

AI Driven Legal Research and Risk Mitigation Workflow Guide
To download this as a free PDF eBook and explore many others, please visit the AugVation webstore:
Introduction
Operational Challenges in Legal Research and Risk Management
The volume and complexity of legal materials continue to grow at an unprecedented pace. Organizations generate petabytes of contracts, court filings, statutes, regulations, internal policies and external alerts each year. Simultaneously, regulatory landscapes evolve constantly across multiple jurisdictions, driven by policy reforms, technological advances and geopolitical developments. Legal teams struggle to locate relevant documents, extract key provisions and assess compliance obligations using manual processes. This leads to high costs, delayed decision making and increased risk exposure.
- Document Volume Explosion: A steady influx of master service agreements, court dockets, regulatory guidance and industry bulletins overwhelms traditional intake methods.
- Evolving Regulatory Dynamics: Continuous updates in data privacy, environmental standards and financial regulations demand real-time visibility into contract triggers and remediation actions.
- Document Complexity and Heterogeneity: Contracts may contain embedded spreadsheets, scanned signatures and multilingual annexes, while case files mix typed transcripts and discovery materials in diverse formats.
- Unchecked Risk Exposure: Manual review often misses indemnity obligations, termination deadlines or jurisdictional conflicts until after breaches occur.
- Data Silos and Fragmented Systems: Disparate repositories, on-premises servers, cloud storage and specialized applications prevent unified access and end-to-end workflows.
- Resource Constraints and Skill Gaps: Highly skilled attorneys spend excessive time on routine tasks, while locating experts in niche regulatory domains remains challenging.
- Version Control and Auditability: Ensuring traceable document versions, AI model parameters and reviewer annotations is essential for compliance audits and litigation support.
- High Stakes of Timely Research: Missed deadlines can trigger fines, sanctions or litigation setbacks, placing pressure on legal teams to deliver rapid, evidence-based insights.
Addressing these challenges requires a systematic intake process that captures, normalizes and classifies all relevant materials before applying advanced analytics. Prerequisites include a unified document management policy, standardized taxonomies, secure connectors to diverse data sources and governance frameworks for data privacy and model accountability.
Towards a Cohesive AI Workflow
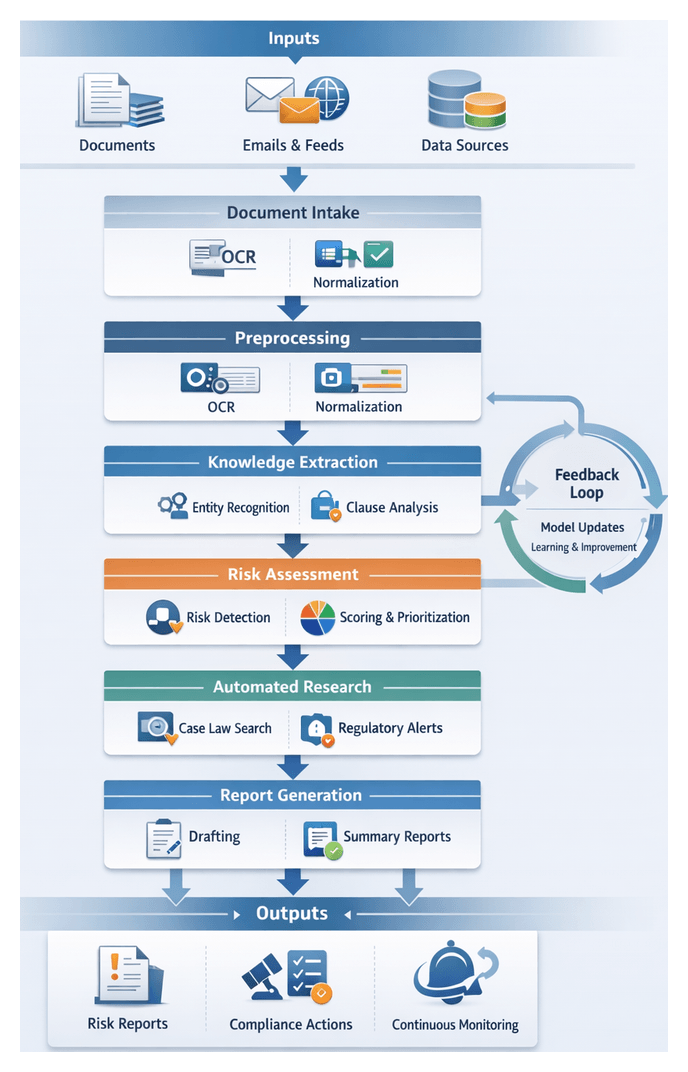
A cohesive AI workflow integrates stages of data ingestion, text processing, knowledge extraction, risk analysis and reporting into an orchestrated pipeline. By replacing ad hoc handoffs and email exchanges with standardized interfaces and event-driven triggers, legal operations achieve predictable throughput, transparent monitoring and clear accountability.
Key Participants and Systems
- Document Intake System: Ingests contracts, case files, regulatory texts and external feeds via upload portals, email services or APIs.
- Preprocessing Engine: Applies optical character recognition and format conversion, producing machine-readable text and enriched metadata.
- Knowledge Extraction Module: Uses tools like Kira Systems and Google Document AI to identify entities, clauses and relationships.
- Risk Classification Engine: Employs rule-based checks and machine-learning models on platforms such as Azure Machine Learning to flag compliance issues and contractual exposures.
- Scoring and Prioritization Service: Ranks risks by severity using business context from systems like DocuSign CLM.
- Automated Research Agents: Conduct semantic searches in databases such as Thomson Reuters Westlaw and LexisNexis.
- Report Drafting Interface: Leverages AI drafting modules like OpenAI GPT-4 and human review in platforms such as Clio.
- Orchestration Layer: Coordinates tasks, triggers exception workflows and maintains audit logs.
- Monitoring and Alerting Component: Tracks regulatory changes and contract performance, generating timely notifications.
- Feedback and Learning Pipeline: Uses tools like DataRobot to retrain models based on user corrections and performance metrics.
Workflow Sequence
- Ingestion: Documents enter via portals, email connectors or APIs and are cataloged with preliminary metadata.
- Preprocessing: OCR engines and format converters produce normalized text formats stored in a unified repository.
- Extraction: NLP engines extract parties, dates, obligations and clauses, populating a knowledge graph.
- Risk Detection: Rule sets and ML classifiers analyze extracted data to generate risk flags and confidence scores.
- Scoring: Risks are quantified and ranked according to impact models and external risk factors.
- Automated Research: High-priority items trigger semantic searches for relevant case law and statutes.
- Drafting: NLG modules compile executive summaries and dashboards for review.
- Decision Support: Approved findings are integrated into case management systems with assigned tasks and deadlines.
- Continuous Monitoring: Alerts for regulatory updates or contract expirations are routed to stakeholders.
- Feedback Loop: User annotations and performance data feed retraining pipelines, updating models and ontologies.
AI Capabilities in Research and Risk Analysis
Artificial intelligence transforms legal research by automating routine tasks, revealing hidden relationships and enabling predictive insights. By moving beyond keyword searches to context-aware models, AI enhances accuracy and accelerates time to insight.
Core Functions
- Document Classification and Topic Tagging: Pretrained classifiers such as Google Cloud Natural Language categorize documents by risk profile, jurisdiction or subject.
- Entity Extraction and Relationship Mapping: Engines like IBM Watson Discovery identify legal entities and build knowledge graphs that reveal contractual linkages.
- Semantic Search and Contextual Retrieval: Services in Microsoft Azure Cognitive Services surface relevant precedents and clauses based on intent rather than exact terms.
- Predictive Analytics and Risk Forecasting: ML models analyze historical outcomes to predict dispute likelihood and compliance violations.
- Automated Summarization and Issue Spotting: Natural language generation via OpenAI GPT-4 produces concise summaries highlighting key obligations and deadlines.
Integration and Governance
- API-First Design: Each AI capability exposes RESTful or gRPC interfaces, enabling modular scalability.
- Event-Driven Processing: Message buses such as Apache Kafka dispatch tasks and trigger downstream services automatically.
- Model Management: A registry tracks versions, training data provenance and performance metrics, with automated validation before deployment.
- Security and Compliance: End-to-end encryption, role-based access controls and audit logging ensure confidentiality and regulatory adherence.
- Explainable AI and Bias Mitigation: Tools provide feature-level explanations for risk scores, while training data audits prevent unintended bias.
Risk Signal Generation
- Clause Flagging: Pre-trained models detect non-standard indemnities or liability language for attorney review.
- Regulatory Alerts: Change-detection algorithms compare new regulations against existing obligations and trigger notifications.
- Exposure Scoring: Numeric values reflect potential financial and reputational impact, guiding prioritization.
- Contextual Classification: Hybrid engines combine policy rules with ML patterns to categorize alerts by type and severity.
Architecture of an AI-Driven Solution
A modular, layered architecture underpins a scalable, transparent AI workflow. Distinct stages encapsulate inputs, outputs and dependencies, with a central orchestration layer managing sequencing, human-in-the-loop approvals and audit trails.
- Data Ingestion: Catalogs raw assets and metadata, publishing file pointers to preprocessing queues.
- Preprocessing and Normalization: Converts files to plain text or XML, detects languages and enriches metadata.
- Knowledge Extraction: Populates entity tables and knowledge graphs via NLP pipelines.
- Risk Identification and Classification: Generates risk flags and preliminary categories using policy engines and ML classifiers.
- Risk Scoring and Prioritization: Produces quantitative scores and priority lists based on impact models.
- Automated Legal Research: Curates case law, statutes and annotated summaries via semantic search engines.
- Insight Generation and Drafting: Creates draft memoranda, dashboards and language templates with NLG models.
- Decision Support and Orchestration: Assigns tasks, logs approvals and routes action items to compliance processes.
- Compliance Monitoring and Alerting: Delivers real-time alerts and change logs tied to performance metrics.
- Continuous Learning and Optimization: Retrains models, updates ontologies and refines workflows based on feedback.
Integration and Resilience
- Message Queues and RESTful APIs: Standardized interfaces ensure decoupled, fault-tolerant handoffs.
- Model Registry and Fallback Strategies: Tracks AI artifacts and provides rule-based backups when needed.
- Health Monitoring and Containerization: Automated checks and isolated runtime environments support reliable operations.
- Horizontal Scaling and Encryption: Stateless stages scale on demand, while data encryption safeguards sensitive content.
Implementation Roadmap
- Baseline Assessment: Map current processes, repositories and integration points.
- Pilot Deployment: Deploy ingestion, preprocessing and extraction on a representative document set.
- Iterative Expansion: Introduce risk detection, scoring and research agents, refining handoffs based on user feedback.
- Governance Onboarding: Establish policies for data privacy, access controls and model accountability.
- Continuous Improvement: Leverage feedback loops to retrain models, update taxonomies and optimize the workflow.
By aligning technology with human expertise, enforcing robust governance and adopting a modular architecture, legal teams can transform research and risk management. The result is faster, more accurate insights, reduced operational costs and a resilient platform that adapts to evolving regulations and organizational needs.
Chapter 1: Data Ingestion and Document Intake
Purpose and Goals of the Intake Stage
The Intake Stage establishes a unified, secure, and standardized foundation for AI-driven legal research and risk mitigation. By aggregating contracts, filings, regulatory bulletins, correspondence, and third-party feeds into a governed repository, the intake process eliminates manual bottlenecks and siloed information. Four core objectives guide its design:
- Unified capture of all incoming documents and data streams.
- Consistent classification through an initial taxonomy and metadata schema.
- Secure handling via encryption, access controls, and audit trails.
- Seamless routing based on document type, jurisdiction, or priority.
Achieving these goals ensures that downstream AI stages—entity extraction, risk analysis, and automated reporting—operate on organized, high-quality inputs, accelerating time-to-insight and reducing operational risk.
Prerequisites and Governance
Governance and Policy Framework
A robust governance model defines ownership, roles, and standards for retention, security, and compliance. Essential elements include:
- A firm-wide classification taxonomy for categorizing documents (agreements, pleadings, discovery materials) and tagging attributes such as jurisdiction, counterparty, and confidentiality level.
- Role-based access controls and approval workflows to restrict document viewing and routing.
- Compliance alignment with regulations such as GDPR or HIPAA, preserving audit trails and preventing unauthorized disclosures.
Technical Infrastructure and Connectivity
Scalable IT infrastructure supports high-volume ingestion and secure storage. Key requirements include:
- Elastic storage solutions, on-premises or cloud-based, with redundancy and backups.
- Encrypted network channels (VPNs or SSL/TLS) and sufficient bandwidth for batch uploads, streaming feeds, and API integrations.
- Connector frameworks for systems like SharePoint, iManage, NetDocuments and external sources such as PACER or regulatory websites.
Data Quality and Standardization
Consistent formatting and metadata integrity at intake reduce downstream errors and improve AI accuracy:
- Supported file formats (PDF/A, Word, TIFF, XML, JSON) with procedures to flag or convert unsupported types.
- Mandatory metadata fields (document date, author, source, counterparty) and controlled vocabularies.
- Exception management workflows for corrupted files or missing metadata, with quarantine buckets and notification processes.
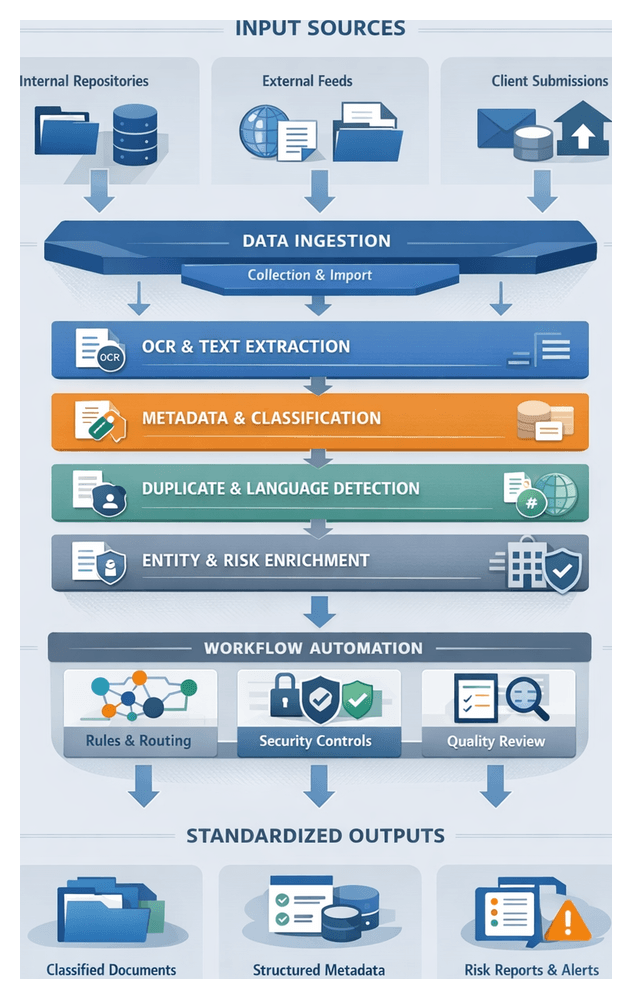
Sources and Document Types
The intake system must ingest content from diverse internal and external locations, applying the appropriate classification and routing logic from the outset.
Internal Repositories
- Document Management Systems such as iManage or NetDocuments.
- Contract Lifecycle Management platforms like Luminance and Kira Systems.
- Case and matter management tools tracking filings and client communications.
- Shared network drives and email archives containing legacy files and draft memos.
External Feeds and Regulatory Sources
- Judicial dockets and filings via PACER or state court registries.
- Regulatory publications from the SEC, Federal Register, or European Commission.
- Industry watchlists and compliance databases from providers such as Dow Jones or Thomson Reuters.
Client and Counterparty Submissions
- Email attachments and secure portal uploads containing signed agreements or exhibits.
- Hard-copy scans digitized with OCR services like Google Cloud Vision API or Azure Form Recognizer.
- Structured data feeds from third-party providers delivering market data and research.
AI-Driven Ingestion Capabilities
The intake stage leverages AI microservices to transform raw inputs into enriched, standardized data assets.
Optical Character Recognition
Image-based files are converted to machine-readable text with high-precision OCR engines such as Amazon Textract, ABBYY FineReader, or Google Cloud Document AI. These services preserve tables, columns, and footnotes, returning text outputs with positional metadata for layout reconstruction.
Metadata Extraction and Tagging
AI models identify key attributes—title, author, dates, parties, jurisdiction—using tools like Azure Form Recognizer or IBM Watson Natural Language Understanding. Extracted fields include confidence scores and adhere to custom taxonomies, facilitating accurate indexing and search.
Preliminary Classification
Supervised classifiers based on transformer architectures or decision trees assign document types—contracts, pleadings, regulatory notices—using platforms such as Relativity or open-source frameworks built on spaCy. Low-confidence results route to human review queues, blending AI speed with expert oversight.
Language Detection and Multi-Language Support
Language detection models, including open-source libraries or commercial services like Google Cloud Translation, identify document languages to invoke appropriate OCR engines or translation workflows, ensuring global materials are processed correctly.
Duplicate Detection
Fingerprinting techniques (MinHash, SimHash) detect exact and near duplicates to prevent redundant processing and maintain version links across revisions.
Data Enrichment and External Reference Linking
Extracted entities are validated and enriched against external databases or APIs such as OpenCorporates, attaching standardized identifiers, corporate addresses, and status information that inform risk models.
Integration Patterns and Model Governance
Each AI capability operates as a microservice within an event-driven architecture, using message queues and an API gateway to orchestrate processing. Model governance frameworks monitor performance metrics—OCR character error rate, classification precision—and trigger retraining with human-verified examples when drift occurs. Versioned artifacts and validation reports ensure auditability.
Security and Compliance
All data in transit and at rest is encrypted, and role-based access controls restrict service invocation. Models flag personally identifiable information for redaction, and audit logs capture service calls and predictions for regulatory review.
