

AI Powered Security and Risk Management A Practical End to End Workflow
To download this as a free PDF eBook and explore many others, please visit the AugVation webstore:
Introduction
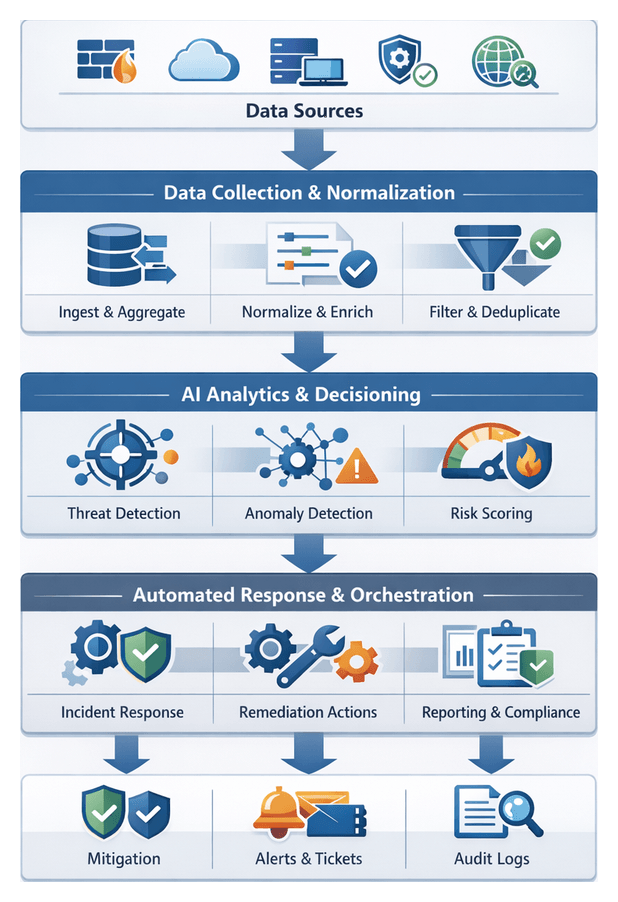
Security Landscape and Data Challenges
Over the past decade, the enterprise security landscape has been reshaped by cloud adoption, remote work expansion, and the proliferation of IoT devices. Threat actors—from nation-state campaigns to financially motivated cybercriminals—leverage sophisticated techniques such as fileless malware, zero-day exploits, and multi-stage attacks. These campaigns traverse hybrid clouds, virtualized data centers, on-premises infrastructure, and edge networks, exploiting gaps in visibility and coordination to remain undetected for extended periods. As digital footprints grow, security teams face unprecedented volumes, velocities, and varieties of telemetry data, challenging traditional perimeter defenses and manual processes.
Modern environments generate logs from firewalls, intrusion detection systems, endpoint detection and response agents, cloud security posture assessments, vulnerability scanners, threat intelligence feeds, and identity governance solutions. Each source delivers unique schemas, timestamp conventions, and metadata attributes. This heterogeneity creates:
- Visibility gaps, forcing analysts to pivot across multiple consoles and slowing investigations.
- Inefficient workflows dominated by manual exports, spreadsheet consolidations, and ad hoc scripts.
- Inconsistent reporting for compliance and executive metrics, eroding stakeholder confidence.
- Poor data quality, with duplicate events, missing fields, and misclassifications introducing noise.
- Scalability limits, as parsing pipelines and point solutions falter under growing log volumes.
Unified Data Collection and Integration
Establishing a centralized data collection pipeline is the essential first step toward cohesive security operations. This stage aggregates and normalizes all security-relevant telemetry—logs, metrics, configuration snapshots, vulnerability findings, and threat indicators—into a unified stream. Key functions include:
- Aggregation: Ingest data from firewalls, SIEM platforms, Splunk, endpoint agents, cloud APIs, vulnerability scanners, and threat feeds.
- Normalization: Convert diverse formats into a canonical schema, apply consistent timestamp conventions, and standardize field names for source, severity, and asset identifiers.
- Deduplication and Filtering: Eliminate redundant events, suppress routine health checks, and focus processing on actionable telemetry.
- Preliminary Enrichment: Tag events with metadata—geolocation, vendor family, protocol context—to streamline downstream AI parsing and correlation.
- Reliability and Scalability: Leverage streaming platforms such as Apache Kafka or cloud-native equivalents with retry logic, backpressure handling, and horizontal scalability.
Prerequisites and Conditions
- Data Source Registry: Document all security systems with connection details, protocols (syslog, REST API, message bus), formats, and expected volumes.
- Secure Connectivity: Establish TLS, VPN, or private links and least-privilege service accounts for log and metric retrieval.
- Time Synchronization: Ensure all systems use NTP or equivalent time services for accurate event correlation.
- Governance Policies: Define classification rules, retention schedules, data residency, encryption standards, and role-based access controls.
- Schema Definition and Mapping: Develop a canonical event model covering fields such as timestamp, source IP, user identity, asset tag, and severity.
- Ingestion Infrastructure: Provision resilient message queues, streaming platforms, batch connectors, and change data capture mechanisms.
- Monitoring and Alerting: Implement dashboards tracking latency, throughput, error rates, and backlogs, with automated alerts for connector failures or schema mismatches.
- Cross-Functional Collaboration: Align security, IT operations, network engineering, and application teams on onboarding, schema updates, and change control.
- Continuous Improvement: Review performance and data quality metrics regularly to refine filtering rules and mappings.
- Security Hardening: Enforce host hardening, network segmentation, and key management for the ingestion platform and connectors.
Orchestrated AI Workflows in Security
To overcome fragmented processes and manual handoffs, organizations implement an orchestrated AI workflow that unites people, processes, and technology into an adaptive pipeline. This orchestration layer acts as the traffic manager, directing data flows between detection engines, enrichment modules, ticketing systems, and response platforms. Key stages include:
- Trigger and Ingestion: Events, alerts, or scheduled scans initiate workflows via a central orchestration engine.
- Enrichment and Contextualization: AI agents retrieve relevant telemetry, threat intelligence, and asset data to add context.
- Automated Decisioning: ML models assess severity, compute risk scores, and recommend next steps.
- Task Assignment: Orchestration routes tasks to analysts, ticketing systems, or automated responders.
- Action Execution: Automated playbooks or human teams perform containment, remediation, or policy updates.
- Recording and Reporting: All actions and communications are logged for audit, analytics, and continuous improvement.
System Interactions and Integration Patterns
- Message Bus Integration: Event notifications travel via Kafka clusters or RabbitMQ queues, decoupling producers and consumers.
- RESTful APIs: Orchestration services call platforms like Cortex XSOAR to fetch playbook results or update incident statuses.
- Webhooks: Real-time cloud workload and SaaS integrations leverage webhooks to trigger flows on suspicious events.
- Data Lake Access: Enrichment engines query centralized asset inventories and historical logs stored in data lakes or via platforms such as Apache NiFi.
- Event Streaming: Bulk telemetry streams into data lakes for near-real-time consumption by AI modules.
Roles and Responsibilities
- Orchestration Engine: Manages triggers, routes tasks, enforces SLAs, tracks metrics, and logs handoffs.
- AI Enrichment Agents: Use ML and NLP to classify alerts, extract indicators, and pull context from intelligence feeds.
- Decisioning Models: Evaluate risk based on policies, historical trends, and supervised learning outcomes.
- Case Management Systems: Provide analysts with structured workspaces, integrating tasks, evidence, and communications.
- Automated Playbooks: Encapsulate conditional logic for containment, mitigation, and remediation through EDR tools and cloud APIs.
- Human Analysts: Validate AI recommendations, perform in-depth investigations, and authorize critical actions.
Auditability and Compliance
- Policy Gates: Enforce approvals and policy checks before critical actions like account suspension.
- Append-Only Logs: Record orchestration commands and AI outputs in tamper-resistant logs.
- Role-Based Access Controls: Restrict sensitive actions and data to authorized roles.
- Evidence Collection: Automatically attach artifacts such as packet captures and memory snapshots to incident records.
- Reporting Interfaces: Generate compliance reports and dashboards summarizing performance, SLA adherence, and control effectiveness.
AI Agent Roles Across the Security Lifecycle
AI agents—software components leveraging machine learning, natural language processing, and decision logic—embed intelligence at each stage of the security lifecycle. A modular agent architecture accelerates threat detection, streamlines investigations, and bolsters risk management.
Data Ingestion and Enrichment Agents
- Connector Management: Maintain secure connections to sources such as SIEM platforms, Splunk, cloud logging services, and databases.
- Schema Normalization: Map vendor-specific formats into standardized records using ML classifiers.
- Contextual Tagging: Use NLP to extract entities—IP addresses, user IDs, file hashes—and enrich with metadata from CMDB systems.
- Noise Filtering: Suppress benign events through rule engines and anomaly detection models.
Detection and Analysis Agents
- Statistical Anomaly Detection: Profile normal baselines and surface deviations in network flows or user behavior.
- Signature and Heuristic Engines: Match known Indicators of Compromise using curated threat feeds.
- Behavioral Analytics: Apply deep learning to action sequences and assign risk scores to behaviors.
- Hybrid Correlation: Combine ML outputs with domain rules to reduce false positives and prioritize alerts.
Prioritization and Risk Scoring
- Asset Context Integration: Weight events using business impact data from IT service management systems.
- Threat Intelligence Correlation: Match anomalies with feeds such as VirusTotal and Recorded Future.
- Dynamic Risk Modeling: Calculate composite scores with Bayesian networks and decision trees.
- Alert Prioritization: Rank incidents to trigger high-priority workflows for critical assets.
Automated Response and Remediation Agents
- Playbook Selection: Use AI classifiers to match incidents with appropriate response procedures.
- Command Orchestration: Integrate with EDR tools, firewalls, and cloud APIs to isolate hosts or block IPs.
- Adaptive Execution: Apply reinforcement learning to refine quarantine scope and remediation timing.
- Recovery Confirmation: Run post-remediation scans and compliance checks to verify system restoration.
Orchestration and Workflow Coordination
- Task Sequencing: Ensure enrichment precedes detection and that risk scoring informs response decisions.
- State Management: Track incident states and synchronize updates across dashboards and ticketing systems.
- Exception Handling: Detect workflow failures, trigger manual approvals, and reroute tasks as needed.
- Scalability: Auto-scale containerized agent instances to handle event spikes and maintain availability.
Workflow Architecture and Module Layout
A modular workflow architecture delivers consistency, scalability, and clarity. By defining clear interfaces, data contracts, and orchestration mechanics, organizations align technical teams, streamline integrations, and enable component substitution as needs evolve. The architecture is structured into three logical tiers:
- Data Orchestration Tier:
- Collection Engine: Aggregates logs, metrics, inventories, and threat feeds.
- Normalization Service: Converts inputs to canonical schemas.
- Enrichment Hub: Applies initial tagging and contextual metadata.
- Analytic Processing Tier:
- Threat Correlator: Matches indicators against internal telemetry.
- Anomaly Detector: Applies ML models for behavior baselining.
- Risk Scorer: Calculates dynamic risk ratings based on asset criticality.
- Action Execution Tier:
- Remediation Orchestrator: Automates patching and configuration updates.
- Case Management Interface: Generates investigation workflows and tickets.
- Compliance Reporter: Produces audit-ready evidence and summaries.
Interface Contracts and Handoffs
- Synchronous APIs: For on-demand risk evaluations and report generation, secured by OAuth2 or mutual TLS, documented via OpenAPI.
- Asynchronous Event Streams: Real-time telemetry, alerts, and retraining triggers over Apache Kafka topics, with schema management for backward compatibility.
- Batch Transfers: Scheduled exports for compliance archives and large scans via secure file shares or object storage.
Handoffs include validation checks with correlation identifiers and schema versions. Downstream modules acknowledge or return errors, triggering automated retries and alerts for integration issues.
Dependencies, SLAs and Governance
- Data Dependencies: Asset inventories, threat feeds, and historical logs.
- Compute Requirements: CPU, memory, GPU for model inference.
- Storage Needs: Databases, retention policies, and encryption standards.
- Network Constraints: Bandwidth, latency, and segmentation requirements.
- Third-Party Services: External APIs, licensing, and subscription tiers.
Each dependency is paired with service level agreements defining uptime targets, maintenance windows, and escalation paths. Architecture artifacts—workflow diagrams, interface catalogs, dependency matrices, and module registries—are maintained in version control with change workflows, peer reviews, and automated testing.
Readiness and Handoff to Implementation
Upon completing the architecture stage, teams receive a handoff packet containing high-resolution diagrams, interface catalogs, module registry exports, dependency matrices with SLAs, testing playbooks, deployment guides, and governance charters. Operational readiness reviews ensure that infrastructure, development, and security teams can deploy, integrate, and monitor the solution effectively. This structured transition accelerates time to value, minimizes rework, and establishes a clear chain of custody for every workflow component.
Chapter 1: Data Collection and Integration
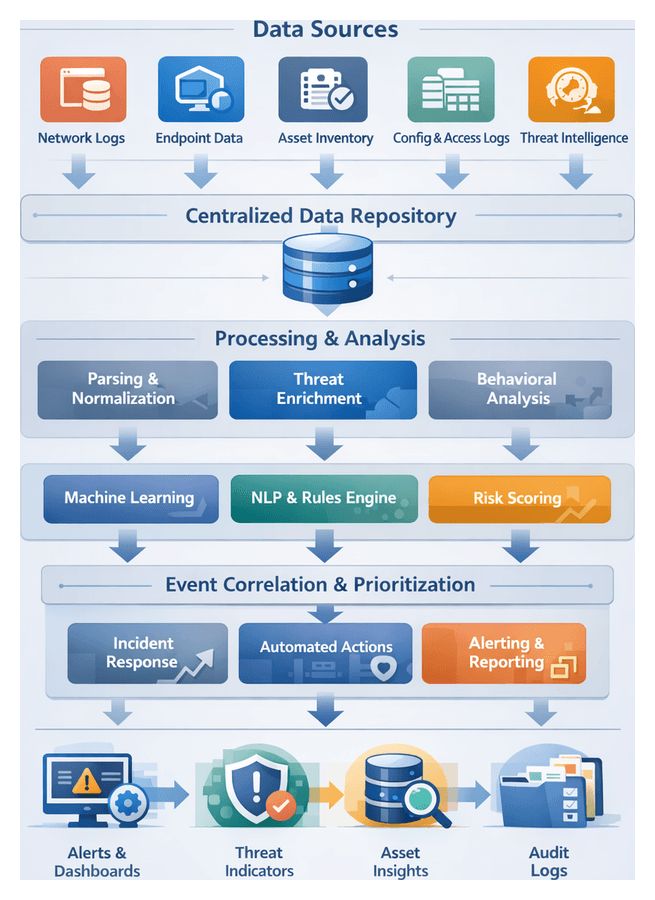
Establishing a Centralized Data Foundation
Purpose and Industry Context
A centralized data pipeline unifies security telemetry—network logs, endpoint metrics, asset inventories, configuration records and external threat intelligence—into a single repository. This foundation eliminates silos, ensures consistent semantics and quality standards, and delivers the unified data fabric required for AI-driven analysis, risk scoring and automated response. By meeting regulatory requirements such as GDPR, HIPAA and PCI DSS, organizations in financial services, healthcare and critical infrastructure achieve both operational visibility and compliance readiness.
Core Data Inputs
- Network and Perimeter Logs: Traffic flows, firewall events and intrusion prevention records capture anomalous connections and lateral movement attempts.
- Endpoint and Host Metrics: CPU, memory and process activity from EDR platforms reveal unexpected code execution, privilege escalation and file integrity changes.
- Asset Inventory Records: Databases of hardware and software assets, including configurations and application versions, support vulnerability correlation and risk scoring.
- Configuration and Change Data: Patch histories, configuration snapshots and change control logs provide context for drift and compliance assessments.
- Identity and Access Logs: Authentication events, privileged session records and directory synchronization snapshots detect credential misuse and insider threats.
- External Threat Intelligence Feeds: Indicators of compromise, vulnerability disclosures and reputation scores from feeds in STIX/TAXII, CSV or JSON formats enrich internal records.
Prerequisites and Governance
- Data Governance Framework: Policies for ownership, retention, privacy and access control ensure alignment with organizational and regulatory mandates.
- Security Controls: TLS, VPNs, API keys and certificates protect data in transit and at rest, while role-based access controls restrict pipeline operations.
- Infrastructure Readiness: Scalable compute, storage and networking with high availability and disaster recovery provisions support high-velocity streams and large batch loads.
- Data Quality Baseline: Initial validation for completeness, timestamp accuracy and schema conformity prevents downstream errors and monitors ongoing fidelity.
- Schema and Field Mappings: A canonical model such as Elastic Common Schema guides normalization, with documented mappings from vendor-specific attributes.
Connectivity to Enterprise Platforms
- SIEM Solutions: Native ingestion connectors for Splunk and Elastic.
- Streaming Services: High-throughput collectors such as AWS Kinesis and Azure Event Hubs.
- Configuration and Asset Databases: Integrations with ServiceNow CMDB and other ITSM platforms.
- Endpoint Detection and Response: APIs from EDR vendors supply host metrics, threat alerts and forensic data.
- Cloud Workload Monitoring: Collectors for AWS CloudTrail, Azure Monitor and Google Cloud Logging.
Scalability and Compliance Considerations
- Elastic Resource Allocation: Container orchestration and auto-scaling adapt compute resources to ingestion demands.
- Partitioning and Sharding: Distributing streams by source or log type optimizes throughput.
- Batch vs. Streaming Modes: Real-time processing balanced with cost-effective batch ingestion for less time-sensitive data.
- Backpressure Management: Buffering and rate-limiting prevent downstream overload during surges.
- Retention and Security Policies: Automated purging, encryption at rest and in transit, data masking, audit trails and data residency controls satisfy legal requirements.
AI-Driven Parsing, Enrichment, and Contextualization
Transforming Raw Data into Actionable Intelligence
AI-driven parsing and enrichment bridges the gap between raw collection and advanced analysis by classifying streams, extracting entities and attaching contextual metadata. Machine learning models, NLP pipelines and rule engines reduce noise, surface high-value indicators and prepare semantically consistent records for anomaly detection, risk scoring and response orchestration.
Machine Learning for Event Classification
- Supervised classifiers assign events to known categories—firewall denials or authentication failures—based on labeled training data.
- Unsupervised clustering algorithms detect emerging patterns and outliers in high-volume streams.
- Anomaly detection models score records against historical baselines to flag significant deviations in real time.
Tools such as Splunk with the Splunk Machine Learning Toolkit and Elastic SIEM embed these models directly into the pipeline for continuous retraining and feedback-driven improvements.
Natural Language Processing for Unstructured Feeds
- Entity extraction identifies CVE codes, malware families and attacker group names.
- Topic modeling groups documents into themes to highlight emerging campaigns.
- Sentiment and intent analysis gauge urgency in threat advisories and dark-web postings.
Platforms like Recorded Future and ThreatConnect apply NLP to harvest, parse and correlate unstructured threat intelligence, enriching indicators with context and reputation metrics.
Rule Engines and Hybrid Enrichment
Rule engines codify deterministic policies and known IOCs for immediate triage, while hybrid systems route data to AI classifiers when complex inference is required. Security orchestration platforms such as Cortex XSOAR and Cisco SecureX coordinate rule execution alongside model inference based on context and performance needs.
Context Enrichment and Threat Tagging
- Asset mapping from CMDBs attaches business impact scores to hosts and services.
- Geo-location lookups translate IP addresses into country and city identifiers.
- Identity context from directory services flags privileged users and group memberships.
- Standardized tags—MITRE ATT&CK TTPs, vulnerability severity and malware taxonomy—enable precise filtering and visualization.
Metadata Management and Lineage
Data lineage frameworks record enrichment steps, model versions and rule sets applied to each record. Timestamps, pipeline stage identifiers and validation statuses support auditability, forensic analysis and retrospective corrections.
Orchestrating AI-Driven Security Workflows
Need for Orchestration
Fragmented tools and manual processes impede visibility, slow triage and introduce compliance gaps. An orchestrated AI workflow formalizes data ingestion, enrichment, detection, prioritization and response into a cohesive pipeline that delivers measurable risk reduction, consistent audit trails and rapid coordination between human analysts and machine agents.
Core Workflow Components
- Event Bus and Data Bus: Real-time transport of normalized events to analytics engines and orchestration modules.
- Orchestration Layer: Central engine enforcing workflow logic, routing events, applying business rules and tracking task status.
- AI Agents: Modular functions—natural language parsing, threat correlation, risk scoring and automated remediation.
- Human-in-the-Loop Interfaces: Dashboards and workbenches for analysts to review alerts, approve playbooks and refine models.
- Audit and Reporting Module: Captures every transition, decision rationale and response action for compliance and continuous improvement.
Workflow Flow and Interactions
- Data Ingestion and Normalization: Collectors apply format-specific parsers to attach metadata such as source, timestamp and environment tags.
- Event Routing and Pre-Filtering: Filtering agents discard low-value noise and route suspicious records to the orchestration queue.
