance dashboards, and continuous learning pipelines. Explicit dependencies ensure timely delivery of inputs to:
- Knowledge Management (e.g., Pinecone vector databases)
- Decision Support Engines using rule-based or generative AI
- Governance Dashboards for regulatory reporting
- Model Retraining Pipelines leveraging error logs and performance data
- Orchestration Feedback Loops for dynamic rerouting
Handoff Mechanisms
- Publish/Subscribe Messaging via Apache Kafka or Azure Service Bus.
- RESTful APIs with standardized schemas.
- File Drops and ETL via Apache NiFi or Azure Data Factory.
- Webhooks configured in Automation Anywhere.
- Database Writes to relational or NoSQL stores.
Consistency and Best Practices
- Two-Phase Commit for distributed transactions.
- Compensating Actions for rollback routines.
- Idempotent Operations to support safe retries.
- Checkpointing long-running processes.
- Contract Testing and Schema Versioning for reliable integration.
- Latency Monitoring and Retry Policies for resilient handoffs.
- Documentation and Cataloging of events, APIs, and schemas.
This structured approach to execution monitoring, log management, and next-stage dependencies ensures that RPA and AI agents operate reliably within orchestrated workflows, delivering measurable business value and supporting ongoing digital transformation.
Chapter 6: Conversational Virtual Agents for User Interaction
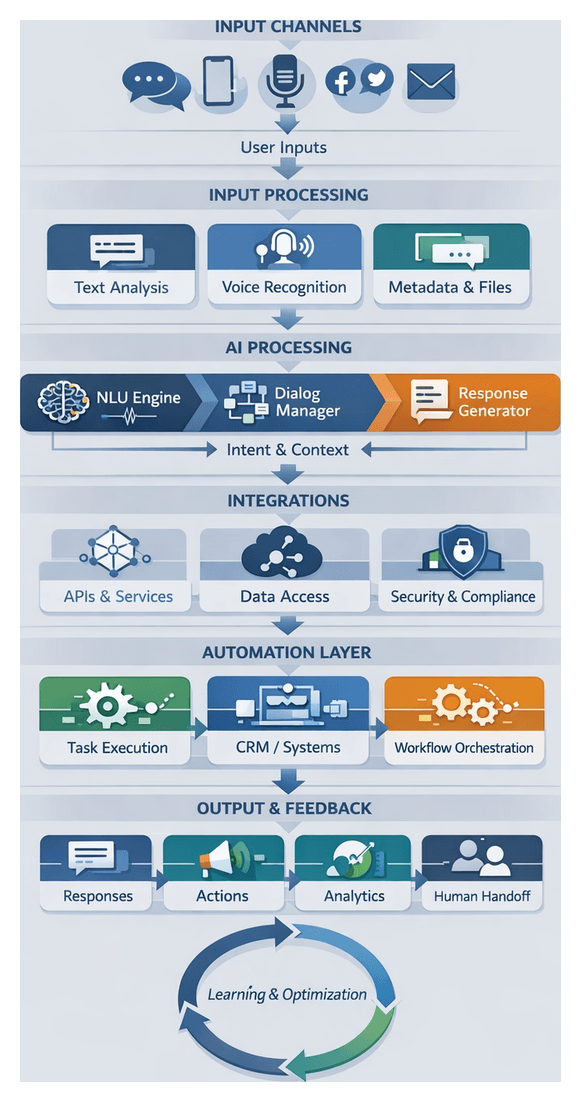
Designing Dialog Inputs and Channel Specifications
Purpose and Business Alignment
Defining dialog inputs and channel specifications ensures that virtual agents receive consistent, well-formed data aligned with business objectives. By modeling input modalities—free-form text, voice, structured selections, rich media and contextual metadata—and mapping them to communication channels, teams capture user intents accurately, reduce integration overhead and maintain brand consistency across finance, healthcare, retail and public sector deployments. Clear specifications support regulatory compliance by documenting data capture methods, API contracts and privacy safeguards.
Strategic Benefits and Prerequisites
- Consistent User Experience: Standardized input formats and channel behaviors deliver coherent responses across touchpoints.
- Optimized Intent Recognition: Structured inputs guide NLU models, reducing misclassification and improving accuracy.
- Scalability: Modular input-channel configurations simplify the addition of new platforms or modalities.
- Reduced Integration Overhead: Defined schemas and authentication flows speed handoffs between UI components and orchestration layers.
- Regulatory Compliance: Documented channel specifications facilitate audits and demonstrate adherence to standards such as GDPR and HIPAA.
Prerequisites for this stage include:
- Clear business objectives, use cases and KPIs for conversational interactions.
- Stakeholder alignment across customer support, IT, legal and compliance teams.
- Inventory of existing messaging platforms, telephony providers and front-end frameworks.
- API credentials and integration documentation for channels such as WhatsApp Business API, Twilio and Microsoft Teams.
- Defined user authentication strategy via OAuth, SSO or anonymous sessions.
Conversational Input Types
- Free-form Text: Unstructured chat requiring robust NLU pipelines.
- Voice Commands: Audio streams converted to text via services like Google Dialogflow or Amazon Lex.
- Structured Selections: Buttons, quick replies and carousels to simplify state transitions.
- Rich Media Uploads: Documents, images or audio processed via OCR and image recognition agents.
- Contextual Metadata: Locale, device type, geolocation and user profile attributes for personalization.
Supported Channels
- Web Chat Widgets: Embedded via frameworks such as Microsoft Bot Framework.
- Mobile App Chat: Native iOS and Android integrations using SDKs or custom APIs.
- Social Messaging Platforms: Facebook Messenger, WhatsApp, WeChat leveraging respective Business APIs.
- SMS and RCS: Managed through providers like Twilio or Vonage.
- Voice Assistants and IVR: Integrations with IBM Watson Assistant, Google Dialogflow and Amazon Lex.
Channel Specification Considerations
- API Endpoints and Authentication: Base URLs, headers, OAuth flows and token refresh mechanisms.
- Message Formatting: Supported payload structures, markup languages (SSML for voice) and media protocols.
- Rate Limits and Throttling: Throughput constraints, retry strategies and concurrency limits.
- Error Handling: Standard response codes, webhook callbacks and fallbacks for undeliverable messages.
- Localization Support: Character encoding, right-to-left languages and time zone normalization.
Session Context and State Management
- Session Identifiers: Unique tokens persisting across requests for context retrieval.
- Context Store: In-memory caches or persistent stores like Redis and Amazon DynamoDB holding intents, entities and slot values.
- Timeout Policies: Session expiration rules, idle thresholds and context purging strategies.
- Cross-Channel Continuity: Synchronization mechanisms for device or channel switches using webhooks or event buses.
Technical and Security Requirements
- Webhook Design: Endpoint schemas and validation rules for incoming message callbacks.
- Middleware Components: Logic to normalize channel-specific formats into a unified schema.
- Latency Benchmarks and Load Testing: SLA targets, stress scenarios and performance criteria.
- Monitoring and Logging Hooks: Observability integrations capturing message flows, errors and metrics.
- Data Encryption: TLS in transit, encryption at rest and PII masking for compliance.
- Access Controls and Audit Trails: Role-based permissions, consent management and immutable logs.
Virtual Agent Architecture and Modules
Dialog Management Module
The dialog management module orchestrates conversation flow through a state machine, policy engine and session manager. The state machine tracks interaction stages, while the policy engine applies business rules for slot validation, branching logic and multi-intent resolution. By externalizing policies in configuration files or rule stores, conversational logic can be updated without code redeployment.
- Session Manager: Persists context variables, user attributes and conversation history across channels using in-memory caches for low latency and document stores for long-lived sessions.
- Context Enrichment: Retrieves user profiles and preferences from CRM or identity services to personalize responses.
Natural Language Understanding Engine
The NLU engine processes text or speech transcripts to identify intents, extract entities and detect sentiment. Enterprises leverage managed services and open-source frameworks for hybrid deployments, combining rapid cloud solutions with on-premise compliance.
- Dialogflow, Amazon Lex, IBM Watson Assistant, Microsoft Bot Framework and Rasa.
- Intent classification models trained on annotated data and entity recognition using CRF or neural architectures.
- Sentiment analysis modules adjust tone and escalation rules based on emotional cues.
- Custom domain adaptation for industry-specific terminology and regulatory concepts.
Response Generation Module
- Template-Based Responses: Predefined text blocks with variable placeholders for confirmations and guided forms.
- Retrieval-Based Responses: Selecting best matches from a known corpus using similarity metrics.
- Generative Models: Neural language models (GPT variants) producing freeform text with post-filtering against policy constraints.
Hybrid strategies often route routine requests through templates and funnel ambiguous queries to generative pathways to balance compliance with flexibility.
Integration Adapters
- REST and SOAP: JSON-based adapters with OAuth or API key authentication; XML-based SOAP with WS-Security tokens, managed via API gateways or iPaaS.
- Database and Messaging: Direct connectors for queries and pub/sub adapters for event-driven updates using enterprise service buses or cloud messaging.
- RPA and Legacy Systems: Bot orchestration to perform desktop automation against applications lacking public APIs.
Security and Compliance Module
- Authentication Adapters: Support OAuth, SAML and MFA before disclosing sensitive data.
- Data Masking and Tokenization: Protect PII in logs and transcripts.
- Role-Based Access Controls: Restrict configuration, policy editing and integration endpoints to authorized personnel.
- Audit Trails: Capture changes to configurations, policies and model training iterations for regulatory mandates.
Analytics and Monitoring Module
- Conversation Logs: Record inputs, detected intents, system actions and response timestamps.
- Quality Metrics: Intent recognition accuracy, fallback rates and user satisfaction scores.
- Operational Metrics: Latency, error rates and throughput per channel.
Logs feed into data lakes or warehouses for dashboards and machine learning pipelines that identify emerging intents, language drift and compliance issues.
Conversation Flow and Escalation Logic
Core Conversation Flow Sequence
- Receive User Input: Ingest text or speech via channel adapters.
- Preprocessing: Tokenization, language detection and noise filtering.
- Intent Classification: Assign intent labels with confidence scores.
- Entity Extraction: Recognize named entities, dates and domain-specific slots.
- Contextual Slot Filling: Merge new entities with stored slot values in the dialog state.
- Business Rule Evaluation: Check data completeness, compliance constraints and routing directives.
- Response Generation: Construct replies via templates, retrieval engines or generative models.
- Output Delivery: Return formatted responses through channel adapters.
- Post-Response Monitoring: Capture response times, sentiment and confidence metrics.
- Escalation Assessment: Evaluate fallback counters, sentiment trends and explicit triggers.
Intent Handling and Dynamic Routing
Intent handling modules coordinate with orchestration services to invoke specialized microservices or skill containers for tasks such as order lookups or appointment scheduling. Sensitive operations apply additional security checks or multi-factor prompts. Dynamic routing logic evaluates user profile, agent availability and priority rules to assign interactions to automated skills or escalate to human queues managed by Genesys or Zendesk.
Escalation Criteria and Workflow
- Low Intent Confidence: Consecutive scores below threshold.
- Unresolved Slot Dependencies: Missing required data after multiple prompts.
- User Sentiment Decline: Negative cues detected over turns.
- High-Priority Keywords: Urgent terms like “emergency” or “complaint.”
- Time-to-Resolution Limits: Exceeded thresholds for transaction types.
- Explicit User Request: Direct asks to speak to a human agent.
- Generate Escalation Event: Emit event to human support platform.
- Context Packaging: Bundle transcript, profile, entities and logs.
- Queue Assignment: Apply skill-based routing to specialized teams.
- Notification Dispatch: Alert agents via dashboards or SMS.
- Session Transfer: Seamlessly hand over the session identifier.
- Handoff Confirmation: Inform user of expected wait times.
- Post-Handoff Monitoring: Record handoff success and wait durations.
Integration Points
- Customer Relationship Management (CRM) for personalized interactions.
- Knowledge Base Services for dynamic content retrieval.
- Authentication and Authorization via identity providers.
- Workforce Management for agent availability data.
- Ticketing Platforms for automatic support ticket creation.