Intake Workflow and System Orchestration
The end-to-end intake process transforms raw inputs into QA-validated, metadata-enriched packages ready for preprocessing. Sequential actions include source integration, central repository consolidation, pre-assessment filtering, metadata enrichment, automated classification, dynamic routing, quality control, and handoff.
- Source integration via email APIs, SFTP, watch-folders, eDiscovery connectors, and secure web portals.
- Capture and normalization using engines like ABBYY FlexiCapture, converting legacy formats into searchable PDFs and applying version control.
- Content filtering with duplicate detection, password handling, and size thresholds.
- Metadata extraction, entity recognition, and context inference with Amazon Comprehend or on-premise NLP services.
- Machine learning classification and tagging yielding topic labels, risk flags, and priority markers.
- Dynamic routing by a BPMN engine such as Camunda, directing documents to high-priority, language-specific, standard pipelines, or exception queues.
- Automated and manual quality checks ensuring metadata completeness, OCR accuracy, and sampling-based audits.
- Handoff to preprocessing via message buses or API triggers once validation criteria are met.
System interactions span capture engines, AI microservices, orchestration platforms, case management portals, and monitoring dashboards. Key roles include intake coordinators, paralegals for validation, and IT specialists for connector maintenance and model updates. Performance metrics—throughput, intake time, error rate, SLA adherence, queue depths—are tracked on dashboards with alerting to guide continuous improvement.
Outputs, Handoff, and Quality Assurance
At the intake stage’s conclusion, standardized deliverables enable seamless downstream processing:
- Document packages containing original files, OCR or native text, version IDs, and checksums, serialized as ZIP archives or JSON manifests and ingested into platforms.
- Structured metadata artifacts—classifications, extracted fields, language tags, provenance details, preliminary risk flags—stored in indexes such as Elasticsearch or managed datastores via Google Document AI.
- Quality and confidence metrics covering OCR accuracy, completeness checks, format compliance, and duplicate scores, guiding conditional routing or human review.
Handoff mechanisms include message queues (Kafka, RabbitMQ), RESTful APIs, change data capture streams, or filesystem watchers. Dependency management and versioning capture package versions, timestamped metadata snapshots, integrity proofs, and AI service release references. Error handling employs classification tiers, retry policies with backoff, engine fallback options, and dead-letter queues, with alerts escalated for human intervention. This rigorous framework ensures that preprocessing and extraction pipelines receive reliable, traceable inputs, maintaining throughput and compliance in AI-driven legal research workflows.
Chapter 2: Preprocessing and Text Normalization
Preprocessing Objectives and Inputs
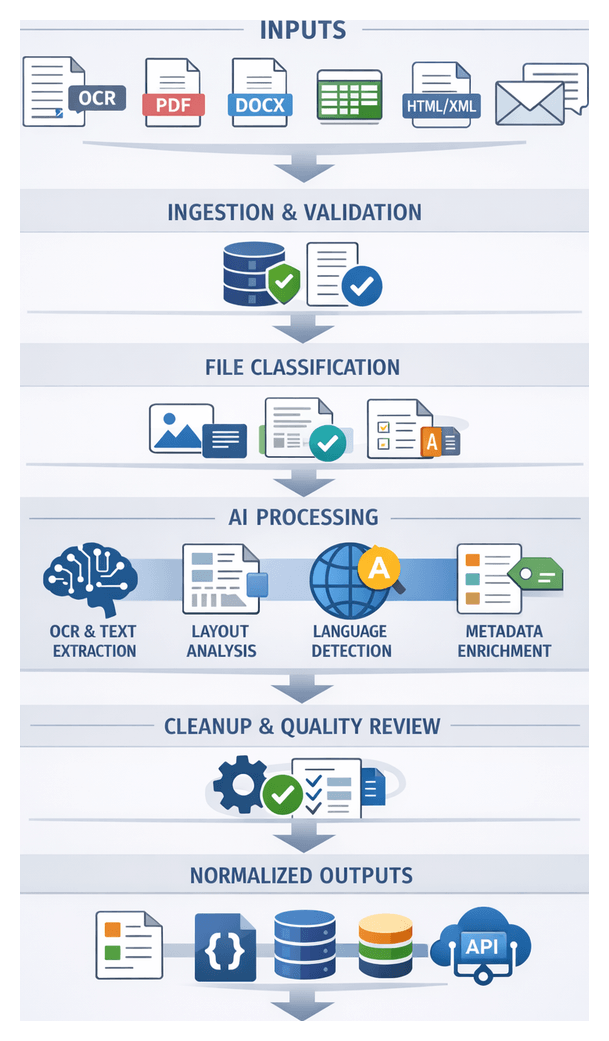
The preprocessing stage transforms incoming legal documents—regardless of format or origin—into a unified, machine-readable text representation enriched with aligned metadata. By enforcing input validation, format conversion, and metadata alignment at scale, it minimizes manual remediation, accelerates processing cycles, and ensures full auditability. Consistent normalization underpins reliable downstream AI functions such as entity extraction, clause segmentation, and risk detection.
Key objectives of this stage include:
- Convert heterogeneous file formats into a standardized text representation suitable for NLP and machine learning.
- Validate document integrity and quality, flagging files that fail resolution, completeness, or encoding standards.
- Extract and enrich metadata attributes—such as document type, creation date, jurisdiction, and author—from headers and content.
- Annotate language, encoding, and structural markers (headings, tables, lists) to guide downstream parsing.
- Maintain traceability by logging transformation steps, tool versions, and corrective actions.
Prerequisites and Tooling
- Secure Repository Access: Raw files and ingestion metadata must reside in a version-controlled storage with system read/write permissions.
- Metadata Schema: A controlled vocabulary and schema defining required fields (for example, document_id, jurisdiction_code) and permitted values.
- Quality Thresholds: Minimum image resolution (300 DPI), file size limits, and UTF-8 encoding standards. Outliers are flagged for review.
- Language Configuration: Supported languages and character sets specified. Unsupported languages routed to human operators.
- Service Credentials: API keys and endpoints for OCR and extraction tools such as Amazon Textract, Google Cloud Vision, and ABBYY FlexiCapture.
- Error Handling Policies: Defined retry logic, fallback conversions, and escalation procedures for persistent failures.
Acceptable Input Formats
- Scanned Images (TIFF, JPEG, PNG) require OCR with high-resolution scans processed by services like Amazon Textract or Google Cloud Vision.
- Searchable PDFs are parsed directly when containing embedded text; otherwise OCR fallback applies.
- Word Documents (DOC, DOCX) leverage libraries that preserve semantic markup (headings, tables, lists).
- Spreadsheets (XLSX, CSV) convert tabular data into structured arrays, mapping headers to metadata fields.
- Markup Files (HTML, XML) strip irrelevant tags while retaining hierarchy and content structure.
- Email Archives (EML, MSG) extract headers, body text, and attachments, preserving cross-references for traceability.
Text Normalization Workflow Sequence
A central orchestration engine governs the text normalization pipeline, coordinating document repositories, AI services, metadata systems, human validation interfaces, and logging tools. The following sequence ensures that raw files become structured, high-quality inputs for downstream analysis.
- Workflow Initiation and Format Validation: The orchestration engine triggers upon receipt of ingestion outputs, invoking a format validation service to confirm supported file types. Non-compliant or corrupted files are routed to an exception queue.
- File Classification and Routing: A microservice inspects headers and MIME types to classify each file as native text, image-only, or mixed content, routing it to the appropriate processing stream.
- AI-Driven Text Extraction: Image-based and mixed content files are processed by OCR services such as Amazon Textract, Google Cloud Vision, or Azure Cognitive Services. Native text files proceed directly to encoding normalization.
- Layout Analysis and Structural Reconstruction: Bounding box metadata guides a layout engine—using solutions like Azure Form Recognizer or open-source frameworks combining Tesseract with custom heuristics—to identify paragraphs, headings, tables, and lists, reconstructing the document hierarchy.
- Language Detection and Encoding Standardization: Language identification services (for example, langdetect) tag primary and secondary languages at block level. Text is normalized to UTF-8, and unsupported languages trigger alerts.
- Metadata Enrichment and Tagging: Standardized metadata fields—title, author, date, jurisdiction, document type—are extracted and mapped using a metadata management service augmented by NLP libraries such as spaCy. Controlled vocabulary terms ensure consistency.
- Noise Reduction and Text Cleanup: Cleanup routines eliminate hyphenation errors, strip non-textual artifacts, normalize whitespace and punctuation, and correct common OCR misrecognitions. High-impact corrections are logged for audit.
- Quality Assessment and Human Review: Documents receive quality scores based on OCR confidence, layout success, and metadata completeness. Those meeting thresholds advance automatically; others enter a human review queue for validation.
- Exception Management: Errors—format incompatibility, timeouts, metadata conflicts—are logged centrally. Transient failures trigger retries; persistent issues generate alerts for operations teams.
- Versioning and Delivery: Original and normalized outputs are persisted in a version-controlled repository with timestamps, agents, and change logs. The final structured bundles—text payloads, metadata, quality metrics—are forwarded to extraction APIs.
AI-Driven Normalization Functions and Roles
AI services automate critical transformation tasks within the normalization pipeline, ensuring consistent quality and efficiency across large document volumes.
Character Recognition and Optical Text Extraction
OCR engines—such as ABBYY FlexiCapture, Google Cloud Vision, and Amazon Textract—detect printed and handwritten text, preserve font styles and reading order, and generate confidence scores for gating low-confidence segments.
Document Layout Analysis and Structural Segmentation
AI modules distinguish document regions—title pages, clause headers, tables, footnotes—using convolutional neural networks and visual cues. Platforms like Azure Form Recognizer and custom Tesseract-based heuristics assign semantic tags to guide targeted downstream processing.
Language Detection and Text Standardization
Automated language identification tools (for example, langdetect) evaluate text at sentence or paragraph granularity, enabling locale-aware tokenization and integration with translation services such as Amazon Translate or Azure Translator. Encodings and diacritics are normalized to Unicode standards.
Semantic Noise Reduction and Cleanup
Sequence-to-sequence models and transformer-based denoisers correct OCR artifacts, recombine hyphenated words, remove watermarks and graphic overlays, and standardize punctuation and special characters, improving input quality for NLP models.
Advanced Table, Chart, and Form Extraction
Deep learning modules in Azure Form Recognizer or Amazon Textract’s table analysis detect grid structures, infer merged cells, and extract header relationships. Embedded charts are transcribed to capture legends and axis labels. Outputs—CSV, JSON, or XML—preserve cell coordinates and semantic labels.
Metadata Alignment, Enrichment, and Validation
NLP models, including spaCy fine-tuned for legal entities, extract author names, execution dates, and jurisdiction references. Extracted values are mapped to a controlled schema, validated against business rules, and enriched with external data (for example, corporate registries).
Governance, Monitoring, and Dynamic Role Assignment
A governance layer tracks OCR confidence, segmentation accuracy, and entity extraction metrics in real time. Low-confidence outputs route to human reviewers; feedback loops retrain models. Dynamic assignment directs specialized content (multilingual or complex contracts) to expert teams, while audit logs capture every normalization event.
Normalized Outputs and Processing Handoffs
Upon completion of normalization, standardized artifacts and clear handoff mechanisms enable seamless integration with knowledge extraction components. Stringent quality controls, metadata schemas, and packaging formats ensure data integrity and auditability.
Core Output Artifacts
- Canonical Text Streams: Fully extracted text stripped of extraneous formatting, with consistent markup for paragraphs, headings, tables, and lists.
- Enriched Metadata Records: Structured fields capturing document IDs, source references, format types, language codes, and timestamps.
- Structural Tag Index: Mappings of text offsets to semantic tags—clause headers, numbered sections, signature blocks—for targeted extraction.
- Quality and Confidence Metrics: OCR confidence scores, language mismatch alerts, and tokenization error rates guiding downstream logic.
Metadata Schema and Enrichment
- Document ID: Persistent unique identifier across systems.
- Source Reference: Originating repository or feed name.
- Format and Language: Original file type and detected primary language.
- Normalization Timestamp: Completion time for audit and performance tracking.
- Checksum and Version: Cryptographic hash of text streams and version increments for lineage.
Packaging and Transmission Formats
- JSON Bundles: Nested representation of text, metadata, and tags conforming to canonical schemas.
- XML Transmissions: Schema-validated packages for legacy integrations.
- Parquet Files: Columnar structures for analytics pipelines and data warehouses.
- Database Inserts: Bulk loading into relational or NoSQL stores (for example, PostgreSQL, MongoDB).
Handoff Mechanisms
- Message Queues and Event Streams: Platforms like Apache Kafka or RabbitMQ enabling asynchronous triggers.
- Object Storage Notifications: S3 or Cloud Storage events invoking serverless functions.
- RESTful APIs: Synchronous or asynchronous endpoints accepting JSON or XML payloads.
- Shared File Systems: Network volumes with manifest files signaling readiness.
Dependencies and Downstream Integration
- Taxonomy Alignment: Metadata must conform to controlled vocabularies used by extraction models.
- Model Parameter Configuration: Language, domain, and document type parameters driven by metadata fields.
- Service Orchestration: Workflow engines such as Apache Airflow coordinating normalization and extraction tasks.
- Security Credentials: Authorized tokens or certificates required for artifact consumption.
Quality Assurance and Exception Handling
- Reprocessing Triggers: Low confidence or incomplete tag coverage flags documents for retry or human review.
- Partial Outputs: Generated when only sections normalize successfully, with error logs indicating skipped content.
- Audit Logs and Notifications: Centralized tracking of exceptions by type, frequency, and document attributes.
Security, Governance, and Compliance
- Encryption: TLS in transit and AES-256 at rest for all artifacts.
- Access Controls: Role-based permissions enforced via identity and access management.
- Retention Policies: Defined retention and secure purge schedules to meet data minimization requirements.
- Compliance Reporting: Automated generation of processing and access logs for audits.
Versioning and Audit Trail
- Immutable Versions: Each output assigned a unique version identifier tied to its checksum and parameters.
- Diff Reports: Textual change logs capturing manual corrections and reprocessing reasons.
- Audit Records: Tamper-evident logs documenting timestamps, principals, and model configurations.
By delivering standardized outputs, enforcing rigorous normalization standards, and defining clear handoff mechanisms, this stage ensures that downstream AI services receive high-quality, traceable inputs—enabling accurate entity recognition, clause mapping, and risk analysis within legal research workflows.
Chapter 3: Knowledge Extraction and Structuring
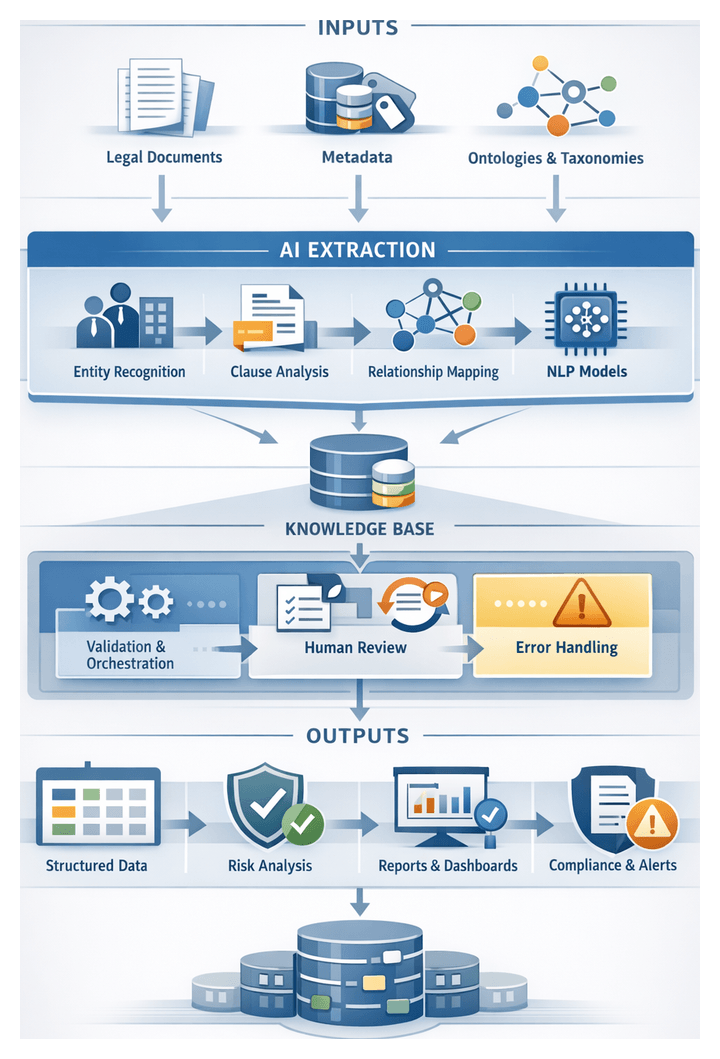
Purpose of the Extraction Stage
The extraction stage transforms unstructured legal documents into a structured, machine-readable knowledge base, enabling precise risk analysis, classification, and decision support. By isolating parties, obligations, clauses and relationships, this stage converts narrative text into discrete data elements that power downstream workflows. Key objectives include:
- Data Structuring: Parsing contracts, case law, regulations and memoranda to capture semantic relationships.
- Entity Recognition: Detecting parties, dates, monetary values, jurisdictions, statutes and other domain-specific elements.
- Clause Identification: Isolating provisions such as indemnities, termination rights, confidentiality obligations and compliance conditions.
- Relationship Mapping: Linking entities and clauses in a relational graph that models dependencies and cross-references.
- Knowledge Base Population: Feeding extracted elements into a centralized repository or knowledge graph for query, aggregation and traceability.
By automating these tasks, organizations accelerate review cycles, enhance risk detection accuracy and maintain rigorous audit trails for compliance and governance.
Inputs, Prerequisites, and System Integration
Normalized Text Artifacts
High-quality, preprocessed text forms the basis of reliable extraction. It must feature accurate character recognition with minimal OCR errors, consistent encoding and formatting, correct language segmentation, and preservation of structural elements such as headings, lists, tables and footnotes.