- Intelligence Enrichment: AI agents augment events with threat feed correlation, vulnerability data and reputation scores.
- Behavioral Analysis and Detection: Analytics engines apply machine learning to identify deviations from established baselines and assign confidence scores.
- Risk Scoring and Prioritization: Models integrate asset criticality and business impact to rank incidents for response.
- Investigation Orchestration: Predefined steps—data collection, hypothesis generation, forensic capture—and human-machine task coordination.
- Automated Response Execution: Playbooks act through connectors to firewalls, EDR platforms and cloud APIs for containment and remediation.
- Feedback and Model Refinement: Remediation metrics and false-positive rates feed back into automated retraining and policy adjustment.
Integration and Coordination
- API-Based Integration: RESTful and message interfaces enable automated event push, intelligence retrieval and command execution.
- Event-Driven Architecture: Decouples producers and consumers; tasks trigger on event patterns rather than scheduled polls.
- Role-Based Task Assignment: Access controls assign tasks to appropriate analyst groups, track approvals and escalate overdue items.
- Shared Context Repository: Central store for enriched events, asset attributes and investigation notes to prevent redundant lookups.
- Audit Trail and Reporting: Real-time dashboards and audit-ready documentation capture workflow metrics and transitions.
Benefits of an Orchestrated Approach
- Reduced mean time to detect and respond through automated handoffs.
- Consistent, repeatable processes with standardized policies and playbooks.
- Optimized analyst effort as routine tasks are automated.
- Enhanced visibility and compliance via comprehensive logging and reporting.
- Scalable operations adapting to growing data volumes and evolving threats.
Delivering Unified Outputs and Handoff
Unified Artifact Formats
- Normalized Event Records: JSON objects with timestamp, source, event_type, severity and normalized fields for pattern detection.
- Asset and Inventory Catalogs: Enriched profiles of hosts, identities and cloud resources with ownership and classification metadata.
- Threat Indicator Collections: STIX or JSON feeds of IOCs, vulnerability signatures and reputation scores with confidence metrics.
- Contextual Tagging and Taxonomies: Controlled vocabularies—MITRE ATT&CK tactics, data sensitivity labels and criticality levels.
- Data Lineage and Provenance Logs: Metadata capturing source identifiers, transformation steps and quality metrics for auditability.
Validation and Quality Assurance
- Schema Conformance: Automated validators compare records against a centralized registry, routing invalid entries to exception queues.
- Referential Integrity: Cross-checks identifiers against master data sources to ensure asset and user references resolve.
- Completeness and Freshness: Thresholds for field population and maximum age limits on external feed entries to flag stale data.
- Duplicate Detection: Hashing techniques to collapse redundant records and preserve storage.
- Anomaly Filtering: Noise reduction filters drop or quarantine malformed events guided by configurable rules.
Delivery Mechanisms and SLAs
- Streaming Pipelines: Real-time topics via Apache Kafka for sub-second latency consumption.
- Batch Exports: Periodic deliveries to Snowflake or Hadoop in Parquet or Avro for model training and historical analysis.
- RESTful APIs: On-demand endpoints for ad-hoc enrichment and targeted lookups.
- File Share Interfaces: Secure FTP or object storage buckets for discrete payload drops and audit artifacts.
SLAs define latency objectives, throughput guarantees, uptime targets, error budgets and handoff notifications to ensure predictable delivery and accountability.
Error Handling and Governance
- Dead-Letter Queues: Isolated queues for records that fail validation for human review.
- Circuit Breakers: Rate-limiting controls to suspend ingestion when error thresholds are exceeded.
- Automated Rollback and Replay: Checkpointing for reprocessing from the last known good offset after systemic errors.
- Alerting and Diagnostics: Integration with Splunk and Elastic Stack to surface pipeline health metrics.
- Access Controls and Encryption: Role-based permissions, TLS in transit, AES-256 at rest and privacy filtering of PII.
Continuous Improvement of Output Quality
- Refine taxonomies to align with emerging threats and business priorities.
- Update transformation logic to capture new attributes and correct misclassifications.
- Tune SLAs based on operational metrics and incident response performance.
- Expand interfaces with GraphQL endpoints or new message bus connectors as analytics platforms evolve.
Ensuring Seamless Transitions
By standardizing outputs, formalizing handoff agreements and embedding observability, organizations deliver timely, trustworthy and actionable data to intelligence, detection, risk and response modules. This cohesive foundation accelerates threat mitigation and reinforces enterprise resilience.
Chapter 2: AI-Driven Threat Intelligence
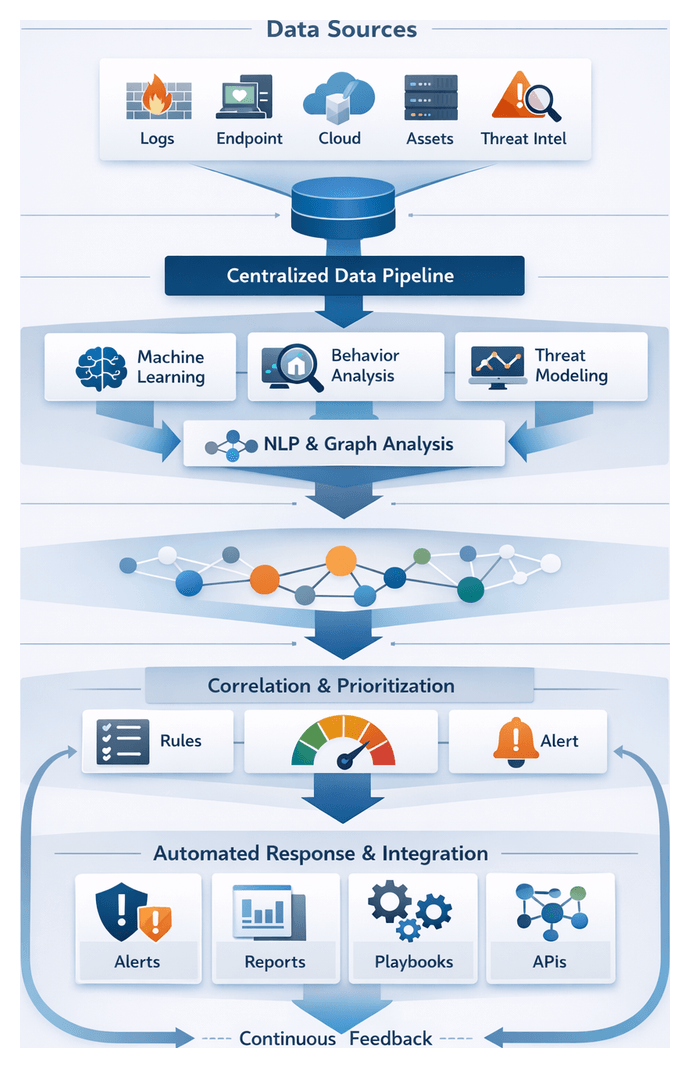
Centralized Data Pipeline and Source Integration
Establishing a centralized data pipeline is the foundational step in any AI-driven security workflow. By aggregating infrastructure logs, endpoint telemetry, cloud metrics, asset inventories, identity records and external threat feeds, organizations eliminate silos, ensure consistency and create the raw material for advanced analytics. Solutions such as Splunk and Elastic ingest syslog streams, API calls and forwarders to provide a unified stream for downstream AI modules. This unified context supports threat detection, risk assessment and automated response at scale.
Inputs and Data Sources
- Infrastructure Logs from network firewalls, routers and switches via Splunk or Elastic.
- Endpoint Telemetry from EDR platforms such as CrowdStrike Falcon and Carbon Black.
- Cloud Metrics and Application Audits from AWS CloudTrail, Azure Monitor and Google Cloud Logging.
- Asset and Configuration Inventories maintained in ServiceNow, Device42 or Microsoft SCCM.
- External Threat Intelligence Feeds delivered via STIX/TAXII from providers like Recorded Future and ThreatConnect.
- Identity and Access Logs from Okta, Microsoft Active Directory and CyberArk.
Prerequisites for Reliable Ingestion
- Secure Connectivity: TLS-encrypted channels or VPN tunnels with least-privilege service accounts.
- Schema and Data Contracts: Canonical schemas (CEF, LEEF, JSON) with version control and deprecation policies.
- Time Synchronization: NTP/PTP across systems, original timestamps preserved and time zone normalization applied.
- Data Governance: Retention policies aligned with GDPR, HIPAA and PCI DSS, field-level encryption and audit logging.
- Scalability Planning: Horizontally scalable frameworks such as Apache Kafka, defined SLOs for latency and buffer capacity.
- Error Handling: Quarantine for malformed events, data quality metrics and alerting on ingestion failures.
- Operational Visibility: Dashboards for source health, throughput and latency; tooling for collector deployment and credential rotation.
These measures transform a collection of connectors into a resilient, secure and governed foundation for AI-driven intelligence.
Machine Learning Models for Threat Contextualization
In the enrichment stage, machine learning models elevate raw indicators into actionable insights by injecting risk scores, attribution data and behavioral context. Integrating AI-driven analysis enables filtering of noise and prioritization of high-impact threats for downstream correlation and response.
Supervised Classification
Supervised learning models—logistic regression, decision trees, random forests and gradient boosting—distinguish malicious indicators from benign ones. Historical labels on phishing domains, malware hashes and command-and-control IPs feed training pipelines. Real-time scoring is exposed through endpoints on platforms such as Amazon SageMaker and Vertex AI.
- Feature Engineering uses domain age, certificate properties and anomaly scores.
- Model Calibration ensures precision and recall with cross-validation.
- RESTful Inference Endpoints support on-demand predictions.
Unsupervised Clustering
Clustering algorithms—k-means, DBSCAN and hierarchical methods—identify latent patterns in unlabeled data. Grouping similar domains or URLs exposes campaigns and isolates outlier indicators for analyst review.
- Noise Reduction by separating anomalies.
- Campaign Identification through analyst-driven cluster labeling.
- Adaptive Grouping with incremental clustering on streaming data.
Graph-Based Relationship Mapping
Graph models represent indicators as nodes and associations—shared IPs, certificate reuse—as edges in databases such as Neo4j or Amazon Neptune. Graph neural networks and random walk algorithms compute embeddings that reveal hidden connections among threat infrastructure.
- Ingestion into graph stores from SIEM events and external feeds.
- Community Detection highlights high-risk clusters.
- Visualization of entity relationships guides threat hunting.
Natural Language Processing
NLP techniques extract entities, sentiment and relationships from unstructured text—threat reports, advisories and social media. Models like BERT or GPT derivatives perform named entity recognition on security-specific corpora.
- Text Preprocessing tokenizes and normalizes terminology.
- Entity Extraction identifies malware names, CVEs and targeted sectors.
- Contextual Embeddings link text findings back to existing indicators.
Ensemble and Hybrid Approaches
Combining multiple model types enhances accuracy and resilience. Voting ensembles aggregate classifier scores, while pipelines sequence NLP extraction, clustering and classification. Rule-based engines complement AI by enforcing signature matches.
- Stacked Models feed lower-level outputs into meta-classifiers.
- Sequential Enrichment applies multiple techniques in turn.
- Feedback Loops incorporate analyst verdicts into retraining.
Continuous Learning and Model Governance
Automated retraining pipelines refresh models based on new labels and feature drift detection. CI/CD integration, canary deployments and automated validation guard against performance regressions. Feature stores like DataRobot Feature Store and Azure Machine Learning Feature Store centralize data for consistent training and inference.
- Data Versioning ensures reproducibility.
- Performance Monitoring tracks drift and latency.
- Rollback Plans address unexpected model behavior.
Intelligence Correlation and Prioritization Flow
This stage transforms enriched indicators and telemetry into prioritized, actionable alerts. By aligning threat data with internal asset and identity context, applying correlation rules and AI-driven pattern detection, organizations reduce noise and focus resources on high-impact events.
Data Mapping and Asset Contextualization
Accurate correlation begins with mapping indicators to assets and users. Queries against CMDBs or ServiceNow provide device owners and criticality. Identity resolution links logon events from Microsoft Active Directory and Okta to user profiles. Threat indicators from ThreatConnect feed into correlation rules alongside logs ingested by Splunk Enterprise Security.
Pattern Matching and Correlation Engines
- Rule-Based Correlation detects known TTP sequences.
- Behavioral Analysis uses ML models to spot anomalies such as data exfiltration.
- Graph Analytics surfaces multi-entity attack chains.
Platforms like IBM QRadar and Elastic Security generate composite events tagged with detection metadata and confidence scores.
Risk Scoring and Prioritization
- Severity Assignment evaluates exploitability, asset criticality and threat actor sophistication.
- Dynamic Scoring combines static risk factors with real-time intelligence.
- Thresholding auto-suppresses low-priority alerts.
Adaptive learning adjusts weights based on analyst feedback. Integration with Cortex XSOAR streamlines this feedback loop.
Orchestration and Integration
- Trigger Event from enriched feeds or streaming telemetry.
- Parallel Data Normalization, Asset Lookup and Entity Resolution.
- Routing to Correlation and Scoring Engines.
- Alert Publication via SIEM dashboards, ticketing systems or SOAR playbooks.
Microservices communicate over APIs and message queues, with defined SLAs for processing times and retry policies.
Stakeholder Coordination
- Shared Dashboards in SIEM or SOAR consoles.
- Synchronized Playbooks triggering incident response workflows.
- Feedback Channels for analysts to annotate and refine alerts.
- Governance Reviews to align rules and models with business risk.
Enriched Threat Feeds and Integration Interfaces
Structured, enriched threat feeds package correlated indicators, TTP mappings, risk scores and confidence metrics into standardized outputs for downstream systems. Adhering to schemas ensures interoperability and consistency across monitoring, risk assessment and response modules.
Structured Intelligence Outputs
- Indicator Packages in STIX-2.1 JSON, grouped by campaign or actor.
- Threat Actor Profiles summarizing attribution, malware families and historical patterns.
- MITRE ATT&CK Mappings with severity weights and detection difficulty ratings.
- Risk Scores and Confidence Metrics from ensemble models.
- Contextual Enrichment Fields including geolocation, business impact and sector tags.
Quality Controls and Dependencies
- Normalization Integrity with a unified threat taxonomy.
- Model Version Metadata embedded for reproducibility.
- Source Trust Scores to quarantine low-reliability feeds.
- Schema Compliance via a central registry and change logs.
- Latency SLAs ensuring timely enrichment.
Delivery Mechanisms
- RESTful APIs for on-demand queries.
- Publish/Subscribe streams via Kafka with Avro schemas.
- STIX/TAXII v2.1 servers for pull and push cycles.
- Webhooks for event-driven SOAR playbooks.
- Scheduled JSON or CSV exports to SFTP.
- SIEM Connectors for Splunk, Elastic Security and IBM QRadar.
- SOAR Integrations with Cortex XSOAR and ServiceNow Security Operations.
Handoff and Best Practices
- Real-Time Monitoring: Live telemetry correlation in SIEM and UEBA platforms.
- Risk Assessment: Ingestion of risk scores into vulnerability management and patching workflows.
- Case Management: Automated population of investigation templates with deep links to intelligence artifacts.
- Automated Response: SOAR playbooks triggered by confidence thresholds.
- Continuous Feedback: Post-incident data refines model parameters and source trust ratings.
- Data Validation Handshakes: Two-way acknowledgements and schema mismatch alerts.
- Schema Versioning: Feed URLs and headers embed version identifiers linked to a registry.
- SLA Monitoring: Alerts on delivery latency, consumer lag and error rates.
- Adaptive Throttling: Rate limiting and batching to protect legacy systems.
- Audit Trails: Immutable logs of enrichment transactions for compliance reviews.
This integrated workflow—from centralized ingestion through AI-driven enrichment, correlation and structured delivery—enables organizations to automate detection, prioritize threats and respond decisively, maintaining a proactive security posture in a dynamic threat landscape.
Chapter 3: Real-Time Monitoring and Anomaly Detection
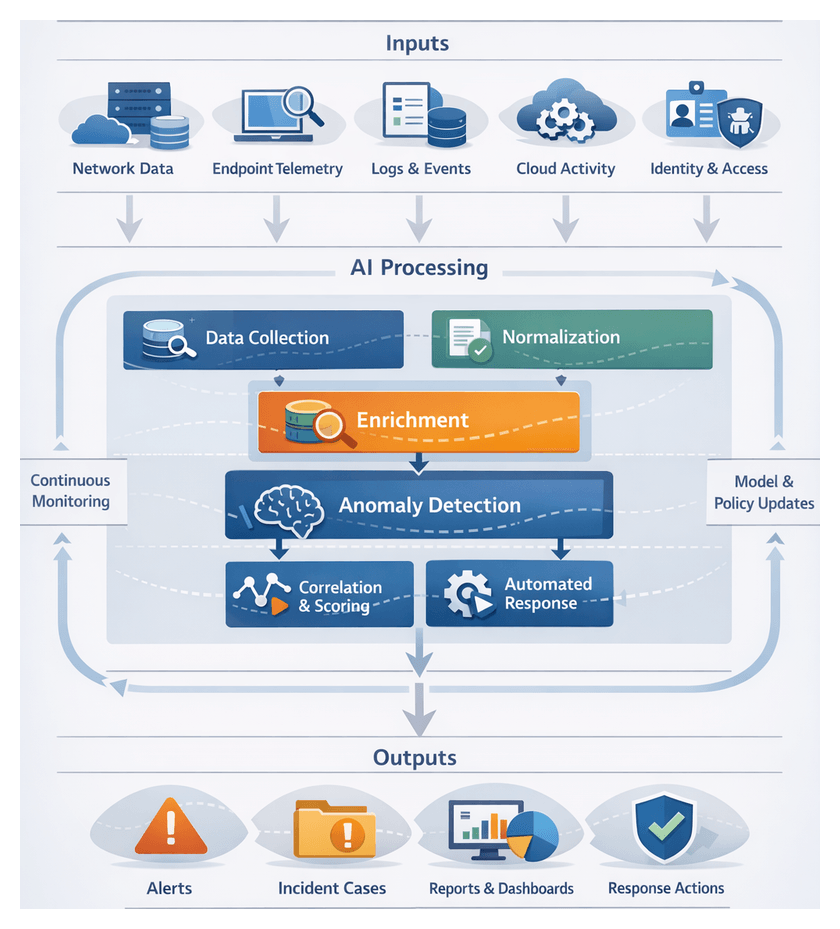
Continuous Surveillance Prerequisites and Core Data Streams
Establishing continuous surveillance is the foundation of an AI-driven security workflow. It ensures real-time visibility across network, endpoint and cloud environments, feeding high-fidelity telemetry into detection engines. Prior to deploying anomaly detection models, organizations must satisfy technical, procedural and governance prerequisites to maintain data integrity, completeness and compliance.
Defining Scope, Boundaries and Retention
Security teams should first identify the assets, applications and user groups in scope for continuous monitoring. This includes:
- Network segments, virtual workloads and endpoint populations for telemetry capture
- Critical applications, services and identities that generate high-value logs
- Data retention periods and storage tiers aligned with GDPR, HIPAA or industry mandates
- Encryption and access controls to safeguard sensitive information
Clear scoping avoids overcollection and privacy breaches, balancing data depth against operational constraints.
Key Technical Prerequisites
- Synchronized Timekeeping: Configure Network Time Protocol (NTP) or Precision Time Protocol (PTP) across sensors, log forwarders and agents to ensure event correlation and accurate forensic reconstruction.
- Scalable Ingestion Infrastructure: Build a resilient data pipeline using streaming platforms such as Apache Kafka or Amazon Kinesis. Include load balancing, back-pressure controls and redundancy to prevent data loss during traffic spikes.
- Standardized Data Schema: Adopt common formats like Elastic Common Schema (ECS) or Splunk Common Information Model (CIM). Consistent field naming, timestamp formats and severity levels enable seamless cross-source correlation.
- Secure Connectivity: Encrypt telemetry in transit with TLS and at rest in storage. Implement certificate rotation and role-based access controls on ingestion endpoints.
- Baseline Profile Initialization: Collect representative data over 30–90 days under varied load conditions. This historical window enables machine learning models to learn normal behavior patterns.
- Asset and Identity Context: Enrich raw telemetry by integrating with a CMDB and identity directories such as Active Directory or Okta. Contextual attributes like asset criticality and user roles inform risk weighting.
- Retention and Compliance Policies: Implement tiered storage—hot, warm and cold—and automated deletion pipelines to comply with organizational and regulatory retention mandates.
Primary Telemetry Streams
A multi-facet view of activity is achieved by ingesting diverse telemetry:
- Network Traffic Metadata: Collect NetFlow, IPFIX and sFlow records from routers and cloud network appliances, revealing flow patterns without payload capture.
- Selective Packet Capture: Use tools like Zeek for deep protocol analysis on triggered sessions, balancing forensic depth against storage costs.
- Endpoint Telemetry: Stream process, file and registry events from agents such as CrowdStrike Falcon or Microsoft Defender for Endpoint.
- System and Application Logs: Normalize syslog, Windows Event Logs, database and web server logs using forwarders like Fluentd or Logstash.
