

Orchestrating Omnichannel Customer Journeys with AI Agents A Practical Workflow for Retail and E Commerce
To download this as a free PDF eBook and explore many others, please visit the AugVation webstore:
Introduction
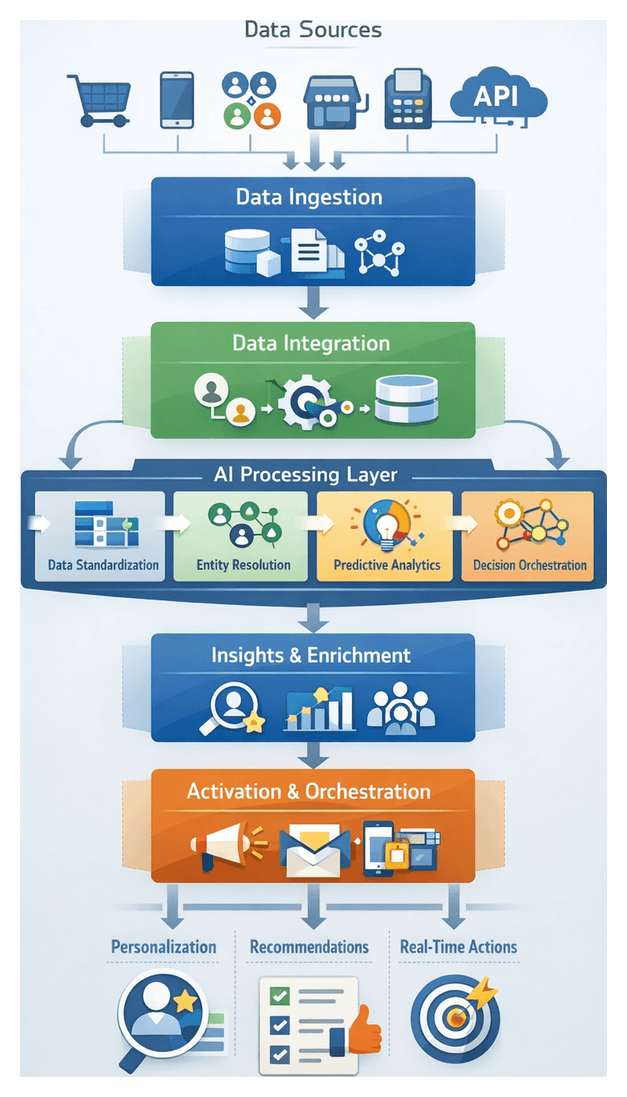
Fragmented Data Landscape in Retail and E-Commerce
Today’s retail and e-commerce ecosystem spans an extensive network of digital and physical touchpoints. Consumers browse product catalogs on web storefronts and mobile apps, engage with brands on social channels, shop through third-party marketplaces, scan items at point-of-sale terminals, and interact with chatbots or call centers. Each interaction generates event data—page views, clicks, transactions, returns, loyalty redemptions, reviews, service requests—captured in disparate systems with proprietary schemas, authentication mechanisms and retention policies. Legacy on-premises databases, cloud-native analytics services, custom applications and partner feeds maintain isolated data silos, leading to inconsistent formats, fragmented customer views and significant blind spots for personalization and attribution.
Without a unified approach to inventorying and ingesting every data source, organizations struggle to assemble a reliable, end-to-end picture of the customer journey. Web events may stream through Apache Kafka or Amazon Kinesis, mobile analytics SDKs batch logs to cloud storage, POS terminals upload daily transaction files, and social media APIs or webhook feeds deliver sentiment and engagement metrics on varying schedules. The absence of a transparent blueprint for source connectivity, schema definitions and quality standards makes it difficult to ensure data completeness, enforce latency requirements or measure extraction SLAs reliably.
Establishing a comprehensive inventory of interaction sources and defining precise ingestion conditions is the essential first step. This foundational work catalogs every channel—web properties, content delivery networks, native mobile apps, in-store POS systems, social platforms such as Facebook and Instagram, partner marketplaces and customer support applications—and describes event schemas, payload structures and authentication credentials. By specifying data quality thresholds for latency, completeness and accuracy, and by agreeing on extraction methods—real-time streaming, batch exports or API polling—teams eliminate hidden blind spots and create a transparent roadmap for downstream normalization, integration and AI-driven enrichment.
Necessity of a Cohesive AI-Driven Workflow Framework
Addressing the complexities of a fragmented data landscape requires a structured, multi-stage workflow that orchestrates ingestion, integration, analysis and activation tasks. Rather than relying on ad hoc scripts or isolated point solutions, a cohesive framework provides end-to-end visibility, governance and error handling across the customer data pipeline. By decomposing the process into interoperable stages, organizations enable transparent handoffs, consistent artifacts and predictable outcomes, reducing operational risk and supporting scalable growth.
Key benefits of a defined workflow framework include:
- Repeatability: Standardized procedures and interfaces guarantee that data flows follow the same path with predictable results.
- Scalability: Modular stages can be parallelized or distributed across processing clusters to accommodate increasing event volumes.
- Resilience: Built-in monitoring, exception handling and retry logic detect anomalies and automatically remediate issues, preventing data loss or corruption.
- Traceability: Metadata capture at each stage preserves lineage—source timestamps, transformation parameters and validation outcomes—supporting audit and compliance requirements.
- Collaboration: Clear delineation of responsibilities across data engineering, analytics, marketing and IT fosters alignment on inputs, outputs and dependencies.
Within this orchestrated framework, AI-driven enhancements can be introduced at precise handoff points. Intelligent agents for extraction, normalization, entity matching, predictive modeling and decision orchestration integrate via standardized connectors, ensuring that downstream services—identity resolution, segmentation engines, journey analytics platforms and campaign orchestrators—receive validated, enriched data on schedule. Solutions exemplify how plug-and-play AI agents can augment existing pipelines without requiring wholesale redesigns.
Integrating AI Agents throughout the Customer Journey
AI agents encapsulate specialized capabilities into modular services that automate critical tasks across the omnichannel workflow. By embedding these agents at strategic points, organizations achieve:
- Scalability: Parallel processing of millions of interactions without manual intervention.
- Consistency: Uniform application of enrichment rules, matching logic and decision policies across all channels.
- Agility: Rapid deployment of new models or business rules through continuous integration and delivery pipelines.
- Insight: Continuous learning loops that refine predictions and recommendations over time.
The principal categories of AI agents include:
Data Extraction and Standardization Agents
- Adaptive connectors supporting REST APIs, message queues such as Apache Kafka, file systems and change-data-capture streams.
- Automated format detection to infer field delimiters and nested structures, reducing manual schema mappings.
- Runtime schema enforcement and validation to flag or reject anomalous records before downstream processing.
Data Enrichment and Semantic Interpretation Agents
- Text analysis and sentiment scoring through Google Cloud Natural Language or AWS Comprehend to extract entities, key phrases and customer sentiment.
- Computer vision models for image and video tagging, identifying products, logos or in-store behaviors.
- Contextual attribute assignment to infer demographics, purchase intent and campaign affiliations.
Predictive Analytics and Next-Best-Action Engines
- Feature engineering pipelines that transform raw and enriched data into model-ready features.
- Model training, hyperparameter tuning and A/B testing on platforms such as Amazon SageMaker or Azure Machine Learning.
- Low-latency inference endpoints delivering churn risk, lifetime value and propensity scores in real time.
Decision Logic and Orchestration Agents
- Rule evaluation engines enforcing deterministic policies—exclusions, budget caps and compliance constraints.
- Dynamic pathing through ML-augmented decision trees that learn from historical outcomes.
- Workflow coordination and task scheduling with platforms like Apache Airflow to guarantee reliability and retry logic.
These agents interoperate via event streams, message buses and API calls, producing enriched event streams and actionable recommendations for personalization and campaign orchestration.
Pillars of the Omnichannel AI Workflow
The unified workflow framework can be conceptualized in four coordinated pillars, each supported by AI agents and integration tools:
1. Data Ingestion and Capture
Ingestion agents collect raw customer events from web SDKs, mobile apps, POS terminals and social APIs. They standardize formats, enrich records with metadata and perform initial validation. High-throughput pipelines using Apache Kafka or cloud equivalents buffer and route data into data lakes or cloud storage, preserving provenance for audit and replay.
2. Data Integration and Harmonization
Integration agents map normalized event batches to a canonical data model. Entity matching services consolidate related records into unified customer and product profiles, while cleansing agents resolve anomalies and impute missing values. Harmonized data is persisted in centralized repositories—data warehouses on platforms such as Snowflake—or customer data platforms for downstream consumption.
3. Insight Generation and Profile Enrichment
Identity resolution agents merge duplicates and reconcile identities across channels. Journey analytics reconstructs time-ordered interaction paths, highlighting milestones and drop-off points. Behavioral clustering and sentiment scoring identify customer segments, while predictive models score profiles for churn risk, lifetime value and next-best actions.
4. Activation and Campaign Orchestration
Personalization engines evaluate real-time triggers—page views, cart updates, loyalty events—and select tailored messages or offers. Orchestration platforms schedule multi-touch campaigns, enforce channel priorities, and route content to delivery systems, including email service providers, push notification gateways and in-store displays. Monitoring agents track performance, update attribution data, and trigger model retraining when drift is detected.
By defining clear interfaces—message schemas, API contracts and storage conventions—this architecture supports incremental enhancements. New channels, AI agents or data sources can be onboarded by adding connector adapters and updating orchestration rules without overhauling the core pipeline.
Chapter 1: Data Ingestion and Channel Capture
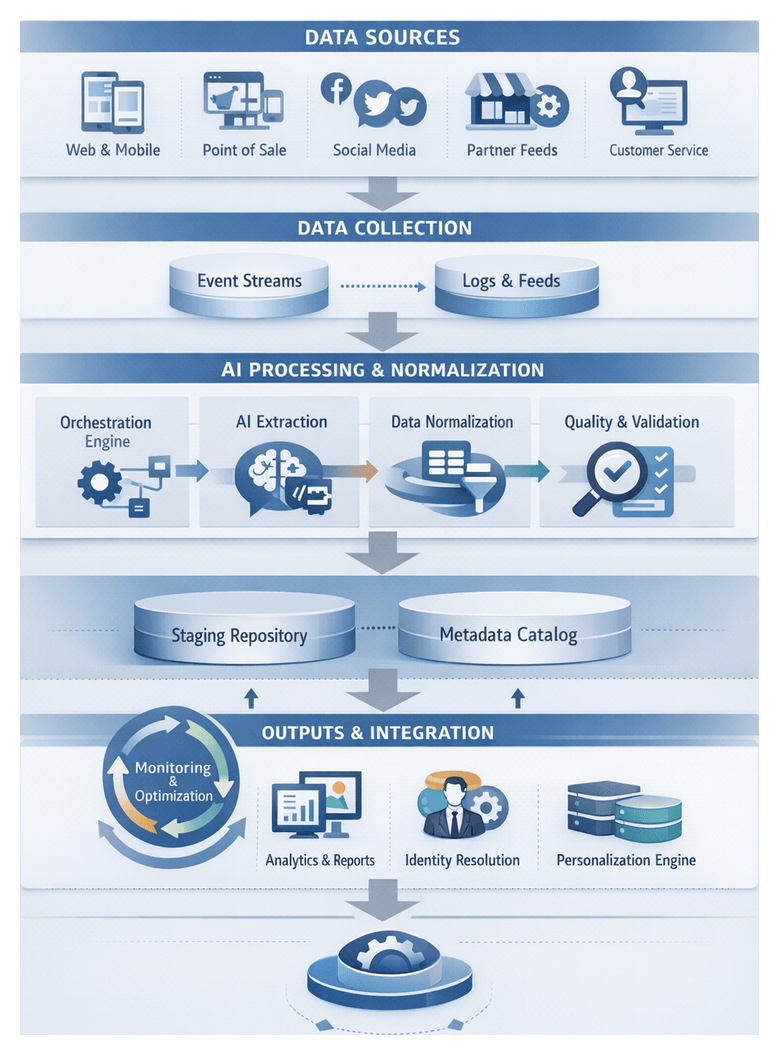
Omnichannel Data Gathering
The foundational step in any omnichannel AI workflow is systematic capture of customer interactions and transactions across web browsers, mobile apps, point-of-sale terminals, social platforms and partner systems. Comprehensive event collection provides a time-stamped repository that serves as the single source of truth for personalization engines, predictive models and analytics. By defining inputs, data contracts and governance structures at this stage, organizations enable unified customer journeys, real-time recommendations, robust attribution analysis and compliance with regulations such as GDPR and CCPA.
Business Context and Importance
- End-to-end visibility: Complete logs from desktop, mobile, in-store and third-party marketplaces support precise journey mapping.
- Personalization at scale: Dynamic content delivery and next-best-action recommendations require fresh, channel-agnostic event streams.
- AI-driven analytics: High-fidelity data inputs minimize bias and improve accuracy in sentiment analysis, forecasting and attribution models.
- Operational efficiency: Automated pipelines reduce manual handling, accelerate time-to-insight and lower error rates.
- Regulatory compliance: Audit trails of every event ensure readiness for data subject requests and regulatory audits.
Key Input Sources
- Web event streams: Clickstreams, page views, form submissions from platforms like Google Analytics and Adobe Experience Platform.
- Mobile application events: In-app actions and session metadata via mobile SDKs for iOS and Android.
- Point-of-sale systems: Transactions, returns and loyalty interactions from retail management software.
- Social interactions: Likes, shares, comments and ad engagement retrieved through Facebook, Instagram, Twitter and LinkedIn APIs.
- Partner feeds: Referral data and marketplace transactions ingested via SFTP, webhooks or API calls.
- IoT and sensors: Proximity beacons, shelf monitors and smart fitting rooms enriching digital records.
- Customer service logs: Chat transcripts, email threads and call center interactions from CRM exports.
Prerequisites and Governance
- Event taxonomy and schema design: A unified model defining event types, attributes and naming conventions that drive instrumentation and downstream logic.
- Instrumentation strategy: Deployment of tracking pixels, SDKs and in-store tags coordinated across marketing, development and analytics teams.
- Privacy and compliance: Consent management, anonymization policies and retention schedules aligned with GDPR, CCPA and PCI DSS requirements.
- Secure ingestion channels: Encrypted pipelines (TLS/HTTPS), VPN or private connections to safeguard data in transit.
- API access and rate management: Valid credentials, token rotation and monitoring to prevent service disruptions.
- Latency requirements: Definition of real-time streams via message brokers like Apache Kafka or Amazon Kinesis, versus batch ingestion schedules.
- Data quality at source: Validation rules, anomaly thresholds and completeness checks to catch errors early.
- AI-enabled connectors: Intelligent agents that detect new sources, adapt to evolving formats and enrich metadata during capture.
Conditional Dependencies and Alignment
- Synchronization windows aligning session identifiers across web and mobile events.
- Time-zone normalization to ensure consistent chronology between digital and in-store logs.
- Referential integrity linking CRM identifiers to anonymous analytics records.
- Graceful handling of missing feeds with fallback values and retry policies.
Cross-Functional Collaboration
- Data engineering configures pipelines, manages infrastructure and enforces security controls.
- Marketing and analytics define event requirements, attribute priorities and measurement objectives.
- IT and security oversee compliance, credential management and network security.
- Business units coordinate with external partners on SLAs, data sharing agreements and change notifications.
Automated Data Extraction and Normalization
Bridging raw event capture and unified integration, this stage uses orchestration engines, source connectors and AI agents to retrieve, parse and standardize heterogeneous records. By automating extraction, classification and schema mapping, organizations reduce custom coding, accelerate deployments and maintain consistent data quality at scale.
Core Workflow Components
- Orchestration Engine: Schedules jobs, enforces dependencies and manages retries using platforms such as Apache Airflow or Azure Data Factory.
- Source Connectors: Prebuilt adapters for web analytics APIs, mobile SDKs, POS databases, social platforms and partner feeds.
- AI Extraction Agents: ML modules that parse semi-structured and unstructured payloads using natural language processing and computer vision.
- Normalization Service: Rules engine for schema mapping, type conversion, timestamp alignment and reference lookups.
- Metadata Catalog: Repository tracking data lineage, schema versions, transformation rules and quality metrics.
- Staging Repository: Transient storage in a data lake or cloud object store holding normalized records before integration.
Connector Invocation Patterns
- Batch Pull: Scheduled extractions via API queries for legacy systems and partner CSV feeds.
- Event Stream: Continuous ingestion through message brokers like Apache Kafka or Amazon Kinesis, supporting at-least-once delivery and offset management.
AI-Driven Parsing and Classification
- Schema Inference Models: Supervised learning to identify field boundaries and flatten nested JSON.
- Natural Language Processing: Entity recognition and sentiment extraction from customer comments and social posts.
- Computer Vision Techniques: Decoding QR scans and shelf monitoring metadata into structured events.
Normalization Logic
- Attribute Mapping: Canonical naming of fields such as txn_id versus transactionId.
- Data Type Conversion: Standardizing numerics, dates to ISO 8601 and boolean flags.
- Reference Enrichment: Lookup tables for regions, product categories and loyalty tiers.
- Currency and Unit Standardization: Base currency conversion and uniform measurement units.
- Timestamp Alignment: Harmonizing time zones and applying ingestion timestamps.
- Anomaly Detection: Flagging outliers such as negative quantities or implausible prices.
Data Lineage and Quality Assurance
- Recording each transformation step, AI model version and connector detail in the metadata catalog.
- Automated quality checks capturing field coverage, null rates and value distributions.
- Quarantine zone for malformed or suspicious records, triggering exception workflows.
- Audit logs documenting errors, warnings and performance metrics for root-cause analysis.
Error Handling and Exception Management
- Quarantine Repository: Secure staging for failed records awaiting triage.
- Automated Alerting: Notifications via email, Slack or Microsoft Teams with sample payloads and error codes.
- Human-in-the-Loop Triage: Engineers update parsing rules or reference data and retry ingestion via API.
- Ticketing Integration: Incident tracking in Jira for resolution and root-cause documentation.
- Feedback Loop: AI agents and rules engines incorporate corrections to prevent recurrence.
Performance and Scalability
- Parallel Processing: Partition by source, event type or time window for concurrent ingestion.
- Auto-Scaling Compute: Containerized microservices on Kubernetes or serverless functions (AWS Lambda, Azure Functions).
- Streaming vs. Micro-Batch: Sub-second windows for latency-sensitive channels, longer intervals for batch feeds.
- Resource Monitoring: Metrics on CPU, memory and I/O integrated with Datadog or Prometheus dashboards.
Security and Compliance
- Authentication and Authorization: OAuth 2.0 or API keys with role-based access control (RBAC).
- Data Encryption: TLS in transit, AES-256 at rest managed by AWS Key Management Service.
- PII Masking: Obfuscation policies aligned with GDPR and CCPA applied during parsing.
- Audit Trails: Immutable logs of access, transformations and configuration changes.
Handoff to Integration
- Message Bus: Publishing normalized events to Kafka or Amazon Kinesis topics for consumption.
- File Drop: Compressed Parquet or Avro files in Amazon S3 or Google Cloud Storage for batch ingestion.
- API Push: Data ingestion into unified repositories such as Snowflake or Azure Synapse Analytics.
- Webhook Notifications: Callbacks signaling data availability with schema metadata and manifests.
AI-Powered Event Formatting and Validation
This quality-gate stage uses AI modules to classify events, detect anomalies and enforce schema integrity. Adaptive, learning-driven systems complement rule-based checks, scaling with evolving sources and reducing manual effort while ensuring clean inputs for identity resolution and predictive modeling.
Event Classification
- Semantic labeling of events like page_view, add_to_cart or coupon_redemption.
- Context enrichment flags for promotion_code, loyalty_member or abandoned_session.
- Model retraining to incorporate new event types from A/B tests or integrations.
- Confidence scoring to trigger fallback logic when certainty is low.
