

AI Driven Automated Financial Reporting An End to End Workflow for Finance and Banking
To download this as a free PDF eBook and explore many others, please visit the AugVation webstore:
Introduction
Context and Industry Imperatives
The finance and banking sector operates under relentless pressure to deliver accurate, timely reports within stringent regulatory frameworks. Legacy systems, manual reconciliations and siloed data sources contribute to prolonged close cycles, elevated error rates and compliance risks. In this environment, an end-to-end AI-enabled reporting pipeline becomes a strategic imperative. By transforming disparate data flows into standardized, auditable outputs, institutions can accelerate decision making, meet regulatory deadlines and enhance stakeholder transparency.
Adopting a structured AI workflow addresses key operational challenges. It replaces error-prone manual tasks with automated validation checks, surfaces anomalies early and embeds continuous compliance controls. From a strategic standpoint, this approach fosters resilience against evolving regulations and market dynamics, ensuring that reporting frameworks remain adaptable, defensible and aligned with business objectives.
Structured AI-Enabled Reporting Workflows
A structured AI workflow delineates discrete stages—from data ingestion through report distribution—each governed by defined inputs, outputs and handoff protocols. This modular design isolates complexity, applies targeted AI capabilities and maintains end-to-end visibility. Core elements include orchestrators that sequence tasks, AI agents that perform specialized functions and monitoring components that enforce service-level objectives and error thresholds.
- Workflow Orchestration coordinates connectors, validation engines and natural language generation services. Platforms such as Apache Airflow trigger ingestion agents, invoke cleansing routines and manage retry logic.
- AI Agents encapsulate discrete functions—schema matching, anomaly detection, narrative synthesis—allowing individual models to be updated without disrupting the broader pipeline.
- Monitoring and Governance components capture metadata, audit logs and performance metrics to support compliance, continuous improvement and drift detection.
This structured design enforces version control, exception handling and retry policies at each stage. It prevents ad hoc interventions, promotes repeatability and satisfies audit requirements. By encapsulating AI logic into autonomous agents, finance teams gain the flexibility to retrain models, refine rule sets and integrate new data sources with minimal operational risk.
Data Ingestion: Foundation for Automation
The data ingestion layer serves as the foundational pillar of an AI-driven reporting solution. Its purpose is to gather, centralize and harmonize structured and semi-structured data streams—ranging from ERP extracts to market feeds—into a unified repository. A formalized ingestion stage eliminates manual extraction efforts, accelerates the close cycle and ensures that downstream automation operates on a complete, consistent dataset.
Key goals of the ingestion layer include:
- Establishing secure, automated connections to on-premises and cloud systems
- Ingesting batch extracts and real-time streams within defined SLAs
- Capturing metadata and lineage for auditability
- Providing an extensible framework that accommodates new sources and schema changes
Successful ingestion requires collaboration among IT, data governance and finance stakeholders to define:
- Source Inventory and Access—cataloged connection details for ERP platforms like SAP, trading systems, treasury applications and external market providers such as Bloomberg and Refinitiv; credentials managed via secure vaults under least-privilege principles.
- Connector Configurations—RESTful or SOAP APIs implemented through tools like AWS Glue or Azure Data Factory, with endpoint definitions, throttling limits and retry policies.
- File Transfers and Streams—secure FTP or object-storage transfers for flat-file exports; Apache Kafka for high-frequency market feeds.
- Reference Data—exchange rates, instrument master files and regulatory taxonomies from authoritative providers.
- Network and Security—firewalls, VPNs, TLS encryption and compliance with SOC 2, ISO 27001 or FFIEC standards.
- Metadata and Schema Registry—central repository of canonical definitions, versioning and automated schema validation.
- Governance Policies—data retention, archival rules and SLOs for freshness, volume thresholds and quality metrics.
- Infrastructure Planning—provisioned compute, storage and network capacity, with auto-scaling clusters to handle peak loads.
- Change Management—version control for connector configurations, scripts and orchestrations; formal approval processes for schema or workflow updates.
- Scheduling and Handoffs—task schedules aligned with business events; orchestration rules for dependency management and alerting.
- Stakeholder Sign-off—formal alignment on data ownership, SLAs and exception handling protocols.
By codifying these prerequisites, organizations mitigate risks from fragmented sources and ad hoc extraction methods. The resulting unified data lake or staging repository becomes the single source of truth for all automation stages, from cleansing and transformation to narrative generation and distribution.
Embedding AI Agents into the Close Cycle
AI agents—autonomous software entities powered by machine learning, rule engines and natural language capabilities—transform the financial close cycle by automating data collection, validation, analysis and narrative drafting. These digital workers collaborate with human professionals, enabling finance teams to focus on interpretive and strategic activities rather than routine data handling.
Core AI capabilities include:
- Connector Orchestration—agents configure and invoke data connectors, handle authentication and manage retries automatically.
- Schema Matching—models detect and reconcile schema mismatches when source templates change.
- Anomaly Detection—unsupervised algorithms flag outliers in trial balances and transaction streams.
- Data Validation—rule engines enforce business logic and regulatory requirements.
- Preliminary Analysis—statistical routines compute KPIs and variance reports.
- Natural Language Generation—models such as GPT-4 assemble draft commentary and variance explanations.
- Continuous Learning—feedback loops capture human corrections to refine training datasets.
Supporting systems and integration components include:
- Message Brokers—Enterprise Service Bus or Apache Kafka for reliable event routing and data distribution.
- API Gateway—secure access to external feeds and third-party data.
- Orchestration Platforms—tools like UiPath coordinate agent schedules and monitor execution statuses.
- Model Management—systems such as DataRobot for versioning, performance tracking and automated deployments.
- Metadata Repository—stores schema definitions, transformation rules and audit logs.
- Secure Data Lake—centralized storage with access controls and encryption.
Common integration patterns include:
- Event-Driven Microservices—agents subscribe to domain events (for example, “new ERP batch posted”) and execute tasks asynchronously for real-time responsiveness.
- Pipeline Orchestration—central orchestrator invokes agent services sequentially or in parallel, providing structured visibility into workflow progress.
Agents embed at multiple touchpoints within the close cycle:
- Data Ingestion—fetching raw data, detecting schema changes and normalizing formats.
- Data Cleansing—applying anomaly detection, imputing missing values and logging interventions.
- Transformation—mapping entries to chart of accounts structures using classification models.
- Analytics—batch scoring forecasting models and flagging outlier trends.
- Narrative Drafting—generating preliminary commentary based on statistical outputs.
- Compliance Checking—evaluating regulatory rules and assigning risk scores to exceptions.
- Review Facilitation—routing tasks to reviewers, tracking annotations and sending reminders.
High-Level Architecture and Component Outputs
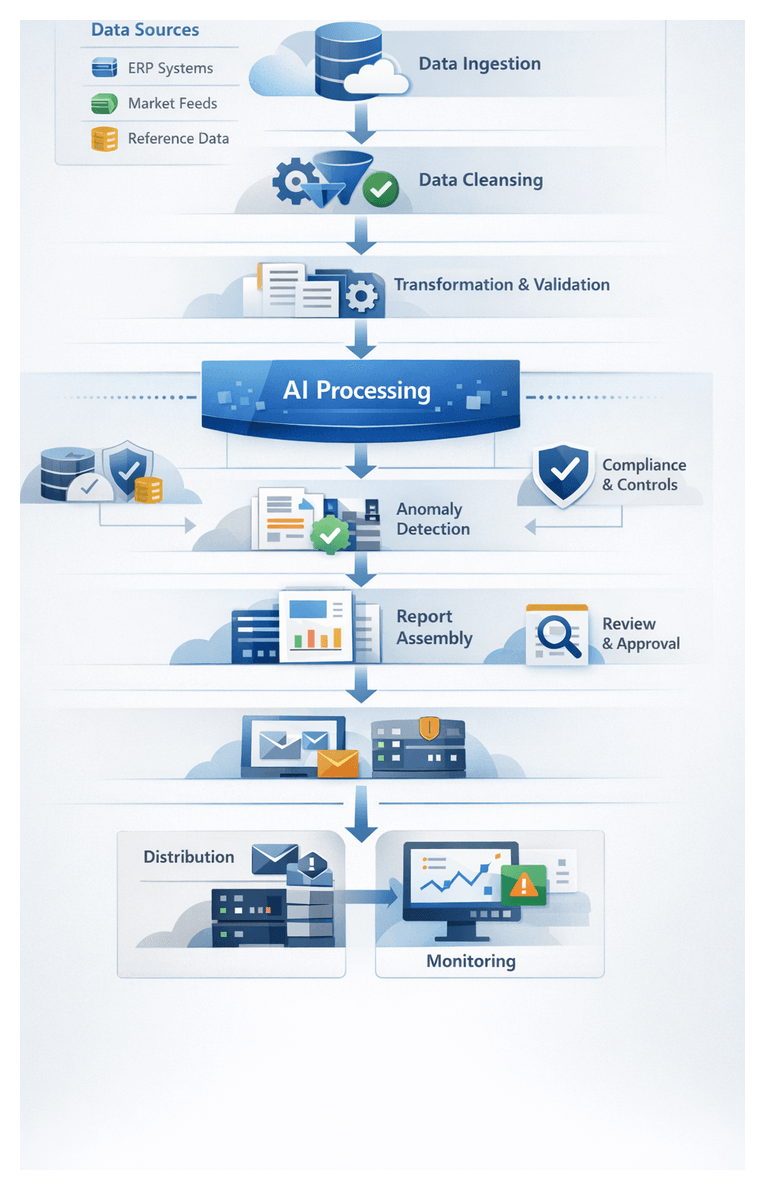
The automated reporting solution architecture integrates AI agents, traditional data stores and user interfaces into a cohesive system. At its core, this blueprint defines data flows across stages—ingestion, cleansing, transformation, analytics, narrative generation, assembly, compliance checks, review, distribution and monitoring. Each component produces well-defined outputs and relies on explicit dependencies, ensuring that handoffs maintain data integrity and context.
- Data Ingestion Layer: Output: Unified raw data snapshot combining ERP extracts, trading logs, market feeds and reference tables in a landing zone. Handoff: Populates centralized data lake or staging database and triggers the cleansing service.
- Data Cleansing Service: Output: Validated and normalized dataset with anomalies flagged. Handoff: Stores cleansed data in sandbox schema and publishes quality metrics to governance dashboard.
- Intelligent Transformation Engine: Output: Structured ledger entries aligned to chart of accounts and consolidated balances. Handoff: Writes transformed ledgers to reporting database and signals the analytics module.
- AI-Powered Analytics Module: Output: Trend analyses, variance reports, anomaly flags and forecasts. Handoff: Exposes results via RESTful endpoints for the narrative generator and dashboards.
- Natural Language Generation Service: Output: Draft narratives enriched with compliance annotations. Handoff: Delivers fragments to report assembly and archives versioned drafts.
- Report Assembly Engine: Output: Fully assembled reports (PDF, HTML, dashboards) with branding and visuals. Handoff: Publishes final reports to secure repositories and notifies review teams.
- Compliance and Risk Controls: Output: Audit logs, exception reports and risk matrices. Handoff: Feeds artifacts to review portal and archives records in an immutable ledger.
- Collaborative Review Portal: Output: Annotated report versions, reviewer comments and sign-off metadata. Handoff: Promotes approved reports to distribution module.
- Secure Distribution: Output: Encrypted report packages, secure links and delivery logs. Handoff: Delivers to recipient portals or email gateways and updates monitoring dashboard.