- Cloud Service Telemetry: Capture AWS CloudTrail, Azure Monitor and Google Cloud Audit Logs to track API calls, configuration changes and access events.
- Identity and Access Management Events: Ingest authentication and authorization logs from identity providers, tracking SSO tokens, MFA events and privilege changes.
- Threat Intelligence Feeds: Integrate indicators from Recorded Future or AlienVault OTX, supplying reputations for IPs, domains and file hashes.
- Configuration Snapshots: Continuously export vulnerability scan results and compliance checks to detect drift and newly exposed risks.
Data Quality and Operational Readiness
Maintaining high-quality data streams demands ongoing governance and monitoring:
- Telemetry health dashboards for latency, error rates and ingestion volumes
- Schema validation to enforce presence and conformance of critical fields
- Adaptive sampling to control costs while preserving coverage of key events
- Enrichment pipelines for geolocation, ASN mappings and asset tagging, designed to be fault tolerant
- Privacy-preserving anonymization to protect PII without losing analytical utility
Operational governance includes 24×7 ownership, escalation procedures, change management for sensors and retention policies, and regular exercises to validate end-to-end readiness.
AI-Driven Ingestion, Normalization and Enrichment
AI capabilities automate ingestion and ensure consistency across heterogeneous data sources. Machine learning models dynamically infer schemas, classify feeds and filter noise, reducing manual configuration and maintaining parser accuracy as formats evolve.
Automated Ingestion and Schema Inference
Leading platforms such as Splunk Enterprise Security and Elastic Stack employ AI-driven parsers to:
- Automatically classify incoming sources by type and origin, routing high-priority streams appropriately
- Filter redundant or low-fidelity records, conserving pipeline capacity
- Cluster similar log formats to infer structural templates, accelerating onboarding of new devices
Contextual Enrichment and Confidence Scoring
Once normalized, raw telemetry is enriched with threat intelligence, vulnerability metadata and business context. AI engines perform:
- Entity resolution to consolidate references to the same host or identity across logs
- Context tagging for geolocation, business unit and compliance domain attributes
- Confidence scoring, weighing the reliability of enrichment sources
Platforms like IBM QRadar expose enrichment APIs that feed correlation rules and custom detections.
Behavioral Analytics and Alert Generation
Behavioral analytics leverages both statistical and machine learning methods to detect deviations from dynamic baselines, transform observations into prioritized alerts and orchestrate handoffs without overwhelming analysts.
Data Preprocessing and Feature Engineering
Structured and unstructured inputs—normalized logs from Splunk or Elastic SIEM, flow records, threat feed indicators, and user behavior logs—are validated, de-duplicated and enriched. Noise reduction filters remove benign events while enrichment agents append metadata such as asset criticality and vulnerability scores.
Baseline Modeling and Scoring
- Unsupervised learning jobs (clustering, autoencoders) run in data lakes, with model development on platforms like IBM Watson Studio.
- Automated feature pipelines transform attributes—session durations, file accesses, network statistics—for model training.
- Validated models are deployed into real-time inference layers using streaming frameworks such as Apache Flink.
- Each event is scored by deviation magnitude, threat context from Recorded Future feeds, asset criticality and user trust levels.
Aggregation, Correlation and Case Creation
Anomaly scores alone are insufficient. Correlation engines group related signals—common IPs, sequential authentication events or kill chain stages—using graph analysis. When an incident exceeds thresholds in linked events or cumulative risk, it is escalated to a case.
Notification, Assignment and Enrichment Handoffs
High-priority incidents publish structured alerts in CEF or JSON Schema to SIEM and SOAR queues. Automated tickets are created in ServiceNow or Jira Service Management. Notifications via email or collaboration platforms such as Slack alert on-duty analysts. Secondary enrichment jobs pull process traces from EDR systems, packet captures from forensics appliances and WHOIS data from VirusTotal, attaching findings to the case.
Analyst Interaction and Feedback Loops
Investigations begin in unified workspaces with event timelines, risk scores and enrichment artifacts. Analysts annotate evidence, mark false positives and update case status. These decisions feed back into retraining pipelines and policy repositories, refining detection logic and scoring thresholds.
High-Confidence Alerts and Handoff Mechanisms
High-confidence alerts signal events that meet strict statistical and behavioral criteria. Structured outputs include unique identifiers, timestamps, severity levels, source context, behavioral summaries, enriched attributes and suggested next steps. Alerts adhere to the Open Cybersecurity Schema Framework and are delivered in JSON or AVRO.
Dependencies and Validation
- Anomaly detection models in Elastic Security or Splunk UBA must be continuously validated to prevent drift.
- Threat intelligence feeds from Recorded Future and ThreatConnect require timely updates.
- Asset and identity repositories inform severity weighting; synchronization failures can misclassify alerts.
- Quality assurance filters enforce false positive controls and threshold recalibrations.
Service-level agreements measure latency from ingestion to alert generation, ensuring rapid detection of critical events.
Automated Handoff to Investigation and Response
- Case creation in ServiceNow or Jira Service Management with full alert details.
- Ingestion into SOAR platforms such as Cortex XSOAR, initiating playbooks and tracking remediation steps.
- Real-time dashboards in Microsoft Sentinel and IBM QRadar for manual review.
- Notifications through email, SMS or collaboration tools to on-call personnel.
Bidirectional integrations propagate analyst findings back to the monitoring layer, suppressing duplicates and adjusting baselines.
AI Agents for Orchestration and Automated Response
Intelligent agents bridge analytics and operational controls, executing dynamic playbooks via APIs to firewalls, endpoints and identity systems. They log each action for audit trails and learn from remediation outcomes to refine decision logic.
Policy-Driven Playbooks and Risk Prioritization
Agents follow adaptive playbooks based on incident characteristics and risk scores. AI-driven risk prioritization platforms such as Tenable.io combine threat intelligence, asset value and business context to rank alerts, guiding resource allocation.
Automated Containment and Recovery
- Endpoint isolation via EDR APIs to quarantine compromised hosts.
- Blocking malicious IPs or domains on firewalls and proxies.
- Revoking user credentials through identity management connectors.
- Coordinating patch deployment with vulnerability management tools.
- Post-remediation scans to validate system integrity and close feedback loops.
Platforms like Demisto (part of Cortex XSOAR) exemplify AI-powered response orchestration driven by reinforcement learning.
Scalability, Resilience and Continuous Improvement
To support high data volumes and evolving threats, the entire workflow leverages distributed processing, microservices and container orchestration with Kubernetes. Key features include:
- Horizontal scaling of ingestion, inference and enrichment nodes.
- Load-balanced API gateways and message queues for policy queries and alert distribution.
- Automated failover, retry mechanisms and self-healing workflows for pipeline resilience.
- Feedback loops triggering model retraining, policy tuning and enrichment rule updates.
Cross-functional roles—data engineers, data scientists, SOC analysts, SOAR engineers and governance teams—collaborate in regular reviews to align detection logic with threat intelligence, business priorities and compliance mandates. This living capability adapts to new applications, cloud services and adversary tactics, ensuring proactive defense powered by AI.
Chapter 4: Risk Assessment and Prioritization
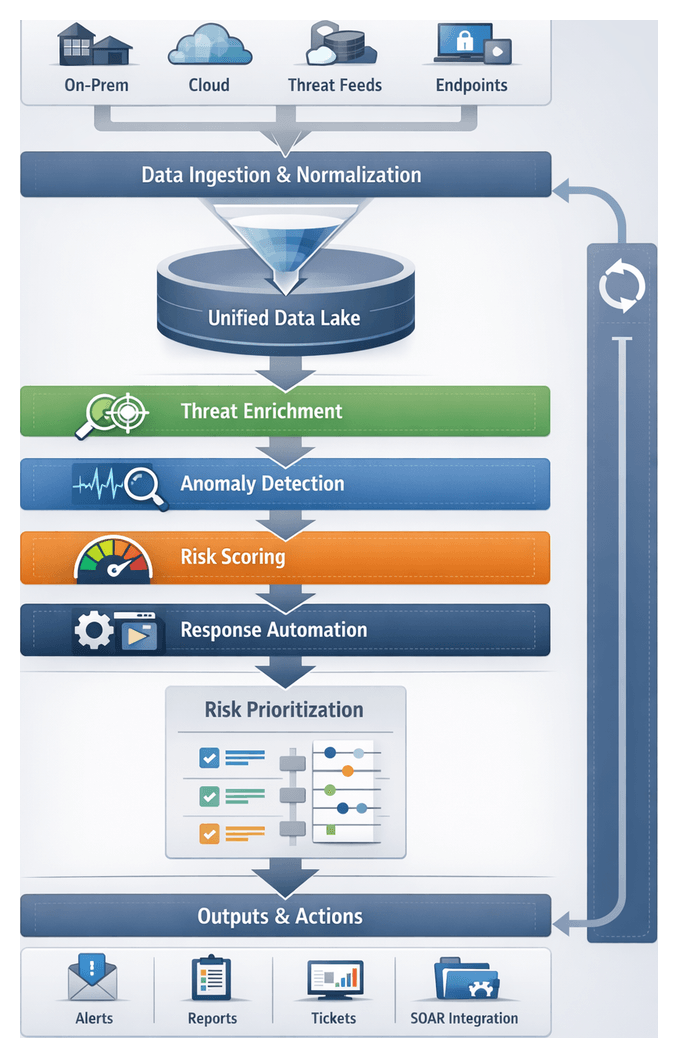
Security Data Unification and Fragmentation Challenges
The modern threat landscape spans on-premises data centers, multi-cloud environments, edge locations and remote workforces. Each domain produces distinct streams of logs, metrics, asset inventories and external threat intelligence. When this security data resides in silos—with inconsistent schemas, isolated toolchains and delayed context—organizations face blind spots, slow detection, manual toil and compliance hurdles. Legacy ingestion pipelines buckle under high volumes, creating backlogs that impair real-time monitoring and elevate risk.
Overcoming these challenges demands a centralized data pipeline that:
- Aggregates logs and telemetry from platforms such as Splunk, Elastic and cloud provider services.
- Enforces schema normalization and data quality controls.
- Integrates threat feeds from Recorded Future and VirusTotal with internal inventories.
- Delivers enriched, metadata-rich events for downstream analytics and response.
This unified approach eliminates silos, accelerates detection, reduces manual interventions and ensures a complete audit trail for compliance frameworks such as PCI DSS, GDPR and NIST SP 800-53.
Orchestrated AI Workflows for Detection and Response
Ad hoc scripts and fragmented point tools cannot keep pace with today’s scale and complexity. Embedding AI agents within an orchestration layer creates structured, end-to-end workflows that deliver consistency, resilience and auditability. Key AI-powered components include:
- Data Ingestion Agents: Secure connectors fetch and normalize logs from SIEMs and cloud services.
- Enrichment Models: NLP and classification engines attach context—IoC mapping, actor attribution and risk tags.
- Anomaly Detection Engines: Unsupervised learning models flag deviations from behavioral baselines.
- Risk Scoring Agents: AI and statistical modules compute exploitability, impact and threat likelihood.
- Response Orchestration Agents: Playbook frameworks such as Cortex XSOAR and IBM Security SOAR automate containment and remediation tasks.
- Adaptive Learning Engines: Reinforcement learning pipelines refine models using post-incident feedback.
An orchestration backbone coordinates these agents via a fault-tolerant event bus, enforces policy management, and logs every workflow step for traceability. This design scales elastically, retries failures, and aligns security actions with business risk priorities.
Risk Evaluation and Prioritization Workflows
Transforming enriched events into prioritized risk lists requires a formalized sequence of aggregation, normalization, weighting, scoring, adjustment, grouping and handoff. This workflow delivers transparent, repeatable and auditable risk assessments that guide remediation and investment decisions.
- Input Aggregation: Collect threat intelligence from enrichment models, alerts from monitoring engines and asset metadata from CMDBs and platforms such as Splunk Enterprise Security.
- Normalization and Enrichment: Standardize data types, unify CVSS vectors and MITRE ATT&CK classifications, and append business process impact scores.
- Weight Assignment: Apply organizational and regulatory multipliers (PCI DSS, GDPR) stored in a policy repository.
- Risk Score Calculation: Combine AI-driven exploit probability (gradient boosting, neural networks) with impact projections (Monte Carlo simulation) into a 0–100 scale.
- Dynamic Adjustment: Recalibrate scores in real time based on active exploit campaigns, maintenance windows or network segmentation changes.
- Ranking and Grouping: Sort items into critical, high, medium and low tiers using clustering algorithms to batch related issues.
- Handoff: Deliver prioritized lists to ticketing systems such as ServiceNow Security Operations or dashboards, and trigger remediation playbooks.
The orchestration layer enforces SLAs, monitors latency and volume, and logs all policy versions and decisions to satisfy audit requirements.
Advanced Scoring Algorithms and Risk Modeling Engines
At the heart of risk assessment lie machine learning and probabilistic inference techniques that quantify risk across likelihood, impact and propagation. Core capabilities include:
- Supervised and Unsupervised Learning: Classification and regression models trained on historical incidents predict exploit likelihood, while clustering and anomaly detection surface novel risk patterns. Platforms such as Splunk Enterprise Security Machine Learning Toolkit and IBM QRadar Advisor with Watson provide prebuilt algorithms and feature management.
- Graph-Based Propagation and Bayesian Networks: Graph engines and Bayesian inference in suites like RSA Archer Suite model interdependencies and calculate how a compromise spreads through connected assets.
- Simulation and Scenario Analysis: Monte Carlo and discrete event simulations in platforms such as AttackIQ evaluate “what-if” scenarios, estimating loss distributions, time-to-compromise and control effectiveness.
- MLOps Framework: Feature stores, model registries, containerized inference services and workflow engines (e.g., Apache Airflow) automate training, validation, deployment and monitoring of risk models.
- Continuous Calibration: Feedback loops ingest incident closure data, detect drift, retrain models via automated pipelines and promote validated versions into production, leveraging services like Microsoft Azure Sentinel.
This combination ensures dynamic, explainable risk scores that adapt to emerging threats and changing environments.
Outputs and Handoff Mechanisms
The risk assessment stage generates deliverables that drive remediation, governance and reporting:
- Prioritized Risk Listings: Ranked inventories of assets and vulnerabilities.
- Interactive Dashboards: Heat maps, trends and KPIs via Splunk or IBM Security QRadar.
- Executive Summaries: High-level narratives and scorecards for leadership.
- Data Exports and API Feeds: JSON/CSV streams to SOAR systems and asset databases.
- Score Reports: Detailed breakdowns of criteria, weights and model versions.
These outputs are versioned, timestamped and annotated for auditability. Handoff to downstream modules occurs through:
- RESTful APIs: Integrations with vulnerability scanners like Tenable.io and Qualys VM.
- Message Queues: Real-time event streams consumed by automation platforms.
- SOAR Triggers: Playbooks in Cortex XSOAR initiate containment and patch workflows.
- Ticketing Integration: Automatic creation of remediation tickets in ServiceNow or Jira.
- Scheduled Reports: Recurring PDF or HTML summaries distributed via email or collaboration tools.
Interface-level SLAs, authentication policies and encryption requirements govern these exchanges to ensure security and reliability.
Continuous Improvement and Compliance Integration
A robust feedback framework captures remediation outcomes, new threat intelligence and control performance metrics to refine risk models and weight policies. As updates occur, the orchestrator automatically incorporates changes without disrupting core services. Compliance and audit readiness are supported through:
- Control Gap Matrices: Automated alignment to NIST CSF, ISO 27001 and other frameworks.
- Evidence Packages: Correlation of risk findings with remediation attestations and exceptions.
- Custom Dashboards: Real-time status of high-risk controls and assets for governance boards and auditors.
- Exportable Documentation: Methodologies, data sources and model configurations for external review.
By seamlessly integrating outputs with retraining workflows and compliance reporting, organizations maintain an adaptive risk posture and demonstrate proactive governance in a continuously shifting threat landscape.
Chapter 5: Vulnerability Management Automation
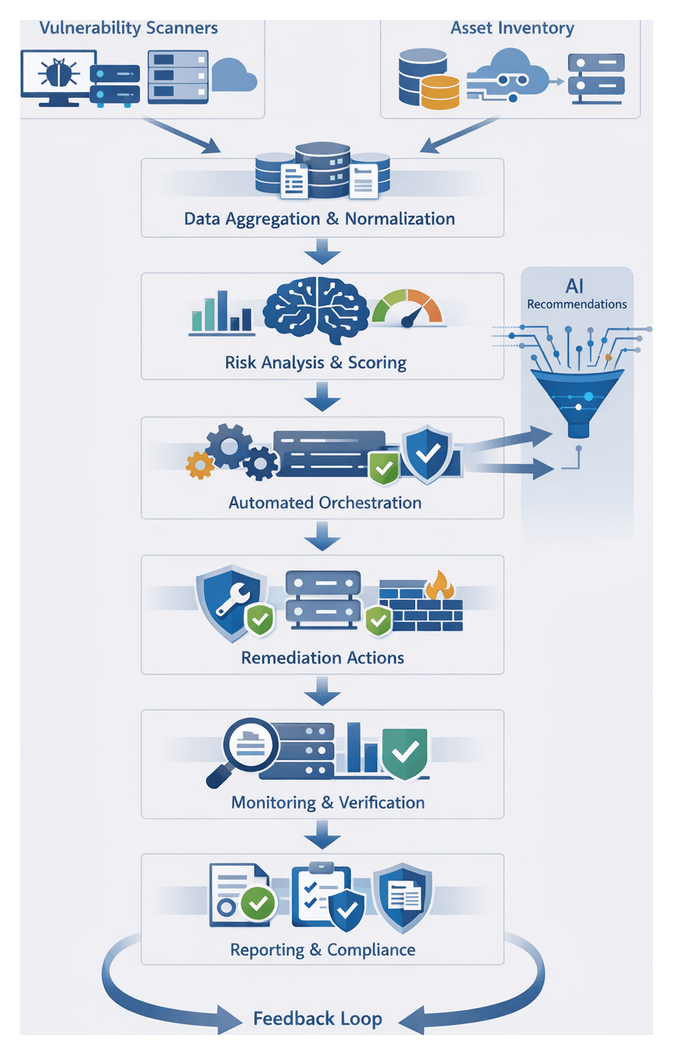
Vulnerability Scan Results and Asset Inventories
Combining vulnerability scan outputs with comprehensive asset inventories establishes the foundation for automated vulnerability management. By ingesting data from multiple scanners and asset repositories, organizations create a unified view of every hardware and software component tied to known vulnerabilities. This high-fidelity dataset enables accurate risk scoring, prioritized remediation, and audit-ready reporting.
Automated vulnerability scanners such as Nessus, Qualys and Rapid7 InsightVM run both agentless and agent-based assessments alongside platforms like Microsoft Defender for Endpoint and Tanium. Manual penetration tests and red-team exercises supplement these tools. Asset data is sourced from CMDBs and ITSM systems such as ServiceNow and BMC Helix, cloud inventories from AWS Config, Azure Resource Graph and Google Cloud Asset Inventory, and network topology tools.
To ensure reliable ingestion and integrity, standardized asset identifiers (serial numbers, GUIDs) must align across systems. Scan policies—covering scope, credentials, frequency and network segmentation—should reflect asset criticality and maintenance windows. Authentication uses least-privilege service accounts and secure credential stores, while API connectors or secure file transfers provide data feeds with defined SLAs for freshness and error handling. A canonical schema for vulnerability records and asset attributes—capturing fields such as asset ID, OS version, CVE number, CVSS score, remediation recommendation and scan metadata—guides data normalization workflows that parse diverse formats, map severity levels, unify timestamps to ISO 8601, validate required fields and deduplicate records.
Connectivity between scanners, inventory repositories and ingestion pipelines requires firewall configurations, reliable APIs with retry logic, and a choice between batch exports or streaming deltas. Quality controls include record-count reconciliation, schema compliance checks, severity distribution monitoring, random sampling against source reports and SLA alerts for ingestion failures. By rigorously integrating and normalizing scan results and asset data, organizations achieve greater visibility, fewer false positives and accelerated time to remediation.
Automated Remediation Orchestration Sequence
The orchestration engine transforms enriched vulnerability data into coordinated remediation actions, replacing manual workflows with standardized, scalable automation. It ingests findings, asset context and risk scores to trigger predefined playbooks that execute patch deployments, configuration updates and compensating controls. By integrating with patch management systems, container registries, firewall controllers and cloud platforms, the engine delivers consistent, auditable and accelerated remediation.
Framework and Workflow Coordination
The typical sequence is:
- Trigger evaluation: receive vulnerability findings with severity, asset metadata and compliance requirements.
- Playbook selection: choose remediation workflows based on severity thresholds, asset criticality and business context.
- Approval gating: route high-impact actions through ITSM approvals.
- Execution: invoke APIs or automation agents to apply fixes on endpoints, servers, containers or network devices.
- Monitoring: track execution status, capture success or failure events and detect anomalies.
- Verification: perform post-remediation checks to confirm resolution and policy compliance.
- Feedback loop: update the vulnerability management platform and risk scoring engines with remediation outcomes.