- Analytics Dashboards such as Power BI and Tableau for operational insights.
Response Structures, Handoff Mechanisms and Feedback Loops
Response Structures and Output Formats
- Fulfillment Text: Localized, templated messages.
- Rich Response Objects: Cards, quick replies, images and media payloads.
- Action Directives: Client instructions for API calls or payment flows.
- Contextual Parameters: Key-value pairs of entities, sentiment scores and session variables.
- Event Tokens: Identifiers for analytics tracking and A/B testing.
Handoff Mechanisms and Data Passing
- Conversation Transcript with timestamps and channel identifiers.
- Extracted Entities and Parameters captured during dialog.
- Session Context Variables indicating prior escalations and authentication status.
- Diagnostic Metadata such as confidence scores and error codes.
- User Profile and Permissions from CRM or IAM systems.
- Routing Instructions for appropriate queue or skill group.
Integration with Customer Service Platforms
- Zendesk – Chat handoff API, ticket hooks and webhooks.
- Salesforce Service Cloud – Omni-Channel routing, case creation and Live Agent transcripts.
- Freshdesk – Support SDK, auto-ticketing and custom fields.
- Twilio Flex – Programmable chat handoff, TaskRouter and event streams.
- LivePerson – Conversational Cloud API for seamless bot-agent transitions.
Post-Handoff Continuity and Feedback Loop
- Resolution Outcome Tags such as “Resolved” or “Escalated.”
- User Feedback Surveys for satisfaction ratings and comments.
- Knowledge Base Updates adding new FAQs and dialog variations.
- Model Retraining Data incorporating labeled transcripts.
- Operational Metric Reconciliation correlating virtual and human agent performance.
- Rule Refinement adjusting escalation thresholds and fallback conditions.
Implementing this closed-loop feedback mechanism drives continuous improvement, enabling virtual agents to handle an expanding scope of interactions autonomously while ensuring high-quality support for complex or sensitive cases.
Chapter 7: Data Augmentation and Knowledge Management
Purpose and Business Drivers
In large enterprises, core datasets often lack the context, completeness, or semantic relationships needed for advanced analytics and AI-driven decision making. Data augmentation and knowledge management enrich records with external information, link entities through semantic structures, and maintain a centralized knowledge repository. By integrating diverse API sources and specialized knowledge stores, organizations transform raw data into a richer, interconnected asset that powers more accurate insights, accelerates automated workflows, and improves downstream model performance.
- Filling Information Gaps—Supplement internal records with authoritative external data to improve completeness.
- Enhancing Context—Link entities through ontologies or knowledge graphs to expose semantic relationships.
- Improving Quality—Validate and standardize data against reference sources for consistency.
- Enabling Richer Analytics—Provide AI models with multidimensional inputs for higher‐fidelity insights.
- Supporting Compliance—Cross-verify sensitive information against regulatory registries and privacy databases.
Objectives and Scope
This stage aims to integrate external feeds, align schemas, construct a centralized knowledge store, ensure governance compliance, and expose enriched artifacts to downstream systems. Key objectives include:
- Identify and integrate relevant external data feeds, APIs, and ontological stores.
- Map and align diverse schemas, taxonomies, and identifiers for entity resolution.
- Build or update knowledge graphs or vector indexes for semantic search and context retrieval.
- Enforce data governance, security standards, and privacy regulations.
- Deliver enriched records and semantic relationships to AI agents, analytics engines, and decision-support modules.
Key Inputs
- Internal Data Repositories—ERP, CRM, finance, and inventory systems provide core records, unique identifiers, and master data attributes.
- External APIs and Data Feeds—Authoritative sources ensure enrichment reflects current market realities. Examples include:
- Salesforce for firmographics and technographics.
- SAP for supplier ratings, material descriptions, and compliance certificates.
- Bloomberg for real-time pricing and economic indicators.
- Twitter and LinkedIn for social sentiment and network analytics.
- Google Knowledge Graph API for entity definitions and relationships.
- OpenStreetMap and NOAA for geospatial and environmental data.
- Knowledge Stores and Ontologies—Structured semantic models for entity resolution and inference:
- Neo4j knowledge graphs for complex relationship queries.
- Apache Jena ontologies for triple-store representations and SPARQL queries.
- DBpedia and Wikidata as public knowledge bases.
- Vector Databases and Embedding Stores—High‐dimensional indexes for semantic similarity:
Prerequisites and Conditions
- Data Governance Framework—Policies, access controls, and privacy compliance (GDPR, CCPA) with defined stewardship and approval workflows.
- API Credentials and Access Management—Secure authentication (OAuth, API keys) and centralized secrets management via HashiCorp Vault or AWS Secrets Manager.
- Identifier and Schema Alignment—Unique keys, global identifiers, and master data management to maintain a single source of truth.
- Data Quality Baselines—Profiling and validation scripts or AI-driven tools to ensure completeness, consistency, and accuracy.
- Latency and Throughput Requirements—Performance SLAs with batch and real-time orchestration, caching, and bulk enrichment strategies.
- Error Handling and Retry Policies—Logging, retry logic, circuit breakers, and fallback mechanisms to prevent workflow disruptions.
- Security and Compliance Checks—Masking, tokenization, encryption in transit and at rest, and periodic audits.
Augmentation Workflow
The end-to-end workflow orchestrates a sequence of coordinated actions to enrich raw data with context and knowledge, ensuring downstream AI components receive fresh, accurate artifacts.
- Triggering and Initialization
- External Knowledge Retrieval
- Semantic Processing and Embedding
- Data Merge and Conflict Resolution
- Knowledge Store and Index Update
- Quality Validation and Monitoring
- Scheduling and Continuous Updates
Triggering and Initialization
Enrichment begins via scheduled jobs or event-driven triggers—new data arrivals, manual invocations, or messaging events. Orchestration tools like Apache Airflow, Prefect, AWS Lambda, or Azure Functions manage workflows.
- Fetch source rosters and change-log pointers.
- Allocate compute resources and instantiate service endpoints.
- Validate API credentials, endpoint URLs, and rate-limit quotas.
- Record job metadata in an execution ledger.
External Knowledge Retrieval
Connect to REST or GraphQL APIs from domain providers, public knowledge graphs like Neo4j, and enterprise repositories via Azure Cognitive Search or Amazon Kendra.
- Apply mapping rules to translate source fields into a canonical schema.
- Batch requests to optimize throughput and respect rate limits.
Semantic Processing and Embedding
Process enrichment payloads with NLP services for entity resolution, relation extraction, and sentiment tagging. Generate embeddings via the OpenAI API or self-hosted transformer models, and augment knowledge graphs with new nodes and edges.
- Parallel microservices handle entity linking and embedding generation.
- Orchestration rules manage concurrency, batching thresholds, and fallback on model timeouts.
Data Merge and Conflict Resolution
Reconcile enriched records with existing entries through key-based joins, conflict detection, and resolution policies (last-write-wins, priority hierarchies, or manual review).
- Flag discrepancies and capture merge decisions in audit logs.
- Track dependent tasks and reprocess records when thresholds are exceeded.
Knowledge Store and Index Update
Propagate merged changes to persistent stores and indexes:
- Upsert enriched attributes into document stores or relational databases.
- Update vector indices on Pinecone or Weaviate for similarity search.
- Synchronize knowledge graphs in Neo4j or Amazon Neptune.
- Coordinate transactions across systems with two-phase commits or compensating actions.
Quality Validation and Monitoring
Ensure outputs meet standards through:
- Schema compliance tests for data types and cardinality.
- Statistical profiling and drift detection via Evidently AI.
- Sampling and human-in-the-loop reviews for edge-case accuracy.
- Alerting via email, messaging, or incident tickets on validation failures.
Scheduling and Continuous Updates
Maintain freshness with incremental updates, event triggers, or ad hoc runs. Store versioning metadata for audits and enable parallel execution across partitions to minimize downtime.
- Time-window batches for non-critical streams.
- Low-latency event-driven updates on ingestion or schema changes.
- Self-service interfaces for user-initiated refreshes.
Knowledge Graphs and Vector Databases
Role of Knowledge Graphs
Knowledge graphs structure entities and relationships into nodes and edges, enabling semantic reasoning, graph traversals, and rule-based enforcement. They model customer profiles, product catalogs, supply chains, and regulatory networks. Databases such as Neo4j or Amazon Neptune ingest triples from relational sources and document stores, with orchestration pipelines handling extraction, entity resolution, and ontology alignment.
Vector Databases for Similarity Retrieval
Vector databases index high-dimensional embeddings of text, images, and audio for semantic search, recommendations, and anomaly detection. Transformer models convert unstructured inputs into numeric vectors, which are ingested into platforms like Pinecone, Weaviate, or Milvus. Orchestration services manage batch and real-time indexing, ensuring new embeddings support k-nearest neighbor queries with metadata annotations for access rights and confidence scores.
Combining Graph and Vector Capabilities
A hybrid approach filters candidates via vector similarity and traverses graph relationships for deeper context. Orchestration pipelines index data into both stores, and on query arrival, parallel requests to graph and vector services return results merged by a ranking service that balances connectivity and semantic proximity. Failure in one store triggers retries or fallbacks to cached data.
- Indexing pipelines update graph and vector stores simultaneously.
- Agents issue parallel similarity and traversal queries.
- Ranking merges results and supplies composite responses to decision logic.
AI Agents Interaction
AI agents—conversational interfaces, RPA bots, planning engines—leverage graph and vector APIs to fetch relevant context. Token-based authentication integrates with enterprise identity providers to enforce access controls, and circuit breakers detect latency or error spikes, rerouting requests as needed. Every query and traversal is logged for audit and compliance.
Operational Considerations and Governance
- Shard and partition vector indexes and graphs to reduce latency.
- Implement incremental updates to capture only delta changes.
- Cache hot-spot nodes and embeddings in-memory for low-latency access.
- Monitor resource utilization and query patterns to drive auto-scaling.
- Classify sensitive data during ingestion, enforce least-privilege access, and log all operations for GDPR and CCPA compliance.
- Encrypt data at rest and in transit, rotate keys regularly, and validate schema conformance to prevent unauthorized evolutions.
Future Directions
Emerging architectures integrate graph neural networks, unified graph-vector stores, and advanced approximate nearest neighbor techniques. Enterprises should evaluate open-source frameworks like Apache JanusGraph alongside managed services offering preconfigured graph-vector workflows, ensuring agility and scalability as requirements evolve.
Enhanced Context Outputs and Handoff
This stage delivers enriched, semantically rich artifacts that serve as the foundation for downstream decision support, generative insights, workflow automation, and compliance monitoring. Outputs include augmented datasets, embeddings, graph entries, enrichment logs, and versioned snapshots.
Output Categories
- Augmented Master Datasets—Tabular or document stores enriched with API attributes, taxonomy annotations, and computed features, with lineage pointers for traceability.
- Semantic Vector Embeddings—High-dimensional vectors persisted in vector stores for nearest-neighbor search.
- Knowledge Graph Entries—Nodes, edges, and ontology-driven relationships with provenance metadata.
- Metadata Enrichment Logs—Records of API responses, transformation rules, and validation checks.
- Versioned Context Snapshots—Periodic captures of augmented states for rollbacks and historical analysis.
Handoff Mechanisms
- RESTful and GraphQL APIs—Expose enriched records with search parameters and pagination.
- Event-Driven Streams—Publish enrichment events to Apache Kafka or Amazon Kinesis for real-time consumption.
- Shared Data Lake Zones—Store augmented datasets in Snowflake or Databricks for bulk processing.
- Vector Store Index Access—Client SDKs provide semantic retrieval for recommendation and anomaly detection.
- Graph Database Query Interfaces—Cypher or SPARQL endpoints enable complex traversals.
- File-Based Artifact Delivery—JSON, Parquet, or AVRO files published to object storage with manifest files.
Versioning and Traceability
- Semantic Version Tags—MAJOR.MINOR.PATCH conventions for schema changes, new features, and fixes.
- Provenance Metadata—Embed source timestamps, lineage, and model versions within record metadata.
