

Orchestrating AI Agents for End to End Data Analysis Workflows
To download this as a free PDF eBook and explore many others, please visit the AugVation webstore:
Introduction
Challenges of Fragmented Analytics Processes
Enterprises today generate enormous volumes of data across diverse systems, geographies, and business units. Without a unified analytics framework, information becomes trapped in departmental silos, manual handoffs introduce errors and delays, and critical insights arrive too late or not at all. Disconnected toolchains and legacy platforms amplify complexity, while inconsistent definitions and schema drift lead to broken reports and flawed models. As workloads grow, scalability constraints strain infrastructure, and security or compliance gaps expose organizations to risk. Cultural and organizational barriers further hinder collaboration, causing duplication of effort, redundant pipelines, and lost productivity.
- Data silos that limit visibility and collaboration
- Inconsistent definitions, formats, and schema drift
- Manual handoffs prone to delay and human error
- Latency issues impeding real-time or near-real-time analysis
- Lack of standardized processes, governance, and accountability
- Duplication of effort across teams and redundant pipelines
- Security, privacy, and compliance gaps in scattered systems
- Scalability and resource constraints under growing workloads
- Fragmented toolchains that increase integration complexity
- Cultural and organizational barriers that hinder collaboration
When data is isolated in on-premise databases, cloud services, or departmental spreadsheets, cross-functional reporting requires massive manual effort. Definitions such as “customer_id” versus “clientID” diverge across systems, and schema drift can trigger downstream failures without detection. Traditional handoffs involve exporting snapshots, spreadsheet cleansing, and email exchanges, each step introducing versioning errors and audit gaps. The result is delayed insights, reactive troubleshooting, and a growing backlog of unresolved data requests.
Consider a common scenario: a marketing team submits an analytics request, IT must approve elevated access to a vendor database, engineers write custom queries and export flat files, analysts discover missing fields and reopen tickets, and data scientists resort to manual imputation to meet deadlines. By the time senior leadership receives corrected analysis, the original campaign window has closed. This reactive cycle undermines agility, erodes trust in analytics, and wastes valuable resources.
AI Agents and Unified Orchestration
Transforming fragmented processes into an end-to-end, automated pipeline requires intelligent orchestration. Specialized AI agents operate at each stage of the analytics lifecycle—discovery, ingestion, profiling, cleansing, feature engineering, modeling, validation, and reporting—eliminating routine manual tasks and enabling teams to focus on strategic problem solving. These agents embed decision logic, self-learning capabilities, and metadata capture, ensuring consistent quality, governance, and auditability.
By autonomously detecting schema changes, triggering cleansing routines, recommending model configurations, and generating narrative summaries, AI agents remove bottlenecks and reduce time-to-insight. Centralized orchestration engines manage dependencies, scheduling, retries, and event-driven handoffs, providing real-time visibility into pipeline health and performance. As a result, organizations can scale analytics operations, enforce security policies, and maintain compliance—all while fostering cross-team collaboration and reducing technical debt.
Key AI Agent Capabilities Across the Analytics Lifecycle
- Discovery and Ingestion Agents: Scan enterprise catalogs, apply connector templates, and adapt to schema variations. Examples include Apache Airflow connectors and custom adaptive pipelines.
- Profiling and Cleansing Agents: Use statistical analysis and anomaly detection to generate quality metrics, classify outliers, and enforce standardization rules. Platforms such as H2O.ai illustrate automated rule enforcement.
- Feature Engineering Agents: Derive new variables, apply aggregations, integrate external enrichment, and assess feature importance. Solutions like DataRobot embed these capabilities within automated pipelines.
- Visualization and Pattern Recognition Agents: Generate interactive charts, detect clusters, and propose hypotheses. Tools such as Prefect and Kubeflow dashboards leverage embedded pattern detection.
- Modeling and Optimization Agents: Automate algorithm selection, hyperparameter tuning, and cross-validation. MLOps platforms like MLflow and DataRobot streamline experimentation and artifact management.
- Validation and Drift Detection Agents: Monitor production performance, detect concept drift, trigger alerts, and orchestrate retraining workflows.
- Simulation and Scenario Planning Agents: Run stress tests, Monte Carlo simulations, and risk analyses to support strategic decision making.
- Prescriptive and Optimization Agents: Solve resource allocation, pricing, and operational planning problems using linear programming, genetic algorithms, or heuristic search.
- Narrative Generation Agents: Employ generative language models to produce executive-grade summaries, embed visualizations, and tailor language to specific stakeholders.
- Orchestration and Governance Agents: Manage Directed Acyclic Graphs (DAGs), enforce dependencies, capture audit trails, and integrate with orchestration engines.
Supporting Systems and Integration Layers
AI agents depend on a robust ecosystem of metadata services, workflow engines, and MLOps platforms. These systems provide service discovery, configuration management, and execution environments that underpin reliable automation and scalability.
- Metadata and Data Catalogs: Central repositories for schema definitions, lineage graphs, and access policies. Examples include Apache Atlas and commercial governance platforms.
- Workflow Orchestration Engines: Coordinate agent tasks, manage scheduling, and handle retries. Common tools include Apache Airflow, Prefect, and Kubeflow.
- MLOps and Model Management Platforms: Track experiments, version models, and automate deployment. Platforms like MLflow and H2O.ai Driverless AI serve these roles.
- API Gateways and Microservices: Expose agent functions via REST or gRPC, enforce authentication, and route requests to internal services.
- Containerization and Orchestration: Docker and Kubernetes enable isolated, scalable runtime environments, service discovery, and rolling updates.
- Logging and Monitoring Frameworks: Centralized log aggregation, metrics collection, and alerting with Prometheus and Grafana support real-time observability.
Operational Benefits of AI-Driven Automation
- Reduced manual effort through automation of repetitive tasks
- Accelerated time-to-insight via parallelized, self-healing pipelines
- Consistent data quality with embedded validation and lineage tracking
- Scalability to accommodate growing data volumes and user demands
- Enhanced governance with audit trails and policy enforcement
- Improved cross-team collaboration using standardized interfaces
- Adaptive intelligence as agents learn from evolving patterns
Designing a Structured AI-Driven Workflow Framework
A well-defined framework serves as the blueprint for operationalizing AI-driven analytics. It sequences processes, assigns agent responsibilities, and specifies integration points, ensuring alignment with business objectives and minimizing fragmentation. The output of this design phase guides engineering teams, data scientists, and operations in executing a cohesive, scalable solution.
Key Deliverables
- Workflow Stage Sequence Specification: Diagrams and narratives detailing each stage from discovery through deployment, including inputs, outputs, conditionals, and exception paths.
- Agent Role and Communication Matrix: Mapping of agents, responsibilities, input parameters, and messaging protocols, referencing orchestration platforms such as Apache Airflow.
- Integration Interface Definitions: API contracts, message formats, and data schemas for connecting to data lakes, feature stores, model registries, and reporting platforms like Amazon SageMaker and several other listed on AgentLinkAI.
- Metadata Catalog and Lineage Mapping: Repository of schema definitions, transformation histories, and governance rules documenting dataset provenance and audit trails.
- Orchestration Configuration Artifacts: Templates for container manifests, scheduling parameters, and CI/CD pipelines that automate agent provisioning and lifecycle management.
Dependencies and Preconditions
- Data Platform Readiness: Availability of data lakes, warehouses, or streaming platforms compatible with agent runtimes and serialization formats.
- Security and Compliance Policies: Defined access controls, encryption standards, identity integrations, and audit logging in line with regulations.
- Agent Runtime Environment: Provisioned container orchestration (Kubernetes, Docker Swarm), monitoring tools, resource quotas, and auto-scaling rules.
- Integration Tooling and Licenses: Connectors, SDKs, and middleware for ETL platforms, message brokers, and external data sources.
- Governance and Stakeholder Alignment: A steering committee to approve schemas, naming conventions, and quality standards, with regular checkpoints to align technology with business goals.
Handoff Mechanisms to Execution Teams
- Version-Controlled Repositories: Storage of design documents, diagrams, and configuration templates in Git or equivalent systems with tagged releases.
- Automated CI/CD Pipelines: Integration of artifacts into delivery workflows where changes trigger validation and staging tests for agent coordination.
- Design Review Sessions: Workshops to walk through specifications, communication matrices, and interface definitions, generating actionable backlog items.
- Technical Readiness Checklists: Standard forms to confirm environment configurations, dependency installations, and access rights before development.
- Onboarding Guides and Templates: Preconfigured code and container templates referencing naming conventions, error-handling patterns, and logging standards.
Integration Points and Governance
- Data Source Connectors: Automated interfaces to on-premise databases, cloud storage, and SaaS applications, driven by metadata-driven connectors that adapt to schema changes.
- Feature Store APIs: Standardized endpoints for registering and retrieving features to ensure consistency across modeling teams.
- Model Registry Endpoints: Interfaces for versioning and publishing trained models to support validation and deployment workflows.
- Reporting and Visualization Platforms: Event-driven handoffs to tools such as Tableau and Power BI via RESTful endpoints for automated dashboard updates.
- Monitoring and Observability Services: Integration with log aggregation, metrics platforms, and alerting frameworks to ensure SLA compliance and proactive issue resolution.
Scalability and Future Extensibility
- Modular Agent Design: Self-contained agents that can be deployed, scaled, or replaced independently.
- Microservices and API-First Approach: Service-oriented components with well-defined interfaces for independent evolution.
- Metadata-Driven Configuration: Dynamic workflows driven by catalogs and configuration files to minimize code changes for new sources or rules.
- Elastic Compute and Storage: Cloud-native infrastructure and infrastructure-as-code templates that auto-scale with demand.
- Plug-In Frameworks for New Agents: Extension points that allow integration of future AI capabilities without major refactoring.
With this structured framework in place—articulating challenges, agent roles, integration layers, deliverables, and governance—organizations can transition seamlessly from design to production. The next stage focuses on deploying autonomous agents for data discovery and ingestion, guided by the artifacts, dependencies, and handoff protocols defined here.
Chapter 1: Data Discovery and Ingestion
The journey from dispersed raw data to actionable insights begins with a unified discovery and ingestion stage. This foundational phase defines objectives for connecting to relational databases, NoSQL stores, streaming platforms, file shares, APIs, and edge devices. AI-driven discovery agents automate the detection of new repositories, infer logical relationships between datasets, and adapt to schema changes. By centralizing source enumeration and metadata capture, organizations enforce consistent governance, streamline security reviews, and eliminate manual handoffs that delay insight generation. Scalable pipelines ingest structured, semi-structured, and unstructured data—ranging from event logs and sensor telemetry to social media feeds and multimedia assets—into a raw landing zone that primes downstream preparation, feature engineering, and modeling efforts.
Core Capabilities and AI-Driven Tools
Modern discovery and ingestion leverage intelligent agents and orchestration layers to deliver resilience, traceability, and performance at scale. Key capabilities include automated source cataloging, adaptive connector configuration, dynamic schema management, real-time streaming ingestion, and robust error handling. These functions are supported by specialized platforms and frameworks:
- Databricks Unity Catalog for unified metadata management.
- Apache NiFi for extensible connector plugins and data flow orchestration.
- Apache Kafka for high-throughput event streaming.
- AWS Glue Data Catalog, Azure Data Catalog, and Google Cloud Data Catalog for cloud metadata synchronization.
Discovery Agents and Metadata Harvesting
Discovery agents perform automated endpoint enumeration across on-premises and cloud environments. Adaptive crawlers probe storage locations, streaming topics, and API endpoints to harvest schema definitions, file structures, protocol requirements, and access credentials. Natural language processing and pattern recognition classify data domains, detect sensitive information, and assign contextual tags. Agents populate centralized catalogs—such as Databricks Unity Catalog—and maintain an up-to-date inventory that feeds governance engines and supports policy enforcement.
Adaptive Connector Configuration
Connector agents leverage AI to create and tune connectors for JDBC, REST, file-based, and streaming protocols. Machine learning models predict optimal batch sizes, parallelism levels, and polling intervals. When source interfaces evolve, agents detect API version changes or schema shifts and automatically adjust authentication methods, request parameters, or plugin versions. In Apache NiFi environments, agents orchestrate plugin management to ensure compatibility and security compliance.
Schema Evolution and Dynamic Mapping
Before ingestion, schema interpretation agents analyze source definitions and sample records, inferring field structures, data types, and nested hierarchies. Versioned schema registries track changes over time. Upon detecting new columns, type mutations, or reordering, agents validate impacts on downstream consumers, auto-generate mapping updates or flag anomalies for human review. Mapping templates govern type casting, naming conventions, and default value assignments, ensuring consistent staging schemas across diverse sources.
Batch Ingestion Workflow
Batch ingestion handles predictable, high-volume transfers with minimal latency requirements. The workflow steps include:
- Snapshot Capture: Agents query new or changed records using watermark or change data capture (CDC) markers to enable incremental extraction.
- Data Extraction: Connectors pull records into secure staging zones. Window sizes and polling intervals are optimized to protect source performance.
- Pre-Ingestion Validation: Validation agents inspect payloads for schema compliance, missing keys, and null constraints. Quarantined batches are rerouted for cleansing.
- Transformation and Enrichment: Transformation agents apply mapping templates to standardize field names, cast types, and add metadata such as source identifiers, extraction timestamps, and lineage IDs.
- Load into Staging: Processed batches are written to data lakes, object stores, or staging tables. Completion events are registered in the metadata catalog.
- Post-Load Verification: Verification agents reconcile record counts and checksums against source statistics. Discrepancies trigger retries or alert notifications.
Streaming Ingestion Workflow
Streaming pipelines deliver low-latency data feeds into analytics platforms. The sequence typically follows:
- Topic Provisioning: Provisioning agents create or update partitions on messaging brokers (e.g., Apache Kafka) to balance load.
- Event Capture: Source adapters publish events using HTTP callbacks, WebSockets, or proprietary push interfaces.
- Stream Processing: Agents subscribe to topics, applying in-motion transformations, deduplication, and timestamp normalization.
- Windowing and Aggregation: Events are grouped into tumbling or sliding windows for preliminary metric computations.
- Continuous Delivery: Enriched events are written continuously to real-time dashboards, data warehouses, or sandboxes via high-throughput connectors.
- Stream Monitoring: Monitoring agents track lag, throughput, and error rates. Threshold breaches trigger automated scaling or operator alerts.
Error Handling and Retry Mechanisms
Resilience is built into every ingestion workflow. Agents implement layered error handling:
- Connection Errors: Back-off and retry strategies for transient network or authentication failures, with escalation of persistent issues.
- Schema Mismatches: Fallback mappings or record quarantining for unexpected field types or missing columns.
- Data Quality Violations: Anomaly resolution agents divert critical anomalies—such as null primary keys—to cleansing queues or human operators.
- Resource Exhaustion: Dynamic scaling and throttling maintain stability under high load conditions.
Orchestration and Monitoring
A central orchestration layer coordinates agent tasks via RESTful APIs and message queues. Core components include:
- Task Scheduler: Manages execution windows, dependencies, and concurrency limits.
- Metadata Catalog: Stores connector definitions, schema versions, lineage, and performance metrics.
- Event Bus: Facilitates asynchronous communication, driving state transitions with events like “ingestion success” or “error detected.”
- Resource Manager: Allocates compute resources and orchestrates containerized agent deployments to meet SLAs.
- Alerting Service: Aggregates notifications from error handling agents and delivers them via email, chat, or dashboards.
Raw Data Consolidation and Handoff Protocols
Upon completion of ingestion, raw data consolidation establishes consistent storage, annotation, and communication of datasets for downstream preparation. Standardized deliverables include object storage files, staging tables, message queue topics, metadata manifests, and lineage records. By enforcing predictable folder structures, metadata tagging conventions, and event-driven notifications, organizations minimize handoff failures and ensure end-to-end traceability.
Raw Data Deliverables
- Object Storage Files in S3, Azure Data Lake Storage, or Google Cloud Storage (formats: JSON, Parquet, Avro, CSV)
- Staging Tables in data warehouses or relational databases preserving source schemas
- Message Queue Topics on systems like Apache Kafka or AWS Kinesis
- Metadata Manifests describing schema versions, record counts, checksums, and extraction timestamps
- Lineage Records in centralized metadata repositories linking data artifacts to origin systems and agents
Dependencies and System Integration
- Extraction Success Signals from agents feeding orchestration tools such as AWS Step Functions
- Schema Registry Access for compatibility and version control
- Storage Infrastructure Availability with sufficient capacity and performance
- Security and Access Controls compliant with GDPR, CCPA, or HIPAA mandates
- Catalog and Metadata Services
Handoff Mechanisms
- File Landing and Folder Structure: Organize raw files by source, date, and run ID (e.g., /raw/sourceA/2026-02-25/run_07/).
- Event Publication: Publish events with file URIs, record counts, and manifest references to messaging topics.
- Catalog Registration and Tagging: Register datasets in the data catalog with tags: sourceSystemId, schemaVersion, extractionTimestamp, storageLocation, lineageId.
- Orchestration Workflow Transitions: Trigger data preparation workflows upon successful handoff or send alerts on failures.
- Notification and Alerting: Inform stakeholders via email, chat, or dashboards with hyperlinks to logs, catalog entries, or diagnostics.