- Continuous Monitoring Layer: Output: Performance dashboards, model drift alerts and retraining configurations. Handoff: Triggers pipeline updates and workflow refinements via CI/CD pipelines and tools like Kubeflow Fairing.
Integration interfaces and system dependencies must be clearly defined, covering data connectivity (REST, SOAP, JDBC, SFTP), message buses (Apache Kafka), orchestration platforms (Apache Airflow), API gateways, metadata catalogs and security layers. Machine-readable interface specifications, data contracts and solution blueprints ensure transparency, facilitate collaboration and support audit activities.
By aligning component outputs with downstream needs and embedding feedback loops, the architecture supports continual improvement. Metrics and health indicators feed the monitoring layer, triggering retraining workflows or rule updates in a controlled DevOps environment. This design preserves the integrity of financial reporting processes while enabling agility in response to changing business requirements and regulatory demands.
Chapter 1: Data Ingestion and Integration
Data Ingestion Foundations
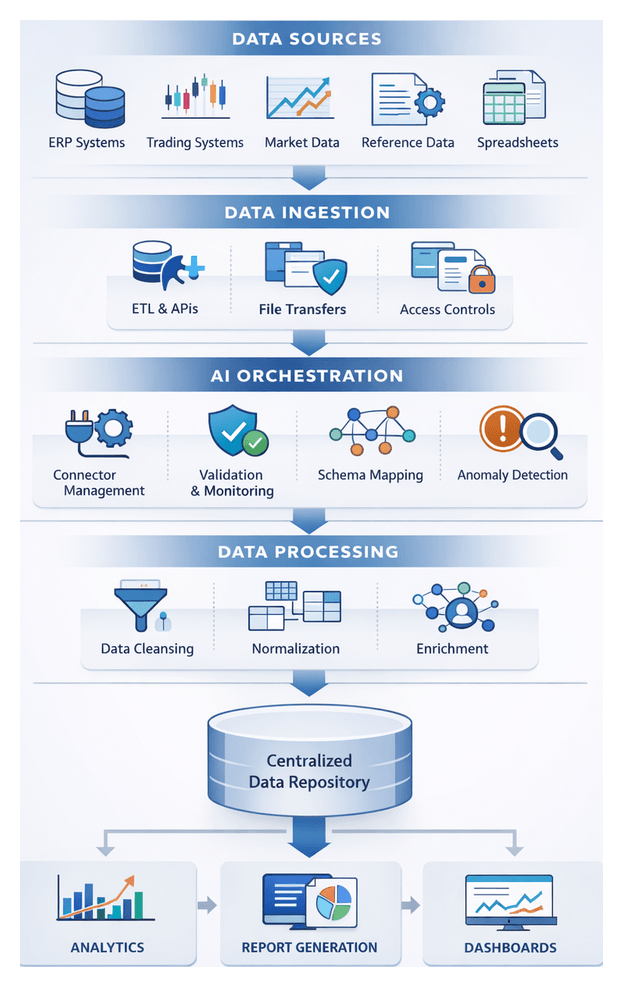
The data ingestion stage establishes the foundation for a robust, AI-driven financial reporting workflow by identifying, connecting, and consolidating disparate inputs into a unified repository. Its primary objectives are to centralize data, ensure completeness and timeliness, apply initial validation, and enforce governance and security from the outset. This orchestration accelerates downstream processes—cleansing, transformation, analytics, narrative generation, and report assembly—while minimizing manual intervention and compliance risk.
Key Data Source Types
- ERP Systems: Platforms such as SAP, Oracle Financials, and Microsoft Dynamics provide core accounting entries and ledger balances, typically accessed via native extraction utilities or REST APIs.
- Trading and Treasury Systems: Solutions like Calypso and Murex generate position files and cashflow projections, ingested via secure file transfers or specialized connectors.
- Market Data Feeds: Real-time and end-of-day price feeds from Bloomberg or Refinitiv arrive via FIX protocols, message queues, or vendor APIs.
- External Reference Data: Exchange rates, instrument master lists, and mapping tables published as CSV, XML, or JSON by third parties or regulatory bodies.
- Spreadsheets and Flat Files: Excel workbooks and text files require automated uploads, validation rules, and change-management controls.
- Unstructured Documents: PDF statements and scanned forms may be parsed by AI-driven engines to extract structured records.
Ingestion Objectives and Success Criteria
- Data Completeness: Capture all expected records, tracked by row counts and key field thresholds.
- Data Timeliness: Meet fixed close schedules and SLAs, monitoring extraction start and finish times.
- Schema Alignment: Verify column presence, data types, and field lengths before loading.
- Quality Flags: Detect nulls in key fields, invalid codes, and out-of-range amounts for review or remediation.
- Security and Access Controls: Encrypt data in transit and at rest, enforce role-based access, and maintain audit logs in line with GDPR and SOX.
Prerequisites and Conditions
- Data Access Agreements: SLAs with system owners and vendors define extraction windows and retention policies.
- Network Connectivity and Security: VPN, SSL/TLS channels, firewall configurations, certificates, and key management must be in place.
- Credential Management: Secure vaults store service accounts and API keys, with rotation policies and audit logs.
- Data Governance Framework: Documented master data definitions, taxonomies, and change-management workflows.
- Infrastructure Capacity Planning: Allocate compute, storage, and network resources to meet peak volumes.
- Monitoring and Observability: Logging frameworks, metric collectors, and alerting rules enable rapid root-cause analysis.
Role of AI Agents in Orchestration
AI-driven platforms automate connector configuration, schema discovery, and error handling. Agents monitor for schema drift, standardize field names and data types, and maintain an audit log of all ingestion activities, accelerating source onboarding and strengthening resilience against API changes.
Handoff to Downstream Processing
Upon completion, the ingestion pipeline delivers raw, structurally validated records to the cleansing stage. Change data capture markers, version tags, and run identifiers ensure traceability. Automated alerts and dashboards notify stakeholders of status, quality metrics, and any exceptions requiring review.
Orchestrating Connectors and APIs
The orchestration layer functions as the conductor of the ingestion workflow, coordinating connectors and APIs to extract, transfer, and stage data reliably and on schedule. Enterprises deploy engines such as MuleSoft Anypoint Platform or Informatica Intelligent Cloud Services, augmented by AI agents that validate configurations, detect anomalies, and trigger self-healing routines.
Connector Configuration and Scheduling
Data engineers register connectors by specifying endpoints, authentication schemes (OAuth 2.0, API keys, certificate-based TLS), extraction queries, and frequency parameters. The orchestration engine persists these definitions and generates an ingestion calendar. AI agents analyze schedules to detect overlaps and resource contention, suggesting optimizations such as staggering high-volume pulls to maximize throughput.
API Invocation and Parameterization
On schedule, the engine issues API calls or database queries, performing token retrieval, request assembly (interpolating dates, account IDs, currency codes), and payload submission over HTTPS. Responses are transformed into canonical formats (JSON-lines, Avro) and written to staging areas. AI-driven validation inspects schemas in real time, invoking fallback rules or alerts upon mismatches.
Monitoring, Logging, and Error Handling
Execution metadata—timestamps, row counts, data volumes, and performance metrics—is streamed to centralized services like Datadog or Splunk. Structured events published to Kafka or Amazon EventBridge trigger downstream tasks. Retry logic with exponential backoff handles network, authentication, or format errors, while failures beyond thresholds automatically open tickets in platforms such as ServiceNow. AI monitoring agents spot recurring issues, adjust connector parameters within guardrails, and escalate critical alerts.
Security, Authentication, and Governance
Sensitive financial data is protected by integrating with identity providers (Okta, Azure AD) to enforce role-based access. Credentials are stored in encrypted vaults like HashiCorp Vault or AWS Secrets Manager. Transport security (TLS 1.2 ) safeguards API calls, and AI-driven compliance agents verify adherence to data residency, privacy regulations, and contractual rules, quarantining non-compliant payloads for review.
Integration with Scheduling and Workflow Engines
Orchestration integrates with enterprise schedulers (Control-M, AutoSys), container platforms (Kubernetes, AWS Lambda), and workflow engines such as Apache Airflow or the AgentLinkAI Orchestration Service. AI agents coordinate across these systems to optimize resource allocation, delay or reschedule jobs during maintenance windows, and ensure end-to-end pipeline resilience.
Handoff to Normalization
Upon connector completion, the orchestration layer consolidates raw extracts into a staging repository and publishes completion events with metadata. AI-driven normalization agents detect schema mismatches and apply initial formatting rules. Dependencies recorded in the orchestration engine trigger downstream cleansing and preprocessing tasks, with automated notifications summarizing execution status and anomalies.
AI-Driven Data Collection and Normalization
Embedding AI throughout the ingestion process accelerates configuration, enhances data quality, and reduces manual intervention. AI roles focus on automating connector lifecycles, detecting schema drift, enriching metadata, and standardizing incoming records to deliver a clean, unified dataset for downstream processing.
Connector Orchestration and Self-Healing
AI-driven engines integrated with platforms like Apache Airflow and Prefect schedule connector jobs, monitor execution, and predict bottlenecks using machine learning models trained on historical metrics. Self-healing routines restart jobs, switch to fallback endpoints, or throttle requests to maintain feed continuity, alerting operations teams only when interventions exceed thresholds.
Automated Schema Detection and Field Mapping
AI models compare incoming schemas against baseline definitions, detecting added columns or type changes. Semantic similarity, historical usage, and domain ontologies guide mapping suggestions—such as aligning “trade_timestamp” with “execution_time”—which data engineers can validate, feeding corrections back to refine the model.
Semantic Enrichment and Knowledge Graph Integration
By referencing financial ontologies and domain-specific taxonomies, AI agents annotate fields with standardized descriptors—account classifications, instrument types, regulatory codes—and leverage knowledge graphs to infer relationships, ensuring each record carries both raw values and semantic context.
Anomaly Detection at Ingestion
Statistical methods and unsupervised learning detect outliers in volume, value ranges, or correlations. Suspect records—such as abnormal foreign exchange spikes—are quarantined or flagged for rapid review, preventing errors from propagating downstream.
Intelligent Prioritization and Sampling
AI agents analyze the impact of each dataset on critical reporting deliverables, allocating bandwidth and compute to high-value feeds and sampling lower-priority sources. Adaptive scheduling elevates or delays connectors in response to performance degradation, ensuring timely delivery of essential records.
Data Normalization and Standardization
Rule-based transformations and machine learning classifiers standardize units, date formats, numeric precision, and categorical labels. Currency conversions use real-time rate feeds, dates normalize to ISO 8601, and clustering algorithms group transaction types under canonical categories.
Metadata Management and Lineage Tracking
AI components capture lineage at each ingestion step, recording source systems, applied transformations, and quality checks. Centralized catalogs by Informatica or Talend recommend tags, define domains, and surface usage patterns, synchronizing technical and business metadata.
Performance Monitoring and Feedback Loops
Observability platforms equipped with AI correlate latency, error rates, and throughput with business outcomes. Feedback loops ingest user annotations and exception logs to refine anomaly thresholds, schema mappings, and prioritization heuristics over time.
Integration with Enterprise Orchestration
AI services communicate via REST APIs and event-driven architectures with platforms such as Azure Data Factory and AWS Glue, triggering upstream or downstream tasks based on real-time ingestion events, ensuring synchronized execution across connectors, normalization routines, and metadata updates.
Governance, Compliance, and Security
Policy engines enforce regulatory rules—GDPR privacy mandates, SOX controls—masking or routing sensitive data during ingestion. Continuous compliance checks generate audit logs of every decision and transformation, embedding security validation within AI agents to prevent non-compliant data from entering the reporting pipeline.