- Audit Trail Storage—Persist logs in immutable stores or blockchain-backed ledgers for compliance.
- Rollback Procedures—Automated workflows revert to previous snapshots upon anomaly detection.
Monitoring and Validation
- Enrichment Success Rate—Track successful augmentations versus skips.
- API Latency and Error Metrics—Monitor response times and error codes to inform retry policies.
- Semantic Drift Detection—Use statistical tests or embedding similarity checks to detect distribution shifts.
- Graph Consistency Checks—Validate referential integrity, detect orphaned nodes, and enforce ontology rules.
- Data Freshness Indicators—Monitor time since last augmentation to guide refresh intervals.
Integration Patterns for Downstream Consumers
- On-Demand Fetch Model—Real-time API queries for specific interactions or rule evaluations.
- Preemptive Prefetch Model—Bulk context retrieval and local caching for upcoming tasks.
- Event-Triggered Update Model—Subscription to enrichment streams to refresh local state.
- Hybrid Cache-And-Stream Model—In-memory caches for frequent context and streaming updates for less critical data.
Strategic Value
- Accelerated decision cycles through immediate access to domain-rich data.
- Higher accuracy in AI predictions and recommendations with semantically coherent inputs.
- Reduced development overhead as services consume a common context layer.
- Improved compliance and audit readiness via embedded provenance and versioning controls.
- Scalability of new use cases on a reusable foundation across AI workflows.
Chapter 8: Decision Support and Generative AI Insights
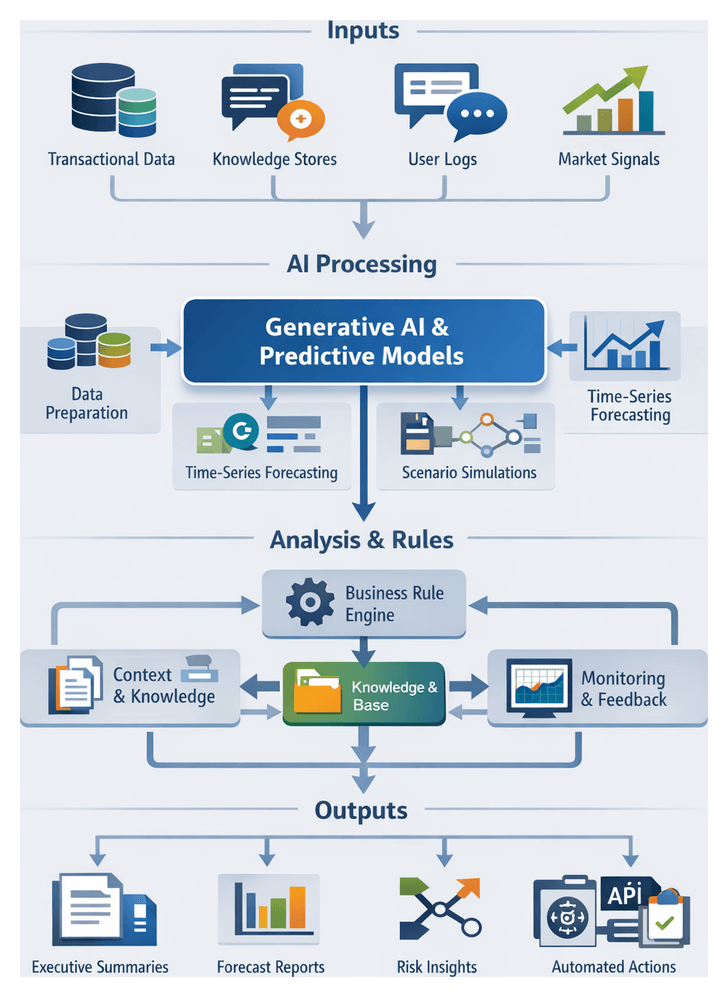
Generating Summaries and Predictive Insights
In large enterprises, transforming raw and augmented data into clear, actionable intelligence is essential for strategic decision making. Generative AI models and predictive algorithms condense extensive transaction logs, reports, and performance metrics into concise summaries, numerical forecasts, and scenario analyses. By leveraging advanced language models and time-series frameworks, organizations accelerate insight delivery, reduce cognitive load on stakeholders, and enable decisions grounded in both historical patterns and forward-looking projections. This capability bridges data processing and executive action, empowering leaders to grasp key trends and evaluate potential outcomes with confidence.
Purpose and Key Models
The objectives of this stage are to generate executive-level briefs and produce predictive inputs—forecasts, risk assessments, and what-if scenarios—that support budgeting, resource prioritization, and risk mitigation. Three categories of AI models drive these outputs:
- Large language models such as GPT-4 via the OpenAI platform for narrative generation and text abstraction
- Time-series and regression frameworks like Prophet by Meta and services on Amazon SageMaker or Google Cloud AI Platform for numerical forecasting
- Simulation engines and custom modules deployed in environments like IBM Watson Studio for scenario analysis and sensitivity testing
Contextual Inputs and Prerequisites
High-quality summaries and forecasts require:
- Unified datasets from transactional systems and ERP extracts
- Enriched domain context from knowledge bases and vector stores
- Transcripts, intent metadata, and user feedback logs
- Time-stamped metrics, external economic indicators, and annotated training data
- Business rules and governance parameters for compliance, style, and risk thresholds
Operational readiness demands:
- Data quality validation with no critical anomalies or schema mismatches
- Successful ingestion, normalization, and augmentation into a unified repository
- Deployed, version-controlled AI models reachable via API endpoints
- Provisioned compute resources (CPU/GPU) and acceptable network latency
- Configured authentication, encryption, and audit logging
- Active business rules engine to filter or constrain outputs
Stakeholders and Strategic Impact
Cross-functional collaboration among data scientists, AI engineers, domain experts, data engineers, business analysts, and compliance officers ensures generative summaries and forecasts align with organizational priorities and regulatory standards. Embedding these capabilities into an orchestration framework delivers:
- Accelerated decision cycles with executive briefs delivered in hours rather than days
- Reduced cognitive load through automated narratives and clear forecasts
- Consistent templates and transparent model documentation to build trust
- Scenario-based planning for proactive risk management
- Resource optimization through data-driven budgeting and capacity planning
Orchestrating Insight Generation and Feedback Flow
This stage transforms model outputs into actionable recommendations while closing the loop on performance refinement. It orchestrates interactions among AI services, rule engines, user interfaces, and monitoring tools, ensuring that insights remain accurate, relevant, and compliant with business objectives.
Request Ingestion and Preprocessing
Requests from BI dashboards, APIs, or virtual assistants are standardized by:
- Mapping parameters to a canonical schema
- Retrieving context from knowledge stores or interaction history
- Validating access controls and usage quotas
Model Invocation and Prompt Management
The orchestration layer selects a generative model—such as OpenAI’s GPT series or Vertex AI’s PaLM via Vertex AI—and dynamically assembles prompt templates populated with context variables. This maintains consistency in tone, structure, and compliance with business rules.
Business Rule Enforcement and Response Formatting
Prior to submission, prompts pass through a rule engine to enforce regulatory constraints, style guidelines, and policy checks. After generation, outputs undergo structuring into predefined sections (for example, Executive Summary, Key Drivers, Forecast), tagging with metadata (confidence scores, model version, timestamp), and sanitization to remove hallucinations or out-of-scope content.
Key System Interactions
- Orchestration Engine: Sequences workflow steps, handles retries, and logs traces
- Generative AI Service: Delivers language and predictive capabilities via REST or gRPC
- Business Rule Engine: Enforces compliance before and after model calls
- Knowledge Store: Supplies domain context and reference documents
- User Interface/API Gateway: Presents insights and captures feedback
- Monitoring Framework: Observes performance metrics and error rates in real time
Feedback Loop Mechanics
Continuous improvement relies on capturing user feedback through:
- Interactive dashboards with rating controls
- Qualitative comment fields
- Usage analytics (review time, click-through rates)
Feedback is ingested, categorized, and tagged with context identifiers. Automated prompt adjustments address minor issues, substantive errors route to governance queues for human review, and strategic suggestions feed into product backlogs. Aggregated feedback triggers model fine-tuning jobs, ensuring outputs remain aligned with user needs and quality benchmarks.
Error Handling and Best Practices
- Transactional patterns or compensating actions to maintain data integrity
- Retry logic with exponential backoff and circuit breakers to handle transient failures
- Unique correlation identifiers and audit logs capturing parameters, rule evaluations, and feedback events
- Clear SLAs for response times and feedback processing
- Modular prompt templates, role-based access controls, and observability via tools like Prometheus or Datadog
- Scheduled drift detection and model evaluations against benchmarks
Integrating Generative Models with Business Rules
Combining generative AI platforms with rule engines creates a hybrid architecture that balances creative language generation and strict compliance. Leading models such as OpenAI ChatGPT, Anthropic Claude, and Meta’s Llama series operate alongside rule engines like Drools, Camunda DMN, and IBM Operational Decision Manager to ensure outputs adhere to corporate policies and regulations.
Mapping Business Logic to Generation
Integration involves:
- Cataloging policies, constraints, and decision criteria (pricing thresholds, confidentiality rules)
- Encoding rules in a decision model notation or rule engine
- Augmenting prompts with rule references (for example, “Ensure recommendations comply with the 15% maximum discount rule.”)
- Validating generated content post-generation and routing violations for correction or review
- Feeding exceptions and feedback back into prompts and rule parameters for continuous refinement
Architectural Patterns
- Sequential orchestration: generate first, then validate and amend
- Inline constraint injection: embed rule logic in prompts
- Parallel validation: run generation and rule checks simultaneously
- Continuous enforcement loop: real-time monitoring and rerouting upon violations
Compliance, Governance, and Prompt Design
- Policy versioning with rule set snapshots
- Immutable audit logs capturing prompt parameters and rule evaluations
- Exception workflows for unrecoverable violations
- Sensitivity tagging to apply specialized rules to financial advice or personal data
- Structured prompts and controlled vocabulary to reduce ambiguity
Operationalization and Scaling
Within an orchestration framework, hybrid workflows are implemented through microservices for inference, rule evaluation, and post-processing. API gateways expose unified endpoints, workflow engines sequence tasks, and monitoring dashboards track compliance violations and performance. Ongoing governance includes automated rule testing, policy change management, model retraining using feedback signals, and performance analytics to guide optimizations.
Recommendation Outputs and Downstream Integration
At the culmination of the decision support workflow, the system emits structured recommendation artifacts that drive execution engines, monitoring dashboards, and human review processes. Ensuring data integrity, traceability, and seamless handoff requires carefully designed payloads, dependency linkages, and integration mechanisms.
Outputs Generated
- Structured Recommendation Payloads: JSON or Protocol Buffers containing recommendationId, timestamp, modelVersion (for example, GPT-4 via OpenAI), confidenceScore, payload, and metadata (ruleVersion, dataSnapshotId, userContextHash)
- Actionable Insight Reports: Narrative briefs and visual summaries delivered as PDF or HTML embeds compatible with Tableau or Power BI, slide decks, or interactive Jupyter notebooks
- Scenario Simulation Outputs: Time-series datasets and decision matrices with scenarioId, parameterVariations, projectedMetrics, and riskIndicators
- Human Review Flags: Queue objects referencing recommendationId, approvalDeadline, and escalationContacts for manual oversight
- API Endpoints and Webhooks: RESTful interfaces and event subscriptions for real-time integration with downstream agents
Key Dependencies and Lineage
- Data Quality and Freshness: Normalized datasets in enterprise lakes or warehouses managed by Databricks, enriched vectors from Hugging Face, and interaction logs
- Model and Rule Lineage: References to generative model artifacts (checkpointHash, trainingSnapshotDate) and invoked rule definitions (ruleSetId, effectiveDate)
- Session Context: sessionId, userProfileAttributes, and priorInteractionHistory stored in a cache or key-value store such as Redis
- External Data References: Source endpoints, retrievalTimestamps, and dataLicenseIdentifiers for market benchmarks or competitive intelligence
Handoff Mechanisms
- Event-Driven Messaging: Publishing recommendationAvailable events via Apache Kafka or AWS EventBridge to RPA services, workflow engines, and monitoring platforms
- RESTful APIs: Exposing endpoints such as /getRecommendation or /acknowledgeRecommendation with HATEOAS links to related resources
- Direct Database Writes: Inserting outputs into relational or NoSQL stores with foreign keys linking back to ingestionId, modelVersion, and ruleSetId
- UI Embedding: Surfacing recommendations in web portals via iFrame widgets or GraphQL-based front-end components
- Human Task Management: Creating approval tasks in ServiceNow or Jira carrying recommendationId, context summaries, and approval artifacts
Traceability and Auditability
- Embedding a traceIdentifier across messages and records
- Recording lineage metadata in a central catalog such as DataHub or Amundsen
- Generating immutable audit logs of state transitions: inputLoaded → modelInvoked → recommendationEmitted → handoffCompleted
- Exporting reconciliation reports that compare recommendation outcomes with execution results
By structuring outputs meticulously, cataloging dependencies, and defining robust integration mechanisms, organizations ensure that AI-driven insights flow seamlessly into execution pipelines and human decision processes. This rigor enhances operational efficiency, governance, and continuous improvement across the enterprise AI ecosystem.