Anomaly Detection
- Threshold-based alerts for metrics such as event volume per minute or latency distributions.
- Clustering algorithms like Isolation Forest or DBSCAN to identify sparse clusters of unusual events.
- Time-series techniques for spikes or drops using seasonal decomposition or z-score evaluation.
- Automated triage creating incidents when critical integrity breaches occur.
Schema Validation and Normalization
- Dynamic schema inference with machine learning proposals for new attributes.
- Type coercion of timestamps, numerics and nested JSON structures.
- Missing data imputation via predictive models leveraging correlated features.
- Normalization of categorical values such as country codes and product identifiers.
Supporting Systems
- Message queues like Kafka or cloud services such as Google Cloud Dataflow.
- Metadata catalogs tracking schema definitions, model versions and validation outcomes.
- Data lakes or warehouses persisting validated and normalized events.
- Monitoring dashboards visualizing error rates, anomaly trends and throughput metrics.
Production Readiness
- Model governance with version control and performance regression tests.
- Observability of throughput, latency and error metrics.
- Graceful degradation to rule-based logic or data buffering on model failures.
- Security controls ensuring validation logs meet compliance standards.
Benefits and Considerations
- Improved data quality through automated error detection and correction.
- Scalability across diverse event types without constant rule updates.
- Adaptability via continuous learning loops for new schemas and anomaly patterns.
- End-to-end transparency with metadata annotations and lineage tracking.
Output Artifacts and Downstream Integration
The final phase of ingestion delivers structured artifacts, clear dependency mappings and automated handoff mechanisms. These outputs form the basis for data integration, identity resolution and analytics orchestration, ensuring reliability, traceability and compliance.
Defined Output Artifacts
- Raw Event Archive: Immutable, time-ordered payloads stored in object storage or a data lake for audit and reprocessing.
- Normalized Records: Schema-conformant events with uniform fields such as customerID, timestamp and eventType.
- Quality and Validation Reports: Summaries of anomalies, schema failures, duplicates and completeness metrics for data owners.
- Lineage Metadata: Provenance records tracing each event to its source, AI model versions and transformation steps.
- Processing Logs: Execution status, resource metrics and error traces captured by orchestration engines and AI agents.
Dependencies and Risk Management
- Source System Availability: SLAs and real-time monitoring of web servers, POS terminals, APIs and partner endpoints.
- Schema Registry: Central repository of canonical definitions fetched at runtime by AI parsers and classifiers.
- Anomaly Detection Services: Operational AI modules tuned to flag outliers and prevent silent data corruption.
- Enrichment Engines: Low-latency lookups against master tables for product, loyalty and promotional metadata.
- Orchestration Framework: Workflow engines that coordinate tasks, manage failure states and enforce execution order.
Automated Handoff Mechanisms
- Landing Zone Transfer: Writing normalized files to a data lake directory or table with notifications via message queues or event buses.
- Streaming Publication: Publishing cleaned event streams to Kafka or cloud streaming services for real-time consumption.
- API Callbacks: Webhooks informing downstream microservices of new batches or streams with metadata payloads.
- Orchestration Signals: Task completion events carrying schema version, processing node and anomaly flags for conditional branching.
- Metadata Catalog Updates: Registration of new datasets, partitions or offsets enabling dynamic discovery by integration pipelines.
Governance, Security and Compliance
- Access Control: RBAC for ingestion outputs, with encryption at rest and in transit.
- Data Masking: Tokenization of PII fields before landing in shared zones, with key management and vaulting.
- Audit Trails: Immutable logs of access, modification and deletion actions for regulatory audits.
- Retention Policies: Automated purging of stale archives and reports according to defined schedules.
Reliability Patterns
- Transactional Writes: Atomic operations to prevent partial writes and enable safe retries without duplication.
- Ready/Failed Markers: Status flags (_SUCCESS, _ERROR) encapsulating summary statistics for downstream decision logic.
- Automated Alerts: Monitoring of volume drops, error spikes and schema drift with escalation workflows.
- Versioned Artifacts: Tagging outputs by timestamp, schema evolution and agent code revision for reproducibility.
- Health Checks: Probes validating connectivity to sources, schema registry and AI modules, pausing ingestion on failure.
Integration with Catalogs and Lineage Tools
- Automated Metadata Ingestion: Catalog connectors retrieving lineage, schema and processing metadata from logs.
- Lineage Visualization: Graph-based tools mapping data flow from raw archives through normalization and validation.
- Impact Analysis: Forecasting downstream effects of schema or model updates to prevent incidents.
- Collaboration: Annotation of artifacts and linkage to issue tickets within the catalog interface for cross-functional alignment.
Best Practices
- Define explicit data contracts for each artifact, including field-level schemas and quality thresholds.
- Implement idempotent, transactional writes to support safe retries and avoid duplicates.
- Automate health checks and alerts to detect upstream issues before they cascade.
- Maintain centralized schema and AI model registries to coordinate parsing, classification and enrichment logic.
- Use metadata catalogs and lineage tools for end-to-end visibility and impact analysis.
- Establish clear governance around access control, data masking and audit logging.
Chapter 2: Data Integration and Harmonization
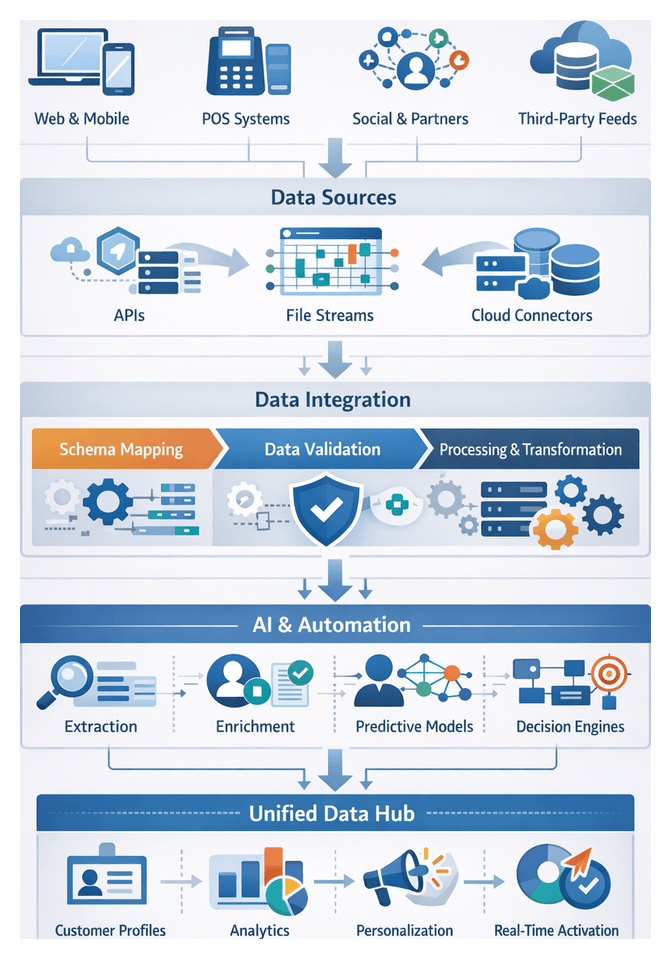
Data Landscape and Intake for Omnichannel AI Workflows
Retail and e-commerce organizations capture customer interactions across web sites, mobile apps, point-of-sale terminals, social media and partner platforms. Each touchpoint emits distinct event streams—clickstream logs, in-app engagement metrics, transactional records, sentiment data and third-party feeds—often in incompatible formats and update cadences. Without a unified intake strategy, these silos undermine personalization, fragment reporting and delay real-time decisioning.
Fragmentation arises from disparate technology stacks—legacy on-premises systems coexisting with cloud-native services—and independent business unit procurements that define asynchronous schemas and governance policies. Data arrives as nested JSON, XML feeds, flat files and proprietary APIs. Channels generate bursty volumes during peak campaigns or seasonal sales, while legacy exports may only refresh daily. Achieving comprehensive capture demands streaming connectors alongside batch pipelines, a central schema registry and automated validation to adapt to evolving definitions.
Core prerequisites for reliable intake include:
- Persistent customer identifiers to unify profiles
- Instrumented event tracking across web, mobile and in-store systems
- APIs or connectors for third-party and partner feeds
- Data governance framework covering ownership, lineage and quality
- Schema registry or catalog to track and version structures
- Security and privacy policies ensuring regulatory compliance
- Scalable infrastructure supporting both streaming and batch modes
- Monitoring and alerting for data latency, throughput and anomalies
Collaboration between IT, data engineering, security and business teams is essential. For example, marketing defines matching rules for persistent identifiers, digital teams manage API credentials for social feeds, and compliance vets data handling standards. Underpinning the intake stage with these technical and organizational conditions lays the foundation for downstream AI-driven processes.
Schema Mapping and Data Harmonization
After intake, the orchestration layer unifies heterogeneous datasets by mapping source models to a canonical schema. Automated metadata ingestion, AI-driven mapping proposals and human validation ensure that every field and entity aligns with master definitions. This coordinated approach enables consistent analytics, identity resolution and personalization.
Metadata Ingestion and Catalog Population
Connectors poll source endpoints—relational databases, data lakes, queues or SaaS APIs—and extract schema definitions, sample records and data type information into a central catalog such as Collibra or Alation. Profiling agents apply statistical and machine learning techniques to infer semantic roles, detect anomalies and classify fields by domain.
- Orchestration via engines like Apache Airflow or AWS Step Functions schedules regular schema refreshes.
- Versioned metadata tracks schema evolution over time.
- Health checks and automated retries ensure connector reliability.
Automated Mapping Rule Generation
AI-assisted engines propose field-to-field correspondences between source schemas and the target model. Semantic matching leverages metadata tags, natural language processing on field names and historical mapping patterns. The system logs confidence scores to determine which mappings auto-approve and which require human review.
- Mapping requests include source metadata, sample values and target definitions.
- Returned candidates specify transformation hints such as unit conversions.
- Low-confidence mappings generate review tasks; high-confidence ones proceed automatically.
Human-in-the-Loop Validation
Ambiguous or critical mappings route to data stewards through governance portals. Tasks include source and target context, sample data and transformation examples. Reviewers accept, adjust or annotate mappings, ensuring edge cases and legacy code sets receive proper handling.
- Review interfaces link directly to the metadata catalog and profiling dashboards.
- Approved mappings are versioned in the canonical mapping repository.
- Escalation rules enforce SLAs and notify stakeholders of overdue tasks.
Transformation Logic Execution
Finalized mappings drive ETL/ELT jobs in engines such as AWS Glue, Talend or cloud warehouses. The orchestration layer sequences transformations, allocates compute resources and enforces dependencies.
- Type casting, unit conversion and value mapping apply at field level.
- Intermediate checks validate schema conformance and data completeness.
- Errors trigger notifications and automated rollbacks per policy.
Entity Relationship Alignment
Post-transformation, workflows consult master data management platforms to reconcile customer, product and order references. Calls to the MDM API resolve foreign keys or generate exception tickets for orphan records. Corrections loop back into transformation jobs to ensure synchronized entity definitions.
Publishing to the Unified Repository
Aligned data loads into the unified customer data repository—whether a cloud data warehouse, lakehouse or CDP. Loading tasks write to production tables or object storage, with final reconciliation checks comparing record counts and key metrics against catalog expectations.
- Loading to platforms like Snowflake may leverage Snowpipe for incremental ingest.
- Post-load validations enforce completeness, uniqueness and statistical baselines.
- Successful loads open datasets for identity resolution, analytics and personalization.
Monitoring and Governance
Dashboards surface job durations, error rates and mapping coverage. Lineage tracking records every field’s journey from source to target, facilitating impact analysis when upstream changes occur. Role-based access controls restrict modifications to mappings and schema definitions, preserving dataset integrity.
Embedding AI Agents in Journey Design
AI agents automate extraction, enrichment, modeling and decision logic within customer journeys. Modular agents—each encapsulating expertise in text analysis, predictive scoring or recommendation—scale horizontally and adapt to new channels without reengineering workflows.
Data Extraction Agents
- Connector Agents: Discover API schemas, generate optimized calls and apply adaptive throttling.
- Parsing Agents: Infer nested JSON or XML structures, normalize records and flag anomalies.
Enrichment and Feature Engineering Agents
- Attribute Agents: Append demographics via third-party signals and assign loyalty tiers with hybrid ML rules.
- Context Agents: Profile devices, infer attribution channels and enrich sessions with contextual metadata.
Predictive Modeling Agents
- Propensity Scoring: Supervised models estimate purchase likelihood and churn risk.
- Value Estimation: Regression and survival analysis forecast customer lifetime value and upsell opportunities.
Next-Best-Action Agents
- Policy Engines: Combine deterministic rules with ML outputs to balance revenue, engagement and compliance.
- Personalization Engines: Rank content with learning-to-rank algorithms and optimize creatives via dynamic A/B testing.
Real-Time Orchestration Agents
- Event stream processors ingest data at sub-second scale and trigger decision pipelines.
- Delivery connectors invoke channel APIs—email, push or in-store—to execute recommendations.
- Resiliency agents detect failures and reroute interactions or initiate retries.
Integration Patterns and Governance
Standard patterns—central orchestrator invocation, event-based choreography and microservice deployments—ensure loose coupling and independent scalability. Model registries, automated monitoring and retraining pipelines maintain performance, detect drift and support compliance audits.
Delivering Harmonized Datasets and Dependencies
The harmonization stage produces consolidated fact and dimension tables, metadata catalogs and change data capture streams that feed identity resolution, enrichment and analytics. Controlled delivery and clear dependency definitions guarantee that downstream stages operate on complete, high-quality data.
Output Artifacts
- Consolidated customer master and event timeline tables
- Reference dimensions for channels, products, geography and time
- Schema registry entries and lineage logs documenting AI-driven transformations
- Delta tables or CDC topics for incremental updates
Upstream Dependencies
- Raw event feeds via secure FTP or Amazon S3, streaming topics from Apache Kafka or Confluent Cloud, and connectors like Fivetran or Stitch
- Schema mapping configurations stored in Git or Databricks Unity Catalog
- Data quality reports from validation agents highlighting exceptions
Delivery Mechanisms
- Batch exports to warehouses such as Snowflake with Snowpipe for CDC
- Streaming publication to Kafka topics with schema enforcement
- RESTful or gRPC data service APIs secured via OAuth
- External tables and materialized views for ad hoc analysis
Handoff to Identity Resolution
- Event-driven triggers or schedules in engines like Apache Airflow or Azure Data Factory launch matching jobs
- Direct reads from shared storage or API retrieval for incremental enrichment
- Schema contracts enforced via registry with backward-compatibility checks
- Automated retries and dead-letter queues for failed records
Audit, Lineage and Compliance
- Lineage captured in governance tools such as Apache Atlas or Collibra
- Immutable audit logs detailing AI-driven actions and change histories
- Role-based access controls, encryption in transit and at rest
- Data anonymization flags and retention schedules enforced via policy engines
Operational Monitoring and SLAs
- End-to-end latency and throughput metrics from raw ingestion to harmonized availability
- Error dashboards alerting on data quality breaches and schema drift
- Defined SLAs for batch windows or streaming freshness, with rollback and escalation paths
By unifying fragmented data, automating schema alignment, embedding AI agents in journey orchestration and delivering harmonized datasets with clear dependencies, organizations establish an end-to-end foundation for real-time personalization, advanced analytics and scalable customer engagement.
Chapter 3: Identity Resolution and Profile Enrichment
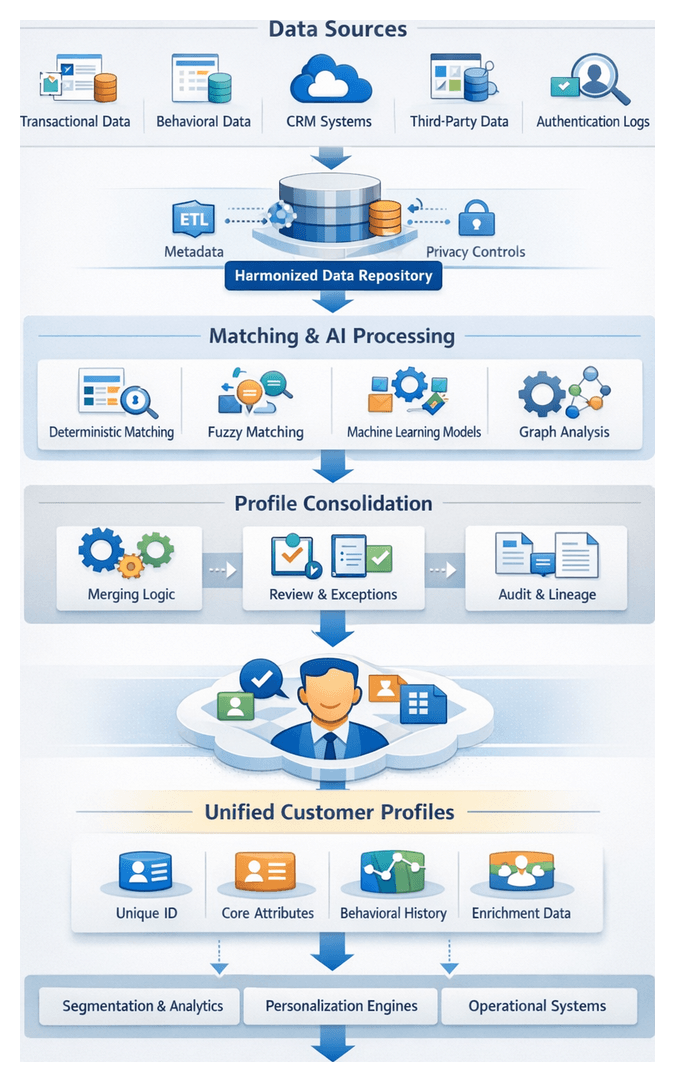
Establishing Single Customer Identities
In omnichannel retail and e-commerce, consumer journeys generate fragmented data across web sessions, mobile apps, in-store transactions, social platforms and third-party enrichments. Establishing single customer identities merges these discrete records into authoritative, persistent profiles. This unified view drives personalized experiences, accurate analytics and efficient campaign orchestration.
Key objectives include:
- Eliminating duplicate profiles and reducing data fragmentation
- Reconciling conflicting attributes such as name variants, addresses and contact details
- Assigning persistent identifiers to support cross-channel recognition
- Enabling precise lifetime value measurement and engagement metrics
- Laying a foundation for segmentation, journey mapping and real-time personalization
By the end of this stage, each customer is represented by a single, enriched profile that supports downstream AI-driven personalization engines.
Data Inputs and Prerequisites
Effective identity resolution requires harmonized input datasets and governance controls. Core prerequisites include:
- Harmonized Data Repository: Event records must be schema-mapped and format-normalized via ETL frameworks.
- Metadata and Lineage Tracking: Records should carry source identifiers, ingestion timestamps and transformation history.
- Consent and Privacy Flags: Customer opt-in statuses must be captured to enforce compliance with GDPR, CCPA and other regulations.
- Reference Tables: Standard lists for countries, currencies, product categories and channel codes ensure attribute alignment.
Common data source categories:
- Transactional Systems: Order databases, payment processors
- Behavioral Logs: Web clickstreams, mobile events, email tracking pixels
- CRM Platforms: Contact records, service tickets, loyalty data
- Third-Party Enrichments: Demographic append services, geolocation feeds
- Authentication Providers: Single sign-on logs, device fingerprints
These inputs feed deterministic and probabilistic matching engines to consolidate records.
Matching Approaches and AI Algorithms
Identity matching combines multiple strategies to balance precision and recall. AI-driven tools and algorithms automate this process at scale.
Deterministic Matching
Exact comparisons on unique identifiers deliver high precision when fields are reliable. Typical rules include exact matches on email, phone number, loyalty ID and hashed keys. Platforms such as Informatica MDM and Microsoft Azure Data Factory embed deterministic rules within ETL pipelines to standardize and compare values.