Unified Repository Architecture and Handoff
The culmination of ingestion is a centralized repository consolidating raw and normalized financial data, enriched with metadata and lineage. This authoritative store supports cleansing, transformation, analytics, narrative generation, and reporting, while providing auditability, version control, and performance optimization.
Repository Structure and Artifacts
- Raw Data Staging: Immutable copies of extracts from ERP platforms, trading systems, market feeds, and reference tables are stored in object storage like Azure Data Lake Storage or Snowflake internal stages.
- Normalized Data Domains: Core domains—general ledger entries, transaction details, currency rates, and counterparty master data—are aligned to standardized schemas via SQL, Apache Spark on Databricks, or managed pipelines in Google Cloud Dataflow.
- Metadata Catalog: Searchable definitions, field descriptions, owner contacts, ingestion timestamps, and lineage pointers reside in AWS Glue Data Catalog or open-source solutions like Apache Atlas.
Versioning and Lineage
Datasets are tagged with unique identifiers, timestamps, and checksums, while lineage platforms—such as Confluent or Pachyderm—map downstream tables to upstream raw files and transformation scripts, enabling audit-ready traceability.
Critical Upstream Dependencies
- Source System Availability: SLAs with ERP, trading engines, and market data vendors ensure extract availability and schema stability.
- Connector and API Health: Stable connectivity, valid credentials, and schema adherence are monitored by automated health checks and retry logic.
- Schema Contracts: Formal change-management workflows notify pipelines of field additions or type changes to prevent data loss.
- Security Controls: Key management, encryption certificates, and role-based permissions guarantee only authorized pipelines access repository layers.
- Network Performance: Load-balancing, compression, and incremental extraction address bandwidth demands of high-volume feeds.
Metadata-Driven Data Quality Gates
Quality gates validate record counts, field completeness, and value ranges before committing to normalized domains. AI-assisted anomaly detection flags deviations in real time, triggering exception workflows and automated correction routines. Quality metrics—null percentages, schema drift indicators, and ingestion latency—are stored in the metadata catalog for trend analysis and proactive remediation.
Handoff to Cleansing and Preprocessing
- Event Triggers: Completion events published to Apache Kafka or cloud pub/sub services include dataset identifiers, timestamps, and catalog references.
- Batch Scheduling: Workflow engines like Apache Airflow execute cleansing DAGs once all feeds arrive successfully.
- API Invocation: REST or gRPC endpoints expose schema definitions and data slices, enabling on-demand preprocessing.
- Audit Logging: Every handoff action is recorded with user and system identifiers, timestamps, and status codes in the metadata catalog.
Governance, Monitoring, and Continuous Improvement
Governance rules in the metadata catalog define retention policies and access entitlements. Monitoring dashboards track storage utilization, query performance, and data freshness, surfacing alerts for threshold breaches. Continuous improvement processes analyze ingestion metrics to refine metadata models, optimize resource allocation, and drive cost-performance balance over time.
By defining clear objectives, leveraging AI-driven orchestration, and establishing a unified repository with robust handoff protocols, finance organizations create a scalable, audit-ready foundation for end-to-end automated financial reporting.
Chapter 2: Data Cleansing and Preprocessing
Cleansing Stage Objectives and Input Requirements
The cleansing stage establishes the quality gate for automated financial reporting workflows, ensuring that all incoming data meets rigorous standards before transformation, analysis, and narrative generation. In finance and banking, where precision and regulatory compliance are paramount, undetected data issues can lead to costly misstatements and audit exceptions. This stage defines explicit data quality objectives, catalogs acceptable input types, and enforces prerequisites to mitigate risk, accelerate close cycles, and maintain confidence in reporting outputs.
Key Data Quality Objectives:
- Completeness: All required fields and records—transaction details, account identifiers, reference codes—must be present.
- Accuracy: Values must fall within valid ranges, match reference tables, and adhere to validation rules for amounts, dates, and codes.
- Consistency: Formats for dates, numbers, and text are standardized, and discrepancies across sources are resolved.
- Validity: Data types, schemas, and business rules are enforced; any violations are flagged.
- Timeliness: Timestamps and periods align with the financial close cycle; stale or future-dated entries are quarantined.
- Traceability: Lineage metadata captures source identifiers, batch timestamps, and connector logs for audit and root-cause analysis.
Input Data Types and Sources:
- General ledger and sub-ledger extracts from ERP platforms such as SAP or Oracle Financials.
- Transactional feeds from trading systems, treasury applications, and payment networks.
- Market data streams and reference rates from vendors like Bloomberg or Refinitiv.
- External benchmarks and regulatory tables: currency codes, country classifications, taxonomies.
- Supplementary metadata: source system identifiers, batch timestamps, connector logs.
- Prior-period reconciliations and audit adjustments for comparative checks.
Input Criteria and Prerequisites
Schema Conformance:
Each dataset must match centralized schema definitions—column names, data types, and record structures—registered in a schema registry. Deviations trigger alerts or quarantine for investigation.
Contextual Metadata Requirements:
- Source System Identifier: Unique code for origin application or feed.
- Batch and File Timestamps: Extraction times to support timeliness checks.
- Record-Level Lineage Tags: Correlation IDs linking entries to ingestion logs.
- Regulatory Context Flags: Indicators for jurisdictions, currency regimes, compliance boundaries.
- Processing Context Attributes: Workflow run IDs, user approvals, configuration versions.
Access and Security Preconditions:
- Secure Credentials: Validated service accounts or token-based authentication for connectors.
- Encryption-at-Rest and In-Transit: Compliance with policies and standards like PCI DSS and GDPR.
- Role-Based Access Controls: Restrict cleansing logic modifications and data exposure.
- Audit Logging: Tamper-proof records of access, modifications, and approvals.
System and Resource Availability:
- Provisioned Compute Resources: CPU, memory, and storage to handle period-end data spikes.
- Connector Health Checks: Pre-run validations of database connections, message queues, and APIs.
- Scalability Mechanisms: Autoscaling or orchestration via platforms such as Kubernetes or Apache Airflow to manage dynamic workloads.
- Disaster Recovery Paths: Fallback routines and data snapshots for system failures or network disruptions.
Best Practices for Input Preparation:
- Implement a Centralized Data Glossary using a governance tool like Collibra to standardize definitions and maintain a single source of truth.
- Automate Schema Validation with AI-driven profiling solutions to detect schema drifts before ingestion.
- Define Modular Validation Rules in reusable components to adapt quickly to regulatory changes.
- Embed Real-Time Monitoring via dashboards powered by Google Cloud Dataprep to surface data quality metrics and alert stakeholders.
- Maintain a Quarantine Framework: Secure staging area for non-conforming data with automated notifications to data stewards.
- Foster Cross-Functional Collaboration among data owners, compliance officers, and IT operations to align on input specifications and remediation responsibilities.
Intelligent Cleansing Workflow
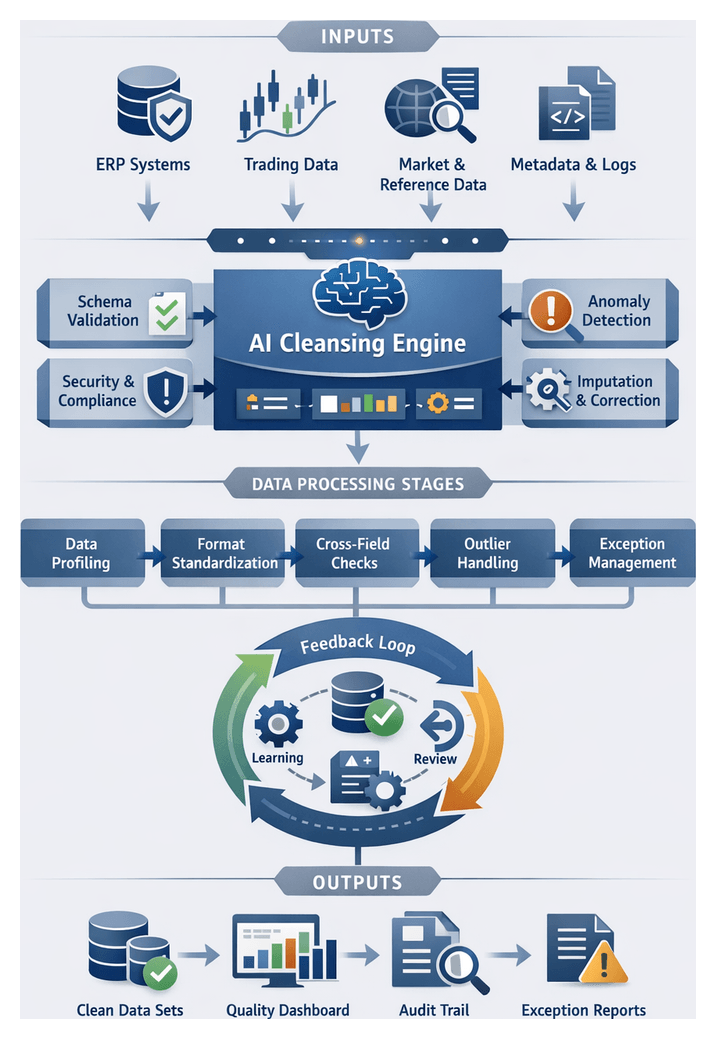
The intelligent cleansing workflow transforms raw ingested records into validated, consistency-enforced datasets ready for transformation. An orchestration engine coordinates profiling, anomaly detection, imputation, format standardization, and exception handling, with AI agents monitoring execution, applying machine learning models, and routing exceptions to data stewards. The following steps outline this end-to-end process:
Step 1: Data Profiling and Metadata Extraction
The orchestration engine invokes profiling services to extract statistical summaries—cardinality, null rates, value distributions—and metadata descriptors (min/max, standard deviation, pattern frequency). Tools like Informatica Data Quality catalog module automate pattern detection and seed anomaly models. Profiling results populate the metadata repository and inform thresholds for anomaly detection.
Step 2: Anomaly Detection and Scoring
An anomaly detection microservice applies rules-based checks (ISO 4217 currency codes, date range validations) and unsupervised learning algorithms to flag irregularities. Machine learning models trained on historical cleansed data compute anomaly scores, while categorical anomalies are identified using frequency-based methods and embeddings. An AI agent adjusts thresholds dynamically and logs anomalies with contextual metadata for review.
Step 3: Missing Value Identification and Imputation
Records with nulls undergo a multi-tiered imputation strategy: simple replacements with median or mode, contextual imputations using reference tables, and predictive imputations via a DataRobot model. Each attempt is scored for confidence; low-confidence cases trigger manual review alerts through the collaboration platform.
Step 4: Format Standardization and Schema Alignment
- Standardize dates to YYYY-MM-DD and validate against business calendars.
- Normalize numeric values for common precision and scale.
- Apply NLP routines for text normalization (punctuation, case).
- Reconcile source-specific schemas with the target model via a knowledge graph in Trifacta.
Schema versions are tracked, and automated mapping updates prevent drift and ensure downstream compatibility.
Step 5: Outlier Handling and Correction
- Apply statistical smoothing or percentile capping for numeric outliers.
- Cross-reference categorical outliers with master data in an MDM system; escalate unmatched codes to data stewards.
- Invoke a rule engine for complex anomalies (e.g., negative balances) to suggest corrections based on historical patterns.
Corrected records re-enter anomaly detection to confirm resolution; unresolved cases remain in exception queues.
Step 6: Referential Integrity and Cross-Field Validation
- Verify foreign keys (account IDs, branch codes) against master tables.
- Ensure debit and credit totals reconcile within each transaction.