Playbook Design and Modularity
Playbooks encapsulate discrete actions—OS patch deployments, container image rebuilds, firewall rule adjustments, application hardening and cloud policy enforcement. Modular design enables reuse, rapid adaptation to new vulnerabilities and centralized version control to propagate updates consistently.
Integration and Execution Engines
Orchestration platforms such as Palo Alto Networks Cortex XSOAR and Splunk Phantom provide connector libraries, state management, conditional logic and secure credential storage. They interface with vulnerability management platforms, CMDBs, endpoint management systems and cloud consoles to tailor remediation actions to operational context and minimize disruption.
Human-in-the-Loop and Approval Mechanisms
Integration with ITSM tools—ServiceNow and Jira Service Management—supports automated ticket creation, role-based approvals, time-bound escalations and comprehensive audit logs. This ensures governance for changes affecting critical systems while preserving remediation momentum.
Monitoring, Logging and Feedback
Execution logs, status dashboards and automated alerts feed back into security operations and risk engines. Post-remediation verification and compliance scans confirm vulnerability resolution. This continuous feedback maintains accurate asset risk profiles and drives improvement in playbooks and processes.
Scalability and Resilience
Best practices include:
- Distributed orchestration nodes across regions or data centers.
- Event-driven architectures with message queues to decouple modules and absorb peak loads.
- Idempotent playbooks for safe retries.
- Circuit breaker patterns to detect systemic failures and trigger fallbacks.
- Monitoring of queue backlogs, execution latencies and error rates.
Operational Metrics and AI-Driven Adaptation
Key performance indicators—mean time to remediate, percentage of automated fixes, playbook success rates, reduction in asset risk scores and patch compliance rates—guide workflow optimizations. Emerging AI capabilities enable predictive prioritization, adaptive playbook generation, anomaly detection during execution and natural language interfaces for ad hoc commands, evolving remediation ecosystems toward intelligent self-optimization.
AI-Driven Agent Recommendation and Ticketing Integration
AI models transform raw vulnerability data into prioritized remediation strategies by scoring each finding based on exploit prevalence, asset criticality and remediation complexity. Natural language processing extracts patch identifiers, change log steps and compensating controls from vendor bulletins. Reinforcement learning refines recommendations using feedback on deployment time, rollback incidents and user-reported issues.
Integration with ITSM Platforms
Structured ticket payloads—with CVE references, asset details, recommended steps, dependencies and SLA-aligned completion dates—are generated in ServiceNow or Jira. AI-driven rules route tickets to in-house teams, managed service providers or automated agents, assigning appropriate priority and resolver groups.
SOAR Orchestration and Playbooks
Orchestration engines consume AI recommendations and translate them into executable playbooks that:
- Validate patch applicability against live inventories
- Stage updates in test environments
- Deploy patches via endpoint management agents
- Coordinate reboots within maintenance windows
- Verify post-remediation compliance
Human analysts intervene at annotated checkpoints, while chat and mobile notifications keep stakeholders informed.
Dynamic Prioritization and Workflow Adjustment
Real-time threat intelligence feeds trigger reprioritization of tickets, SLA modifications or emergency playbooks that bypass standard change processes. Dynamic workflows reroute tasks, notify advisory boards or initiate out-of-band approvals when risk thresholds are exceeded.
Collaborative Feedback and Knowledge Base
Operational data from ticket updates—resolution times, rollback incidents and engineer comments—populate a semantic search-enabled knowledge base. The system auto-suggests proven solutions for recurring issues, integrating vendor documentation and internal runbooks to tailor steps to organizational configurations.
Governance, Audit Trails and Compliance
Each ticket records recommendation rationale, AI model version, timestamp and approver identity. Audit dashboards demonstrate compliance with patch policies, track backlog and measure adherence to risk-based SLAs, supporting regulatory requirements and internal governance.
Scalability, Security and Model Retraining
Microservices expose RESTful APIs for scanner ingestion across diverse platforms—Windows, Linux, macOS, network devices, industrial control systems and cloud services. Multi-tenancy partitions recommendations by business unit or geography. Encryption in transit and at rest, mutual TLS and role-based access controls safeguard vulnerability data. Continuous retraining pipelines ingest closed-ticket feedback, updated vulnerability databases and vendor advisories to refine classification, priority scoring and support for new asset types, with versioned model deployments ensuring traceability.
By embedding AI-driven recommendations into automated ticketing, organizations reduce mean time to remediation, lower manual workloads, improve compliance posture, accelerate critical fixes and enhance transparency through comprehensive audit trails.
Remediation Status Reporting and Change Management Handoffs
The final phase translates remediation actions into structured reports and integrates outcomes with change control systems. This ensures transparency, auditability and alignment with enterprise risk policies, closing the loop on the vulnerability lifecycle and demonstrating compliance to stakeholders.
Key Remediation Outputs
- Fix Confirmation Logs with time-stamped records of deployments, source identifiers and verification status.
- Compliance Check Results from post-remediation scans, policy indicators and deviation logs.
- Audit Trails and Evidence Packages consolidating actions, approvals, digital signatures and attachments.
- Executive Summary Reports featuring metrics on remediated vulnerabilities, outstanding issues, remediation velocity and risk reduction impact.
Dependencies and Validation Gates
- Accurate Asset Inventories referencing canonical identifiers from CMDBs or asset repositories.
- Consistent Scanner Configurations and up-to-date signature sets in tools like Qualys or Tenable to avoid false positives.
- Authorized Change Approvals captured in audit logs with timestamps and approver identities.
- Robust API Connectivity between remediation engines and reporting dashboards with retry and error-handling mechanisms.
- Encryption and Access Controls to secure remediation evidence in transit and at rest.
Integration with Change Management Systems
- Automated ticket creation and updates in ServiceNow or Jira, linking vulnerability IDs to ticket numbers.
- Bi-directional API calls to sync approvals and remediation status, with notifications based on escalation policies.
- Alignment of remediation schedules with maintenance windows and automated deferral logic for noncritical patches.
- Automated ticket closure upon verification scan success and generation of post-implementation review documents.
Handoff Mechanisms and SLAs
- SLA Definition mapping vulnerability severity and asset criticality to remediation targets encoded in playbooks.
- Automated Notifications at handoff points, embedding links to dashboards and ticket references.
- Escalation Paths for missed SLAs, notifying team leads, risk managers and executives across regions.
- Handoff Acknowledgments via digital signatures or confirmation clicks as audit evidence.
Feedback Loop to Risk Management
- Risk Score Adjustments that update asset risk profiles upon successful remediations or escalate on delays.
- Process Metrics—mean time to remediation, patch success rates and exception rates—informing playbook refinements.
- Model Retraining Inputs from false positives, remediation failures and exception justifications to improve AI predictions.
- Governance Reporting with real-time remediation statistics in dashboards supporting strategic planning and risk decisions.
By delivering structured remediation reports, enforcing change management handoffs and integrating results into the risk management continuum, organizations transform raw vulnerability data into enterprise-ready intelligence. The combination of automation, audit trails and governance interfaces ensures that remediation efforts are transparent, accountable and continually optimized—ultimately reducing exposure and reinforcing a mature security posture.
Chapter 6: Identity and Access Governance
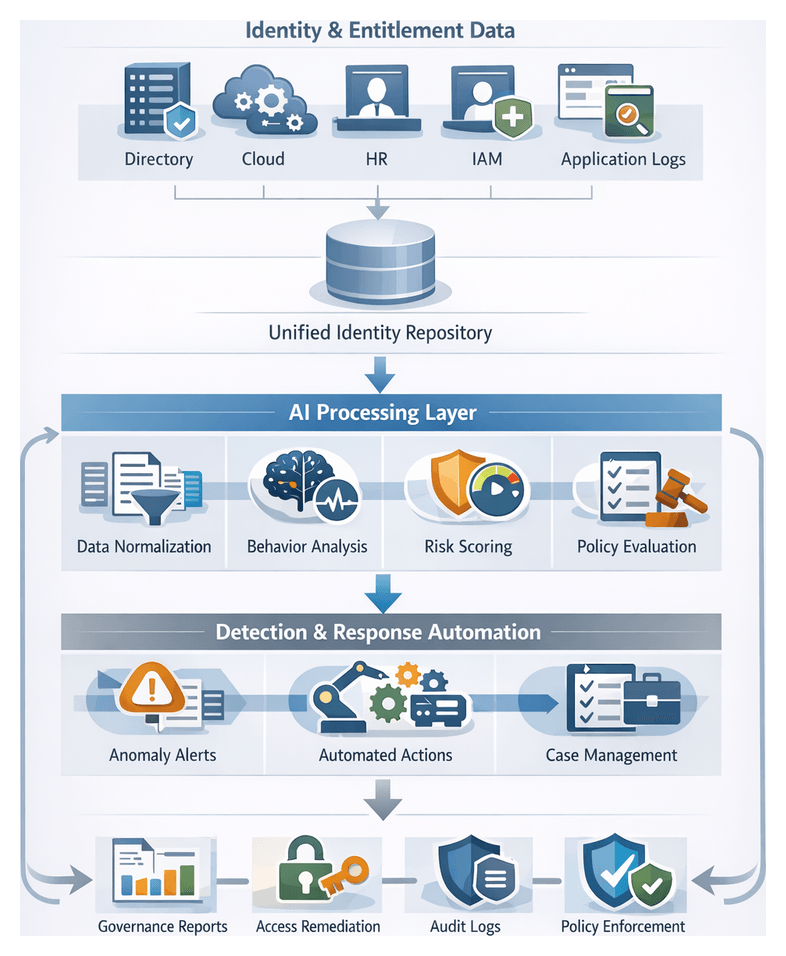
Identity Data Collection and Entitlement Inputs
In the Identity and Access Governance stage, the objective is to aggregate identity attributes, entitlement assignments and access events from across on-premises and cloud platforms into a centralized repository. This unified identity graph provides a high-fidelity view of who has access to what resources, under which conditions and with what privileges, serving as the foundation for analytics, policy evaluation and anomaly detection.
Purpose and Scope
The primary aim of this stage is to maintain a trusted, normalized repository of identity data to support downstream governance processes. Key goals include:
- Centralizing user, service and application identities from Active Directory, Azure Active Directory, LDAP, HR systems and cloud IAM platforms
- Capturing roles, group memberships, delegated privileges and resource entitlements
- Recording authentication events, authorization decisions and privilege usage logs
- Normalizing disparate schemas to a consistent model and validating data integrity
- Enabling real-time ingestion or scheduled synchronization based on source criticality
Data Sources and Integration
Sources range from directory services and identity management platforms to HR systems, privileged access tools and application logs. Representative inputs include:
- Directory Services: Microsoft Active Directory, Azure Active Directory and LDAP servers supply core identity attributes and group hierarchies.
- IAM Platforms: Okta, SailPoint and native IAM modules expose entitlements, approval workflows and role definitions via RESTful APIs.
- HR and ERP Systems: Employment status, department assignments and lifecycle events inform orphan account detection and access revocation triggers.
- Privileged Access Management: Vault solutions record checkout logs, dynamic session credentials and just-in-time elevations.
- Cloud Providers: AWS IAM, Google Cloud IAM and Azure subscriptions provide service principals, resource-level roles and policy attachments.
- Application Logs: Authentication, single-sign-on assertions, API token usage and failed login events enrich entitlement usage analytics.
Prerequisites and Controls
Ensuring data accuracy and security requires:
- Encrypted, least-privilege service accounts and token-based authentication for all integrations
- Attribute mapping specifications to translate source schemas into a unified identity model
- Validation rules for mandatory fields, referential integrity checks and automated alerts for anomalies
- Onboarding procedures, change management workflows and rollback plans for new sources
- Data privacy controls, masking sensitive attributes and enforcing role-based access to the identity repository
With these prerequisites in place, organizations can eliminate silos, reduce manual reconciliation and lay the groundwork for adaptive, risk-driven access governance.
Continuous Access Review and Anomaly Detection
Moving beyond static reviews, continuous access review and anomaly detection orchestrates real-time monitoring of entitlement changes, authentication patterns and resource access events. By applying AI-driven models within streaming data pipelines, this phase detects privilege creep, orphaned accounts and policy violations as they emerge, triggering immediate remediation or human review.
Data Flows and Enrichment
- Streaming Ingestion: Connectors retrieve logs from identity providers, single-sign-on platforms and privileged access appliances.
- Normalization: Events standardize to a schema with fields for user ID, timestamp, action, resource and context metadata.
- Contextual Enrichment: The centralized identity store adds attributes such as role, department and historical access patterns.
- Behavioral Scoring: AI models assess deviations from baseline profiles, assigning risk scores that consider asset criticality and policy severity.
- Policy Evaluation: A policy engine applies segregation-of-duties rules, access review criteria and certification status to determine necessary actions.
- Alerting and Remediation: High-risk events generate tasks in case management systems or invoke automated remediation agents.
- Review and Resolution: Risk scores drive routing to identity administrators or automated modules for approval, revocation or escalation.
- Audit Logging: All actions, decisions and system changes feed into an immutable audit repository for compliance reporting.
Detection Models and Scoring
Core AI scenarios include:
- Privilege Creep: Clustering algorithms flag users whose privilege sets expand beyond peer norms.
- Orphaned Accounts: Rule engines detect stale accounts lacking recent activity or manager assignments.
- Anomalous Logins: Time-series forecasting and geo-IP checks identify unusual sign-on patterns.
- Excessive Group Memberships: Graph analysis finds users in critical groups exceeding policy thresholds.
- Policy Violation Prediction: Supervised classifiers learn from past audits to predict high-risk entitlement changes.
Risk scoring engines combine deviation magnitude, user risk profiles and policy weightings to prioritize events for human or automated action.
Review and Workflow Automation
- Task Creation: Tickets with event details, risk scores and recommended actions are opened in platforms like ServiceNow or Jira.
- Notification: Assigned analysts receive alerts via governance dashboards, email or collaboration tools.
- Investigation: Contextual links to related events, entitlement histories and user profiles support decision-making.
- Decision and Execution: Access approvals, revocations or escalations execute through directory and IAM connectors.
- Validation and Closure: Post-remediation monitoring confirms resolution and updates the audit trail.
- Feedback Loop: Outcome metadata refines AI models, recalibrates thresholds and reduces false positives over time.
Integration with periodic certification campaigns ensures that remediated entitlements are excluded from future review tasks and that unresolved anomalies are highlighted during formal attestation cycles.
Positioning AI Agents in the Security Process
AI agents act as intelligent intermediaries across the access governance lifecycle, automating data parsing, anomaly detection, decision support and remediation. By distributing specialized agents into microservices and event-driven pipelines, organizations can scale operations, maintain consistent audit trails and accelerate response times.
Agent Roles and Capabilities
- Data Ingestion and Normalization Agents: Parse logs (CSV, JSON, CEF) using NLP tokenization and regex patterns; integrate with Splunk and Elasticsearch for storage and indexing.
- Anomaly Detection Agents: Employ clustering algorithms (DBSCAN) and forecasting models (ARIMA, LSTM) to identify deviations from behavioral baselines.
- Threat Enrichment Agents: Query STIX/TAXII feeds and knowledge graphs for threat context, scoring indicators and mapping adversary tactics.
- Risk Scoring Agents: Combine CVSS data, asset criticality and historical outcomes to generate composite risk ratings and ranked dashboards.
- Orchestration Agents: Coordinate playbooks, retries and SLAs using Cortex XSOAR.
- Remediation Orchestration Agents: Execute containment, patch rollouts and access modifications through connectors to ServiceNow and Jira.
- Continuous Learning Agents: Monitor model drift, manage versioning with MLflow and TensorFlow Extended, and trigger retraining pipelines.
Architectural Patterns and Best Practices
- Microservices: Containerize agents with RESTful APIs or message queues for independent scaling and resilience.
- Event-Driven Pipelines: Use Kafka or AWS Kinesis streams for low-latency detection and real-time response.
- Batch Workflows: Schedule non-urgent tasks, such as compliance reporting, on Spark or Hadoop clusters.
- Hybrid Orchestration: Combine immediate alerts for critical events with batch processing for routine analyses.
- Security Controls: Enforce mutual TLS, encrypt data in transit and at rest, and apply RBAC to agent identities.
- Observability: Instrument agents with telemetry for latency, throughput and error rates; centralize logs for root-cause analysis.
- Governance Alignment: Tag automated actions with metadata for audit trails and compliance evidence.
- Continuous Improvement: Maintain feedback loops between analysts and data scientists to refine models and adapt thresholds.
Governance Reports and Access Policy Triggers
Governance reports and policy triggers translate analytics insights into actionable outputs, driving enforcement and compliance. These outputs serve both as operational signals and audit evidence, ensuring that detected risks lead to documented remediation and continuous policy validation.
Outputs and Delivery Mechanisms
- Access Governance Reports: Tabular and narrative summaries of entitlements, risk scores, anomaly trends and policy exceptions.
- Policy Violation Alerts: Real-time notifications categorized by severity and compliance impact.
- Remediation Task Lists: Work queues outlining corrective actions, routed to application owners, managers and IT administrators via ServiceNow or Jira.
- Dashboard KPIs: Visualizations of certification completion, exception rates and access recertification cycle times for executive briefings.
- Audit-Ready Packages: Compiled logs, policy versions and digitally signed decision trails meeting regulatory mandates.
Integration and Reliability
Outputs must integrate reliably with enforcement engines, SIEMs like Splunk or QRadar, GRC platforms and ITSM systems. Common patterns include:
- RESTful APIs exposing alerts and report data for downstream consumption
- Message queues and event buses (Kafka, Azure Event Grid) for asynchronous notifications
- Automated file exports in CSV, JSON or XML to secure repositories
- Webhooks triggering ticket creation, approval workflows and policy adjustments
Auditability and Operational Considerations
- Transactional processing with acknowledgements and idempotent API calls
- Versioned schemas and change logs for policy definitions and report templates
- End-to-end traceability using unique activity identifiers
- High-availability connectors and failover procedures to prevent data loss
- Adaptive scheduling and threshold tuning based on risk fluctuations and audit cycles
- Role-based access controls for report distribution and data retention policies aligned with regulatory requirements
- Standardized taxonomies such as CEF or Open Policy Agent to streamline integration
- Health checks, SLAs and monitoring of API latency, queue depths and job completion rates
- Continuous feedback loops feeding remediation outcomes back into analytics and AI models
By meticulously defining data collection, real-time monitoring, AI agent orchestration and robust reporting, organizations transform identity governance into an adaptive, intelligence-driven process. This integrated approach ensures that access risks are identified, remediated and documented, supporting both dynamic security operations and rigorous compliance objectives.
Chapter 7: Compliance Management and Reporting
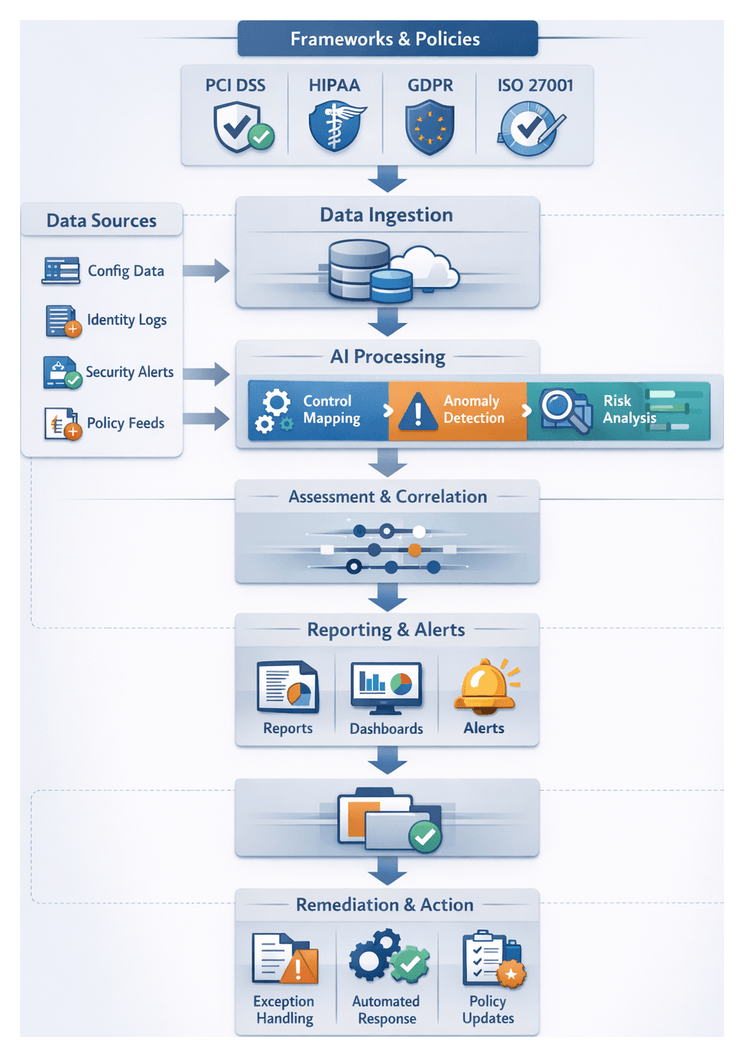
Regulatory Control Mapping and Evidence Collection Requirements
At the core of an audit-ready compliance program is a comprehensive framework that maps organizational processes and technical configurations to applicable regulations and standards. Whether aligning with PCI DSS, HIPAA, GDPR, SOX, NIST SP 800-53 or ISO 27001, security and compliance teams must translate each requirement into measurable control objectives—such as encryption at rest, privileged access reviews and change management validation—and bind these to evidence collection tasks. This mapping clarifies accountability for systems, data stores and operational processes, and ensures roles are assigned for configuring controls, capturing evidence and remediating deviations.