Metadata Tagging Conventions
- sourceSystemId: code representing the originating application (e.g., ERP_12)
- schemaVersion: semantic version number (e.g., v1.3.2)
- extractionTimestamp: ISO 8601 timestamp (e.g., 2026-02-25T14:30:00Z)
- ingestionRunId: UUID for each execution
- recordCount: integer count of ingested records
- checksum: MD5 or SHA-256 hash for integrity verification
Error Handling and Retries
- Automatic Retries with exponential back-off for transient failures
- Dead-Letter Queues for unresolved records and failure manifests
- Alert Escalation to on-call engineers with diagnostic details
- Audit Logs capturing structured actions for compliance and forensics
Operational Best Practices
- Leverage Incremental Ingestion and CDC to minimize resource consumption
- Implement Data Compression and Partitioning to improve storage efficiency
- Enforce Schema Evolution Policies for compatibility and data integrity
- Adopt a Unified Orchestration Layer with platforms like Azure Data Factory or Google Cloud Dataflow
- Maintain a Centralized Data Catalog with automated metadata harvesting
- Regularly Review and Optimize SLAs with upstream and downstream stakeholders
Transition to Data Preparation and Cleaning
With raw data consolidated and handoff protocols executed, cleaning agents subscribe to event triggers, retrieve artifacts, and commence profiling. Guaranteed conditions include accessible URIs, comprehensive metadata manifests, automated workflow activation, and exception queues for human review. These foundations empower downstream AI-driven feature engineering and modeling to proceed with high-quality, traceable inputs.
Connecting to Enterprise Data Sources
The foundation of a unified analytics workflow lies in automated discovery and secure connectivity to every data repository across cloud, on-premise, and third-party systems. AI-driven agents scan warehouses, databases, file shares, APIs, and streaming platforms to build a consolidated inventory of data assets, schemas, access protocols, and quality indicators. This eliminates manual integration bottlenecks, uncovers hidden silos, and ensures downstream processes operate on a complete, governed data foundation.
Key Objectives
- Comprehensive Source Identification: Detect all structured and unstructured repositories, including under-utilized or private assets.
- Schema Interpretation and Profiling: Assess field definitions, data types, and distributions to guide ingestion logic.
- Metadata Cataloging: Enrich asset records with lineage pointers, sensitivity labels, owner details, and refresh schedules.
- Access Validation: Verify connectivity, authentication, and authorization settings to prevent runtime failures.
- Prioritization: Rank sources by strategic value, data volume, and recency to optimize ingestion order.
Inputs and Deliverables
- Credentials and Network Details: Secure tokens, certificates, VPC/subnet info, firewall rules, and proxy settings.
- Prioritization Criteria and Glossary: Business rules ranking sources and a seed dictionary of known entities.
- Agent Configuration Profiles: Templates specifying protocols (JDBC, REST, SFTP), scanning frequency, and resource quotas.
- Consolidated Inventory: Searchable catalog of detected repositories with standardized identifiers.
- Schema Extracts and Connectivity Report: Machine-readable definitions (JSON/XML) and status summaries with remediation guidance.
- Metadata Registry: Enriched asset descriptions supporting governance and self-service discovery.
Prerequisites and Handoff Conditions
- Infrastructure Readiness: Pre-provisioned network access, approved scanning windows, and containerized or serverless agent deployment.
- Governance Policies: Classification frameworks (GDPR, CCPA), masking rules, and retention guidelines.
- Logging and Audit Trails: Centralized systems capturing connection attempts, schema changes, and anomalies.
- Stakeholder Alignment: Agreed source prioritization, maintenance windows, and escalation procedures.
- Handoff Protocols: Versioned catalogs (JSON Schema or Apache Atlas), standardized metadata formats, and connectivity validation reports.
Integration with platforms delivers adaptive connector generation, intelligent schema matching, anomaly alerts, and self-service catalog interfaces, closing the loop on metadata enrichment and source management.
Profiling and Detecting Data Anomalies
Once sources are connected, an orchestration layer triggers profiling agents to compute summary statistics—counts, min/max values, null rates, histograms—and index schema definitions in a metadata catalog. Profiling tasks execute via RESTful APIs or JDBC drivers against data lakes and warehouses, with progress and metrics streamed to a monitoring dashboard.
- Orchestration polls ingestion outputs and retrieves dataset identifiers.
- Profiling agents compute aggregates and store field definitions in the catalog.
- Anomaly detection compares current metrics to historical baselines and thresholds.
- Alerts for deviations feed into an anomaly resolution queue.
A decision engine classifies anomalies—distinguishing schema evolution from data corruption—and invokes schema-evolution agents to update connectors and rerun profiling when necessary. This automated feedback loop ensures consistent awareness of data health and readiness for cleansing.
Automated Cleansing and Standardization
Following detection, a cleansing workflow applies domain-specific rules to standardize, deduplicate, impute, and enforce data types. A centralized rule repository, accessible via API, supplies transformations that execute in stages over a distributed messaging bus.
- Rule Retrieval: Fetch format patterns, value mappings, and null-handling directives.
- Bulk Standardization: Apply global normalization—date formatting, numeric scaling, text casing.
- Inconsistency Resolution: Use record linkage algorithms to identify and merge duplicates.
- Null Handling: Impute, delete, or insert placeholders based on field criticality.
- Type Enforcement: Coerce data to target schema types, capturing conversion errors for review.
Status messages and error logs publish to a centralized event store, powering dashboards for throughput, error rates, and processing durations. When automated rules cannot resolve an anomaly, a human-in-the-loop interface alerts data stewards to review samples, update rule definitions, and resume processing.
AI-Driven Rules Enforcement and Anomaly Resolution
Detection and Classification
- Statistical Profiling Engines compute dynamic baselines and flag outliers without manual threshold tuning.
- Classification Models leveraging Great Expectations categorize anomalies—format violations, referential errors, business rule conflicts.
- Metadata-Aware Contextualization using platforms like Collibra refines classification by applying semantic context and lineage information.
- NLP Modules inspect semi-structured text for sentiment shifts and terminology inconsistencies.
Rule Generation and Refinement
- Automated Rule Synthesis analyzes historical corrections to propose new validation rules.
- Active Learning Workflows present recommended rules with confidence scores for steward approval.
- Versioned Rule Repository via Informatica Data Quality tracks rule versions, approvals, and deployments.
- Policy Alignment cross-references regulatory libraries to ensure compliance.
Automated Remediation and Validation
- Pattern-Based Corrections apply transformation templates for phone, address, and date fields.
- Predictive Imputation using H2O.ai models estimates missing values from correlated features.
- Master Data Reconciliation enforces golden records by matching duplicates against authoritative sources.
- Transactional Rollbacks and version control ensure safe reversal of corrections.
Validation agents re-run classification models, verify referential integrity, and update lineage metadata to confirm that remediations adhere to rules without introducing new anomalies.
Continuous Learning and Integration
- Expert Review Dashboards and feedback loops refine models based on steward decisions.
- Automated Retraining via Amazon SageMaker updates classification and imputation models.
- Performance Monitoring tracks precision, remediation accuracy, and false positive rates.
- Orchestration with Apache Airflow or Azure Data Factory handles scheduling, dependencies, and SLAs.
- Collaboration via Jira or ServiceNow tickets streamlines escalation of complex anomalies.
Clean Dataset Delivery and Integration Handoffs
Output Artifacts
- Schema and Formats: Clean datasets in Parquet, Avro, or relational tables with embedded definitions.
- Metadata and Quality Metrics: Completeness, uniqueness, validity, and consistency scores attached to each field.
- Lineage and Provenance: Graphs linking raw sources, applied rules, steward decisions, and outputs.
Dependency Tracking and Version Control
- Dependency Graphs visualize relationships among sources, agents, and outputs.
- Automated Change Detection triggers reprocessing on rule or connector updates.
- Semantic Versioning encodes schema evolution and quality threshold conformance.
Handoff Protocols
- Secure Storage and Access: Role-based permissions on data lakes, warehouses, or catalog-managed URIs.
- Notification Triggers: Event payloads with dataset identifiers, versions, and lineage links.
- API Access: RESTful or gRPC endpoints exposing datasets under defined contracts.
Integration with Feature Engineering and Compliance
- Metadata Catalog APIs list available datasets and quality profiles for self-service discovery.
- Orchestration Workflows in Apache Airflow sequence cleaning and feature-derivation tasks.
- Shared Storage Mounts in Databricks enable direct table access.
- Audit Logs, Digital Signatures, and Access Reviews ensure traceability and regulatory compliance.
Example Implementation Pattern
- A Trifacta pipeline transforms raw data into cleaned Parquet tables in S3.
- Trifacta emits an AWS SNS event with dataset URIs and lineage pointers.
- Apache Airflow captures the message, validates output against Git-stored schemas, and updates the data catalog.
- Feature engineering DAGs then load the validated tables for analytic feature derivation.
Summary of Deliverables
- Validated, schema-compliant datasets in production-ready repositories.
- Rich metadata and lineage documentation for auditability.
- Automated notifications and orchestration triggers for downstream stages.
- Governance controls ensuring secure, compliant data access.
- Monitoring and versioning strategies to manage dataset evolution.
Chapter 3: Feature Engineering and Enrichment
Defining Feature Objectives and Inputs
Feature engineering is the stage where cleansed data is transformed into structured variables that drive predictive models, simulations, and decision-support systems. A formal feature definition process aligns data signals with business priorities, accelerates time-to-model, and ensures governance. Clear objectives and comprehensive inputs prevent ad hoc efforts, rework, and suboptimal outcomes.
Evolution and Importance
Traditional feature creation relied on manual coding in Python or R, limiting scale across enterprises. AI-driven frameworks embedded domain heuristics and meta-learning to recommend transformations, validate new variables against quality benchmarks, and automate repetitive tasks. This shift frees data teams to focus on strategic alignment, interpretation of model outputs, and reuse of high-value features.
Primary Objectives
- Business Alignment: Map features to measurable metrics—customer lifetime value, processing time reductions—to translate model outputs into strategic insights.
- Predictive Performance: Prioritize variables that maximize accuracy, reduce error rates, or improve AUC.
- Parsimony and Scalability: Select a minimal feature set that captures maximal information and supports templating for new domains.
- Interpretability: Ensure transparent transformations and clear naming conventions for stakeholder trust.
- Operational Feasibility: Define acceptable latency and resource constraints for production generation.
Core Inputs and Prerequisites
- Cleaned and Standardized Data: Free of invalid values, duplicates, and inconsistencies.
- Metadata and Data Dictionary: Field definitions, data types, lineage, and sampling timestamps.
- Business Metric Specifications: Documented targets and KPIs guiding optimization goals.
- Domain Knowledge Artifacts: Ontologies, ER diagrams, and stakeholder heuristics for rule-based transformations.
- External Enrichment Sources: Geolocation, weather, social sentiment, or economic indices invoked via connectors.
- Transformation Libraries: Access to tools such as Featuretools, DataRobot Autopilot, H2O.ai Driverless AI, or Amazon SageMaker Autopilot.
- Compute Environment: Batch and real-time configurations with container orchestration parameters.
- Governance Guidelines: Data retention, PII handling, anonymization, and consent policies.
- Versioning and Lineage Trackers: Systems recording transformation code versions and experiment metadata.
Aligning Business Goals to Feature Strategies
- Identify top-level outcomes—revenue growth, cost reduction, fraud prevention.
- Define analytical use cases—classification, regression, anomaly detection.
- Translate outcomes into metrics—recall at set false positive rates, error thresholds.
- Host ideation workshops with domain experts to brainstorm and prioritize candidate features.
- Apply scoring matrices to rank ideas by impact, complexity, and compliance risk.
Success Criteria and Environment Preconditions
- Completeness Thresholds: Minimum non-null percentages per field.
- Freshness Windows: Latency limits for time-sensitive inputs.
- Quality Benchmarks: Statistical range checks and distribution tests.
- Scalable Infrastructure: Distributed frameworks (Spark, Dask) or serverless compute.
- Feature Store Integration: Low-latency feature serving for training and inference.
- CI/CD for Analytics: Orchestration tools (Airflow, Prefect) with Git integration.
- Monitoring and Logging: Data drift signals, processing metrics, and error tracking.
- Stakeholder Roles: Data engineers, scientists, domain experts, compliance officers, ML engineers, and architects collaborating on inputs and validations.
- Feedback Loops: Define protocols for drift detection, model explainability reports, and iterative feature refinement.
Transformation and Derivation Workflow
The transformation phase bridges raw inputs and enriched features through automated operations orchestrated by AI agents. This stage applies normalization, scaling, encoding, aggregations, and statistical derivations, integrates external data, and validates outputs against governance standards. Automation ensures consistency, reduces manual coding, and accelerates time-to-insight.
System Components and Actors
- Orchestration Engine—such as Azure Data Factory or AWS Glue—manages task sequencing and retries.
- Transformation Agent—executes AI-generated scripts or code templates.
- Metadata Store—houses definitions, lineage, and version history.
- Data Processing Cluster—scalable compute resources via Apache Spark on Databricks or AWS Glue.
- External Connectors—invoke third-party APIs and reference datasets.
- Monitoring Services—track execution metrics, anomalies, and trigger alerts.
Step-By-Step Process Flow
- Ingest Specifications: Retrieve transformation logic, source fields, aggregation windows, and target formats from the metadata store.
- Pre-Profiling: Compute summary statistics to guide algorithm selection and detect distribution shifts.
- Execute Transformations: Apply scaling, encoding, date-time extraction, and normalization with full context logging.
- Derive and Synthesize: Generate rolling averages, ratios, composite scores, and time-window aggregates.
- External Enrichment: Append demographic or environmental attributes from connectors to services like WeatherAPI or OpenWeatherMap.
- Validation: Enforce null thresholds, range constraints, and statistical consistency tests with automated rollback on failure.
- Lineage Recording: Update metadata with versioned transformation parameters, agent identifiers, and timestamps.
- Handoff: Package enriched features into feature store tables or Parquet files for modeling via APIs or data contracts.
Orchestration Patterns and Collaboration
Event-driven pipelines trigger transformations upon data arrival, while scheduled jobs ensure periodic updates. Hybrid architectures combine real-time message queues with batch frameworks. Human analysts define parameters, review derivation rules via interactive interfaces, and provide annotations that AI agents use to refine future transformations.
Tooling Considerations
- Compute Scalability—distributed engines like Spark or serverless models for elasticity.
- Feature Store Integration—platforms such as Featuretools to manage and serve features.
- Security and Governance—access controls, encryption, and audit logging.
- Extensibility—plug-in architectures for custom transformations.
- Monitoring and Alerting—central dashboards for drift, latency, and errors.
Agent Strategies for Automated Feature Creation and Enrichment
AI agents accelerate feature discovery, transformation, and enrichment by leveraging meta-learning, statistical analysis, and external data integration. Centralized governance systems enforce policies, naming conventions, and lineage tracking, ensuring transparency and compliance.
Key Agent Roles and Interfaces
- Discovery Agents—statistical profiling, correlation analysis, pattern extraction, and schema exploration to propose candidates.
- Transformation Agents—apply mathematical, encoding, aggregation, and extraction operations in the most efficient execution environment.
- Enrichment Agents—ingest third-party data via dynamic connectors, align entities, synchronize temporally, and validate quality.
- Evaluation Agents—rank features using mutual information, chi-square, SHAP values, permutation importance, and cross-validation.
- Meta-Learning Agents—match current dataset meta-features to historical experiments, reuse proven pipelines, and update recommendations.
- Governance Systems—feature catalogs and metadata stores for lineage, naming, quality annotations, and access controls.
- Orchestration Platform—coordinates dependencies, scheduling, error handling, and resource allocation.
Continuous Feedback and Refinement
- Monitor model performance for feature-specific drift and trigger re-engineering workflows.
- Automate retraining when drift thresholds are exceeded.
- Capture domain expert feedback on feature utility to inform discovery agents.
- Maintain version control of feature pipelines and enable rollbacks.
By orchestrating these agents with governance systems, organizations build an automated, scalable, and auditable feature creation process that feeds directly into predictive modeling.
Packaging Enriched Feature Sets and Dependencies
Concluding feature engineering, enriched feature sets must be packaged, documented, and handed off with clear dependency information. Standardized deliverables and protocols ensure reproducibility, traceability, and seamless integration with modeling pipelines.
Output Artifacts
- Feature Matrix—tabular dataset aligned to primary keys or timestamps.
- Schema Definition—machine-readable descriptor (JSON Schema, Avro) of names, types, and ranges.
- Feature Dictionary—human-readable metadata with business definitions, logic, and units.
- Lineage Logs—records of source data, version identifiers, and transformation scripts.
- Pipeline Specifications—DAG configurations or job manifests.
- Dataset Snapshot—semantic version tag or timestamped marker for rollback and comparison.
Dependency Management
- Source Data References—connection details, schema versions, and extraction timestamps.
- Transformation Code Links—repository commits, notebook versions, or script archives.
- Parameter Records—stored thresholds, window lengths, and aggregation rules.
- Lineage Graphs—visual or machine-readable maps of raw data through transformations, supported by tools like Featuretools.
Packaging and Deployment
- Modular Archives—versioned ZIP or TAR bundles of matrices, schemas, and documentation.
- Containerization—Docker images encapsulating computation code for consistent environments.
- Semantic Versioning—MAJOR.MINOR.PATCH for breaking changes, additions, and metadata updates.
- Virtual Views—materialized or virtual tables in the data warehouse for direct querying by modeling agents.
Feature Store Integration
- Automated Ingestion—CI/CD pipelines pushing artifacts via APIs in platforms such as H2O.ai Driverless AI and DataRobot.