- Validate aggregated balances against summary entries.
Violations are tagged with root-cause metadata and routed to system owners, with AI agents monitoring resolution progress.
Step 7: Error Logging, Triage, and Exception Routing
- High-severity financial discrepancies trigger immediate alerts to senior analysts.
- Medium-severity schema mismatches generate tickets in the issue management system.
- Low-severity anomalies are batched for periodic review.
An AI agent tracks ticket resolution times and escalates overdue issues, capturing detailed audit records for compliance.
Step 8: Human-In-The-Loop Review and Feedback Incorporation
- Data stewards review suggested imputations and corrections, approving or modifying changes.
- Annotations capture override rationale, feeding back into model retraining pipelines.
- AI agents detect steward decision patterns and propose rule enhancements to reduce manual interventions.
Step 9: Automated Rule Refinement and Model Retraining
- AI agents aggregate steward annotations to identify frequently overridden rules.
- Supervised learning pipelines retrain anomaly detection and imputation models with enriched datasets.
- Updated rules and models are versioned in the governance repository and validated before deployment.
Step 10: Clean Data Validation and Handoff Preparation
- Aggregate counts and reconciliations confirm no records were dropped.
- Quality dashboards display metrics—anomaly reduction, imputation success—for stakeholder sign-off.
- Cleaned datasets are stamped with version metadata and prepared for secure transfer to transformation.
Meeting predefined thresholds, the dataset is handed off to the intelligent transformation pipeline for chart of accounts mapping and regulatory classification.
AI-Driven Quality Enforcement
AI agents augment traditional validations with machine learning–driven anomaly detection, adaptive feedback loops, and automated remediation suggestions. This multi-layered approach ensures comprehensive data validation, reduces manual intervention, and supports faster close cycles, improved compliance, and stakeholder confidence.
Automated Rule-Based Validation Engines
Rule engines codify business logic, regulatory policies, and schema constraints into executable validations. AI workflows integrate leading frameworks:
- Great Expectations for defining and documenting data expectations.
- Amazon Deequ for scalable rule execution on Apache Spark.
- Custom rule modules for business-specific checks like cross-entity balance validations.
Machine Learning–Driven Anomaly Detection
- Unsupervised clustering and density estimation identify high-dimensional outliers.
- Time series models monitor periodic financial metrics for spikes, dips, and drifts.
- Autoencoder networks quantify reconstruction error to detect structural anomalies.
- Statistical methods—Isolation Forests and k-nearest neighbors—provide lightweight detectors.
Adaptive Feedback Loops and Active Learning
- Flagged records are annotated by experts; feedback retrains detection models.
- Rules engines auto-generate suggestions based on recurring error patterns.
- Active learning prioritizes labeling of ambiguous records to maximize model improvements.
Explainability and Model Interpretability
Techniques such as SHAP and LIME provide feature-level insights. Interactive dashboards trace anomaly scores to contributing factors, building trust and accelerating remediation.
Integration with Orchestration and Monitoring Systems
- Job scheduling via Apache Airflow, Prefect, or Azure Data Factory.
- Distributed execution on Apache Spark, Kubernetes, or serverless engines.
- Real-time dashboards track error rates, anomaly counts, and validation coverage.
- Audit trails capture rule versions, model configurations, and feedback actions.
Integration with Data Catalogs and Metadata Repositories
- Auto-populate metadata for new sources in catalogs like Collibra or Alation.
- Annotate validation outcomes in the catalog to expose quality scores.
- Trigger stewardship workflows when quality scores fall below thresholds.
Scalability and Performance Optimization
- Parallelize validations and ML scoring with Apache Spark clusters.
- Perform incremental validations on changed partitions to reduce processing.
- Incorporate streaming anomaly detectors for real-time pipelines.
- Leverage cloud autoscaling to handle workload peaks.
Governance, Security, and Compliance
AI agents enforce role-based access, encryption at rest and in transit, and encode compliance rules (GDPR, SOX, Basel) to flag PII exposure, segregation-of-duties violations, and risk concentration anomalies. Automated compliance reports aggregate results for regulator submissions.
Supporting Data Lineage and Audit Trails
- Capture lineage for each record: source references, applied rules, anomaly scores, and feedback outcomes.
- Version-control rule sets and ML artifacts for reproducibility.
- Generate audit summaries highlighting data quality evolution, rule changes, and retraining events.
- Feed metadata into GRC platforms for regulatory review and internal controls.
Case Study: Monthly Close Process
- Rule-Based Validations detected missing cost center codes and invalid currency conversions across 500,000 entries in under ten minutes.
- ML Anomaly Detection surfaced 2,300 unusual entries with anomalous intercompany balance spikes.
- Adaptive Feedback Loops cut false positives by 60% after two cycles through analyst annotations.
- Integration with the Airflow orchestrator ensured immediate handoff to transformation without manual delays.
- Comprehensive audit trails accelerated external reviews by 30% and satisfied regulatory auditors.
Key Benefits and Considerations
- Enhanced accuracy with combined rule-based and ML-driven validations.
- Operational efficiency by automating routine checks and focusing expert effort on exceptions.
- Scalability to accommodate growing data volumes and source diversity.
- Continuous improvement through feedback loops and adaptive models.
- Regulatory compliance via transparent audit trails and lineage records.
Success depends on governance frameworks for rule management, domain expertise for annotation, and selection of interpretable models to ensure explainability.
Clean Data Output and Downstream Handoffs
At the end of the cleansing stage, standardized, validated datasets form the foundation for reporting and analysis. These outputs carry provenance, audit trails, and contextual metadata, enabling seamless downstream workflows with minimal rework and reduced risk.
Clean Data Artifacts:
- Validated Transaction Records: Unified schema with standardized fields; exception logs for failed records.
- Master Reference Tables: Refreshed chart of accounts mappings, currency rates, and entity hierarchies.
- Data Quality Dashboard: Real-time metrics on completeness, validity, consistency, and timeliness via platforms like Talend Data Fabric or Great Expectations.
- Provenance and Lineage Records: Embedded metadata on source systems, cleansing rules, and AI agent versions.
- Exception Case Bundles: Records flagged for manual review with remediation actions and reviewer comments.
Dependencies Reviewed Before Handoff:
- Schema Contracts: Conformance to registry definitions, data types, and mandatory attributes.
- Reference Integrity: Valid foreign key resolution against master tables.
- Security Controls: Data encryption and role-based permissions in downstream environments.
- Audit Documentation: Timestamps, rule versions, and operator logs assembled for compliance.
- Service-Level Agreements: Processing times, freshness windows, and error-handling SLAs verified.
Key Data Quality Metrics:
- Completeness Score: Percentage of missing critical fields post-cleansing.
- Validity Rate: Proportion of records passing format, range, and referential checks.
- Consistency Index: Alignment across related entries, such as matching debits and credits.
- Anomaly Count: Records flagged by ML models for unusual patterns.
- Remediation Backlog: Exception cases awaiting review or rule updates.
Handoff Protocol to Transformation Stage
- Completion Signal: Cleansing workflow publishes an event to the orchestration engine once all gates clear.
- Schema Verification: Transformation workflow retrieves and compares schema from the registry.
- Metadata Synchronization: APIs update catalogs with new dataset versions, lineage details, and quality snapshots.
- Secure Data Transfer: Encrypted, permission-controlled landing zone for transformation engines.
- Pre-Transformation Validation: Lightweight checks reconfirm integrity before full processing.
- Acknowledgement and Audit Logging: Transformation stage emits an acknowledgement event with timestamps and identifiers.
Ongoing Monitoring and Issue Escalation
- Health Checks: Scheduled jobs sample staging data to verify freshness, format stability, and volume trends.
- Alerting Mechanisms: Threshold-based notifications for quality metric deviations.
- Feedback Loop: Automated tickets feed discrepancies back into cleansing workflows for rule refinement and model retraining.
By defining clear artifacts, enforcing dependency checks, automating handoffs via orchestrators like Apache Airflow, and embedding continuous monitoring, organizations ensure that the transformation stage proceeds with confidence, driving accurate, timely, and compliant financial reporting.
Chapter 3: Intelligent Data Transformation
Purpose and Scope of the Transformation Stage
The transformation stage is the critical nexus where cleansed transaction data is converted into structured, standardized formats ready for analysis, consolidation, and regulatory disclosure. By aligning disparate ledger entries, trading records, and external feeds with predefined charts of accounts, regulatory classifications, and organizational hierarchies, this stage enforces consistency, applies business rules at scale, and generates audit-ready outputs. Precision and traceability are essential to satisfy frameworks such as IFRS, US GAAP, and Basel III. Embedding intelligent mapping, classification, and calculation engines reduces operational risk, accelerates the close cycle, and underpins all downstream analytics, narrative generation, and report assembly functions.
- Standardize entries into a unified ledger schema aligned with corporate charts of accounts
- Map transactions to regulatory categories for compliance reporting and risk analysis
- Apply currency conversion, revaluation adjustments, and inter-company eliminations
- Maintain a complete audit trail of transformation logic, versioned rule sets, and data lineage
- Produce enriched, structured outputs for analytics, narrative generation, and reporting
Inputs, Prerequisites, and Governance
Reliable transformation depends on validated inputs, up-to-date reference data, and a governed infrastructure. Inputs must meet quality metrics—completeness, accuracy, timeliness—and carry metadata tags documenting validation status.
- Cleansed Transaction Data: Verified records from preprocessing pipelines, with anomalies remediated and cleanse logs attached
- Master Data Definitions: Account hierarchies, cost center lists, legal entity structures managed by automated tools
- Business Rule Libraries: Classification criteria, currency rates, revaluation logic, and consolidation rules versioned in a centralized repository
- Regulatory Reference Tables: Code lists and classification schemes mandated by IASB, FASB, Basel, and local authorities
- Metadata and Schema Registries: Definitions of field semantics and data types that underpin validation and output schema generation
- Audit Configuration: Settings for versioning, lineage capture, and exception thresholds
Prerequisites include sign-off on data cleansing, availability of rule libraries, aligned metadata schemas, sufficient compute capacity, secure connectivity, and configured audit logging. Business analysts and regulatory specialists maintain rule libraries, updating mapping and classification logic through automated change management workflows. A centralized metadata registry ensures consistent interpretation of data across systems, supporting audit traceability and rollback capabilities. Scalable infrastructure and orchestration platforms such as Apache Airflow or Databricks must be provisioned for efficient batch or streaming jobs. Governance teams certify that all governance and compliance requirements are met before transformation commences.