Enriched Metadata Sets
Metadata provides context for extraction logic and disambiguation. Essential elements include:
- Document Type (contract, regulatory text, case opinion, memorandum)
- Source and Date (creation or modification timestamps)
- Jurisdiction and Governing Law
- Version History and Revision Identifiers
- Custom Tags (department, matter type, risk level, client identifier)
Reference Ontologies and Taxonomies
Ontologies and taxonomies define the legal vocabulary and relationship schema. They comprise entity dictionaries, hierarchical taxonomies (for example Party Counterparty Subsidiary), ontology graphs modeling permissible relationships, and regulatory thesauri mapping citations to standardized identifiers.
Pretrained NLP Models and Resources
Extraction leverages both rule-based and machine-learning approaches. Required models and resources include:
- Named Entity Recognition (NER) models fine-tuned for legal entities (parties, dates, amounts, obligations).
- Clause Segmentation algorithms trained to detect headings, numbering schemes and semantic boundaries.
- Relation Extraction modules for inferring dependencies between entities and clauses.
- Lexical and Syntactic Tools such as tokenizers, part-of-speech taggers and domain-adapted embeddings.
System Connectivity and Integration Points
Seamless integration with upstream and downstream systems ensures efficient data flow and operational visibility. Key interfaces include:
- Data Ingestion APIs or file-transfer mechanisms delivering normalized text and metadata.
- Knowledge Base Endpoints for persisting entities, clause structures and relational graphs.
- Logging and Monitoring Services capturing extraction metrics and diagnostic data.
- Configuration Management for rules, model versions and resource definitions ensuring reproducibility.
Entity and Clause Extraction Workflow
Workflow Initiation and Input Validation
An orchestration engine—often schedule-driven by Apache Airflow—assigns unique identifiers to document packages containing text, token boundaries and metadata. Pre-extraction validation checks confirm text completeness, language consistency, and metadata integrity. Failed documents route to a staging area for manual review.
Orchestration and Service Coordination
A message broker such as Apache Kafka delivers document payloads to microservices or serverless functions in a decoupled pipeline. Core steps include enqueuing text and metadata, invoking NER and clause segmentation services, storing interim artifacts, and triggering human-in-the-loop reviews. Monitoring dashboards track queue depths, latencies and error rates to maintain high throughput.
Named Entity Recognition and Classification
Tokenized text is processed by legal-domain AI models, including:
- spaCy with custom contract corpora
- Hugging Face Transformers fine-tuned BERT variants
- OpenAI GPT-based endpoints for dynamic, context-aware extraction
These services return structured JSON with entity types, offsets, confidence scores and embeddings for downstream processing.
Clause Segmentation and Relationship Mapping
Parallel to NER, clause segmentation engines apply rule-based patterns and machine-learning classifiers to partition text into clauses (termination, indemnification, confidentiality, etc.). Dependency parsers and semantic role labelers map relationships such as “amends,” “refers to” or “imposes obligation on.” Interim knowledge graphs—often stored in Neo4j—capture these interdependencies for query-driven analysis.
Integration with Knowledge Graph and Repositories
Extracted entities and clauses are merged into a central knowledge graph with de-duplication, normalization of synonyms (for example Tenant = Lessee) and annotation of provenance metadata (document IDs, timestamps, model versions). This integration supports complex queries such as retrieving all confidentiality clauses involving a specific counterparty.
Human-in-the-Loop Review and Feedback
Critical extraction junctures are augmented with human review interfaces, often integrated into case management platforms. Reviewers validate or correct entity labels, clause boundaries and custom annotations. Feedback is captured to retrain models, ensuring iterative improvements and traceability of changes.
Error Handling and Dynamic Reprocessing
Low-confidence extractions or incomplete fragments trigger automated remediation workflows, which invoke fallback rule-based extractors, split large documents for targeted reprocessing, or escalate critical failures via alerting channels. Corrected artifacts are reintegrated into the knowledge graph and downstream systems are notified of updates.
Coordination with Downstream Systems
Validated outputs are dispatched to risk identification services through RESTful APIs, event notifications on Kafka topics, or bulk exports into data warehouses. Payloads include comprehensive metadata—extraction timestamps, model versions and reviewer logs—to support auditability and regulatory compliance.
Performance Monitoring, Scalability and Resource Management
Extraction throughput, latency, model accuracy and human-intervention rates are continuously tracked via dashboards. Container orchestration platforms like Kubernetes manage microservice scaling based on queue backlogs. High-speed NoSQL caches hold interim results, while long-term archives reside in cost-effective object storage.
Roles of NLP Models and Supporting Infrastructure
Model Archetypes and Extraction Roles
NLP models convert raw text into actionable data by performing:
- Named Entity Recognition identifying parties, dates, monetary values and jurisdictions using transformer-based models such as LegalBERT.
- Relation Extraction uncovering semantic links between entities with graph convolutional networks and dependency parsing.
- Clause Classification segmenting and labeling document sections via sequence classifiers.
- Semantic Similarity and Contextual Embeddings assessing meaning using embeddings from libraries like Hugging Face Transformers.
Supporting System Components
- Document Management Systems providing repositories, version control and metadata indexing.
- Message Queues and Stream Processors such as Apache Kafka for ordered delivery and parallel processing.
- Model Serving Platforms like TensorFlow Serving or ONNX Runtime for RESTful deployment with GPU acceleration.
- Knowledge Graph Databases such as Neo4j for efficient traversal of interconnected entities and clauses.
- Monitoring and Logging Systems using Prometheus and visualization dashboards to alert on accuracy drops or latency spikes.
Deployment and Integration Patterns
- Monolithic Pipeline chaining all NLP functions within a single service for simplicity.
- Microservice Architecture encapsulating each function in its own service to enable targeted scaling and independent updates.
- Hybrid Batch and Real-Time Processing combining asynchronous batch jobs for bulk ingests with low-latency inference for high-priority documents.
Data Flow and Annotation Management
Annotations follow a consistent schema capturing document IDs, character offsets, label types, confidence scores and model versions. A centralized schema registry ensures uniform definitions across services. A validation workbench allows legal analysts to correct annotations, feeding back into retraining workflows.
Scalability, Reliability and Performance Considerations
- Autoscaling clusters (Kubernetes) adjusting model-serving pods based on resource metrics.
- Load balancing across model instances with health-check driven routing.
- Model version control via DVC or MLflow for reproducibility and rollback.
- Caching of high-confidence outputs to bypass redundant inference.
Security and Compliance
- Encrypted data in transit (TLS) and at rest (AES-256).
- Role-based access controls and audit logging of API calls and model outputs.
- On-premises or hybrid deployments for data residency requirements.
- Use of platforms with SOC 2 and ISO 27001 certifications.
Roles and Responsibilities
- Data Engineers building pipelines, managing schemas and orchestrating workflows.
- Machine Learning Engineers fine-tuning models, optimizing inference and managing versioning.
- Legal SME Analysts defining taxonomies, reviewing outputs and guiding training data selection.
- DevOps Teams maintaining infrastructure, monitoring health and enforcing security.
- Project Managers coordinating cross-functional efforts and aligning with legal objectives.
Structured Knowledge Outputs and Handoff
Entity Tables and Attribute Profiles
Entity tables enumerate extracted concepts—counter-parties, jurisdictions, statutes, values, dates and renewal terms. Columns capture entity type, canonical name, document IDs, character offsets, confidence scores and normalization links. These tables enable rapid filtering, aggregation and risk engine queries.
Clause and Obligation Mappings
Clause mappings record identifiers, taxonomy labels, text spans, associated entities and hierarchical context. Obligation mappings link parties to actions and deadlines, specifying scope, notice periods and potential financial impact for risk scoring.
Relationship and Knowledge Graphs
Property graphs or RDF models represent entities and clauses as nodes with edges denoting relationships like “party to contract” or “clause references statute.” Extraction tools such as spaCy and AWS Comprehend facilitate semantic relationship extraction. Knowledge graphs support multi-document queries and visual dashboards for holistic risk assessment.
Document Summaries and Anchor Points
AI drafting modules—such as OpenAI GPT or Microsoft Azure Cognitive Services—generate concise summaries with anchor points linking back to source text. Human reviewers validate these summaries to accelerate stakeholder review and exception handling.
Provenance Metadata and Audit Trail
Each artifact includes extraction timestamps, model versions, processing host identifiers and applied confidence thresholds. Audit logs capture human corrections and rule overrides, ensuring traceable pipelines for compliance and dispute resolution.
Dependencies and Quality Constraints
- Preprocessing accuracy to avoid misaligned offsets and missing metadata.
- Consistent document-level metadata for context-aware extraction.
- Regular model calibration and retraining for evolving terminology.
- Version control of models, taxonomies and business rules for consistent scoring.
- Automated validation workflows to flag low-confidence extractions.
Packaging and Data Exchange Mechanisms
- JSON or Avro bundles with schema definitions for entity tables, clause mappings and graphs.
- Graph exports in GraphML, Turtle or Neo4j Bolt protocol.
- Event streams via Kafka or RabbitMQ for real-time updates.
- RESTful APIs returning structured artifacts on demand.
- Secure file transfers (SFTP or encrypted object stores) for batch exports.
Handoff to Risk Identification and Classification
- Automated triggers initiate risk pipelines upon arrival of new data bundles.
- API-driven pulls by engines of structured data at scheduled intervals or on demand to perform classification tasks.
- Streaming integration into policy engines for near-real-time high-risk detection.
- Batch processing for bulk classification, generating risk tags and escalation flags.
Integration with Downstream Systems and Reporting
- Case Management Systems (iManage, Clio) populated with entity tables and clause mappings.
- Compliance Dashboards in Tableau or Microsoft Power BI visualizing risk graphs and metrics.
- Document Management Platforms (SharePoint, Box) enriched with anchor points and summaries.
- Reporting Engines aggregating extraction volumes, model performance and human intervention rates for continuous improvement.
Chapter 4: Risk Identification and Classification
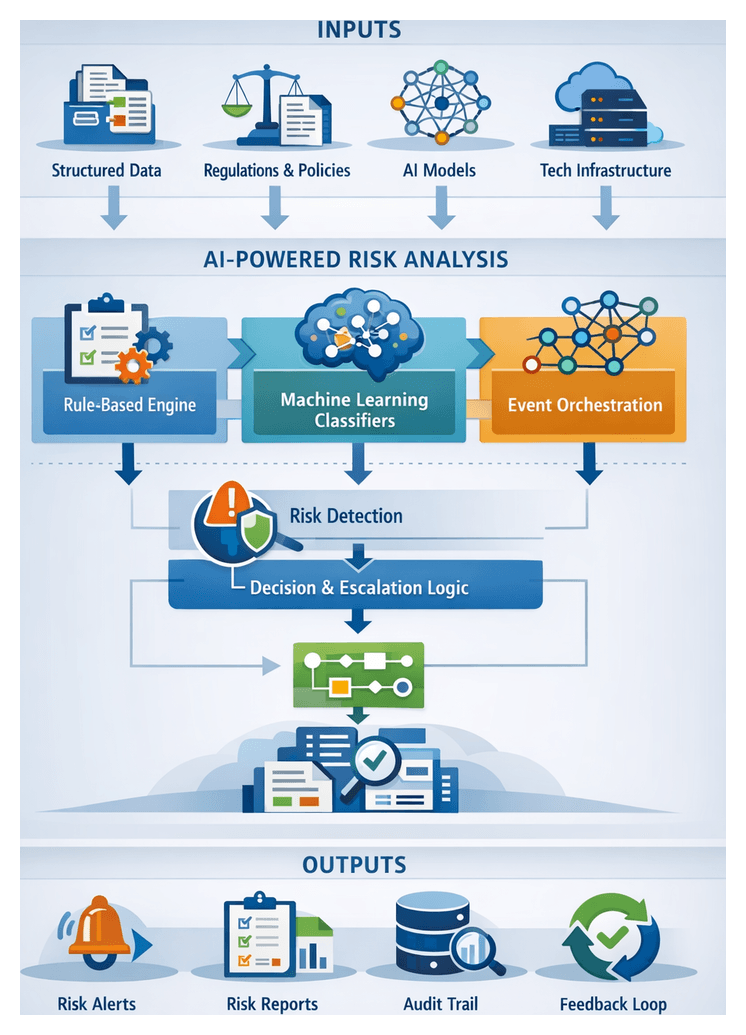
Purpose of the Risk Identification Stage
The risk identification stage transforms structured outputs from knowledge extraction into actionable risk signals. By applying rule-based logic and machine-learning classifiers, it detects compliance issues, contractual breaches and litigation triggers before they escalate. Early codification of risk enables legal teams to prioritize reviews, allocate resources efficiently and maintain an audit trail for decision support and regulatory reporting.
In high-volume, evolving regulatory environments, manual review is unsustainable. AI enhances scalability and consistency by recognising patterns across thousands of documents, freeing legal professionals to focus on validation and strategy rather than repetitive analysis.
Prerequisites and Operational Readiness
Required Inputs
- Structured Text and Metadata
- Normalized text with clause segmentation and language standardization
- Tagged metadata: jurisdiction, effective dates, counterparties, document type
- Entity relationships from knowledge extraction, covering parties, obligations and deadlines
- Regulatory and Policy Frameworks
- Libraries of statutes, industry regulations and compliance guidelines
- Internal policy rule sets and risk taxonomies
- Watchlists and sanction lists from external providers
- AI Models and Training Data
- Pretrained classifiers tuned for legal text, including transformer-based networks
- Annotated datasets of past risk assessments and remediation decisions
- Evaluation metrics and calibration parameters with defined confidence thresholds
- Technology Infrastructure
- AI platforms such as IBM Watson Discovery and Microsoft Azure Cognitive Services
- Secure storage, access controls and integration with case management systems
- Operational Alignment
- Defined roles for experts validating risk signals and refining rules
- Escalation protocols guiding transition to scoring and review stages
- Feedback mechanisms for capturing corrections and policy updates
Readiness Criteria
- Completion of data ingestion, preprocessing and knowledge extraction with audit logs
- Approval of risk taxonomies detailing financial, regulatory, reputational and operational categories
- Configuration of rule engines and ML endpoints with error-handling logic
- Stakeholder sign-off on escalation workflows and notification channels
- Periodic reviews of integration stability, model accuracy and policy alignment
Meeting these conditions ensures that risk identification aligns with legal operations strategy, regulatory obligations and organizational risk appetite.
Risk Detection Workflow
The risk detection workflow orchestrates AI services, rule engines, policy repositories and human interfaces to identify compliance violations and contractual deviations. An event-driven architecture leverages messaging platforms and orchestration services to maintain throughput and reliability.
Input Preparation and Event Generation
Structured outputs from knowledge extraction—delivered as JSON or database records—trigger the workflow via an event bus such as Apache Kafka. Components then:
- Validate payload schema completeness
- Enrich events with provenance, timestamps and processing lineage
- Route to orchestration engines like Camunda or AWS Step Functions
Rule-Based Trigger Evaluation
Deterministic rules in engines such as Open Policy Agent enforce corporate and regulatory policies. Examples include:
- Absence or modification of indemnity clauses in high-value contracts
- Expired regulatory references in jurisdiction-specific agreements
- Performance milestone deadlines at risk
Rule violations emit signals tagged with policy identifiers, severity levels and recommendation codes for classification or direct escalation.
Machine-Learning Risk Classification
Parallel to rules, ML classifiers detect nuanced risk patterns. Services may include OpenAI GPT-based classifiers or AWS Comprehend. The process involves:
- Feature extraction from entity tables, combining contract values, party risk profiles and external data
- Model inference via RESTful APIs, returning probability scores for categories like financial exposure or reputational damage
- Aggregation of rule-based signals and model outputs into unified risk vectors with confidence metadata
Decision Logic and Escalation Pathways
Orchestration engines apply decision-tree logic to consolidated signals:
- High-severity rule triggers escalate to senior counsel
- ML confidence above thresholds (for example, 0.85) generates automated alerts via YouTrack or Microsoft Teams
- Medium risks create tasks in systems like iManage or Clio
- Low-risk signals log to repositories for periodic review
Human Review and Feedback Loop
Flagged items enter review queues where analysts can validate or override AI classifications, annotate remediation plans and approve or reclassify risks. Feedback events feed continuous learning pipelines to refine models and rules over time.
Integration with Compliance Repositories
APIs to platforms such as LexisNexis and Westlaw Edge verify regulatory references and enrich signals with case law. Updates from external sources refresh policy engines and rule bases to reflect the latest legal developments.
Audit Trail and Logging
Each decision point logs timestamps, services invoked, rule and model identifiers and user actions. Centralized logging with the ELK stack or Splunk supports regulatory audits, forensic analysis and operational monitoring.
Scalability and Parallel Processing
To process large document volumes, tasks are sharded by type or jurisdiction and distributed across compute clusters or serverless functions. Autoscaling inference clusters and batch processing off-peak workloads maintain performance under variable demand.
Continuous Improvement and Versioning
Updates to rules, models and workflow logic undergo version control and testing in staging environments. Automated validation ensures that new versions maintain or improve accuracy without disrupting operations.
AI Classification Capabilities
AI-driven classification applies supervised learning, natural language processing, rule engines and knowledge graph integration to convert raw legal text into explainable risk categories.
Supervised Learning Models
- Training Data Management harnesses expert-annotated datasets to train classifiers balancing common and rare risk types
- Feature Engineering uses embeddings from TensorFlow or PyTorch to represent syntactic and semantic patterns
- Model Architectures include transformer-based classifiers (BERT, RoBERTa) and gradient-boosted trees for interpretability
- Continuous Retraining integrates user feedback and data versioning for iterative model updates
Natural Language Processing and Semantic Understanding
- Contextual Embeddings capture term meanings in context and support multilingual analysis with Google Cloud AutoML or Azure Cognitive Services
- Named Entity Recognition identifies parties, dates and values using IBM Watson Natural Language Understanding
- Semantic Role Labeling clarifies agent, action and object roles to improve risk assignment accuracy
Rule Engines and Policy Orchestration
- Deterministic Regulatory Rule Sets enforce statutes and compliance criteria
- Policy Libraries encode internal guidelines, managed via interfaces that allow legal teams to update rules
- An orchestration layer in platforms like ContractPodAi coordinates rule execution and model inference
Knowledge Graphs and Ontologies
- Ontology Management uses standards like LKIF-Core to map hierarchical legal relationships
- Graph Databases such as Neo4j store entities and relationships for rapid inference
- Semantic Enrichment links extracted entities to external reference data, augmenting risk profiles
Confidence Scoring and Explainability
- Probability Scores guide threshold-based routing and human review
- Feature Attribution employs SHAP or LIME to highlight decision drivers
- Audit Logs record inputs, model versions, rule sets and outputs for compliance
Outputs and Handoff to Scoring
The risk identification stage generates annotated documents, risk catalogs, summary matrices, alerts and validation reports, all of which feed downstream scoring and prioritization workflows.