- Metadata Synchronization—programmatic upload of descriptions, lineage, and ownership.
- Access Controls—role-based permissions for reading approved versions and writing rights for governance teams.
- Discovery Interfaces—searchable catalogs promoting reuse and consistency across projects.
Handoff Protocols and Governance
- API Endpoints—RESTful or gRPC services for retrieving feature sets by version, supporting filtering and metadata queries.
- Manifest Files—YAML or JSON manifests enumerating available versions, locations, and parameters.
- Event Notifications—messages via Kafka or SNS triggering modeling jobs on feature publication.
- Approval Gates—sign-off steps for data stewards before production release.
- Audit Trails—immutable logs of publish, update, and rollback actions with user identity and timestamps.
- Regulatory Tags—sensitivity classifications and retention policies embedded in metadata.
- Notification Services—automated alerts via email, Slack, or Teams for stakeholders.
Best Practices
- Standardize names with clear prefixes or suffixes for domain, units, and aggregation levels.
- Document transformation logic with both human-readable descriptions and code references.
- Version early and often to simplify rollback and parallel testing.
- Enforce automated validation in CI pipelines before publication.
- Foster feature reuse via searchable catalogs and cross-team review sessions.
Adherence to these practices ensures analytical rigor, accelerates model development, and sustains enterprise-wide collaboration and compliance.
Chapter 4: Exploratory Data Analysis
Objectives and Prerequisites of Exploratory Visualization
The exploratory visualization stage transforms cleansed and enriched datasets into intuitive visual representations that reveal patterns, distributions, and anomalies. By converting complex numerical outputs into charts, graphs, and interactive dashboards, this stage empowers analysts and stakeholders to validate assumptions, uncover latent relationships, and align findings with business objectives. Visualization agents leverage machine learning and pattern-recognition algorithms to automate the generation of summaries, accelerating insight delivery and reducing manual effort.
Key aims include identifying outliers that may indicate data quality issues or emerging trends, mapping the trajectory of performance indicators over time, and guiding hypothesis refinement. In regulated industries such as finance, healthcare, and manufacturing, rigorous exploratory analysis ensures transparency, auditability, and compliance with standards. Dynamic real-time visual feedback on streaming data feeds supports both batch and live scenarios, enabling alerts on threshold breaches like spikes in customer churn or inventory anomalies.
Well-structured visualizations annotated with metadata become the foundation for downstream reporting and narrative generation. Standardizing outputs with tags for chart type, data source, variable definitions, and agent version ensures seamless handoff to narrative engines and reporting interfaces.
Required Inputs
- Cleansed and enriched dataset with standardized schemas and feature definitions
- Metadata repository detailing variable descriptions, data lineage, and quality scores
- List of analytical hypotheses, business metrics, and key performance indicators
- Visualization templates or style guides aligned to corporate branding and accessibility standards
- User persona profiles defining access levels, analytical roles, and preferred formats
- Domain reference materials such as taxonomies, glossaries, and regulatory requirements
- Configuration files for AI visualization agents specifying algorithm parameters and update frequencies
Technical Preconditions
- Access to a scalable visualization platform (for example, Tableau or Microsoft Power BI)
- Compute resources—CPU, memory, GPU—sized for interactive graphics and large datasets
- Connectivity to data warehouses, lakes, or real-time message queues
- APIs and SDKs configured for AI agents to read, write, and update dashboards
- Authentication and authorization mechanisms—OAuth tokens, LDAP integration—to control access
- Logging and monitoring infrastructure capturing agent performance and errors
- Version control and change management protocols governing dashboard updates
Dashboards and Pattern Discovery Workflow
The dashboards and pattern discovery workflow orchestrates AI-driven agents, visualization engines, and metadata repositories to produce dynamic, context-aware dashboards. It surfaces correlations, clusters, anomalies, and trends through interactive panels, guiding users toward actionable hypotheses. Central to the workflow are entry triggers, orchestration logic, pattern detection, interactive refinement, and handoff artifacts.
Workflow Entry and Initialization
The process begins when a supervisory orchestration agent publishes an event upon delivery of an enriched feature dataset and completion of pattern detection. This event enters a bus like Kafka or AWS EventBridge. A visualization orchestrator agent retrieves dataset metadata from a catalog such as Apache Atlas or Microsoft Purview, establishes a secure connection to the data lake or warehouse, and performs schema validation, data sampling, template selection, and resource allocation via platforms like Tableau or Power BI.
Pattern Detection Routines
Specialized AI-driven agents execute automated routines to detect statistically significant relationships:
- Correlation Analysis: Pairwise Pearson or Spearman computations visualized as heatmaps
- Clustering Identification: Unsupervised algorithms such as K-Means or DBSCAN via DataRobot
- Anomaly Detection: Isolation forests or autoencoder models flagging outliers in high dimensions
- Trend Extraction: Time series decomposition isolating seasonality, trend, and residuals
Results feed back into the dashboard engine via APIs or direct database writes, enabling real-time annotation of heatmaps, scatter plots, and geo-maps.
Interactive Refinement Loop
Analysts interact with dashboards to refine insights. Actions include drill-downs for deeper slices, parameter adjustments for clustering or correlation thresholds, annotation for audit trails, and visualization swaps. A user interaction agent captures events that trigger targeted sub-workflows such as new data fetches or pattern re-computations. The orchestration agent maintains session state for rollback or variant comparisons.
Automated Iterative Enhancement
An adaptive recommendation agent applies reinforcement learning to propose dashboard refinements. It logs actions and outcomes, assigns rewards based on engagement and model performance uplift, updates its policy, and delivers context-aware prompts within the UI. This closed-loop ensures that dashboards evolve with analyst preferences and data characteristics.
Error Handling and Observability
A logging agent collects API latencies, compute utilization, and data anomalies. In case of failures, the system retries operations with exponential backoff and escalates alerts via channels like Slack or Microsoft Teams. Audit logs in a central observability platform support root cause analysis and governance compliance.
Handoff Artifacts and Best Practices
Upon sign-off, final dashboards, annotated metadata, and interaction logs are packaged for downstream teams. Deliverables include:
- Dashboard definition files capturing layout, data sources, and settings
- Pattern metadata records listing correlation pairs, cluster IDs, and anomaly scores
- Exploration session reports with time-sequenced logs of user actions and recommendations
These artifacts are checkpointed in version control and registered with lineage systems, ensuring modeling agents can retrieve precise contexts for feature selection and algorithm training. Best practices include maintaining modular template libraries, metadata-driven orchestration, user-centric feedback loops, and scalable infrastructure.
Capabilities of AI-Driven Visualization and Pattern Recognition Agents
AI-driven visualization agents automate the transformation of datasets into actionable graphical summaries. Pattern recognition agents specialize in extracting higher-order structures. Together, they accelerate insight generation and reduce cognitive load.
- Automated Correlation Analysis: Agents compute Pearson, Spearman, and non-parametric correlations, rendering heatmaps where color gradients reflect association strength.
- Dynamic Clustering and Segmentation: Unsupervised algorithms such as K-Means, DBSCAN, t-SNE, or UMAP group observations and project clusters onto scatter diagrams or multidimensional plots.
- Anomaly and Outlier Detection: Density estimation, isolation forests, and autoencoder models flag deviations, overlaid as highlights on time-series or scatter visuals.
- Contextual Annotation: Natural language modules generate tooltips and summaries, explaining spikes or shifts by correlating external events or related metrics.
- Interactive Drill-Down: Users click chart segments to spawn focused sub-visualizations without manual query building.
- Adaptive Visualization Selection: Agents choose optimal chart types—histogram, box plot, network diagram—based on metadata and analysis objectives.
Pattern Recognition Agents in Practice
- Temporal Pattern Agent: Spectral analysis and change point detection annotate cycles, seasonality, and regime shifts on series plots.
- Spatial Correlation Agent: Metrics like Moran’s I and Getis-Ord Gi\* overlay clusters on choropleth maps for geospatial insights.
- Multivariate Interaction Agent: Partial dependence plots and SHAP interactions reveal joint feature influences on target metrics.
- Trend Extrapolation Agent: Regression models with confidence intervals project future scenarios on line charts.
- Graph and Network Analysis Agent: Force-directed layouts and community detection visualize relational data, highlighting central hubs and connectors.
Supporting Infrastructure Roles
- High-Performance Compute Cluster: GPU-accelerated and distributed nodes power real-time analytics with frameworks like Apache Spark.
- Data Access and Caching Layer: In-memory caches or columnar stores such as Apache Parquet enable sub-second retrieval of slices and aggregates.
- Visualization Libraries and Dashboards: Front-end frameworks like Plotly, D3.js, and platforms such as Microsoft Power BI or Tableau render interactive visuals.
- Message Bus and Event Streaming: Apache Kafka or AWS Kinesis ensure dashboards reflect current data via event-driven refreshes.
- Model Registry and Metadata Store: Central registries version models and templates, enforcing governance and lineage.
- API Gateway and Access Control: Role-based permissions secure agent endpoints for third-party integration.
- Orchestration Engine: Managers such as Apache Airflow or Prefect coordinate data retrieval, inference, and updates with retry logic and logging.
Integration Strategies
- Embedded Agent Widgets: Self-contained widgets embed visualization and pattern logic within BI tools or web portals.
- API-First Microservices: RESTful or gRPC APIs expose agent functionality for custom front ends and cross-unit reuse.
- Event-Driven Trigger Models: Agents subscribe to data change events or schedules, refreshing visuals and alerting stakeholders on emerging patterns.
Insight Reports and Analysis Handoffs
At the conclusion of exploratory analysis, structured insight reports and formal handoffs ensure seamless transition to predictive modeling. Outputs translate patterns into deliverables that support reproducibility, stakeholder alignment, and governance.
- Interactive dashboards and visualizations
- Static summary reports and documentation
- Annotated analysis notebooks
- Derived data artifacts and metadata packages
Interactive dashboards, built on Tableau or Power BI, allow parameterized exploration of correlation matrices, distribution plots, and time series analyses. Static reports synthesize key findings into paginated PDFs or HTML documents, ensuring offline reference. Analysis notebooks in Jupyter or Databricks combine code, visuals, and narrative for full transparency and reproducibility. Derived artifacts—filtered datasets, correlation matrices, and summary tables—are delivered in Parquet or CSV alongside JSON schemas.
Handoffs rely on precise dependencies:
- Versioned cleansed datasets from data preparation
- Feature schemas and data dictionaries from profiling
- Business glossaries from a data catalog
- Environment configurations for compute and visualization libraries
- User feedback from interactive review sessions
Metadata tags—source system identifiers, lineage, and quality metrics—accompany each artifact. Integration with a governance platform such as Alation ensures discoverable lineage and provenance.
Common handoff mechanisms include:
- Artifact repositories or document management systems with access controls and version histories
- Automated BI platform deployments publishing dashboards to shared workspaces
- Data catalog registrations ingesting datasets and metadata for programmatic discovery
- Event streams triggering downstream workflows and notifications upon artifact publication
Technical protocols underpinning handoffs include:
- RESTful API endpoints on data services for on-demand retrieval
- Secure file shares or cloud buckets with IAM policies
- Automated workflows orchestrated by Dagster or Apache Airflow
- CI/CD pipelines versioning notebooks and reports for analytics environments
Best practices for report and handoff management:
- Standardized naming conventions encoding project IDs, data versions, and artifact types
- Metadata headers documenting authoring agent, timestamps, and data sources
- Semantic tags linking metrics to business objectives in the governance catalog
- Strict version control enabling rollbacks
- Automated validation scripts for metadata completeness and schema conformity
A typical modeling intake package includes direct links to dashboards, downloadable reports, notebook repository URLs, dataset locations, and a metadata manifest. Integration with tools like MLflow allows data scientists to trace model performance back to specific exploratory insights. Governance demands audit logs recording artifact access, validation checks, and agent-orchestrated publishing. Containerized environments or notebook manifests capture package versions and compute configurations. A feedback loop via BI comments or project tickets ensures continuous dialogue between exploratory and modeling teams, refining analyses and enhancing collaboration.
Chapter 5: Predictive Modeling Orchestration
Modeling Objectives and Strategic Alignment
The predictive modeling stage transforms curated feature datasets into actionable insights, driving forecasts, classifications, and recommendations at enterprise scale. Defining clear objectives aligns algorithm selection, training processes, and evaluation metrics with business imperatives—whether inventory optimization, risk scoring, or customer churn prediction. Articulating target outcomes and acceptable error thresholds ensures that automated orchestration agents configure workflows to meet performance, interpretability, and compliance requirements. Embedding strategic goals into the modeling blueprint guides resource allocation decisions, balancing compute intensity, inference latency, and operational agility to maximize business impact.
Inputs and Operational Prerequisites
Automated modeling relies on a comprehensive set of inputs and conditions to ensure reproducibility, governance, and technical readiness.
Feature and Label Definitions
Agents retrieve versioned feature matrices from centralized feature stores, with clear documentation of transformation logic, source fields, and update cadences to support consistency across training and inference. Target labels—binary classes, multi-class tags, or numeric values—must be precisely defined to prevent data leakage. Orchestration systems validate label completeness, temporal alignment with feature windows, and distribution stability to ensure effective generalization.
Metadata, Lineage, and Historical Baselines
Rich metadata captures dataset versions, ingestion timestamps, data quality metrics, and transformation histories, enabling audit trails and impact analysis. Lineage information links each feature back to its origin, satisfying governance and regulatory requirements. Baseline performance metrics from previous cycles—logged by frameworks such as scikit-learn, TensorFlow, or PyTorch—provide reference points for evaluating candidate models and preventing regressions.
Infrastructure, Access Controls, and Quality Gates
Orchestrators integrate with compute platforms—on-premise Kubernetes clusters and cloud services like Azure Machine Learning, Amazon SageMaker, and Google Vertex AI—to provision CPU, GPU, or accelerator resources. Automated data quality checks gate datasets against missing values, distribution shifts, and schema changes. Secure authentication and least-privilege policies ensure agents access only approved datasets and encrypted artifact repositories, with audit logs supporting SOC2 and GDPR compliance.
Automated Algorithm Selection and Training Workflow
A mature analytics workflow orchestrates algorithm evaluation, hyperparameter optimization, and model evaluation through coordinated AI agents and orchestration layers. This flow accelerates time-to-model while enforcing consistent criteria and governance controls.
Experiment Initialization
The orchestration engine aggregates cleaned feature sets, metadata, and modeling objectives from the project configuration repository. Through an API call, the Experiment Manager initiates a session in an experiment tracking platform such as MLflow, performing actions that include:
- Registering experiment parameters and artifacts
- Allocating unique identifiers for result aggregation
- Establishing communication channels between compute nodes and the tracking system
- Validating input schema against model requirements
Algorithm Candidate Generation and Ranking
The Algorithm Selection agent consults an algorithm catalog—spanning linear models, random forests, gradient boosting, deep neural networks, and ensemble frameworks—and uses historical performance logs to prioritize candidates. It adapts selections based on data characteristics such as dimensionality and class imbalance, ranking algorithms by estimated resource consumption, training time, and predictive potential. This ranking informs compute scheduling and shapes hyperparameter search strategies.
Hyperparameter Optimization and Resource Allocation
Once candidates are chosen, the Hyperparameter Tuning agent defines search spaces and budgets, leveraging methods like grid search, Bayesian optimization, or AutoML solutions such as DataRobot and H2O.ai. The Resource Manager negotiates with the compute orchestration layer—powered by Kubernetes or Apache Airflow—to provision training environments, schedule containerized jobs, and monitor resource budgets. Coordination steps include:
- Defining parameter spaces and evaluation budgets
- Requesting compute instances via cluster APIs
- Packaging jobs into Docker containers with pre-installed dependencies
- Publishing job status updates to messaging systems such as Apache Kafka
Training Execution and Monitoring
The Training Execution agent oversees job health, streams loss and accuracy metrics to the Experiment Manager, and integrates with monitoring tools—Prometheus for system metrics and TensorBoard for model statistics. It enforces early stopping criteria, retries failed tasks, and archives model checkpoints at defined intervals. In preemptible environments, checkpoints are restored automatically to minimize progress loss.
Experiment Tracking and Metadata Management
The Metadata Manager captures hyperparameter values, convergence metrics, dataset versions, and code commit identifiers in the tracking system. Consistent tagging enables traceability from input data to trained artifacts, supports comparative analysis, and fulfills audit requirements. Metadata APIs ensure downstream stages access experiment details seamlessly.
Result Evaluation and Model Selection
Upon training completion, the Evaluation agent aggregates metrics—AUC, F1 score, MAE, inference latency—and applies predefined thresholds to filter top performers. Approved models are registered in the Model Registry, and detailed performance reports are published to reporting dashboards. Notifications trigger the Model Validation stage, ensuring only rigorously evaluated artifacts advance.
Scalability and Parallelization Strategies
To meet enterprise demands, the Parallelization agent fragments hyperparameter searches and model configurations, distributing tasks across multi-node clusters. Data sharding and vectorized processing accelerate throughput, while cloud autoscaling adjusts cluster size based on queue depth. This elastic resource management maximizes cost-performance efficiency without manual intervention.
Key Integration Points
- API endpoints for feature store retrieval
- MLflow SDK for real-time logging
- Message bus topics for job status notifications
- Compute cluster APIs for resource provisioning
- Model Registry interfaces for artifact publishing
Machine Learning Agents and System Roles
Machine learning agents automate the end-to-end model building lifecycle, coordinating training orchestration, resource management, experiment logging, and candidate recommendation. By abstracting infrastructure management, these agents allow data scientists to focus on hypothesis testing and model interpretability.