Probabilistic and Fuzzy Matching
When data contains errors or variations, probabilistic models compute similarity scores across attributes. These models apply functions like Levenshtein distance, Jaro-Winkler and cosine similarity, weighted by attribute reliability. Services evaluate candidate pairs and return confidence scores, routing high-confidence matches to automated merges and lower-confidence cases to review queues.
Supervised Learning Models
Supervised classifiers learn matching patterns from labeled record pairs. Feature engineering captures similarity metrics, contextual signals and behavioral alignment. Training platforms like Amazon SageMaker, Google Cloud AI Platform and Microsoft Azure Machine Learning support model training, validation and deployment. RESTful APIs integrate these models into master data management and customer data platforms.
Unsupervised Clustering Techniques
Clustering algorithms such as DBSCAN and hierarchical clustering group similar records without labeled data. Dimensionality reduction methods like PCA or t-SNE simplify attribute spaces before clustering. Solutions like Databricks Lakehouse enable prototyping and productionizing unsupervised workflows, feeding cluster assignments back to identity resolution engines.
Graph-Based Analysis
Graph analytics represent records and attributes as nodes and edges, uncovering indirect links through community detection and centrality algorithms. Databases like Neo4j and frameworks such as Apache Spark GraphX facilitate scalable graph processing. This approach reveals complex relationships like shared devices or networked behaviors, enriching identity resolution beyond pairwise matching.
Deep Learning and Embeddings
Deep learning models produce dense embeddings that capture latent identity signals. Autoencoders compress attribute sets into compact representations, while Siamese networks train twin encoders to separate matched and non-matched pairs. Frameworks like TensorFlow and PyTorch accelerate training on GPU clusters. Embeddings drive both supervised and unsupervised matching, improving accuracy for sparse or inconsistent identifiers.
Real-Time and Batch Architectures
Identity matching can run in batch mode—through scheduled ETL jobs—or in real time via streaming frameworks. Apache Kafka with Confluent and AWS Kinesis support sub-second resolution, powering fraud detection and live personalization. Hybrid architectures combine batch-generated master indexes with low-latency lookup services exposed via APIs.
Merging Workflows and Ambiguity Resolution
The merging stage consolidates matched records into unified profiles, managing deterministic and probabilistic flows, exceptions and auditability.
Deterministic vs Probabilistic Flows
An orchestration engine—often implemented with AWS Step Functions or Apache Kafka workflows—partitions records based on match strategy. Deterministic sets invoke MDM platforms such as IBM InfoSphere MDM for exact merges. Non-deterministic records pass to probabilistic services, which returns confidence scores and merge recommendations.
Interactive Review and Exception Handling
Ambiguous matches fall into a review console where data stewards compare attributes side by side, view interaction histories and decide on merges, non-matches or enrichment requests. Steward decisions feed back into the match rules repository and retrain probabilistic models. Exception queues capture timeouts, format violations and conflicting directives. Tools such as Google Cloud Dataflow or Databricks streaming jobs manage retries and incident ticket creation.
Data Lineage and Auditability
Every merge action logs record IDs, source tags, match strategy, confidence scores and timestamps into a metadata ledger. This ledger integrates with data catalogs to provide an auditable trail for compliance and analysis. Attributes such as merge rules, steward decisions and service interactions remain traceable back to original events.
Scalability and Performance
High-volume implementations shard records by region or segment, use micro-batches to balance throughput and latency, and auto-scale matching services via container orchestration like Kubernetes. Monitoring tools track queue depths, service latencies and merge success rates. Alerts drive dynamic resource adjustments, preventing backlogs.
Coordination with Enrichment and Analytics
Post-merge profiles trigger enrichment workflows that fetch demographic appends, geolocation lookups and behavioral scores. Unified profiles synchronize with CRM and marketing automation platforms via events or batch exports to secure data lakes. They also populate graph databases for social network and household analysis, enabling downstream journey reconstruction and analytics.
Consolidated Profile Artifacts and Handoff
Upon merge completion, the system produces consolidated profiles containing:
- Unique Customer Identifier linking to the master record
- Core Attributes: Demographics, contact data, account metadata
- Behavioral History: Chronological interaction events and purchase records
- Enrichment Metadata: Third-party appends and inferred preferences
- Confidence and Provenance Scores quantifying attribute reliability and lineage
Dependencies and Data Lineage
Profile integrity depends on:
- Harmonized dataset feeds conforming to unified schemas
- Match rule configurations and threshold settings
- Audit trails from ingestion, transformation and merge stages
- Successful enrichment service calls before profile consolidation
Handoff to Journey Reconstruction
Consolidated profiles publish to customer data platforms such as Segment CDP or Salesforce Customer 360. Journey analytics engines subscribe via message queues or change data capture pipelines to:
- Link profiles with historical touchpoints using the unique identifier
- Augment events with profile attributes—segment membership, loyalty status, risk scores
- Assemble end-to-end timelines for visualization and analysis
Integration with Segmentation and Analytics
Downstream workflows consume profiles through:
- Batch Exports in Parquet or CSV for cohort analysis and model training
- API Endpoints for real-time decisioning and personalization
- Streaming Feeds for near-real-time segment assignment and scoring
This decoupling enables experimentation with new segmentation criteria and ML models without reprocessing raw data.
Synchronization with Operational Systems
Operational applications—CRM, email service providers and marketing platforms—receive incremental profile updates. Key practices include:
- Delta exports to minimize data transfer
- Field mapping rules to align repository attributes with target schemas
- Conflict resolution policies favoring the most recent updates
- Error handling routines that log exceptions and trigger retries
Governance, Monitoring and Feedback Loops
Robust governance ensures profile quality and operational reliability. Essential components:
- Data Quality Dashboards tracking completeness, match rates and confidence distributions
- Alerting on anomalous profile volumes, low-confidence merges or sync failures
- Feedback channels for downstream teams to flag incorrect merges or missing data
- Audit logs of profile creation, updates and exports for compliance and investigation
These controls maintain trust in unified profiles and enable continuous improvement of the identity resolution process.
Chapter 4: Touchpoint Mapping and Journey Reconstruction
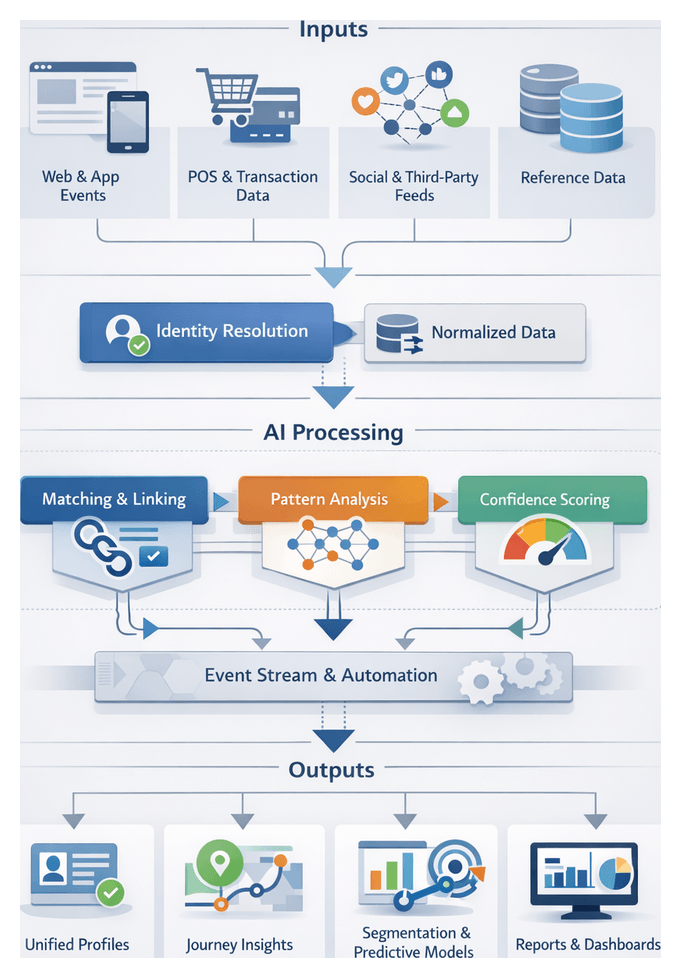
Linking Interactions to Customer Profiles
Establishing a unified view of each customer’s touchpoints across channels is the foundation of a robust omnichannel workflow. Raw event data—web page views, mobile app actions, point-of-sale transactions, social media engagements and third-party feed events—must be systematically associated with resolved identity records. This linking process bridges fragmented event streams and actionable insights, enabling downstream analyses such as journey reconstruction, segmentation and next-best-action modeling.
By correlating behavior across channels, organizations gain the context required to sequence behavior, detect patterns and drive data-informed decision making. A single source of truth for customer history underpins real-time personalization engines and advanced analytics including cohort evolution, channel attribution and drop-off detection. Without precise linkage, event data remains siloed by channel and identifier, preventing a holistic view of the customer experience.
Key Inputs and Data Sources
- Interaction Event Streams:
- Web clickstream logs from Tealium or mParticle
- Mobile app events collected via SDKs (in-app purchases, feature interactions, push engagements)
- Point-of-sale and loyalty program transactions streamed through Fivetran
- Social media data harvested via platform APIs (Facebook, Twitter, Instagram)
- Third-party referral events, affiliate clicks and syndicated content logs
- Resolved Identity Records:
- Unified customer profiles with canonical identifiers, hashed emails and device IDs
- Matching confidence scores and audit trails from deterministic and probabilistic resolution
- Historical merge logs preserving profile lineage for governance
- Reference Data:
- Data dictionaries defining event schemas and attribute semantics
- Metadata catalogs describing source systems, ingestion timestamps and transformation lineage
Prerequisites and Conditions
- Robust Identity Resolution Framework: High-fidelity profiles served by a CDP or data warehouse such as Segment or RudderStack
- Normalized Event Schemas: Standardized field names, timestamp formats and taxonomies enforced by automated agents
- Time Synchronization: NTP-aligned timestamps across systems to prevent ordering anomalies
- Access Controls and Privacy Compliance: Role-based restrictions, GDPR/CCPA adherence and PII pseudonymization
- High-Performance Infrastructure: Scalable compute engines such as Snowflake or Apache Spark clusters to process billions of events
- Monitoring and Alerting: Dashboards tracking link success rates, unmatched volumes and latency with automated alerts for anomalies
Operational Workflow
- Event Partitioning and Pre-Filtering: Batch events by time window or source and remove noise (internal pings, bot traffic)
- Identifier Extraction and Normalization: Extract emails, device IDs and loyalty numbers; lowercase, strip non-numeric characters and apply consistent formatting
- Lookup and Match Execution: Perform deterministic key-value lookups for exact matches; invoke fuzzy matching logic for probabilistic associations
- Confidence Scoring and Thresholding: Compute match scores, automatically link above thresholds and flag gray-zone cases for manual review
- Audit Logging and Lineage Tracking: Record source event ID, profile ID, match method and confidence for governance and model retraining
- Error Handling and Retry Logic: Route unmatched events through retry policies, classify error types and alert engineers as needed
Integrating event streaming platforms like Apache Kafka or Amazon Kinesis with CDPs such as Segment and RudderStack, machine learning services on Amazon SageMaker, data warehouses like Snowflake and Google BigQuery, and orchestration tools such as Apache Airflow or Prefect ensures modularity, scalability and resilience.
Measurement and Quality Metrics
- Link Rate: Percentage of events successfully associated with a profile
- Match Confidence Distribution: Ratio of deterministic to probabilistic matches and score distribution
- Unmatched Event Volume: Count and percentage of events failing to link by type and source
- Latency: Average and percentile processing time per event
- Audit Trail Completeness: Coverage of lineage metadata for compliance and troubleshooting
Regular review of these metrics identifies data quality issues, system bottlenecks and opportunities to refine matching logic.
Sequencing and Visualizing Customer Journeys
With interactions linked to identities, the next step imposes temporal order on events and translates ordered sequences into visual artifacts. This sequencing and visualization stage transforms raw, profile-linked touchpoints into coherent journey paths for business analysts, data scientists and AI engines.
Events emitted by the identity resolution stage—including customer identifiers, timestamps, channel tags and contextual attributes—are published to an event bus such as Apache Kafka or Amazon Kinesis. An orchestration layer then directs records through batching, sorting, sessionization, enrichment and delivery to visualization engines.
Data Flow and System Interactions
- Time Window Batching: Group events into sliding windows to accommodate late arrivals and out-of-order records
- Temporal Sorting: Sort within batches by normalized timestamps, correcting for timezone differences and clock skew
- Sessionization: Define sessions using inactivity thresholds and channel-specific idle rules to identify coherent sequences
- Enrichment: Append AI-driven metadata—intent tags, journey phases and propensity scores—via agents
- Delivery to Visualization Engines: Forward sequences through REST APIs or connectors to platforms like Google Analytics Journey Reports or Microsoft Power BI
Actors and Tools
- Data Engineers: Configure time windows, message queue topics and schema evolution
- Integration Layer: Middleware such as Adobe Experience Platform to route messages and enforce transformations
- AI Agents: Stateless microservices for intent classification and anomaly tagging
- Stream Processing Engines: Apache Flink or Tableau Prep Conductor for high-volume temporal operations
- Visualization Platforms: Journey mapping in Google Analytics Journey Reports, Microsoft Power BI and Apache Superset for exploratory analysis
- Business Analysts: Validate journeys, identify drop-off points and annotate with business context
Standardized Data Models
- EventRecord: Fields for customerId, eventTimestamp, channel, eventType, attributes and sessionId
- SessionWindow: Represents contiguous EventRecords with sessionStart, sessionEnd and inactivityThreshold
- JourneyPath: Aggregates multiple SessionWindows annotated with journeyPhase and segmentTags
- VisualizationFrame: Converts JourneyPath into nodes and edges with metrics like timeOnStep, transitionProbability and dropOffRate
These models are defined with Avro or protocol buffers to enforce type safety and version control. Schema registries validate incoming records to prevent structural drift.
Visualization Pipeline
- Data Extraction: Pull JourneyPath records from the data lake or operational store via batch jobs or real-time connectors
- Aggregation: Compute temporal metrics such as average time per touchpoint, transition frequencies and loop patterns
- Chart Generation: Produce Sankey diagrams, sequence plots and heatmaps to surface flow volumes and concentration of activity
- Dashboard Assembly: Combine visual elements with filters for channel, cohort and recency in self-service portals
- Publication: Embed dashboards within campaign orchestration consoles or BI platforms for on-demand access
Organizations often employ a mix of open source and commercial tools. Apache Superset supports exploratory work, while Tableau and Power BI serve enterprise reporting. Real-time dashboards leverage WebSocket connectors for near-zero latency updates.
Coordination and Governance
- Schema Evolution Management: Change control for EventRecord and JourneyPath definitions
- Data Quality Monitoring: Checks for missing timestamps, duplicates and sessionization errors with automated alerts
- Access Control: Role-based permissions to safeguard sensitive data in visualization tools
- Performance Tuning: Continuous measurement of pipeline latency and rendering times
- Documentation and Training: Runbooks, data dictionaries and workshops to align business and technical teams
Sequencing and visualization deliver end-to-end transparency into customer journeys, accelerate insight cycles from days to minutes and foster cross-functional alignment. Interactive journey maps inform A/B tests, UI improvements and AI model retraining by highlighting friction points and emerging patterns.
AI-Driven Path Reconstruction
While sequencing orders touchpoints, AI-driven path reconstruction uncovers hidden loops and infers missing steps in customer journeys. Advanced algorithms process high-volume event streams to generate complete journey narratives, enabling end-to-end visibility into behavior patterns that inform predictive analytics and personalization engines.
Core AI Techniques
Probabilistic Sequence Models
- Hidden Markov Models (HMMs) and Markov Decision Processes (MDPs) infer hidden states such as engagement intent or purchase readiness
- Expectation-maximization trains transition and emission probabilities on historical sequences
- Viterbi decoding reconstructs the most likely state sequence for each journey
Graph-Based Journey Analysis
- Graph databases like Neo4j or Amazon Neptune model events as nodes and transitions as edges
- Edge weights capture transition frequency, time lag or revenue value
- PageRank and modularity algorithms identify influential touchpoints and journey clusters
Deep Learning Approaches
- Recurrent neural networks (RNNs), LSTM and transformer architectures learn complex temporal dependencies
- Attention mechanisms assign dynamic importance to touchpoints based on context
- Embedding layers convert high-cardinality attributes (product IDs, campaign codes) into dense vectors
Anomaly and Pattern Detection
- Autoencoders learn compressed representations of normal journeys and flag high-error sequences as anomalies
- Density-based clustering (DBSCAN) groups rare paths, revealing niche behaviors or data issues
- Statistical process control monitors key transition metrics for sudden shifts
Supporting Systems and Infrastructure
- Event Ingestion: Apache Kafka for ordered delivery of interaction logs
- Storage: Time-series databases and data lakes for raw event persistence
- Compute: Apache Spark and serverless platforms for distributed training and inference
- Model Serving: Container orchestration systems deploy low-latency inference microservices
- Graph and Feature Stores: Persist precomputed journey graphs and feature vectors for reuse
- Orchestration Engines: Apache Airflow or Prefect schedule retraining, inference calls and data synchronization
- Monitoring: Dashboards for pipeline health, model performance and data quality alerts
Operational Considerations
- Data Consistency and Lineage: Synchronize profile updates to reconstruction pipelines with metadata tracking for reproducibility
- Latency and Throughput: Employ edge inference, model caching and event partitioning to meet sub-second requirements
- Resilience and Error Handling: Implement retry logic, dead-letter queues and fallback sequencing rules to maintain continuity
- Scalability and Continuous Improvement: Use CI/CD pipelines for automated retraining, feature integration and zero-downtime deployments
By integrating probabilistic models, graph analytics and deep learning with scalable data platforms and orchestration layers, organizations transform fragmented logs into coherent path reconstructions. These narratives uncover high-impact touchpoints, feed predictive and personalization modules and support real-time responses to emerging trends.
Journey Map Outputs and Analysis Handoffs
The final stage produces structured artifacts that serve as the input for segmentation, predictive analytics, personalization orchestration and optimization dashboards. Clear output schemas, dependency tracking and robust handoff protocols ensure that journey insights flow seamlessly into downstream processes.
Core Output Artifacts
- Journey Sequence Dataset: Chronologically ordered events enriched with profile references, campaign IDs, engagement outcomes and sentiment flags in JSON Lines or Apache Parquet
- Visual Journey Map Models: Graph representations with nodes and weighted edges exported as Vega-Lite specifications, Cytoscape JSON or SVG
- Drop-Off and Engagement Heatmaps: Aggregated matrices highlighting abandonment points and channel transitions delivered as CSV or dashboard tables
- Engagement Loop Reports: Recurring behavior patterns with counts and average durations to inform churn prediction and re-engagement strategies
- Metadata and Lineage Catalog: Registry of source identifiers, schema versions, transformation references and execution timestamps for auditability
Key Dependencies
- Identity Resolution Outputs: Accurate profiles from Segment or RudderStack
- Unified Schema Definitions: Centralized repository for event and profile schemas
- Time Synchronization Services: NTP-synchronized servers and latency monitoring
- AI Model Artifacts: Versioned predictive and pattern-detection models
- Execution Orchestration Engine: Platforms like Apache to schedule and trigger handoffs
Handoff Mechanisms
- API Endpoints: RESTful or gRPC interfaces with OpenAPI-defined payloads for on-demand retrieval
- Message Queues and Event Streams: Kafka topics or cloud pub/sub channels broadcasting notifications of new artifacts
- Scheduled Data Exports: Bulk exports to Amazon S3, Google BigQuery or Snowflake with versioned file naming
- Shared Metadata Store: Central catalog services like Apache Atlas for asset discovery and validation
Each channel enforces access controls, encryption in transit and at rest, and schema validation to prevent downstream failures. Monitoring tracks deliverable latency, file integrity checksums and API response times, ensuring prompt escalation of any disruptions.