Chapter 9: Monitoring, Compliance, and Governance
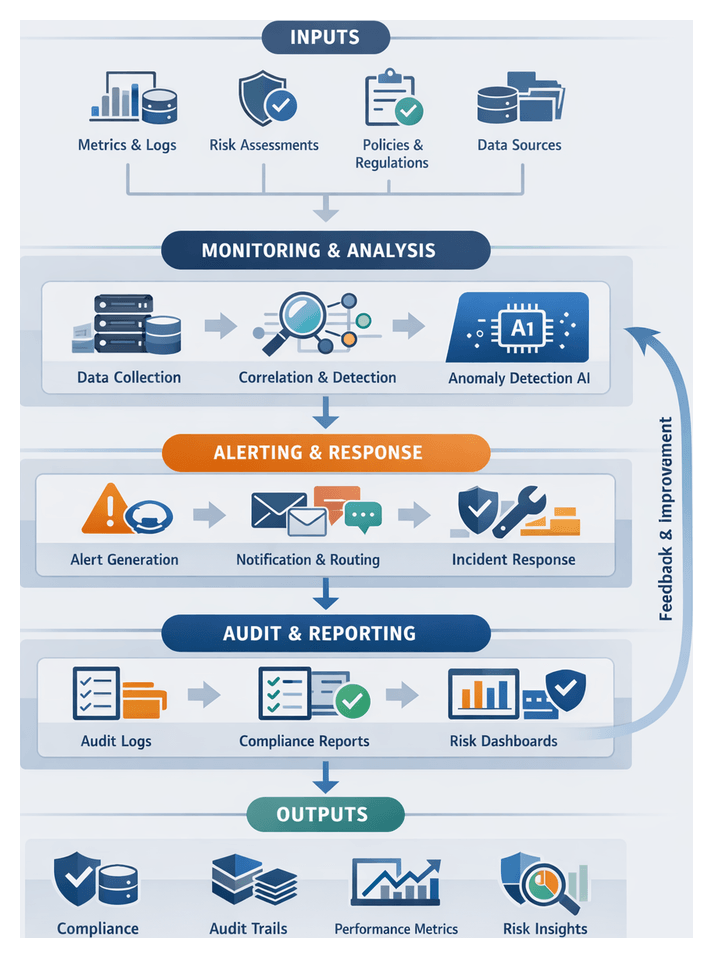
Purpose and Objectives of Monitoring and Compliance
The monitoring and compliance stage establishes a structured framework for tracking performance metrics, enforcing regulatory requirements, and safeguarding system integrity across AI-driven workflows. By defining clear objectives—real-time visibility, anomaly detection, regulatory adherence, and audit readiness—organizations achieve operational resilience, maintain stakeholder trust, and mitigate legal and reputational risks. This stage bridges technical telemetry with governance goals, ensuring AI automations deliver value while remaining fully compliant with standards such as GDPR, HIPAA, ISO/IEC 27001 and industry-specific mandates.
- Proactive Issue Detection: Identify performance degradations, security incidents or data drift before they breach SLAs or impact user experience.
- Regulatory Adherence: Embed compliance checkpoints aligned to legal obligations, reducing fines and enforcement actions.
- Data Integrity and Trust: Maintain tamper-evident logs and audit trails to validate the accuracy and provenance of AI outputs.
- Continuous Improvement: Use quantifiable KPIs to refine models, optimize resource allocations, and enhance orchestration logic.
- Cross-Functional Collaboration: Provide shared dashboards and standardized criteria to development, operations, security and audit teams.
Inputs and Prerequisites for Effective Monitoring
Successful monitoring and compliance depend on comprehensive inputs spanning technical, operational and regulatory domains, as well as foundational conditions that enable reliable governance.
Key Inputs
- Performance Metrics Definitions: Business and technical KPIs for latency, throughput, error rates, resource utilization and user satisfaction, mapped to SLAs and strategic objectives.
- System and Application Logs: Structured and unstructured logs from AI services, orchestration engines, data pipelines and infrastructure components, capturing timestamps, event types and correlation identifiers.
- Regulatory and Policy Documentation: Internal policies, legal requirements and standards governing data privacy, security controls and ethical AI usage.
- SLA and Contractual Obligations: Availability targets, response times and penalty clauses defined with internal or external customers.
- Risk Assessment Reports: Threat modeling, vulnerability scans and impact analyses guiding control selection and monitoring thresholds.
- Data Classification and Sensitivity Labels: Metadata categorizing data assets by confidentiality, integrity and criticality levels.
- User Activity and Access Logs: Audit trails of user interactions, API calls and administrative actions within AI platforms.
- Data Lineage and Provenance Metadata: Records of data flows through ingestion, transformation and decision-making stages.
- Environmental Context: Deployment environments, network topology and third-party integrations influencing threat surfaces and compliance scope.
Foundational Prerequisites
- Instrumentation and Telemetry Infrastructure: Deploy monitoring agents and exporters within AI services, integrating with observability stacks such as Splunk, Datadog, Prometheus and Grafana.
- Centralized Logging and Alerting Pipeline: Unified log aggregation that normalizes events from disparate systems, supports queryable storage and triggers alerts based on thresholds or anomaly-detection models.
- Access Controls and Role-Based Permissions: Apply least-privilege principles across monitoring tools and data stores, defining roles for analysts, security officers and auditors.
- Baseline Metrics and Thresholds: Historical performance data and benchmark studies informing realistic alert thresholds and SLA targets, reviewed periodically.
- Governance Framework and Accountability Model: Document ownership for metric definitions, policy enforcement, incident response and audit remediation, backed by steering committees or councils.
- Regulatory Mapping and Control Catalog: Matrix linking business processes, data classifications and technical controls to specific regulatory requirements.
- Data Quality and Integrity Checks: Automated validation routines in data pipelines to detect corruption, schema mismatches or unauthorized modifications.
- Integration with Incident Response and Ticketing Systems: Connect alerting platforms to ITSM tools for rapid assignment, tracking and resolution of incidents.
- Training and Awareness Programs: Continuous education for development, operations and audit teams on monitoring best practices, tool usage and regulatory obligations.
Audit and Alert Workflow Execution
The audit and alert workflow orchestrates the end-to-end process of event collection, analysis, notification and remediation to ensure real-time oversight and rapid response.
Event Collection and Normalization
Raw telemetry—application logs, transaction records, API access logs and system metrics—is streamed into a central ingest layer using distributed log shippers and message brokers. Data preprocessing pipelines standardize timestamps, identify fields and tag events with metadata. Normalized events are stored in secure time-series databases or data lakes for correlation.
Correlation and Rule Evaluation
Normalized streams feed rule-based engines and machine learning models that identify patterns indicating non-compliance, security anomalies or operational issues. Static rules defined by compliance teams detect repeated login failures or unauthorized exports. Dynamic queries join events across sources, while AI-driven anomaly detection models surface outliers. The orchestration framework schedules evaluations in micro-batches or streams, coordinating hot-swap deployments of updated rule sets.
Anomaly Detection and AI Enrichment
Advanced workflows invoke AI services—for example, unsupervised clustering or NLP classifiers—to enrich events. Enrichment actions include attaching user-risk scores, annotating events with data-sensitivity labels and correlating with threat-intelligence feeds. These asynchronous functions feed back into correlation contexts, with orchestration logic managing timeouts and merging annotations.
Alert Generation and Prioritization
When evaluations cross predefined thresholds, alerts are generated following a schema containing alert ID, timestamp, source, severity and recommended actions. Prioritization algorithms classify alerts by urgency and aggregate related alerts to reduce noise. Business context—customer SLA levels, regulatory risk ratings or asset criticality—drives dynamic ranking and queue adjustments.
Notification and Routing
Alerts reach responders via email, SMS, collaboration platforms such as Slack or Microsoft Teams, and incident management systems like PagerDuty or ServiceNow. Orchestration maps alert types to responder groups, selects channels based on urgency and implements retry and escalation timers to ensure acknowledgment within SLAs.
Audit Logging and Traceability
An immutable audit log captures event ingestion and normalization timestamps, rule and model evaluation results, alert metadata, routing decisions and remediation actions. Logs reside in tamper-resistant storage—often backed by blockchain or WORM storage—enabling forensic analysis and regulatory reporting.
Feedback Loops and Closed-Loop Remediation
After alert resolution, workflows feed remediation details—root cause, corrective actions and time to remediate—back into correlation models. Post-incident reviews update static rules, detection thresholds and enrichment models. Orchestration schedules retraining cycles based on drift metrics and performance evaluations, refining alert accuracy and strengthening compliance posture over time.
Governance Roles and Enforcement Mechanisms
Clear governance roles and automated enforcement mechanisms ensure policy adherence, risk management and ethical standards across AI workflows.
- Chief Data Officer (CDO): Oversees data governance policies, stewardship programs and data quality across AI systems.
- AI Ethics Officer: Defines ethical guidelines, conducts fairness reviews and monitors transparency standards.
- Compliance and Risk Manager: Designs audit frameworks and leads automated compliance checks.
- IT Security Lead: Implements access controls, encryption and secure communications.
- Data Steward: Manages metadata, approves data usage requests and ensures lineage tracking.
- Internal Auditor: Performs independent reviews of workflow logs and documents findings.
System Enforcement Mechanisms
- Policy-as-Code Engines: Enforce access controls, usage limits and data retention rules via declarative definitions.
- Automated Audit Trails: Capture immutable logs of data transformations, model training runs and decision outputs.
- Runtime Guards: Monitor AI agent behavior, blocking unauthorized operations on sensitive data.
- Drift Detection Modules: Analyze model performance and data distributions to trigger retraining.
- Secure Secret Management: Protect API keys and encryption certificates using hardware-backed vaults.
Embedding Enforcement in Orchestration
- Pre-Execution Validation: Check user permissions, data sensitivity labels and regulatory constraints before task initiation.
- Mid-Workflow Compliance Gates: Scan outputs for PII redaction and explainability artifacts before downstream tasks.
- Post-Execution Verification: Audit outcomes, certify log integrity and archive artifacts in governance repositories.
- Dynamic Policy Updates: Hot-load updated policy bundles without full system restarts.
Continuous Audits and Governance Feedback
- Real-Time Alerts: Notify on critical policy failures such as unauthorized data access.
- Scheduled Compliance Scans: Nightly sweeps reconciling system states against policy baselines.
- Governance Reporting: Generate executive summaries and detailed audit logs.
- Remediation Workflows: Open tickets in ITSM or GRC systems to track corrective actions.
Critical Success Factors
- Executive Sponsorship: Senior-leadership support and resource allocation.
- Policy Alignment: Ensure policies support business objectives and regulatory requirements.
- Scalable Architecture: Modular, cloud-native enforcement components.
- Stakeholder Collaboration: Engage data scientists, developers and legal teams early.
- Training and Awareness: Role-based education on governance tools and processes.