Training Orchestration Agents
Training orchestration agents translate high-level specifications into executable pipelines, provisioning environments on platforms such as AWS SageMaker and Google Vertex AI. They schedule distributed training tasks, monitor resource utilization, and handle failures or preemptions, retrying or migrating tasks to maintain throughput.
Experiment Tracking Agents
Experiment tracking agents log metadata—hyperparameters, performance curves, dataset versions, code commits—into systems like MLflow or internal stores. Unique run identifiers, real-time metric archiving, and artifact storage enable reproducible research and support regulatory audits.
Automated Model Selection Agents
Selection agents rank trained models using composite scoring functions aligned with business objectives. Advanced implementations leverage meta-learning to recommend promising hyperparameter regions based on historical data, accelerating convergence and reducing compute waste.
Resource Allocation and Parallelism Agents
These agents assess workload characteristics—data size, algorithm complexity—and select appropriate execution modes, integrating with Kubernetes to launch isolated training pods. Auto-scaling policies adjust resources based on queue depth, delivering elastic capacity in response to demand.
Integration with Validation Pipelines
Upon selection, agents package model artifacts—serialized weights, preprocessing code, environment specifications—and publish manifest files describing dependencies and performance. Downstream validation agents detect new models via metadata catalogs, triggering cross-validation, bias assessments, and compliance checks. This end-to-end traceability preserves consistency from data preparation to validated production models.
Model Outputs, Packaging, and Handoff Protocols
At the conclusion of modeling, AI agents produce deliverables—model binaries, configuration files, performance metrics, and metadata—that underpin validation and deployment.
Artifact Types and Formats
- Serialized Models: Python pickle, TensorFlow SavedModel
- Interchange Formats: ONNX, scikit-learn joblib
- Container Images: Docker bundles encapsulating runtimes
- Configuration Manifests: YAML or JSON detailing hyperparameters and feature mappings
- Feature Pipelines: Serialized transformers or scripts capturing preprocessing logic
Metadata, Lineage, and Dependency Management
- Data References: URIs to raw and processed datasets
- Version Tags: Semantic versions, commit hashes, build numbers
- Execution Logs: Structured logs of agent actions and resource metrics
- Performance Summaries: Tables of accuracy, precision, recall, and latency
- Environment Specs: Conda or pip requirements.txt and Dockerfiles
Packaging Standards and Registry Integration
Agents adhere to model exchange protocols—PMML for statistical models, ONNX for cross-framework interoperability, and MLflow Model Format for centralized management. Artifacts are registered in model registries—MLflow Model Registry, Kubeflow Metadata, or enterprise repositories—with stage tags, access policies, and governance metadata.
Handoff to Validation and Deployment
- API Transfers: RESTful endpoints accept model bundles and return validation job IDs
- Message Queues: Notifications via Kafka or RabbitMQ trigger validation workflows
- Storage Watches: Object storage events initiate validation pipelines
- Orchestration Hooks: Kubeflow Pipelines or Airflow tasks ensure seamless stage transitions
Notification, Governance, and Security
- Automated Alerts: Summaries posted to Slack or Microsoft Teams with artifact links
- Dashboard Updates: Real-time modeling progress and pending validations
- Version Control: Git tags, branches, and pull request identifiers linked to artifacts
- Security Scans: Container vulnerability assessments and data privacy checks
- Audit Trails: Immutable logs recording agent actions and approvals
Through rigorous definition of objectives, curated inputs, automated orchestration, and disciplined artifact management, organizations establish a high-velocity, reproducible modeling pipeline. This integrated ecosystem of AI-driven agents and orchestration services accelerates predictive insights while upholding governance, compliance, and operational excellence.
Chapter 6: Model Validation and Monitoring
Purpose of Model Validation
The validation stage serves as the critical checkpoint between model training and deployment, confirming that predictive models meet predefined performance criteria and behave reliably on unseen data. By evaluating outputs against real-world benchmarks, organizations mitigate risks related to overfitting, data drift, and unintended bias. Validation transforms a model from a black-box artifact into a production-ready asset with documented reliability metrics and governance controls.
In regulated industries such as finance, healthcare, and telecommunications, thorough validation provides evidence to satisfy compliance requirements. In dynamic markets, it ensures models maintain forecast accuracy as conditions evolve. Across all sectors, robust validation underpins stakeholder confidence, reduces costly errors, and establishes a foundation for continuous improvement.
Key Inputs and Prerequisites
Effective validation relies on clearly defined inputs and a stable environment. These include:
- Test Datasets: Hold-out data that mirrors production distributions, including seasonality and rare events.
- Validation Metrics: Core measures—accuracy, precision, recall, AUC-ROC, mean absolute error—or domain-specific KPIs with defined acceptance thresholds.
- Baseline Models: Reference systems or rule-based models for comparative performance evaluation.
- Feature Metadata: Documentation of data sources, transformation pipelines, and quality indicators to support reproducibility.
- Operational Constraints: Latency budgets, memory limits, and throughput targets aligned with service-level agreements.
- Versioning and Registry: Centralized tracking of dataset versions, metric evaluations, and model artifacts via MLflow or TensorFlow Extended.
Before validation begins, teams must ensure:
- Data Quality Assurance: Profiling to confirm completeness, correct labeling, and absence of systemic errors.
- Environment Parity: Replication of production infrastructure using platforms like AWS SageMaker or Azure Machine Learning.
- Access Controls and Governance: Role-based permissions, audit logs, and approval workflows for threshold changes and dataset modifications.
- Baseline Benchmarking: Agreed performance metrics and edge-case scenarios documented and approved by stakeholders.
- Monitoring Infrastructure: Logging frameworks and agents configured to capture inference logs, resource usage, and error rates during validation runs.
- Automated Orchestration: Integration of validation tasks into pipelines managed by Apache Airflow or Kubeflow Pipelines.
Validation Workflow and System Architecture
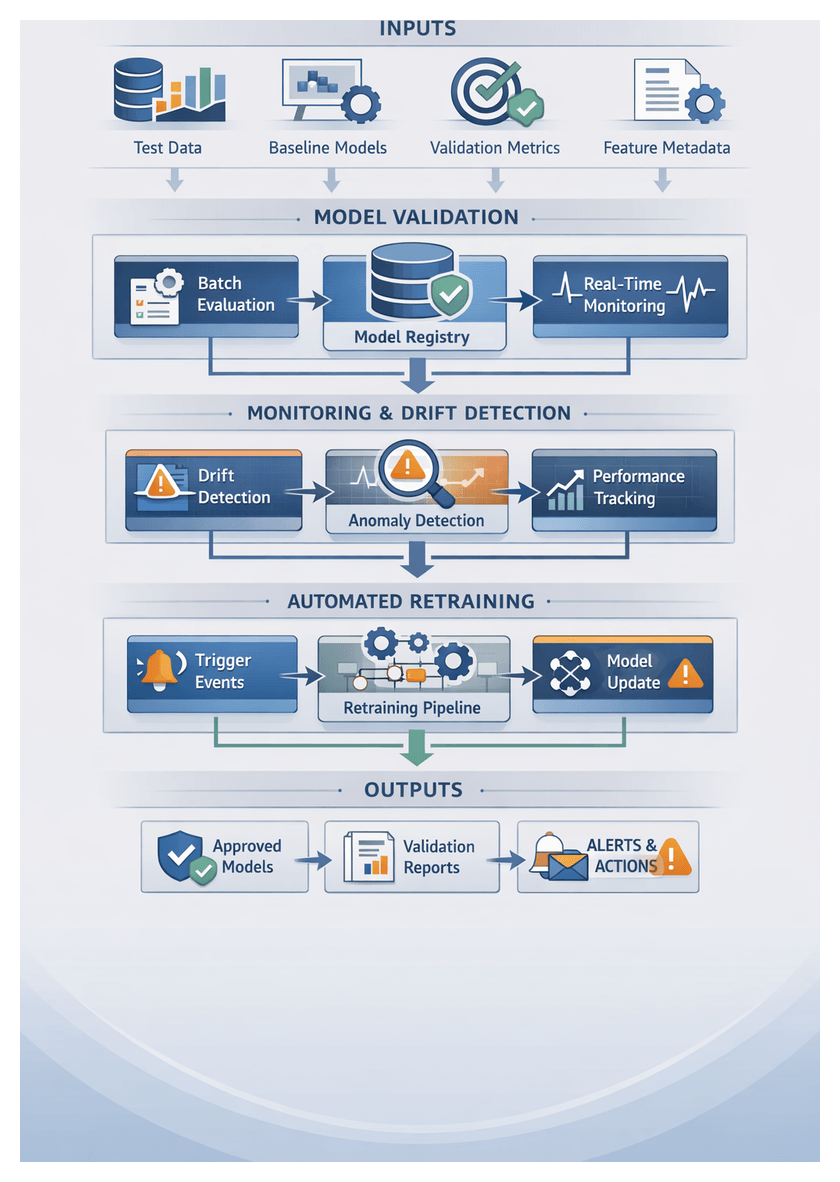
The validation workflow comprises batch validation, real-time monitoring, and feedback integration. Models are first evaluated against hold-out datasets and KPIs. Approved models are registered in a central repository, while monitoring agents track live performance to detect drift. Deviations trigger alerts and retraining workflows, ensuring only validated models remain in production.
System interactions span data lakes or feature stores, model registries, metrics stores, streaming platforms, and observability tools. A typical data pipeline:
- Batch Evaluation Pipeline: Ingests test datasets from a feature store, retrieves model artifacts from MLflow, computes metrics, and writes results to Prometheus or an enterprise warehouse.
- Real-Time Ingestion: Uses Apache Kafka to stream production data. Monitoring agents compute statistical summaries and push them to time-series databases for trend analysis.
- Observability Integration: Correlates inference logs, container metrics, and infrastructure telemetry with platforms like Datadog and Grafana.
- Alerting: Configured to notify stakeholders via email, Slack, or ServiceNow when thresholds are breached.
Batch Validation Sequence
- Schedule Evaluation: Triggered by a cron job or detection of new model versions in the registry.
- Retrieve Test Data: Fetch hold-out datasets and labels from the feature store.
- Load Model: Download the candidate model via the registry API.
- Compute Metrics: Execute evaluation routines for classification or regression KPIs.
- Compare Thresholds: Validate metrics against predefined benchmarks stored in a configuration repository.
- Update Registry: Mark the model as approved or rejected and record the validation report.
Failures notify data science and engineering teams with detailed reports, guiding corrective actions.
Real-Time Monitoring and Drift Detection
- Stream Ingestion: Drift Detection Agent subscribes to Kafka topics or cloud streaming services.
- Compute Drift Metrics: Continuously calculate population stability index, Kullback–Leibler divergence, or other measures.
- Evaluate Alerts: Compare metrics against sensitivity thresholds in the monitoring configuration.
- Trigger Events: Publish drift or anomaly events to the message bus.
- Initiate Investigation: Alerting Agent logs incidents in ServiceNow or Jira, enriches tickets with logs and performance trends.
AI-Driven Monitoring Agents and Automated Retraining
Specialized monitoring agents and trigger systems ensure models maintain accuracy and relevance. These components automate detection of performance degradation and initiation of retraining workflows, reducing manual oversight.
- Statistical Drift Detection: Methods such as PSI and Kolmogorov-Smirnov tests identify feature distribution shifts.
- Performance Alerts: Track accuracy, precision, recall, and AUC to trigger notifications when metrics fall below thresholds.
- Anomaly Classification: Unsupervised learning distinguishes normal variability from significant deviations.
- Adaptive Thresholding: Reinforcement learning or Bayesian optimization adjusts alert levels based on historical trends.
- Resource Monitoring: Observe compute, memory, and I/O usage to maintain service-level objectives.
Agents may leverage Amazon SageMaker Model Monitor, Kubeflow Pipelines modules, Prometheus collectors with Grafana dashboards, or DataDog anomaly detection rules.
When drift or degradation is detected, automated retraining triggers initiate end-to-end pipelines. Key components include:
- Trigger Evaluation Service: A decision engine that applies business rules and retraining policies.
- Pipeline Orchestration: Hooks into Apache Airflow or AWS SageMaker Pipelines to launch data ingestion, feature engineering, training, and validation jobs.
- Configuration Management: Dynamic injection of hyperparameters, dataset references, and version identifiers for reproducibility.
- Version Control Coordination: Interaction with MLflow or Git repositories to archive artifacts and tag new model versions.
- Automated Test Gates: Data quality checks, performance benchmarks, and bias detection integrated into the retraining workflow.
Platforms like Neptune.ai and Weights & Biases can fire webhooks to rerun pipelines when monitored metrics drop below thresholds.
Integration with MLOps infrastructure involves:
- Event Bus Architecture: Apache Kafka or AWS EventBridge to publish alerts and retraining commands.
- Service Mesh: Istio or Linkerd for secure communication among microservices.
- Unified Metadata Store: MLflow Tracking or AWS Glue Data Catalog for audit trails.
- RBAC: Kubernetes or cloud IAM permissions to control agent actions.
These components form a closed feedback loop, enabling continuous data collection, incremental model updates, performance benchmarking, and automated documentation generation. Over time, meta-learning processes refine monitoring configurations and feature engineering strategies.
Operational Best Practices:
- Define Acceptance Criteria: Document quantitative benchmarks for drift, latency, and resource usage.
- Human-in-the-Loop Oversight: Include review steps for critical retraining events.
- Alert Prioritization: Configure multi-channel notifications for timely response.
- Audit Trail Preservation: Store logs of monitoring events and retraining workflows in immutable storage.
- Scalability Testing: Simulate peak loads to validate pipeline reliability.
- Security and Privacy: Encrypt data, anonymize sensitive features, and enforce access controls.
Validation Reporting and Feedback Handoffs
Validation produces structured deliverables and handoffs that drive continuous improvement across teams and processes. Key report artifacts include:
- Performance Metric Summaries: Tabulated KPIs contrasting training and hold-out results.
- Visual Diagnostics: Confusion matrices, ROC and precision-recall curves, calibration plots, and residual charts.
- Drift Analysis Reports: Time-series plots and statistical test outcomes highlighting distribution shifts.
- Anomaly Logs: Detailed listings of outlier predictions with contextual metadata.
- Model Version Metadata: Manifests of artifact identifiers, data snapshots, transformations, hyperparameters, and code commits.
- Executive Summary: Narrative overview for non-technical stakeholders outlining health, risks, and recommendations.
Dependencies and lineage are recorded for test datasets, feature store pipelines, model registry entries in MLflow, monitoring configuration profiles, and ground truth data feeds. Automated systems capture provenance to support debugging and auditability.
Automated Handoff Protocols
- Validation Completion Event: Publishes model version and status to a message broker such as Apache Kafka or RabbitMQ.
- Alert Engine: Parses events, compares metrics to thresholds, and dispatches notifications via email, Slack, or ticketing systems.
- Retraining Invocation: CI/CD pipelines fetch updated training data, rerun feature engineering, rebuild the model, and execute validation checks.
- Approval Gateways: Data stewards and compliance officers review artifacts before authorizing retraining or redeployment.
- Feedback Loop Records: Logs of all decisions, user or agent identities, and rationale stored in a central audit database.
Integration with Production Monitoring
- Real-Time Dashboards: Grafana visualizes live performance against validation baselines with overlayed drift signals.
- Metric Aggregators: Prometheus ingests custom validation metrics and triggers alerts.
- Model Governance Portals: ModelOps dashboard consolidates validation reports and deployment histories.
- Data Quality Gatekeepers: Frameworks that alert data engineering teams to upstream anomalies flagged during validation.
Stakeholder Reporting and Governance Handovers
- Scheduled Distributions: Automated PDF or HTML summaries delivered regularly to defined mailing lists.
- Interactive Reviews: Dashboard links embedded in calendar invites for model review sessions with stakeholders.
- Policy Exception Logging: Documentation of tolerated performance dips with defined remediation timelines.
- Regulatory Submission Packages: Bundled reports, audit trails, and approval records for compliance reviews.
Governance, Audit Trails, and Compliance Integration
Transparent audit trails and governance controls are mandatory in regulated environments. Core requirements include:
- Immutable Experiment Logs: Timestamped artifacts, metrics, configurations, and environment specs tracked by DataRobot or MLflow.
- Version Control: Git-based repositories for code, feature transformations, and test datasets, tagging each model with commit IDs.
- Approval Workflows: Multi-stage sign-offs with digital signatures and notifications documenting authorization timestamps.
- Access Logs: Records of user interactions, configuration changes, and permission grants monitored via RBAC and SSO.
- Retention Policies: Data retention schedules aligned with governance standards, archiving or purging old runs as needed.
Key Performance Indicators and Scalability Considerations
Measuring validation and monitoring effectiveness requires tracking both process and outcome KPIs:
- Validation Latency: Time from model artifact availability to validation completion.
- Detection Lead Time: Interval between drift onset and alert generation.
- Retraining Cycle Time: Duration from retraining trigger to redeployment of the refreshed model.
- Uptime and Reliability: Percentage of operational availability for validation and monitoring agents.
- Alert Precision: Ratio of true performance issues to total alerts.
- Compliance Adherence: Number of audit exceptions relative to checks performed.