Integration with Downstream Modules
- Segmentation and Cohort Analysis: Dynamic clustering based on path similarity, time-to-conversion metrics and channel preferences
- Predictive Modeling: Next-best-action and churn-risk models trained on loop patterns and drop-off attributes
- Personalization Orchestration: Real-time decision engines triggering contextual messages based on journey state indicators
- Optimization Dashboards: BI teams visualizing heatmaps and loop frequencies to prioritize A/B tests and UX improvements
By codifying artifacts, dependencies and handoff protocols, retail and e-commerce organizations create a repeatable link between customer behavior insights and activation platforms. This rigor accelerates time-to-value and enables continuous optimization of the omnichannel experience.
Chapter 5: Segmentation and Cohort Analysis
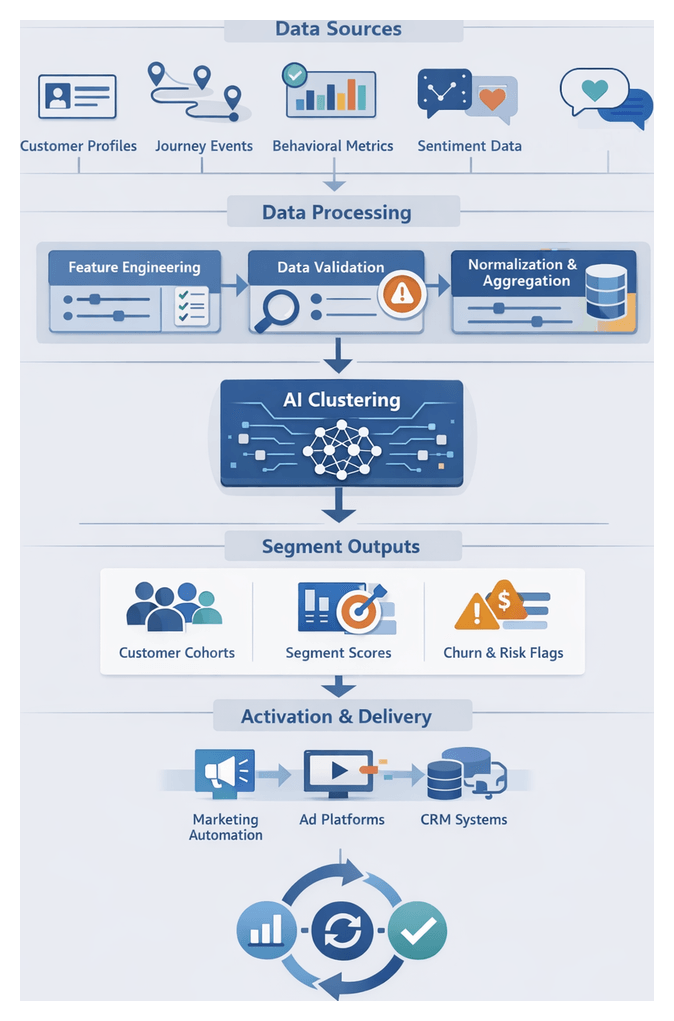
Purpose and Strategic Value of Behavior-Based Segmentation
In omnichannel retail and e-commerce, segmenting customer behaviors transforms raw interaction data into actionable insights. By grouping customers based on purchase patterns, engagement frequency, lifetime value and sentiment signals, organizations tailor messaging, optimize media spend and deliver experiences that resonate. Behavior-based segmentation replaces one-size-fits-all approaches, reducing wasted spend, increasing conversion rates and deepening loyalty.
- Targeted messaging and personalized content for specific cohorts
- Optimized channel budgets by focusing on high-value segments
- Precise measurement via cohort-level attribution and performance tracking
- Cross-functional alignment around a unified customer taxonomy
Operational benefits include improved return on ad spend through resource allocation by segment potential, faster multi-touch attribution analysis and agility in campaign decisions. Focusing on behavioral patterns also supports privacy compliance by avoiding sensitive attributes and underpins data governance through clear rules and quality thresholds.
Prerequisites for effective segmentation include:
- Consolidated Customer Profiles with persistent identifiers, demographic attributes and enriched data such as loyalty tier and predicted lifetime value.
- Sequenced Journey Data capturing ordered touchpoint records with timestamps, channel identifiers and session metrics.
- Behavioral Metrics including RFM parameters, browsing history, product affinities, abandoned carts and churn indicators.
- Sentiment and Qualitative Insights from behavioral and sentiment analysis providing intent tags and feedback summaries.
- Data Quality and Governance Metrics such as completeness scores, anomaly flags and lineage records with at least 95% coverage.
- Business Taxonomy and Rules defining lifecycle stages (new, active, at-risk, churned) and value tiers (high, mid, low).
- Technical Environment with scalable compute, storage and integration to AI clustering services like AWS SageMaker and Google Cloud AI Platform.
- Stakeholder Alignment on segmentation objectives, KPIs and governance processes across marketing, analytics and IT teams.
Segmentation Workflow and AI-Driven Clustering
The segmentation and cohort identification workflow orchestrates the transformation of unified profiles and journey data into meaningful customer groups. It leverages event streams, feature stores, AI clustering services and orchestration engines to keep segments current, relevant and ready for activation.
Data Streams and Orchestration
Key input sources include harmonized profiles in Snowflake, event sequences from Segment or Tealium, behavioral scores from Google Cloud AI Platform or Azure Machine Learning, and transactional data from ERP or CRM systems. Triggers may be scheduled intervals, data-readiness events or manual initiation. The orchestrator—using tools like Amazon SageMaker Pipelines or Apache Airflow—validates dependencies, allocates resources on clusters such as Databricks running Apache Spark, executes data preparation scripts and ensures end-to-end traceability.
Feature Engineering and Data Preparation
Data scientists and engineers define features including recency, frequency, monetary value, product affinity scores, channel engagement ratios and sentiment indices. The workflow involves:
- Joining journey and profile tables to enrich customer records
- Aggregating session metrics and time-windowed interactions in Apache Spark or SQL engines
- Normalizing and scaling features (z-score, min-max) for comparability
- Computing derived attributes such as lifetime value predictions using Amazon SageMaker
- Persisting engineered features to a feature store or staging tables
Data validation routines check for missing values, outliers and schema drift. Anomalies trigger exception paths for manual review or AI-based imputation via services like H2O.ai.
Clustering Algorithm Selection and Execution
Algorithm choice depends on dataset size, dimensionality and interpretability needs. Common options include:
- K-means and MiniBatch K-means via scikit-learn or Spark MLlib
- Density-based methods (DBSCAN, OPTICS) in scikit-learn for noise handling
- Hierarchical clustering in H2O.ai or Databricks for nested cohort structures
- Gaussian Mixture Models for soft assignments
- Self-organizing maps or spectral clustering for nonlinear relationships
Configuration parameters (cluster count, distance metrics, convergence thresholds) are managed in a versioned repository. Parameter tuning via grid search or Bayesian optimization may run asynchronously before production execution on Azure Machine Learning or similar platforms.
Model Monitoring, Validation and Quality Assurance
During execution, progress logs and metrics stream to dashboards such as Looker. Key indicators include silhouette scores, Davies-Bouldin index and inertia. Alerts trigger if metrics fall below SLAs, enabling rollbacks or hyperparameter re-tuning. Post-clustering, analysts and stakeholders review segment profiles in interactive notebooks or BI tools, compare against historical cohorts, conduct A/B tests, and apply business rules to merge or split clusters. Approved definitions are captured and versioned before activation.
Integration with Activation Systems
Final segments are published through APIs or batch exports to downstream systems:
- CDPs such as Segment Personas, Tealium or mParticle for real-time personalization
- Marketing automation platforms—Marketo, HubSpot, Salesforce Marketing Cloud—for email, SMS and push campaigns
- Ad platforms and social engines importing look-alike audiences derived from high-value segments
- Analytics suites updating dashboards with segment distributions and performance metrics
Secure data exchange protocols and audit logs ensure traceability of segment lineage and usage.
AI Contributions and Advanced Techniques
AI accelerates segmentation at every stage, from automated feature generation to dynamic clustering and real-time inference. A cohesive ecosystem of services, frameworks and orchestration platforms delivers precision and scalability.
Automated Feature Engineering and Data Quality
- Apache Airflow and Prefect orchestrate ETL pipelines that extract recency, frequency, monetary values and sentiment scores
- Databricks AutoML modules suggest optimal feature transformations and interactions
- H2O.ai Data Quality Monitor applies anomaly detection to flag outliers before clustering
- Feature store integration ensures consistent definitions across training and real-time inference
Advanced Clustering and Dynamic Segmentation
- Autoencoder-based embeddings in Amazon SageMaker or Microsoft Azure Machine Learning uncover nonlinear relationships
- Graph-based community detection with Amazon Neptune or Neo4j detects referral and co-purchase networks
- Online and incremental clustering on Apache Flink or AWS Kinesis Data Analytics updates segments in real time
Real-Time Inference Engines
- RESTful endpoints on Google Cloud AI Platform and Amazon SageMaker serve pre-trained models with millisecond latency
- Message buses like Kafka, AWS SNS and Azure Event Hubs distribute segmentation decisions for immediate personalization
- Embedding lightweight models in mobile apps or edge devices ensures offline segment evaluation
Monitoring, Governance and Workflow Automation
- Segment performance dashboards in Tableau and Power BI track size, stability and response rates
- Drift detection via Neptune AI and Fiddler triggers retraining workflows when boundaries no longer align
- Data catalogs such as Collibra and Alation record lineage of features and model versions
- Orchestration platforms (Apache Airflow, Prefect) and Infrastructure as Code tools (Terraform, CloudFormation) automate end-to-end pipelines
Segment Catalog and Campaign Handoff
The segment catalog consolidates defined cohorts, metadata and technical artifacts for downstream consumption. Key deliverables include:
- Segment Definitions: Human-readable names, logical criteria and business context
- Cohort Metadata: Creation date, model version, source datasets and stability scores
- Performance Baselines: Historical conversion rates, average order value, churn rates and engagement benchmarks
- Data Payload Schemas: API contracts for batch exports and real-time ingestion
- Membership Lists: Customer IDs mapped to segment IDs in tabular or JSON formats
Dependencies and Infrastructure
- Unified profiles and journey data enriched with behavioral and sentiment insights
- Storage in platforms like Google BigQuery or Adobe Experience Platform
- Orchestration frameworks such as Apache Airflow or Azure Data Factory managing refresh cadences
Handoff Mechanisms
- Batch exports to tables or object storage for platforms like Salesforce Marketing Cloud and Adobe Campaign
- API-based delivery to personalization engines such as Segment
- Streaming via Kafka or AWS Kinesis for instant campaign triggers
- Direct database synchronization through integration connectors
- Artifact versioning in a centralized registry for traceable deployments and rollback
Campaign Integration Considerations
- Trigger Configuration: Campaigns initiate based on segment membership changes
- Rule Mapping: Segment IDs map to email templates, push messages and in-app experiences
- Channel Prioritization: Sequenced outreach based on segment preferences and historical responses
- Personalization Tokenization: Dynamic content tokens populated with segment attributes
- Monitoring Hooks: Tracking parameters capture engagement by segment for analytics feedback
Feedback and Continuous Improvement
- Outcome Attribution: Linking campaign results to originating segments
- Model Retraining Triggers: Underperforming segments or behavior shifts initiate retraining on Google Cloud AI Platform
- Segment Health Dashboards: Stability scores, overlap metrics and growth rates guide merges or splits
- Governance and Compliance: Audit logs record segment creation, modification and deployment activities
Best Practices for Catalog Management
- Define clear naming conventions and versioning protocols for traceability
- Document business rationale, inclusion criteria and performance benchmarks for each segment
- Automate quality checks on membership counts and distribution anomalies prior to handoff
- Enforce role-based access controls to protect segment definitions and sensitive data
- Regularly review performance and adjust refresh cadences to balance agility and stability
Chapter 6: Behavioral and Sentiment Analysis
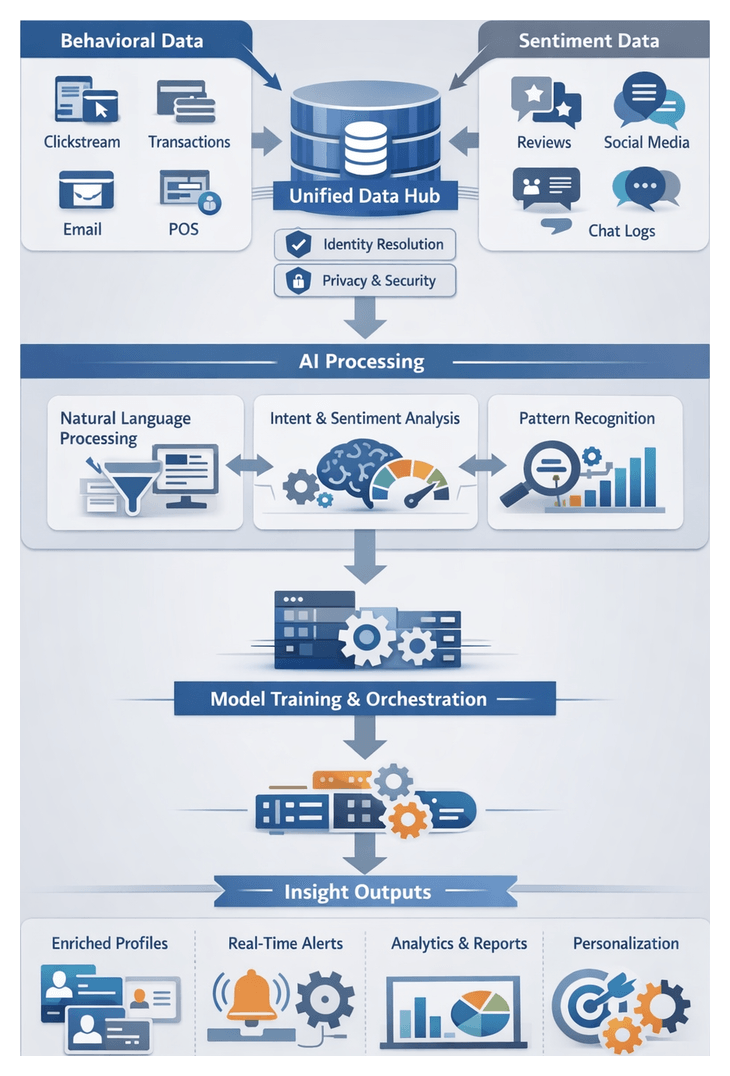
Ingesting and Preparing Behavioral and Sentiment Data
The initial phase integrates quantitative interaction metrics with qualitative feedback to create a unified foundation for customer analysis. Structured records—clickstream events, transaction logs and engagement rates—are combined with unstructured inputs such as product reviews, social media comments and contact center transcripts. Aligning these signals to resolved customer identities enables accurate attribution and prepares data for advanced natural language processing and pattern recognition. Privacy, consent and security controls are applied to ensure compliance with regulations such as GDPR and CCPA.
Key Objectives
- Define the scope of behavioral metrics and feedback channels
- Verify data availability, quality and completeness across structured and unstructured sources
- Link each input to a unified customer identifier and journey segment
- Enforce privacy, security and consent management
- Partition or stream data for downstream AI workflows
Primary Data Inputs
Quantitative Interaction Metrics
- Web and mobile analytics (page views, clicks, session duration)
- Transaction records (orders, cart additions, promotions, refunds)
- Search queries and product exploration patterns
- Email and notification engagement (open rates, clicks)
- Loyalty program activity and point redemptions
- In-store point-of-sale logs
Qualitative Feedback Signals
- Product reviews and star ratings
- Social media posts and direct messages
- Survey responses and NPS feedback
- Contact center transcripts and chat logs
- User-generated content on forums and support portals
- Voice-of-customer data from focus groups
Prerequisites and Conditions
- Consolidated Data Repository: Scalable storage and real-time ingestion via platforms such as Snowflake, Google BigQuery or Azure Synapse Analytics, and streaming using Apache Kafka or Amazon Kinesis.
- Resolved Customer Identities: Identity resolution services merge cookies, device IDs and loyalty IDs into a single profile.
- Data Quality Assurance: Cleansing rules remove duplicates, correct malformed records and validate timestamps. Text sources undergo language detection, profanity filtering and spam removal using tools such as spaCy or NLTK.
- Privacy and Consent Management: Consent and retention policies enforced by OneTrust or TrustArc.
- Access Controls and Security: Role-based permissions, encryption at rest and in transit, and audit logging.
- Language and Locale Support: Locale tagging and optional translation via services like Google Translate API to guide multilingual workflows.
Organizations that satisfy these conditions can proceed to the analytical core where unstructured feedback is transformed into structured sentiment, intent and pattern insights.
Natural Language Processing and Pattern Recognition
This stage orchestrates AI-driven services to convert raw text into structured data. A distributed messaging layer decouples data producers and consumers, while preprocessing modules normalize text for analysis. Core components include intent classification, sentiment scoring and pattern detection. Model training, serving, orchestration and error handling ensure high accuracy and reliability at scale.
Data Intake and Preprocessing
- Stream text payloads via Apache Kafka or Amazon Kinesis with Avro or JSON Schema enforcement.
- Preprocess using spaCy or NLTK: language detection, tokenization, stop-word removal, lemmatization and entity masking.
- Apply backpressure controls and partition messages by channel for parallel processing.
Intent Classification, Sentiment Scoring and Pattern Detection
- Intent Classification: Transformer models such as BERT via Google Cloud Natural Language API categorize messages into intents like product inquiry or return request. Features include batch vs real-time modes, model versioning, confidence thresholds and fallback to human review.
- Sentiment Analysis: Compute polarity and emotional attributes with Amazon Comprehend or IBM Watson Natural Language Understanding. The pipeline orchestrates API calls, handles rate limits and enriches records with normalized scores.
- Pattern Recognition: Extract keywords and themes using TF-IDF, Latent Dirichlet Allocation and regex engines to surface recurring topics and domain-specific patterns.
Model Training, Deployment and Hybrid Strategies
- Feature Management: Centralized feature store feeds both batch training and real-time inference.
- Training Infrastructure: GPU clusters on Amazon SageMaker or Kubernetes, orchestrated by Kubeflow Pipelines or Apache Airflow, with experiment tracking via MLflow or Weights & Biases.
- Real-Time Serving: Models hosted on TensorFlow Serving, TorchServe or SageMaker Endpoints. Autoscaling, caching with Redis or Memcached, and monitoring with Prometheus and Grafana ensure low-latency inference.
- Hybrid Rule-Based Approaches: Incorporate sentiment lexicons, business rules and ensemble methods. Leverage Hugging Face Transformers for open collaboration and fine-tuning.
Orchestration, Enrichment and Quality Controls
- Manage workflows with Apache Airflow or AWS Step Functions, defining dependencies and retry policies.
- Integrate with knowledge bases and search indexes like Elasticsearch to enrich records with product specifications, past ticket histories and active promotions.
- Publish enriched sentiment and intent to change-data-capture topics for profile enrichment and downstream consumption.
- Implement dead-letter queues for exceptions, human review dashboards, drift detection and automated retraining triggers to maintain model performance.
Insight Outputs and Downstream Enrichment
Structured insights are delivered as enriched interaction records, aggregated datasets, real-time event streams and interactive dashboards. Clear schemas and governed handoff mechanisms ensure reliable delivery to predictive analytics, personalization engines and business intelligence tools.
Enriched Interaction Records
- Combine raw events with sentiment polarity, emotion labels, intent tags and quality flags.
- Serialize in JSON or Avro into a behavioral_insights.interactions schema partitioned by date and channel.
Aggregated Insight Datasets
- Compute metrics by customer, time window, product category and region (for example, average sentiment over 30 days).
- Store in behavioral_insights.aggregates for model training and BI analysis.