Annotated Documents and Risk Tag Catalog
- Annotations embed risk markers with RiskType tags, clause identifiers, highlight ranges and audit metadata
- Risk tag catalogs list DocumentID, ClauseID, RiskCategory, DetectionMethod, ConfidenceScore and versioning details
Risk Summary Matrices and Alerts
- Summary matrices aggregate counts, confidence statistics, portfolio segments and trend indicators for visualization
- Real-time alerts and payloads for platforms like Microsoft Teams or Slack include critical flags and remediation recommendations
Validation and Confidence Reports
- False positive/negative counts and user override logs
- Performance metrics (precision, recall, F1 scores) and retraining recommendations
Handoff Mechanisms
- Publishing catalogs and annotations via REST APIs or event buses
- Triggering scoring workflows with DocumentID and tag references
- Supplying matrices and validation metrics for dynamic threshold calibration
- Updating matter systems with initial assessments for resource allocation
Integration Patterns, Governance and Monitoring
- Event-Driven Architecture: publish risk events on a pub/sub bus for scoring and alerting
- API-First Design: standardized REST endpoints for retrieving annotations and catalogs
- Data Contracts: strict JSON schemas or Avro contracts to enforce consistency
- Incremental Updates: delta payloads for new or changed risk tags
- Audit Trails: trace identifiers linking back to extraction and ingestion events
Governance and Traceability
- Role-Based Access Control to restrict output visibility
- Immutable logs of output generation events with model and rule versioning
- Data retention policies for archival and deletion of risk artifacts
- Encryption at rest and in transit for output data
Monitoring and Operational Metrics
- Output volumes: annotated documents and risk tags per interval
- Error rates: serialization failures and API timeouts
- Latency: from extraction completion to output availability
- Model drift indicators from validation reports
Through a comprehensive suite of outputs, rigorous governance and well-architected integration, the risk identification and classification stage establishes a reliable foundation for prioritization, research and decision support in AI-driven legal workflows.
Chapter 5: Risk Scoring and Prioritization
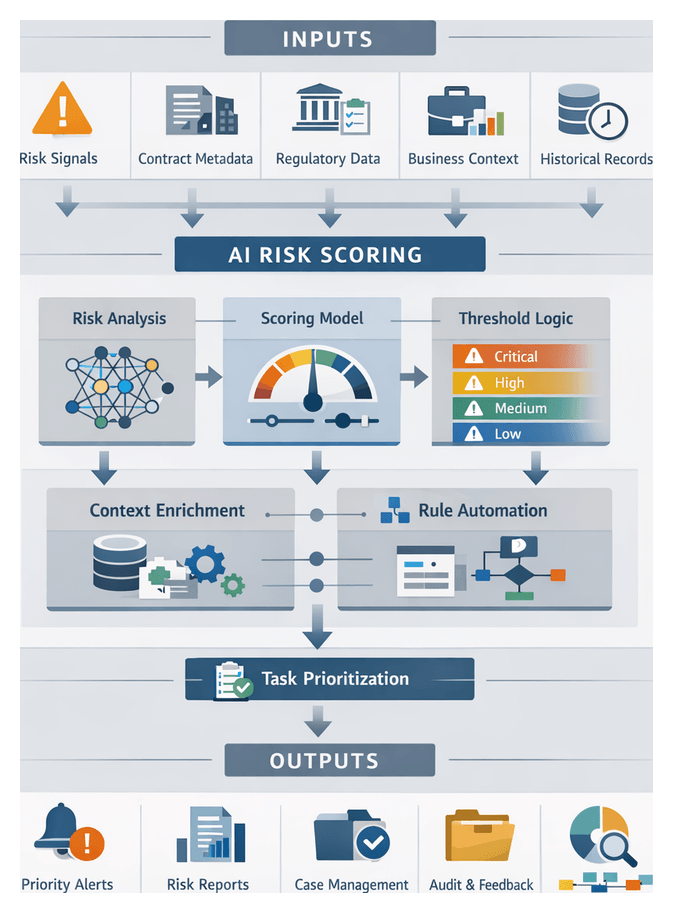
The Role of Risk Scoring in Legal Operations
Risk scoring transforms raw risk signals into standardized metrics that quantify severity, likelihood, and potential impact. This phase bridges identification and quantification, guiding legal teams to focus on the most significant exposures, align mitigation efforts with business priorities, and enable data-driven decisions. A repeatable scoring framework ensures transparency, auditability, and a defensible rationale for prioritization.
Strategically, risk scoring aggregates individual events into a holistic view of organizational exposure, informing portfolio-level assessments. Operationally, it generates prioritized worklists for review or escalation, reducing subjective judgments and inefficiencies. Adopting a structured approach delivers consistency across teams, accelerates response times, and lays the foundation for predictive analytics and trend analysis. Embedding governance controls within scoring logic ensures that legal, financial, operational, and reputational factors are accounted for in every assessment.
- Standardize disparate risk signals into unified scoring scales.
- Rank and filter risks to guide review priorities.
- Integrate business context and regulatory requirements.
- Enable transparent criteria for audit trails and compliance reporting.
- Support ongoing monitoring and dynamic risk adjustment.
Inputs and Organizational Prerequisites for Effective Scoring
Accurate risk scoring relies on high-quality inputs and robust organizational processes. The following data categories form the backbone of the scoring stage:
- Identified Risk Signals and Classifications: Risk tags such as compliance breach, contractual non-performance, and associated confidence scores from AI classifiers, each with metadata on detection rationale and initial severity indicators.
- Entity and Contractual Metadata: Counterparty details, jurisdiction, effective and expiry dates, obligation types, penalty provisions, and governance clauses for context-aware weighting.
- Business Context and Impact Factors: Transaction volumes, financial thresholds, strategic significance, and exposure limits drawn from ERP or financial systems.
- Regulatory and Policy Frameworks: Regulatory change feeds, compliance checklists, policy version histories, and audit criteria to reflect evolving legal requirements.
- Historical Data and Calibration Sets: Records of past risk events, actual loss amounts, litigation durations, and settlement figures for training and benchmark calibration.
- Model Configuration and Parameter Settings: Algorithmic features, weighting schemes, threshold definitions, calibration datasets, and governance controls for score adjustments and escalation triggers.
Technical infrastructure and organizational processes must support these inputs:
- System integrations with document repositories, case management, analytics platforms, and dashboards to ensure bidirectional data flow.
- Data quality standards, including validation routines, error handling, and metadata consistency checks.
- Security and access controls with role-based permissions, data encryption in transit and at rest, and comprehensive audit logging.
- Governance processes, such as change advisory boards, to oversee scoring model updates and enforce policy alignment.
- Cross-functional teams of data scientists, legal experts, compliance officers, and IT specialists for model development, monitoring, and refinement.
Conditions that increase the likelihood of successful deployment include:
- Pilot and validation phases on representative contract sets to benchmark performance and identify gaps.
- Cross-functional collaboration among legal operations, risk management, compliance, finance, and IT to define weighting criteria and impact factors.
- Iterative feedback loops incorporating user feedback, expert overrides, and post-mortem analyses to refine scoring parameters.
- Continuous monitoring and reporting via real-time dashboards and periodic score distribution analyses to detect drift and maintain calibration.
- Regulatory change management processes to update scoring logic in response to new laws or policy shifts.
AI-Driven Scoring and Prioritization Workflow
The prioritization workflow transforms quantitative risk scores into actionable task lists and resource assignments. By applying threshold logic, business context rules, and escalation engines, the system elevates high-impact risks for immediate attention while routing lower-level items into standard review queues.
1. Workflow Initiation
When the risk scoring engine publishes a batch of scored items, each carries metadata including document ID, risk type, score, confidence level, and timestamp. An orchestration layer—often implemented with Microsoft Azure Logic Apps—listens for completion events and dispatches items into the prioritization queue.
- Event detection via completion messages or webhooks.
- Input validation of required fields before advancing items.
- Queue insertion into a prioritized broker such as Apache Kafka or Amazon SQS.
2. Threshold Evaluation and Tier Assignment
- Fetch risk band definitions from a policy engine like PolicyManager Pro.
- Compare raw scores against numeric ranges for tiers: Critical, High, Medium, Low.
- Assign tier tags and log mapping events for auditability.
3. Business Context Enrichment
Contextual attributes are fetched from enterprise systems—CLM, ERP, CRM—to refine priorities:
- Contract value lookup from CLM databases.
- Regulatory urgency from compliance calendars.
- Historical precedent from case management archives.
- Stakeholder priority from CRM sensitivity indicators.
4. Rule-Based Adjustments and Escalation
A decision engine such as Drools applies conditional logic:
- Escalate risks tied to revenue above configurable thresholds.
- Route cybersecurity compliance risks to a “Security Review” queue.
- Flag manual override cases for supervisory review.
5. Task Generation and Resource Mapping
With final tiers and escalation flags, the orchestration layer constructs task objects containing document references, priority scores, recommended actions, and due dates. These tasks are routed into case management platforms such as Salesforce Service Cloud or Jira Service Management via REST APIs, assigning users based on skill matrices and availability.
6. Notification and Collaboration
- Immediate alerts for Critical-tier items via SMS or push.
- Daily summaries for High and Medium tiers via email or dashboard widgets.
- Weekly reports for Low-tier items to support batch reviews.
7. Human Review and Exception Handling
- Validate AI-derived tiers and contextual enrichment.
- Adjust priorities or reassign tasks based on expert judgment.
- Capture feedback on scoring and rule effectiveness.
8. Monitoring, Auditing, and Feedback Loops
- Audit logs record every decision point and user override.
- Performance metrics feed into visualization tools like Tableau or Microsoft Power BI.
- User feedback collected in-app informs rule tuning and threshold adjustments.
9. Scalable and Resilient Design
- Event-driven architecture supports decoupled parallel processing.
- Idempotent task creation prevents duplication.
- Configuration-driven thresholds and rules enable rapid adaptation.
- High availability via clustered services and automatic failover.
AI Scoring Models and System Functions
AI-driven scoring models convert identified risks into quantifiable metrics. These models, combined with system functions for deployment, monitoring, and explainability, deliver reproducible, transparent risk assessments.
Model Selection and Architectural Patterns
- Logistic regression and linear models for interpretable binary classification.
- Ensemble methods (XGBoost, LightGBM) for high predictive accuracy.
- Deep neural networks with embeddings from OpenAI or Google Cloud Natural Language.
- Transformer architectures fine-tuned via Hugging Face Transformers.
- Anomaly detection models for novel risk patterns.
Feature Engineering and Data Inputs
- Entity-level attributes from the extraction stage (termination clauses, indemnities).
- Clause metrics: length, amendment history, template deviations.
- Semantic embeddings of clause or document text.
- Historical outcomes: dispute results and litigation records.
- Business context indicators from systems like Salesforce or Oracle ERP Cloud.
- Temporal features: time-to-renewal and notice deadlines.
Model Training, Calibration, and Validation
- Data splitting with balanced representation for training, validation, and testing.
- Hyperparameter tuning via Amazon SageMaker Autopilot or Azure Machine Learning.
- k-fold cross-validation for robustness.
- Calibration techniques (Platt scaling, isotonic regression) for probability alignment.
- Performance metrics: precision, recall, ROC-AUC, Brier score.
- Bias and fairness assessments with mitigation strategies.
System Integration and Deployment
- Model as a microservice with RESTful APIs using Kubeflow or MLflow.
- Event-driven scoring triggered by Apache Kafka or AWS EventBridge.
- Serverless inference via AWS Lambda or Azure Functions.
- Batch re-scoring jobs with AWS Batch or Google Cloud Dataflow.
- Integration into platforms such as iManage or Mitratech TeamConnect.
Real-Time Inference and Orchestration
- Low-latency inference endpoints with GPU acceleration.
- Autoscaling via Kubernetes Horizontal Pod Autoscaler or AWS Application Auto Scaling.
- Workflow orchestration using Camunda or n8n.
- State management with distributed caches like Redis.
Explainability, Auditability, and Compliance
- Feature importance analysis using SHAP or LIME.
- Decision logs stored in append-only systems such as Elasticsearch or Amazon OpenSearch.
- Integration with policy engines like IBM Operational Decision Manager for automated approvals and escalations.
- User feedback loops for overrides and annotations that feed retraining pipelines.
- Regulatory reporting for SOC 2 and GDPR transparency.
Monitoring, Retraining, and Continuous Improvement
- Telemetry collection with Prometheus and Grafana.
- Drift detection to identify shifts in feature distributions or score patterns.
- Automated retraining triggers in Azure Machine Learning or Amazon SageMaker.
- Canary deployments to validate new models before full rollout.
- Governance dashboards for executive visibility into model health and recommended updates.
Output Artifacts and Resource Handoffs
The culmination of scoring and prioritization is a suite of artifacts that quantify and contextualize risks, enabling decision support and resource allocation.
Overview of Scoring Artifacts
- Scorecard reports listing risks with severity, likelihood, impact factors, and overall indices.
- Confidence intervals that communicate model certainty and guide manual validation triggers.
- Priority flags (High, Medium, Low) for rapid filtering in dashboards.
- Annotated risk profiles with extracted clauses, entities, and AI-generated explanatory notes.
Scorecard Report Structure
- Risk ID linking to the source document.
- Document reference or file path.
- Entity and clause details that generated the risk signal.
- Severity and likelihood scores.
- Composite risk index.
- Confidence interval bounds.
- Priority flag based on configured thresholds.
Handoff Mechanisms to Downstream Systems
- Case management platforms such as LegalCaseFlow receive scorecards via API or batch uploads.
- Dashboards and BI tools ingest data for interactive monitoring.
- Automated research agents trigger targeted legal research on high-priority risks.
- Alerting services dispatch email, SMS, or in-app notifications when thresholds are exceeded.
Integration Patterns
- RESTful APIs for synchronous data access.
- Message queues for asynchronous, high-throughput event delivery.
- Scheduled exports of CSV or JSON to data lakes.
- Webhooks for real-time push notifications.
Resource Allocation and Task Assignment
- Automatic task creation in matter management systems, linking to risk profiles.
- Assignment of subject-matter experts based on jurisdiction and practice area.
- Deadline and escalation pathways defined by confidence intervals and SLAs.
- Tracking of resolution status and time spent for performance analytics.
Governance, Auditability, and Continuous Improvement
All scoring outputs carry metadata references to source documents, extraction anchors, model versions, and applied policy rules to maintain full traceability. Embedded checksums and version identifiers ensure integrity, while comprehensive logging captures every API call, file transfer, and user interaction for audit readiness.
Feedback from post-mortem assessments and user corrections feeds back into the continuous learning pipeline. This loop enables periodic retraining, threshold adjustments, and rule tuning, driving ongoing optimization of the risk scoring and prioritization framework.
Chapter 6: Automated Legal Research
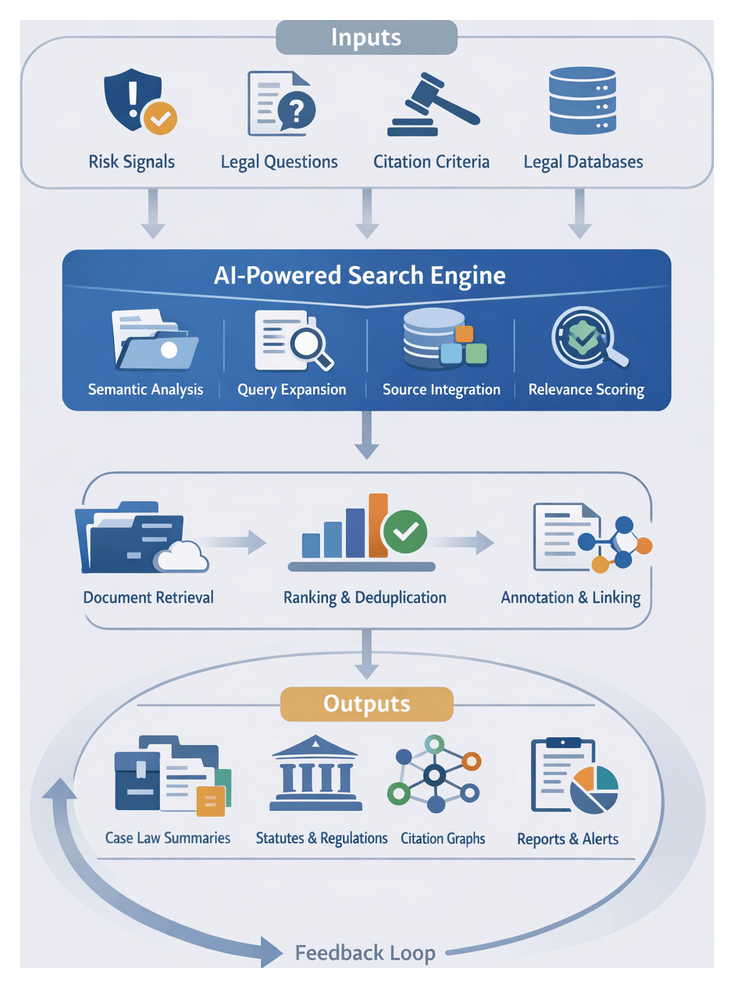
The automated legal research stage transforms identified risk signals, contractual inquiries, and compliance requirements into precise, AI-optimized searches that deliver comprehensive, accurate, and contextually relevant authorities. By leveraging semantic search, natural language understanding, and relevance scoring, this stage accelerates inquiry resolution, reduces manual effort, and minimizes oversight. Legal teams gain rapid access to statutes, case law, administrative rulings, and secondary commentary aligned with the issues surfaced in preceding workflow stages. The result is more consistent, defensible analysis and faster response to emerging risks.