Scalability and resilience are achieved through microservices architecture on Kubernetes, event-driven design with back-pressure management via Apache Flink, fault tolerance using retries and dead-letter queues, data partitioning by model or tenant, and multi-region deployments with automated failover. Embedding health check endpoints enables the orchestration layer to replace unhealthy instances automatically, ensuring continuous, reliable validation and monitoring at enterprise scale.
Chapter 7: Simulation and Scenario Planning
Purpose and Context of Scenario Planning
The Scenario Definition and Input Gathering stage establishes the foundation for robust, AI-powered simulation and scenario planning. Teams begin by aligning on high-level objectives, cataloging internal and external data sources, and defining governance policies. By clearly specifying parameters, variables, and data elements, organizations ensure that simulation agents operate on a coherent, well-structured set of assumptions. This preparatory work reduces iteration cycles, minimizes stakeholder misalignment, and enhances the credibility of scenario outcomes.
Traditional approaches to forecasting—manual spreadsheets and ad hoc workshops—struggle to keep pace with growing market volatility, regulatory shifts, and supply chain disruptions. Modern frameworks leverage AI-driven tools to process vast data sets, explore hundreds of parameter combinations, and deliver insights in hours rather than weeks. Yet rigorous input gathering remains essential: inputs govern the fidelity of simulations, guide agent behaviors, and determine the relevance of results for strategic decision making.
Key Inputs, Stakeholder Alignment, and Technical Prerequisites
Effective scenario planning depends on a structured collection of inputs, clear roles and responsibilities, robust infrastructure, and governance controls. Front-loading effort in this stage amplifies the value of downstream AI orchestration and accelerates time-to-insight.
Data Sources and Variables
- Historical Performance Data: Time-series records of sales, costs, production volumes, and customer demand establish baseline trends.
- External Market Indicators: Interest rates, inflation, commodity prices, and competitive activities drawn from public APIs or third-party feeds.
- Operational Constraints: Inventory levels, capacity limits, labor availability, supplier lead times, and logistics parameters.
- Risk Factors: Supply chain shocks, regulatory changes, currency fluctuations, cybersecurity events, and other disruptions.
- Strategic Parameters: Planning horizons, decision thresholds, target KPIs, and scenario labels reflecting executive priorities.
- Qualitative Inputs: Expert judgments, narrative assumptions, and survey results capturing uncertainties not easily quantified.
Stakeholder Alignment and Decision Criteria
- Objective-Setting Workshops: Collaborative sessions with executives, risk managers, finance, operations, and legal teams to agree on scenario purposes and success criteria.
- Decision Matrix Development: Mapping scenarios to outcomes such as resource reallocations, contingency plans, or strategic pivots.
- Approval Workflows: Defined processes for sign-off on scenario definitions, assumptions, and parameter ranges.
- Documentation Standards: Templates and naming conventions to capture input metadata, version histories, and rationale.
Technical and Infrastructure Requirements
- Data Connectivity: Secure integrations with ERP, CRM, data lakes, and cloud storage platforms.
- Compute Resources: Scalable clusters or cloud-based GPU/CPU instances to support parallel simulation workloads.
- Agent Orchestration Platform: A management solution capable of scheduling, monitoring, and scaling simulation agents.
- API Endpoints and ETL Services: Automated pipelines to extract, transform, and load inputs into agent-accessible repositories.
- Version Control and Audit Logs: Systems to track changes to input definitions, parameter sets, and agent configurations.
Governance and Compliance Controls
- Data Privacy: Role-based access restrictions and encryption mechanisms for sensitive data.
- Regulatory Validation: Checks against financial reporting standards, healthcare privacy rules, or supply chain transparency requirements.
- Audit Mechanisms: Automated logging of data access, input modifications, and stakeholder approvals.
- Risk Mitigation Policies: Protocols for handling data anomalies, input discrepancies, or unauthorized changes.
Simulation Workflow and Parameter Variation
The Simulation Workflow stage transforms static predictive models into dynamic, AI-orchestrated processes capable of stress-testing assumptions and quantifying uncertainties across a range of conditions. Automated agents coordinate parameter generation, distribute computational tasks, monitor execution, and consolidate results for downstream interpretation.
Core Workflow Steps
- Scenario Initialization
- Parameter Generation and Variation
- Parallel Simulation Execution
- Result Aggregation and Normalization
- Quality Assurance and Error Handling
- Result Publication and Notification
Scenario Initialization
A Scenario Planner Agent reads definitions from a centralized repository, validates schemas against a metadata catalog, and applies context-specific constraints such as regulatory limits. It creates unique execution identifiers, configures logging namespaces, and allocates storage resources in the analytics environment.
Parameter Generation and Variation
The Parameter Variation Agent employs AI-driven sampling techniques—Latin hypercube sampling, Monte Carlo methods, factorial designs—to generate systematic variations of input variables. It consults a domain knowledge base to enforce realistic relationships among correlated variables. Each parameter set is tagged with metadata specifying the sampling technique, random seed, and dependency mappings.
Parallel Simulation Execution
The Workflow Orchestrator Agent distributes jobs across compute resources. On AWS SageMaker it may invoke batch transform jobs or managed training endpoints. On Azure Machine Learning it schedules pipeline steps for containerized simulation tasks. Runner nodes execute domain-specific models and write raw outputs to object storage or data lakes.
Result Aggregation and Normalization
A Data Consolidation Agent collects raw outputs, performs unit conversions, timestamp alignment, and schema validation. It computes summary statistics—means, variances, percentiles—and stores normalized results in a structured repository ready for rapid querying by reporting or visualization agents.
Quality Assurance and Error Handling
A Monitoring Agent audits job statuses, resource utilization, and error logs. Failed runs trigger automated retries with exponential backoff or graceful degradation isolating problematic configurations. Persistent failures escalate alerts via issue-tracking systems such as Jira or ServiceNow, and detailed logs are archived for post-mortem analysis.
Result Publication and Notification
A Publication Agent generates simulation summary reports and triggers notifications to stakeholders. Reports are published to interactive dashboards powered by tools like Tableau or Power BI, or exposed via API endpoints for decision support applications.
AI-Driven Capabilities and Supporting Systems
AI agents and supporting systems automate the discovery, orchestration, and analysis of scenario inputs and simulation tasks, delivering agility and scale.
Parameter Identification Agents
- Use natural language processing and knowledge graphs to extract variables from documents, news feeds, and regulatory bulletins.
- Align extracted variables with standardized definitions in metadata repositories and ontology management services.
- Produce prioritized lists of parameters annotated with provenance and confidence scores.
Adaptive Data Connectors
Adaptive connectors integrate with ERP, CRM, and external data marketplaces to ingest time series and risk indices. AI-driven schema inference adapts to evolving source structures and maintains seamless data flow into the simulation environment.
Workflow Coordination Engine
- Decomposes complex scenario runs into parallelizable jobs.
- Interfaces with orchestration platforms such as Kubernetes or Azure Machine Learning to allocate resources dynamically.
- Implements error handling, retry logic, and logging for resilience and reproducibility.
Simulation Kernel Agents
- Host domain-specific models—Monte Carlo engines, discrete event simulators, agent-based frameworks—in modular containers.
- Execute numeric simulations with optimized libraries for parallel processing.
- Report intermediate metrics and diagnostics back to the coordination engine.
What-If and Stress Testing Agents
- Sensitivity Analysis Agents perform one-at-a-time and global sensitivity methods, leveraging platforms like DataRobot for computation and visualization.
- Stress Test Orchestration Agents define adverse regimes, launch parallel batches of stress simulations, and generate standardized reports on resilience metrics.
Supporting Infrastructure and Management
- Configuration Management Databases (CMDB) track agent versions, simulation kernels, and resource allocations.
- Logging and Monitoring Systems collect metrics on runtime performance and system health.
- Access Governance Tools enforce role-based permissions for scenario definition, simulation execution, and stress test approvals.
- Data Lineage Services trace inputs through simulation pipelines to support auditability and root-cause analysis.
Scenario Results Packaging and Delivery
Delivering simulation outputs in a clear, structured manner ensures stakeholders can interpret outcomes, compare scenarios, and make informed strategic decisions. This stage encompasses packaging, visualization, automated reporting, decision interfaces, and secure handoff protocols.
Packaging Simulation Results
- Raw event logs in JSON or Parquet capturing state changes at discrete time steps.
- Aggregated KPIs—throughput, utilization, cycle times—exported as CSV for compatibility.
- Sensitivity matrices in spreadsheet or nested JSON formats linking parameter variations to outcomes.
- Risk quantification tables reporting confidence intervals and worst-case projections.
- Metadata manifests recording model versions, parameter set IDs, timestamps, random seeds, and build numbers.
Visualization Dashboard Integration
- Data Modeling Agents convert KPI tables into star schemas or key-value stores for BI tools.
- Connector Agents publish result tables to platforms like Tableau or Power BI, configuring live data sources and refresh schedules.
- Visualization templates with heatmaps, spider charts, and waterfall diagrams are instantiated from a template repository.
- Interactive widgets allow parameter adjustments and on-the-fly recalculations of KPIs.
- Performance Optimization Agents monitor dashboard load times and recommend caching strategies in Grafana or similar platforms.
Automated Reporting and Narrative Summaries
- Extraction Agents identify top scenarios and assemble highlight reels of key metrics.
- Generative AI models, such as those from OpenAI, craft contextual summaries explaining the impact of parameter changes.
- Chart Embedding Agents link narratives to dynamically generated graphics.
- Document Assembly Agents compile content into PDF reports, slide decks, or interactive HTML pages.
- Notification Agents distribute deliverables via email, Slack, or enterprise messaging systems.
Decision Interface Design
- Scenario Selector Panels listing scenario groups with metadata badges and run statuses.
- Parameter Sliders for rapid what-if toggles with live KPI recalculation.
- Outcome Visualizers offering side-by-side comparisons and change indicators.
- Bookmark and Annotation Tools for flagging scenarios, attaching comments, and requesting follow-up analyses.
- Export Widgets enabling download of filtered data tables or annotated snapshots.
Handoff Protocols and Integration Points
- RESTful APIs exposing result bundles, metadata manifests, and scenario summaries to external applications.
- Event-Driven Pipelines using message brokers such as Kafka or AWS EventBridge to trigger downstream ingestion.
- Automated Ingestion Scripts loading KPI tables and sensitivity matrices into Amazon S3, Azure Data Lake, or Google Cloud Storage.
- Orchestration Jobs in platforms like Apache Airflow or Prefect sequencing data transfers and validating schemas.
- Dependency Declarations linking each artifact to its scenario definition ID, model version, and input hash.
Security and Compliance in Delivery
- Role-Based Access Control (RBAC) enforcing permissions via identity providers such as Okta or Azure Active Directory.
- Encryption at rest and in transit using TLS and AES-256 for stored data.
- Audit Trails capturing dashboard interactions, report generation events, and API access logs.
- Data Masking or Anonymization when sharing outputs across business units or external partners.
- Policy Enforcement Agents validating artifact classifications, monitoring access patterns, and enforcing retention schedules.
By integrating rigorous input definition, automated simulation workflows, AI-driven orchestration, and secure result delivery, organizations can perform scalable, governed scenario planning that empowers decision-makers with actionable, traceable insights under uncertainty.
Chapter 8: Prescriptive Analytics and Optimization
Purpose and Context of Prescriptive Analytics
Prescriptive analytics represents the pinnacle of data-driven decision support, translating predictive forecasts into concrete recommendations that optimize outcomes across operational, financial, and strategic domains. By leveraging mathematical optimization algorithms, simulation models, and constraint-based reasoning, this stage bridges the gap between “what is likely to happen” and “what should be done.” Embedding AI-powered agents within analytics workflows enables organizations to implement informed strategies, allocate resources efficiently, and respond dynamically to market changes.
In modern enterprises, the volume and velocity of data exceed the capacity of manual analysis. Fragmented data sources, siloed systems, and disparate reporting tools often yield insights that fail to inform timely action. Leading platforms such as Google Cloud AI and Azure Machine Learning provide optimization toolkits—linear programming solvers, constraint engines, and robust APIs—that accelerate deployment and operationalize recommendations at scale.
Objectives and Success Criteria
Clear objectives and measurable KPIs guide prescriptive analytics efforts. Core goals include:
- Resource Allocation Optimization: Efficient distribution of personnel, capital, and materials to maximize throughput or minimize cost.
- Operational Scheduling and Planning: Production schedules, supply chain plans, and workforce rosters aligned with demand forecasts and constraints.
- Pricing and Revenue Management: Dynamic price adjustments balancing demand, competitive positioning, and margin objectives.
- Risk Mitigation and Compliance: Actions that reduce exposure to financial, regulatory, or operational risks while satisfying policy requirements.
- Strategic Scenario Evaluation: Comparison of alternative courses of action under varying market conditions to support executive decision making.
Success is measured by reductions in operating costs, improvements in service levels, increased revenue capture, and adherence to compliance thresholds. These metrics provide a quantitative basis for evaluating and refining prescriptive agents.
Inputs, Prerequisites, and Readiness
Effective prescriptive analytics relies on validated inputs, organizational alignment, and robust infrastructure. Key prerequisites include:
- Predictive Insights: Point forecasts, probability distributions, confidence intervals, and scenario projections from the predictive modeling stage.
- Business Objectives: Documented performance metrics and weight assignments—maximizing profit, minimizing cost, balancing resource utilization, or enhancing service reliability.
- Operational Constraints: Capacity limits, budgetary guidelines, regulatory restrictions, service-level agreements, and domain rules encoded from ERP and policy repositories.
- Data Quality and Governance: Frameworks ensuring accuracy, completeness, and consistency of transactional records, inventory levels, and cost parameters.
- Unified Data Infrastructure: Centralized data lake or warehouse supporting real-time and batch access with consistent schema definitions and low-latency queries.
- Optimization Engine: Scalable solver engines or cloud-based services capable of large-scale problem formulations.
- Cross-Functional Alignment: Stakeholder buy-in from business users, data science teams, and IT operations to define objectives and interpret recommendations.
- Governance and Change Management: Protocols for model versioning, decision audit trails, and approval workflows.
By satisfying these conditions, organizations ensure that optimization routines yield feasible, aligned, and operationally actionable recommendations.
Prescriptive Analytics Workflow
Workflow Inputs and Contextual Data Gathering
Prescription generation starts with aggregation of predictive results and contextual inputs. Agents collect:
- Forecast outputs—including probability distributions and scenario projections.
- Operational constraints and resource availability—budget ceilings, staffing limits, inventory capacities.
- Business objectives—cost minimization, revenue maximization, risk thresholds, service-level agreements.
- External factors—market conditions, regulatory requirements, seasonal demand patterns.
Metadata tagging and version control ensure consistency, while discovery agents validate input freshness before optimization routines commence.
Algorithm Selection and Constraint Definition
Optimization agents select appropriate algorithm classes based on problem characteristics:
- Linear Programming for continuous variables with linear relationships.
- Mixed-Integer Programming for discrete decisions and resource allocation, often executed with Gurobi or IBM CPLEX.
- Constraint Programming for logical rules, scheduling, and combinatorial constraints.
- Heuristic and Metaheuristic approaches—Genetic Algorithms or Simulated Annealing for non-convex or NP-hard problems.
Business policies are converted into mathematical expressions by rules enforcement agents, ensuring capacity, budget, risk, and compliance constraints are codified. Conflict detection routines route contradictory constraints to exception-handling agents for human review.
Model Construction, Execution, and Monitoring
With constraints and objectives defined, the workflow advances to model instantiation:
- Template Loading: Retrieval of model templates matching the selected algorithm.
- Parameter Binding: Injection of demand forecasts, cost coefficients, and resource availabilities.
- Feasibility Checks: Preliminary solves to confirm model solvability.
- Full Optimization Run: Execution by the chosen engine, utilizing parallel compute resources or GPU acceleration.
Monitoring agents track objective value progression, iteration counts, and solve time. If time or resource limits are reached, fallback strategies return the best available solution.
Solution Evaluation, Trade-Off Analysis, and Iterative Refinement
Post-solve, analytical agents assess solution quality:
- Objective Performance Metrics against baseline scenarios.
- Constraint Slack Analysis to identify binding constraints.
- Pareto-Optimal Trade-Off Frontiers for multi-objective decisions.
Sensitivity agents systematically vary key inputs—demand forecasts or cost parameters—to gauge solution robustness. Feedback loops alert stakeholders when adjustments to constraints or inputs are required, prompting re-execution of refined models.
Coordination with Execution Systems
Upon confirmation of an optimal solution, export agents format recommendations into actionable deliverables:
- Decision Tables mapping scenario parameters to execution steps.
- Prioritized Action Lists with estimated impacts and timelines.
- API Payloads for ERP, CRM, or supply-chain management interfaces.
- Report Artifacts compatible with Microsoft Power BI or Tableau.
Delivery agents invoke RESTful endpoints or message queues to transmit prescriptions, while confirmation handlers verify integration and log metadata in a central audit ledger.
AI-Driven Optimization Agents and Infrastructure
Optimization agents integrate advanced mathematical programming, machine learning–based decision policies, and real-time data to automate resource allocation and planning at scale. Their core capabilities include:
- Mixed-Integer and Linear Optimization using solvers such as Gurobi and IBM CPLEX to maximize profit, minimize cost, or balance service levels.
- Heuristic and Metaheuristic Techniques—Genetic Algorithms, Simulated Annealing, or Tabu Search for large-scale, non-convex problems.