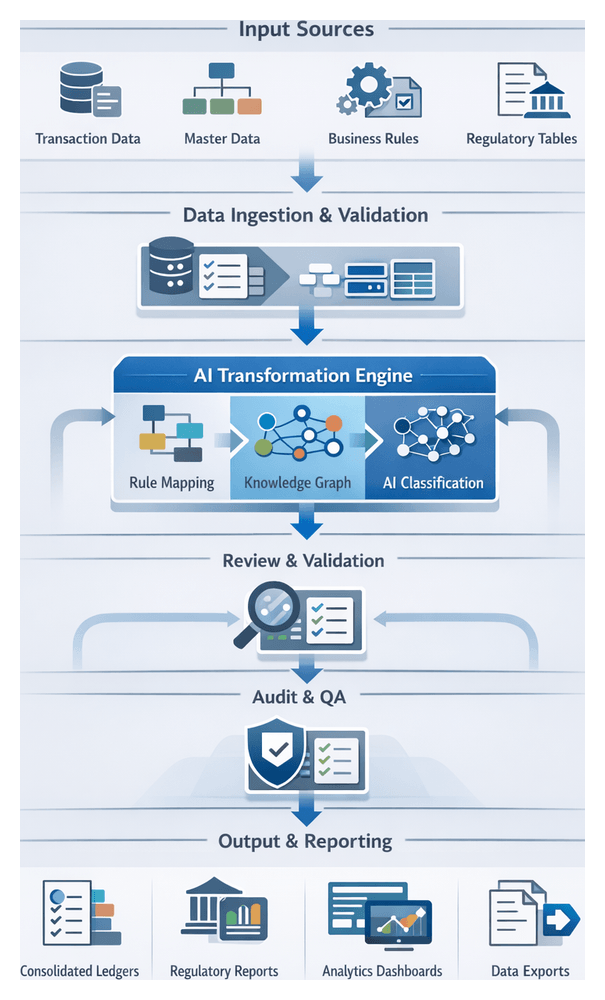
AI-Driven Mapping and Categorization Workflow
This workflow orchestrates deterministic and AI-driven components to harmonize cleansed data with reporting requirements. A centralized orchestration engine manages dependencies, invoking rule engines, knowledge graph services, and classification models in sequence.
- Data Intake: Retrieve batched records with contextual metadata from the cleansing repository
- Reference Loading: Fetch and cache the active chart of accounts and classification rules via secured API calls to the metadata service
- Rule-Based Mapping: Apply deterministic mapping rules for straightforward cases, reducing AI load
- Knowledge Graph Enrichment: Invoke a graph service to infer semantic relationships among entities, products, and regulatory categories
- AI-Driven Classification: Trigger supervised and unsupervised models for ambiguous records, producing proposed mappings with confidence scores
- Confidence Evaluation: Automatically accept high-confidence mappings, route low-confidence entries to human review, and apply secondary checks for intermediate cases
- Human-in-the-Loop Review: Present exceptions in a review interface; record decisions to refine models and rules
- Final Tagging: Assign account codes, cost centers, regulatory classifications, and standardized metadata
- Quality Assurance: Cross-validate aggregates against expected balances; trigger alerts or rollbacks for discrepancies
- Publish to Repository: Persist finalized records and lineage metadata for downstream analytics and reporting
System interactions include:
- Orchestration engine to rule engine (e.g., OpenRules, Drools)
- Orchestration to knowledge graph services (e.g., Neo4j)
- Orchestration to AI classification engines and review interfaces
- Monitoring and logging services capturing audit trails, timestamps, and payload details
Error handling distinguishes transient failures—automatically retried with backoff—from permanent errors routed to exception queues. Business rule violations and low-confidence AI failures trigger dedicated remediation workflows. Continuous feedback loops capture human corrections, rule failure patterns, and newly inferred graph relationships, feeding model retraining and rule refinement. To scale, the workflow leverages parallel processing, asynchronous integration via message queues, auto-scaling infrastructure, in-memory caching of reference data, and real-time monitoring to maintain throughput and low latency.
Key benefits include consistent application of business rules, accelerated data readiness, comprehensive auditability, rapid adaptability to policy changes, and transparent mapping decisions supported by confidence scores and exception reports.
Embedding AI Agents in Data Collection, Validation, and Preliminary Analysis
AI agents automate routine tasks throughout the reporting cycle, orchestrating connectors, enforcing quality, and generating initial insights.
- Connector Orchestration: Agents invoke REST or SOAP APIs against ERP platforms, trading systems, and market data services, managing authentication, retries, and execution logs
- Schema Discovery: Lightweight inference models detect changes in source structures and adapt mapping rules dynamically
- Incremental Retrieval: Watermarking strategies fetch only new or updated records, optimizing performance
- Logging and Audit Trails: Centralized logging captures every connector action for full traceability
- Rules-Based Checks: Predefined validations for account balances, date sequences, and cross-ledger reconciliations
- Anomaly Detection: Unsupervised models surface statistical outliers in amounts, volumes, and time series behaviors
- Master Data Validation: Fuzzy matching against reference repositories for identifier resolution
- Feedback Loops: Analyst resolutions retrain anomaly models to improve future detection
- Aggregated Metrics: Compute totals by business unit, region, and product line
- Variance Analysis: Compare current, prior, and budget figures; highlight significant deviations
- Trend Detection: Time series models identify emerging patterns and threshold breaches
- Pre-Scoring: Assign preliminary risk scores for fraud detection and compliance pipelines
Supporting systems include workflow orchestration engines such as Apache Airflow, messaging platforms like Apache Kafka or RabbitMQ, centralized metadata repositories, observability tools (Prometheus with Grafana), and security frameworks integrating OAuth or LDAP. Embedding AI agents yields faster close cycles, reduced error rates, audit readiness, horizontal scalability, and adaptive learning. Best practices involve clear objectives, a unified metadata repository, human-in-the-loop controls, incremental rollouts, continuous monitoring and retraining, and rigorous change governance.
Delivering Transformed Ledgers and Integration Interfaces
The final stage formalizes transformed ledgers into authoritative outputs and defines integration endpoints for analytics, narrative generation, and reporting systems.
- Standardized general ledger tables for profit and loss, balance sheet, and cash flow
- Subledger details for receivables, payables, fixed assets, and inventory
- Regulatory classification flags under IFRS, US GAAP, Basel III, Solvency II
- Currency translation records with rate logs and gain/loss calculations
- Audit-friendly crosswalks between source codes and chart of accounts segments
Outputs reside in cloud platforms such as Snowflake, Amazon Redshift, or Parquet files on Databricks, or on-premises in Oracle Exadata or SQL Server. Schemas are registered in catalogs like Apache Atlas or Collibra.
- Dependency Matrix: Align cleansed inputs, rule definitions (OpenRules, Drools), graph records (Neo4j), and versioned charts of accounts
- Lineage Tracking: Automated tools detect upstream changes and orchestrate targeted reprocessing to maintain responsiveness
Integration endpoints:
- Batch extraction via JDBC/ODBC for Tableau and Microsoft Power BI
- RESTful APIs through gateways like NGINX or Kong
- Message streams to Apache Kafka for ML scoring in TensorFlow Serving or PyTorch
- Secure file transfers via SFTP for regulatory filings
Data contracts specify schema definitions, refresh schedules, and error rules. Automated contract testing with Pact or Stoplight verifies conformance. Monitoring of API latency, queue lag, and batch completion uses platforms like Datadog or Splunk.
- API and Streaming Handoffs: Kafka events trigger microservices on Kubernetes; REST endpoints support dynamic report; webhook notifications alert downstream systems
- Metadata and Lineage: Orchestration engines such as Apache Airflow or Prefect capture end-to-end data journeys
- Quality Assurance: Validate control totals and balance integrity; exceptions routed for AI-driven reconciliation and reprocessing
- Security and Compliance: Encryption at rest and in transit using AWS KMS, Azure Key Vault, Google Cloud KMS; access via Auth0 or Okta; continuous compliance scanning
- Monitoring and Alerts: Track transformation runtime, API availability, data freshness, and error rates; anomaly detection on telemetry; incident response via PagerDuty or OpsGenie
- Versioning and Change Management: Track mapping rule and schema changes in Git; support concurrent schema versions; automate deployments through CI/CD pipelines
This integrated framework delivers fully validated ledger artifacts and robust interfaces, providing a scalable, audit-ready foundation for end-to-end AI-driven financial reporting, analytics, narrative generation, and executive decision support.
Chapter 4: AI-Powered Analytics and Insight Generation
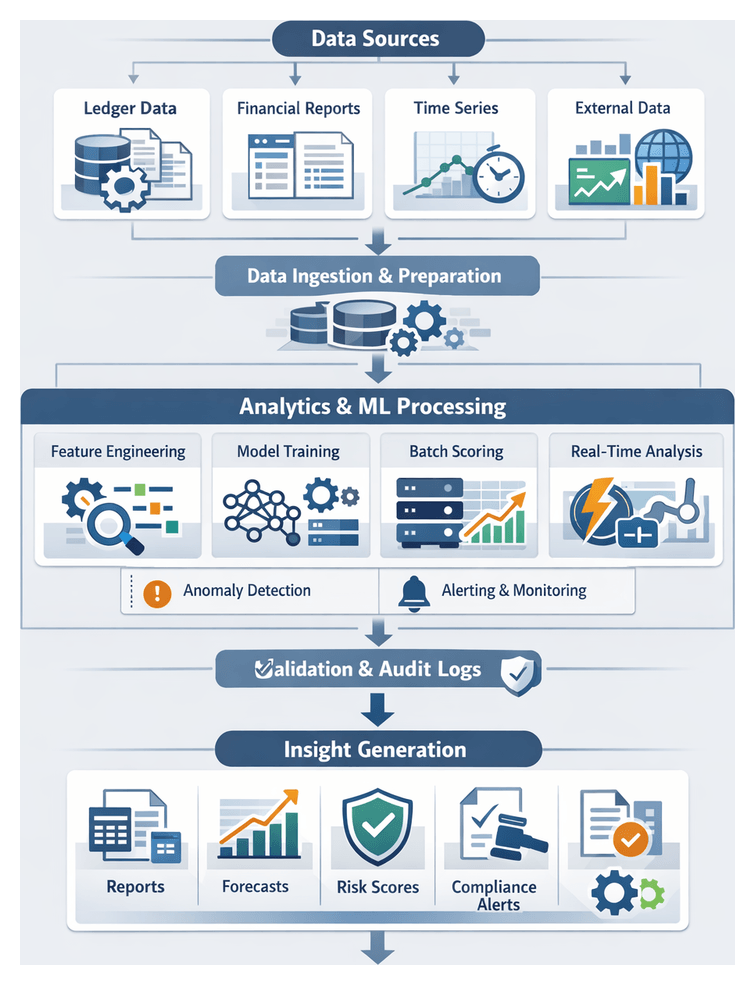
Analytics Stage Objectives and Data Requirements
The analytics stage transforms cleansed, normalized data into actionable business insights for automated financial reporting. By applying statistical analysis, machine learning models, and rule-based algorithms, it generates performance indicators, forecasts, and anomaly alerts that support decision making and narrative disclosures. In finance and banking contexts, analytics must comply with IFRS, GAAP, Basel and other regulatory frameworks, ensure reproducible methodologies for key metrics—return on equity, liquidity ratios, credit exposures—and establish thresholds for early detection of outliers or compliance breaches.
Successful analytics depends on comprehensive inputs that meet strict quality and structural criteria:
- Structured Ledger Data
- Reconciled general ledger entries and sub-ledger mappings
- Account hierarchies aligned with corporate taxonomy and regulatory codes
- Financial Statements
- Balance sheet, profit & loss, and cash flow aggregates across periods and entities
- Historical Time Series
- Multi-period transaction histories and rolling windows for trend analysis and model training
- External Reference Data
- Market prices, interest rate curves, FX rates, GDP, CPI, unemployment figures, and peer benchmarks
- Metadata and Configuration
- Business rules for revenue recognition, provisioning, risk weights, and alert thresholds
- Feature definitions and serialized machine learning model artifacts
Each input must satisfy quality gates for completeness, accuracy, consistency, timeliness, lineage, and traceability. Data readiness demands a unified repository accessible via high-performance interfaces, scalable compute resources for batch and real-time analytics, containerized model deployment frameworks (Kubernetes or Docker), role-based security controls, and governance mechanisms for KPI definitions and regulatory approvals. Outputs adhere to standardized schemas—tabular reports, JSON or XML payloads with metadata annotations and confidence scores—and trigger events for narrative generation, visualization, and compliance workflows.