Required Inputs and Prerequisites
- Extracted Entities and Risk Signals: Outputs from clause and risk identification feed query refinement. Entity tags (parties, obligations, regulatory references) carry metadata—confidence scores, context snippets, jurisdictional scope.
- Defined Legal Questions: Natural language issues or structured risk identifiers provided by legal teams guide the AI in semantic parsing and query formulation.
- Citation Patterns and Precedent Criteria: Citation networks, headnote mappings, and precedence filters (for example, binding in the Second Circuit or persuasive authority from state supreme courts) shape result ranking.
- Access to Legal Databases: Credentials and API integrations for platforms such as Westlaw Edge, LexisNexis, Bloomberg Law, and Casetext CARA.
- Semantic Search Index: An up-to-date index of legal texts, maintained internally or via services, supports concept clustering, topic modeling, and jurisdictional filtering.
- Secondary Source Libraries: Treatises, practice guides, and law review articles accessible via publisher feeds or in-house repositories supplement primary authorities.
- Jurisdictional and Language Settings: Filters for federal, state, or international law and multilingual preferences ensure retrieved materials are applicable and correctly interpreted.
- Search Agent Configuration: Role definitions (semantic matcher, citation analyzer, relevancy ranker), model priorities, and fallback protocols govern agent behavior.
- Performance Benchmarks: Response time targets, throughput requirements, and error thresholds maintain service-level agreements.
- Security and Privacy Controls: Encryption, role-based access, audit logging, and compliance with GDPR, CCPA, or client policies safeguard confidential content.
Automated Search and Retrieval Workflow
Query Submission and Interpretation
Queries originate from legal professionals, risk analysts, or triggered events within matter management systems. Inputs may include natural language questions, structured risk codes, and filters for jurisdiction or document type. An orchestration service parses the payload and invokes an AI interpretation module that applies transformer-based models to:
- Classify intent (statutory analysis, case precedent, regulatory comparison)
- Extract entities (statute names, case citations, regulatory sections)
- Apply jurisdictional and date filters
Integration with services such as Microsoft Azure Cognitive Search enriches semantic understanding, ensuring nuances of legal terminology are captured.
Query Expansion and Multi-Source Coordination
A query builder maps parsed tokens to index fields across internal and external repositories. Synonyms and legal thesaurus expansions—for example, “force majeure” to “act of God”—improve recall. Domain ontologies, retrieved from knowledge graphs or solutions, surface related legal concepts and precedent patterns. The orchestration layer dispatches expanded queries in parallel to:
- Internal repositories indexed by ElasticSearch or Apache Solr
- Subscription platforms via secure API connectors to Westlaw Edge, LexisNexis, Bloomberg Law, Casetext CARA
- Regulatory portals and government feeds through RESTful interfaces
- Secondary source libraries for treatises and commentary
Connectors log requests for auditability and monitor latency to prevent bottlenecks. As results stream in, they are unified into a consolidated set.
Relevance Scoring, Deduplication, and Annotation
Retrieved documents undergo multi-stage evaluation:
- Initial Scoring applies field-weighting and keyword density algorithms.
- ML-Driven Ranking refines scores using classifiers trained on historical research, user preferences, and citation patterns.
- Citation Analysis computes authority metrics—citation counts, appellate history, jurisdictional weight—elevating controlling precedents.
A deduplication service collapses identical or near-duplicate texts by comparing checksums and content similarity. Metadata is normalized—titles, dates, jurisdictions—ensuring uniform filtering. An entity linking module then applies named entity recognition to annotate statutes, clause references, and defined terms, anchoring them to a central knowledge graph. These annotations enable instant navigation between research outputs and extracted obligations or risk signals.
Result Packaging, Delivery, and Feedback
Once scored and annotated, results are packaged into structured containers that may include:
- Paginated lists sorted by combined relevance and authority scores
- Faceted filters for jurisdiction, source type, date range, and risk category
- Previews with highlighted terms and annotated passages
- Downloadable bundles in PDF or DOCX formats
The orchestration layer emits a JSON payload for insight generation and notifies user interfaces or case management systems when results are ready. Real-time feedback loops allow users to flag irrelevant results, adjust filters, or request query refinements. These interactions inform continuous improvement of expansion and ranking models.
AI Search Agents and System Integration
AI search agents replace manual keyword searches with context-aware retrieval, combining natural language understanding, knowledge graph reasoning, and predictive relevance. Key functions include:
- Semantic Query Interpretation: Intent classification, entity disambiguation, query expansion, and contextual filtering using transformer architectures.
- Hybrid Relevance Algorithms: Machine learning models trained on prior research, rule-based heuristics prioritizing binding jurisdictions, and fusion techniques blending both approaches. User feedback—clicks, saves, manual ratings—continuously refines scoring.
- Federated Source Connectivity: Gateways for LexisNexis, Thomson Reuters Westlaw, and Casetext CARA; open access harvesters; and internal connectors to document management systems. Normalization engines unify disparate metadata into a common schema.
- Real-Time Citation Analysis: Neutrality checks for good-law status, KeyPoint extraction of pivotal passages, citation network graphing, and automated Shepardization to classify citing references as positive, negative, or cautionary.
- Workflow Integration: API-driven handoffs to case management systems like Clio and Legal Workspace, collaboration plugins for Microsoft Teams and Slack, task automation for drafting or review, and audit logging for compliance and billing.
Governance layers—performance dashboards, model review boards, data lineage logs, and security controls—ensure accuracy, transparency, and adherence to ethical and regulatory standards.
Outputs and Integration Points
The automated research stage delivers a comprehensive suite of artifacts designed for seamless integration with downstream analytics, drafting, and reporting tools:
- Structured Search Results Package: Consolidated bundle of retrieved documents with standardized metadata, delivered in JSON and human-readable PDF or Word formats.
- Annotated Case Law Summaries: NLP-generated synopses highlighting holdings, principles, and fact patterns, with hyperlinks to full-text sources.
- Statutory and Regulatory Records: Extracted provisions, amendment histories, effective dates, and regulatory notes, filterable by jurisdiction and agency.
- Precedent Maps and Citation Graphs: JSON-LD and visual diagrams illustrating relationships among authorities, showing citation direction and treatment (followed, distinguished, overruled).
- Relevance Scores and Confidence Metrics: Quantitative assessments of relevance and model certainty to prioritize review.
- Metadata and Source Lineage Reports: Audit trails documenting source platforms (Westlaw Edge, Lexis AI, Casetext CARA), retrieval timestamps, processing steps, and flags.
Dependencies and Interfaces
- Knowledge Extraction Inputs: Entity tables, clause mappings, and relational graphs from earlier stages inform query precision and linkage.
- Search Engine Connectivity: Robust API connectors to Westlaw Edge, Lexis AI, and Casetext CARA with retry logic for resilience.
- Taxonomy and Ontology Services: Domain taxonomies and knowledge graphs guide semantic expansion and relevance ranking.
- Document Repositories: Secure storage in systems like iManage or NetDocuments with real-time indexing updates.
- ML Model Registries: Versioned storage for transformer and classifier models, ensuring reproducible invocations.
- Security Frameworks: Authentication, single sign-on, token management, and role-based access controls protect sensitive data.
Data Standardization and Packaging
- Schema Compliance: JSON Schema templates define required fields, data types, and validation rules.
- Citation Normalization: Bluebook or OSCOLA formats enforced via parsing libraries to guarantee accuracy.
- Identifier Consistency: Unique URIs link authorities to central knowledge graph nodes, avoiding duplication.
- Versioning Metadata: Outputs carry tags for creation date and model version to support traceability and rollback.
Handoff to Insight Generation
- Analytics Dashboards: Ingested results and metrics enable stakeholders to filter, sort, and visualize findings in real time.
- Report Template Population: Annotated summaries, citation graphs, and extracts feed directly into document assembly engines for memoranda, briefs, and client deliverables.
- Automated Drafting APIs: Research artifacts exposed to AI drafting services that generate executive summaries, outline arguments, and annotate citations with confidence indicators.
- Task Creation and Notifications: Automatic assignment of review tasks and alerts in matter management platforms upon research completion.
- Audit Log Entries: Detailed records of handoff events, user IDs, timestamps, and data checksums for compliance and forensic analysis.
Operational Considerations and Best Practices
- Quality Assurance Reviews: Periodic audits of annotations, relevance rankings, and citation mappings by cross-functional teams to refine models and taxonomies.
- Performance Monitoring: Continuous tracking of query latency, precision/recall metrics, and API error rates with automated alerts for anomalies.
- User Feedback Loops: Embedded feedback mechanisms in research interfaces to capture corrections, missing items, or outdated citations, feeding into retraining pipelines.
- Scheduled Model Retraining: Routine updates using expanded corpora and verified feedback to improve entity recognition, citation parsing, and ranking accuracy.
- Scalability and Resilience: Containerized deployments, load-balanced gateways, and distributed indexing clusters to handle peaks in query volume without performance degradation.
- Security and Compliance: Regular penetration testing, security audits, and compliance reviews to uphold client mandates, ethics rules, and data privacy regulations.
Chapter 7: Insight Generation and Report Drafting
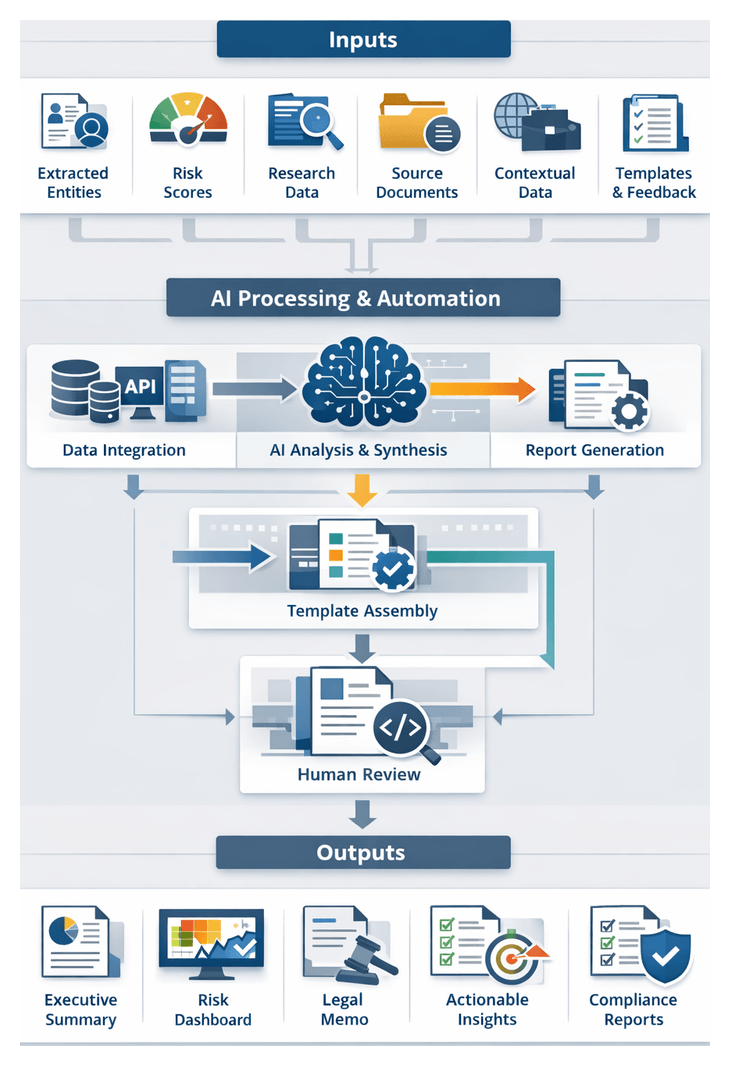
Purpose and Scope of the Reporting and Drafting Workflow
The reporting and drafting workflow transforms analytical outputs into actionable legal deliverables. By consolidating entity extraction, risk scoring, automated research and AI-generated narratives into structured reports, dashboards and memoranda, this stage delivers clarity, traceability and speed to legal decision makers. Through standardized templates, integrated AI services and human-in-the-loop review, organizations ensure that complex data converges into coherent insights supporting strategic planning, compliance and case management.
Prerequisites, Data Inputs and Integration
Before initiating report assembly, all upstream processes—document ingestion, entity and clause extraction, risk identification, scoring and research—must be complete and validated. Inputs are stored in accessible repositories with standardized naming conventions and metadata. Reporting templates, style guides and branding assets should be available, with access controls configured to enforce permissions. Integration endpoints between AI modules, document generation engines and orchestration services must be active and secured using OAuth 2.0 or API keys. Quality gates, including schema validation and confidence threshold checks, confirm completeness and accuracy of inputs.
Key Data Inputs
- Extracted Entities and Clauses: Structured tables or JSON artifacts representing parties, obligations, deadlines and references, supporting narrative sections and hyperlink navigation to source text.
- Risk Scores and Classifications: Numeric severity and likelihood values, category labels and escalation flags informing heat maps, dashboards and prioritization logic.
- Automated Research Results: Curated statutes, case law excerpts and regulatory commentary with citation metadata supplied by research engines.
- Source Documents and Metadata: Pointers to original contracts, court filings and regulatory texts, enabling traceability through embedded document references.
- Contextual Business Data: Client preferences, jurisdictional profiles and organizational risk tolerances shaping narrative tone and recommended actions.
- Templates and Style Guides: Predefined document structures, visual themes and language rules ensuring consistency and compliance.
- Reviewer Feedback and Annotations: Prior comments and change requests captured in collaboration platforms to inform iterative refinement.
Integration with AI Services
- OpenAI GPT-4 for draft narrative generation, outline proposals and executive summary suggestions.
- IBM Watson Discovery for document summarization, sentiment analysis and theme extraction.
- Google Cloud Natural Language API for entity sentiment scoring, syntax analysis and topic classification.
- Microsoft Azure Cognitive Services Text Analytics for key phrase extraction and language detection.
- Visualization connectors for Tableau and Power BI to generate interactive dashboards and heat maps.
- ContractExpress for template management and brand-compliant formatting.
Orchestrated Insight Synthesis and Drafting Flow
The workflow orchestrator retrieves and aligns data artifacts via API-driven protocols. Extracted entities and clause mappings are pulled from the knowledge graph, risk metrics from the scoring engine, and research citations from the legal research repository. Metadata alignment reconciles identifiers, timestamps and stakeholder roles, establishing a unified workspace for narrative construction.
Outline Generation and Content Structuring
- Outline Proposal: An AI summarization service applies abstractive summarization techniques to propose a hierarchical outline, including introduction, key findings, comparative analysis and recommendations.
- Section Drafting: A natural language generation module populates each section with narratives integrating entity definitions, risk annotations and precedent summaries. Transformer-based models, such as those accessed via Azure OpenAI Service, ensure human-like coherence.
- Dashboard Assembly: Visualization services compile risk heat maps, trend graphs and KPI metrics, leveraging historical data to illustrate performance trajectories.
Template Application and Document Assembly
- Template Selection: Based on report type and jurisdiction, the orchestrator selects appropriate layouts from the template repository managed by Thomson Reuters HighQ or ClauseBase.
- Drafting Engine: Populates designated fields with AI-generated text, visual assets, and automated citations. It seamlessly integrates style conventions and citation rules, utilizing tools like Westlaw Edge APIs and Lexis Advance connectors to ensure accuracy and compliance.
- Rendering: A document rendering service compiles the populated template into review-ready PDF or DOCX, embedding metadata for version control and audit logs.
Human Review and Iterative Refinement
Assembled drafts are routed to legal teams via collaboration platforms such as iManage, NetDocuments, Microsoft Teams or Slack. Reviewers validate substantive accuracy, style and compliance:
- Task Assignment: Review tasks are assigned based on role, practice area and availability. Automated notifications provide context and document links.
- Comment Capture: Reviewers annotate drafts, flag discrepancies and suggest revisions. An AI revision module ingests comments to propose edits, reducing manual rework.
- Approval Routing: Critical changes trigger additional approval steps, with escalation rules handling missed deadlines or conflicting input.
This loop continues until drafts meet predefined quality thresholds. Role-based approvals and electronic signatures ensure accountability and auditability.
Deliverables, Distribution and Handoff
Final deliverables span multiple formats, each enriched with metadata for searchability, version control and governance reporting:
- Executive Summaries: One- to two-page overviews highlighting key findings and recommended actions for senior leadership.
- Risk Dashboards: Interactive visualizations presenting quantitative risk scores, trend analyses and heat maps to support rapid prioritization.
- Annotated Memoranda: In-depth reports with embedded citations, clause references and commentary for legal review and negotiation.
- Actionable Recommendations: Bullet-point lists of next steps, responsibility assignments and timeline proposals aligned with internal protocols.
- Compliance Checklists: Itemized mappings of regulatory requirements to document provisions and risk mitigations for audit readiness.
- Custom Presentation Decks: Slide decks formatted for stakeholder briefings, combining narrative, charts and callouts.
Distribution Mechanisms
- API-Driven Transfer: Documents and metadata are delivered to case management systems such as iManage and SharePoint via RESTful endpoints.
- Secure Archiving: Final reports are stored in encrypted repositories with role-based access controls, ensuring compliance with data residency and retention policies.
- Notification Workflows: Alerts and task assignments are triggered in Microsoft Teams or Slack when deliverables are ready for review.
- Version Control and Audit Logging: Each iteration is captured in a centralized versioning service with change logs, reviewer comments and approval timestamps.
Validation, Security and Compliance Controls
To uphold accuracy, confidentiality and regulatory standards, the workflow incorporates:
- Schema and Confidence Checks: Validation rules confirm that JSON/XML artifacts conform to expected structures and flag low-confidence results for manual review.
- Data Encryption: Encryption at rest (AES-256) and in transit (TLS 1.2 ) protects sensitive information.