- Metrics and KPIs: Track policy violation rates, audit times and remediation effectiveness.
Report Generation and Regulatory Handoff
Detailed reports and structured handoff protocols deliver performance metrics, audit logs, compliance certificates and risk assessments to internal teams and external regulators. Automated workflows streamline preparation, minimize human error and ensure secure distribution.
Key Report Categories
- Operational Performance Reports Generated via Datadog and AWS CloudWatch, delivering metrics on processing times, throughput and error rates.
- Audit Log Summaries Compiled by Splunk and Elastic Stack, exporting searchable indices in CSV or JSON.
- Compliance Certification Reports Automated control testing and certificate generation by ServiceNow GRC and MetricStream.
- Incident and Remediation Reports Detailed accounts of anomalies, root-cause analyses and follow-up actions, formatted for frameworks like PCI-DSS.
- Risk Assessment Dashboards Interactive visuals from Azure Monitor integrated with Power BI for board reviews.
- Data Lineage and Provenance Artifacts Visual maps and logs showing data origin, transformation and consumption for GDPR or SOX evidence.
Dependencies and Data Sources
- Log Aggregation Services: Splunk, Elastic Stack, Datadog Log Management.
- Metric and Telemetry Pipelines: Prometheus, AWS CloudWatch, Azure Monitor.
- Configuration Repositories: Git-based stores and CMDB entries.
- AI Model Monitoring Engines: Drift detectors, performance profilers and bias detection tools.
- Identity and Access Management Logs: Active Directory, Okta and privileged access monitoring.
Report Generation Workflow
- Data Validation: Confirm completeness of all data feeds and pause on discrepancies.
- Template Selection: Choose templates based on audience and regulatory framework.
- Data Aggregation and Calculation: Compute summary statistics and risk scores via SQL or APIs.
- Visualization Embedding: Incorporate charts from Power BI, Grafana or native exporters.
- Metadata Annotation: Append generation timestamp, coverage period and signature hashes.
- Format Rendering: Produce PDF, CSV/Excel and XBRL artifacts.
- Approval Workflow: Route drafts for review and sign-off using ServiceNow GRC or RSA Archer.
- Secure Distribution: Deliver via encrypted channels, secure portals or regulatory filing systems, maintaining audit trails.
Regulatory Handoff Mechanisms
- GRC System Integration: API transfers into MetricStream, ServiceNow GRC and RSA Archer.
- Encrypted Email: Secure attachments via S/MIME or PGP.
- SFTP Uploads: Scheduled transfers to dedicated servers with IP whitelisting.
- Regulatory Portals: Automated connectors for XBRL filing to SEC or FINRA.
- Collaboration Platforms: Secure Microsoft Teams or SharePoint workspaces with conditional access.
Best Practices for Secure Handoffs
- Encryption at Rest and in Transit using AES-256.
- Role-Based Access Control and Segregation of Duties.
- Comprehensive Audit Trails for each generation and distribution action.
- Version Control and Change Management for templates and scripts.
- Automated Retention and Archival aligned with regulatory requirements.
Continuous Improvement and Traceability
Report outputs and handoff workflows integrate with continuous monitoring loops. Feedback from audit teams and regulators triggers updates to monitoring rules, report templates and data pipelines. Lineage metadata records each data point’s origin—ingestion process, preprocessing step or model evaluation—ensuring full traceability. Immutable logs or blockchain-based ledgers prevent tampering and strengthen auditability. This closed-loop framework fosters a culture of transparency, agility and continuous enhancement of compliance and governance capabilities.
Chapter 10: Continuous Learning and Optimization
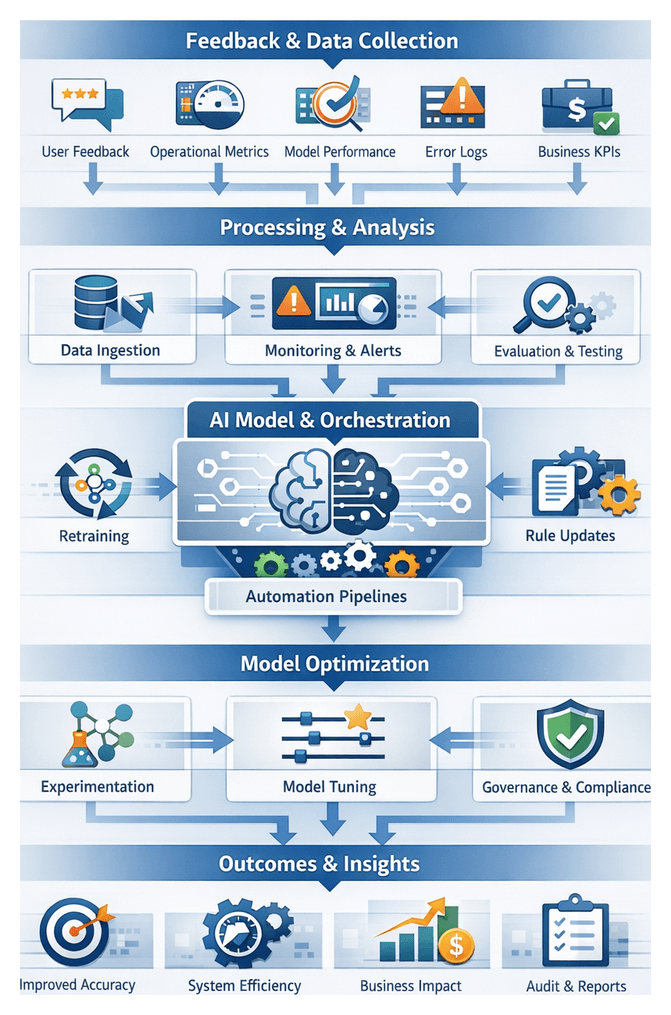
Continuous Feedback and Learning Infrastructure
Purpose and Importance
In dynamic enterprise environments, static AI deployments erode performance over time. A structured feedback collection stage transforms raw operational data—user interactions, performance metrics and error logs—into actionable inputs for ongoing model refinement, rule adjustments and orchestration logic updates. This continuous learning framework aligns AI agents with shifting data distributions, emerging business objectives and evolving compliance requirements, maintaining relevance and user trust while documenting system behavior for audit and governance.
Key Inputs and Collection Mechanisms
- User Feedback
- Explicit ratings and survey responses via in-product widgets or services such as SurveyMonkey.
- Implicit signals—click-throughs, session durations, navigation paths—captured by front-end telemetry.
- Operational Metrics
- Latency, throughput and resource utilization monitored by platforms like Datadog.
- Queue depths, retry rates and failure counts from orchestration engines.
- Model Performance Indicators
- Accuracy, precision, recall, F1 score and ROC metrics tracked via MLflow.
- Prediction confidence distributions and calibration logs in Weights & Biases.
- Error and Exception Logs
- Tracebacks and error codes recorded by Sentry.
- API failure responses, network timeouts and validation rejections.
- Business KPIs
- Conversion rates, revenue impact and customer satisfaction scores.
- Operational costs, error remediation expenses and compliance violation counts.
Prerequisites and Data Flow
- Instrumentation Strategy: Embedded structured logging (Log4j, Serilog) with trace identifiers to correlate events across layers.
- Scalable Pipelines: Message queues or event hubs (for example, Apache Kafka) for high-volume telemetry and near-real-time processing.
- Storage and Retention: Retention policies balancing historical analysis and storage costs; encrypted archives in object stores.
- Governance Controls: Data classification, encryption and access controls to comply with GDPR, CCPA and industry regulations.
- Cross-Functional Alignment: SLAs and agreed metric definitions among data science, development and operations teams.
Integration Points
- Front-End Layer: Capture feedback and engagement signals via UI hooks or telemetry APIs.
- Orchestration Middleware: Log task routing, retries and execution outcomes within engines such as Apache Airflow or Kubeflow Pipelines.
- Model Serving Endpoints: Record inputs, predictions and ground truth labels in inference logs.
- Monitoring Systems: Forward operational metrics and anomaly alerts to central dashboards for real-time oversight.
- Data Lake/Warehouse: Ingest curated telemetry and feedback records into long-term storage for batch analysis and model retraining.
Iterative Optimization Workflow
Defining Cycles and Objectives
Structured optimization cycles—such as two-week sprints or monthly reviews—balance responsiveness with stability. Each cycle specifies key performance metrics (accuracy, throughput, error rates, satisfaction scores), quantitative success criteria, resource allocations and team responsibilities. Integration with an experimentation platform like MLflow automates recording of metrics, hyperparameters and artifacts for each iteration, ensuring reproducibility and clarity.
Feedback Loops and Experimentation
Robust feedback loops drive continuous improvement by funneling production data into hypothesis testing and updates. Sources include user surveys, system logs, business outcomes and A/B test results. Feature stores or data lakes centralize this data, while orchestration via Kubeflow Pipelines handles extraction, transformation and evaluation. Experimentation frameworks such as DataRobot or Dataiku support variant management, metric dashboards and automated rollbacks.
Rule Management and Model Governance
- Versioning: Store rule definitions and policy configurations in Git with clear changelogs and branching strategies.
- Peer Reviews: Implement approval workflows for changes impacting production behavior.
- Simulation: Validate rule updates against historical or synthetic data to detect side effects.
- Dependency Mapping: Document interactions between rule changes, agent outputs and downstream systems to prevent cascading failures.
- Model Management: Coordinate with Amazon SageMaker or Azure Machine Learning to track rule updates alongside model code.
Automation Triggers and Orchestration
- Threshold Alerts: Monitoring systems raise alerts when metrics breach predefined limits, initiating optimization pipelines.
- Scheduled Jobs: Periodic pipelines retrain models on fresh data and evaluate them against baselines.
- Event-Driven Flows: Real-time ingestion pipelines detect drift or anomalies and invoke retraining or rule updates.
- Manual Approvals: High-risk changes pause automation until stakeholder review.
Team Coordination and Scaling
Cross-functional collaboration is essential. Shared dashboards present model performance, experiment outcomes and orchestration logs. Defined communication protocols, role-based access controls and documentation templates ensure efficient handoffs. As optimization matures, modular pipeline design, resource elasticity, dependency management and updated governance frameworks enable scaling across additional use cases and geographies.
Model Retraining and Deployment Orchestration
Drift Detection and Retraining Triggers
Continuous monitoring of input feature distributions and business KPIs signals when retraining is needed. Statistical tests (Kolmogorov-Smirnov, population stability index) and performance alerts guard against prolonged degradation. Tools like TensorFlow Data Validation or pipelines on Pachyderm archive input snapshots and analyze them against reference distributions, triggering retraining only when thresholds are exceeded.
Automated Training Pipelines
- Kubeflow Pipelines: Kubernetes-native orchestration for end-to-end ML workflows.
- MLflow Projects & Model Registry: Experiment tracking, versioning and lifecycle management.
- Apache Airflow: DAG scheduling with rich operator ecosystem.
- Argo Workflows: Container-based pipeline execution with event triggers.
- Prefect: Hybrid cloud orchestration with dynamic task mapping.
These pipelines coordinate data preparation, feature engineering, distributed training (GPU clusters), hyperparameter optimization with Optuna or Ray Tune, and artifact publication to centralized stores.
Model Registry and Version Control
- MLflow Model Registry: Centralizes lineage with stage transitions.
- Amazon SageMaker Model Registry: Managed lifecycle within AWS.
- DataRobot MLOps: Automated retraining, deployment and monitoring.
- Git and GitOps: Infrastructure-as-code for pipelines and environments.
Approval gates enforce quality checks—bias assessments, compliance validations—before model promotion.
Orchestration Logic Updates
- Task Templates: Reference new training images or scripts in job definitions.
- Parameter Propagation: Ensure hyperparameters and feature flags flow through tasks.
- Dependency Graphs: Add validation or feature extraction steps to workflow DAGs.
- Resource Quotas: Adjust compute limits and GPU allocations dynamically.
- Notification Rules: Reroute alerts to reflect updated pipeline contexts.
Conditional routing assigns specialized agents based on artifact metadata and pipeline state.