- Reinforcement Learning to learn dynamic allocation policies that adapt to uncertainty and delayed feedback.
- Multi-Objective Optimization generating Pareto frontiers for trade-off analysis between competing goals.
- Constraint Learning and Soft Constraints inferred from historical data to penalize but not strictly forbid violations.
- Explainable Outputs leveraging approximation methods or scenario decomposition to clarify recommendation drivers.
Supporting systems ensure seamless operation:
- Data Integration Platforms—centralized warehouses or lakes ingest forecasts, inventory, and cost data. Tools like Apache Airflow and Kafka orchestrate data workflows.
- Model Orchestration—MLOps frameworks (Kubeflow, MLflow) manage versioning, scheduling, and lifecycle of optimization models.
- Compute Resource Management—container orchestration (Kubernetes) allocates CPU, GPU, and memory with autoscaling for peak demand.
- APIs and Integration Services—REST endpoints expose optimization services to ERP, supply chain, and CRM systems.
- Monitoring and Alerting—tools like Prometheus and Grafana capture solution quality, computation times, and constraint slackness.
- Visualization Dashboards—interactive dashboards built with D3.js or Plotly support scenario exploration and stakeholder alignment.
Collaboration interfaces allow business users to modify parameters via web portals, triggering agents to re-run optimization and display updated recommendations. Structured reports outline allocation plans, constraint shadow prices, and marginal benefit analyses, while approval workflows enforce governance before execution.
Deliverables and Integration Handoffs
Prescriptive agents produce a suite of artifacts that embed recommendations into operational workflows. Key deliverables include:
- Decision Tables: Matrices mapping conditions to actions with execution steps.
- Priority Action Lists: Ranked tasks by impact, cost-benefit ratio, or urgency.
- Optimization Scorecards: Dashboards highlighting KPIs, expected gains, and trade-offs.
- Runbooks and Playbooks: Step-by-step procedures with preconditions, commands, and rollback strategies.
- Real-Time Alerts: Event-driven messages with context, severity, and recommended responses.
Successful handoff depends on upstream dependencies and formalized data contracts:
- Validated predictive model scores and probability distributions.
- Feature lineage metadata ensuring provenance of optimization variables.
- Business rules and constraint definitions from policy repositories.
- Real-time or batch feeds updating cost parameters and inventory levels.
- Service level agreements governing latency, availability, and data freshness.
Integration mechanisms vary by use case:
- Synchronous APIs exposing REST or gRPC interfaces with JSON Schema/OpenAPI definitions.
- Event-Driven Messaging via Kafka topics consumed by CRM, ERP, or orchestration engines.
- Batch Exports writing CSV, Parquet, or Avro files to shared storage for ingestion by ETL pipelines.
- Dashboard Embedding of scorecards in Microsoft Power BI or Tableau portals.
- Direct Connectors linking optimization platforms to execution systems for automated action implementation.
Governance, Monitoring, and Continuous Improvement
Maintaining control and ensuring compliance requires extensive metadata, versioning, and audit trails. Each artifact includes generation timestamps, agent versions, input parameter identifiers, business context attributes, and confidence scores. A centralized registry manages artifact versions and data contracts, while audit logs capture handoff events and user approvals.
Error handling mechanisms detect validation failures against schemas, implement retry policies with exponential backoff, escalate critical issues to operations teams, and route undeliverable messages to dead-letter queues.
Governance policies enforce role-based access controls, encryption for data in transit and at rest, retention rules for logs, and compliance checks for frameworks such as GDPR, SOX, or HIPAA. Authentication and authorization leverage standards like OAuth2, JWT, or mutual TLS.
Performance monitoring tracks latency from optimization completion to consumption, success rates of automated actions, measured business impact, and user feedback scores. These metrics feed back into objective functions and constraint weightings, enabling agents to refine strategies over time. Canary deployments validate updated models on subsets of scenarios before full-scale rollout, ensuring robust versioned model rollouts.
Best Practices for Handoff Standardization
- Define Clear API Contracts with interface definitions, examples, and test harnesses to accelerate adoption.
- Adopt a Modular Data Schema structuring artifacts into header metadata, decision rules, and execution parameters.
- Implement Canary Deployments to validate new recommendation versions on a subset of transactions or geographies.
- Maintain a Centralized Registry cataloging all prescriptive outputs, versions, and consumption endpoints.
- Encourage Cross-Functional Collaboration involving business owners, IT operators, and data scientists in defining handoff requirements and acceptance criteria.
By standardizing outputs, enforcing governance, and automating integration, organizations embed prescriptive insights into daily operations—from supply chain planning to customer engagement—achieving faster decision cycles, higher operational agility, and sustained competitive advantage.
Chapter 9: Narrative Insight Generation
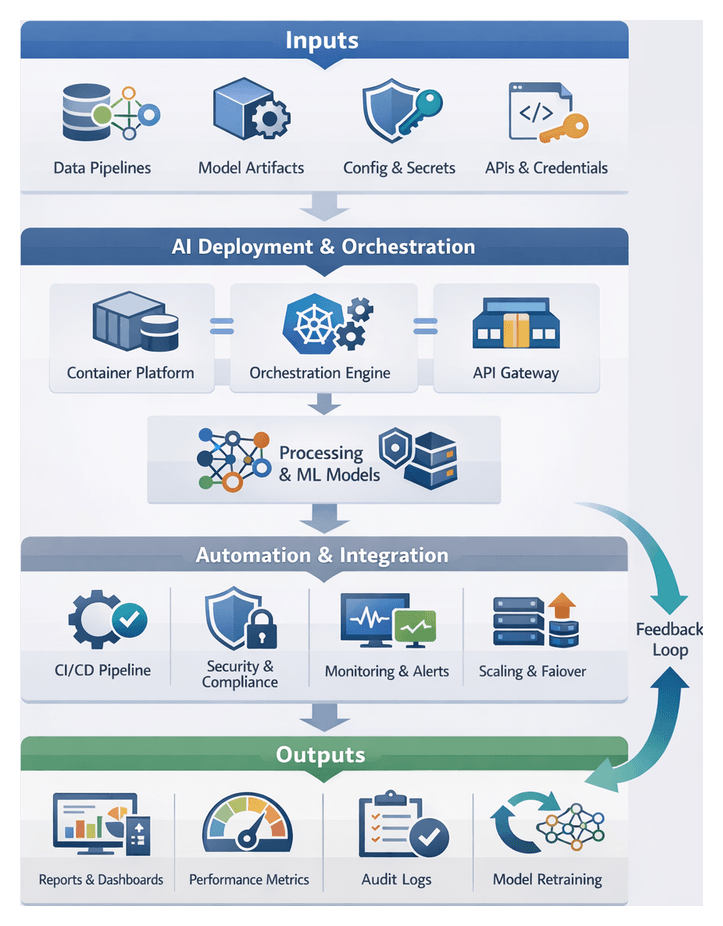
Reporting Objectives and Essential Inputs
The narrative insight generation stage bridges analytical outputs and stakeholder decision making by translating quantitative findings, model results, and visualizations into concise, context-rich narratives. Automated agents synthesize data summaries, integrate charts, and tailor language to specific audiences—ensuring consistency of message, rapid report turnaround, and alignment with strategic goals. Key objectives include:
- Clarifying technical results in business terminology
- Standardizing tone and format through reporting templates
- Accelerating report production for agile decision cycles
- Customizing content for executive, technical, or operational audiences
- Embedding actionable recommendations with supporting evidence
Successful narrative generation relies on comprehensive inputs and prerequisites that guarantee accuracy, relevance, and stakeholder alignment:
Analytical Findings and Data Artifacts
- Summary statistics, key performance indicators, and anomaly reports
- Predictive outputs with forecast tables and validation metrics
- Scenario simulation matrices and risk exposure backtesting
- Prescriptive recommendations detailing resource allocations
Visualization Assets
- Time-series plots, heat maps, scatter matrices, and dashboard snapshots
- Cluster highlights, trend annotations, and interactive filter states
Metadata and Lineage
- Data source identifiers, ingestion timestamps, and schema versions
- Processing logs documenting transformations and validation checkpoints
- Agent execution metadata, including model versions and quality scores
Audience Profiles and Style Guidelines
- Role-based specifications for terminology level and document format
- Corporate tone and brand voice standards
- Preferred delivery channels such as email, intranet, or BI platforms
Templates and Conventions
- Document structures defining headings, layout grids, and visuals
- Formatting rules for tables, lists, and accessible design
Compliance Requirements
- Data privacy rules and redaction for sensitive fields
- Industry-specific disclosure mandates and audit protocols
Integration with upstream stages—Exploratory Data Analysis, Predictive Modeling, Scenario Planning, and Prescriptive Analytics—depends on standardized handoff formats (for example JSON schemas), API contracts, and messaging protocols that trigger narrative generation upon task completion. Establishing scalable compute resources, role-based access controls, version management, monitoring dashboards, and review workflows ensures operational readiness and content quality. Success metrics include report turnaround time, stakeholder satisfaction, hours saved, consistency rates, narrative accuracy, and adoption of recommendations.
Narrative Composition and Visualization Pipeline
The composition pipeline orchestrates multiple AI sub-agents to assemble reports that combine textual narratives with visual elements. The modular workflow comprises:
- Input aggregation and metadata tagging
- Template and style configuration
- Chart and graphic rendering
- Textual narrative crafting
- Content synchronization and layout assembly
- Quality checks and version control
- Packaging for delivery platforms
Input Aggregation and Metadata Tagging
An orchestration agent retrieves validated outputs—performance metrics, anomaly flags, and simulation results—and tags each element with metadata such as insight category, confidence level, and relevance score. This drives content prioritization and template selection.
Template and Style Configuration
Template agents select report layouts aligned with corporate branding and audience preferences. When targeting interactive dashboards, integrations with Power BI or Tableau ensure optimal embedding. Templates define section order, typography, and permitted visual types.
Visualization Generation
Visualization agents choose appropriate chart forms—line charts for trends, bar graphs for comparisons, heatmaps for correlations, and box plots for distributions. Leveraging D3.js libraries or the DataRobot API, they apply consistent color palettes, annotate key points, and export interactive components. Steps include:
- Data normalization for accurate scaling
- Dynamic legends based on series count
- High-resolution exports for print and web
Textual Narrative Crafting
Generative language agents, powered by models such as ChatGPT, structure narratives into overview, methodology recap, key findings, and implications. They embed data references to reinforce credibility, adjust tone per audience, and insert transitions for readability.
Layout Assembly and Synchronization
A layout agent assembles text and visuals within the chosen template, positioning each chart adjacent to its narrative block. It generates captions and alt-text for accessibility and produces draft reports in HTML, PDF, or dashboard formats.
Orchestration and Monitoring
Workflow managers—such as Apache Airflow—schedule sub-agent tasks. Agents communicate via RESTful APIs or message queues, exchanging JSON payloads with data pointers and rendering instructions. The orchestration layer handles error retries, template version control via Git, load balancing for graphic rendering, and audit logging of narrative revisions.
Quality Assurance and Iteration
Validation agents perform automated checks on data accuracy, completeness of figures, and style adherence. Natural language quality checks assess readability. Discrepancies trigger loops back to generation agents until acceptance criteria are met.
System Integrations
Key integrations include data lakes, template repositories, visualization engines, language model APIs, workflow orchestrators, collaboration tools (Slack, Microsoft Teams), and delivery channels. Human reviewers validate drafts through collaborative interfaces, providing feedback that refines content and ensures strategic alignment.
Generative AI Agents for Contextual Narratives
Generative AI agents autonomously convert structured analysis into audience-aware summaries. They leverage large language models—such as GPT-4, Claude, or AI21 Studio—and retrieval-augmented generation techniques to ground narratives in up-to-date data. Core capabilities include:
- Contextual Summarization: Extracting key insights from statistical reports and model outputs
- Tone and Style Adaptation: Adjusting formality and pacing for executives, analysts, or operators
- Reference Integration: Embedding captions, call-outs, and hyperlinks to visual assets
- Domain Consistency: Enforcing terminology from industry glossaries
- Multilingual Rendering: Producing narratives in multiple languages
- Interactive Refinement: Responding to conversational prompts in real time
System components that enable these capabilities include:
- Knowledge Base Manager: Maintains ontologies, style rules, and phrasing templates
- Prompt Orchestration Engine: Sequences API calls to language models and adjusts prompts based on context
- Content Quality Validator: Checks factual accuracy, style compliance, and bias mitigation
- Feedback Collector: Aggregates user edits for continuous model improvement
Retrieval-Augmented Generation Architecture
- Embedding Service converts text snippets, captions, and metadata into vectors for similarity search
- Context Retrieval fetches facts, definitions, and prior examples to enrich prompts
- Prompt Compiler assembles composite prompts integrating retrieved context
- Language Model Executor invokes LLM endpoints, optionally via LangChain
- Post-Processing Module cleans formatting, validates numeric references, and adds hyperlinks
Visualization and Data Reference Integration
- Auto-generate descriptive captions that include axis labels and trend explanations
- Inline call-outs citing figure numbers or dashboard widget IDs
- Interactive annotations for web-based reports
- Cross-document hyperlinks between narrative sections and appendices
Human-in-the-Loop and Governance
Critical reports undergo human review via a collaborative workbench. Automated fact-checkers cross-reference numeric claims, and style scans ensure compliance. Reviewer edits feed back into fine-tuning pipelines, reinforcing trust and accuracy.
Deployment and Scalability
- Deploy agents as microservices behind API gateways
- Version control prompt templates and model configurations
- Monitor LLM usage and cache common segments to manage cost
- Pre-retrieve context and use distilled models for low-sensitivity text
- Enforce encryption, access controls, and compliance with data governance policies
Final Reports Delivery and Feedback Loops
The delivery phase packages synthesized narratives and visualizations into formats tailored to stakeholder preferences and distribution channels. Artifacts include:
- PDF and Word documents for executive briefings and archives
- Interactive dashboards in Power BI and Tableau
- HTML-formatted webpages with expandable sections and tooltips
- API-accessible JSON or XML payloads for CRM and ERP integration
- Email and messaging summaries delivered via Microsoft Teams or Slack
Provenance management and metadata cataloging ensure that narrative text, visualization assets, and data lineage remain synchronized. Delivery frameworks automate handoffs to:
- Content management systems such as SharePoint or Confluence
- BI portals publishing dashboards without manual redeployment
- Email servers with secure links and personalized placeholders
- Messaging tools like Slack and Microsoft Teams for real-time notifications
- RESTful APIs for programmatic report retrieval
User Feedback and Interaction
Embedding feedback mechanisms directly within reports transforms delivery into a collaborative dialogue. Interaction modalities include:
- Commenting in Google Docs or Microsoft Word online
- Annotations on dashboard charts and filter states
- Embedded surveys capturing ratings and suggestions
- Chatbot interfaces soliciting clarifications in Slack or Teams
- Issue tickets in Jira or ServiceNow for data concerns
Feedback items, tagged with report version and user metadata, feed back into requirement backlogs, trigger report regenerations, update metadata catalogs, and even initiate model fine-tuning when drift is detected. Approved recommendations can be converted into automated rules that update operational systems, closing the loop from insight to execution.
Security and Compliance
Delivery orchestration enforces authentication via single sign-on, encryption in transit and at rest, audit logging of access events, data masking for PII, and retention policies aligned with regulatory standards such as GDPR or HIPAA. Role-based permissions ensure that only authorized personnel can access sensitive insights.
By unifying objectives, workflow orchestration, generative AI capabilities, and secure delivery, organizations establish a repeatable, scalable framework that transforms data into actionable narratives and fosters continuous improvement through stakeholder collaboration.
Chapter 10: Deployment and Continuous Improvement
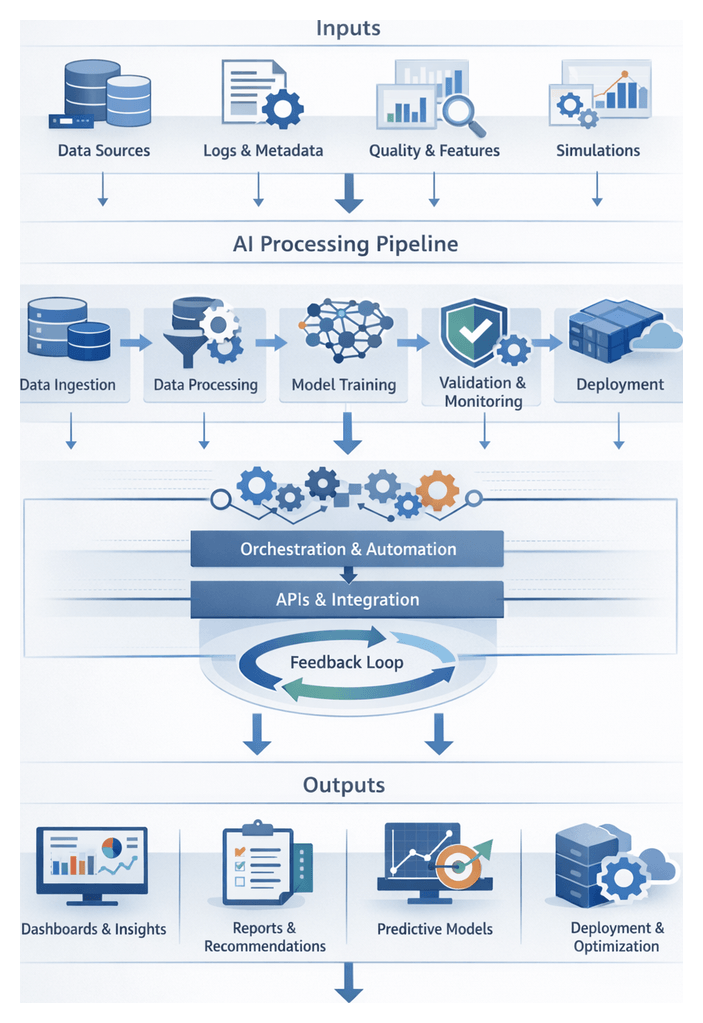
Deployment Requirements and Integration Inputs
The transition of AI-driven analytics workflows into production demands a structured deployment process that aligns infrastructure, security, and operational practices. By defining clear requirements and assembling critical inputs, teams ensure reliable performance, compliance adherence, and rapid updates in response to evolving business needs.