- Role-Based Access Control: Permissions govern viewing, editing and approving AI-generated content.
- Audit Trails: Detailed logs track report generation events, user interactions and downloads to support GDPR, HIPAA and other compliance regimes.
- Automated Redaction: Privileged or confidential information is redacted prior to distribution.
- Retention Policies: Archival or purging of artifacts aligns with organizational and regulatory requirements.
Stakeholder Roles, Collaboration and Continuous Improvement
Successful execution depends on collaboration among data analysts, legal subject matter experts, report designers, IT/DevOps, compliance officers and project managers. Feedback loops capture reviewer annotations and decision outcomes, feeding into model retraining pipelines. AI engines parse inline comments and categorize feedback to refine templates and NLG models. Dashboards track quality metrics—draft revision rates, error types and turnaround times—informing process adjustments and governance updates.
Operational Challenges and Mitigation Strategies
- Fragmented Data Sources: Consolidate inputs in a centralized data lake with consistent schemas and metadata tagging.
- Template Drift: Maintain versioned templates in source control and automate distribution to authors.
- Review Bottlenecks: Implement parallel review workflows and leverage AI-assisted suggestions to accelerate sign-off.
- Scalability Constraints: Use containerized microservices and auto-scaling clusters to manage variable loads.
- Change Management: Track revisions with audit logs and support merge capabilities for collaborative editing.
By integrating AI-driven drafting, rigorous validation, secure distribution and human expertise, this unified workflow delivers high-value insights efficiently, enabling informed legal decisions and strategic operational outcomes.
Chapter 8: Decision Support and Workflow Orchestration
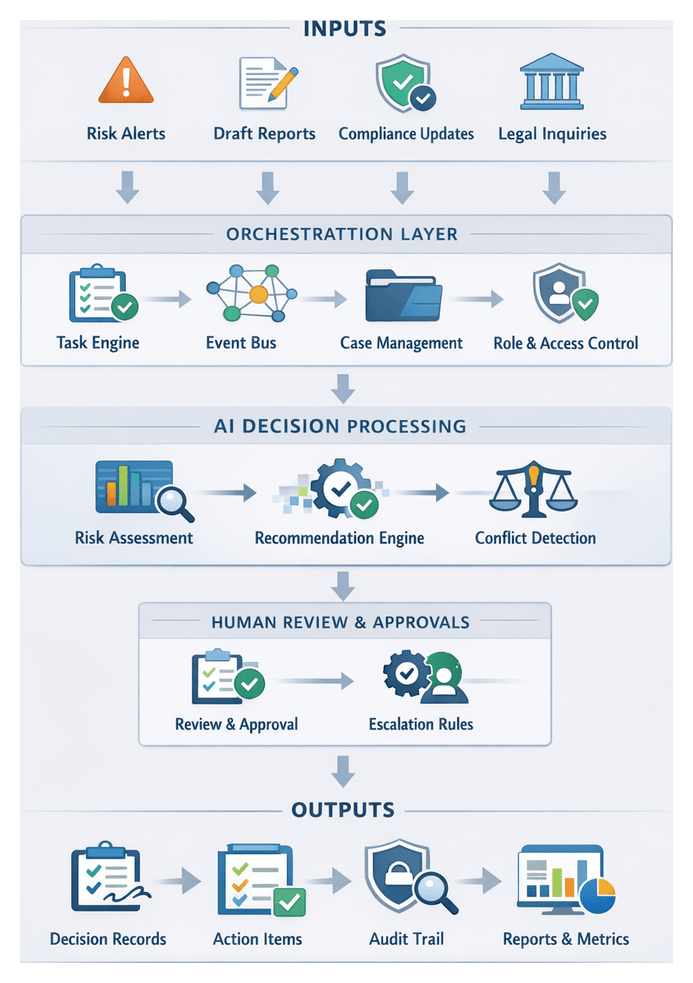
Decision Support Stage
The decision support stage bridges analytical outputs and strategic action, synthesizing risk scores, automated research, compliance alerts, and draft reports into actionable recommendations. By consolidating insights from upstream modules—such as risk identification, legal research, and compliance monitoring—this stage delivers prioritized decision triggers that align with governance policies and regulatory requirements. Its objectives are to provide clear decision thresholds, facilitate human-in-the-loop reviews, and maintain end-to-end traceability for auditability.
Successful execution depends on high-quality structured outputs, consistent metadata, and a robust orchestration layer that manages permissions, routing, and approval sequences. Automated recommendations are generated by machine learning algorithms, while manual review processes ensure oversight. Governance policies define when decisions require human sign-off or emergency escalation, and access controls enforce role-based visibility into sensitive data. Real-time system integration and performance SLAs guarantee that recommendations remain current and reliable.
Input triggers activate the decision stage automatically or via user requests. Common triggers include high-severity risk alerts indicating contractual breaches or compliance violations, completion of draft memoranda for stakeholder review, regulatory change notifications requiring reassessment, ad hoc legal inquiries, and scheduled contract renewals. Each trigger carries metadata—risk levels, affected entities, review deadlines, jurisdictional scope—that informs priority, routing, and escalation rules. A hybrid of API connections and embedded user interfaces ensures that no critical input is overlooked, while conditional logic directs items with elevated risk directly to senior counsel and streamlines routine approvals for low-risk matters.
Orchestration Workflow
The orchestration layer serves as the central nervous system of the AI-driven legal workflow, coordinating tasks across AI services, case management platforms, collaboration tools, and human reviewers. It manages task lifecycles, enforces business rules, and tracks progress against SLAs, transforming discrete outputs into coherent action items and reducing bottlenecks through parallel processing.
Key Components
- Task Engine: Creates, assigns, escalates, and completes tasks linked to cases or matters.
- Event Bus: Enables real-time messaging between AI modules and downstream systems via publish-subscribe or message queues.
- Case Management Integration: Synchronizes task statuses and logs activities in platforms such as ServiceNow and iManage.
- Role and Permissions Service: Defines user roles, access rights, and approval hierarchies.
- Monitoring Dashboard: Visualizes task throughput, bottlenecks, and compliance metrics.
- Notification System: Automates alerts and reminders through email, collaboration applications like Slack or Microsoft Teams.
Task Assignment and Routing
- Interpret Trigger Metadata: Extract risk tags, confidence scores, and document attributes.
- Match with Routing Rules: Map metadata to roles, priorities, and review paths.
- Generate Task Records: Link tasks to cases and assign responsible parties.
- Notify Assignees: Dispatch contextual notifications with direct review links.
- Monitor Acknowledgement: Reassign if tasks are unclaimed within defined time windows.
Inter-System Communication
- Publish-Subscribe: AI modules publish outputs to an event bus consumed by multiple subscribers.
- Request-Response: Synchronous API calls for on-demand data retrieval or policy checks.
- Webhook Notifications: External platforms receive HTTP callbacks for manual reviews.
- Message Queues: Ensure reliable delivery with retry logic and dead-letter handling.
These patterns support decoupled, scalable interactions and maintain workflow continuity during system failures. Error handling, fallback routes, and audit logs preserve data integrity and trace every exchange for compliance.
Automated and Manual Coordination
- Contextual Data Packaging: Task notifications include document excerpts, risk rationales, and activity logs.
- Parallel Streams: Independent review streams run concurrently where dependencies allow.
- Handoff Protocols: Defined entry and exit criteria trigger precise next steps.
- Version Control: Locking, branching, and audit trails prevent conflicting edits.
Escalation and Exception Management
- Time-Based Escalation: Unacknowledged tasks escalate to higher authorities.
- Threshold Breaches: Critical risk items override standard routing to executive review.
- Dependency Failures: Low-confidence AI results trigger manual intervention.
- Policy Violations: Workflow halts for legal counsel assessment when controls are breached.
Scalability and Security
- Microservices Deployment: Independent services scale horizontally in containers or serverless environments.
- Auto-Scaling Policies: Resources adjust based on queue length and event rates.
- Load Balancing and Monitoring: Ensure optimal throughput and SLA adherence.
- Role-Based Access Controls, TLS Encryption, Data Residency Compliance, and Immutable Audit Trails maintain confidentiality and integrity.
AI Decision Assistants
AI decision assistants translate analytical insights into consistent, accurate legal decisions by applying advanced reasoning, policy engines, and collaborative workflows. They build on ranked risk tags, research outputs, and draft reports to recommend optimal actions and facilitate human oversight.
Decision Recommendation Engines
- Ingest risk scores, extracted clauses, and entity metadata.
- Apply machine learning models trained on historical decision outcomes.
- Enforce corporate policies and jurisdictional rules via policy engines.
- Generate ranked lists of recommended actions with explanatory insights.
For example, a recommendation engine may analyze ambiguous termination provisions, cross-reference similar cases in LexisNexis Context, and propose alternative clauses ranked by projected risk reduction.
Conflict Detection and Resolution
- Scan matter metadata and relationship graphs for conflict signals.
- Cross-reference internal conflict databases in real time.
- Recommend screening protocols or engagement terms to mitigate conflicts.
- Block automated workflows until safeguards are confirmed.
Workflow Routing and Collaboration
- Analyze decision outputs and stakeholder roles.
- Match tasks to profiles based on expertise, availability, and priority.
- Generate tasks in case management or project systems, integrating with Thomson Reuters HighQ or Microsoft Power Automate.
- Send notifications and track progress through automated status updates.
- Embed decision summaries and evidence into collaboration platforms.
- Support simultaneous stakeholder review using Google Vertex AI or Amazon SageMaker microservices.
- Automate approval routing based on risk thresholds.
- Integrate electronic signature applications for rapid execution.
Human-in-the-Loop and Continuous Learning
- Present transparent rationales and capture reviewer feedback.
- Log overrides and annotations to inform model retraining.
- Feed feedback into learning pipelines hosted on platforms like IBM Watson.
- Maintain complete decision histories for audit readiness.
The modular architecture relies on a decision data lake, policy engine, microservices for recommendation, conflict detection, and routing, and an event bus that integrates with collaboration and task services. RESTful APIs and secure messaging ensure seamless data flows while preserving access controls and encryption.
Decision Outputs and Integration Handoffs
Validated recommendations and approvals are transformed into structured artifacts—decision records, action item lists, approval tokens, audit trails, and performance metrics—that feed downstream systems and continuous improvement processes.
- Decision Records: Capture rationale, risk scores, signatures, and document references in standardized schemas for content management.
- Action Items and Task Lists: Detail responsibilities, deadlines, and notes, injected into case management platforms via APIs or message queues.
- Approval Artifacts: Include e-signatures and policy engine endorsements stored in secure repositories.
- Audit Trails and Metadata: Immutable logs of triggers, approvals, user IDs, AI model versions, and confidence scores.
- Performance Reports: Dashboards formatted for Microsoft Power BI or Tableau measuring throughput, accuracy, and SLA compliance.
Key dependencies include knowledge repositories, risk scoring services, policy engines, case management systems such as ServiceNow and iManage, and collaboration tools like Slack or Microsoft Teams. Integration patterns combine:
- API-Driven Data Exchange with RESTful endpoints and role-based access control.
- Event-Driven Messaging via event buses or message queues (e.g., Apache Kafka, AWS EventBridge).
- Batch Export and Secure File Transfer for legacy systems.
- Direct Database Integration into relational or NoSQL stores.
- UI Embedding to refresh dashboards and portals with real-time decision data.
For example, upon final approval of a high-risk clause amendment, a JSON payload is delivered via API to ServiceNow, published to the corporate Kafka cluster, logged in a secure audit database, and rendered on an executive dashboard. Parallel handoffs support compliance monitoring, feeding decision events, updated watchlists, reconfiguration triggers, and audit reference IDs into the continuous monitoring layer. Approved decisions and user feedback also supply metadata—model versions, confidence scores, outcome labels—to retraining pipelines, closing the feedback loop for system optimization.
Chapter 9: Compliance Monitoring and Alerting
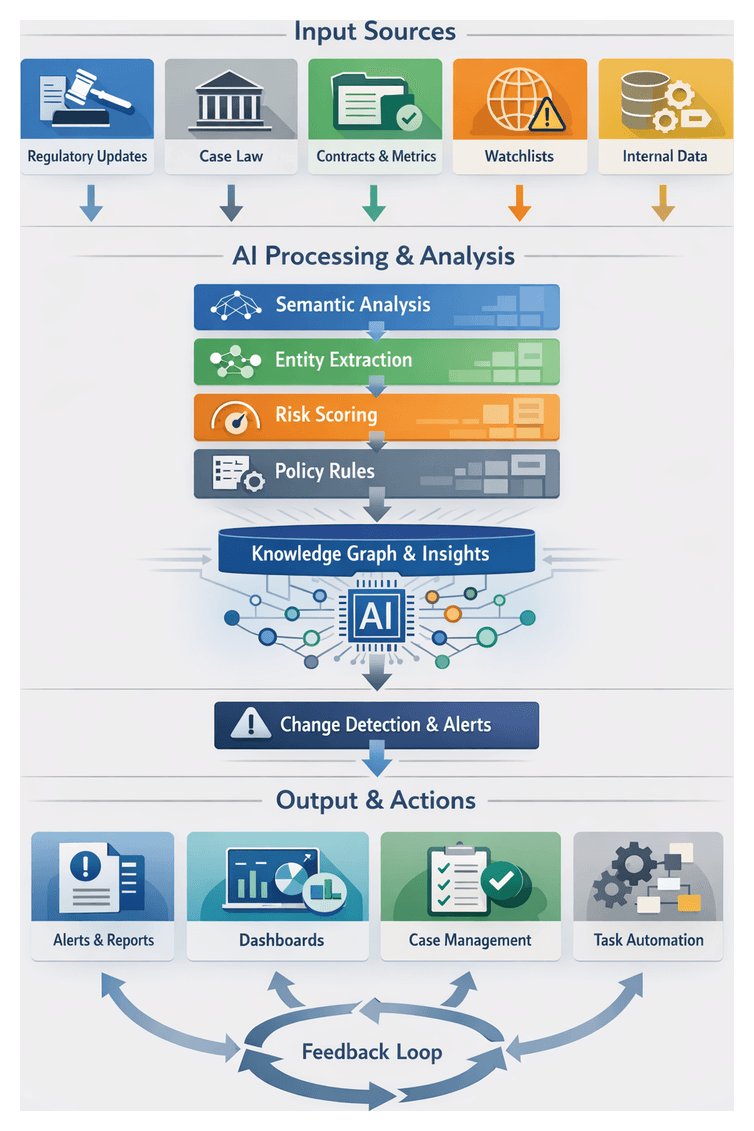
The Evolving Role of AI in Legal Research and Monitoring
Legal teams today face an unprecedented volume of contracts, regulations, and judicial opinions. Traditional manual processes struggle to keep pace with rapid regulatory changes and complex contractual landscapes. By embedding artificial intelligence into research, risk analysis, and continuous monitoring workflows, organizations shift from reactive reviews to proactive risk mitigation. AI-driven systems ingest and harmonize diverse data sources, detect changes in real time, assess material impact, and generate prioritized alerts that guide stakeholders toward timely decisions and remedial actions.
AI-Driven Research and Risk Analysis
At the core of an AI-enabled legal workflow lies the research and risk analysis stage, where advanced algorithms transform unstructured text into structured insights. AI accelerates review cycles, enhances the precision of risk evaluations, and uncovers hidden dependencies across document portfolios. Key capabilities include:
- Semantic Classification: Deep learning classifiers interpret meaning and context beyond keywords, categorizing contracts, statutes, and case law by type, jurisdiction, and regulatory domain. Solutions such as Azure Cognitive Services and Amazon Comprehend apply neural models to support targeted risk rules and downstream analytics.
- Entity and Relationship Extraction: Natural language processing pipelines identify parties, obligations, deadlines, and financial terms. Platforms like OpenAI GPT-4 and Relativity extract structured data from contracts and court opinions, while relationship mapping builds knowledge graphs that link clauses to risk scenarios.
- Predictive Risk Scoring: Machine learning models trained on historical enforcement actions and dispute outcomes assign probability scores to documents and clauses. Tools such as RAVN generate risk metrics that enable rapid triage of high-exposure items.
- Rule-Based Policy Engines: Codified regulations and firm-specific standards produce executable rules. AI-extracted data feeds into policy platforms to flag deviations—such as missing confidentiality language or obsolete jurisdiction references—in real time.
- Knowledge Graphs and Ontologies: Graph databases based on Neo4j or Amazon Neptune organize entities and relationships, revealing complex interdependencies. Users perform impact analysis by tracing how a single contractual term or statutory amendment propagates across portfolios.
- Semantic Search and Retrieval: Vector embeddings enable precise search of case law, statutes, and internal precedents. AgentLink AI’s semantic search capabilities uncover relevant references often missed by keyword queries.
- Visualization and Analytics Dashboards: Interactive dashboards present risk hotspots, amendment frequencies, and jurisdictional trends. Business intelligence integrations turn AI outputs into visual metrics that inform executive decisions.
Supporting systems such as content management platforms (iManage, NetDocuments), matter management solutions, cloud infrastructures (AWS, Azure, Google Cloud), API orchestration layers, audit logging services, and feedback platforms (Microsoft Teams, Slack) ensure data integrity, scalability, and traceability. Feedback loops capture user annotations and resolution outcomes, feeding retraining pipelines that refine model accuracy over time.
Continuous Monitoring: Inputs and Workflow
The monitoring stage operationalizes continuous oversight by ingesting diverse inputs to detect regulatory updates, contractual deviations, and emerging risk indicators in real time. By correlating signals from multiple sources, AI systems surface contextualized alerts that reflect both legal substance and organizational risk appetite. Core input categories include:
- Regulatory Feeds: Rule amendments, guidance documents, and enforcement notices from government agencies and standards bodies.
- Case Law Updates: New judicial decisions, appellate rulings, and precedential opinions from legal research services.
- Contract Performance Metrics: Milestone achievements, overdue deliverables, payment schedules, and KPIs from contract lifecycle management systems.
- External Watchlists: Sanctions lists, politically exposed persons registers, and high-risk jurisdiction databases.
- Industry News and Bulletins: Relevant articles and expert commentary signaling regulatory trends or operational risks.