Real-Time Event Streams
- Publish minimal payloads to Kafka topics or Pub/Sub channels, including interaction IDs, sentiment scores, emotions and intents.
- Enable low-latency personalization, chat routing and in-memory updates for next-best-action.
Interactive Dashboards
- Visualize sentiment trends, intent distributions, negative sentiment spikes and campaign correlations in Tableau, Power BI or Looker.
- Version dashboards, document filters and refresh schedules in a BI repository.
Handoff Mechanisms and Governance
- Batch transfers of Parquet feature tables to platforms like Databricks or SageMaker for model training.
- Real-time routing via Kafka streams to scoring services and profile stores.
- RESTful APIs for on-demand insights retrieval, authenticated and rate-limited.
- Metadata catalog registries to record schema versions, lineage and interface contracts.
Quality Management, Scaling and Security
- Enforce schema versioning, automated data quality checks and audit logging for compliance.
- Scale storage and processing through partitioning, autoscaling Kubernetes deployments, materialized views in Apache Druid or ClickHouse and near-line archiving.
- Protect data with encryption, masking of personal identifiers and regular security audits aligned with GDPR and CCPA.
These enriched insights form the basis for predictive modeling and personalized experiences, enabling organizations to forecast churn risk, optimize next-best-action strategies and deliver dynamic, empathetic customer interactions across the omnichannel ecosystem.
Chapter 7: Predictive Analytics and Next-Best-Action Models
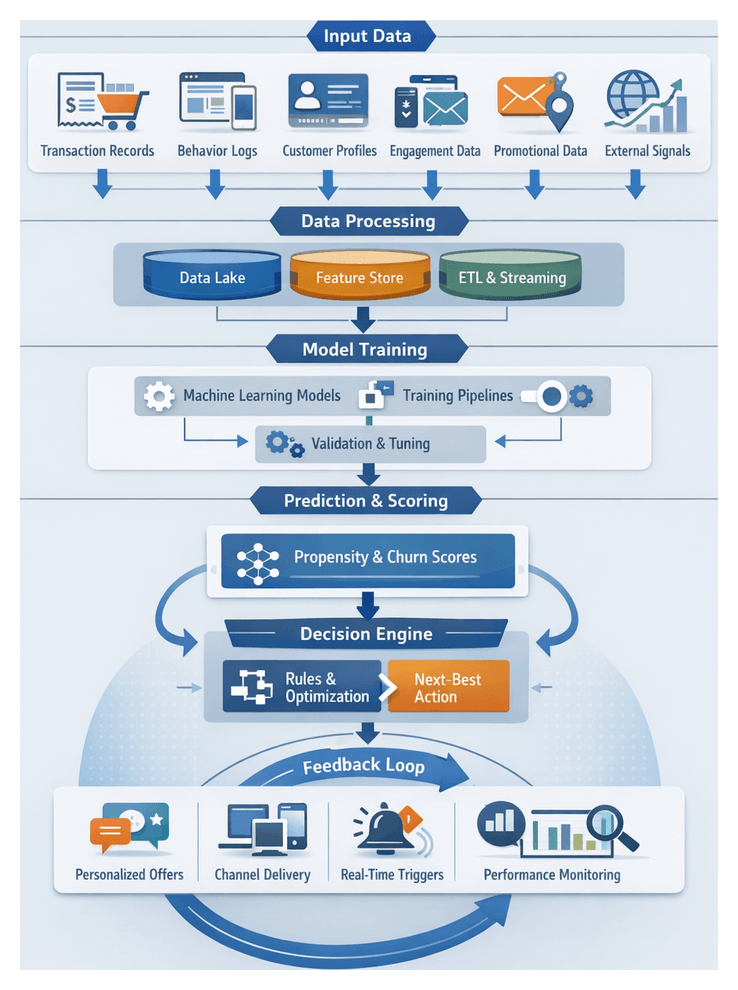
Forecasting Customer Behavior
In an omnichannel retail and e-commerce environment, predicting customer behaviors such as purchase intent, churn risk and product preferences is essential for delivering timely, relevant experiences that drive engagement and revenue. Forecasting transforms raw transaction, interaction and profile records into actionable probability scores that fuel next-best-action recommendations. Key objectives include quantifying individual purchase propensities, identifying churn indicators, segmenting customers by forecasted value and enabling real-time triggers based on evolving scores.
Accurate forecasts rely on comprehensive input datasets:
- Transaction Histories: Timestamped purchase records with SKUs, quantities, prices and discount codes.
- Behavioral Logs: Web and mobile events such as page views, searches and add-to-cart actions.
- Customer Profiles: Unified identities with demographics, loyalty status and lifetime value.
- Engagement Metrics: Email opens, click-throughs, push responses and store visits.
- Promotional Data: Historical campaign offers, coupon usage and price changes.
- External Indicators: Macroeconomic factors, weather data, competitor pricing and social trends.
Prerequisites for launching forecasting pipelines include a unified data repository such as a cloud data lake or warehouse, identity-resolved profiles, a feature engineering framework, data quality assurance, scalable compute (for example Amazon SageMaker, Google Cloud AI Platform, Azure Machine Learning), governance and cross-functional alignment.
A robust analytical infrastructure comprises:
- Feature Store: Versioned repository for rolling purchase counts, average order value and session durations.
- Model Toolkit: Open-source libraries (scikit-learn, XGBoost, TensorFlow, PyTorch) or managed platforms (DataRobot, H2O.ai).
- Training Pipelines: Orchestrated with Apache Airflow or Kubeflow to automate data ingestion, model training, evaluation and registration.
- Batch and Real-Time Scoring: Scheduled jobs and inference endpoints serving propensity scores to personalization engines.
- Monitoring and Feedback: Systems to track model drift, feature importance shifts and prediction accuracy, triggering retraining.
- Version Control: Git for code, Docker for environments and metadata tracking for reproducibility.
- Integration: APIs or message queues forwarding predictions to decision engines.
Common challenges include balancing model complexity with interpretability, addressing class imbalance, handling seasonality, maintaining data freshness, aligning business and data science objectives and ensuring ethical use of predictions.
Real-Time Data Ingestion and Feature Engineering
Continuous collection of structured customer attributes, transaction histories, session logs and interaction events is achieved through message brokers such as Apache Kafka or managed streaming services like Amazon Kinesis. Feature engineering agents process data in motion, computing rolling aggregates and derived metrics within containerized environments orchestrated by Kubeflow or Apache Airflow, ensuring reproducibility and versioned transformations.
A centralized feature store—built on open-source frameworks like Feast or managed platforms such as Databricks Feature Store—serves consistent features to both batch training and real-time inference workloads. Orchestration guarantees that features are synchronized across environments, while automated retries and alerting maintain end-to-end data lineage.
Model Training, Validation and Deployment
With a comprehensive feature set available, data scientists initiate training workflows on GPU or CPU clusters managed by Kubernetes. Experimentation frameworks include scikit-learn, TensorFlow, PyTorch and XGBoost, while experiment tracking and artifact registration use platforms such as MLflow or Amazon SageMaker Experiments. Automated hyperparameter tuning and cross-validation ensure statistical rigor.
Upon meeting validation thresholds for accuracy, precision and recall, models are packaged into container images scanned for vulnerabilities and deployed via CI/CD pipelines to inference clusters. Deployment strategies employ A/B testing and canary releases, routing subsets of traffic to new model versions and measuring real-time performance against baselines.
Inference services expose REST or gRPC APIs secured by OAuth 2.0, auto-scaling replica counts to meet latency and throughput SLAs. Automated rollback safeguards ensure continuity in case of performance anomalies.
Next-Best-Action Decision Logic
Prediction scores feed into a rules engine where machine learning outputs merge with deterministic constraints to select the optimal recommendation for each customer. Decision frameworks powered by Drools or Google Recommendation AI apply business policies, frequency caps and channel preferences. The logic layer interfaces with a centralized decision API, logging inputs and outputs for auditability.
Decisions respect budget allocations and regulatory constraints while optimizing for revenue, margin and engagement. Real-time triggers respond to events such as cart abandonment or in-store check-ins, launching tailored recommendations across digital and physical channels.
Recommendation Outputs and Channel Routing
The Action Recommendations and Channel Routing stage produces the artifacts that bridge analytics and execution systems. Core outputs include:
- Personalized Payloads: Recommended actions with content variants and timing windows.
- Channel Instructions: Prioritized lists of channels such as web push, email, mobile push and in-store kiosks.
- Execution Metadata: Decision rationale, model version identifiers, timestamps and confidence scores.
- Trigger Flags: Indicators for immediate execution, deferral or suppression based on business rules and opt-out status.
Dependencies include churn and propensity scores from engines like Amazon Personalize or Google Cloud AI Platform, unified profiles, real-time context signals, business rule configurations and model metadata for traceability.
Handoff mechanisms ensure reliable delivery to personalization and campaign systems:
- Event Streaming: Publishing to Kafka topics or Kinesis streams for real-time consumption.
- RESTful APIs: Exposing endpoints for on-demand recommendation retrieval.
- Shared Repositories: Writing batch outputs to data warehouses or NoSQL stores.
- Webhooks: Delivering payloads to external partner endpoints.
- Acknowledgment and Retry: Protocols to confirm receipt and handle transient failures.
Personalization engines—whether in-house microservices or platforms like Adobe Experience Platform—assemble content via APIs, merge metadata into templates and adapt formats through channel adapters for email, mobile and digital signage.
Monitoring, Feedback Loops and Governance
End-to-end observability captures metrics, logs and trace data using time-series databases such as Prometheus and logging stacks like ELK. Distributed tracing tracks each request from ingestion to delivery, helping teams identify bottlenecks. Anomaly detection alerts trigger incident workflows and automated remediation.
Closed-loop feedback integrates delivery receipts, click-through metrics and conversion events into the feature store. Drift detection algorithms monitor feature distributions and prediction quality, initiating retraining pipelines when necessary. Continuous retraining leverages updated data to refine features, explore new algorithms or adjust hyperparameters.
Governance and security controls enforce data privacy and compliance. Traffic encryption uses TLS, services authenticate via OAuth 2.0, and sensitive data is tokenized via HashiCorp Vault. Role-based access restricts pipeline modifications and data access. Audit logs record model configurations, decision rules and API schemas. Bias detection and explainability modules ensure fairness and transparency. Data retention policies govern storage of logs, features and artifacts in objective-driven repositories.
This integrated predictive analytics and next-best-action framework empowers retailers and e-commerce organizations to anticipate customer needs, personalize engagements and drive measurable business outcomes across the omnichannel landscape.
Chapter 8: Personalization Engine and Recommendation Delivery
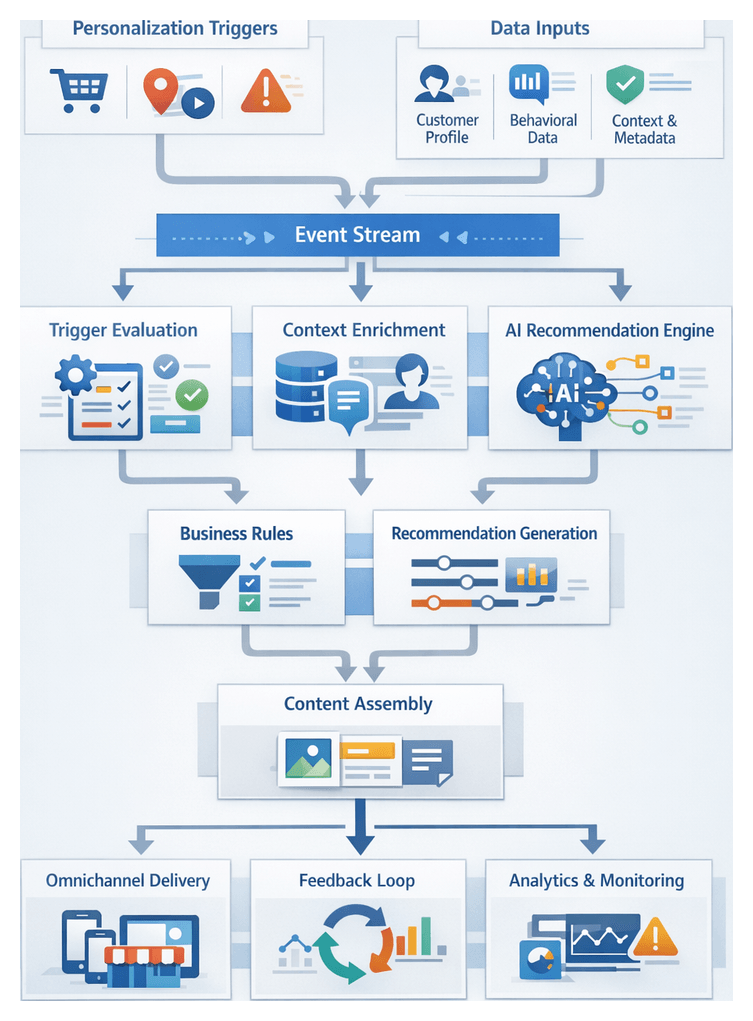
Defining Personalization Triggers and Data Inputs
At the core of omnichannel personalization lies the definition of precise triggers and the assembly of comprehensive data inputs. Personalization triggers—events, conditions or predictive thresholds—signal the engine to generate tailored content at moments of peak relevance. Inputs provide the high-fidelity context needed for accurate decisioning. Together they power AI-driven recommendation engines and ensure consistent customer experiences.
Personalization triggers transform raw behavioral signals into actionable opportunities. They can be explicit actions—such as adding an item to cart—or inferred events backed by predictive scores. Clear trigger definitions enable:
- Precision timing to maximize engagement
- Contextual relevance aligned with journey stage
- Scalable automation of decision logic
- Consistency across channels
Examples include abandoned cart reminders, dynamic homepage banners, location-based push notifications and in-store proximity offers. Well-defined triggers prevent irrelevant messaging and customer fatigue.
Key Data Inputs
A robust personalization engine ingests multiple input categories:
- Customer Profile Attributes such as demographics, loyalty status and segmentation, often sourced from platforms like Segment.
- Real-Time Behavioral Events including page views, search queries and cart updates, collected via services like Dynamic Yield or custom Apache Kafka pipelines.
- Contextual Metadata covering device, geolocation, time of day and channel environment.
- Predictive Scores such as purchase propensity or churn risk generated by Amazon Personalize or Google Recommendations AI.
- Content Inventory and Metadata managed in systems like Adobe Target or Optimizely.
- Business Rules and Campaign Constraints for frequency capping, regional restrictions and compliance.
- Historical Interaction Records consolidated in unified repositories for long-term context.
Prerequisites and Conditions
Effective personalization demands:
- High data quality with validation and cleansing pipelines
- Low-latency streams via platforms like AWS Kinesis or Apache Kafka
- Unified identity resolution with deterministic and probabilistic matching
- Standardized event taxonomy under version control
- API contracts for seamless integration with CRM, CMS and order management
- Real-time consent enforcement for GDPR and CCPA compliance
- Cross-functional governance for trigger and rule management
- Performance monitoring with SLAs on latency and accuracy
With this foundation, organizations can activate AI recommendation engines and orchestrate real-time personalization at scale.
Real-Time Recommendation Orchestration
Real-time orchestration coordinates event capture, context enrichment, AI-driven suggestion retrieval and content delivery across web, mobile, email and in-store touchpoints. It automates the evaluation of triggers, the application of business rules and the dispatch of personalized recommendations with sub-second responsiveness.
Core Workflow Components
- Event Stream Ingestion via platforms such as Apache Kafka or AWS Kinesis
- Trigger Evaluation Engine applying predefined and AI-derived rules
- Context Enrichment Service querying unified profiles and session data
- Recommendation API Invocations to services like Amazon Personalize, Adobe Target or Google Recommendations AI
- Business Rule Processor enforcing merchandising strategies and inventory checks
- Content Delivery Integration with web front-ends, mobile SDKs, email engines and in-store systems
- Monitoring and Logging for latency, success rates and fallback usage
Workflow Sequence
- Event Capture publishes customer actions with metadata to the event bus.
- Trigger Matching identifies events that warrant recommendations.
- Session Enrichment retrieves real-time profile attributes and inventory status.
- Recommendation Generation calls one or more AI services—such as Dynamic Yield or Optimizely—and aggregates ranked suggestions.
- Business Rule Application filters and prioritizes recommendations according to strategy.
- Recommendation Consolidation merges outputs from multiple engines based on weighted priorities.
- Payload Construction formats item lists, images, tracking tokens and metadata for each channel.
- Channel Dispatch delivers payloads via REST, Pub/Sub, SDK callbacks or WebSockets.
- Feedback Capture records customer interactions with recommendations for model retraining.
- Monitoring and Error Handling implements fallbacks and alerts for failures or latency breaches.
System Coordination Patterns
- Asynchronous Event Bus for decoupled, fault-tolerant communication
- Versioned Microservice APIs for context enrichment, rule processing and recommendations
- Service Discovery and Load Balancing to support horizontal scaling
- Circuit Breakers and Retries to isolate failures and maintain uptime
- Distributed Tracing via OpenTelemetry for end-to-end visibility
- Caching Strategies using Redis or Memcached to reduce lookup latency
- Real-Time Analytics Feeds into dashboards tracking engagement and conversion metrics
By orchestrating these components, retailers achieve consistent, adaptive personalization that drives engagement and revenue uplift.
Recommendation Algorithms and System Integration
Advanced recommendation algorithms transform data inputs into ranked suggestions. System architects must select and integrate models—collaborative, content-based, hybrid, sequence-aware and reinforcement learning—while ensuring robust interfaces and observability.
Collaborative Filtering
Collaborative filtering analyzes user-item interaction patterns to find similar users or items. Services like Amazon Personalize automate feature engineering, latent factor generation and real-time inference via API.
Content-Based Models
These models leverage item attributes and user preferences. Techniques include text embeddings via Google Cloud Natural Language API and image feature extraction with Azure Computer Vision. Feature stores support low-latency vector lookups for real-time scoring.
Hybrid Frameworks
Hybrid systems blend collaborative and content-based signals. Platforms such as Adobe Target and Salesforce Einstein manage ensemble models, feature pipelines and A/B testing for continuous improvement.
Sequence-Aware and Deep Learning Models
Recurrent neural networks, transformers and graph neural networks capture temporal and relational patterns. Environments like IBM Watson Machine Learning provide preconfigured clusters for training and GPU-accelerated inference.
Reinforcement Learning
RL agents optimize recommendation policies through reward-based learning. Multi-armed bandits and policy gradient methods balance exploration and exploitation, with Apache Kafka streaming feedback for online updates.
Integration Patterns and Governance
- API Gateway for routing, authentication and rate limiting
- Microservice architecture with REST or gRPC endpoints
- Feature Store for consistent offline and online feature access
- Event-Driven Workflows via Kafka or AWS Kinesis
- Front-End SDKs for JavaScript and mobile clients
- CMS Connectors to embed recommendations in editorial content
- In-Store IoT Interfaces using MQTT or WebSockets
- Monitoring with Datadog, Splunk or AWS CloudWatch
- Governance frameworks for model versioning, privacy compliance and drift detection
This layered approach enables scalable, reliable recommendation delivery aligned with business objectives and regulatory requirements.
Personalized Content Output and Deployment
In the final stage, the personalization engine produces actionable artifacts and handoff mechanisms that drive consistent experiences across channels. Outputs include recommendation payloads, content variants, delivery instructions, enrichment records and operational logs.
Recommendation Payloads
These structured messages contain item lists, context attributes, TTL values and compliance flags. They are serialized as JSON or Protocol Buffers and delivered via REST or gRPC endpoints supported by services such as Amazon Personalize or Google Recommendations AI.
Content Variant Definitions
Variant outputs specify template IDs, dynamic fields, layout rules and fallback logic. They integrate with platforms like Dynamic Yield and Adobe Target for campaign mapping.
Delivery Instructions
Instructions include channel identifiers, trigger conditions, priority settings and tracking tokens. Multichannel orchestrators such as Optimizely translate these into calls to Mailchimp, Firebase Cloud Messaging or digital signage APIs.