Purpose and Goals
The deployment stage establishes a stable, repeatable mechanism for releasing data ingestion pipelines, processing agents, machine learning models, and reporting services. Key objectives include:
- Operational Readiness: Validate compute, storage, security policies, and network configurations.
- Integration Validation: Confirm seamless communication among data sources, processing agents, model endpoints, and downstream applications.
- Scalability and Resilience: Provision autoscaling and failover mechanisms for variable workloads.
- Auditability and Compliance: Establish logging, monitoring, and reporting to meet regulatory standards.
- Repeatability: Implement infrastructure-as-code templates and orchestration scripts for consistent deployments.
Prerequisites and Environmental Conditions
- Infrastructure Provisioning: Allocate virtual machines, container clusters, or serverless resources and define network segmentation.
- Orchestration Framework: Configure platforms such as Kubernetes or Kubeflow with cluster and autoscaling policies. Establish CI/CD pipelines for automated builds and releases.
- Configuration Management: Store environment-specific parameters, secrets, and feature flags in code using tools like etcd or Consul.
- Security and Compliance Controls: Define role-based permissions, encryption policies, and audit trails using solutions such as HashiCorp Vault or AWS Secrets Manager.
- Network and Connectivity: Ensure firewall, proxy, and load balancer rules support traffic among agents, data stores, and external APIs.
- Version Control and Artifact Management: Maintain source code in repositories, container images in registries, and model artifacts with immutable tags.
- Monitoring and Observability: Configure metrics collection and log aggregation with frameworks like Prometheus and Grafana.
- Stakeholder Alignment: Communicate deployment schedules, rollback plans, and notification processes to operations, data stewards, and business owners.
Required Inputs
- Data Pipeline Definitions: Source connectors, transformation scripts, and target schemas.
- Model Artifacts and Metadata: Trained binaries or container images with version and performance details.
- API Contracts and Endpoints: OpenAPI or gRPC specifications, URLs, and port configurations.
- Configuration Files: YAML or JSON templates specifying resource limits, timeouts, and feature flags.
- Credentials and Secrets: Tokens, certificates, and keys for secure communications.
- Deployment Scripts and Templates: Terraform modules or Helm charts for provisioning infrastructure.
- Testing and Validation Artifacts: Integration tests, validation scripts, and test datasets.
- Operational Runbooks: Step-by-step procedures, rollback instructions, and incident response guides.
Integration Points and Dependency Mapping
- Data Source Connectors: Map ingestion agents to databases, APIs, and storage locations.
- Processing Agents to Message Brokers: Document topics, queues, serialization formats, and schema registry endpoints.
- Model Serving Endpoints: Link inference services to dashboards and applications, defining payload and error-handling structures.
- Monitoring and Alerting Channels: Assign metric exporters and configure alert recipients.
- Configuration Management Systems: Align CI/CD pipelines with version-controlled parameter stores.
- Identity and Access Management: Define service accounts and roles with least-privilege policies.
Environmental Testing and Validation
- Staging Parity: Mirror production data volumes, network settings, and security policies.
- Smoke Tests: Verify connectivity, endpoint availability, and data flow.
- Load and Performance Testing: Simulate peak workloads to validate autoscaling and SLA compliance.
- Failover Drills: Introduce simulated faults to test resilience and recovery mechanisms.
- Security Scans: Perform vulnerability assessments, penetration tests, and configuration audits.
Orchestration and API Management Workflow
Orchestration and API management form the backbone of AI-driven analytics, coordinating containerized workloads, routing requests, and enforcing security policies to enable continuous data analysis and operational agility.
Key Components
- Container Platform: Docker for standardized execution environments.
- Orchestration Engine: Kubernetes or Kubeflow for scheduling and health management.
- Workflow Scheduler: Apache Airflow for DAG-based task orchestration.
- API Gateway: AWS API Gateway or Kong for routing, authentication, and rate limiting.
- Service Mesh: Istio or Linkerd for secure service-to-service communication and observability.
- Message Broker: Apache Kafka or RabbitMQ for event-driven interactions.
- Configuration Store: etcd or Consul for runtime settings and secrets.
Workflow Sequence
- Agent Packaging: CI builds container images and pushes to the registry.
- Job Scheduling: Scheduler reads DAGs and invokes orchestrator APIs to launch pods.
- Service Registration: Agents register endpoints and metadata with the API gateway.
- Request Routing: Gateway applies policies and forwards requests to agents.
- Inter-Agent Communication: Data flows via synchronous API calls or asynchronous messages with tracing headers.
- State Management: Agents persist intermediate results, triggering downstream tasks.
- Health Monitoring: Orchestrator polls probes, auto-restarts failed services.
- Version Rollouts: Canary or blue-green deployments shift traffic using weighted routing.
- Autoscaling: Metrics feed autoscalers to adjust instance counts.
- Graceful Shutdown: Agents deregister, complete in-flight requests, and offload metrics.
Resilience Patterns
- Retry with Backoff: Automatic retries for transient errors.
- Circuit Breaker: Prevents cascading failures to unresponsive services.
- Fallback Routes: Alternate logic paths preserve critical functionality.
- Bulkhead Isolation: Resource pools limit failure blast radius.
- Dead Letter Queues: Captures unprocessable messages for manual review.
- Graceful Degradation: Disables nonessential features under high load.
Security and Governance
- Authentication and Authorization: OAuth 2.0 or JWT with role-based access control.
- Mutual TLS: Encrypted service-to-service channels.
- Secret Management: Runtime retrieval from HashiCorp Vault or AWS Secrets Manager.
- Audit Logging: Immutable logs of orchestration events and API requests.
- Policy Enforcement: Validation via Gatekeeper or OPA at deployment time.
- Traffic Encryption: End-to-end data encryption in transit.
Monitoring, Observability, and Feedback Loops
- Metrics Collection: Prometheus-compatible metrics for resources and custom KPIs.
- Distributed Tracing: Jaeger or Zipkin for end-to-end request tracing.
- Log Aggregation: Centralized storage with Elasticsearch, Splunk, or Kibana.
- Dashboards: Visualizations in Grafana or Kibana.
- Automated Feedback: Performance data influences autoscaling and retraining triggers.
Best Practices for Scalable Orchestration
- Infrastructure as Code: Version-controlled definitions using Terraform or Helm.
- Immutable Deployments: Build new container images for every change.
- Contract-Driven Development: Define APIs with OpenAPI or gRPC for early validation.
- Decoupled Dependencies: Favor asynchronous events to reduce coupling.
- Progressive Rollouts: Canary and blue-green deployments for safe releases.
- Scalability Testing: Regular load and stress tests on orchestration layers.
- Documentation and Training: Maintain runbooks, diagrams, and API references.
Integrating with Enterprise Systems
- Trigger jobs via webhooks from Git repositories or data catalog changes.
- Expose agent services through standardized REST or gRPC APIs.
- Connect to enterprise message buses for analytics events.
- Bridge legacy systems with API adapters or federated gateways.
- Synchronize identities using SAML or OpenID Connect for single sign-on.
Agent Orchestration and Version Control
Coordinating numerous AI agents across development, testing, and production requires integrated orchestration and version control. This ensures reproducibility, compliance, and efficient lifecycle management.
AI-Driven Orchestration Capabilities
- Dynamic Task Scheduling: AI schedulers trigger agents based on events and data availability.
- Dependency Mapping: Graph models detect upstream and downstream relationships automatically.
- Auto-Scaling and Resource Optimization: Machine learning adjusts compute allocations to match demand.
- Failure Detection and Self-Healing: Monitors health metrics and restarts or reroutes tasks as needed.
- Adaptive Workflow Revision: Reinforcement learning refines task ordering and retry policies over time.
Supporting Infrastructure
- Container Platforms: Docker for portable images.
- Cluster Orchestration: Kubernetes with autoscaling and rolling updates.
- Workflow Engines: Apache Airflow and Kubeflow.
- Messaging and Event Buses: Apache Kafka and RabbitMQ.
- Service Mesh and API Gateways: Istio and Kong.
- Logging and Monitoring: ELK Stack, Prometheus, and Grafana.
- Artifact Repositories: Container registries integrated with CI/CD.
CI/CD and Containerization
Continuous Integration and Deployment pipelines automate build, test, and release workflows. Code merges in GitHub trigger linting, unit tests, security scans, and container builds. Successful images are pushed to registries and deployed via orchestrator rolling updates.
Version Control Practices
- Source Code Repositories: Git-based systems with branching strategies like GitFlow.
- Model Artifact Registries: MLflow and Weights & Biases for versioned models and metrics.
- Configuration as Code: Store infrastructure and agent parameters in version control.
- Immutable Releases: Tag each deployment with unique identifiers linking code, configs, and models.
- Artifact Promotion Policies: Automated gates for tests, security scans, and performance benchmarks.
- Branch Protection: Pull request reviews and automated checks before merges.
Versioning Strategies
Adopt semantic versioning (MAJOR.MINOR.PATCH) to signal breaking changes, enhancements, and bug fixes. Consistent labels enable orchestrators to ensure compatibility and avoid runtime conflicts.
Governance, Traceability, and Compliance
- Audit Trails: Immutable logs of who deployed what and when.
- Lineage Tracking: Map data flow from raw inputs through transformations to reports.
- Policy Enforcement: Role-based controls in repositories and orchestrator namespaces.
- Regulatory Reporting: Automated exports of version histories, logs, and performance metrics.
- Drift and Anomaly Alerts: Monitor unexpected changes in agent behavior or model predictions.
Operational Benefits and Best Practices
- Scalability: Automated scheduling and resource management for horizontal expansion.
- Reproducibility: Versioned artifacts guarantee regeneration of past results.
- Risk Mitigation: Rollbacks and immutable releases reduce downtime.
- Faster Time-to-Market: CI/CD automation shortens deployment cycles.
- Collaboration: Clear workflows foster teamwork among data engineers, scientists, and DevOps.
- Continuous Improvement: Monitoring feedback informs version updates and refinements.
Feedback Loop Outputs and Refinement Handoffs
Deployment is the start of a continuous improvement cycle. Feedback loops capture performance data, user signals, and operational health metrics, which drive iterative refinements, retraining, and process optimizations.
Primary Outputs
- Performance Metrics
- Accuracy, precision, recall, F1 score.
- Inference latency and throughput statistics.
- Resource utilization for CPU, GPU, and memory.
- Drift Detection Alerts
- Concept and data drift notifications.
- Schema change reports and risk scoring.
- User Feedback Logs
- Explicit ratings, comments, and survey responses.
- Implicit signals such as click-through rates.
- Error and Exception Traces
- Runtime logs, stack traces, and failure codes.
- Correlation identifiers for cross-service tracing.
- Retraining Triggers
- Automated signals based on drift thresholds.
- Scheduled retraining plans linked to data pipelines.
Dependencies for Feedback Artifacts
- Telemetry Infrastructure: Integrations with Prometheus, Grafana, and service meshes for distributed tracing.
- Model and Feature Registry: MLflow or Kubeflow Pipelines for version and lineage metadata.
- Storage Integration: Persist feedback data in Amazon S3, Google Cloud Storage, or HDFS.
- Alerting and Notification: Connect to PagerDuty, ServiceNow, or Slack for real-time alerts.
- CI/CD and Orchestration Pipelines: Use Jenkins, GitLab CI/CD, or Azure DevOps to ingest feedback and trigger retraining on Kubernetes.
Feedback Data Processing
- Stream processing with Apache Kafka and Apache Flink.
- Batch analysis using Apache Spark.
- Schema validation via Great Expectations.
Handoff Mechanisms
- Model Retraining Pipelines
- Version and tag feedback datasets in the model registry.
- CI/CD triggers retraining when drift thresholds are breached.
- Generate candidate models and comparison reports.
- Data Science Teams
- DevOps Teams
- Capacity metrics inform cluster scaling.
- Error logs drive reliability engineering projects.
- Runbook updates based on alert severity matrices.
- Business Owners
- Executive summaries highlight model impact on KPIs.
- User adoption metrics inform roadmap updates.
Traceability and Auditability
- Model version and training dataset hash.
- Feature pipeline version identifier.
- Deployment environment and container image tag.
- Deployment timestamp and build number.
Continuous Improvement Integration
- Embed feedback tasks into sprint backlogs with defined acceptance criteria.
- Set service level objectives for model performance.
- Implement automated validation tests for retrained models.
- Use feature flags for canary deployments of new models.
Conclusion
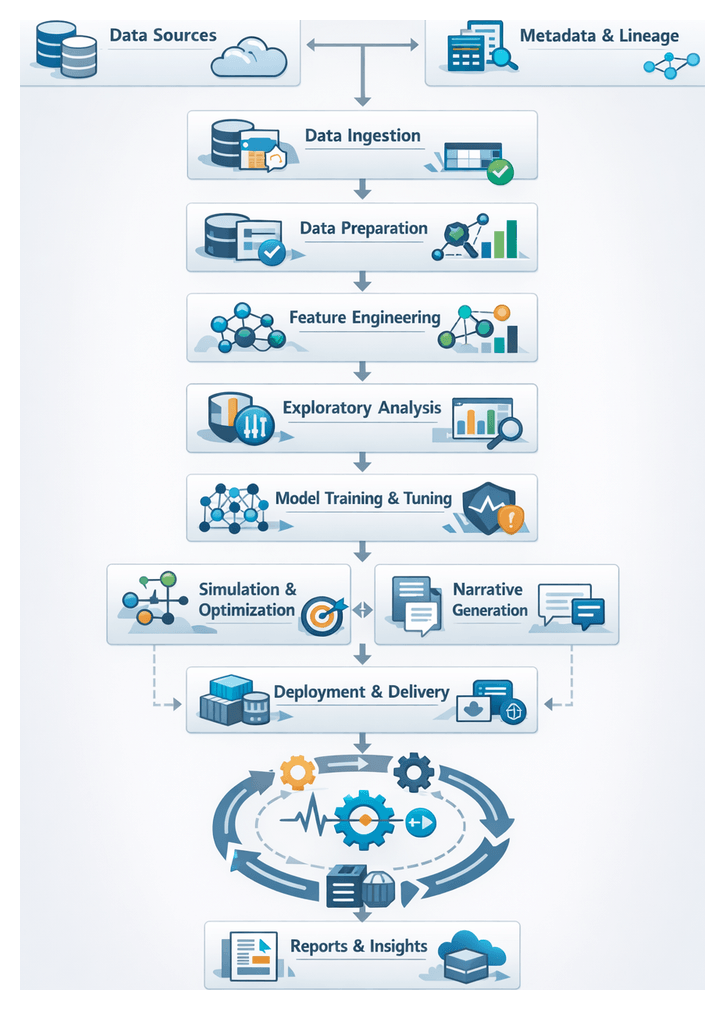
Full Workflow Overview
At the foundation of an AI-driven analytics infrastructure lies a cohesive, automated end-to-end workflow that transforms raw inputs into strategic insights. By mapping objectives, artifacts and inter-agent communications across every phase—from data discovery to deployment and continuous refinement—organizations gain transparency into system dependencies, governance controls and scalability pathways.
Key Components and Inputs
The full workflow relies on comprehensive inputs and documentation, including:
- Data Source Catalog annotated with schemas and access credentials
- Ingestion logs, metadata tags and error reports
- Quality profiling outputs and anomaly detection metrics
- Feature artifacts and dependency mappings
- Exploratory dashboards and pattern recognition summaries
- Serialized model artifacts, hyperparameters and experiment metadata
- Validation reports, drift detection logs and retraining triggers
- Simulation results and sensitivity analyses
- Prescriptive recommendations and decision tables
- Generative narrative templates and executive summaries
- Deployment manifests, API specifications and container definitions
- Feedback logs, performance dashboards and improvement metrics
Integration Patterns and Governance
- Event-driven triggers that launch downstream agents upon data arrival or metadata updates
- Centralized metadata bus for asset lineage, schema versions and quality annotations
- API-first interactions via RESTful or gRPC endpoints for profiling, training and simulation services
- Federated data access through virtualization or query federation techniques
- Versioned artifact registries for models, features and configurations
- Automated feedback loops routing performance metrics and user comments back to preparation and modeling agents
- Orchestration dashboards presenting real-time status, throughput and error metrics
- Governance policies embedded across roles, audit trails and compliance controls
- Version control repositories ensuring reproducibility and rollback capabilities
Efficiency Gains and Accelerated Time to Insight
Pipeline Orchestration and Reduced Latency
Transitioning from siloed batch jobs to continuous, event-driven pipelines compresses analytics cycles from weeks to days. A workflow engine such as Apache Airflow or Kubeflow schedules extraction, profiling, cleansing and modeling tasks. Messaging platforms like Apache Kafka and Amazon EventBridge facilitate near real-time event streams, enabling agents to process new data immediately.