- Internal Transaction Logs: Amendments filed, waiver approvals, and dispute filings that alter obligation status.
Data Ingestion and Preprocessing
An event-driven architecture underpins continuous monitoring. Data subscriptions to regulatory APIs, contract management feeds, industry clearinghouses, and legal intelligence services deliver JSON, XML, RSS, and CSV updates. Message brokers such as Apache Kafka or AWS SNS decouple ingestion from processing, ensuring resilience under load. OAuth or API key authentication secures feed access.
- Schema Alignment: Map source payloads to a canonical model with standardized field names and types.
- Metadata Enrichment: Attach jurisdiction, document type, and regulatory domain tags based on rule sets.
- Timestamp Normalization: Convert date/time values to UTC, recording ingestion meta-timestamps.
- Quality Validation: Check required fields, flag inconsistencies, and route exceptions to stewardship queues.
Preprocessing microservices ensure that downstream AI engines operate on uniform, high-quality data while preserving immutable archives of original payloads.
AI-Powered Change Detection and Policy Assessment
The heart of the monitoring workflow is the change detection engine, which compares incoming events against historical baselines. Transformer-based models, fine-tuned on legal and regulatory corpora, identify additions, deletions, and modifications at clause and paragraph levels. Named entity recognition extracts affected parties, deadlines, and obligation types. A relevance classifier scores each change for compliance impact.
- Document Version Retrieval: Fetch prior states from a versioned repository.
- Semantic Diff Analysis: Detect textual modifications with pre-trained transformer models.
- Entity and Obligation Mapping: Apply NER to capture key legal constructs.
- Risk Scoring: Combine rule-based assessments with supervised risk models to evaluate breach likelihood.
Integration with platforms enhances detection accuracy through pre-built legal models. Policy engines apply expert-defined rules to map change types to risk categories. Configurable thresholds determine whether alerts escalate immediately or await batch review.
Alert Generation and Notification
When detected changes exceed risk thresholds, the system generates structured alert objects. Each contains a concise summary, severity score, affected document identifiers, links to source materials, and recommended actions. An AI-driven language module can draft executive summaries and notification text using organization-specific templates.
- Email Dispatch: SMTP gateways deliver alerts with escalation rules for overdue acknowledgments.
- In-Platform Alerts: Case and contract management dashboards display real-time notifications.
- Collaboration Posts: Webhooks push updates to Microsoft Teams or Slack channels.
- Task Creation: Automated assignments in project management tools ensure follow-up actions.
Feedback Loop and Model Refinement
Recipients acknowledge alerts through the case management interface, triggering feedback mechanisms that record response times, resolution details, and false positive flags. Annotated feedback flows back into retraining pipelines, reducing noise and enhancing precision. Comprehensive logging captures all interactions, supporting auditability and continuous improvement.
Alert Outputs, Handoffs, and Governance
Alert outputs form the bridge between detection and remediation, producing artifacts tailored to diverse stakeholder needs. Standard output types include:
- Alert Notifications: Structured messages with unique identifiers, timestamps, risk categories, and summaries.
- Dashboard Events: Visual indicators of severity, trend analyses, and document links in compliance portals.
- Log Records: Immutable entries of raw detection data, model parameters, and processing metadata.
- API Payloads: JSON or XML packets pushed to case management, ticketing, and orchestration systems.
- Summary Reports: Aggregated alerts by risk type, jurisdiction, or contract portfolio, delivered as PDF, Excel, or HTML.
- Exception Queues: Alerts below escalation thresholds, enriched with review recommendations.
Integration with Downstream Systems
- Case Management Platforms: API-driven creation or updates of matter records with alert details.
- Ticketing Systems: Automated task generation with predefined escalation and SLA rules.
- Workflow Orchestrators: Triggered pipelines that sequence reviews, approvals, and remediation tasks.
- Collaboration Suites: Centralized discussion threads in Microsoft Teams or Slack for each alert.
- Business Intelligence Dashboards: Aggregated alert metrics and resolution timelines for executive reporting.
Roles and Responsibilities
- Compliance Officers: Validate high-severity alerts, coordinate policy updates, and liaise with regulators.
- Legal Teams: Assess contractual deviations and regulatory changes, draft remedial plans.
- Risk Managers: Prioritize alerts, allocate investigation resources, and track resolution progress.
- Operations Personnel: Execute remediation tasks, update procedures, and close cases.
- IT Administrators: Maintain integrations, monitor pipeline health, and manage security credentials.
Handoff Protocols and Performance Metrics
- Alert Generation: Assign unique identifiers and classify by severity and domain.
- Notification Dispatch: Send alerts to configured recipients and endpoints.
- Automated Case Creation: Initiate matter records for critical issues and assign owners.
- Stakeholder Acknowledgment: Track receipt confirmations via tokens or manual sign-offs.
- Task Assignment: Route follow-up actions based on metadata and expertise requirements.
- Resolution Tracking: Update status in case management at key milestones.
- Closure and Audit: Finalize cases and preserve logs for compliance reviews.
- Detection-to-Notification Latency: From event to alert dispatch, typically seconds for critical issues.
- Acknowledgment Rate: Proportion of alerts confirmed within SLA windows.
- Time-to-Assignment: Interval between alert generation and task assignment.
- Resolution Cycle Time: Duration from case creation to closure.
- False Positive Ratio: Share of non-actionable alerts, guiding threshold adjustments.
Best Practices
- Standardize Alert Taxonomy: Consistent classification of risk categories and severity levels.
- Embed Contextual Metadata: Include contract IDs, jurisdictions, and related parties for clarity.
- Implement Dynamic Routing: Adapt assignments based on workload, expertise, and location.
- Maintain Complete Audit Trails: Record every detection, notification, and resolution action.
- Iterate Thresholds Regularly: Balance sensitivity and specificity through ongoing review.
- Provide Stakeholder Training: Equip teams with guided workflows and decision support tools.
By integrating AI-driven research, real-time monitoring, and structured alert management into a unified workflow, organizations achieve continuous compliance vigilance. This dynamic capability reduces reaction times, enhances decision quality, optimizes resource deployment, and preserves audit readiness in an ever-changing legal environment.
Chapter 10: Continuous Learning and System Optimization
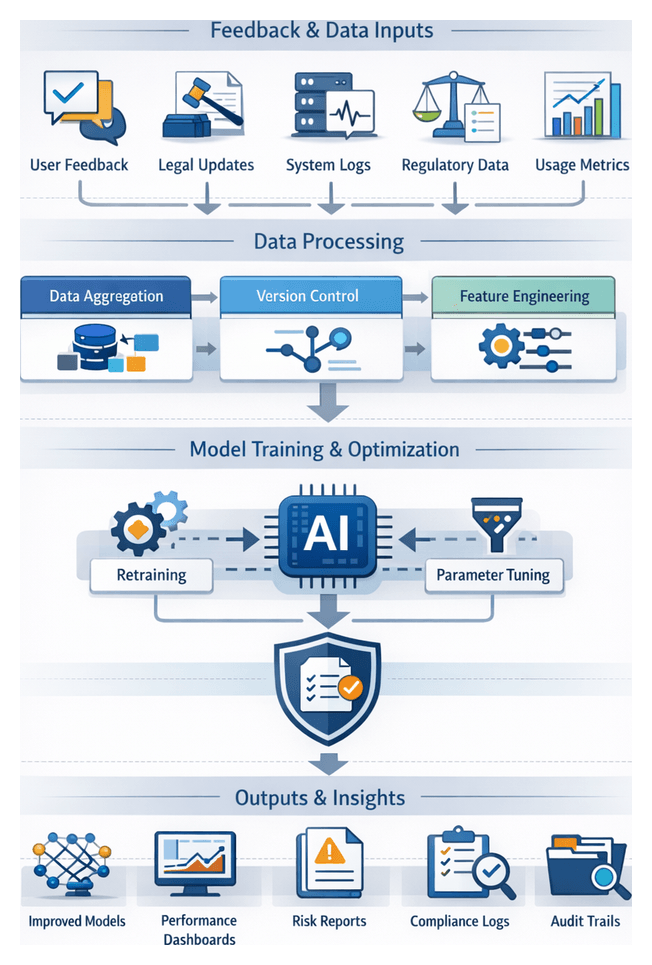
Learning Stage Purpose and Feedback Foundations
The learning stage establishes a dynamic feedback loop that transforms static AI performance into continuous adaptation. By integrating real-world corrections, usage data, regulatory updates, and system metrics, legal research and risk mitigation models evolve to maintain accuracy, reduce false positives, and address emerging patterns. This cycle prevents model decay, mitigates bias, and ensures compliance with changing statutes and organizational policies.
This stage serves three primary objectives:
- Collect structured feedback from user interactions and post-analysis reviews reflecting actual legal decisions
- Analyze performance metrics to identify underperforming models or unintended biases
- Incorporate domain and regulatory updates into retraining to align AI outputs with current legal standards
These elements create a controlled, auditable process for continuous improvement, preserving trust among legal professionals and supporting high-value insights in compliance monitoring and risk assessment.
Key feedback inputs include:
- Corrective annotations and user overrides during document review
- Post-mortem analyses of deliverables against real-world outcomes
- System performance logs measuring accuracy, latency, and user engagement
- Structured feeds of statutes, regulations, and judicial opinions
- Workflow logs capturing navigation paths and module usage patterns
Essential prerequisites encompass:
- Secure, scalable data capture and storage infrastructure with metadata tagging standards
- Governance framework defining ownership, access controls, and audit trails
- Version control and model registry to track training data snapshots and model artifacts
- Change management processes that align legal, compliance, and technology stakeholders
Iterative Optimization Workflow
The iterative optimization workflow orchestrates feedback collection, model retraining, parameter tuning, validation, and deployment in a continuous loop. Cross-functional teams collaborate to integrate improvements without disrupting ongoing operations, ensuring alignment with organizational objectives and evolving legal requirements.
Feedback Capture and Aggregation
Feedback from legal teams, automated monitors, and external feeds is aggregated into a centralized repository. Sources include annotations in case management tools, orchestration engine validation reports, regulatory update streams, and performance logs. Each feedback item is timestamped and tagged with metadata—document type, risk category, user role—to maintain traceability to specific model versions and data pipelines.
Data Ingestion and Version Control
An orchestration layer coordinates extraction, transformation, and loading of feedback into the retraining datastore. Key steps include:
- Extraction of records meeting severity or confidence thresholds
- Transformation via AI-driven tagging services that categorize feedback as false positive, false negative, or missed entity
- Loading enriched feedback alongside versioned training data and labels into the feature store
Data snapshots and transformation scripts are tracked in version control systems. Feature engineering pipelines, leveraging frameworks such as TensorFlow Extended and Dataiku, ensure consistency between offline training and online inference.
Model Retraining and Parameter Tuning
The orchestration engine triggers the retraining pipeline when feedback volumes, performance drift, or scheduled intervals dictate. Platforms like Kubeflow or Apache Airflow manage workflow dependencies, resource provisioning, and checkpointing. The process entails:
- Fetching the latest training configuration from the model registry
- Provisioning compute resources for distributed training
- Sharding data to blend new feedback-driven examples with historical corpora
- Executing training runs and collecting metrics—loss curves, precision, recall, F1 scores
- Hyperparameter optimization via grid search or Bayesian methods to fine-tune model performance
Automated logs and artifact tracking record experiment details, dataset versions, and evaluation outcomes for auditability and reproducibility.
Staging Validation and Quality Assurance
Validated model candidates are deployed to staging environments for comprehensive testing. Activities include:
- API integration tests to verify inference formats, latency, and error handling
- Use case scenario validation with representative legal documents to assess output quality
- Rule-based compliance checks to detect classification drift or regulatory conflicts
- Load testing to ensure resilience under peak ingestion and inference volumes
Staging results feed into dashboards and trigger rollback if performance falls below predefined thresholds.
Production Deployment and Monitoring
Production rollout employs canary or blue-green strategies to minimize risk. Deployment steps include:
- Containerizing the model and inference service with versioned images
- Updating orchestration descriptors to shift a portion of traffic to the new version
- Executing health checks on latency, error rates, and throughput with automated rollback triggers
- Completing full traffic migration upon successful canary validation
- Logging all deployment events in audit systems linked to version control commits
Continuous monitoring tools, including MLflow for experiment tracking and Kubeflow dashboards, detect anomalies and feed new issues back into the learning loop.
Reporting and Governance Handoff
Automated reports summarize retraining cycle insights, including performance trends, feedback distribution, resource utilization, and parameter changes. These reports are delivered to governance committees and legal operations leadership via collaboration platforms, supporting strategic decisions on model expansion, data sourcing, and workflow adjustments.
Cross-functional coordination mechanisms include sprint planning sessions, shared issue-tracking boards, regular synchronization meetings, and versioned documentation repositories. Clear ownership of tasks and standardized handoff formats ensure that improvements proceed efficiently and transparently.
Performance Outputs and Improvement Handoffs
The continuous learning stage generates a suite of artifacts that document system performance, guide enhancements, and facilitate audit and compliance reviews. Precise handoff mechanisms ensure these deliverables reach data scientists, engineers, legal analysts, and compliance officers without delay.
Performance Dashboards and Metric Reports
Interactive dashboards present accuracy, precision, recall, F1 score, drift measurements, latency, and resource utilization trends. These visualizations leverage real-time pipelines and tools like MLflow and Kubeflow, with automated alerts notifying teams when metrics breach defined thresholds.
Model Artifact Packages
Retraining cycles produce versioned model artifacts containing serialized weights, preprocessing code, configuration files, and metadata. CI/CD pipelines validate and publish these packages to model registries, enabling one-click deployment and maintaining audit trails for compliance.
Comparative Evaluation and A/B Test Analyses
Comparative reports assess performance gains and trade-offs by pitting retrained models against production baselines. A/B tests route a subset of inference traffic to new models, with statistical significance analyses guiding rollout decisions and rollback mechanisms ensuring continuity.
Data Drift and Feature Importance Reports
- Univariate and multivariate drift metrics detect shifts in input distributions
- SHAP or LIME decompositions reveal feature contributions to model decisions
These reports inform data engineering teams on preprocessing adjustments and aid risk analysts in recalibrating policy engines.
Retraining Data Sets and Feedback Aggregates
Curated data sets combine user corrections, post-mortem annotations, and newly ingested documents with standardized metadata tags. Sampling strategies balance rare and common cases, while quality checks filter noise. Data scientists access these assets via secured repositories with version control and access permissions.
Process Improvement Recommendations
Analytical insights yield recommendations for workflow enhancements, such as adjustments to routing rules, classification thresholds, or integration of new external data sources. These proposals are delivered to operations managers, legal team leads, and architecture stakeholders as blueprints for change management initiatives.
Versioned Runbooks and Deployment Playbooks
Runbooks detail step-by-step deployment, rollback protocols, and monitoring configurations. Playbooks enumerate environment settings, container image tags, and service endpoints. Stored in knowledge repositories with audit controls, they serve as authoritative references during scheduled releases or emergency interventions.
Handoff Mechanisms and Governance
Effective handoffs use automated ticketing in collaboration platforms, scheduled cross-functional reviews, and secure notifications. Each artifact references unique identifiers—model versions, experiment IDs, issue keys—to preserve traceability. Governance oversight ensures compliance, with legal operations committees reviewing outputs, approving data sets, and signing off on deployment readiness.
By producing comprehensive performance outputs and orchestrating precise handoffs, the continuous learning stage closes the optimization loop, delivering an adaptive AI workflow that evolves with data, legal requirements, and organizational priorities—safeguarding accuracy, mitigating risk, and reinforcing trust throughout the legal research lifecycle.
Conclusion

Integrated Workflow and Outcomes
The integrated AI-driven solution unifies the legal research and risk mitigation process from document ingestion to continuous monitoring. By orchestrating services such as optical character recognition, natural language processing, and predictive analytics, legal teams gain comprehensive insights, improved risk visibility, and streamlined decision support.
Key Objectives
- Establish a sequential flow of data and insights from initial intake to ongoing compliance monitoring.
- Enable metadata enrichment, entity and clause extraction, and risk scoring at each handoff.
- Validate seamless integration of AI services to maintain transparency and auditability.
- Provide a framework to assess performance, identify bottlenecks, and drive enhancements.
Integration Conditions
- High data quality through consistent metadata tagging and minimal OCR errors.
- A common taxonomy of entities, clauses, and risk categories.
- Interoperable systems connected via APIs or event-driven platforms.
- Governance controls with role-based access and approval workflows.
- Performance baselines and SLAs to monitor throughput, accuracy, and turnaround times.
- Change management for model updates and ontology refinements.
Efficiency and Proactive Risk Minimization
Efficiency gains arise from automating and parallelizing tasks across preprocessing, extraction, classification, research, and reporting. Modular components interact through well-defined interfaces, reducing latency and manual intervention.
Streamlined Execution
- Central orchestration dispatches document packages for parallel OCR, language detection, and metadata enrichment.
- Entity tables and clause graphs automatically feed risk classifiers without human handoffs.
- Real-time dashboards track throughput metrics, queue backlogs, and task status.
- Integrations with practice management tools such as iManage, collaboration suites like Microsoft Teams, and case platforms like Clio.
Proactive Risk Detection
- Immediate flagging of high-impact risks upon entity and clause extraction.
- Severity scoring to prioritize legal intervention.
- Automated research via agents querying platforms such as Westlaw and LexisNexis.
- Alerts through case management channels to ensure timely review and action.
Closed-Loop Validation
Human reviewer corrections feed back into continuous learning pipelines, enhancing model accuracy over time.
- Annotations captured alongside original context for structured feedback.
- Retraining pipelines use validated samples to update models via MLOps platforms like MLflow or Amazon SageMaker Model Registry.
- Monitoring tools such as Evidently AI and Amazon SageMaker Model Monitor detect drift and trigger retraining.
- Automated deployments maintain version control and audit trails.
Strategic Value and Collaboration
Embedding AI into legal operations transforms compliance and risk management into strategic capabilities, aligning legal activities with corporate objectives.