Statistical and Machine Learning Workflow Sequence
This stage orchestrates data ingress, feature engineering, model operations, anomaly detection, and scoring across batch and streaming contexts. Coordination between orchestration engines, feature stores, model registries, compute clusters, and alerting services ensures timely, accurate, and compliant analytical outputs.
Data Ingress and Feature Preparation
Ingestion jobs, scheduled by platforms such as Apache Airflow, extract transformed ledgers, account mappings, and regulatory labels into an analytics data lake or feature store. Metadata validation against catalog schemas confirms completeness and consistency. Feature engineering agents compute rolling aggregates, financial ratios, lag features, moving averages, volatility measures, and statistical indicators, versioning them in the feature store with lineage metadata for reproducibility.
Model Selection and Configuration
An AI orchestration engine consults a model registry—tracking algorithms from ARIMA and exponential smoothing to gradient boosted trees and neural networks—selecting candidates based on data freshness, latency requirements, and explainability constraints. Hyperparameters, cross-validation settings, and evaluation metrics are sourced from configuration files or parameter stores. A run specification outlining compute environment, data inputs, model code repository, and notification endpoints is version-controlled for audit purposes.
Batch Scoring Workflow
- Job Submission: The orchestration engine submits run specifications to platforms such as Apache Spark or Databricks.
- Data Loading: Worker nodes retrieve feature partitions from the feature store.
- Model Execution: Serialized model artifacts are fetched from the registry and applied to feature sets.
- Result Aggregation: Predictions, probability estimates, residuals, and anomaly flags are aggregated into result tables or message queues.
- Validation Checkpoint: Post-scoring services verify totals against expected ledger balances.
Completion notifications are dispatched via messaging infrastructure such as Apache Kafka, and performance metrics are logged for capacity planning and SLA tracking.
Real-Time Evaluation Pipeline
For low-latency requirements—intraday liquidity analysis or fraud detection—streaming events traverse a message bus into engines like Apache Flink. Lightweight models deployed as microservices apply inference on each event, producing scores, confidence intervals, and feature attributions for explainability. Results feed dashboards and risk systems, while feedback loops trigger retraining when data drift or low confidence is detected.
Anomaly Detection and Alerting
- Statistical tests (z-score, residual analysis) and ML-based detectors examine batch and streaming outputs.
- Rules engines evaluate anomalies against severity thresholds, routing alerts via email, collaboration platforms, or ticketing systems.
- Incident records in management tools enable analysts to review, annotate, and resolve anomalies, with feedback refining detection parameters and retraining triggers.
Audit Logging and Traceability
Every action—data retrieval, feature computation, model training, scoring, anomaly flagging—is recorded in a write-once, append-only audit log. Entries capture timestamps, actor identities, data snapshot identifiers, model versions, parameters, execution outcomes, and references to change requests or incidents, supporting tamper-evident audits and regulatory compliance.
Machine Learning Agents and MLOps Integration
Specialized AI agents automate feature engineering, model lifecycle management, scoring, monitoring, and explainability, integrating with MLOps platforms and data repositories to deliver transparent, governed analytics.
Core Agent Types
- Feature Engineering Agents: Generate temporal and statistical variables, encode categorical attributes, normalize features using libraries such as scikit-learn, and enrich with external market indicators.
- Model Orchestration Agents: Coordinate training pipelines, hyperparameter tuning, experiment tracking via MLflow or Elyra.
- Scoring and Inference Agents: Deploy models on platforms like Databricks or Kubeflow for batch and real-time predictions.
- Monitoring and Drift Detection Agents: Compute statistical divergence metrics, detect data and concept drift, trigger retraining when thresholds are exceeded.
- Explainability and Compliance Agents: Leverage SHAP and LIME to produce feature attributions, generate audit-ready documentation, and serve explainability dashboards for compliance officers.
Model Lifecycle Orchestration
Agents select algorithms using heuristics or AutoML frameworks such as TensorFlow AutoML and H2O.ai, execute hyperparameter optimization via grid or Bayesian search, parallelize training in cloud or on-prem clusters, and log experiment metadata in registries. Validation includes k-fold cross-validation, stress scenarios, baseline comparisons, and model card generation for governance review. Approved models are promoted to production with containerization on Docker and orchestration on Kubernetes.
Scoring and Deployment Patterns
Scoring agents expose RESTful APIs for low-latency inference, schedule batch inference during off-peak hours, and stream predictions through event-driven architectures like Apache Kafka. Consistency is maintained by versioning model artifacts and shared transformation code. Fallback mechanisms ensure reporting continuity during system failures.
Continuous Monitoring and Retraining
Monitoring agents track performance, compute PSI and KL divergence, compare prediction distributions to baselines, and invoke retraining pipelines when drift or degradation occurs. Notifications provide drift diagnostics to data scientists and business stakeholders, integrating with CI/CD workflows for automated promotion of approved model versions.
Human-in-the-Loop Collaboration
Despite automation, human expertise shapes analytics by reviewing ambiguous patterns, experimenting in interactive notebooks, signing off on model deployments via ticketing systems, and providing feedback on prediction accuracy. Collaborative platforms like Slack or Microsoft Teams receive alerts and reports, enabling timely decision-making in financial close activities.
Insight Outputs and Handoff Protocols
Insight outputs—anomaly flags, trend forecasts, performance metrics, risk scores, and scenario simulations—are packaged with metadata and dependencies to ensure seamless integration with narrative engines, visualization platforms, and compliance systems.
Output Types and Formats
- Anomaly Reports: Structured JSON or tabular listings of outliers and irregularities.
- Trend Forecasts: Time series projections generated with tools like Prophet and TensorFlow.
- Performance Dashboards: Aggregated KPI summaries, variance analyses, and scorecards.
- Risk and Compliance Scores: Outputs from regulatory rule engines and ML classifiers.
- Scenario Simulations: What-if analyses for market, policy, or operational changes.
Standardized Delivery Mechanisms
- Delimited Files (CSV, TSV) and database tables for bulk transfers.
- Structured JSON/XML payloads for API-driven consumption.
- Message queues via Apache Kafka or AWS Kinesis for real-time updates.
- Data cubes and RESTful endpoints for BI tools and custom dashboards.
Metadata and Lineage
- Source system identifiers, ingestion timestamps, and pipeline versions.
- Model version, hyperparameters, training dataset snapshot, and validation metrics.
- Confidence scores, p-values, and annotations explaining data imputation or overrides.
- Processing timestamps and quality flags to track SLA adherence and exception handling.
Handoff to Narrative and Visualization
- JSON payloads with metric names, values, annotations, and template selection keys for engines like DataRobot NLG.
- Controlled vocabularies mapping analytics outputs to narrative sections.
- Embedded visualization metadata—chart types, axis configurations, and drill-down hierarchies—for automatic dashboard layouts in tools such as Tableau and Power BI.
Compliance, Audit Trails, and Quality Assurance
- Immutable logs capturing insight generation events, approvals, and exception workflows.
- Rule engine inputs for regulatory validations (Sarbanes-Oxley, IFRS checks).
- Quality checks for drift detection, low confidence scores, and excessive data imputations.
- Trigger mechanisms—scheduled batch runs, event-driven invocations, and ad hoc requests—to refresh insights on demand.
By formalizing insight outputs, metadata, dependencies, and handoff protocols, the analytics stage becomes a reliable foundation for narrative generation, visualization, compliance, and audit processes, enhancing operational efficiency, governance, and regulatory resilience in financial reporting.
Chapter 5: Automated Narrative Generation
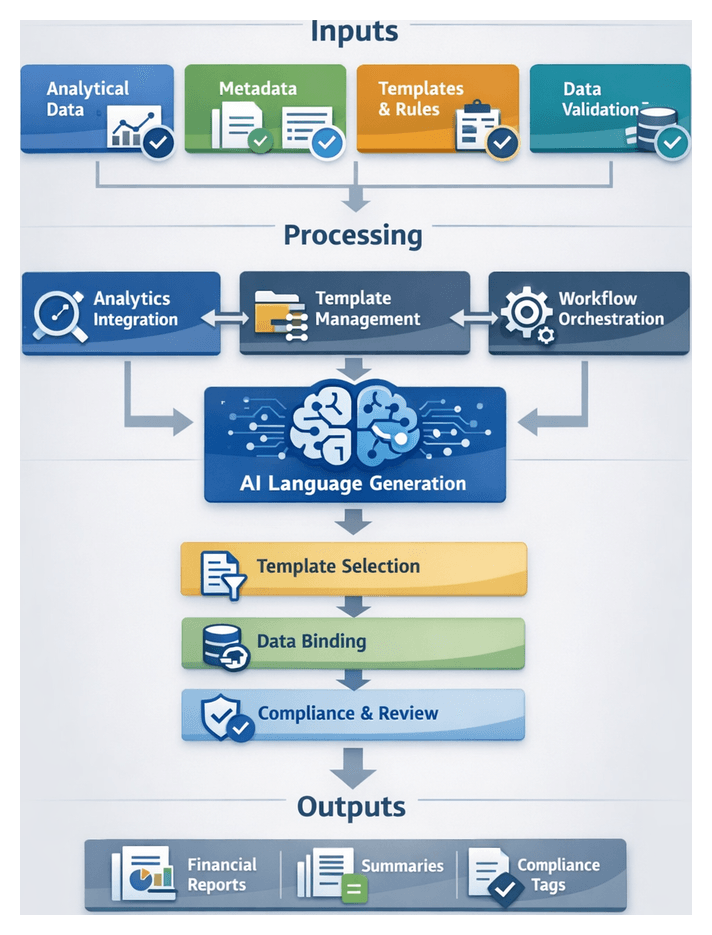
Automated narrative generation transforms quantitative analytics into clear, context-rich commentary that guides readers through financial results, risk assessments, and performance drivers. By converting statistical outputs, anomaly flags, and trend forecasts into coherent prose, organizations bridge the gap between raw data and decision-ready insight. In regulated environments such as banking and finance, this stage ensures disclosures meet compliance requirements, maintain consistency across reporting periods, and reinforce the institution’s brand voice.
Key objectives include:
- Articulating key financial movements, such as revenue variance and margin fluctuation.
- Highlighting anomalies detected by AI-driven analytics in terms of risks or opportunities.
- Providing forward-looking commentary based on forecast models for strategic planning.
- Embedding regulatory and compliance language aligned with IFRS, GAAP, or Basel requirements.
- Maintaining a consistent tone and terminology in line with corporate style guides.
By automating narrative creation, finance teams reduce drafting time, minimize human error in disclosures, and free subject-matter experts to focus on strategic review.
Essential Inputs and Prerequisites
Reliable narrative generation depends on well-defined analytical outputs, metadata, templates, and data quality controls:
- Analytical Outputs: KPIs (revenue growth, cost ratios, liquidity metrics), anomaly reports, trend analyses, forecast summaries, and segment breakdowns.
- Contextual Metadata: Reporting period definitions, regulatory reference data, risk appetite indicators, and comparative benchmarks.
- Templates and Style Artifacts: Pre-approved narrative templates (earnings commentary, MD&A), a glossary and taxonomy, brand voice guidelines, and a compliance ruleset.
- Data Quality Preconditions: Accurate, complete, and consistently formatted inputs validated against master data and reference tables.
Key Components and Integration Architecture
The narrative generation stage relies on specialized AI components and integration layers to access inputs and deliver outputs into the reporting pipeline:
- Natural Language Generation Engine: Domain-tuned NLG platforms such as OpenAI GPT-4, IBM Watson Natural Language Generation, or Arria NLG.