Inter-Agent Communication and Automated Handoffs
Lightweight interfaces—RESTful APIs, gRPC services and messaging queues—enable agents to exchange data contracts, status updates and control signals. Standardized artifacts with metadata hashes and quality scores ensure integrity at each handoff. Self-service APIs empower business analysts to invoke workflows on demand, while Kubernetes orchestrates containerized agents, scaling resources dynamically.
Continuous Monitoring and Scalability
A monitoring agent aggregates KPIs—end-to-end latency, throughput and error rates—and exposes dashboards via Grafana. Automated alerts trigger corrective workflows for schema drift, data anomalies or resource contention. Stateless microservice deployments on elastic compute and object storage platforms enable horizontal scaling, partitioned processing and caching of intermediate results to optimize throughput.
Quantifying Efficiency Improvements
- Data discovery cycles reduced from days to hours through automated scanning
- Data preparation accelerated by 60–80 percent via AI-driven cleansing and anomaly resolution
- Model development lead times shortened from weeks to days with automated feature engineering and hyperparameter tuning
- Near real-time monitoring and retraining capabilities ensuring up-to-date insights
Business Impact and Decision Quality Enhancement
Strategic Decision-Making with Predictive Analytics
Predictive modeling agents powered by TensorFlow and PyTorch uncover leading indicators and generate probability distributions for market trends and customer behavior. A centralized model registry tracks versions and performance, while controlled staging environments ensure robust governance before production deployment.
Risk Mitigation and Compliance
Risk assessment agents monitor drift in accuracy and data distributions, triggering automated retraining. Policy management systems enforce masking, anonymization and role-based access controls, while audit logs document dataset usage to maintain regulatory compliance.
Prescriptive Optimization and Resource Allocation
Prescriptive analytics agents leverage constraint-solving algorithms to optimize workforce scheduling, inventory replenishment and budget distribution. CI/CD frameworks propagate updates seamlessly, enabling dynamic adjustments to operational plans in response to real-time data.
Data-Driven Culture and Collaboration
Generative narrative agents produce stakeholder-specific reports combining concise text and visualization references. Integrated collaboration platforms allow teams to comment, adjust parameters and request ad-hoc analyses. A unified data catalog documents feature definitions, model assumptions and lineage, fostering a single source of truth.
Innovation through Simulation and Experimentation
Scenario-planning agents test new strategies—product launches, pricing models and supply-chain configurations—under diverse conditions. Experimentation platforms capture outcome data, feeding back into predictive models to refine assumptions and accelerate iterative innovations.
Continuous Improvement and ROI Measurement
Monitoring agents track the impact of recommendations, measuring uplift in revenue, cost savings and risk reduction. Automated feedback loops trigger policy adjustments and model retraining. Attribution frameworks combine baseline and counterfactual analyses, presenting ROI dashboards that link AI initiatives to strategic KPIs.
Deliverables, Handoff Protocols and Scalability Artifacts
Executive Synthesis and Technical Compendium
An executive synthesis report distills business outcomes, performance benchmarks and prioritized actions. The technical compendium details architecture diagrams, agent specifications, API mappings and performance profiles, providing a reference for audits and future enhancements.
Implementation Playbooks and Reusable Templates
Blueprints and playbooks include infrastructure-as-code templates for Docker and Kubernetes, deployment manifests for Kubeflow or Apache Airflow, CI/CD pipelines, testing procedures and operational runbooks. Modular workflow definitions and parameterized agent profiles support rapid adaptation to new use cases.
Artifact Lineage and Governance Frameworks
Clear mapping of dependencies links raw data snapshots, cleansed datasets, feature stores, model binaries and validation logs to final outputs. Policy templates, audit trail frameworks and change management guidelines ensure that future modifications adhere to governance standards.
Automated Handoff and Integration Protocols
Artifacts are published to versioned Git repositories, artifact registries and feature stores with consistent tagging. Deployment scripts register API endpoints and webhooks, generate OpenAPI specifications and configure gateways. Structured review cycles and sign-off protocols engage business, IT, compliance and DevOps teams before production rollout.
Scalability and Framework Reuse
Version-controlled code libraries, CI/CD workflows and modular governance templates enable rapid scaling and reuse across projects. By operationalizing these artifacts and protocols, organizations can replicate successful analytics patterns, maintain compliance and accelerate time to value as business objectives evolve.
Appendix
Workflow Terminology and Core Concepts
An AI-driven analytics workflow comprises interconnected stages managed by autonomous software components, or AI agents, that perform tasks from data discovery through deployment. Orchestration coordinates these agents via workflow engines that define Directed Acyclic Graphs (DAGs), enforce dependencies, handle errors, and autoscale resources. Standardized handoff protocols govern artifact structure, annotations, and metadata exchange between stages. Central to governance and discoverability are metadata catalogs and lineage systems, while feedback loops enable continuous improvement through monitoring agents, drift detection, and automated retraining triggers.
AI Agents and Roles
Each AI agent fulfills a system role with defined interfaces and responsibilities:
- Discovery Agent: Catalogs data sources, infers schemas, and captures metadata.
- Ingestion Agent: Extracts, transforms, and loads raw data into landing zones.
- Preparation Agent: Profiles datasets, detects anomalies, and applies cleansing rules.
- Feature Engineering Agent: Derives and enriches variables for modeling.
- Exploratory Analysis Agent: Generates visualizations, identifies patterns, and drafts hypotheses.
- Modeling Agent: Selects algorithms, trains models, and tunes hyperparameters.
- Validation Agent: Evaluates performance, detects drift, and triggers retraining.
- Simulation Agent: Executes what-if analyses and stress tests.
- Optimization Agent: Solves prescriptive decision problems for resource allocation.
- Narrative Agent: Crafts textual summaries and integrates visuals into reports.
- Deployment Agent: Manages containerization, API endpoints, and service updates.
Orchestration and Workflow Engines
The orchestration layer schedules tasks, enforces retries, maintains checkpoints, and monitors service health. Key concepts include task definition, Directed Acyclic Graphs, schedulers, retry policies, and health checks. Engines such as Apache Airflow, Kubeflow Pipelines, Prefect, Dagster, AWS Step Functions, Azure Data Factory, and Google Cloud Dataflow provide DAG-based orchestration, autoscaling, and error handling across cloud and on-premises environments.
Pipeline Stages and Handoffs
Data Discovery and Ingestion
Automated source identification, schema inference, and adaptive connector tuning deliver raw data and metadata manifests to staging zones.
- AI Capabilities: Source Cataloging, Schema Inference, Adaptive Connector Tuning
- System Roles: Metadata Repository, Orchestration Engine
- Tools: Apache NiFi, AWS Glue Data Catalog, Azure Data Catalog, Google Cloud Data Catalog
Data Preparation and Cleaning
Data quality is enforced through anomaly detection, rule synthesis, and automated imputation, producing standardized datasets with quality metrics and lineage.
- AI Capabilities: Anomaly Detection, Rule Synthesis, Automated Imputation
- System Roles: Cleansing Engine, Quality Dashboard
- Tools: Great Expectations, Informatica Data Quality, Trifacta
Feature Engineering and Enrichment
Automated transformation, external data linking, and relevance analysis generate feature sets managed in a feature store.
- AI Capabilities: Automated Transformation, Semantic Matching, Feature Relevance Analysis
- System Roles: Feature Store, Dependency Tracker
- Tools: Featuretools, Google Vertex AI Feature Store
Exploratory Data Analysis
Visualization agents select appropriate charts, detect patterns, and annotate insights with natural language explanations.
- AI Capabilities: Pattern Recognition, Adaptive Visualization Selection, Natural Language Annotation
- System Roles: Visualization Engine, User Interaction Agent
- Tools: Tableau, Microsoft Power BI, Apache Superset
Predictive Modeling
AutoML selects algorithms, tunes hyperparameters, and manages experiments, optimizing for accuracy and resource efficiency.
- AI Capabilities: AutoML Algorithm Selection, Hyperparameter Optimization, Early Stopping
- System Roles: Experiment Tracker, Compute Orchestrator
- Tools: MLflow, Weights & Biases, Neptune.ai, H2O.ai Driverless AI, DataRobot, Amazon SageMaker Autopilot
Model Validation and Monitoring
Performance benchmarking, drift detection, and automated retraining triggers are visualized on monitoring dashboards linked to incident management.
- AI Capabilities: Performance Benchmarking, Drift Detection, Automated Retraining
- System Roles: Monitoring Dashboard, Incident Manager
- Tools: AWS SageMaker Model Monitor, Prometheus, Grafana, Datadog
Simulation and Scenario Planning
Agents explore parameter spaces, conduct sensitivity analyses, and summarize scenario outcomes for strategic planning.
- AI Capabilities: Parameter Sampling, Sensitivity Analysis, Scenario Summarization
- System Roles: Simulation Engine, Scenario Repository
- Tools: AnyLogic, Arena Simulation, MATLAB Simulink
Prescriptive Analytics and Optimization
Mathematical solvers and reinforcement learning agents recommend resource allocations and generate trade-off analyses.
- AI Capabilities: Linear and Integer Optimization, Multi-Objective Analysis, Reinforcement Learning Policies
- System Roles: Optimization Engine, Decision Execution API
- Tools: Gurobi, IBM CPLEX, Google OR-Tools
Narrative Insight Generation
Generative language models produce context-rich summaries and visuals, adapted to stakeholder personas.
- AI Capabilities: Contextual Summarization, Retrieval-Augmented Generation, Style Adaptation
- System Roles: Template Repository, Content Review Interface
- Tools: OpenAI ChatGPT, Anthropic Claude, AI21 Studio, Hugging Face Transformers, LangChain
Deployment and Continuous Improvement
CI/CD pipelines automate builds, tests, and deployments while self-healing orchestration and feedback-driven optimization maintain production reliability.
- AI Capabilities: Dynamic Orchestration, Self-Healing, Feedback-Driven Optimization
- System Roles: CI/CD Pipeline, Version Registry
- Tools: Jenkins, Docker, Kubernetes, Terraform
Metadata, Catalogs, and Lineage
Metadata describes schemas, ownership, quality scores, and update schedules. Data catalogs index metadata for search and governance, while lineage traces data transformations across pipeline stages. Schema registries validate compatibility, and tagging enforces classification and access control. Tools include Collibra, Alation, Databricks Unity Catalog, Apache Atlas, Microsoft Purview, and AWS Lake Formation.
Event-Driven Architecture
Asynchronous communication via message brokers decouples producers and consumers. Core constructs include event buses, topics, consumer groups, backpressure, and dead-letter queues. Platforms such as Apache Kafka, AWS Kinesis, Azure Event Hubs, and Google Cloud Pub/Sub support scalable streaming integration.
Version Control and Artifact Management
Reproducibility demands Git-based source control, versioned container registries, and model artifact stores. Configuration as code and semantic versioning ensure consistent environments. MLOps platforms like MLflow, Pachyderm, DVC, Weights & Biases, and Neptune.ai track experiments, data, and models.
Governance, Security, and Compliance
Role-Based Access Control governs permissions. Encryption in transit and at rest, immutable audit logs, centralized secret management, and policy engines enforce data residency and privacy. Secret stores include HashiCorp Vault, AWS Secrets Manager, Azure Key Vault, and Google Cloud Secret Manager. API gateways such as Kong, Apigee, and AWS API Gateway secure microservice interactions.
Monitoring, Feedback, and Continuous Improvement
Monitoring agents track infrastructure and model metrics. Drift detection and user feedback feed into retraining workflows. Experiment tracking guides optimization, and governance reviews ensure compliance. Observability tools include Prometheus, Grafana, and Datadog.
Handling Data Consistency and Latency Variations
Strategies for eventual consistency and late arrivals include watermarking, checkpointing, idempotent writes, and defined consistency windows. Reprocessing routines ensure completeness without duplicates.
Schema Drift and Data Quality Variations
Automated schema reconciliation agents compare source definitions against registry baselines. Flexible type casting and anomaly pattern libraries accelerate cleansing. Progressive validation gates log noncritical discrepancies while blocking critical mismatches.
Resource Management and Scaling
Autoscaling policies adjust compute replicas or node sizes based on metrics. Load shedding defers low-priority tasks, batch window optimization trades latency for throughput, and resource quotas prevent runaway consumption.
Regulatory and Compliance Edge Cases
- Policy Engines enforce residency and privacy rules at the agent level.
- Dynamic Encryption Controls apply field-level encryption via key vault integration.
- Automated retention workflows purge or archive data per region-specific policies.
- Immutable audit trails capture all agent activities for compliance audits.
Asynchronous Integration Patterns
- Event Bus Fan-In/Fan-Out decouples batch and streaming pipelines.
- Stateful Orchestration persists workflow state for asynchronous triggers.
- Hybrid Triggers enable batch pipelines to subscribe to event streams.
- Backpressure Handling smooths bursts via buffering and throttling.
Interpretability and Explainability
- Interpretability Agents compute feature attributions (SHAP, LIME) alongside predictions.
- Surrogate Models approximate complex architectures for human review.
- Explanation Metadata embeds saliency maps or rule lists in payloads.
- Compliance Workflows route explanations to domain experts for bias detection.
Security, Privacy, and Ethical Considerations
- Data Provenance Verification uses fingerprinting and checksums to detect tampering.
- Adversarial Input Detection flags anomalous patterns indicative of attacks.
- Privacy-Preserving Techniques leverage differential privacy and federated learning.
- Ethical Guardrails embed policy modules to veto noncompliant outputs.
Resilience and Contingency Patterns
- Fallback Agents deliver simplified results when primaries fail.
- Checkpoint and Resume persist intermediate states for recovery.
- Circuit Breakers isolate failing components and prevent cascading retries.
- Health Probes and Self-Healing replace unhealthy instances automatically.
Domain-Specific Extensions
- Domain Agent Extensions add tailored logic for specialized data types.
- Configurable Rule Repositories allow expert adjustments without code changes.
- Interoperable Formats support standards such as DICOM or NetCDF.
- Domain Knowledge Graphs enrich reasoning with industry-specific ontologies.
Best Practices and Extension Strategies
- Modular Architecture with interchangeable microservices and clear APIs.
- Configuration-Driven Behavior externalizes thresholds and rules.
- Comprehensive Metadata tags every artifact for context and debugging.
- Automated Testing, including chaos testing, surfaces edge-case failures early.
- Continuous Monitoring and Feedback sustain adaptability under evolving conditions.
AI Tools and Resources
Key platforms and libraries organized by category:
- Data Ingestion and Cataloging: Apache NiFi, AWS Glue Data Catalog, Azure Data Catalog, Google Cloud Data Catalog
- Messaging and Streaming: Apache Kafka, AWS Kinesis, Azure Event Hubs, Google Cloud Pub/Sub
- Data Quality and Preparation: Great Expectations, Informatica Data Quality, Trifacta
- Feature Engineering and AutoML: Featuretools, H2O.ai Driverless AI, DataRobot, Amazon SageMaker Autopilot, Google Vertex AI Feature Store
- Machine Learning Frameworks: TensorFlow, PyTorch, scikit-learn, Dask, Apache Spark MLlib
- Experiment Tracking and MLOps: MLflow, Weights & Biases, Neptune.ai, Pachyderm, DVC
- Simulation and Optimization: AnyLogic, Arena Simulation, MATLAB Simulink, Gurobi, IBM CPLEX, Google OR-Tools
- Orchestration and Infrastructure: Apache Airflow, Kubeflow Pipelines, Prefect, Dagster, Kubernetes, Terraform
- Observability and CI/CD: Prometheus, Grafana, Datadog, Jenkins, Docker
- Secrets and API Management: HashiCorp Vault, AWS Secrets Manager, Azure Key Vault, Google Cloud Secret Manager, Kong, Apigee
- Generative AI and NLP: OpenAI ChatGPT, Anthropic Claude, AI21 Studio, Hugging Face Transformers, LangChain
The AugVation family of websites helps entrepreneurs, professionals, and teams apply AI in practical, real-world ways—through curated tools, proven workflows, and implementation-focused education. Explore the ecosystem below to find the right platform for your goals.
Ecosystem Directory
AugVation — The central hub for AI-enhanced digital products, guides, templates, and implementation toolkits.
Resource Link AI — A curated directory of AI tools, solution workflows, reviews, and practical learning resources.
Agent Link AI — AI agents and intelligent automation: orchestrated workflows, agent frameworks, and operational efficiency systems.
Business Link AI — AI for business strategy and operations: frameworks, use cases, and adoption guidance for leaders.
Content Link AI — AI-powered content creation and SEO: writing, publishing, multimedia, and scalable distribution workflows.
Design Link AI — AI for design and branding: creative tools, visual workflows, UX/UI acceleration, and design automation.
Developer Link AI — AI for builders: dev tools, APIs, frameworks, deployment strategies, and integration best practices.
Marketing Link AI — AI-driven marketing: automation, personalization, analytics, ad optimization, and performance growth.
Productivity Link AI — AI productivity systems: task efficiency, collaboration, knowledge workflows, and smarter daily execution.
Sales Link AI — AI for sales: lead generation, sales intelligence, conversation insights, CRM enhancement, and revenue optimization.
Want the fastest path? Start at AugVation to access the latest resources, then explore the rest of the ecosystem from there.