- Identification of Applicable Frameworks: Determine regulations and standards relevant to your industry, data processing activities and geographic footprint.
- Control Objective Definition: Specify desired security outcomes in measurable terms, for example “all cardholder data shall use AES-256 encryption in transit and at rest.”
- System and Process Alignment: Map each objective to applications, databases, network devices and operational workflows.
- Responsibility Assignment: Assign owners for control implementation, evidence capture and exception handling.
Quality evidence consists of configuration snapshots, audit logs, change tickets, vulnerability scan reports and key inventories that together demonstrate control efficacy. To satisfy auditors and regulators, evidence must be tamper-resistant, timestamped and contextually enriched. Key requirements include:
- Data Integrity Assurance: Use cryptographic hashing or timestamped journaling to prevent unauthorized modification of logs and artifacts.
- Chain of Custody Tracking: Record metadata on who collected or accessed each artifact, when and by which method.
- Retention and Archiving Policies: Define retention periods—such as the one-year log retention required by PCI DSS—and implement secure archival mechanisms.
- Evidence Accessibility: Ensure searchable, role-based access to evidence stores for audit and investigative needs.
Effective evidence collection depends on foundational prerequisites and environmental conditions. Organizations should maintain governance policy documentation, establish secure configuration baselines, synchronize system clocks and deploy centralized log management solutions such as Splunk or the Elastic Stack. Read-only API or agent-based access to CMDBs, version control systems and infrastructure-as-code repositories must be provisioned. Connectivity conditions include service accounts with scope-limited API credentials, lightweight collectors on endpoints, encrypted transport layers using TLS and high-availability ingestion points. Finally, normalization and validation processes—schema standardization, timestamp conversion to UTC, metadata enrichment, deduplication and automated validation checks—ensure data quality before any policy assessments occur.
- Schema Standardization: Adopt common formats (CEF or JSON ECS) to harmonize logs and events.
- Field Enrichment: Annotate events with asset owner, criticality, environment and geographic region.
- Error Handling: Monitor ingestion failures and anomalies to trigger alerts for prompt remediation.
Security and privacy safeguards around evidence repositories preserve confidentiality, integrity and availability. Evidence stores and backups should be encrypted at rest, with key management services controlling access. Role-based and attribute-based policies limit viewing rights, while audit logging records every access, modification or deletion. Automated redaction removes unnecessary PII, and retention and disposal controls enforce legal hold requirements.
- Encryption at Rest: Apply strong cryptographic algorithms to evidence storage systems.
- Access Control Policies: Restrict evidence access to authorized roles only.
- Audit Logging for Evidence Access: Maintain an immutable trail of evidence interactions.
- Data Masking and Redaction: Redact PII unless explicitly required for compliance.
- Retention and Disposal Controls: Automate purging or archiving per schedule, preserving legal holds.
Automated Compliance Management Workflows
Transforming raw telemetry, configuration data and access logs into audit-ready evidence requires an orchestrated workflow of agents, assessment engines and reporting systems. Automated, AI-driven workflows provide real-time visibility into control status, accelerate policy assessments and generate standardized documentation that closes the gap between operational security posture and governance obligations.
Data Inputs and Trigger Points
The workflow ingests data from configuration snapshots, identity and access logs, security telemetry and external policy feeds whenever triggered by system changes, privilege modifications or regulatory updates:
- Configuration Snapshots: Periodic exports from cloud platforms, network appliances and endpoint agents against baselines.
- Access and Identity Logs: Authentication records, directory changes and entitlement modifications for privileged accounts.
- Security Telemetry: Alerts and anomaly reports from SIEM or continuous monitoring solutions.
- External Policy Feeds: Regulatory updates and standards catalogs from authorities such as ISO and the PCI Council.
Automated Assessment and Monitoring
AI-driven rule engines and machine learning models evaluate control compliance against policies:
- Rule-Based Evaluation: Static checks flag violations such as disabled encryption or missing multi-factor authentication.
- Behavioral Analytics: Models detect policy drift by comparing current activity patterns to historical baselines.
- Continuous Scanning: On-demand scans after deployments ensure controls remain enforced.
- Dynamic Policy Adjustment: Workflows update assessment criteria in response to new threat intelligence.
Evidence Aggregation and Reporting
Assessment outputs are organized into evidence sets and merged with narrative templates aligned to frameworks like GDPR, HIPAA and SOC 2:
- Evidence Packaging: Group raw outputs—logs, snapshots and exception descriptions—by control family.
- Template Population: Populate regulatory report templates with evidence and narrative sections.
- Automated Summaries: Generate executive overviews with trending deviations and critical failures.
- Version Control: Timestamp and version each report iteration for traceability.
Exception Handling and Alerting
Not all deviations pose unacceptable risk. Exception workflows validate, approve or remediate flagged issues:
- Exception Requests: Business-justified deviations submitted via ticketing systems with contextual explanations.
- Automated Validation: AI models assess requests against historical data and risk thresholds for approval recommendations.
- Escalation and Notifications: High-risk exceptions trigger alerts to compliance officers and senior management.
- Workflow Integration: Exception outcomes feed remediation pipelines or policy updates.
System and Team Coordination
A central integration orchestrator manages task scheduling and data handoffs, while service buses relay change events in real time. Collaboration tools assign and track remediation tasks. Quarterly governance boards review compliance metrics, driving continuous improvement. SLAs for assessment, reporting and exception resolution are monitored via performance dashboards.
- Integration Orchestrator: Coordinates agents, tracks execution status and enforces SLAs.
- Service Bus Connectivity: Relays source system events—HR directories, configuration repositories—to compliance agents.
- Feedback Loop: Remediation outcomes refine rules and models for future cycles.
- Continuous Improvement: SLA breaches and audit findings generate root cause analyses and model retraining.
- Modular Architecture: Deploy agents on-premises, in private clouds or at the edge for localized assessments and scalability.
AI-Driven Compliance Agents and Orchestration
Compliance agents and report generation engines form the operational core of an automated governance framework. Deployed as microservices or serverless functions, they automate data ingestion, classification, control mapping, anomaly detection and report assembly. A central orchestrator invokes agents based on policy updates, scheduled compliance cycles and anomaly triggers.
- Data Ingestion Agents connect to identity directories, CMDBs, SIEM platforms and cloud providers to retrieve raw evidence via REST APIs, database queries, file transfer and message queues.
- Classification and Tagging Agents apply natural language processing models to parse policy texts, control descriptions and logs, extracting entities and tagging artifacts.
- Control Mapping Agents use rule engines and machine learning classifiers to associate evidence with regulatory requirements, leveraging a knowledge graph or ontology of standards.
- Anomaly Detection Agents monitor evidence streams with time-series forecasting, clustering or autoencoder models to flag irregularities indicating noncompliance.
- Report Assembly Agents integrate validated evidence into templates, generating PDF, HTML or spreadsheet deliverables for auditors and stakeholders.
Key AI capabilities and supporting systems include:
- Natural Language Processing for named entity recognition, topic classification and semantic linking between policy text and evidence.
- Machine Learning Classification to categorize evidence, cluster events and predict potential compliance breaches using supervised and unsupervised algorithms.
- Knowledge Graphs and Ontologies to encode relationships among regulations, controls, systems and risks.
- Robotic Process Automation bots to automate interactions with legacy systems lacking modern APIs.
- Report Generation Engines that assemble narratives, charts and metrics using template-driven frameworks consistent with corporate standards.
Agents integrate with leading GRC platforms such as ServiceNow GRC, OneTrust, MetricStream and RSA Archer. They register as connectors or plugins, inherit authentication policies and leverage the platform data model for control libraries and risk taxonomies. Deliverables are published to GRC dashboards, emailed to stakeholders or exposed via APIs.
Workflow orchestration relies on tools such as AWS Step Functions, Azure Logic Apps or Apache Airflow to define triggers and handoffs:
- Policy Update Trigger: Invokes control mapping to update knowledge graphs and evidence requirements.
- Scheduled Compliance Cycle: Retrieves snapshots and logs, then runs classification and anomaly detection.
- Exception Alert Trigger: Generates exception reports on deviations and documents findings.
- Audit Preparation Workflow: Compiles evidence bundles, enriches narratives and delivers packages for auditor review.
Scalable architectures leverage container orchestration (Kubernetes) and serverless compute to elastically adjust agent instances. Message queues and persistent buffers decouple components, while retry and dead-letter mechanisms manage transient failures. Governance policies dictate human review for low-confidence results or new controls, feeding corrections back into model retraining loops.
Audit-Ready Reporting and Remediation Recommendations
The culmination of compliance automation is a suite of formal deliverables that document control effectiveness, highlight noncompliance and recommend remediation. These outputs provide auditors, executives and risk teams with clear, defensible artifacts and guide remediation owners through prioritized action plans.
- Evidence Package: A structured collection of configuration snapshots, logs, change records and key inventories, indexed for rapid retrieval.
- Control Status Matrix: A tabular mapping of controls to compliance status, assessment methods, timestamps and responsible owners.
- Executive Summary: A high-level narrative of compliance posture, key findings and risk trends.
- Operational Dashboards: Interactive visualizations in tools like Tableau or Power BI, with drill-down capabilities and real-time KPI updates.
- Exception and Findings Log: Detailed entries of noncompliance instances with severity ratings, root cause analysis and evidence links.
- Policy Deviation Metrics: Quantitative measures of deviation frequency, time to detection and resolution timelines by control category and business unit.
Remediation recommendations transform findings into actionable guidance:
- Gap Analysis Narrative: Root cause explanations tying failures to missing configurations, outdated software or insufficient access restrictions.
- Action Plan and Prioritization: Ranked remediation tasks with responsible teams, estimated effort and target completion dates.
- Remediation Playbook Links: References to automated or manual playbooks in orchestration platforms, with step-by-step procedures and rollback guidelines.
- Policy Update Suggestions: Refined control thresholds, revised policy clauses and improved exception handling to reduce future false positives.
- Training and Awareness Briefs: Targeted materials on control objectives and best practices to support consistent remediation execution.
Deliverables are distributed via scheduled reports (PDF or spreadsheet), interactive dashboards, API endpoints (JSON or XML) and collaboration tool notifications with direct links to archives and playbooks. Dependencies on upstream processes—evidence aggregation, policy definitions, data normalization, identity and asset inventories and real-time vulnerability feeds from tools like Nessus, Qualys and Rapid7—must be validated to ensure report integrity. Handoffs trigger ticket creation in ITSM systems such as ServiceNow, case initialization for incident investigations, API callbacks for remediation automation and event publications on enterprise buses like Kafka or RabbitMQ. Role-based access controls, encryption of output files and tamper-evident audit logging protect report content. Versioned repositories track changes over time.
- Maintain standardized report templates aligned to frameworks (PCI DSS, GDPR, ISO 27001) and update them as standards evolve.
- Automate scheduling to align with audit cycles and provide on-demand generation.
- Enable modular report architecture for flexible service expansions.
- Conduct validation exercises by comparing automated reports to manual audits for tool accuracy.
By delivering structured, validated and actionable compliance reports alongside prioritized remediation guidance and seamless handoffs to remediation and investigation teams, organizations achieve continuous improvement in security posture and preserve a complete, defensible audit trail aligned with regulatory expectations.
Chapter 8: Incident Investigation and Case Management
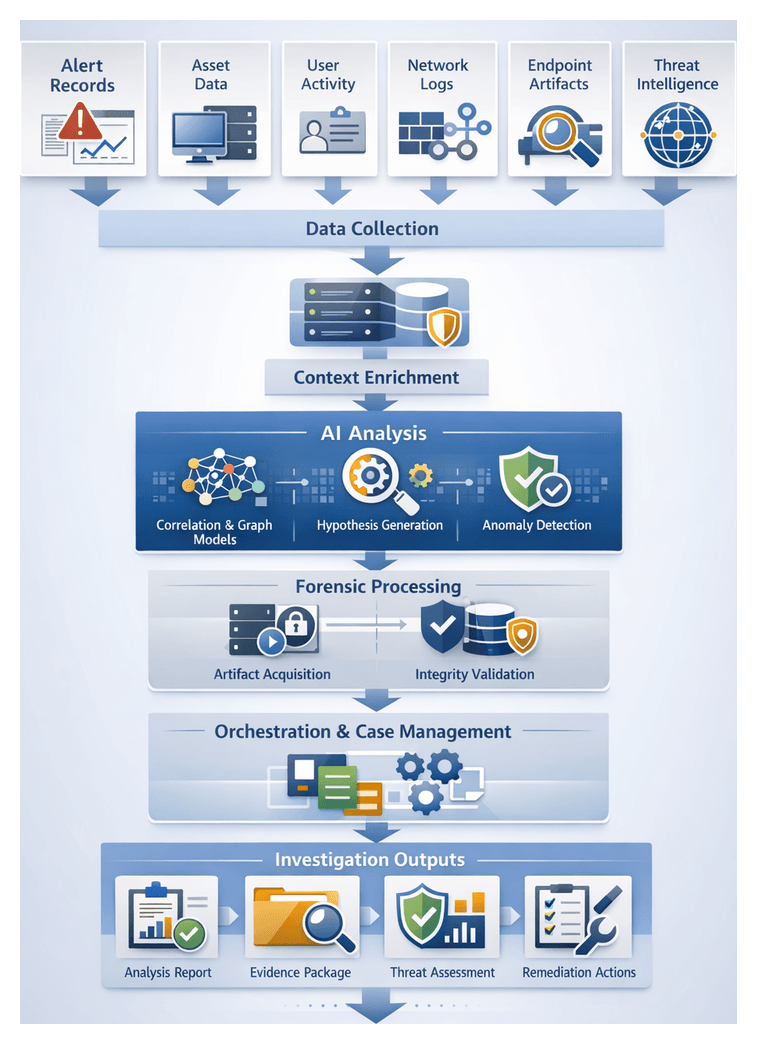
Escalated Alert Context and Forensic Data Inputs
When an alert exceeds defined severity or complexity thresholds, it triggers the structured incident investigation process. This stage formalizes context enrichment and forensic data collection to provide analysts with a complete evidence base and preserve compliance. By augmenting raw alerts with metadata—asset ownership, criticality, user activity—and gathering artifacts from endpoints, networks, cloud platforms, and identity systems, security teams ensure consistency, accelerate evidence assembly, and maintain chain-of-custody controls.
Key inputs include:
- Alert Records: Timestamps, detection rules, severity scores, and confidence metrics exported from SIEMs or EDRs such as Splunk, IBM QRadar and CrowdStrike Falcon.
- Asset Inventory: Hostnames, IP addresses, operating systems, ownership and business impact ratings.
- User Context: Authentication logs from providers like Active Directory, Okta or Azure AD capturing login times, geolocations and privilege changes.
- Network Telemetry: Packet captures, flow records (NetFlow, IPFIX) and firewall logs.
- Endpoint Artifacts: Memory snapshots, disk images and process listings collected via tools such as Volatility Framework or FTK Imager.
- Cloud Logs: AWS CloudTrail, Azure Activity Logs and Google Cloud Audit Logs.
- Threat Intelligence Correlations: IOC feeds and reputation data from Recorded Future or ThreatConnect.
- Configuration Baselines: Policy definitions from CMDBs or infrastructure-as-code repositories.
Prerequisites include:
- Bi-directional integrations with detection and orchestration platforms.
- Retention policies and write-once storage supporting tamper-evident logging.
- Documented chain-of-custody procedures with cryptographic hashing.
- Appropriate access permissions and operational forensic agents on targets.
- Time synchronization via NTP and vendor-neutral schemas (OpenIOC, STIX 2.0).
The workflow proceeds through:
- Alert intake, schema validation and initial severity tagging.
- Automated context lookup for assets, users, vulnerabilities and threat matches.
- Conditional forensic data requests and secure artifact acquisition.
- Integrity verification, completeness checks and tamper-evident storage.
- Delivery of an initial analysis brief combining enriched context and artifact inventory.
Handoff occurs once:
- All core artifacts are collected and integrity-verified.
- The enriched alert record is available with threat intelligence links.
- Chain-of-custody logs are complete.
- A unique case identifier is assigned and shared via systems like IBM Resilient or ServiceNow Security Operations.
Investigation Orchestration and Case Tracking Flow
This stage bridges automated detection and human analysis, coordinating actions across SIEM, SOAR, forensic tools and collaboration platforms to ensure consistency, auditability and SLA compliance. The orchestration engine transforms escalated alerts into structured cases, assigns tasks, enriches evidence and tracks progress until closure.
Workflow trigger and case initialization:
- High-confidence alerts that meet escalation criteria are forwarded into platforms such as Splunk Phantom or Cortex XSOAR.
- Alert contexts are enriched with threat actor profiles, IOC matches and business impact metrics.
- A unique case identifier is created and synchronized across SOAR, forensic systems and collaboration channels.
Task assignment and role coordination:
- Playbook-driven routing assigns tier 1 analysts, threat hunters, forensics specialists or legal advisors based on an organizational matrix.
- Notifications via ServiceNow, Microsoft Teams or Slack include links to dashboards and data sources.
- SLA timers and approval gates maintain accountability and send reminders on threshold breaches.
Cross-system data retrieval and enrichment:
- Automated evidence collection via API calls to EDR platforms and cloud security tools.
- Threat intelligence correlation using machine learning similarity models to surface related events.
- Contextual tagging by AI-driven services to annotate artifacts with malware families, vulnerabilities and behavior anomalies.
Dynamic playbook execution:
- Conditional branching directs investigators to sub-playbooks (for example, quarantining assets or escalating forensic analysis).
- Parallel tasks reduce time to resolution, with dependencies managed to prioritize critical activities.
- Manual intervention gates require analyst review and justification, all logged for audit.
Collaboration and knowledge sharing:
- A shared investigation timeline consolidates actions, milestones and comments in the case management dashboard.
- Automated briefings summarizing risk levels and impact matrices are distributed at key progress points.
- Resolved cases and methodologies are indexed in knowledge bases for rapid retrieval of similar scenarios.
Audit logging and SLA monitoring:
- Immutable action logs record every API call, playbook step and analyst decision with timestamps and identities.
- SLA dashboards track task durations and case age, triggering escalations on deadline breaches.
- Standardized reports on resolution metrics and lessons learned feed continuous improvement.
Case closure and handoff:
- Automated validation ensures artifacts are archived, compliance checklists completed and follow-up actions scheduled.
- Closure notifications with summaries are sent to incident response teams, legal counsel and business units.
- Post-incident reviews are scheduled, with AI agents analyzing metrics to recommend process or detection rule updates.
Enrichment Models and Hypothesis Generation
Enrichment models and hypothesis generation agents form the cognitive layer of incident investigations, transforming raw alerts into actionable insights. By ingesting data from endpoint logs, network flows, directory records, vulnerability scans and external threat intelligence, these AI components normalize and extract features before analysis.
Graph analytics and contextual linking:
- Graph engines like Neo4j or Linkurious construct relationships among hosts, user accounts and process activities.
- Entity resolution models consolidate identities across systems to reduce false positives.
- Temporal correlation aligns events across drifting clocks to produce coherent timelines.
- Semantic tagging algorithms classify artifacts—malicious URLs, ransomware signatures or command-line parameters—using NLP techniques.
Machine learning classifiers, such as IBM QRadar Advisor with Watson, score anomalies based on known attack patterns to prioritize high-risk alerts. Continuous feedback from analysts on confirmed threats and false positives feeds retraining pipelines, ensuring models evolve with adversary tactics.
Hypothesis generation agents apply probabilistic reasoning, NLP and graph traversal to propose and rank attack scenarios. Bayesian networks and MITRE ATT&CK mappings guide these agents, as exemplified by integrations with Recorded Future and Palantir Gotham. NLP agents parse incident reports and chat logs for contextual cues, recommending investigative actions such as registry queries or file server scans.
These AI modules are orchestrated through platforms like Cortex XSOAR, with RESTful APIs enabling lightweight integration. Event streaming via Apache Kafka or Amazon Kinesis ensures low-latency data delivery, while container orchestration systems like Kubernetes scale capacity to match investigation workloads.
Within the workflow, AI components assume defined roles:
- Data Normalization Agents: Standardize formats and validate schemas.
- Entity Resolution Models: Unify identity fragments into consolidated profiles.
- Graph Construction Engines: Build relationship graphs for analysis.
- Contextual Enrichment Models: Annotate alerts with risk scores and threat actor tags.
- Hypothesis Generation Agents: Propose attack scenarios and assign confidence levels.
- Feedback Integration Modules: Capture analyst decisions for model retraining.