- Template Management System: Repository for narrative templates, style guides, and compliance rules that interfaces with the NLG engine, enabling template updates without code changes.
- Analytics Integration Layer: APIs delivering anomaly flags, trend data, and forecasts from AI-powered analytics, with secure, low-latency data exchange and error handling.
- Workflow Orchestration: Orchestration platforms schedule the narrative job, monitor execution, and manage retries in case of data dependency delays.
Template Selection and Text Assembly
The system transitions from raw analytical data to structured prose through a controlled flow of template selection, data binding, content sequencing, and validation:
Initial Inputs and Repository
- Analytical outputs: time-series trends, variance analyses, anomaly flags, forecast summaries.
- Report metadata: period identifiers, entity hierarchy, regulatory framework, materiality thresholds.
- Audience profiles: tone and depth requirements for executives, auditors, or internal stakeholders.
- Compliance flags: mandatory disclosures and phrasing constraints.
Template repository entries include identifiers, modular content blocks, placeholder maps, conditional logic, styling attributes, and regulatory annotations. Each element serves a distinct purpose: identifiers streamline content retrieval, modular content blocks enhance flexibility, and placeholder maps guide content placement. Conditional logic allows for dynamic content adaptation, while styling attributes ensure visual consistency. Regulatory annotations maintain compliance, safeguarding against legal pitfalls.
Together, these components create a robust framework for efficient content management and deployment.
AI-Driven Template Ranking and Selection
- Relevance Scoring: Machine learning models assess template fit based on context, language style, and historical usage.
- Compliance Verification: Rule engines filter non-conforming templates against regulatory flags.
- Performance Heuristics: Past metrics such as review turnaround times guide template prioritization.
- Selection: The orchestrator assembles an initial structure, mapping content blocks to analytical insights.
Data Binding and Placeholder Resolution
- Placeholder matching and validation against data fields ensures that all required inputs are accounted for. Implement exception workflows to address any missing data, allowing for seamless adjustments and maintaining the integrity of the final output. This process not only enhances data accuracy but also streamlines the overall workflow, reducing the risk of errors and improving turnaround times.
- Value formatting for numbers, dates, and currencies according to regional settings.
- Contextual enrichment: pluralization, article selection, and numeric-to-text conversion.
- Cross-reference integration: inline links to charts or tables managed in the report assembly stage.
Content Sequencing and Flow
- Dependency Analysis: Ensuring logical order (e.g., overview before variance explanation).
- Transition Generation: Leveraging models such as AWS Comprehend to create connective sentences.
- Tone Consistency Checks: Style evaluation models enforce uniform vocabulary and complexity.
- Adaptive Reordering: Customizing block order based on audience profile.
Compliance, Exception Handling, and Feedback
- Regulatory and brand style audits ensure mandatory language and approved phrasing.
- Fallback mechanisms: default templates, manual intervention queues, data request triggers, and graceful degradation for missing inputs.
- Continuous learning: telemetry on template performance, exception frequency, and reviewer edits informs model retraining and rule updates.
AI Language Models and Domain Tuning
Transformer-based models such as GPT-4, Azure OpenAI Service, and Amazon Bedrock provide the generative backbone. Domain tuning ensures compliance and brand alignment through:
- Fine-Tuning: Training on historical financial narratives, regulatory filings, and annotated commentary to imbue industry jargon, compliance patterns, and corporate tone.
- Prompt Engineering: Structured input templates with placeholders, tone instructions, and regulatory context flags enable rapid adaptation without retraining.
These models integrate with metadata management, style and compliance repositories, human-in-the-loop interfaces, and monitoring frameworks that track semantic accuracy, regulatory adherence, and readability metrics. Specialized agents include:
- Model Orchestrator: Selects appropriate model instances based on report type and throughput needs.
- Domain Adapter: Manages fine-tuned checkpoints and retraining schedules aligned with regulatory updates.
- Prompt Manager: Constructs and optimizes prompt templates with dynamic context variables.
- Compliance Verifier: Executes semantic checks and regulatory rule validations.
- Feedback Integrator: Aggregates reviewer annotations and performance metrics for continuous improvement.
Generated Outputs and Downstream Handoffs
The narrative engine produces structured content artifacts in a standardized schema, ensuring seamless integration into the report assembly process:
- Executive summaries, section-level narratives, footnote explanations, and meta-segments for compliance tagging.
- JSON-like schema fields: SectionIdentifier, ContentText, ContextTags, StyleProfile, and VersionInfo.
Handoff to the dynamic report assembly stage follows a protocol of artifact publication, orchestrator notification, schema validation, content merging with visuals, and final compliance confirmation. Robust error handling addresses schema validation failures, content quality flags, dependency breakdowns, and audit trail recording. Version control tracks template, model, and content versions, along with change metadata for full traceability.
Human-in-the-loop processes manage expert review of high-risk sections through review task creation, inline annotations, and digital sign-off workflows. The result is a consistent, efficient, and scalable narrative output that accelerates report production while ensuring regulatory compliance and audit readiness.
Chapter 6: Dynamic Report Assembly and Formatting
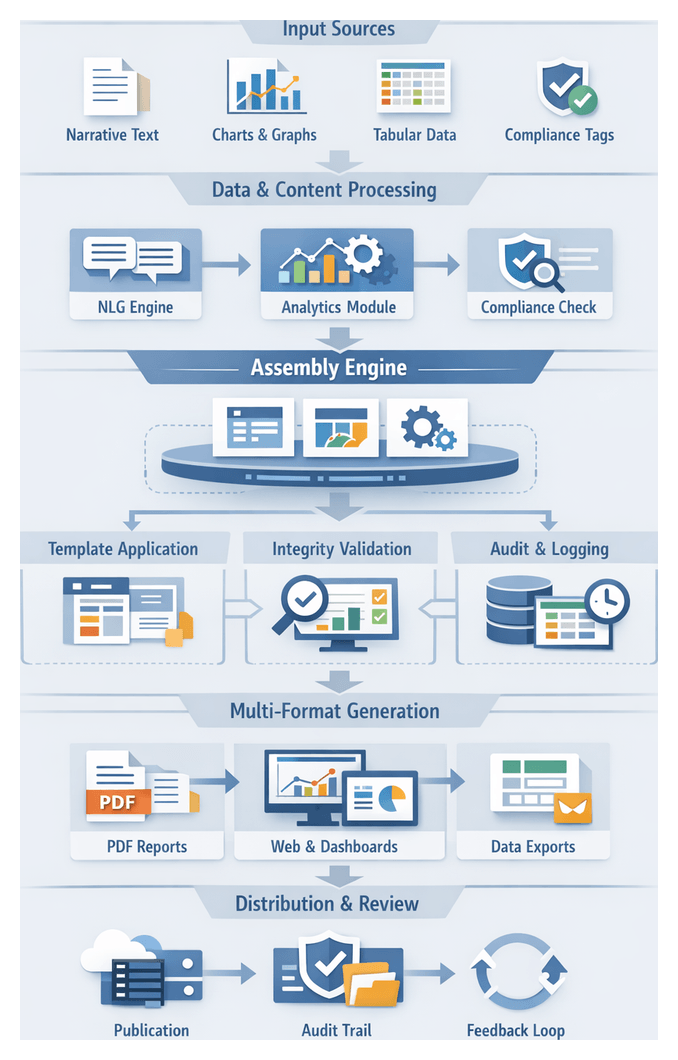
Assembly Stage: Purpose and Strategic Role
The assembly stage represents the culmination of automated financial reporting workflows, orchestrating narrative text, analytical charts, tabular data, and compliance annotations into a cohesive deliverable. Beyond aggregation, this phase validates that each component adheres to branding guidelines, regulatory requirements, and formatting standards. By integrating outputs from natural language generation modules, machine learning analytics, and compliance checks, the assembly engine produces professionally styled documents optimized for PDF, web, and interactive dashboards. In banking and finance contexts, this stage is critical for consistency, compliance, and timeliness: any error can undermine disclosures, jeopardize filings, or erode stakeholder confidence.
Key Objectives
- Integrity Validation: AI agents perform structural checks on narratives, visualizations, and tables to confirm alignment with analytics outputs and regulatory annotations.
- Template Application: Layout engines map validated components onto master templates in Adobe InDesign Server or custom HTML/CSS frameworks, enforcing style rules from font usage to pagination.
- Multi-Format Output: Generation of PDF, HTML5, and dashboard slices tailored to finance teams, auditors, and executives.
- Audit Trail Maintenance: Logging of template versions, input hashes, and AI decisions to create transparent provenance records for internal and external audits.
- Extensibility: Modular workflows allow configuration of new formats or compliance mandates without code changes, enhancing agility for design updates and regulatory shifts.
Essential Inputs and Prerequisites
Successful assembly depends on readiness of upstream assets:
- Narrative Documents: Commentary and disclosures from NLG modules, verified for compliance and clarity.
- Analytical Visualizations: Charts and infographics produced by ML engines, rendered for tools like Tableau and Microsoft Power BI.
- Tabular Data Sets: Financial line items and schedules in CSV, XLSX, or database exports.
- Regulatory Annotations: Metadata tags, footnotes, and disclosure checklists applied during compliance checks.
- Brand Assets and Templates: Logos, color palettes, typography rules, and layout definitions stored in Bynder or similar DAM systems.
- Metadata and Audit Information: Source timestamps, AI agent identifiers, and version histories for traceability.
Prerequisites include signed-off narratives, completed analytics runs with anomaly flags, validated compliance tags, updated template definitions, and network access to generation engines and asset repositories.
Layout and Template Workflow Execution
This stage transitions from content aggregation to visual composition. A template repository, layout engine, AI-driven design agents, and validation modules collaborate to arrange narratives, tables, charts, and graphics into branded, compliant templates. AI agents map content blocks to dynamic placeholders, apply style rules, and generate proofs for review, eliminating manual positioning and ensuring consistency across PDF, web, and dashboard formats.
Workflow Trigger and Template Selection
- Orchestration Signal: Triggered by completion of narrative and visualization modules in platforms like Apache Airflow or Prefect.
- Metadata Extraction: Attributes such as report type, region, language, and distribution channel guide template lookup.
- Rules-Based Selection: A template registry returns the best-matching file; fallback options raise exception flags for manual review.
Content Block Mapping
- Placeholder Parsing involves the layout engine recognizing and interpreting semantic labels such as ExecutiveSummary and TrendChartRevenue. This process ensures that content is accurately categorized and displayed, enhancing the overall coherence and usability of the document.
- Asset Matching: AI agents bind narratives, charts, and tables to placeholders, applying minor transformations for size and flow.
- Error Handling: Missing or mismatched content triggers validation errors and escalates tasks to human operators.
Automated Style Application
Design agents enforce typography, color palettes, spacing, and dynamic resizing. Rules ensure headings, subheadings, and body text follow hierarchy; corporate colors meet contrast and accessibility standards; and charts and tables scale to avoid overflow. Style decisions are logged for audit purposes.
Adaptive Multi-Format Rendering
- Format Variants: Templates optimized for print, PDF, responsive web, and interactive dashboards share a common logical structure.
- Conditional Inclusion: High-resolution images or interactive widgets appear only in supported formats.
- Responsive Reflow: Web reports use CSS-like rules to adapt columns and navigation for devices.
- Interactive Embedding: Dashboard outputs integrate as live components in Tableau or Power BI with data streams for drill-down analysis.
Orchestration, Validation, and Human-in-the-Loop
An orchestration engine coordinates template retrieval, content storage, layout service, and a validation module that checks pagination, links, style adherence, and accessibility before creating proofs. Reviewers annotate proofs via integrated dashboards, and comments trigger automated reprocessing. Issue annotation, comment threads, version control, and retry policies foster a rapid, traceable review cycle.