Data Enrichment Records
Decision outputs append to customer profiles and session records, feeding back into CDPs or data lakes for analytics and retraining. Records include timestamps, confidence scores and segment updates.
Operational Logs and Metrics
The engine emits error logs, latency metrics, throughput statistics and business KPIs. Integrations with Datadog, Splunk or AWS CloudWatch enable monitoring, alerting and A/B test analysis.
Handoff Mechanisms
- API Endpoints for synchronous payload retrieval
- Event Streams via Kafka, Kinesis or Azure Event Hubs
- Webhooks for push-style integrations
- CDP and Warehouse Loads for batch enrichment and reporting
Reliability and Traceability
- Version Control of models and templates
- Schema Validation and contract testing
- Idempotency and deduplication safeguards
- Security controls to protect PII
- Distributed tracing for end-to-end visibility
Through these mechanisms, Retail and E-Commerce organizations operationalize AI-driven personalization with precision, scalability and compliance, delivering consistent, measurable experiences that enhance customer engagement and lifetime value.
Chapter 9: Multichannel Campaign Orchestration
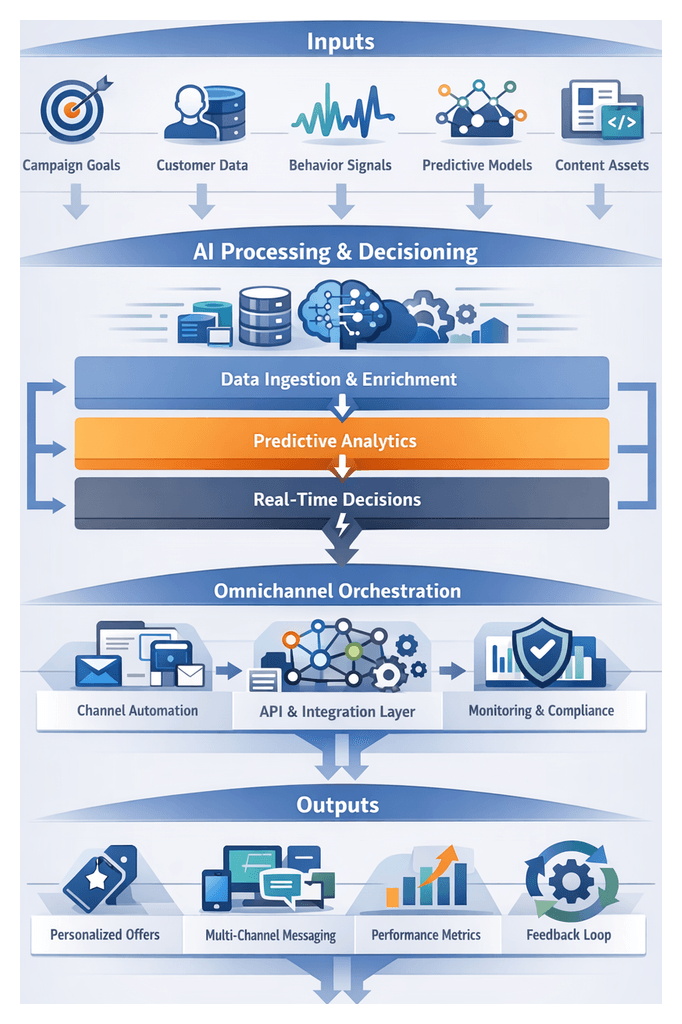
Campaign Objectives and Trigger Logic
Effective multichannel campaign orchestration begins with clearly defined objectives and trigger conditions that align with overarching business strategies and real-time customer behaviors. At this stage, marketing and analytics teams translate high-level goals—such as increasing average order value, reducing cart abandonment or boosting loyalty enrollment—into actionable parameters. These objectives are decomposed into specific, measurable Key Performance Indicators (KPIs), including volume metrics (open and click-through rates), revenue targets (incremental sales uplift, average order value increases), engagement thresholds (session frequency, repeat purchase rates), acquisition goals (new subscribers, first-time purchases) and retention outcomes (churn reduction, reactivation rates). Establishing baselines and target thresholds enables ongoing monitoring, rapid decision-making and post-campaign evaluation.
Campaign prerequisites span data inputs, creative assets and technical configurations. Essential inputs include customer segment definitions from cohort analyses, predictive scores (next-best-action recommendations, churn risk indicators), resolved identity profiles enriched with transaction histories and lifetime value estimates, as well as approved content templates and offer variations. Connectivity to execution platforms must be validated, whether via Salesforce Marketing Cloud or Adobe Campaign, along with compliance checks for GDPR, CCPA and regional regulations and calendars that account for blackout dates and peak demand periods.
Channel alignment is critical for maximizing impact. Historical performance data guides channel assessment—recognizing that email may excel at content delivery, SMS at urgent promotions and in-app notifications at driving immediate action. Messages are adapted to each channel’s format and audience expectations, with sequencing logic defining the optimal order of touches. Frequency and cadence rules prevent fatigue by enforcing limits such as no more than two SMS per week or email intervals of at least 72 hours. Fallback paths specify alternative channels or content when a primary delivery fails, ensuring continuous engagement without conflicting offers.
Trigger conditions determine the precise moments campaigns activate. Common categories include event-based triggers (cart abandonment, product view thresholds), time-based triggers (birthday greetings, monthly statements), threshold triggers (spending milestones, points earned), behavioral triggers (declines in engagement) and predictive triggers powered by machine learning. Decision logic can combine multiple criteria with AND/OR operators, nested conditions and exclusion rules—for example, a reactivation message may fire when a customer’s churn risk exceeds a threshold AND no purchase has occurred in 90 days AND opt-in consent is valid. Documenting triggers in a centralized workflow repository promotes governance and transparency, with visual rule editors and audit trails provided by platforms.
AI-Driven Journey Architecture
Integrating AI agents into the customer journey transforms static processes into adaptive, learning workflows. Instead of manual handoffs between analytics and activation, autonomous agents continuously ingest signals, enrich data, apply predictive models and execute decisions in real time. This paradigm ensures that each touchpoint—whether web, mobile, in-store or third-party—reflects up-to-the-moment customer context and preferences.
Data Extraction and Semantic Enrichment
AI agents first consolidate raw event data streams from web logs, mobile SDKs, point-of-sale systems and social feeds into centralized platforms. Event ingestion frameworks such as Apache Kafka or AWS Kinesis capture high-velocity inputs, writing timestamped batches to data lakes on Amazon S3 or Google Cloud Storage. Adaptive parsers standardize heterogeneous schemas into normalized tables, forming the basis for harmonization. Agents then invoke natural language processing services like IBM Watson Natural Language Understanding to analyze unstructured content—product reviews, chat transcripts—and append sentiment scores or intent tags. The result is a rich, canonically formatted dataset ready for identity resolution and journey reconstruction.
Predictive Modeling and Real-Time Decisioning
With enriched profiles in place, AI agents orchestrate end-to-end model lifecycle management. They integrate with training platforms such as DataRobot, H2O.ai, AWS SageMaker, Google AI Platform and Microsoft Azure Machine Learning to automate data selection, feature engineering, hyperparameter tuning and model validation. Resulting models—scoring purchase propensity, churn likelihood or next-best-action—are deployed to inference endpoints. During live interactions, AI agents process incoming events, call models within milliseconds and return tailored recommendations, ensuring offers display instantly and align with customer needs.
Omnichannel Orchestration and Sequencing
AI agents collaborate with orchestration engines to determine when and how messages deploy across channels. Using decision trees and priority matrices, agents evaluate incoming triggers from order management systems, web analytics and third-party data feeds, assign priority based on lifetime value or segment tier, and resolve conflicts by suppressing lower-value messages in favor of high-ROI offers. Time-sensitivity scoring incorporates offer windows and customer time zones to ensure timeliness.
API Integration and System Interactions
- Outbound integrations connect to email platforms such as Adobe Campaign, SMS gateways, push notification services and social ad APIs.
- Inbound listeners track delivery receipts, open and click events, and in-store transaction confirmations.
- Batch transfers use secure file drops or database exports for bulk scheduling.
- Webhooks enable real-time synchronization of campaign state across personalization engines and execution platforms.
Exception Handling and Reliability
Robust fall-back and retry logic safeguard the customer experience. Automated retries with exponential back-off address transient delivery errors, while channel redirection switches to alternate channels—such as SMS if a push notification is unsupported. Escalation rules alert operations teams when failures exceed thresholds, and suppression lists enforce opt-outs and compliance requirements.
Real-Time and Batch Coordination
Orchestration engines balance immediate responses to live events—like location-based check-ins—with scheduled batch campaigns, ensuring coherent narratives through de-duplication, concurrency controls and dependency chains. Non-urgent communications may be grouped into nightly cycles, while high-priority triggers bypass batch queues to deliver time-sensitive offers.
Transparency, Governance and Scalability
Comprehensive logging and audit trails capture trigger receptions, priority scores, scheduling decisions and API transactions. Workflow dashboards visualize campaign progress, message volumes and error rates, while audit reports document compliance with regulatory policies. Role-based access controls and approval workflows ensure that only authorized stakeholders modify orchestration logic. Versioning and rollback mechanisms support rapid issue resolution. Auto-scaling clusters and distributed queuing—leveraging message brokers like Apache Kafka or Amazon SQS—handle peak loads, enforce rate limits per channel and gracefully degrade non-critical tasks during surges. Feedback loops stream real-time metrics back into analytics systems, enabling automated channel reprioritization, model retraining triggers and operational alerts when KPIs deviate from targets.
Workflow Artifacts and Integration
Key Outputs Across Stages
- Data Ingestion Streams: Timestamped event batches, source-system mappings and metadata logs stored in data lakes.
- Normalized Tables: Standardized customer events, product interactions and channel attributes in staging databases.
- Harmonized Repository: Canonical customer records, attribute lineage logs and transformation audit trails.
- Resolved Profiles: Identity-matched customer records enriched with demographics, transaction history and behavioral metrics.
- Journey Maps: Chronological session chains, drop-off indicators and inferred engagement loops.
- Segment Catalogs: Cohort definitions, member lists and stability scores from AI-driven clustering.
- Sentiment Insights: NLP-derived sentiment scores, intent tags and annotated interaction records.
- Predictive Scores: Churn risk, purchase propensity and next-best-action tables with feature importance analyses.
- Personalization Assets: Content variants, offer templates and decision logic scripts ready for deployment.
- Execution Reports: Dispatch logs, engagement metrics and anomaly flags feeding into optimization loops.
Dependencies and Resources
Each workflow stage relies on data connectors and ingestion frameworks (Apache Kafka, AWS Kinesis), storage and catalog services (Amazon S3, Snowflake), AI and ML platforms (Google Cloud AI, IBM Watson, custom frameworks), orchestration engines (Apache Airflow, enterprise schedulers), API gateways and message brokers (Kafka topics, REST endpoints, GraphQL services) and observability tools (Datadog, Splunk) for performance monitoring and compliance.
Integration Patterns and Handoffs
- Event-Driven Triggers: Upstream stages publish notifications to a message bus; downstream consumers subscribe and initiate processing immediately.
- API Orchestration: RESTful or gRPC endpoints expose outputs—such as resolved profiles or predictive scores—for on-demand retrieval.
- Data Share and Views: Shared warehouses or analytics views grant controlled access to harmonized datasets for reporting and segmentation.
- Webhook Notifications: Real-time callbacks alert personalization engines to event updates, prompting immediate message generation.
- Batch File Transfers: Hourly or daily exports in CSV or Parquet format are placed in secure storage for bulk downstream ingestion.
Operational Excellence and Continuous Optimization
Operational reliability and continuous improvement hinge on cohesive governance, transparent metrics, and agile feedback loops. Detailed event logs and API transaction records facilitate rapid root-cause analysis, while workflow dashboards provide real-time insights into campaign health and error rates. Regular cross-functional reviews—uniting marketing, data science, IT operations, and legal teams—adapt sequence logic, channel priorities, and compliance rules based on performance insights. Auto-scaling clusters and distributed queuing systems dynamically adjust capacity to manage traffic surges, enforcing per-channel rate limits to prevent throttling. Automated monitoring identifies KPI deviations, triggering alerts that initiate adjustments to triggers, sequencing rules, or model parameters. When drift is detected, model retraining pipelines activate to maintain predictive accuracy. Key performance indicators—average response latency, model precision and recall, conversion lift from personalization, and system uptime—offer a comprehensive scorecard for evaluating AI-driven journey effectiveness. Through disciplined governance, robust infrastructure, and closed-loop optimization, organizations consistently deliver personalized omnichannel experiences at scale while ensuring brand integrity and regulatory compliance.
Chapter 10: Monitoring, Attribution, and Continuous Optimization
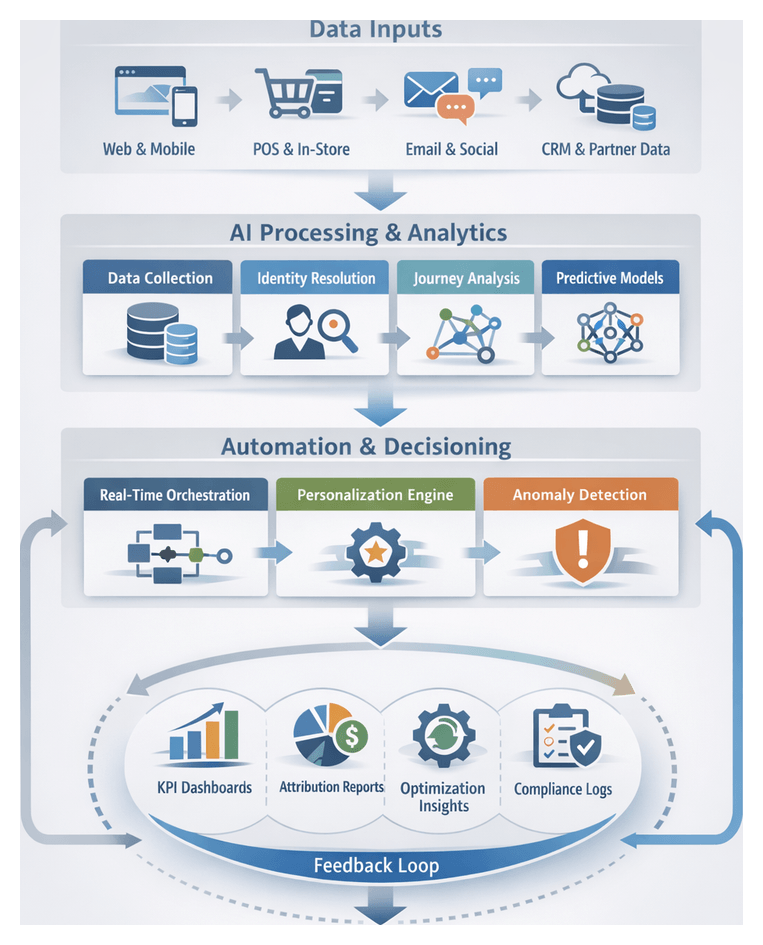
Establishing Performance Tracking Criteria
Performance tracking criteria define clear, measurable objectives that guide every stage of the omnichannel customer journey. In retail and e-commerce, these criteria align key performance indicators with strategic priorities, enable end-to-end visibility, and facilitate continuous optimization. By specifying required inputs, technical prerequisites, and governance conditions upfront, organizations ensure consistent monitoring, accountable handoffs, and actionable AI-driven insights.
Objectives
- Align Metrics with Business Goals: Link conversion rate, average order value, and customer lifetime value to revenue growth, retention, and operational efficiency.
- Enable End-to-End Visibility: Define measurement points across data ingestion, identity resolution, journey reconstruction, and campaign orchestration.
- Facilitate Continuous Optimization: Establish feedback loops with performance thresholds and anomaly detection rules to trigger model retraining and campaign adjustments.
Key Performance Indicators
- Conversion Rate: Percentage of interactions resulting in purchases or desired actions across web, mobile, and in-store channels.
- Average Order Value: Mean transaction value for revenue forecasting and customer segmentation.
- Customer Acquisition Cost: Marketing spend divided by new customers, guiding budget allocation.
- Customer Lifetime Value: Projected net profit per customer relationship, informing personalization and retention efforts.
- Churn Rate: Percentage of customers ceasing engagement, driving win-back strategies.
- Time to Purchase: Interval between initial interaction and transaction, revealing path friction.
- Engagement Rate: Click-through, email open rates, and session duration indicating content relevance.
- Attribution Share: Contribution of channels or touchpoints to conversions, supporting multi-touch attribution.
Data Inputs and Prerequisites
- Raw Interaction Logs: Clickstream data, point-of-sale records, CRM events, and partner feeds captured during ingestion.
- Identity Resolution Outputs: Customer identifiers and confidence scores from AI-driven matching algorithms.
- Journey Reconstruction Artifacts: Chronological touchpoint sequences exported from journey analytics modules.
- Segmentation Assignments: Cohort labels and cluster membership scores from classification workflows.
- Behavioral Insights: Sentiment scores and intent classifications produced by natural language processing engines.
- Predictive Scores: Propensity, risk estimates, and next-best-action recommendations from machine learning pipelines.
- Campaign Logs: Content variants, timestamps, and delivery confirmations from recommendation and orchestration platforms.
- Finance Data: Order confirmations, revenue records, marketing spend, and inventory levels from ERP systems.
Prerequisites include data integrity thresholds, unified time synchronization to UTC, consistent event taxonomy and tagging, role-based access controls, and cross-functional stakeholder alignment on definitions and SLAs.
Metric Taxonomy and Synchronization
Maintaining a centralized metric glossary ensures consistent interpretation. Each KPI should include a calculation formula, data source mapping, update frequency, and assigned owner. Normalizing timestamps to Coordinated Universal Time at ingestion prevents sequencing errors, with local time conversions handled only for presentation. Automated validation services enforce a standardized event taxonomy across channels.
Tools for KPI Monitoring
- Google Analytics for web and app engagement and real-time reporting.
- Adobe Analytics for advanced segmentation and pathing visualizations.
- DataDog for pipeline latency alerting and anomaly detection.
- DataRobot for model performance tracking and drift detection.
- Business intelligence platforms such as Tableau or Power BI for consolidated dashboards.
Documentation of criteria in a living knowledge base—with version histories and stakeholder sign-offs—ensures iterative refinement as customer behaviors and business goals evolve.
Data Collection and Multi-Touch Attribution
The data collection and attribution workflow aggregates raw interaction data from every touchpoint, standardizes events, applies attribution models, and feeds results into personalization and predictive systems. This process underpins channel investment decisions and continuous feedback into AI engines.
Data engineers define schema contracts that specify required fields—customer identifiers, timestamps, channel codes, campaign IDs, product SKUs, and event metadata. Enforcing these contracts across ingestion endpoints prevents downstream inconsistencies and supports traceable lineage for each data asset.
Data Acquisition
- Web events via Google Tag Manager feeding into Google Analytics 360.
- Mobile SDK events ingested with Segment or mParticle.
- Point-of-sale and in-store records streamed through Apache Kafka or Amazon Kinesis.
- Email engagement data from Mailchimp or Adobe Campaign.
- Call center transcripts and chat or social listening feeds via Apache NiFi or Tealium EventStream.
- Third-party partner feeds, loyalty data, and CRM exports delivered through Fivetran or Stitch.
Event Processing and Standardization
- Stream Ingestion: Events land in raw partitions managed by Kafka or Kinesis; frameworks like Apache Flink or Confluent ksqlDB apply initial parsing.
- Schema Validation: Compare against Confluent Schema Registry; route non-compliant records to error queues.
- Normalization: Standardize country codes, currency formats, and timestamps; map product codes via enrichment APIs.
- Enrichment: Append IP geolocation, merge loyalty and CRM IDs using identity resolution.