Validation and Monitoring
- Shadow Testing: Parallel inference with legacy and retrained models on real traffic.
- Canary Analysis: Incremental rollout of new models to production requests.
- Performance Dashboards: Real-time visualization of quality and latency metrics.
- Feedback Integration: Automated capture of misclassifications for next retraining cycle.
- Governance Audits: Logging of fairness metrics and approval annotations.
Automated rollback triggers revert to stable versions if post-deployment metrics breach thresholds.
Elastic Infrastructure and Security
- Auto-scaling GPU clusters and spot instance utilization with graceful fallbacks.
- Node tainting, affinity rules and data locality strategies to optimize performance.
- Cost monitoring and budget alerts tied to retraining schedules.
- Automated container vulnerability scans via Trivy.
- Encryption compliance checks, role-based access controls and audit logging.
CI/CD and Scaling Patterns
- Git-triggered pipelines with schema validation hooks, unit tests and integration tests.
- Deployment pipelines that push container images and perform blue-green rollouts.
- Distributed training strategies—Horovod, federated learning, gradient compression—for large-scale experiments.
- Policy-driven adaptations of scheduling priorities, quotas, retry thresholds and alert levels.
Deployment Artifacts, Interfaces, and Handoff
Model Artifacts and Packages
- Serialized weights and checkpoints with checksums and signatures.
- Data transformation pipelines packaged as Docker images (Docker).
- Inference scripts with REST or gRPC entry points and dependency manifests.
- Evaluation reports summarizing metrics, latency and resource usage.
- Version metadata manifests linking git commits, data snapshot IDs and hyperparameters.
API Specifications and SDKs
- OpenAPI or gRPC definitions for inference, health checks and feedback capture.
- Client SDKs (Java, Python, JavaScript) encapsulating authentication and retry logic.
- Error code catalogs and standardized status responses.
- Authentication and authorization policies securing endpoints.
Infrastructure Configurations
- Kubernetes (Kubernetes) deployment charts and Helm templates for service provisioning and autoscaling.
- Terraform (Terraform) modules or CloudFormation templates for cloud resources.
- Compute profiles defining CPU, GPU or TPU requirements.
- Networking and security group configurations ensuring encrypted, performant communication.
CI/CD Pipelines and Quality Gates
- Jenkins (Jenkins) or GitLab CI (GitLab CI) configurations for code linting, unit and integration tests.
- Argo CD or Spinnaker pipelines for container builds, registry pushes and staged rollouts.
- Automated quality gates for performance regressions, security scans and compliance checks.
Monitoring and Feedback Integration
- Prometheus (Prometheus) configuration for scraping latency, throughput and prediction metrics.
- Grafana (Grafana) alerting policies and anomaly detection.
- Data capture hooks—API endpoints or message queues—for inference logs and context metadata.
- Feedback interfaces for accept/reject signals and error annotations driving retraining datasets.
Traceability and Version Control
- Git tags and semantic releases correlating code changes with retraining runs.
- Data lineage logs tracing datasets through ingestion, transformation and training.
- Registry entries in MLflow or Kubeflow metadata store indexing model versions and metrics.
Scaling Considerations and Operations Handoff
- Horizontal scaling policies based on CPU, GPU utilization or request queue length.
- Vertical scaling guidelines for upgrading node types and memory allocations.
- Multi-region deployment patterns and data synchronization strategies.
- Cost monitoring dashboards for budget forecasting.
- Runbooks, training sessions and scheduled retrospectives for Site Reliability Engineering teams.
- Governance sign-off documents certifying compliance, security and ethical standards prior to full production rollout.
Conclusion
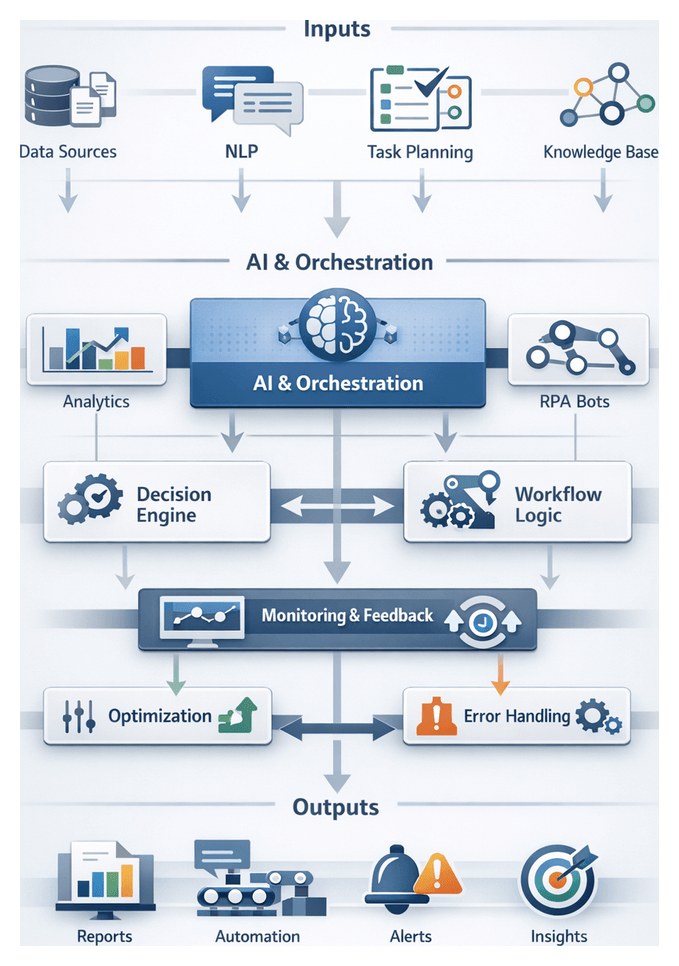
Purpose and Scope
The holistic review synthesizes the components of an AI agent ecosystem—from data ingestion through continuous optimization—into an integrated framework that aligns with enterprise objectives. By mapping end-to-end data flows, decision points, and automation touchpoints, stakeholders obtain visibility into integration maturity, optimization opportunities, and compliance readiness. This purpose-driven analysis confirms that handoffs are seamless, data integrity is maintained, and scalable AI-driven processes support strategic goals. Cross-functional teams—including data engineers, AI specialists, operations leads, and compliance officers—collaborate on a shared blueprint that guides enhancement, governance, and future innovation.
Enterprises operating amid rapid data growth, siloed systems, and stringent regulations benefit from this unified paradigm. By converging machine learning, natural language processing, robotic process automation, and orchestration platforms into a coherent pipeline, organizations in finance, healthcare, manufacturing, and retail achieve timely decisions and auditability. A holistic review ensures each link—from real-time credit risk assessments to automated fraud detections—functions in concert, delivering consistent decision quality and regulatory compliance.
Essential Inputs and Prerequisites
A comprehensive review requires artifacts and conditions that validate the ecosystem’s readiness and performance:
- Data Ingestion Artifacts: Raw and normalized datasets from structured databases, document stores, streaming platforms such as Apache Kafka, and API feeds
- Natural Language Understanding Outputs: Tokenized text, entity recognition, sentiment scores, and intent classifications from engines like OpenAI or spaCy
- Task Planning Records: Goal definitions, metadata annotations, task sequences, and dependency graphs produced by planning engines or custom services
- Orchestration Configurations: Scheduling logic, routing rules, retry policies, and agent capacity profiles
- Execution Logs and Interaction Histories: RPA action logs, API call traces, conversation transcripts, and exception events captured by monitoring tools
- Enriched Knowledge Artifacts: Augmented data from vector databases, knowledge graphs, and external APIs
- Generative Insights and Recommendations: Summaries, forecasts, scenario analyses, and compliance checks synthesized by large language models
- Monitoring Dashboards and Compliance Reports: Performance indicators, audit checkpoints, privacy evaluations, and governance logs
- Feedback and Optimization Data: User ratings, error logs, A/B test outcomes, and retraining triggers for continuous improvement
- Workflow Stage Completion: All stages—from ingestion through optimization—deployed and operational
- Data Quality Baselines: Defined thresholds for accuracy, completeness, and freshness, with monitoring via tools like Prometheus or Elastic Stack
- Unified Logging and Telemetry: Centralized aggregation of agent interactions, orchestration events, and system metrics
- Governance Framework: Policies for data privacy, ethical AI, audit procedures, and regulatory compliance
- Stakeholder Engagement: Alignment among business owners, IT, data science, security officers, and partners
- Performance Benchmarks and SLAs: Agreed targets for latency, throughput, error rates, and availability
- Version Control and Change Management: Reproducible code repositories, model versioning, and deployment pipelines
Integrated Analytical Approach
The review applies a systematic methodology to dissect each orchestration layer and validate end-to-end performance:
- Mapping Data and Control Flows: Visualizing sequences of data movements and decision triggers
- Assessing Integration Touchpoints: Evaluating API contracts, message schemas, and event routing logic
- Validating Agent Interactions: Inspecting logs and transcripts to confirm adherence to business rules
- Measuring Latency and Throughput: Quantifying performance across the full workflow to identify bottlenecks
- Reviewing Compliance and Audit Trails: Ensuring data lineage, access controls, and decision logs meet standards
- Identifying Optimization Opportunities: Analyzing error patterns, underutilized resources, and feedback loops
Operational Efficiency and Reliability
By orchestrating AI agents, RPA tools, and data platforms, enterprises replace manual, error-prone processes with automated, event-driven workflows that deliver significant efficiency gains and error reduction.
Streamlining Workflow Handovers
Event-driven triggers and API-based handoffs eliminate idle wait times. For example, the Google Cloud Natural Language API emits standardized JSON payloads to a planning engine, and Apache Airflow schedules task decomposition immediately. This reduces processing times by up to 60 percent and slashes cycle times for high-volume operations.
Coordinated Agent Interactions
Context preservation is achieved through parallel enrichment and metadata tagging. A query against Pinecone enriches records with semantic context and forwards them to decision support modules and RPA bots. Dynamic routing based on workload and priority prevents context drift and lowers error rates by up to 45 percent.
Automated Error Detection and Correction
Anomaly detection models flag discrepancies in real time, triggering remediation routines. For instance, UiPath bots executing legacy ERP transactions invoke scripts that compare logs to expected outcomes. Exceptions initiate correction flows or escalate to human operators, reducing manual error handling by 70 percent and ensuring traceability.
Unified Data Handoffs
Schema validation and data enrichment guard against incomplete payloads. The orchestration layer enforces required fields—such as customer ID and task priority—retrieving missing values from master databases. Upfront validation prevents 80 percent of execution errors.
Feedback Loops and Continuous Correction
Agents emit metrics and error logs to Splunk, where orchestration rules adjust retry policies, routing priorities, and resource allocations. Adaptive scaling and automated rollbacks enhance resilience and minimize downtime.
Cross-Functional Coordination
Role-based dashboards provide real-time status for business analysts via Microsoft Power BI or Tableau, and service health views in Kubernetes. Shared visibility cuts coordination overhead by 50 percent and decision lag by 30 percent.
Performance Metrics
Key indicators include end-to-end cycle time reduction, manual intervention rate, error rate per thousand transactions, first-time-right completion, and labor cost savings. Case studies demonstrate 40–60 percent faster cycles and 70–80 percent fewer validation errors, with ROI realized in six to nine months.
Strategic Insights and Business Value
AI agent orchestration elevates process outputs into strategic intelligence by aggregating performance metrics, predictive signals, and exception patterns into actionable recommendations.
KPIs and Metric Mapping
Defining KPIs—such as cycle time reduction, cost savings, and customer satisfaction metrics—anchors the framework. RPA-driven invoice processing metrics tie into cost-per-transaction savings, while AI-generated summaries inform marketing decision quality. Integration with reporting platforms ensures real-time visibility.
Quantifying ROI
- Baseline Cost Analysis: Document current process costs and error rates
- Benefit Attribution: Assign monetary value to efficiency gains and revenue uplifts
- Time-to-Value: Estimate how quickly net positive returns are achieved
- Sensitivity Scenarios: Model outcomes under various adoption rates
Predictive Analytics
Advanced forecasting models—trained on data from knowledge graphs and real-time streams—enable scenario planning. Integrated with GPT-4, these forecasts deliver narrative reports that guide proactive strategies, such as inventory redistribution recommendations.