Ensuring transparency and trust in AI systems requires explainability features—confidence intervals, decision tree rationales and model drift detection—as provided by tools like IBM Watson OpenScale. Governance frameworks enforce version control, validation and cross-functional approvals to minimize automation errors and support continuous improvement.
Investigative Deliverables and Documentation Outputs
Formal deliverables translate investigation findings into executive summaries, evidence packages, validated analyses and remediation roadmaps. Standardized outputs ensure compliance with GDPR, HIPAA, PCI DSS and other frameworks, support legal defensibility and guide operational teams in risk reduction.
Incident report summaries:
- Components: Incident overview, scope and impact, root cause hypothesis, detection efficacy and resolution summary.
- Formats: PDF or HTML templates integrated with BI platforms such as Microsoft Power BI and distributed via ServiceNow Security Operations.
- Dependencies: Enriched alerts from Splunk, case timelines and analyst sign-off.
Evidence package compilation:
- Contents: Log extracts in OpenIOC or STIX/TAXII, memory dumps, disk images, PCAP files and configuration snapshots.
- Standards: Digital signatures, hash verification, AES-256 encrypted archives and indexed metadata pointers.
- Dependencies: Forensic artifacts collected during orchestration and secure evidence vaults (e.g., AWS S3 with FIPS-compliant encryption).
Analytical findings and root cause documentation:
- Artifacts: Event correlation graphs, hypothesis testing results, behavioral deviation reports from tools like Microsoft Sentinel and statistical model summaries.
- Formats: Rich text or Markdown summaries in case management tools such as JIRA or ServiceNow, with linked visuals in BI dashboards.
- Dependencies: Access to ML model repositories, graph databases and analyst review cycles.
Recommendations and next-step roadmaps:
- Actionable items: Patching schedules, configuration updates, policy revisions and training initiatives.
- Roadmap structures: Gantt charts via project management integrations and auto-generated tickets in ServiceNow or JIRA.
- Dependencies: CMDB asset data, change management workflows and budget constraints.
Collaboration and handoff protocols:
- Automated ticket creation with report summaries and evidence links.
- Role-based notifications to incident owners, legal and compliance stakeholders.
- Secure document sharing via identity governance platforms and SLA enforcement in orchestration dashboards.
- Platforms: Cortex XSOAR and case management systems with audit trails and version control.
By delivering clear, standardized documentation and leveraging automated handoffs, organizations close the loop between investigation and remediation, ensuring that insights drive continuous security improvement.
Chapter 9: Automated Incident Response and Remediation Orchestration
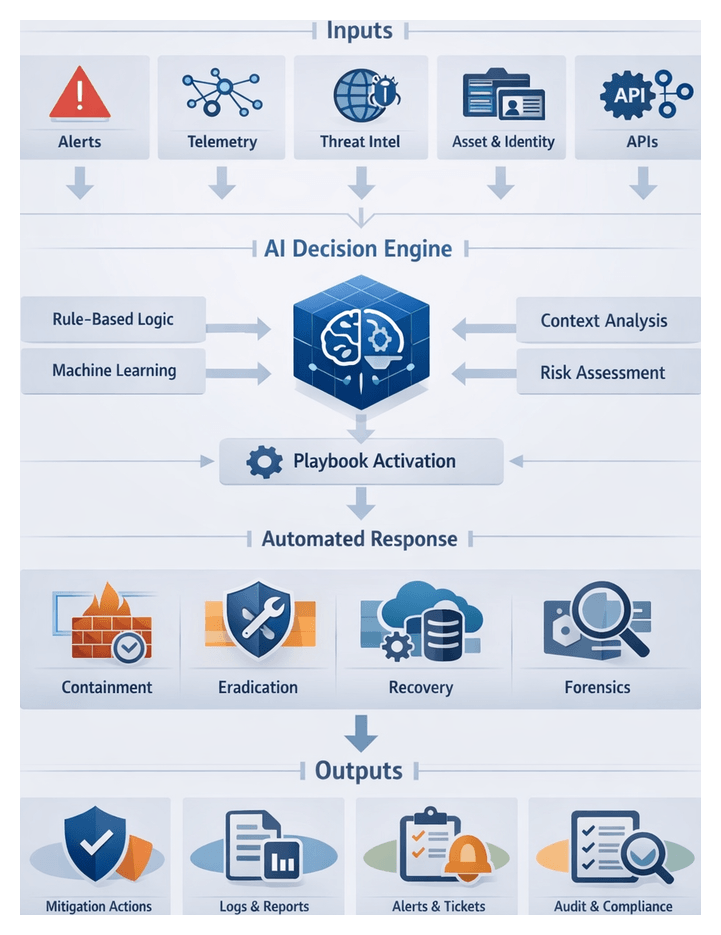
Response Playbook Triggers and Context Inputs
Automated incident response begins with well-defined trigger criteria and comprehensive system context. This stage evaluates incoming alerts against severity metrics, classification tags, temporal thresholds, asset attributes, endpoint and network posture, and external threat intelligence. A decision engine—using rule-based logic or machine learning inference—determines if an event merits activation of a response playbook, balancing speed with accuracy to minimize false positives and operational risks.
To function reliably, the system requires:
- Version-controlled playbook definitions stored in a centralized repository
- Continuous telemetry ingestion from EDR, SIEM, network sensors, and cloud controls
- Service account credentials and scoped API keys for secure access
- High-availability orchestration engines with SLA-backed failover
- Schema validation, data integrity checks, and timestamp synchronization
- Change control processes for configuration and policy updates
Integrations gather trigger inputs and context via:
- RESTful or gRPC APIs to EDR, SIEM, asset management, and threat feeds
- Message queues and event buses (Apache Kafka, Amazon EventBridge, RabbitMQ)
- Webhooks for push notifications from detection services
- Database connectors (JDBC) to CMDBs and vulnerability scanners
- Secure file transfers (SFTP, S3) for batch log ingestion
- LDAP or SCIM connectors for identity and group context
Decision logic leverages contextual data—such as user identity and role, asset criticality, network topology, endpoint health, operational hours, geolocation constraints, and threat intelligence enrichment—to apply granular policies. Environmental preconditions ensure policy conformance, enable audit logging, enforce data retention schedules, protect privacy through encryption, and require manual approval workflows for high-risk actions.
Containment and Eradication Orchestration
Scope Definition and Impact Analysis
Before executing automated actions, the orchestration engine refines incident context to determine affected assets, user accounts, and potential collateral impact. Workflows query SIEM for related events, cross-reference host identifiers with business criticality, assess network segmentation, retrieve user session metadata, and generate an impact assessment report. This precise scope analysis informs containment strategy and decision thresholds for automation versus manual intervention.
Automated Containment Actions
- Network isolation: Quarantine segments or block IPs via firewall APIs (for example Palo Alto Networks NGFW or Cisco Secure Firewall).
- Endpoint isolation: Use integrations such as CrowdStrike Falcon or Microsoft Defender for Endpoint to move hosts into remediation groups.
- Account suspension: Disable or reauthenticate user accounts via identity platforms like Okta or Azure AD.
- Privilege revocation: Revoke elevated permissions for service or administrative accounts.
- Cloud lockdown: Restrict access to compromised instances via AWS Security Hub or Google Cloud Chronicle APIs.
Eradication Procedures
- Process termination and binary removal: EDR agents kill malicious processes and delete binaries.
- Registry and configuration cleanup: Automation frameworks such as Ansible or PowerShell Remoting remove persistence artifacts.
- Vulnerability patching: Trigger patch management via Ivanti or Microsoft WSUS.
- Credential rotation: Rotate exposed secrets using HashiCorp Vault or CyberArk.
- Network route restoration: Reapply baseline configurations via configuration management tools.
- Forensic snapshot: Securely archive removed artifacts for analysis.
Coordination and Error Handling
Automated workflows integrate with service desks—such as ServiceNow or Jira Service Management—to create tickets, notify business units, escalate on timeouts, update incident records, and drive collaboration through chat or war rooms. Dashboards provide real-time visibility of containment and eradication progress.
Error management includes validating API responses, designing idempotent playbooks, implementing retry logic with thresholds, fail-safe rollbacks to known good states, and centralized error logging for root-cause analysis.
Verification and Handoff to Recovery
- Rescan endpoints for indicators of compromise.
- Validate network segmentation integrity.
- Confirm credential rotations and access reviews.
- Execute post-remediation vulnerability scans.
- Generate handoff tickets to transition into the recovery stage.
This disciplined sequence ensures threats are neutralized and assets are ready for restoration workflows, maintaining audit trails at every step.
Automated Response Agents and Integration APIs
Roles of AI Response Agents
- Incident Orchestration Agent: Coordinates playbook execution, monitors progress, retries failures.
- Containment Agent: Executes isolation measures at network, endpoint, and identity layers.
- Eradication Agent: Removes malicious code, cleans configurations, triggers deep scans.
- Recovery Agent: Rebuilds or patches systems via configuration management and cloud orchestration.
- Forensic Data Retrieval Agent: Collects logs, memory dumps, and snapshots for analysis.
- Notification and Collaboration Agent: Updates tickets and notifies stakeholders through chat and email.
Integration API Patterns
Agents interact with security and IT controls via:
- RESTful HTTP APIs: CRUD operations for hosts, rules, and sessions (for example CrowdStrike Falcon).
- GraphQL and RPC interfaces: Precise data retrieval from cloud and microservices.
- Message queues and event buses: Decoupled task exchanges using Apache Kafka, Amazon EventBridge, RabbitMQ.
- Native SDKs and CLIs: Local execution when APIs are limited.
- Infrastructure as Code APIs: Environment provisioning and rollback via AWS CloudFormation, Terraform.
Core Integration Best Practices
- Idempotent Actions: Ensure safe retries without side effects.
- Secure Authentication: Use least-privilege service accounts, rotate tokens.
- Observable Execution: Log all API calls and agent events to a centralized monitor.
- Bulk vs Granular Operations: Balance performance and blast radius.
- Fallback and Rollback: Implement alternate workflows or revert changes on failures.
Agent-API Interaction Examples
- Endpoint Containment: Containment agent uses the CrowdStrike Falcon API to isolate compromised hosts and verify status.
- Firewall Automation: Orchestration pushes dynamic blocklist entries via Palo Alto Networks Cortex XSOAR to firewalls.
- Ticketing Integration: Notification agent creates and updates incidents in ServiceNow.
- System Rebuild: Recovery agent triggers an AWS Lambda function to launch an Amazon EC2 instance and applies Ansible playbooks.
- Forensic Collection: Data retrieval agent pulls memory images via secure EDR transfer APIs and records checksums.
Security, Scalability, and Governance
- Standardize data models and schemas for incident context and artefacts.
- Version-control playbooks and integration code with staged testing.
- Use circuit breakers to throttle automation under high error rates.
- Validate and sanitize all inputs to APIs to prevent misconfiguration.
- Employ feature flags for controlled rollouts of new agents or integrations.
- Continuously monitor API health, response times, and error codes.
- Secure integrations with multifactor authentication, mutual TLS, just-in-time credentials, and encrypted vaults. Conduct periodic penetration tests and code reviews.
- Containerize agents for horizontal scaling in Kubernetes or serverless environments. Decouple orchestration via message queues and implement retry with exponential backoff.
Remediation Logs and Recovery Confirmation
Structured Output Artefacts
- Action Logs: Timestamped records of each API call or command, including parameters, status, and error codes.
- Recovery Confirmation Reports: Health checks validating service availability, patch levels, and malware scan results.
- Compliance Verification: Evidence of policy and regulatory conformance, audit-log snapshots, and configuration drift assessments.
- Audit Trail Artefacts: Immutable records linking actions to agent credentials and workflow identifiers.
- Metrics and Indicators: Mean time to contain and recover, automated versus manual actions, playbook success rates.
Dependencies and Data Lineage
- Orchestration engine context and workflow run IDs anchor action logs.
- Telemetry from endpoints, firewalls, cloud APIs, and containers feeds recovery confirmation.
- Baseline configurations from the CMDB validate post-remediation settings.
- Original threat intelligence informs severity and escalation criteria.
- SLAs and playbook specifications dictate timing for confirmation checks and escalations.
Handoff Mechanisms
- APIs and Webhooks: Publish artefacts to ticketing and GRC platforms.
- Message Queues and Streams: Forward logs via Apache Kafka or AWS Kinesis to SIEM and analytics engines.
- Database Writes: Ingest structured data into enterprise warehouses for reporting.
- Email and Collaboration: Notify via Slack or Microsoft Teams with executive summaries.
- Ticket Closure: Automatically update or close incident tickets once confirmations pass.
Validation and Quality Assurance
- Schema validation to ensure completeness and data type conformity.
- Cross-reference orchestration logs with telemetry for execution reconciliation.
- Active health probes for service responsiveness and security posture.
- Sequence integrity checks to detect timestamp anomalies.
- Permission audits confirming authorised agents generated artefacts.
Stakeholder Responsibilities and Continuous Feedback
- SOC Analysts: Review logs for anomalies, initiate manual reviews as needed.
- IT Service Management: Validate recovery reports and reconcile tickets.
- Compliance Teams: Ingest verification results into GRC platforms.
- Incident Review Board: Analyze metrics to refine playbooks and SLAs.
- Crisis Communications: Use executive summaries for stakeholder updates.
- Identify recurring failures to update decision logic and playbooks.
- Recalibrate risk thresholds based on recovery metrics and latency.
- Adjust automation confidence models to expand or limit autonomous actions.
- Update compliance checks to reflect evolving regulatory requirements.
Through structured artefacts, rigorous validation, clear handoffs, and continuous feedback loops, the incident response framework achieves rapid, auditable remediation and drives ongoing improvement of security posture.
Chapter 10: Continuous Feedback and Strategic Improvement
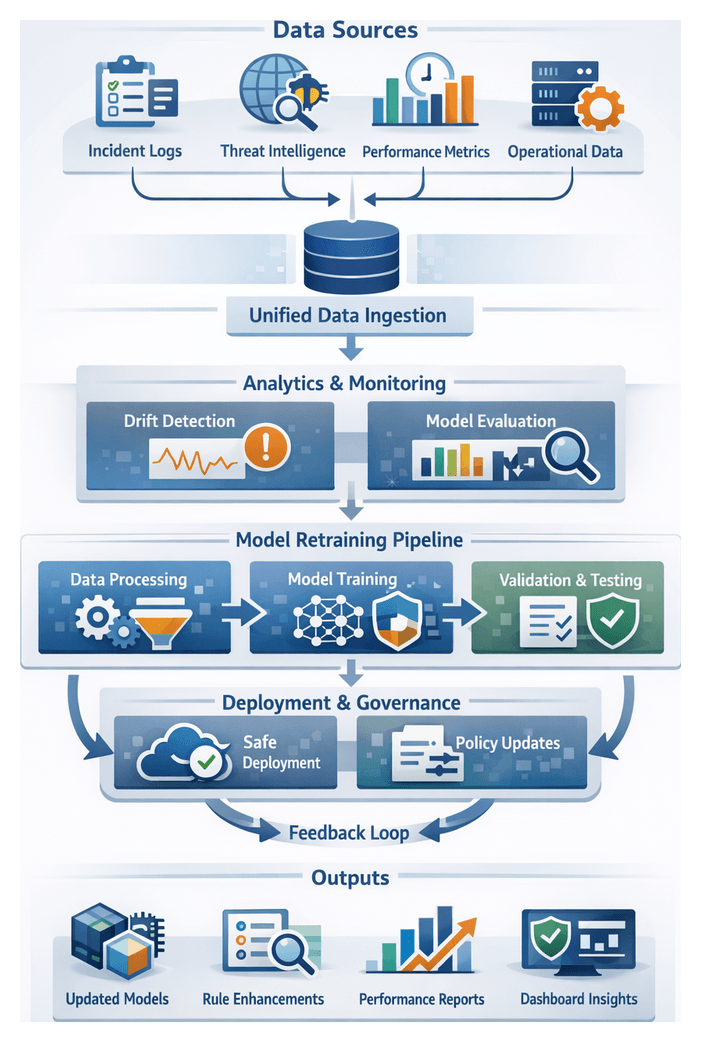
The continuous feedback and strategic improvement stage closes the loop on AI-driven security operations by systematically capturing performance metrics, incident outcomes and threat intelligence to recalibrate detection models, refine response playbooks and update policy controls. It aligns with DevSecOps and MLOps principles, applying iterative cycles of measurement, analysis and enhancement to ensure detection fidelity, reduce false positives and accelerate incident response. By embedding structured feedback mechanisms, organizations quantify gains, identify gaps and adapt security controls in step with evolving attacker tactics, regulatory requirements and business objectives.
Essential Data Inputs and Prerequisites
Effective continuous improvement requires an end-to-end view of security performance and threat evolution. Key inputs include:
- Incident Performance Indicators: Mean time to detect (MTTD), mean time to respond (MTTR), resolution rates and analyst workload statistics.
- Incident Records and Case Data: Structured logs from ServiceNow, Splunk Enterprise Security and Elastic SIEM.
- Threat Intelligence Updates: Indicators and advisories from Recorded Future, Anomali and open-source feeds.
- Model Performance Metrics: False positive rates, true positive rates and drift indicators tracked via MLflow or DataRobot.
- Operational Telemetry: Queue depths, response times and resource utilization from SOAR platforms.
Foundational prerequisites include a unified data repository, historical incident archive, continuous ETL pipelines, standardized taxonomies, secured API integrations and role-based governance controls to ensure data quality, privacy and compliance with frameworks such as ISO 27001, GDPR and CCPA.
Feedback Loop and Model Retraining Process
This process maintains model accuracy and relevance by orchestrating data collection, performance analysis, retraining workflows and governance gates across security operations, data science and compliance teams.
Data Collection and Drift Detection
Operational metrics, alert outcomes, investigation results and threat updates converge in a central feedback repository. Connector services ingest records from SIEM, ticketing and intelligence platforms, applying normalization routines and metadata tagging. An analytics engine evaluates models using confusion matrices, ROC curves, precision-recall scoring, time-series drift analysis and feature distribution monitoring. Drift alerts trigger review when metrics cross predefined thresholds.
Retraining Pipeline Orchestration
Upon drift detection, an orchestration layer launches a retraining pipeline that validates input data, constructs updated training and validation sets, applies synthetic augmentation, and executes containerized training jobs on scalable resources. Tools such as Kubeflow, MLflow and Apache Airflow coordinate dataset versioning, hyperparameter logging and parallel model evaluations.
Validation and Quality Gates
Candidate models undergo cross-validation against hold-out sets, stress testing with adversarial scenarios, latency and throughput benchmarks, security scans, and bias assessments. A policy engine enforces performance thresholds before promoting models to staging. Stakeholders receive notifications for approvals, captured with audit logs to document sign-off and rationale.
Deployment and Rollout Coordination
Approved models deploy via blue-green or canary strategies, routing a controlled percentage of inference traffic to the new version. Real-time monitoring compares detection rates and false positive volumes. Automated rollback triggers and slice-based analysis across asset segments ensure safe adoption. Configuration management tools update downstream consumers—SIEM and SOAR engines—with the new model endpoints.
Adaptive Learning Engines and Policy Refinement Agents
Adaptive learning engines and policy agents continuously tune detection models and security policies using supervised, unsupervised and reinforcement learning. They integrate telemetry, business context and performance signals to generate and deploy control updates under governance oversight.
Core engine architecture includes:
- Data Ingestion Layer: Aggregates logs, alerts and context into a scalable storage system.
- Feature Store: Normalizes feature definitions and tracks lineage.
- Training & Evaluation Engine: Hosts pipelines for classification, anomaly detection and reinforcement learning.
- Deployment Orchestrator: Automates version control, canary rollouts and rollback procedures.
- Feedback Collector: Captures runtime metrics, alert outcomes and user feedback.
Reinforcement Learning for Policy Tuning
RL agents adjust thresholds, firewall rules and access controls by interacting with simulated environments. Frameworks such as Ray RLlib and OpenAI Gym facilitate custom security scenarios, while managed services like AWS SageMaker and Azure Machine Learning provide scalable training clusters. Agents propose adjustments in monitoring mode before transitioning to automated enforcement under governance guards.
Integration with MLOps Pipelines
Drift detection modules trigger automated retraining via Kubeflow, MLflow and Airflow. Dataset versioning, automated testing suites and validation gates ensure that new models reflect the latest threat intelligence and operational feedback, minimizing manual intervention.
Policy Refinement Agent Roles
Policy agents leverage natural language processing from OpenAI GPT-4 to parse policy documents, draft amendments and draft change tickets. They simulate proposed rules in staging environments, generate approval requests and apply updates through CI/CD pipelines. Integration with GRC platforms such as ServiceNow GRC, OneTrust and RSA Archer ensures that changes map to risk assessments and compliance evidence.
Updated Models, Detection Rules and Process Improvement Reports
The outputs of continuous feedback include deployable model packages, enhanced rule sets, process improvement reports and governance dashboards. These artifacts enable controlled handoff to operations, engineering and compliance teams.
- Revised Model Packages: Serialized weights and metadata compatible with TensorFlow or PyTorch, benchmarks, training data snapshots and deployment scripts.