- Persistent Storage: Write cleaned streams to Snowflake or Amazon S3 partitions for efficient querying.
Orchestration engines such as Apache Airflow or Prefect manage task dependencies and trigger downstream processes upon completion.
Typical orchestration schedules ensure data availability by a set time each morning, supporting both batch reporting and near-real-time insights via micro-batch ingestion.
Attribution Modeling
- Journey Assembly: Retrieve prior interactions for each conversion from the event store by customer identifier.
- Model Selection: Business rules select first-touch, last-touch, linear, time-decay, position-based, or algorithmic attribution based on campaign objectives.
- Credit Allocation: Compute fractional credit using services like Adobe Analytics Attribution IQ.
- Score Aggregation: Generate daily metrics such as weighted conversion value, ROAS, and channel influence index.
- Result Persistence: Store outputs in a centralized analytics schema, linked to campaign metadata and budgets.
Governance and Quality Controls
- Completeness Checks: Daily reconciliation of event counts against expected volumes.
- Consistency Checks: Cross-validate revenue figures with financial reporting systems.
- Anomaly Detection: Monitor sudden metric shifts using DataDog or Splunk.
- Audit Trails: Log transformation steps, model parameters, and business rule versions for compliance and reproducibility.
- Role-Based Access Control: Enforce secure data policies via enterprise IAM systems.
Reporting and Feedback
- Visualize channel contributions, conversion paths, and ROI in Tableau or Looker.
- Sync attribution tags and scores to Salesforce or Microsoft Dynamics 365 for accurate scoring and segmentation.
- Feed channel performance into personalization engines to refine next-best-action triggers.
- Adjust media spend recommendations in budget management systems based on updated insights.
Conceptualizing AI Agents in Customer Journey Design
Embedding AI agents in customer journey design transforms static workflows into dynamic, intelligent experiences. Integrated at the orchestration layer, these agents automate decision logic, enrich data continuously, and enable scalable personalization and closed-loop optimization.
Data Extraction and Enrichment Agents
- Content Parsing: Extract metadata and sentiment from text, voice, and image inputs.
- Semantic Tagging: Classify interactions by intent—product inquiry, support request, or promotional engagement—for targeted responses.
- Attribute Augmentation: Integrate demographic, behavioral, and loyalty attributes to enrich each event context.
Predictive Modeling Agents
- Training Platforms: Develop and deploy machine learning pipelines on Amazon SageMaker and Google Cloud AI Platform.
- Feature Engineering: Automate extraction of temporal, frequency, and recency features from interaction logs, preserving lineage.
- Model Selection and Validation: Conduct hyperparameter tuning and cross-validation to choose optimal architectures—random forest, gradient boosting, or deep learning.
- Real-Time Scoring: Deliver propensity, churn risk, and next-best-action scores via inference endpoints integrated into journey logic.
Decision Logic and Orchestration Engines
- Input Assessment: At each journey node, evaluate context variables—current channel, customer status, predicted needs—and route to decision agents.
- Action Selection: Rank potential actions—email offer, push notification, web personalization—based on utility scores.
- Sequencing and Throttling: Enforce business constraints such as send frequency, channel budgets, and opt-out preferences.
Real-Time Personalization
- Session Profiling: Continuously update user context with clickstream and cart activity to refresh content recommendations.
- Contextual Bandits: Apply reinforcement learning to explore and exploit content variants, optimizing engagement signals.
- Cross-Channel Consistency: Synchronize state across web, email, and mobile channels for seamless experiences.
Feedback and Continuous Learning Agents
- Outcome Attribution: Correlate purchases, cancellations, and support interactions with prior journey steps to refine models.
- Anomaly Detection: Deploy statistical and machine learning detectors to flag performance drift and outliers.
- Automated Retraining: Use MLflow to track experiment metadata, manage model artifacts, and schedule retraining when drift thresholds are exceeded.
Supporting Infrastructure
- Data Lakehouse Platforms such as Databricks and Snowflake provide unified repositories for raw and curated data with built-in analytics and ML runtimes.
- Event Streaming and API Gateways: Apache Kafka and cloud Pub/Sub systems deliver low-latency ingestion, while API gateways expose agent services securely.
- MLOps and Model Registry: Tools like MLflow track model versions, manage deployments, and enforce governance.
- Monitoring and Observability: End-to-end instrumentation across agents, orchestration engines, and channels ensures real-time visibility and rapid troubleshooting.
Integration Patterns
- Strangler Pattern: Incrementally replace monolithic journey components with microservices wrapping AI agent logic.
- Event-Driven Integration: Leverage message brokers to decouple data producers and agent consumers with fail-safe fallback paths.
- API-First Design: Expose agent capabilities via REST or gRPC endpoints for consistent invocation across channels.
- Governance Frameworks: Centralize policy enforcement for data privacy, consent management, and model explainability.
Strategic Impact and Emerging Trends
- Accelerated Time to Market: Reusable agent components and standardized APIs shorten development cycles for new journeys.
- Personalization at Scale: Machine-driven decision logic adapts offers for millions of customers in real time.
- Operational Resilience: Automated monitoring and error handling reduce manual intervention and downtime.
- Federated Learning: Privacy-preserving training across decentralized silos enhances security and reduces latency.
- Conversational AI Integration: Embed chatbots and voice assistants into journey flows for seamless dialogue experiences.
- Edge-Based Personalization: Deploy lightweight agents on devices to deliver context-rich interactions with minimal delay.
Stage Outputs, Handoffs, and Continuous Optimization
The final stage delivers a suite of artifacts and integrations that validate campaign effectiveness, drive operational systems, and feed continuous improvement loops. These outputs inform weekly performance reviews, executive dashboards, and governance audits, enabling cross-functional teams to allocate resources and refine strategies efficiently.
Key Outputs
- Performance Dashboards: Interactive visualizations of KPIs, engagement trends, and revenue attribution.
- Attribution Reports: Multi-touch outputs crediting specific touchpoints for conversions.
- Anomaly Alerts: Real-time notifications when metrics deviate beyond defined thresholds.
- Optimization Recommendations: Actionable insights for campaign adjustments, content variants, and channel budgets.
- Model Retraining Triggers: Automated signals to retrain machine learning models based on drift and fresh data.
- Audit and Compliance Logs: Immutable records of data pipelines, model versions, user interactions, and decision logic.
Dependencies and Integrations
- Aggregated Event Streams: Continuous feeds from web analytics, mobile SDKs, POS logs, and social APIs.
- Unified Customer Profiles: Resolved identities and enriched attributes from the profile repository.
- Predictive Model Outputs: Propensity scores, churn risk indicators, and next-best-action recommendations.
- Campaign Execution Logs: Records of message sends, content variants shown, and user responses.
- External Benchmarks: Industry performance standards, market indices, and competitive intelligence.
Handoff Mechanisms
- APIs for Analytics Platforms: RESTful or gRPC endpoints for BI tools to ingest dashboards and attribution datasets.
- Message Queues: Pub/sub channels broadcasting anomaly alerts and optimization recommendations.
- Webhooks: Event-driven callbacks triggering real-time campaign adjustments and content swaps.
- Shared Data Lake: Central repository for audit logs and model artifacts accessible to compliance and analytics teams.
- Model Registry: Integration capturing retraining triggers, model versions, and performance benchmarks.
Continuous Improvement Patterns
- Event-Driven Triggers: Detect KPI deviations in streaming platforms and invoke corrective actions or retraining.
- Scheduled Batch Updates: Run regular jobs to aggregate performance data, recalibrate attribution weights, and refresh dashboards.
- Closed-Loop Feedback: Capture outcomes from personalization engines and campaign modules to refine algorithms.
- Feature Store Integration: Update shared repositories of engineered features with the latest behavior and segmentation insights.
- Version Control and Lineage Tracking: Maintain end-to-end traceability of data transformations, model changes, and deployment history.
End-to-End Visibility and Auditability
- Audit Trails: Immutable records of user interactions, system events, configuration changes, and data access for compliance reviews.
- Metadata Services: Central catalogs describing data schemas, version histories, and transformation logic applied at each stage.
- Lineage Visualization: Graphical representations of data flows from ingestion through optimization for rapid root-cause analysis.
- Governance Policies: Defined protocols for data retention, access controls, and change management aligned with industry standards.
Leveraging AI Platforms
Specialized platforms offer preconfigured modules for performance tracking, anomaly detection, and feedback orchestration. By leveraging these tools, teams accelerate implementation, reduce development overhead, and adopt best-practice workflows that integrate seamlessly with existing data lakes, MLOps stacks, and campaign engines.
By defining robust tracking criteria, orchestrating comprehensive data workflows, embedding AI agents in journey design, and systematically generating outputs and handoffs, retail and e-commerce organizations build a resilient, scalable omnichannel framework. This framework supports continuous optimization, deeper customer engagement, and sustainable business growth.
Conclusion
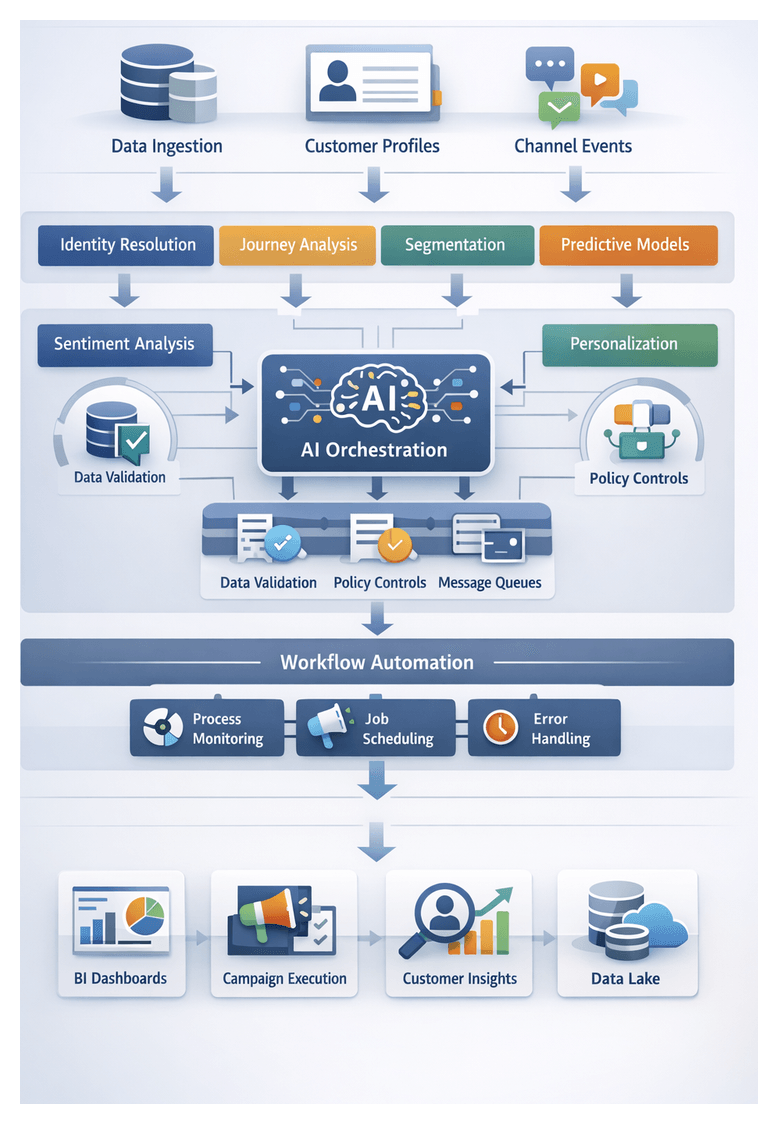
Synthesizing the Omnichannel AI Workflow
Bringing together data ingestion, integration, identity resolution, journey reconstruction, segmentation, sentiment analysis, predictive modeling, personalization, campaign orchestration and monitoring, the final stage transforms disparate artifacts into a unified, operationalized system. Outputs from each stage are consolidated within a central orchestration framework that enforces data quality checks, model performance validation and governance policies. This single pane of glass approach minimizes latency, reduces manual interventions and ensures real-time adaptability as business conditions or channels evolve.
Core objectives include consolidating stage outputs into master pipelines, validating AI-driven artifacts against quality rules, documenting dependencies and failure recovery paths, and establishing data access, privacy and audit policies. Integrated with platforms, organizations automate handoffs between microservices, schedule jobs and track lineage. The orchestration engine polls message queues, subscribes to completion flags from AI agents and triggers export routines that push summary reports to business intelligence platforms or data lakes.
- Consolidate outputs from all workflow stages into a unified orchestration framework
- Validate data integrity and AI model performance across handoffs
- Document triggers, dependencies and failure recovery paths
- Enforce governance policies for access, privacy and auditability
- Provide real-time visibility into pipeline status, latencies and throughput
System-to-system handoffs rely on message queues such as Apache Kafka and RabbitMQ to buffer events like segmentation results or churn scores. REST and gRPC APIs enable synchronous reporting to dashboards, while batch outputs are staged in secure object storage such as Amazon S3 and referenced by pointers in orchestration metadata. Each handoff is logged with a unique correlation identifier, ensuring traceability of artifacts across microservices and data stores.
AI agents performing tasks—identity resolution, sentiment analysis or next-best-action inference—coordinate through publish-subscribe, request-reply and scatter-gather patterns. For compute-intensive retraining jobs, the orchestrator parallelizes data partitions across AI nodes, aggregates results and promotes updated models to production. For example, an AI agent may enrich touchpoints, emit enrichment metadata to Kafka, update the profile store and trigger journey analytics refreshes—all within a tightly choreographed exchange.
Ensuring Technical Integrity and Observability
As datasets converge in the conclusion stage, maintaining consistency and transactional integrity is paramount. Idempotent operations ensure jobs can restart without creating duplicates. Two-phase commits coordinate atomic updates across multiple stores, while schema enforcement via a registry such as Confluent Schema Registry validates message payloads against defined Avro or JSON schemas.
Comprehensive observability underpins reliability and continuous improvement. Metrics collectors such as Prometheus scrape job durations, queue depths and error rates, feeding alerts and visualizations into dashboards. Centralized logging stacks, for example ELK, aggregate logs enriched with correlation IDs to enable cross-system tracing. An audit trail records every state transition—profile_enriched, model_evaluation_complete or campaign_dispatched—supporting compliance and root cause analysis.
- Idempotent data transformations to prevent duplication
- Two-phase commit protocols for atomic multi-store updates
- Schema validation via a centralized registry
- Metrics collection with Prometheus and visualization tooling
- Log aggregation and traceability through ELK or similar stacks
- Audit trails for state transitions and compliance reporting
A robust API layer and middleware framework encapsulate workflow logic as code. Workflow-as-code SDKs enable pipelines to be defined in Python or Java, versioned in repositories and extended without rewriting core logic. Policy engines enforce retry limits, timeout thresholds and resource quotas. Managed services such as AWS Step Functions provide serverless stateful workflows, simplifying deployment and scaling of conclusion processes.
Governance and security protocols woven into the conclusion stage ensure sensitive customer information is protected. Role-based access controls restrict report retrieval and orchestration updates. Data in transit and at rest is encrypted using industry-standard protocols with key management services rotating keys regularly. Orchestration logic enforces data retention and purge policies, and audit logs record security events, supporting regulatory audits and forensic investigations.
Strategic Impact and Business Outcomes
By operationalizing end-to-end AI workflows, organizations unlock transformative strategic benefits that extend well beyond efficiency gains. Predictive personalization engines such as Salesforce Einstein and AWS Personalize deliver contextually relevant recommendations in real time, shifting brand perception from transactional vendor to intuitive partner. Every micro-interaction—complementary product suggestions or timely promotions—builds competitive differentiation that is difficult to replicate without a mature orchestration framework.
Unified identity resolution, behavioral analytics and predictive modeling platforms such as Google Cloud AI Platform and Adobe Experience Platform support the transition from one-off transactions to continuous engagement models. Dynamic loyalty programs, subscription services and replenishment reminders drive recurring revenue, increase customer lifetime value and optimize marketing spend by targeting high-risk, high-opportunity segments.
Agility in the face of market disruptions is achieved through continuous monitoring and automated feedback loops powered by IBM Watson and TensorFlow Extended. Real-time anomaly detection and root-cause insights enable teams to pivot campaigns, reallocate inventory or adjust messaging with minimal lag, reinforcing brand resilience.
Centralized visibility into customer journeys and attribution across channels aligns marketing, merchandising, supply chain and executive leadership around a shared data fabric. Solutions such as Microsoft Azure Synapse Analytics integrate with Azure AI services to provide unified reporting, enabling investment decisions to be guided by predictive ROI models.
Embedding AI into journey orchestration platforms—leveraging open-source frameworks such as Apache Kafka for streaming and Kubeflow for ML pipelines—creates a living laboratory for innovation. Controlled rollouts and performance validations ensure incremental improvements scale to support emerging channels—voice assistants, augmented reality or IoT—without wholesale reengineering.
Proactive governance of data privacy, fairness and transparency through built-in explainability features reduces regulatory risk and fosters consumer trust. Ethical stewardship of AI becomes a competitive asset, attracting privacy-conscious customers and partners. Cross-functional collaboration is accelerated by low-code orchestration tools, cultivating a culture of data-driven decision making and continuous learning.
Scaling and Adapting for New Contexts
To support horizontal growth—new touchpoints, regional markets and increased data volumes—organizations produce tangible scalability artifacts and transition them into operational practice through clear handoff mechanisms.
Key Outputs
- Version-controlled deployment blueprints: Infrastructure-as-code templates for platforms such as AWS SageMaker and Snowflake, codifying high-availability cluster provisioning, autoscaling policies and network security.
- Scalability playbooks and runbooks: Step-by-step guides for capacity planning, failover tests and performance tuning, with diagnostics checklists and escalation paths for Site Reliability Engineering teams.
- Adaptation templates for channel extensions: JSON schemas, mapping rules and AI agent configurations tailored to new channels—voice assistants, connected devices or emerging social platforms.
- Automated CI/CD pipelines: Definitions in tools such as Jenkins or GitLab CI that automate code validation, model retraining, performance benchmarking and staged rollouts, with gating rules enforcing service-level objectives.
- Governance and compliance artifacts: Policy templates, audit logs and automated checks ensuring GDPR and CCPA adherence in new deployments.
Dependencies
- Core AI service mesh exposing stable API endpoints and telemetry streams
- Shared data lakes and warehouses with schema versioning and partitioning for performance at scale
- Orchestration and scheduling frameworks—Apache Airflow or Kubernetes CronJobs—supporting dynamic concurrency and backfill handling
- Mature observability stacks combining Prometheus, distributed tracing and log aggregation for capacity decisions
- Security and access control domains integrating with AWS IAM and Azure Active Directory
Handoff Mechanisms
- Release of deployment packages to DevOps via artifact repositories such as Nexus or Artifactory, accompanied by change logs and compatibility matrices
- Operational training and knowledge transfer through workshops, documentation and structured change management sessions
- Integration of compliance artifacts into governance workstreams with automated policy-as-code checks in CI/CD pipelines
- Feedback loops into the central AI Center of Excellence to refine templates and scaling parameters based on pilot performance metrics
- Triggering new channel onboarding projects via structured tickets in project management tools, ensuring stakeholder alignment and resource allocation
By codifying these outputs, dependencies and handoff processes, organizations ensure that every new context inherits the reliability, performance and governance posture of the established solution, minimizing risk and accelerating time to value.