Executive Dashboards
- Role-Based Views: Tailored for executives, managers, and contributors
- Automated Alerts: Threshold-based notifications for critical deviations
- Interactive Exploration: Self-service filtering and annotation
- Narrative Context: AI-generated explanations alongside visualizations
Embedding dashboards in unified platforms ensures a single source of truth and eliminates reliance on ad hoc reports. Organizational alignment—through training and insight councils—fosters data literacy, governance, and accountability.
Framework Adaptation and Reuse
Capturing reusable orchestration patterns accelerates deployments, enforces consistency, and maximizes return on AI investments. A centralized repository of best practices prevents duplicated effort and variability.
- Pattern Library: Architectural blueprints for parallel processing, error handling, and dynamic routing
- Template Workflows: Parameterized definitions for Apache NiFi and Azure Logic Apps
- Component Modules: Reusable microservices for authentication, logging, monitoring, and retry logic
- Configuration Playbooks: Guides for environment settings, security policies, and scaling parameters
- Governance Checklists: Audit-ready mappings of assets to compliance requirements
- Documentation and Training: Manuals, quick-start guides, and interactive tutorials
- Service Contracts: Versioned RESTful or gRPC APIs with clear schemas
- Data Schemas: Standard definitions for JSON, Avro, or Parquet payloads
- Orchestration Platforms: Minimum version requirements for features such as parallel execution—e.g., UiPath Orchestrator
- Security Modules: Libraries for identity management, encryption, and audit logging
- Monitoring Interfaces: Connectors to Prometheus or Splunk with predefined metrics
- CI/CD Pipelines: Jenkins and GitHub Actions scripts and configurations
Handoff and Integration Processes
- Repository Publication: Versioned assets in a centralized platform
- Onboarding Workshops: Guided sessions on customization and integration
- Governance Review: Compliance validation and formal sign-off
- Integration Sprints: Short cycles integrating templates and capturing feedback
- Support Channels: Dedicated communication on Microsoft Teams or Slack
- Continuous Improvement: Periodic reviews of usage metrics and updates
These handoff mechanisms create a sustainable ecosystem where each project benefits from proven solutions, transforming orchestration into a strategic asset that evolves with organizational needs.
Sustaining and Evolving the Ecosystem
Long-term success demands ongoing governance and refinement. Best practices include:
- Regularly updating orchestration rules to reflect business policy changes
- Revising validation schemas to accommodate new data structures
- Auditing exception logs to uncover emerging error patterns
- Enhancing remediation scripts for evolving edge cases
- Conducting continuous improvement workshops with cross-functional teams
By embedding continuous monitoring, feedback loops, and change management, organizations ensure that efficiency gains, reliability, and strategic insights become foundational capabilities that support sustained innovation and competitive advantage.
Appendix
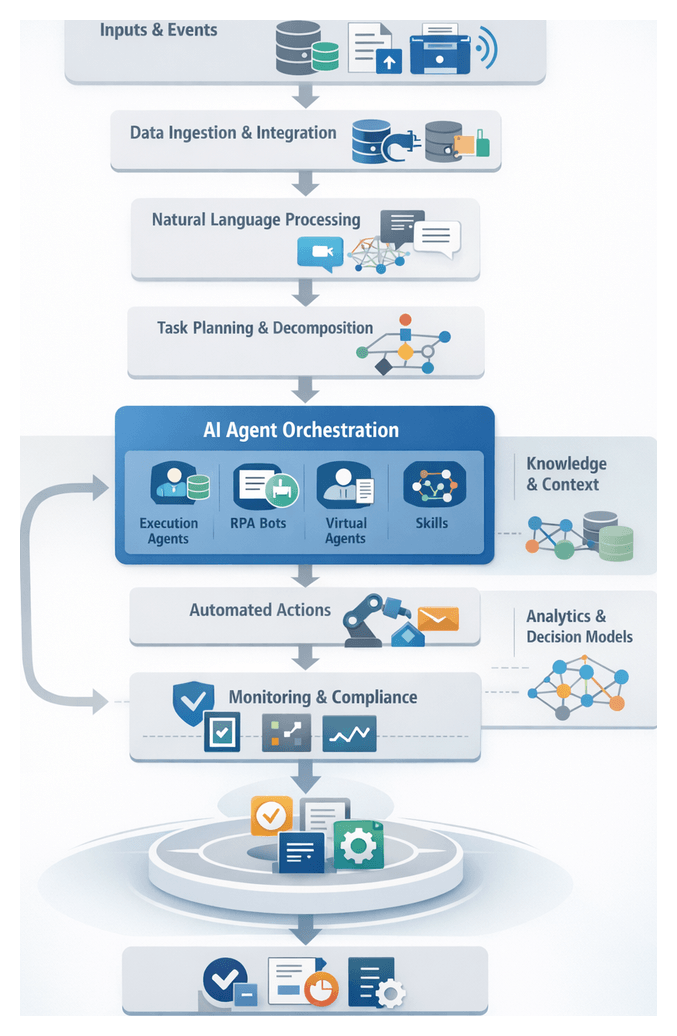
Core Workflow and Orchestration Concepts
Enterprise automation relies on well-defined workflows and orchestration layers to ensure repeatable, auditable and efficient processes. A workflow maps a sequence of tasks, activities and decision points to achieve specific business outcomes, while orchestration provides the automated control plane that schedules tasks, enforces dependencies and handles errors end to end.
- Orchestrator: Schedules workflow definitions, maintains execution state and exposes monitoring interfaces.
- Task: A discrete unit of work—such as data validation, model inference or record update—assigned to agents or services.
- Step: A single operation within a task that may invoke APIs, run scripts or delegate to sub-tasks.
- Dependency: Declared prerequisites between tasks or steps to ensure correct sequencing.
- Data Handoff: Transfer of output artifacts via message queues, API calls or shared storage using standardized schemas.
- End-to-End Workflow: The complete pipeline from event trigger through ingestion, processing, decisioning and action execution.
- Workflow Instance: Each execution of a workflow definition with its own state, context and metadata.
- Event Trigger: Signals—such as new record arrivals or schedule timers—that launch workflow instances.
AI Agents and Execution Components
AI agents extend orchestration by autonomously performing tasks, making decisions and interacting with systems or users. Specialized agents include:
- Execution Agent: Orchestrates process automation, API calls or UI interactions under orchestrator assignments.
- RPA Bot: Emulates human interface interactions with legacy systems, browsers and applications.
- Virtual Agent: A conversational AI component—chatbot or voice assistant—that manages dialogue and routes intents.
- Conversational Agent: Leverages NLU and dialogue management for multi-turn interactions and context handling.
- Action Executor: Performs concrete actions such as sending emails, database updates or payment triggers.
- Skill: A named capability—like “order status lookup”—invoked by agents via the orchestrator.
- Agent Pool: A collection of agent instances for load balancing and scalability.
- Heartbeat: Periodic status messages indicating agent health and availability.
Data Integration and Knowledge Management
Robust AI workflows depend on reliable data integration and contextual knowledge stores. Key components include:
- Data Ingestion: Collecting raw data from structured, semi-structured and unstructured sources using batch, micro-batch or real-time pipelines.
- Data Normalization: Transforming inputs into standardized formats and schemas.
- Metadata Catalog: Central repository for data definitions, lineage, quality metrics and business context.
- Schema Registry: Versioned schema validation service—for example Apache Avro—to enforce compatibility.
- Data Lake: Scalable storage for raw and processed datasets prior to analytical consumption.
- Change Data Capture: Streaming incremental changes from transactional sources to minimize latency.
- API Connector: Reusable integration components that translate external system schemas and authentication.
- Knowledge Graph: Semantic network of entities and relationships for inference and context resolution.
- Vector Database: High-dimensional embedding store—such as Pinecone—for semantic similarity queries.
- Semantic Store: Graph or triple store enabling SPARQL or Cypher queries on linked data.
Natural Language and Decision Support
AI-driven text and speech processing and decisioning are foundational to intelligent automation:
- Natural Language Understanding (NLU): Converts human language into structured data—intents, entities, sentiment.
- Entity Recognition: Identifies and classifies named entities within text.
- Intent Classification: Maps user goals to predefined categories for task routing.
- Sentiment Analysis: Assesses emotional tone to adapt responses or prioritization.
- Generative AI: Produces text, summaries or narratives via large language models like GPT-4.
- Predictive Model: Forecasts outcomes—demand, risk scores—using historical data.
- Task Decomposition: Breaks high-level goals into discrete tasks optimized for parallelism.
- Planning Engine: Sequences and assigns decomposed tasks based on dependencies and SLAs.
- Rule Engine: Applies declarative business rules—such as Drools—to evaluate conditions and drive workflow branches.
Monitoring, Compliance and Governance
Maintaining operational health and regulatory adherence involves:
- Monitoring Metrics: Latency, error rates and resource utilization captured by systems like Prometheus and Grafana.
- Alert: Notifications triggered by threshold breaches or anomaly detection.
- Audit Trail: Chronological record of events, user actions and data transformations.
- Compliance Check: Validation of activities against legal and policy requirements.
- Governance Framework: Organizational roles, policies and oversight for AI and automation initiatives.
- Service Level Agreement (SLA): Contractual performance targets—availability, response times—for services.
- Security Policy: Rules governing data access, encryption and identity verification.
- Role-Based Access Control (RBAC): Restricts operations to authorized roles.
- Drift Detection: Monitors changes in data distributions or model performance.
- Continuous Learning: Feeds production feedback back into training pipelines for iterative improvement.
Mapping AI Functions to Workflow Stages
A clear mapping between AI capabilities and workflow stages guides technology selection, integration planning and governance enforcement. Each stage leverages specialized tools and services to automate tasks and support decision making.
Stage 1: Data Ingestion and Integration
- Schema inference and metadata extraction via Informatica, Talend and Fivetran.
- Event streaming and CDC with Apache Kafka, Amazon Kinesis and Debezium.
- Pipeline orchestration using Apache Airflow, Prefect or Azure Data Factory.
- Serverless ETL with AWS Glue and Google Cloud Dataflow.
Stage 2: Natural Language Understanding and Intent Extraction
- Pre-trained models from Hugging Face Transformers and OpenAI API.
- Managed services like Google Cloud Natural Language and Amazon Comprehend.
- Custom assistants built with Rasa and framework support via LangChain.
Stage 3: Task Decomposition and Workflow Planning
- Graph-based planners and heuristic search engines integrated through Drools.
- Knowledge-driven inference via domain taxonomies registered as orchestrator skills.
- Metadata-driven schedulers that factor SLAs and cost constraints.
Stage 4: Agent Orchestration and Coordination
- Serverless orchestration with AWS Step Functions and Kubernetes-native engines like Argo Workflows.
- Durable microservice coordination via Temporal and modern platforms such as those listed on AgentLinkAI.
Stage 5: Automated Action Execution with RPA Agents
- UI automation and legacy system interaction using UiPath, Automation Anywhere and Blue Prism.
- Intelligent document processing models for form extraction and validation.
Stage 6: Conversational Virtual Agents for User Interaction
- Dialog engines powered by Microsoft Azure Speech Services, Google Cloud Speech-to-Text and Amazon Transcribe.
- Multimodal NLU and response generation with GPT-4 and hybrid templates.
- Escalation workflows integrated with ServiceNow or Jira.
Stage 7: Data Augmentation and Knowledge Management
- Entity linking and graph queries via Neo4j or Amazon Neptune.
- Semantic search embeddings stored in Weaviate, Milvus or Pinecone.
- Reference data enrichment from DBpedia and Wikidata.
Stage 8: Decision Support and Generative AI Insights
- Narrative generation with OpenAI API and time-series forecasting using ARIMA or Prophet.
- Scenario simulation within rule-based frameworks like Drools.
- Feedback integration and model retraining via DataRobot or Dataiku.