- Enhanced Detection Rule Sets: Versioned libraries of signatures, threshold configurations and context enrichment profiles with change logs and approval records.
- Process Improvement Reports: Visualizations of performance trends, false positive/negative analyses, workflow efficiency metrics and strategic recommendations.
- Governance Dashboards: Interactive KPI views, retraining timelines and compliance status indicators.
Quality assurance relies on data lineage verification, cross-validation, automated testing and multi-role peer reviews. Formalized handoff processes include:
Handoff Framework and Scheduling
- Publishing artifacts to version control with tagged releases and release notes.
- Generating change tickets in ServiceNow for deployment and validation tasks.
- Refreshing dashboards in analytics platforms such as Power BI or Tableau.
- Updating incident response playbooks to reflect new detection capabilities.
- Conducting training sessions to onboard analysts and engineers.
- Periodic Releases aligned with governance reviews.
- Threshold-Based Triggers for accelerated retraining after performance dips or major incidents.
- Ad Hoc Updates for urgent threat variants or strategic shifts.
Governance, Collaboration and Continuous Improvement
Strong governance enforces role-based access controls, audit trails, policy-as-code and GitOps practices. Stakeholder collaboration channels include weekly performance reviews, incident retrospectives, dedicated chat queues and strategy workshops. Feedback artifacts feed backlog management systems, driving feature engineering, algorithm upgrades, infrastructure optimizations and automation enhancements. The living roadmap balances effort, risk reduction potential and strategic alignment, ensuring the security posture evolves proactively with the threat landscape and business objectives.
Conclusion
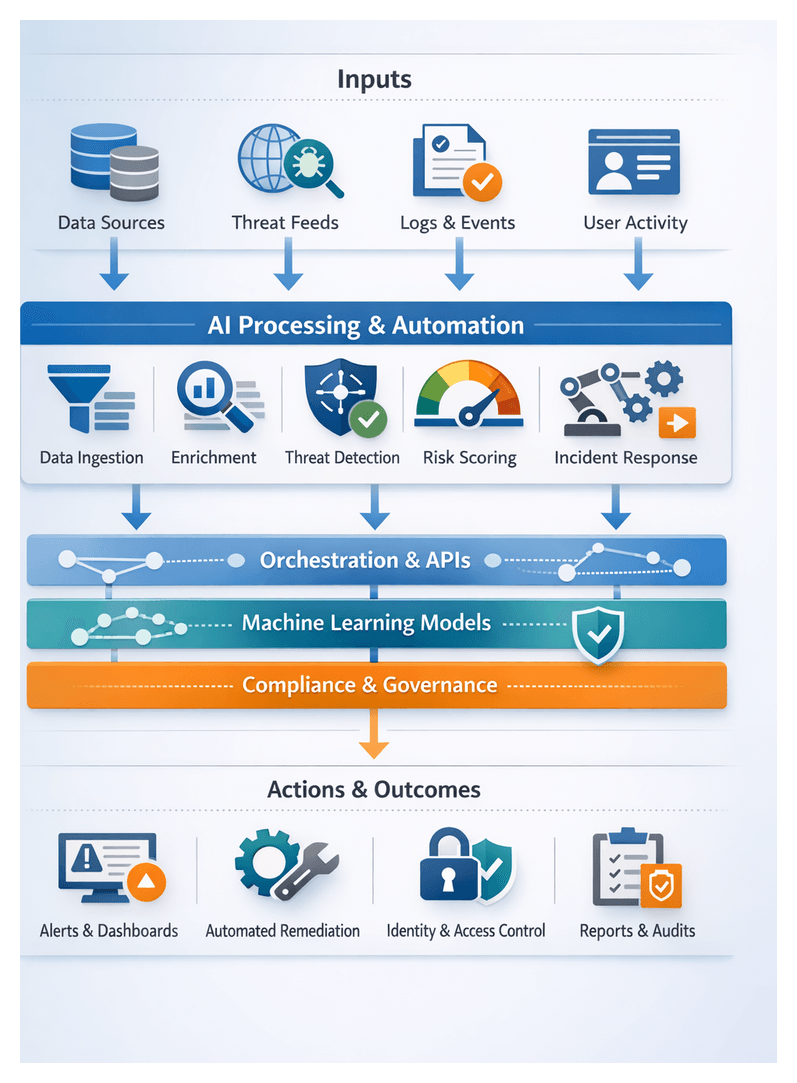
Unified AI-Driven Security and Risk Management Workflow
Purpose and Strategic Alignment
The primary objective of this end-to-end workflow summary is to provide a single reference for all stakeholders—security architects, engineers, compliance officers and executive leadership—to trace the flow of data through each AI-driven module. By articulating decision points, handoff mechanisms and dependencies, the framework transforms complex technical processes into an accessible narrative that aligns operational execution with organizational strategy. This unified view supports transparency, fosters accountability and ensures that the cumulative value of AI orchestration is visible at every level of the enterprise.
In environments where security functions are fragmented across multiple point solutions and data silos, a centralized meta-framework is indispensable. It bridges gaps between data collection, enrichment, detection, scoring, remediation, identity governance, compliance reporting, incident investigation and response orchestration. By codifying how each component interlocks, the workflow recap validates that upstream inputs feed downstream outputs without loss of context and that insights seamlessly transition into automated or human-driven actions.
Prerequisites and Conditions for Linkage Accuracy
To construct a reliable workflow map, organizations must assemble foundational elements and enforce conditions that reflect the live environment. These prerequisites and conditions guarantee that the recap is both accurate and actionable.
- Verified Data Schema Definitions: Establish standardized models for logs, metrics, threat indicators, risk scores and remediation tickets to maintain consistency across modules.
- Operational Status of All Modules: Confirm that data ingestion pipelines, enrichment engines, monitoring systems, risk scoring algorithms, remediation orchestrators, identity governance tools, compliance assessors, investigative platforms and response playbooks are deployed, configured and producing outputs per service-level commitments.
- Integration Metadata and API Contracts: Document API endpoints, message queues, file transfer protocols and connector configurations to map data handoffs precisely.
- Governance and Compliance Frameworks: Articulate organizational policies, regulatory requirements and control objectives to ensure that the workflow aligns with internal mandates and external standards.
- Performance and Reliability Metrics: Collect baseline measurements—ingestion latency, model inference times, alert throughput, remediation cycle durations and report generation schedules—to contextualize efficiency analyses.
- Stakeholder Roles and Responsibilities: Develop a RACI matrix identifying process owners, data stewards, AI model custodians and escalation contacts to clarify accountability.
- Stable Data Processing Flow: Schedule and document maintenance windows and outages to distinguish planned downtime from anomalies.
- Synchronized Timestamps: Normalize timekeeping across systems to enable accurate cross-module event correlation.
- Consistent Error Handling: Define error codes, retry policies and fallback procedures to reflect both successful and failed handoffs.
- Change Management Records: Capture modifications to connectors, model versions, policies and orchestration logic to trace the impact on data flows and outcomes.
- Access Controls and Audit Logs: Preserve permission records and access trails to confirm that data transitions occur under proper security contexts.
Deliverables and Enablers of Continuous Improvement
When prerequisites are in place and conditions satisfied, the workflow recap produces artifacts that drive strategic discussions, operational tuning and governance reviews. These deliverables form the basis for continuous improvement cycles and audit assurance.
- End-to-End Workflow Diagram: A visual map of modular stages, data pipelines, AI model interactions and decision points, annotated with inputs, outputs and service-level indicators.
- Dependency Matrix: A tabular view cataloging upstream sources, downstream consumers, data formats and integration protocols for each component.
- Performance Heatmap: A consolidated dashboard highlighting latency, throughput, error rates and resource utilization across modules.
- Audit Trail Summary: A report of change events, exception occurrences and access logs that validates control integrity and data lineage.
- Actionable Recommendations: Prioritized optimization opportunities, risk exposures and architectural refinements derived from cross-module analyses.
By comparing current performance against baseline metrics and compliance objectives, organizations identify AI model drift, processing bottlenecks and emerging policy gaps. These insights feed retraining pipelines, policy updates and architectural enhancements, closing the loop on the end-to-end workflow and ensuring that security operations evolve in step with changing threats and requirements.
Operational Efficiency and Measurable Risk Reduction
With the workflow recap completed, focus shifts to operational execution. Efficiency gains and risk reduction outcomes are realized through precise orchestration, streamlined data flows and integrated response coordination. This section examines how the pipeline’s backbone, module interactions and feedback mechanisms combine to accelerate detection, remediation and continuous enhancement.
Orchestration Backbone and Intermodule Coordination
A centralized orchestration layer governs event brokering, rule-based alert routing and playbook sequencing. Platforms such as ServiceNow Security Operations or open frameworks manage:
- Event distribution between data collectors and intelligence engines.
- RESTful API calls and secure messaging for intermodule communications.
- Sequencing of automated playbooks in tools like Palo Alto Cortex XSOAR.
- Propagation of incident outcomes into model retraining pipelines.
This approach reduces point-to-point integrations, enforces SLAs for each handoff and provides unified visibility into workflow health and performance.
Streamlined Data Flows Across Modules
Efficient operations begin with rapid ingestion and normalization. Key steps include:
- Tagging data with contextual metadata—asset criticality, geolocation, user identity—before enrichment.
- Correlating external threat feeds with internal telemetry via in-memory databases and distributed caching to minimize lookup delays.
- Applying machine learning models for risk scoring and behavioral analysis, then passing enriched events to monitoring services through secured endpoints.
- Generating alerts that include full contextual metadata to eliminate redundant data retrieval and accelerate investigation.
Centralized schema definitions and automated validation checks at each stage maintain data fidelity and deliver enriched alerts to analysts within seconds, supporting faster decision cycles.
Integrated Threat Prioritization and Routing
A composite scoring engine ingests detection alerts, known vulnerabilities and business impact metrics to assign a unified priority score. Workflow orchestration then handles routing:
- Delivery of detection alerts to the risk engine via a guaranteed delivery queue.
- Enrichment of alerts with severity tags and remediation guidance.
- Publication of high-priority items to a “hot queue” for automated containment.
- Batching of lower-priority events for review in dashboards powered by Splunk Enterprise Security.
Embedding prioritization logic ensures that critical threats trigger immediate action, while nonurgent notifications are consolidated to reduce analyst workload and drive up to a 60 percent reduction in response times.
Automated Response Coordination
High-confidence incidents trigger coordinated containment and eradication across multiple controls:
- Validation of incident context and system health to prevent false positives.
- Endpoint isolation via CrowdStrike Falcon API calls.
- Network quarantine through firewall orchestration connectors.
- Cloud workload lockdown using AWS Security Hub or Microsoft Defender for Cloud.
- Automated ticket creation in IT service management systems, capturing audit logs.
Parallel execution of isolation and blocking actions reduces mean time to containment by as much as 75 percent while preserving an unbroken chain of custody for compliance purposes.
Continuous Feedback Loop and Model Refinement
Incident outcome data—containment success, resolution time, false-positive rates—flows into a central metrics repository. MLOps pipelines access this data to detect model drift and schedule automated retraining jobs. Updated model artifacts are validated in staging environments before being promoted via the orchestration layer. This feedback loop sustains detection accuracy and reduces false positives by up to 40 percent over successive iterations.
Cross-System Collaboration and Role Orchestration
Workflow platforms assign tasks based on role, expertise and workload:
- Junior analysts receive guided triage tasks with AI-driven context cards.
- Senior investigators leverage graph analytics and hypothesis-generation agents.
- IT administrators are notified of remediation playbooks requiring approvals, with embedded change windows.
- Executive stakeholders access dashboards summarizing performance metrics and residual risk.
This role-based orchestration ensures that each actor engages at the right time with precise information, minimizing handoff friction and accelerating resolution cycles.
Case Management and Audit-Ready Documentation
High-severity incidents are recorded in centralized case management platforms such as IBM QRadar or ServiceNow Security Operations. The process includes:
- Automatic population of case fields with enriched alert metadata and forensic artifacts.
- Assignment of investigation tasks with due dates, priority levels and notifications.
- Attachment of remediation logs and compliance evidence from automated response.
- Case closure only after verification of recovery steps and business owner sign-off.
Embedded documentation at every step eliminates late-stage reporting and cuts audit preparation time by over 50 percent.
Quantitative Risk and Efficiency Metrics
- Mean time to detect (MTTD) reduced by 70–80 percent compared to manual processes.
- Mean time to respond (MTTR) reduced by up to 75 percent through automated playbooks.
- False-positive rates decline via continuous enrichment and model refinement.
- Overall risk exposure decreases as the orchestration pipeline reinforces each stage.
These metrics empower security leaders to demonstrate return on investment by correlating operational improvements with risk appetite and business outcomes.
Business Impact and Compliance Assurance
By unifying security operations into an AI-driven pipeline, organizations protect revenue, reputation and regulatory standing while unlocking strategic value from their security investments. The orchestration of data collection, threat intelligence, monitoring, scoring, response and continuous learning drives measurable business outcomes and compliance assurance.
Revenue Protection and Brand Integrity
Security incidents incur direct financial costs—breach remediation, fines, litigation—and intangible losses in customer trust. AI workflows mitigate these risks by detecting anomalies with unsupervised clustering of network telemetry and AI-based log parsing for privilege escalations. Rapid containment measures prevent data exfiltration and service disruptions, minimizing the dwell time of attackers. Quantifiable metrics such as reduced MTTD and MTTR reinforce confidence among customers, partners and auditors, preserving revenue streams and brand equity.
Operational Efficiency and Cost Optimization
Shifting from manual triage and remediation to automated workflows reduces resource-intensive tasks. Natural language processing applied to alerts enriches context and automates prioritization, cutting false positives by up to 80 percent. Orchestration platforms coordinate tool actions—firewall updates, endpoint isolation, patch deployment—without manual intervention, capturing best practices in codified playbooks. These efficiencies translate into a 30–50 percent reduction in operational overhead, lower ticket volumes and extended hardware lifespans through predictive maintenance.
Regulatory Compliance and Audit Readiness
Compliance frameworks such as GDPR, HIPAA, PCI DSS and SOX require continuous controls and evidentiary tracking. AI-driven policy monitoring engines evaluate configurations and user activities, triggering automated remediation or governance alerts when deviations occur. Immutable logs of policy checks, exception approvals and remediation actions populate an audit-ready trail. On-demand compliance reports and real-time dashboards transform periodic audits into continuous assurance, reducing audit preparation costs by up to 60 percent and accelerating audit cycles.
Governance, Analytics and Data-Driven Decision Making
Rich datasets of threat indicators, risk scores, incident outcomes and compliance metrics feed advanced analytics engines. Trend analyses on incident frequency, remediation timelines and vulnerability exposure inform governance decisions. Scenario simulations project potential impacts on business processes, guiding budget allocations and risk transfer strategies such as insurance. Predictive alerts based on KPI thresholds enable proactive policy adjustments and resource reallocation, embedding a culture of continuous improvement.
Strengthened Stakeholder Trust and Market Differentiation
Transparency in security performance—demonstrated by AI-generated dashboards highlighting regulatory compliance, shrinking vulnerability gaps and faster incident resolution—becomes a market differentiator. Publicly shared executive summaries and compliance certifications, such as HITRUST or FedRAMP, enhance customer and partner confidence. Investor assurance increases when risk management and compliance metrics improve credit ratings, insurance terms and valuations, positioning the security program as an organizational asset.
By aligning AI-powered security operations with business objectives and regulatory requirements, organizations elevate security from a cost center to a competitive advantage, delivering measurable business impact, streamlined compliance and sustained stakeholder confidence.
Scalability, Customization and Industry Adaptation
To accommodate growth, evolving threats and regulatory diversity, the security and risk management workflow must be modular, configurable and extensible. By producing comprehensive outputs, establishing foundational dependencies and defining structured handoff mechanisms, the framework enables rapid adaptation across industries.
Deliverables for Extensibility
- Reference Architecture Blueprints: Detailed diagrams of microservices, data pipelines, AI inference clusters and orchestration layers for capacity planning.
- Module Templates and Plug-In Interfaces: Versioned skeletons, configuration files and API contracts for log ingestion, enrichment, routing and response playbooks.
- Industry-Specific Control Packs: Policy definitions, rule sets and report templates aligned with standards such as PCI DSS, HIPAA, NIST SP 800-53 and GDPR.
- Configuration Profiles and Parameter Sets: Environment-specific YAML or JSON files for network zones, cloud regions, storage tiers and model thresholds.
- Performance and Load Testing Scripts: Automated scenarios simulating high-volume ingestion and peak alert loads to guide scaling decisions.
- Extension SDKs and Developer Guides: Kits and documentation for building custom connectors, AI integrations and third-party adapters.
- Operational Runbooks and Playbooks: Procedures for provisioning, patching, key rotation and disaster recovery linked to CI/CD commands.
Foundational Dependencies for Modular Architecture
- Unified Service Registry and API Gateway: A catalog enforcing schema validation, version compatibility and access policies.
- Container and Orchestration Platform: Technologies such as Kubernetes that manage service lifecycles, autoscaling and health checks.
- CI/CD Pipeline with Policy Gates: Automated builds and tests incorporating static analysis, security scanning and compliance validations.
- Centralized Configuration and Secrets Management: Dynamic resolution of environment variables, credentials and encryption keys.
- Data Schema and Model Versioning Processes: Governance for evolving schemas and ML models with backward compatibility testing.
- Cross-Functional Governance Council: Representatives from security, IT, compliance, development and business units overseeing changes and control pack approvals.
- Monitoring and Telemetry Framework: End-to-end observability that feeds centralized analytics for real-time performance and utilization insights.
Structured Handoff Mechanisms
- Versioned Artifact Repository: All blueprints, templates, SDKs and runbooks stored and tagged for specific industry or release milestones.
- Automated Deployment Pipelines: Preconfigured CI/CD workflows that inject environment parameters and execute build, test and deploy stages.
- Onboarding Workshops and Knowledge Transfer: Training sessions and documentation reviews archived alongside code artifacts.
- Integration Checklists and Certification: Standardized tests for connectivity, schema validation and compliance verification before production rollout.
- Operational Support and Escalation Paths: Defined service-level objectives, contact points and escalation tiers for post-deployment issues.
- Feedback Loops into Governance Council: Post-implementation reviews that capture lessons learned and drive roadmap updates.
These modular outputs, dependencies and handoff processes ensure that new data sources, regulatory controls and AI capabilities can be integrated without disrupting core operations. The framework’s governance constructs and versioned artifacts provide a sustainable foundation for industry adaptation, enabling organizations to scale swiftly, customize effectively and maintain resilience in the face of evolving challenges.
Appendix
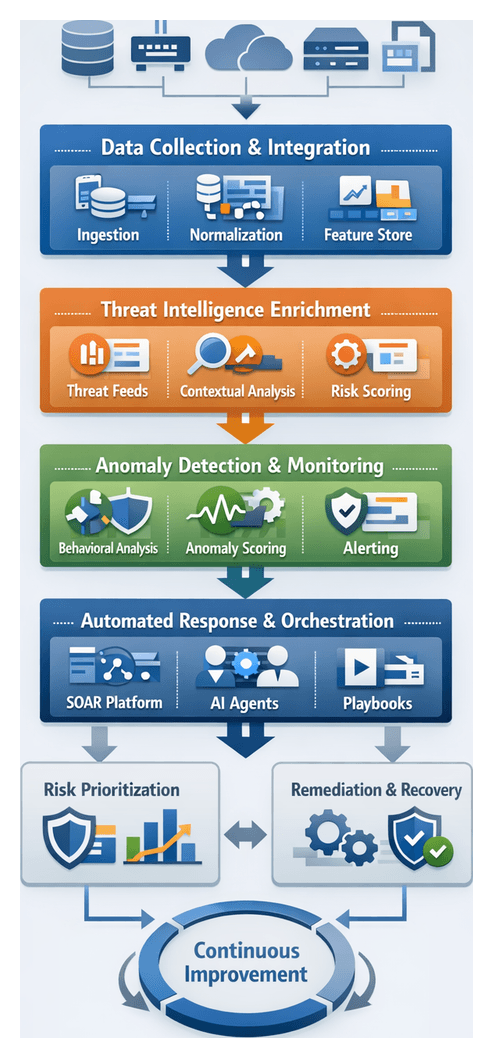
Key Workflow Terminology and Concepts
This appendix establishes a common vocabulary for AI-driven security and risk management workflows, ensuring consistent understanding across security, IT and business teams. Each term is defined with its purpose, relevance and context within an end-to-end pipeline for threat detection, response and continuous improvement.
Data Collection and Integration Concepts
- Centralized Data Pipeline: unified architecture for ingesting logs, metrics, asset inventories and external feeds, enforcing schema normalization and quality controls.
- Ingestion Connector: software agents that securely pull or receive data from network devices, endpoints, cloud services and third-party feeds via APIs, syslog or streaming protocols.
- Data Normalization: mapping vendor-specific fields into a canonical schema with consistent names, types and timestamps for reliable correlation.
- Schema Registry: managed catalog of data models and versioned field mappings that governs schema evolution and compatibility.