Appendix
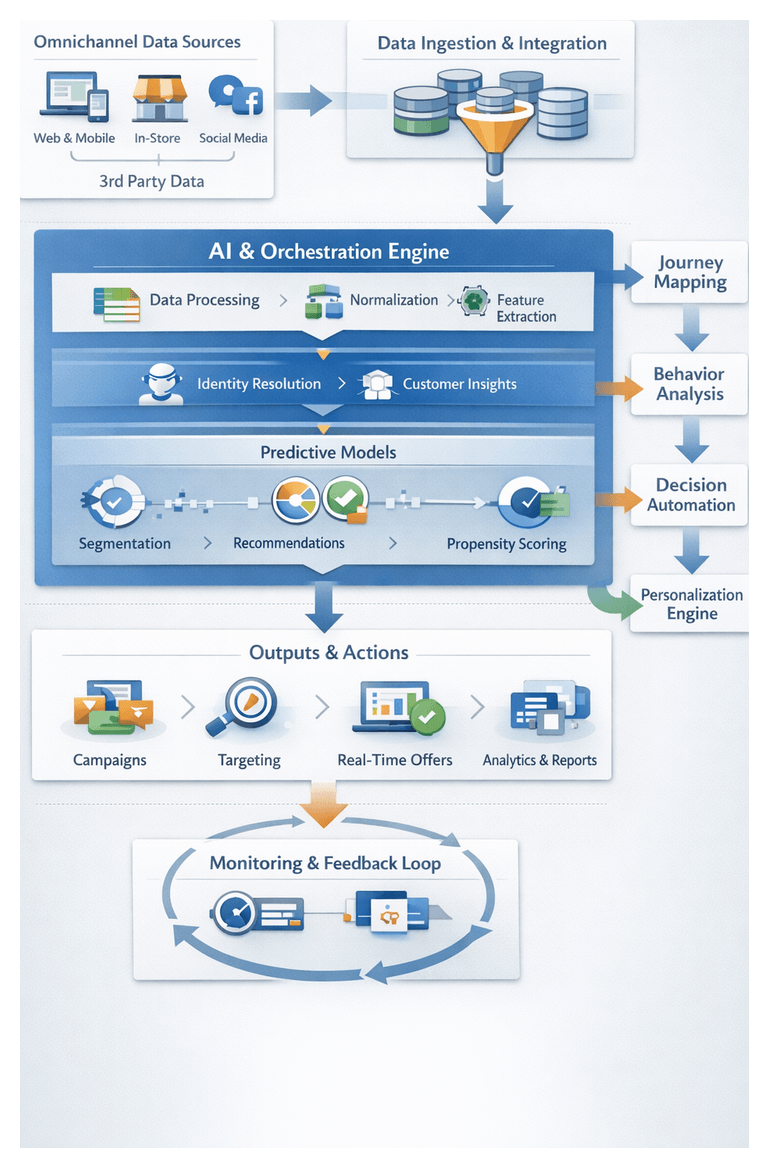
Key Terminology
Understanding the omnichannel AI workflow begins with a shared vocabulary spanning process orchestration, data management, machine learning and governance.
- Omnichannel: A unified approach that connects web, mobile, in-store, social and third-party platforms into a seamless customer experience.
- Stage: A distinct phase in a workflow defined by purpose, inputs, outputs and handoff criteria.
- Task: A discrete unit of work within a stage, such as data extraction, model inference or content generation.
- Orchestration Engine: Software that coordinates tasks and stages, enforces dependencies, handles retries and provides end-to-end visibility.
- Pipeline: A sequence of tasks and stages to process data or execute logic in order, scheduled or event-driven.
- Handoff: Transfer of artifacts or signals via APIs, message queues, file drops or event notifications.
- Dependency: A prerequisite relationship ensuring upstream outputs are ready before downstream processing.
- Trigger: A condition or event—new data arrival, schedule or user action—that initiates workflow execution.
- Service-Level Agreement (SLA): Defined performance metrics—latency, throughput, availability—for tasks or workflows.
- Batch Processing: Scheduled group processing for high-volume, non-time-sensitive workloads.
- Stream Processing: Real-time ingestion and handling of events for low-latency analytics and personalization.
- Data Ingestion: Collection of raw events and records from source systems into a central repository.
- Data Extraction: Retrieval of data from origins—APIs, databases, files—often via connectors or AI agents.
- Data Normalization: Converting diverse formats and conventions into a standardized schema.
- Data Integration: Merging normalized datasets into unified repositories.
- Data Harmonization: Coordinating schema mapping and transformation rules for semantic consistency.
- Master Data Management (MDM): Tools and methodology to maintain authoritative records of customers, products and channels.
- Feature Store: Centralized service storing precomputed ML features for training and inference.
- Data Lake: Scalable storage for raw and processed data supporting analytics and ML workloads.
- Data Warehouse: Structured database optimized for analytical queries and reporting.
- Metadata Catalog: Repository of schemas, lineage and transformation rules for governance and discovery.
- AI Agent: Autonomous component performing specialized tasks—extraction, classification, modeling—via ML and rule-based logic.
- Model Training: Fitting an ML algorithm to historical data and tuning parameters to minimize prediction error.
- Inference: Executing a trained model on new data to generate predictions or classifications.
- Supervised Learning: Training models on labeled datasets to predict target variables.
- Unsupervised Learning: Discovering patterns in unlabeled data through clustering or anomaly detection.
- Clustering: Grouping similar records based on feature similarity for segmentation.
- Classification: Assigning discrete labels—sentiment, event types—to records.
- Recommendation Engine: AI system suggesting products or content based on behavior and attributes.
- Predictive Model: Algorithm forecasting outcomes—purchase propensity, churn risk—based on historical inputs.
- Reinforcement Learning: Agents learning optimal actions through trial and feedback.
- Microservices: Modular services communicating over APIs for agility and scale.
- API Gateway: Central entry point routing, authenticating and monitoring API calls.
- Event-Driven Architecture: Managing state changes via published and consumed events.
- Message Broker: Middleware—Apache Kafka or RabbitMQ—that decouples producers and consumers.
- Containerization: Packaging services into portable containers such as Docker.
- Auto-Scaling: Adjusting compute resources dynamically based on workload metrics.
- Workflow DAG: Directed Acyclic Graph defining task dependencies in orchestration engines.
- CI/CD: Automated pipelines for building, testing and releasing code and ML models.
- Key Performance Indicator (KPI): Quantifiable measures—conversion rate, average order value—used to assess success.
- Attribution Model: Framework assigning credit to touchpoints in a customer journey.
- A/B Testing: Experiment comparing variants of campaigns or interfaces to determine effectiveness.
- Anomaly Detection: Identifying data or performance deviations with statistical or ML methods.
- Feedback Loop: Capturing outcomes—clicks, conversions—and feeding them back into model retraining.
- Model Drift: Degradation of model performance due to changing data distributions.
- Retraining: Updating models periodically or on events with new data to restore accuracy.
- Data Governance: Policies and controls managing data quality, lineage, privacy and access.
- Privacy by Design: Embedding data protection and consent mechanisms into architecture.
- Consent Management: Tracking customer preferences for data collection and communication.
- Audit Trail: Immutable logs recording data transformations and access for compliance.
- Role-Based Access Control (RBAC): Permissions granted based on user roles.
- Schema Versioning: Managing schema changes over time for backward compatibility.
AI Capabilities by Workflow Stage
Data Ingestion and Channel Capture
At intake, AI agents automate retrieval, parsing and normalization of customer interactions across channels.
- Adaptive Parsing Agents leverage supervised schema inference to classify JSON, XML and CSV. Examples include AWS Glue ML Transforms and OpenAI’s Document Parsing API.
- Anomaly Detection Engines such as Datadog Anomaly Detection and Azure Anomaly Detector flag malformed events via unsupervised models.
- Natural Language Preprocessors extract sentiment and entities from text using Google Cloud Natural Language API and IBM Watson Natural Language Understanding.
- Entity Extraction Agents apply named entity recognition with libraries like spaCy and Amazon Comprehend.
Supporting platforms include Apache Kafka, Amazon Kinesis and schema registries like Confluent Schema Registry to manage connector configurations.
Variations and edge cases:
- Batch-Only Legacy Systems: Scheduled pulls with watermark tracking ensure idempotency.
- Intermittent Connectivity: Edge agents buffer events locally with exponential back-off retry.
- Schema Drift: AI-powered inference agents detect changes against a registry and suggest mappings.
- High-Velocity Streams: Autoscale ingestion clusters, shard streams and apply back-pressure controls.
- IoT and Sensor Data: Use NLP and computer vision agents to parse unstructured sensor payloads.
Data Integration and Harmonization
AI modules consolidate disparate sources into a unified model via schema mapping, cleansing and entity resolution.
- Semantic Schema Matching uses embeddings to propose field mappings. Tools include Talend Data Catalog and Informatica Enterprise Data Catalog.
- AI-Driven Data Cleansing with probabilistic algorithms in Trifacta Wrangler and Paxata.
- MDM Services host identity graphs using IBM InfoSphere MDM and Stibo Systems for real-time entity resolution.
Orchestration engines schedule batch and streaming transformations, capturing lineage in metadata catalogs and audit logs.
Variations and edge cases:
- Multilingual Attribute Values: Translation services or multilingual NLP map localized terms.
- Conflicting Reference Data: MDM layer enforces a single source of truth for codes and hierarchies.
- Time Zone Alignment: Normalize timestamps to UTC while preserving original zone metadata.
- Duplicate Event Detection: Hash-based deduplication and anomaly detectors suppress repeats.
- Missing or Partial Attributes: Quarantine for enrichment, apply imputation models or manual review.
Identity Resolution and Profile Enrichment
Building single customer views combines deterministic rules, probabilistic models and graph analytics.
- Deterministic and Probabilistic Matching with tools like Bayard, RecordLinkage libraries and services such as AgentLinkAI Identity Resolution Service.
- Graph Analytics Engines use community detection in Neo4j and Amazon Neptune.
- Profile Enrichment Agents integrate third-party data via Clearbit, Neustar or Experian APIs.
Outputs feed segmentation and predictive modeling.
Variations and edge cases:
- Anonymous Sessions: Probabilistic matching on behavior patterns and demographic inferences.
- Guest Checkout Records: On-the-fly identifier creation with follow-up merges upon authentication.
- Conflicting PII: Supervised ML balances edit-distance metrics and historical merges.
- Privacy-Preserving Match: Tokenized PII and on-premise processing to comply with regional laws.
- High-Value Customer Scrutiny: Human-in-the-loop review for VIP segments.
Touchpoint Mapping and Journey Reconstruction
Sequence modeling and graph analysis reconstruct end-to-end customer journeys.
- Sequence Modeling Algorithms such as LSTM in TensorFlow and PyTorch.
- Graph-Based Path Analysis with GraphX on Apache Spark and Neo4j libraries.
- Anomaly Detection in Journeys using clustering (DBSCAN) to surface deviations.
Journey maps persist to data stores and visualize in BI or platforms like Pointillist and Thunderhead.
Variations and edge cases:
- Cross-Device Flows: Correlate device fingerprints and behavioral overlaps.
- Long Dormant Sessions: Use event-time windows to group or discard stale interactions.
- Invisible Interactions: Probabilistic inference integrates beacon pings and notification opens.
- Recurring Engagement Loops: Graph reconstruction detects loops to optimize intervention points.
- Partial data gaps can disrupt the flow of analysis, but implementing padding rules or inserting specific placeholder events ensures a seamless narrative. This approach allows for the preservation of context and continuity, enabling stakeholders to interpret the journey without losing critical insights. By strategically placing these elements, you enhance the clarity of the touchpoint mapping, making it easier to identify key interactions and their impact on the overall customer experience.
Segmentation and Cohort Analysis
Clustering and validation metrics identify homogeneous groups for targeting.
- Unsupervised Clustering via k-means, DBSCAN or hierarchical methods in scikit-learn, H2O.ai and Databricks MLlib.
- Dimensionality Reduction with PCA or t-SNE for visualization.
- Segment Stability Monitoring using silhouette scores and drift detection in Fiddler.
Segments inform campaign targeting and personalization.
Variations and edge cases:
- Sparse Historical Profiles: Cold-start techniques use demographic proxies or surveys.
- New Channel Adoption: Train NLP or sensor models and incorporate embeddings.
- Cross-Segment Overlap: Soft clustering with probabilistic membership and primary assignment rules.
- Segment Drift: Automated checks merge, split or retire cohorts based on performance.
- Regulatory Constraints: Exclude or anonymize sensitive features per GDPR and CCPA.
Behavioral and Sentiment Analysis
Advanced NLP and pattern recognition combine qualitative and quantitative feedback.
- Sentiment Analysis Models powered by transformers (BERT, RoBERTa) via AWS Comprehend, Google Cloud Natural Language API and Azure Text Analytics.
- Intent Classification using platforms like Rasa and Dialogflow.
- Topic Modeling with LDA or NMF in gensim.
Enriched records advance to predictive modeling and personalization.
Variations and edge cases:
- Multilingual Feedback: Route text via language detection to appropriate NLP or translation.
- Emoji and Slang: Specialized tokenizers and slang dictionaries interpret informal expressions.
- Sarcasm Detection: Supervised models distinguish ironic remarks.
- Voice Transcripts: Speech-to-text followed by NLP pipelines account for transcription errors.
- Low-Volume Channels: Aggregate signals over longer windows for stability.
Predictive Analytics and Next-Best-Action Models
Forecasting employs supervised and reinforcement learning to anticipate customer needs.
- Propensity Scoring Models using XGBoost, LightGBM or logistic regression.
- Time-Series Forecasting with ARIMA, Prophet or LSTM and managed solutions like Amazon Forecast.
- Reinforcement Learning Agents trained in OpenAI Gym and Ray RLlib.
- Model Explainability Tools such as SHAP and LIME.
Next-best-action engines integrate predictions and business rules via APIs.
Variations and edge cases:
- Imbalanced Data: Oversampling or SMOTE for rare outcomes.
- Seasonal Spikes: Include calendar features and align retraining with promotions.
- Feature Drift: Drift detection triggers model refresh.
- Scoring Latency: Precompute embeddings or cache top candidates.
- Cold-Start Forecasts: Use hierarchical forecasting or transfer learning.
Personalization Engine and Recommendation Delivery
Real-time inference services and connectors deliver tailored content across channels.
- Recommendation Algorithms via Amazon Personalize, Google Recommendations AI and Dynamic Yield.
- Template Selection Models in platforms like Optimizely X.
- Edge Personalization deploying inference on CDNs or mobile nodes.
APIs and SDKs integrate with CMS, email, push and in-store systems.
Variations and edge cases:
- API Rate Limits: Local caches and edge decision agents mitigate quotas.
- Payload Size Caps: Truncate lists or request top-scoring items.
- Offline Personalization: Batch exports for print or catalog channels.
- SDK Version Mismatch: Coordinate rollouts for backward compatibility.
- Content Rendering Errors: Default fallbacks and integrity checks.
Multichannel Campaign Orchestration
Decision engines and automation pipelines coordinate campaigns across channels and triggers.
- Decision Orchestration Platforms such as AgentLinkAI Orchestration and Adobe Campaign using rules engines like Drools.
- Automation Workflows managed by Azure Data Factory and Apache Airflow.
- Anomaly and Exception Paths route failures into corrective workflows or human-in-the-loop interventions.
Variations and edge cases:
- Concurrent Campaigns: Priority queues and suppression logic serialize sends.
- Time Zone Mismatches: Convert send times to each subscriber’s local zone.
- Transactional vs Promotional: Separate workflows to meet delivery SLAs.
- Opt-Out and Compliance Flags: Universal suppressions enforce consent across platforms.
- Vendor Constraints: Gateway feedback loops pause or reroute failing sends.
Monitoring, Attribution and Continuous Optimization
Insights and feedback loops drive ongoing improvement and model updates.
- Anomaly Detection Services in Datadog, Splunk and Azure Monitor.
- Attribution Modeling Engines such as Adobe Analytics Attribution IQ and Google Attribution 360.
- Optimization Recommendation Agents via Optimizely Full Stack.
- Model Retraining Orchestrators in MLflow, Kubeflow and Amazon SageMaker Pipelines.
Variations and edge cases:
- Untracked Offline Conversions: Loyalty integrations or post-visit surveys capture in-store purchases.
- Attribution Window Misalignment: Channel-specific lookback periods in models.
- Partial Delivery Data: Callback and retry mechanisms for bounces and undeliverables.
- Model Attribution Bias: Regular audits and weighting adjustments.
- Real-Time Fluctuations: Smoothing techniques and thresholds prevent false alerts.
Scalability and Adaptation for Diverse Retail Contexts
AI workflows must evolve with new markets, channels and regulations to remain resilient.
- New Market Taxonomies: AI agents auto-discover and propose schema extensions for regions.
- Marketplace Integrations: Adaptive connectors onboard proprietary partner formats.
- Subscription Models: Specialized churn models and lifecycle workflows.
- Regulatory Changes: Policy engines enforce data retention and compliance.
- Emerging Touchpoints: Modular pipelines accommodate novel payload schemas for voice, AR or IoT.
AI Tools and Platforms
- Amazon SageMaker is a fully managed ML service for building, training and deploying models at scale.
- Amazon Personalize delivers real-time individualized recommendations based on user behavior.
- Amazon Comprehend extracts sentiment, entities and key phrases from text.
- Google Cloud AI Platform provides an end-to-end ML development environment supporting TensorFlow and scikit-learn.
- Google Cloud Natural Language API offers sentiment analysis, entity recognition and syntactic parsing.
- Google Recommendations AI provides tailored product suggestions with Google’s ranking algorithms.
- Microsoft Azure Machine Learning accelerates ML development, deployment and MLOps with AutoML and drag-and-drop pipelines.
- Microsoft Azure Text Analytics delivers sentiment detection, key phrase extraction and opinion mining.
- IBM Watson Natural Language Understanding provides emotion analysis, semantic role labeling and sentiment detection.
- Apache Airflow is an open-source orchestration platform for scheduling and monitoring data pipelines.
- Azure Data Factory is a cloud ETL service for managing data pipelines across on-premises and cloud sources.
- Apache Kafka is a distributed event streaming platform for high-throughput real-time data.
- Amazon Kinesis provides managed real-time data streaming and analytics.
- Apache Spark is a unified analytics engine for batch and streaming workloads with MLlib.
- Databricks offers a Lakehouse platform combining data engineering, science and ML.
- Snowflake is a cloud data warehouse for scalable storage and analytics.
- Fivetran provides managed data integration with prebuilt connectors.
- Stitch is an extensible ETL service for replicating data into warehouses.
- Great Expectations is an open-source data validation framework for quality tests.
- H2O.ai is an open-source platform for AutoML and model interpretability.
- DataRobot automates end-to-end model development, deployment and monitoring.
- MLflow tracks experiments, packages code and manages model lifecycles.
- Hugging Face Transformers provides pretrained transformer models for NLP tasks.
- Neo4j is a graph database optimized for identity graphs and path analysis.
- Amazon Neptune is a managed graph database service for scalable graph applications.
The AugVation family of websites helps entrepreneurs, professionals, and teams apply AI in practical, real-world ways—through curated tools, proven workflows, and implementation-focused education. Explore the ecosystem below to find the right platform for your goals.
Ecosystem Directory
AugVation — The central hub for AI-enhanced digital products, guides, templates, and implementation toolkits.
Resource Link AI — A curated directory of AI tools, solution workflows, reviews, and practical learning resources.
Agent Link AI — AI agents and intelligent automation: orchestrated workflows, agent frameworks, and operational efficiency systems.
Business Link AI — AI for business strategy and operations: frameworks, use cases, and adoption guidance for leaders.
Content Link AI — AI-powered content creation and SEO: writing, publishing, multimedia, and scalable distribution workflows.
Design Link AI — AI for design and branding: creative tools, visual workflows, UX/UI acceleration, and design automation.
Developer Link AI — AI for builders: dev tools, APIs, frameworks, deployment strategies, and integration best practices.
Marketing Link AI — AI-driven marketing: automation, personalization, analytics, ad optimization, and performance growth.
Productivity Link AI — AI productivity systems: task efficiency, collaboration, knowledge workflows, and smarter daily execution.
Sales Link AI — AI for sales: lead generation, sales intelligence, conversation insights, CRM enhancement, and revenue optimization.
Want the fastest path? Start at AugVation to access the latest resources, then explore the rest of the ecosystem from there.