Stage 9: Monitoring, Compliance, and Governance
- Observability with Prometheus, Grafana, Elastic Stack and Datadog.
- Alerting and incident management via PagerDuty or Opsgenie.
- Policy-as-code enforcement with Open Policy Agent and secrets management via HashiCorp Vault.
- GRC automation in ServiceNow GRC and MetricStream.
Stage 10: Continuous Learning and Optimization
- Automated retraining pipelines orchestrated by Kubeflow or MLflow.
- Experimentation frameworks and hyperparameter tuning with Optuna or Ray Tune.
- Adaptive orchestration adjustments based on historical performance metrics.
Exceptions and Alternate Flows
Real-world AI workflows must handle data anomalies, system failures and business rule violations through well-defined exception and alternate flow patterns. Embedding exception management into orchestration enhances resilience, transparency and compliance.
Common Exception Patterns
- Data validation failures routed to cleansing modules or quarantine queues.
- Service unavailability triggering retries, circuit breakers or fallback endpoints.
- Low-confidence model outputs escalated to human review or secondary models.
- Business rule violations invoking compensating transactions or rejection paths.
- Timeouts diverting to asynchronous processes or stakeholder notifications.
- Security triggers isolating and masking sensitive data.
Detection and Classification
Exceptions are detected via schema validators, health probes, confidence thresholds, rule evaluators and error code interceptors. Classifying errors as transient, data-related, logic or system faults guides remediation strategies.
Handling Strategies
- Automated Retry with exponential backoff for transient failures.
- Fallback Service Invocation using alternative endpoints or cached data.
- Compensating Transaction to rollback partial side effects.
- Data Quarantine for manual investigation of problematic records.
- Human-in-the-Loop Escalation via case management systems like ServiceNow or Jira.
- Graceful Degradation to provide minimal service when full processing is unavailable.
- Abort and Alert for critical failures requiring immediate operational response.
Automated Recovery Constructs
- Circuit breakers and bulkhead isolation to contain failures.
- Timeout and retry policies configured in orchestration engines.
- Compensation workflows for side-effect neutralization.
Human-in-the-Loop Integration
- Escalation Workflows automatically create review tasks in ServiceNow or Jira.
- Decision Review Interfaces present error context and allow resumption post-resolution.
- Approval Gates enforce manual sign-off for high-risk operations.
Design Principles for Fallback Workflows
- Modularity: Encapsulate alternates as reusable workflow modules.
- Configurability: Expose thresholds and retry parameters as settings.
- Observability: Instrument fallback paths with logs and metrics.
- Auditability: Record decision points and context snapshots.
- Graceful Transitions: Ensure state checkpoints for seamless rollback or continuation.
Coordination and Logging
Exception flows coordinate across microservices via choreography, central orchestration or saga patterns. Structured logs, correlation identifiers and dashboards in Prometheus, Grafana or Elastic Stack provide end-to-end visibility.
Testing and Governance
- Unit and integration tests simulate error codes and downstream faults.
- Chaos engineering validates resilience under controlled failures.
- Compliance audits retain exception logs and verify data privacy safeguards.
- Role-based access restricts manual remediation to authorized personnel.
- Runbooks and training ensure operational readiness for exception scenarios.
AI Tools and Platforms
- Informatica: An enterprise-grade data integration platform providing ETL, data quality, and governance capabilities.
- Talend: An open source and commercial data integration suite supporting batch and real-time pipelines.
- Fivetran: A managed data pipeline service that automates extraction and loading of data from SaaS applications to cloud warehouses.
- Stitch: A cloud-based ETL tool for replicating data from multiple sources into data warehouses with minimal configuration.
- Apache Kafka: A distributed event streaming platform designed for high-throughput, fault-tolerant messaging and real-time data pipelines.
- Amazon Kinesis: A fully managed service for collecting and processing real-time streaming data at scale.
- Debezium: An open source change data capture platform that streams row-level database changes into event logs.
- AWS Database Migration Service: A managed service to migrate and replicate databases with continuous data replication and minimal downtime.
- Azure Data Factory: A cloud-based data integration service for creating ETL and ELT pipelines across on-premises and cloud sources.
- Google Cloud Dataflow: A fully managed service for executing Apache Beam pipelines for batch and streaming data processing.
- AWS Glue: A serverless data integration service that automates data discovery, ETL code generation, and job scheduling.
- Apache Airflow: An open source workflow orchestration tool that defines data pipelines as directed acyclic graphs for scheduling and monitoring.
- Prefect: A modern workflow orchestration platform with dynamic pipelines, resilient state handling, and real-time observability.
- Dagster: A data orchestrator emphasizing type-aware pipelines and integrated asset management for scalable data applications.
- AWS Step Functions: A serverless orchestration service that coordinates AWS Lambda functions and other resources into workflows.
- Temporal: A stateful microservice orchestration engine providing durable execution, retries, and distributed transaction support.
- Argo Workflows: A Kubernetes-native workflow engine for orchestrating highly parallel jobs defined as YAML configurations.
- Apache Atlas: An open source metadata and lineage management tool that tracks data provenance across complex pipelines.
- OpenLineage: A vendor-neutral metadata management standard and API for capturing metadata and data lineage.
- Prometheus: An open source monitoring and alerting toolkit that scrapes metrics from instrumented services and stores them in a time-series database.
- Grafana: A visualization and dashboarding platform for real-time data analysis, often paired with Prometheus or other metric stores.
- Elastic Stack (ELK): A suite of Elasticsearch, Logstash, and Kibana for centralized logging, search, and visualization.
- Splunk: A commercial platform for operational intelligence, indexing machine data, and providing security analytics and monitoring.
- Datadog: A cloud-native monitoring and observability service that collects metrics, logs, and traces across infrastructure and applications.
- Sentry: An open source application monitoring platform for capturing error and exception details across multiple languages and frameworks.
- UiPath: A leading RPA platform that automates repetitive tasks through UI scripting and API integrations.
- Automation Anywhere: A cognitive automation platform enabling RPA bots to interact with applications, data sources, and APIs.
- Blue Prism: An enterprise RPA solution for scalable and secure automation of business processes.
- Rasa: An open source framework for building contextual AI assistants with natural language understanding and dialogue management.
- LangChain: A framework for developing applications powered by large language models and chaining together multiple prompt and output transformations.
- OpenAI API: A suite of endpoints for accessing cutting-edge generative models such as GPT-4 for text, code and data generation.
- Hugging Face Transformers: An open source library providing state-of-the-art pre-trained models and tokenizers for natural language processing tasks.
- Google Cloud Speech-to-Text: A managed service that transcribes audio to text in real time with speaker diarization and confidence scores.
- Amazon Transcribe: A speech recognition service that converts spoken language into text for analysis and search.
- Microsoft Azure Speech Services: An AI service offering speech-to-text, text-to-speech and speaker recognition capabilities.
- Google Cloud Natural Language: A service for entity recognition, sentiment analysis and content classification of text.
- Amazon Comprehend: Natural language processing service for entity detection, sentiment analysis and language detection.
- Apache Jena: A Java framework for building semantic web and linked data applications with RDF and SPARQL support.
- Neo4j: A leading graph database for storing and querying interconnected data via the Cypher query language.
- Amazon Neptune: A fully managed graph database service supporting both property graph and RDF models.
- Pinecone: A managed vector database optimized for semantic search and similarity retrieval at scale.
- Weaviate: An open source vector search engine with built-in knowledge graph capabilities for hybrid semantic retrieval.
- Milvus: A high-performance open source vector database for scalable similarity search.
- DBpedia: A crowd-sourced community effort to extract structured content from Wikimedia projects for use in the semantic web.
- Wikidata: A collaboratively edited knowledge base hosted by the Wikimedia Foundation, structured for semantic applications.
- OpenAI GPT-4: A state-of-the-art large language model capable of advanced reasoning, code generation and content creation.
- Azure Bot Service: A fully managed platform for building, connecting and deploying intelligent bots across multiple channels.
- Salesforce CRM: A leading customer relationship management platform that provides APIs for account and opportunity enrichments.
- SAP APIs: Services exposing enterprise resource planning data such as material masters, vendor ratings and compliance documents.
- Bloomberg Professional: A premium financial data and analytics platform offering APIs for market data, news and risk metrics.
- ServiceNow GRC: A governance, risk and compliance solution that automates control assessments and risk reporting.
- MetricStream: A GRC platform providing policy management, audit management and compliance reporting workflows.
- HashiCorp Vault: A secrets management tool that secures, stores and tightly controls access to tokens, passwords and encryption keys.
- Open Policy Agent: A lightweight, general-purpose policy engine that enforces fine-grained, context-aware access and compliance rules.
- IBM AI Fairness 360: A toolkit for detecting and mitigating bias in machine learning workflows to support ethical AI practices.
- Microsoft Fairlearn: An open source package to assess and improve fairness in AI systems through metrics and mitigation algorithms.
- Jenkins: An open source automation server for continuous integration and delivery pipelines.
- GitLab CI/CD: A built-in continuous integration and deployment toolchain within the GitLab platform.
- Argo CD: A declarative continuous delivery tool for Kubernetes that manages GitOps workflows.
- Spinnaker: An open source CD platform that supports multi-cloud deployments and canary strategies.
- LaunchDarkly: A feature management platform for safe rollouts, A/B testing and feature flag orchestration.
- DataRobot: An enterprise AI platform for automated machine learning, model management and MLOps.
- Dataiku: A collaborative data science platform that unifies ETL, machine learning and deployment at scale.
- ServiceNow ITSM: A service management platform for incident, problem and change management workflows.
- PagerDuty: An incident response platform that centralizes alerts, on-call schedules and escalation policies.
- Opsgenie: A modern incident management solution for routing, escalating and tracking alerts.
- Service Mesh (Istio, Linkerd): Infrastructure layers for securing, observing and controlling communication between microservices.
Additional Context and Resources
- Apache Avro Schema Registry: Helps standardize data formats and enforce compatibility rules.
- HashiCorp Vault Best Practices: Guidelines for secrets management and encryption key rotation.
- OpenAPI Specification: Standard for defining RESTful APIs and service contracts.
- gRPC Documentation: High-performance RPC framework for service communication.
- GDPR Compliance Checklist: Key requirements and technical controls for data subject rights and privacy by design.
- HIPAA Privacy Rule Information: Official guidance on protecting health information in automated systems.
- SOC 2 Trust Services Criteria: Framework for security, availability, and confidentiality controls in service organizations.
- Explainable AI Toolkits: Libraries and frameworks for understanding and interpreting model decisions, including IBM AI Explainability 360 and Microsoft InterpretML.
- DataOps Platforms: Best practices and tools for collaborative data pipeline management, such as Databand.ai and StreamSets.
The AugVation family of websites helps entrepreneurs, professionals, and teams apply AI in practical, real-world ways—through curated tools, proven workflows, and implementation-focused education. Explore the ecosystem below to find the right platform for your goals.
Ecosystem Directory
AugVation — The central hub for AI-enhanced digital products, guides, templates, and implementation toolkits.
Resource Link AI — A curated directory of AI tools, solution workflows, reviews, and practical learning resources.
Agent Link AI — AI agents and intelligent automation: orchestrated workflows, agent frameworks, and operational efficiency systems.
Business Link AI — AI for business strategy and operations: frameworks, use cases, and adoption guidance for leaders.
Content Link AI — AI-powered content creation and SEO: writing, publishing, multimedia, and scalable distribution workflows.
Design Link AI — AI for design and branding: creative tools, visual workflows, UX/UI acceleration, and design automation.
Developer Link AI — AI for builders: dev tools, APIs, frameworks, deployment strategies, and integration best practices.
Marketing Link AI — AI-driven marketing: automation, personalization, analytics, ad optimization, and performance growth.
Productivity Link AI — AI productivity systems: task efficiency, collaboration, knowledge workflows, and smarter daily execution.
Sales Link AI — AI for sales: lead generation, sales intelligence, conversation insights, CRM enhancement, and revenue optimization.
Want the fastest path? Start at AugVation to access the latest resources, then explore the rest of the ecosystem from there.