- Feature Store: repository of curated raw and derived attributes serving as inputs to machine learning models, with version control for reproducibility.
Intelligence Enrichment Concepts
- AI-Driven Parsing: supervised and unsupervised models that classify raw logs and extract attributes such as authentication failures or malware indicators.
- Natural Language Processing: transforms unstructured text from vulnerability advisories and threat reports into structured entities like CVE codes and malware names.
- Contextual Enrichment: augments events with metadata such as asset criticality, geolocation, user attributes and threat intelligence scores.
- Threat Intelligence Feed: external indicators of compromise—IP addresses, domains, file hashes—and metadata ingested in STIX, TAXII, JSON or CSV formats.
- Entity Resolution: correlates identifiers—usernames, IPs, hosts—across sources to build unified profiles and prevent duplication.
Orchestration and Automation Concepts
- Event Bus: message backbone routing normalized events to analytics engines, orchestration modules and storage in real time.
- Orchestration Layer: central engine enforcing workflow logic, routing tasks to AI agents, applying policy rules and tracking execution for auditability.
- AI Agent: modular component performing specialized functions such as anomaly detection, risk scoring or remediation execution under orchestration control.
- SOAR: Security Orchestration, Automation and Response platforms that integrate orchestration, case management and automation playbooks.
- Playbook: predefined sequence of actions, decision points and integrations codifying best practices for consistent response execution.
- Human-in-the-Loop: analyst review or approval at critical junctures to maintain oversight over automated actions.
- Service Level Agreement: documented performance targets—trigger-to-containment times, false positive rates—governing workflow stages.
Monitoring and Detection Concepts
- Behavioral Analytics: machine learning techniques—clustering, forecasting, deep learning—that establish baselines of normal behavior for networks, users and systems.
- Anomaly Detection: assigns confidence scores to deviations from learned patterns, triggering alerts for investigation or automated response.
- Confidence Score: numerical value representing likelihood that an event is malicious, used for prioritization and severity assessment.
- Model Drift: performance degradation due to changing data distributions, detected by monitoring input and output statistics.
- Baseline Profile: snapshot of typical behavior patterns—login frequencies, traffic volumes—regularly updated to reflect environmental changes.
Risk Management and Prioritization Concepts
- Risk Scoring: composite metric combining exploitability factors and business impact measures to guide remediation planning.
- Asset Criticality: business-driven rating reflecting system importance, influencing automated response and prioritization.
- Graph Analytics: models entities as nodes and relationships as edges to detect lateral movement and compromised clusters.
- Bayesian Networks: probabilistic models representing conditional dependencies among risk factors to simulate attack paths.
Remediation and Response Concepts
- Containment: actions such as network isolation or account suspension to limit attacker movement.
- Eradication: removal of malicious code, persistence mechanisms and misconfigurations via endpoint cleanup and patching.
- Recovery: steps to restore systems to normal operation, including patch verification and configuration baseline restoration.
- Forensic Data Capture: acquisition of memory dumps, disk images and network captures under chain-of-custody controls.
- Recovery Confirmation: automated or manual validation of security and functional criteria after remediation.
Continuous Improvement and Governance Concepts
- Feedback Loop: processes feeding incident outcomes and performance metrics back into detection and response pipelines.
- Model Retraining: automated or scheduled workflows rebuilding models on updated datasets to address drift.
- MLOps: applying DevOps principles to model development, deployment and monitoring via pipelines, registries and automation.
- Version Control: tracking changes to code, policy definitions, model artifacts and playbooks for auditability and rollback.
- Policy Refinement Agent: AI-driven modules analyzing detection performance and recommending policy adjustments.
- Governance Dashboard: centralized interface displaying security and compliance metrics, model statuses and SLA adherence.
AI-Driven Workflow Stages
Data Collection and Integration
AI streamlines ingestion of heterogeneous data, automating schema discovery, normalization and noise filtering to establish a resilient pipeline.
- Source Classification: unsupervised algorithms group new streams by format, selecting parsing templates and connectors.
- Schema Inference: models analyze sample events to infer field names, types and structures, reducing manual mapping.
- Anomaly Filtering: outlier detection removes redundant or malformed records, ensuring high-value telemetry advances.
- Entity Extraction: NLP parses unstructured fields to extract IP addresses, user names and file paths.
- Contextual Enrichment: AI agents tag records with asset criticality and threat reputation via cross-referencing with inventories and feeds.
Platforms like Splunk and Elastic Stack integrate AI-driven ingestion connectors and schema engines to accelerate source onboarding.
Threat Intelligence Enrichment
AI enhances external and internal feeds by normalizing formats, classifying indicators, connecting relationships and assigning risk ratings.
- Feed Normalization: NLP and pattern matching convert STIX, TAXII and CSV feeds into a standardized schema.
- Indicator Classification: supervised classifiers categorize IOCs by threat type, severity and adversary affiliation.
- Graph Analytics: algorithms reveal relationships among IPs, domains, malware families and actor infrastructure.
- Risk Scoring: ensemble models assign quantitative ratings based on freshness, confidence and source reliability.
- Behavioral Contextualization: clustering groups indicators into campaign clusters for coordinated attack detection.
Solutions such as Recorded Future and ThreatConnect deliver prioritized, context-rich threat feeds.
Real-Time Monitoring and Anomaly Detection
AI models establish dynamic baselines and detect deviations with high confidence, enabling timely alerts and automated responses.
- Dynamic Baseline Modeling: time-series forecasting and clustering accommodate periodic and seasonal behavior variations.
- Anomaly Scoring: deep learning and statistical methods assign severity to deviations in login frequencies, process activity or data transfers.
- Alert Prioritization: decision trees integrate confidence scores, asset criticality and threat context to rank alerts.
- Adaptive Thresholding: reinforcement learning adjusts detection thresholds based on feedback to balance sensitivity.
- Streaming Inference: low-latency frameworks process Kafka and cloud event streams for sub-second alert generation.
Platforms like Microsoft Sentinel and Splunk User Behavior Analytics support real-time security monitoring at scale.
Risk Assessment and Prioritization
AI quantifies exposure by combining vulnerability, intelligence and asset data into prioritized risk scores guiding remediation.
- Asset Criticality Modeling: regression and classification predict business impact from asset attributes and dependency graphs.
- Exploitability Analysis: classifiers estimate exploit likelihood from CVSS vectors, exploit availability and advisories.
- Risk Scoring Engines: ensemble methods and Bayesian networks combine probability and impact into normalized scores.
- Scenario Simulation: probabilistic attack path simulations estimate breach potential through lateral movement and privilege escalation.
- Prioritization Logic: multi-objective optimization ranks remediation tasks by risk reduction and resource constraints.
Solutions such as Tenable.io and RSA Archer integrate AI-driven risk models for executive-level visibility.
Vulnerability Management Automation
AI interprets scan results, recommends fixes and orchestrates remediation workflows to accelerate closure and reduce exposure.
- Vulnerability Classification: NLP parses scanner reports and advisories to extract CVE details and severity contexts.
- Remediation Recommendation: case-based reasoning suggests patch or configuration actions based on historical success rates.
- Ticket Generation: rule engines automatically create prioritized remediation tickets in ITSM systems with asset context.
- Remediation Orchestration: AI-driven playbooks coordinate patch deployment and container image rebuilds via automated connectors.
- Closure Verification: ML models confirm resolution by analyzing updated scan outputs and runtime telemetry.
Platforms like Qualys and Rapid7 InsightVM leverage AI agents for classification, recommendation and orchestration.
Identity and Access Governance
AI enhances access governance through identity reconciliation, privilege anomaly detection and continuous certification.
- Attribute Reconciliation: models resolve identity fragments across directories and cloud providers into unified profiles.
- Entitlement Anomaly Detection: clustering identifies privilege creep by comparing group memberships against peer baselines.
- Continuous Certification Automation: AI agents optimize access review cycles based on usage patterns.
- Behavioral Profiling: sequence and graph-based models detect unusual access requests and insider threats in real time.
- Policy Enforcement Recommendations: classifiers suggest adjustments to enforce least-privilege and remediate deviations.
Solutions such as SailPoint IdentityIQ and Cisco SecureX embed AI for entitlement analytics and automated policy enforcement.
Compliance Management and Reporting
AI automates evidence collection, control assessment and report generation to ensure continuous audit readiness.
- Control Mapping via NLP: agents parse regulatory frameworks to map required controls to technical artifacts.
- Automated Evidence Collection: RPA bots gather logs, configurations and policy settings from disparate platforms.
- Continuous Policy Assessment: rule engines evaluate controls against live data, flagging non-compliance in real time.
- Exception Prediction: classifiers distinguish acceptable exceptions from critical violations.
- Report Generation Engines: templates populate audit-ready reports with dynamic evidence and compliance summaries.
Platforms like ServiceNow GRC and OneTrust leverage AI to automate control assessments and documentation.
Incident Investigation and Case Management
AI accelerates data enrichment, hypothesis generation and workflow orchestration to resolve cases faster.
- Contextual Enrichment: graph analytics assemble related events, sessions and interactions into incident graphs.
- Hypothesis Generation: Bayesian reasoning and NLP propose likely attack scenarios and investigative queries.
- Forensic Data Retrieval: automated agents capture memory dumps, disk images and network PCAPs via EDR platforms.
- Case Orchestration: workflow engines assign tasks, enforce SLAs and track progress in platforms like IBM Security Resilient.
- Collaboration Automation: agents assemble timelines, summaries and dashboards to enhance coordination.
Solutions such as CrowdStrike Falcon integrate AI enrichment and orchestration for accelerated investigations.
Automated Incident Response and Remediation Orchestration
AI-driven orchestration coordinates containment, eradication and recovery steps across security controls and IT systems.
- Trigger Evaluation Models: rule-based and ML systems decide when to launch playbooks based on risk thresholds.
- Containment Agents: integrate with firewalls, NAC, EDR and cloud controls to isolate compromised assets.
- Eradication Agents: remove malicious artifacts and update configurations via security APIs.
- Recovery Agents: interact with IaC and patch management systems to rebuild and restore systems.
- Notification Agents: update ticketing systems and stakeholders with real-time status and audit logs.
Platforms such as Palo Alto Cortex XSOAR and Demisto exemplify AI-driven response orchestration.
Continuous Feedback and Strategic Improvement
AI analyzes operational outcomes to detect drift, optimize policies and refine playbooks, closing the feedback loop for a resilient security program.
- Performance Analytics: models compute metrics such as MTTD, MTTR and detection accuracy for leadership review.
- Drift Detection Agents: monitor data distributions and model outputs, triggering retraining workflows.
- Reinforcement Learning: optimizes thresholds and playbook parameters using reward signals from successful responses.
- Policy Refinement Agents: NLP and rule engines automatically update rules and policies based on insights.
- Strategic Reporting Dashboards: provide real-time visualizations of posture improvements and risk reduction.
Technologies such as DataRobot and Azure Machine Learning support automated retraining, drift detection and policy refinement at scale.
Common Variations and Resilience Strategies
Real-world environments present edge cases—intermittent connectivity, legacy systems, regulatory exceptions and event surges—that challenge ideal workflows. Adaptive strategies ensure robustness and accuracy.
Data Ingestion Under Intermittent Connectivity
- Buffering and Store-and-Forward: local collectors queue events during outages and forward when connectivity returns.
- Edge-Based Enrichment: lightweight AI agents at the network edge perform preliminary parsing and anomaly detection.
- Adaptive Sampling: adjust sampling rates based on bandwidth, prioritizing critical asset logs.
Heterogeneous Log Formats and Unmapped Schemas
- Schema Discovery Agents: unsupervised learning clusters unrecognized logs and infers field mappings.
- Fallback Parsers: generic parsers treat unknown fields as key-value pairs, preserving raw text.
- Incremental Onboarding: automate validation tests to detect mapping issues early in source integration.
API Rate Limits and Throttling Constraints
- Back-off and Retry Logic: exponential back-off with jitter to avoid synchronized retry storms.
- Local Caching: store frequent intelligence lookups with configurable TTL to reduce API calls.
- Batching and Aggregation: group requests into bulk operations where supported.
Data Drift in Detection Models
- Drift Monitoring Agents: track feature distributions and alert on divergences from training baselines.
- Sliding Window Retraining: periodically rebuild models on recent data segments to capture new patterns.
- Shadow Deployments: evaluate candidate models in parallel to production to catch regressions.
Legacy Systems and Limited Integration
- RPA-Driven Extraction: use robotic process automation to extract logs and configurations from legacy UIs.
- Network Traffic Analysis: infer application behavior via passive flow monitoring when direct integration is unavailable.
- Isolated Remediation Tasks: provide manual playbooks alongside automated instructions for unreachable systems.
High-Volume Event Bursts and Backpressure Management
- Rate-Based Filtering: dynamically suppress or summarize low-value events during peaks.
- Elastic Auto-Scaling: leverage container orchestration and cloud scaling to match processing resources to load.
- Dead-Letter Queues: divert malformed records for offline analysis without blocking primary streams.
Cross-Domain Trust and Time Synchronization Errors
- NTP Enforcement: synchronize all agents and devices to central NTP servers and monitor drift.
- Federated Identity Mapping: reconcile identifiers across cloud and on-prem directories via resolution agents.
- Temporal Window Adjustments: configure allowable time windows in correlation engines to account for minor discrepancies.
Split-Brain Scenarios in Orchestration Clusters
- Leader Election and Lease Locks: use distributed coordination services to elect a single active orchestrator.
- Idempotent Playbook Steps: design tasks to be safe to run multiple times without adverse effects.
- Conflict Detection Agents: monitor action logs and reconcile overlapping executions.
Data Privacy Constraints and PII Handling
- Field-Level Encryption and Tokenization: mask personal data before ingestion, preserving correlation via tokens.
- Privacy-Aware Anonymization: reversible anonymization techniques allow controlled re-identification for forensics.
- Policy-Driven Exclusion: filter or restrict telemetry flows based on consent and data residency rules.
Multi-Tenant and Shared Infrastructure
- Scoped Orchestration Namespaces: partition components by tenant to isolate data streams and playbook contexts.
- Tenant-Aware Agents: embed tenant identifiers in telemetry and action logs for strict separation.
- Dynamic Policy Templates: maintain tenant-specific policy attributes and thresholds per service agreement.
Unusual Incident Scenarios
- Exception Playbooks: specialized workflows for insider threats, supply chain compromises and zero-day exploits with manual review steps.
- Human-in-the-Loop Gateways: approval gates before executing broad remediation actions under expert oversight.
- Dynamic Workflow Adaptation: orchestration engines branch into exploratory flows when triggers do not match known patterns.
By anticipating these edge cases and employing modular architecture, idempotent playbooks, dynamic scaling, rigorous validation and continuous feedback, organizations can design AI-driven security workflows that remain effective, compliant and trustworthy in complex environments.
AI Tools and Reference Resources
AI Tools Mentioned
- Splunk – A platform for collecting, indexing and analyzing machine-generated data, offering built-in machine learning for security use cases.
- Elastic Stack – An open-source suite for search, logging and analytics, with Elastic Security providing AI-driven threat detection.
- AWS Kinesis – A managed service for real-time data streaming and ingestion at scale, supporting analytics workloads.
- Azure Event Hubs – A big data streaming platform and event ingestion service capable of receiving millions of events per second.
- ServiceNow CMDB – A configuration management database that tracks assets, dependencies and changes across the enterprise infrastructure.
- CrowdStrike Falcon – A cloud-native endpoint protection platform combining EDR, threat intelligence and AI-powered analytics.
- VMware Carbon Black – An endpoint detection and response solution that uses behavioral analytics to identify malicious activity.
- AWS CloudTrail – A service that records account activity and API calls across AWS infrastructure for auditing and compliance.
- Azure Monitor – A full-stack monitoring service for collecting and analyzing telemetry from on-premises and Azure resources.
- Google Cloud Logging – A log management service for real-time ingestion, storage and analysis of application and system logs.
- Recorded Future – A threat intelligence platform that applies machine learning and NLP to analyze global data sources and deliver risk scores.
- ThreatConnect – A platform for aggregating, analyzing and acting on threat intelligence, integrating AI-driven enrichment and orchestration.
- IBM QRadar – A SIEM solution that integrates AI-enhanced analytics to detect anomalies and prioritize incidents.
- Microsoft Sentinel – A cloud-native SIEM and SOAR solution that uses built-in AI to detect, investigate and respond to threats.
- Palo Alto Cortex XSOAR – A security orchestration, automation and response platform that unifies case management and playbooks with machine learning.
- Cisco SecureX – A cloud-native security platform that integrates Cisco and third-party tools, leveraging AI for automated workflows.
- ServiceNow Security Operations – A module for automating threat response, vulnerability remediation and compliance within the ServiceNow platform.
- Apache Kafka – A distributed event streaming platform used for building real-time data pipelines and streaming applications.
- AWS SageMaker – A fully managed service to build, train and deploy machine learning models at scale.
- Google Vertex AI – A unified platform for building and deploying ML models, integrating AutoML and custom training.
- DataRobot – An enterprise AI platform that automates model building, deployment and monitoring.
- MLflow – An open-source platform for managing the end-to-end machine learning lifecycle, including experiment tracking and model registry.
- Kubeflow – A toolkit for deploying and managing ML workflows on Kubernetes, supporting scalable training and serving.
- Ray RLlib – A scalable reinforcement learning library for distributed training and serving of RL agents.
- Neo4j – A graph-database platform used for relationship mapping and graph analytics in threat investigations.
Additional Context and Resources
- MITRE ATT&CK – A globally accessible knowledge base of adversary tactics and techniques used for threat modeling and behavior mapping.
- STIX/TAXII – Open standards for structuring and exchanging cyber threat intelligence, enabling interoperability across platforms.
- Elastic Common Schema (ECS) – A specification for structuring data in Elasticsearch to simplify query and correlation across diverse sources.
- Common Event Format (CEF) – An open log management standard for representing event data in a consistent format.
- Open Cybersecurity Schema Framework (OCSF) – A collaborative initiative to define common schemas for security telemetry across tools and vendors.
- CSI Benchmarks – Configuration guidelines and best practices for securing systems, maintained by the Center for Internet Security.
- PCI DSS – A standard for securing payment card data, relevant for evidence collection and compliance automation.
- GDPR Compliance Toolkit – Resources for managing data privacy requirements under the EU General Data Protection Regulation.
- HIPAA Security Rule – U.S. regulations for protecting electronic health information, guiding security and audit processes.
- NIST SP 800-53 – A catalog of security and privacy controls for federal information systems and organizations.
- ISO 27001 – An international standard for information security management systems, frequently referenced in compliance frameworks.
- OWASP Top Ten – A regularly updated list of the most critical web application security risks, used for vulnerability management.
- YARA – A tool for identifying and classifying malware through pattern-matching rules.
- Volatility Framework – An open-source memory forensics framework for incident response investigations.
- Zeek (formerly Bro) – A powerful network analysis framework for security monitoring and traffic analysis.
- Demisto – A SOAR platform acquired by Palo Alto Networks and now part of Cortex XSOAR, enabling automated investigation playbooks.
- AttackIQ – A breach and attack simulation platform for testing defensive controls and validating detection capabilities.
- ServiceNow GRC – A governance, risk and compliance application suite for managing policies, assessments and audit workflows.
- OneTrust – A privacy, security and third-party risk management platform used for GDPR, CCPA and ISO 27001 compliance.
- DataRobot Feature Store – A managed feature store that supports consistent feature engineering and retrieval for ML pipelines.
- AWS CloudFormation – An infrastructure-as-code service for deploying and updating AWS resources in a controlled manner.
- Terraform – An open-source tool for provisioning and managing infrastructure as code across multiple cloud providers.
- Apache Airflow – A workflow orchestration platform for authoring, scheduling and monitoring data pipelines and automated tasks.
The AugVation family of websites helps entrepreneurs, professionals, and teams apply AI in practical, real-world ways—through curated tools, proven workflows, and implementation-focused education. Explore the ecosystem below to find the right platform for your goals.
Ecosystem Directory
AugVation — The central hub for AI-enhanced digital products, guides, templates, and implementation toolkits.
Resource Link AI — A curated directory of AI tools, solution workflows, reviews, and practical learning resources.
Agent Link AI — AI agents and intelligent automation: orchestrated workflows, agent frameworks, and operational efficiency systems.
Business Link AI — AI for business strategy and operations: frameworks, use cases, and adoption guidance for leaders.
Content Link AI — AI-powered content creation and SEO: writing, publishing, multimedia, and scalable distribution workflows.
Design Link AI — AI for design and branding: creative tools, visual workflows, UX/UI acceleration, and design automation.
Developer Link AI — AI for builders: dev tools, APIs, frameworks, deployment strategies, and integration best practices.
Marketing Link AI — AI-driven marketing: automation, personalization, analytics, ad optimization, and performance growth.
Productivity Link AI — AI productivity systems: task efficiency, collaboration, knowledge workflows, and smarter daily execution.
Sales Link AI — AI for sales: lead generation, sales intelligence, conversation insights, CRM enhancement, and revenue optimization.
Want the fastest path? Start at AugVation to access the latest resources, then explore the rest of the ecosystem from there.