Compliance Assurance and Cost Efficiency
Machine learning models trained on regulatory texts and policy engines deliver continuous compliance checks. Platforms and AI assistants from OpenAI and IBM Watson surface high-value insights, reducing manual effort and lowering external counsel costs.
Data-Driven Decision Making
Dashboards aggregate risk scores, compliance statuses, and predictive analytics to forecast litigation outcomes and guide resource allocation. Integration with enterprise intelligence ensures legal metrics inform board-level strategy.
Intelligent Orchestration and Collaboration
Case management solutions assign tasks based on risk priority and expertise. Collaboration platforms present contextual summaries, reducing communication overhead and supporting cross-functional decision-making.
Scalability and Knowledge Management
The modular workflow supports multiple practice areas, from due diligence to IP management. Semantic libraries built with tools like spaCy, TensorFlow, and Hugging Face enable efficient knowledge retrieval and institutional learning.
Predictive Analytics and Integration
Forecasting models identify emerging risk trends and suggest mitigation strategies. Bi-directional APIs synchronize contract metadata and risk scores with ERP and CRM systems to enforce controls across business operations.
Adaptability, Reuse, and Future Outlook
Standardized Artifacts and Version Control
- Uniform JSON or XML schemas encapsulate document metadata and annotations.
- Entity and clause repositories stored in relational or graph databases.
- Containerized AI models with versioned configurations accessible via REST or gRPC.
- Schema registries such as Confluent Schema Registry and MLOps tools like MLflow ensure transparency.
- Container orchestration with Docker and Kubernetes Helm charts for reproducible environments.
Handoff Interfaces
- Event-driven messaging via Apache Kafka or Amazon EventBridge.
- RESTful APIs with OpenAPI specifications for synchronous data retrieval.
- Webhook notifications to trigger downstream processes.
- Shared data stores supporting versioned queries alongside practice-specific datasets.
Extending to New Practice Areas
- Define domain taxonomy and collaborate with subject matter experts.
- Augment training data with annotated examples using Prodigy or Labelbox.
- Fine-tune models with transfer learning and update semantic indexes.
- Pilot and A/B test to validate performance against KPIs.
Continuous Integration and Compliance
- Automated testing pipelines for data transformations and end-to-end workflows.
- Blue-green and canary deployments for safe rollouts.
- Governance with role-based access, audit logs, data encryption, and model explainability via SHAP or LIME.
- Alignment with regulations such as GDPR through versioned policies and documented model assumptions.
Future Projections
- Generative AI assistants for contract drafting and negotiation support.
- Multilingual NLP for global matters leveraging Hugging Face and translation services.
- Blockchain integration for digital signatures and audit trails.
- Advanced analytics with interactive visualizations of risk interdependencies.
By architecting a modular, AI-driven workflow with standardized outputs, transparent dependencies, and flexible interfaces, organizations achieve rapid adaptation, sustained innovation, and strategic leadership in legal operations.
Appendix

Terminology Overview
We define core concepts for an AI-driven legal research and risk mitigation workflow to ensure clarity across teams.
- A workflow is a structured sequence of stages—data ingestion, preprocessing, knowledge extraction, risk identification, scoring, research, insight generation, decision support and monitoring—comprising tasks that may be automated or manual.
- Orchestration engines coordinate these tasks, managing dependencies, triggers and handoffs of standardized inputs and outputs.
- Pipelines link workflows from batch or real-time ingestion to continuous monitoring, while SLAs define performance and quality metrics.
- Bottlenecks are performance constraints requiring capacity planning.
- Document intake uses connectors to capture data from systems like iManage, SharePoint or PACER, applying OCR, metadata extraction and taxonomy-based classification.
- Preprocessing normalizes text—handling character encoding, tokenization, language detection and noise reduction—to produce clean inputs for NLP models.
- Knowledge extraction employs named entity recognition, clause segmentation, relationship mapping and knowledge graph creation to structure semantics.
- Risk identification uses rule-based and machine learning classifiers, pattern recognition and confidence scoring to label risk signals.
- Risk scoring aggregates likelihood and severity into composite metrics, calibrated against thresholds to prioritize reviews.
- Automated research leverages semantic search, citation analysis and legal intelligence agents.
- Insight generation uses summarization, natural language generation and visualization dashboards.
- Decision support combines policy engines, decision triggers and human-in-the-loop approvals to enforce compliance.
- Compliance monitoring detects regulatory or contractual changes via change detection and watchlists, issuing alerts and maintaining monitoring dashboards.
- Continuous learning addresses model drift through feedback loops, retraining, canary deployments and version control to refine performance over time.
AI Capabilities by Workflow Stage
Intake
- OCR services convert scanned images into text
- Metadata extraction identifies dates, parties and jurisdictions
- Document classification assigns contract types and matter areas
- Duplicate detection suppresses redundant content
- Language detection routes non-English documents to translation
These integrate with repositories and connectors, logging confidence scores for traceability.
Preprocessing and Text Normalization
- Advanced OCR engines preserve layouts
- Encoding normalization to UTF-8
- Language segmentation and translation
- Structural parsing of headings and lists
- Noise reduction to correct OCR errors
Knowledge Extraction
- Named Entity Recognition for parties, dates and obligations
- Clause segmentation for standard provisions
- Relation extraction between entities and clauses
- Taxonomy alignment with legal ontologies
- Knowledge graph construction for semantic queries
Risk Identification
- Rule-based engines flag policy violations
- Machine learning classifiers detect nuanced risks
- Pattern recognition for high-risk clause constructs
- Confidence scoring for routing to human review
- Policy orchestration combining rules and statistical outputs
Risk Scoring and Prioritization
- Supervised models assign numeric risk scores
- Weighting algorithms balance severity and likelihood
- Threshold logic categorizes risk tiers
- Calibration routines tune model parameters
- Dashboards visualize scoring distributions
Automated Legal Research
- Semantic search interprets query intent
- Embedding models assess document similarity
- Citation analysis ranks authorities
- Automatic summarization of key holdings
- Result de-duplication and normalization
Insight Generation and Drafting
- Natural language generation for summaries and narratives
- Template engines with dynamic data insertion
- Automated citation formatting
- Sentiment and emphasis tailoring
- Visualization of risk heat maps and KPIs
Decision Support and Orchestration
- Recommendation engines propose next steps
- Conflict detection for ethical reviews
- Role-based task routing
- Summarization for decision rationale
- Policy compliance checks
Compliance Monitoring and Alerting
- Change detection against baselines
- Semantic diffs highlight altered clauses
- Threshold-based alert generation
- Contextual alert enrichment
- Notification routing via email or case assignments
Continuous Learning and Optimization
- Active learning for low-confidence cases
- Automated data curation for retraining
- Hyperparameter optimization
- Drift detection for model monitoring
- Canary deployments and A/B testing
Practical Considerations and Edge Cases
Legacy Document Sources and Format Variations
Disparate repositories yield TIFF, WordPerfect and legacy PDFs lacking text layers or with unusual layouts. Flexible connectors, fallback OCR services such as Google Cloud Vision and ABBYY FineReader and format conversion rules normalize these inputs. Unprocessable documents are quarantined for manual review, with metadata capturing error codes.
Multilingual and Cross-Jurisdictional Scenarios
Documents combining multiple languages and legal systems require language detection via Azure Cognitive Services Text Analytics and translation through Google Cloud Translation or custom engines. Jurisdictional tagging and separate policy libraries ensure correct taxonomy and rule application, with fallbacks to human specialists for low-confidence segments.
Encrypted, Redacted, and Privileged Materials
Encrypted or password-protected files and redacted documents must be identified and routed to decryption services or flagged for human review. Privilege detection algorithms apply access controls and maintain separate storage of original privileged content, with audit logs for decryption and redaction events.
High-Volume and Burst Ingest Patterns
During due diligence or eDiscovery, elastic scaling of OCR and NLP microservices, message brokers like Apache Kafka or AWS SQS and workload prioritization ensure performance. Throttling policies and staged parallel ingestion prevent rate-limit violations and bottlenecks, monitored via dashboards.
Human-in-the-Loop Adjustments
HITL frameworks route low-confidence extractions to legal professionals through annotation interfaces. Corrections feed back into retraining pipelines and policy engines, maintaining audit trails of overrides for continuous model improvement.
Practice-Area and Regulation-Specific Adaptations
Modular configurations load practice-area taxonomies and rule sets for M&A, IP, employment law or regulated domains such as HIPAA and GDPR. Orchestration merges analyses across multiple frameworks, ensuring comprehensive coverage.
System Connectivity and Integration Failures
API timeouts, credential expirations or schema changes are handled via exponential backoff, dead-letter queues and circuit breakers. Fallback strategies use cached data or alternative providers, with monitoring dashboards tracking endpoint health and error rates.
Customization for Specialty Use Cases
Industry-specific requirements, such as royalty calculations in energy contracts using Amazon Textract for table parsing or clinical trial regulatory monitoring, leverage custom extraction models and domain taxonomies orchestrated based on matter attributes.
Scaling and Performance Edge Cases
Model serving bottlenecks are addressed through horizontal microservice scaling, model caching and workload segmentation. Large documents are chunked for asynchronous processing, with health checks triggering dynamic scaling to meet service targets.
Data Privacy, Security, and Compliance Exceptions
Dynamic access controls, encryption and automated PII detection ensure GDPR, HIPAA and cross-border compliance. Incident response workflows quarantine exposed data, alert compliance officers and trigger remediation.
Disaster Recovery and Business Continuity
Cross-region replication, multi-cloud failover and automated rerouting of ingestion queues support resilience. Regular drills validate RTO and RPO, while immutable infrastructure enables rapid recovery of containerized deployments.
AI Tools Mentioned
- ABBYY FlexiCapture is an intelligent document processing platform for automating data extraction from structured and unstructured documents. It supports high-volume ingestion and advanced layout analysis.
- ABBYY FineReader is an optical character recognition and PDF conversion tool that delivers high-precision text extraction and layout preservation for scanned documents.
- Amazon Textract is a fully managed OCR service that automatically extracts text and data from scanned documents, preserving table structures and form data.
- Amazon Comprehend is a natural language processing service that offers entity recognition, key phrase extraction, sentiment analysis, and topic modeling for unstructured text.
- AWS SageMaker provides a fully managed environment for building, training, and deploying machine learning models at scale, including support for popular frameworks like TensorFlow and PyTorch.
- AWS Lambda is a serverless compute service that runs code in response to events, enabling event-driven orchestration of AI workflows without managing infrastructure.
- AWS S3 is an object storage service used for storing raw documents, processed artifacts, and model artifacts, offering scalable and durable storage with fine-grained security controls.
- AWS EventBridge is an event bus service that routes change detection and alert events between microservices and downstream systems for real-time integration.
- AWS OpenSearch (formerly Amazon Elasticsearch Service) is a managed search and analytics engine used for indexing metadata, enabling fast search and retrieval of documents and AI outputs.
- Azure Form Recognizer is a cognitive service that extracts text, key-value pairs, and tables from forms and documents, integrating OCR with AI-driven data extraction.
- Azure Cognitive Services is a collection of AI APIs for vision, speech, language, and decision capabilities, supporting tasks such as language detection and sentiment analysis.
- Azure Logic Apps is a cloud-based workflow orchestration service that connects AI microservices, legacy systems, and third-party applications through a visual designer.
- Azure Machine Learning is an enterprise-grade service for training, deploying, and managing machine learning models, offering MLOps capabilities and automated ML.
- Azure Translator provides real-time text translation and language detection, supporting multi-language legal document processing.
- Google Cloud Document AI is a managed service that applies OCR and AI models to classify, extract, and enrich text from complex document layouts.
- Google Cloud Vision provides image analysis capabilities, including OCR for text detection in scanned images and PDF files.
- Google Cloud Natural Language API performs entity recognition, sentiment analysis, and syntactic parsing to extract meaning from text.
- Google Cloud Translation offers neural machine translation and language detection to support global legal workflows.
- IBM Watson Natural Language Understanding delivers entity extraction, keyword detection, sentiment analysis, and semantic roles tailored to domain-specific lexicons.
- IBM Watson Discovery is an AI-powered search and content analytics platform that ingests large volumes of documents for exploratory research and pattern detection.
- OpenAI GPT-4 is a large-scale language model capable of generating natural language summaries, drafting legal narratives, and performing semantic search interpretation.
- OpenAI Embeddings transform text into vector representations for semantic similarity comparisons in document retrieval workflows.
- Camunda is a workflow and decision automation platform that orchestrates AI tasks, human work items, and integration points via BPMN models.
- Apache Kafka is a distributed streaming platform used for high-throughput, low-latency event streaming between AI microservices and downstream consumers.
- RabbitMQ is a message broker that supports asynchronous communication and task queuing for scalable AI workflows.
- iManage is a document and email management system that stores official legal documents and integrates with AI pipelines for ingestion and version control.
- NetDocuments is a cloud-based document and email management service used by legal teams for secure content storage and collaboration.
- Luminance uses machine learning to accelerate contract review, offering clause clustering and anomaly detection.
- Kira Systems applies pre-trained machine learning models to extract and analyze contract provisions at scale.
- Relativity is an e-discovery platform with built-in analytics and machine learning for document review and case management.
- spaCy is an open-source NLP library with pre-trained models and customization capabilities for entity recognition and text processing.
- Hugging Face Transformers provides state-of-the-art transformer-based models for tasks such as semantic search, classification, and summarization.
- Microsoft Graph API enables integration with Microsoft 365 services, including email ingestion and metadata extraction from SharePoint and OneDrive.
- Microsoft Teams is a collaboration platform used for real-time notifications and co-review of AI-generated alerts and documents.
- Microsoft Power BI provides data visualization and dashboarding capabilities for reporting metrics and trends from AI workflows.
- Tableau is a business intelligence tool that visualizes risk data, performance metrics, and compliance dashboards.
- Clio is a cloud-based legal practice management platform that tracks matters, tasks, and integrates alerts from AI systems.
- Salesforce Service Cloud is a customer and case management system used to assign tasks and notifications based on AI-driven risk alerts.
- Westlaw Edge by Thomson Reuters offers AI-enhanced legal research, citation analysis, and case summaries.
- Lexis AI is a legal research platform incorporating AI-driven search, briefs analysis, and risk identification.
- Bloomberg Law provides legal research, news, and analytics, integrating AI for semantic search and risk alerts.
- Casetext CARA uses AI to find relevant cases and predictive research suggestions based on user-provided documents.
- DVC (Data Version Control) manages versioning of datasets and ML models, supporting reproducible retraining workflows.
- MLflow provides tools for experiment tracking, model registry, and lifecycle management in machine learning projects.
- TensorFlow is an open-source ML framework used to build and train AI models for entity extraction and classification.
- PyTorch is a deep learning framework popular for research and production model development.
- Tesseract OCR is an open-source OCR engine used for initial text extraction in document preprocessing.
- Drools is a business rule management system used to codify and execute policy-based rules for risk evaluation and alert thresholds.
- ContractPodAi is an AI-driven contract lifecycle management and enterprise legal management solution with integrated drafting and risk assessment.
- Thomson Reuters HighQ is a collaboration and workflow platform that integrates document automation and AI-driven research outputs.
- ClauseBase is a document automation engine for managing clause libraries and generating contract drafts based on structured data inputs.
Additional Context and Resources
- PACER provides bulk downloads and API access to federal court filings for automated litigation monitoring.
- Federal Register offers RSS and API feeds of U.S. government regulatory notices and rulemakings.
- European Commission EUR-Lex publishes EU law, treaties, and legislative documents via API and bulk downloads.
- OpenCorporates is a global registry of corporate entities used for data enrichment of counterparty references.
- Dow Jones Watchlists include real-time compliance and sanction lists for AML and KYC checks.
- Thomson Reuters Regulatory Intelligence provides global regulatory news and expert analysis via subscription feeds.
- Lexology aggregates legal news and articles from law firms worldwide for regulatory trend monitoring.
- Open Policy Agent is an open-source policy engine for enforcing access controls and compliance rules in cloud-native environments.
- Camunda BPMN Modeler enables design and versioning of workflow and decision models for legal process orchestration.
- Apache Airflow orchestrates complex AI and data pipelines using directed acyclic graphs (DAGs) and scheduled tasks.
- Splunk aggregates and indexes logs from AI workflows for operational monitoring and forensic analysis.
- Kibana visualizes Elasticsearch indices and performance dashboards for AI pipeline health monitoring.
- Judge Analytics Platforms such as Lex Machina provide litigation analytics and predictive insights to support case strategy.
- Regulatory Compliance Forums and Publications offer white papers, guidance documents, and best practices for deploying AI in legal operations. Examples include the International Association of Privacy Professionals (IAPP) and the Global Legal Blockchain Consortium.
The AugVation family of websites helps entrepreneurs, professionals, and teams apply AI in practical, real-world ways—through curated tools, proven workflows, and implementation-focused education. Explore the ecosystem below to find the right platform for your goals.
Ecosystem Directory
AugVation — The central hub for AI-enhanced digital products, guides, templates, and implementation toolkits.
Resource Link AI — A curated directory of AI tools, solution workflows, reviews, and practical learning resources.
Agent Link AI — AI agents and intelligent automation: orchestrated workflows, agent frameworks, and operational efficiency systems.
Business Link AI — AI for business strategy and operations: frameworks, use cases, and adoption guidance for leaders.
Content Link AI — AI-powered content creation and SEO: writing, publishing, multimedia, and scalable distribution workflows.
Design Link AI — AI for design and branding: creative tools, visual workflows, UX/UI acceleration, and design automation.
Developer Link AI — AI for builders: dev tools, APIs, frameworks, deployment strategies, and integration best practices.
Marketing Link AI — AI-driven marketing: automation, personalization, analytics, ad optimization, and performance growth.
Productivity Link AI — AI productivity systems: task efficiency, collaboration, knowledge workflows, and smarter daily execution.
Sales Link AI — AI for sales: lead generation, sales intelligence, conversation insights, CRM enhancement, and revenue optimization.
Want the fastest path? Start at AugVation to access the latest resources, then explore the rest of the ecosystem from there.