Logging, Audit Trails, and Error Escalation
Every action is logged: template versions selected, content binding decisions, style enforcement outcomes, and review iterations. Logs feed compliance reports. Exception queues, notification alerts, fallback templates, and retry mechanisms ensure critical deadlines are met even when automation encounters issues.
AI-Driven Design Adaptation and Branding
As reports proliferate across channels, AI-driven design adaptation ensures consistent brand identity and adherence to design standards. These tools automate style enforcement, optimize layouts, integrate brand assets, and support real-time adjustments at scale.
Automated Style Enforcement
AI engines convert corporate guidelines into tokens for text blocks, charts, and tables. Adobe Sensei detects deviations in font, color, and margin, applying real-time corrections to maintain brand integrity and regulatory compliance.
Dynamic Layout Adjustment
Constraint-based algorithms reflow content for portrait or landscape templates and responsive designs. Canva Magic Design uses reinforcement learning to prioritize critical elements such as executive summaries and key performance indicators when space is constrained, ensuring readability without manual intervention.
Brand Asset Management Integration
AI modules retrieve logos, icons, and images from Adobe Experience Manager and Bynder, using computer vision to select correct regional or co-branding variants. Automated resolution and format conversion guarantee print quality and web optimization.
Visual Consistency and Accessibility
Cross-channel snapshots are compared using image-based similarity metrics to flag misalignments or color shifts. AI-driven solutions generate exception reports. Accessibility tools assess color contrast for WCAG compliance and produce alternative text for visual elements. Localization platforms such as Lokalise AI and Smartling translate narratives, adjust numeric formats, and handle currency symbols automatically.
Real-Time Collaboration and Feedback Loops
Plugins in design platforms such as Figma offer live suggestions for typography, color harmony, and layout based on brand guidelines. Machine learning models refine recommendations by learning from user acceptance and rejection, accelerating convergence on optimal designs with minimal manual styling.
Governance and Version Control
AI systems maintain versioned style libraries and template repositories, tracking updates to brand guidelines or regulatory requirements. When new corporate identity standards are published, the AI identifies impacted templates and generates change requests with suggested updates. Reviewers approve or refine changes within a governed workflow, preserving a full audit trail of styling decisions.
Infrastructure and Supporting Systems
Cloud services underpin design adaptation: Amazon S3 and Azure Blob Storage host media assets and style definitions; Elasticsearch powers metadata catalogs and search indexes; containerized microservices deploy AI inference engines on Kubernetes clusters; identity and access management systems enforce role-based permissions to safeguard branding rules.
Final Report Versions and Multi-Channel Distribution
At the workflow’s end, the system generates synchronized report versions optimized for interactive portals, printable PDFs, embedded dashboards, and spreadsheet exports, meeting stakeholder needs from C-suite summaries to audit-ready documents.
Output Channels and Stakeholder Requirements
- Interactive Web Reports: Secure portals with filters, drill-downs, and responsive layouts for desktops and mobile devices.
- Printable PDFs: Paginated files with bookmarks, hyperlinks, and digital signatures via Adobe PDF Generator.
- Embedded Dashboard Widgets: KPIs and forecasts integrated into Tableau or Power BI dashboards, updating in real time.
- Spreadsheet Exports: CSV and XLSX data tables for ad hoc analysis and audit purposes.
Automated Multi-Channel Generation Workflow
- Template Selection: Rules reference metadata—fiscal period, jurisdiction, distribution channel—to choose layout definitions.
- Content Injection: Conditional logic merges narratives, charts, and tables into placeholders.
- Style Enforcement: AI agents validate color contrast, font sizes, and accessibility compliance.
- Format Conversion: Engines render HTML/CSS bundles for web and high-fidelity PDFs, embedding fonts and optimizing images.
- Quality Validation: AI-powered visual diff tools, content integrity checks, accessibility audits, and security scans detect anomalies.
- Metadata Tagging: Unique identifiers, timestamps, and audit tags are applied to each output file.
- Publication Handoff: Files are deposited via SFTP, encrypted APIs, CMS connectors, or messaging gateways. Dashboard components deploy through BI platform APIs.
Strategic Benefits
- Enhanced stakeholder engagement through tailored, accessible formats.
- Regulatory readiness with pre-staged PDF and XML filings for bodies such as the SEC or ECB.
- Operational efficiency, reducing manual formatting labor by up to 80 percent.
- Consistent branding maintained via centralized template and style management.
- Immutable audit trails for full traceability across distributed outputs.
Chapter 7: Compliance and Risk Management Controls
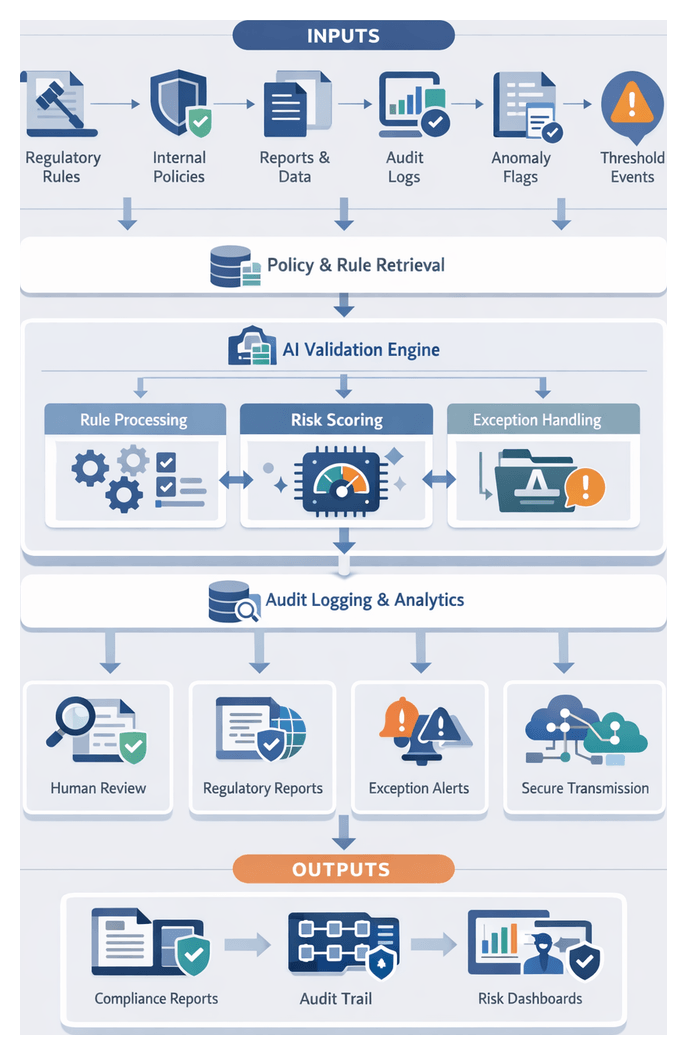
Compliance Stage Scope and Input Triggers
The compliance and risk management stage validates assembled financial reports against regulatory standards, internal policies, and risk frameworks. By embedding AI-driven controls into the reporting pipeline, organizations enforce consistency, adapt rapidly to evolving regulations, and maintain transparent audit trails. Key objectives include identifying exceptions before distribution, reducing operational risk, and accelerating the financial close cycle.
In practice, this stage ingests a variety of inputs to determine when and how controls are applied:
- Regulatory Reference Sets: Machine-readable taxonomies and technical standards for IFRS, Basel III, Dodd-Frank, and local GAAP regimes.
- Internal Policy Libraries: Governance documents, risk appetite statements, threshold tables, and exception criteria defined by compliance teams.
- Assembled Report Artifacts: Draft reports, narrative disclosures, tables, charts, and schedules produced during assembly.
- Data Quality Flags: Metadata and anomaly logs highlighting outliers or missing values from the analytics stage.
- Audit Trail Records: Logs of transformations, annotations, and sign-offs from earlier workflow steps.
- Trigger Events and Threshold Breaches: Operational events such as balance limit exceedances, ratio breaches, or reconciliation failures that initiate compliance routines.
- User and Role Metadata: Identity and access information for authors, reviewers, and approvers to enforce segregation of duties.
Trigger definitions typically include:
- Report Publication Ready: A flag indicating narrative generation and layout assembly have reached stable draft status.
- Data Version Control Checkpoint: Confirmation that the unified data repository has been locked and versioned.
- Anomaly Detection Thresholds: Statistical model rules that, when exceeded, demand compliance review.
- Regulation Update Alerts: Notifications from regulatory feeds or third-party services of standard changes.
- Manual Exception Submissions: Inputs from risk officers flagging specific items for targeted validation.
- Policy Revision Schedules: Calendar-based triggers aligned with policy review cycles.
Successful automation requires foundational components:
- Centralized Rule Management: Engines like DROOLS or commercial platforms such as IBM OpenPages ingest and govern machine-readable rule sets.
- Risk Scoring Models: Pretrained ML algorithms calibrated on historical data and validated periodically to assign risk levels.
- Metadata Annotation Framework: Schemas for tagging report elements with control identifiers, regulatory mappings, and policy references.
- Audit Logging Infrastructure: Tamper-evident repositories, including blockchain-inspired ledgers or append-only databases.
- Identity and Access Management Integration: Connectivity to enterprise directories and single sign-on systems for role-based controls.
- Reporting Artifact Versioning: Systems that timestamp and link each document version to audit entries.
Policy Enforcement and Audit Workflow
The policy enforcement workflow orchestrates AI engines, rule services, data repositories, and human reviewers to automate rule validation, exception handling, and audit trail generation. Managed by an orchestration engine, it ensures task sequencing, dependency tracking, and end-to-end auditability.
Workflow Overview
The main stages are:
- Trigger evaluation and policy retrieval
- Rule execution and validation
- Exception detection and escalation
- Audit trail capture and storage
- Integration with external systems
- Human review and reconciliation
Trigger Events and Policy Retrieval
Triggers can be report assembly completion, updated regulatory guidance, scheduled audits, or flags from analytics. Upon detection, the orchestration engine calls the policy retrieval service to fetch relevant rule sets covering Sarbanes-Oxley, Basel III, IFRS, and internal policies. An AI policy engine validates alignment between report metadata (type, period, jurisdiction) and the retrieved rules, issuing early warnings for mismatches.
Rule Execution and Exception Management
The rule execution engine performs:
- Structural Checks: Ensures sections, tables, and narratives meet template and disclosure requirements.
- Numerical Validations: Cross-checks financial aggregates against source ledgers and variance thresholds.
- Regulatory Thresholds: Verifies capital, ratio, and limit compliance.
- Data Lineage Checks: Confirms traceability of data back to ingestion stages.
Parallel processing and knowledge graph inferences accelerate complex rule evaluations. Exception events are classified by severity:
- Critical Failures: Mandatory breaches requiring immediate action.
- High-Priority Warnings: Significant deviations correctable via data adjustment or annotation.
- Informational Notices: Minor formatting issues or optional disclosures.
Critical failures trigger automated alerts to compliance officers. Warnings appear on an exception dashboard for regional controllers to remediate or accept with justification. Informational notices are logged for continuous improvement. AI-assisted modules can surface root cause suggestions—such as missing journal entries—via anomaly diagnosis.
Audit Trail Generation and Integration
An immutable audit trail records:
- Timestamps, rule versions, and outcomes
- Data inputs and contextual metadata
- User actions, comments, and approvals
- System interactions among rule engines, knowledge graphs, and AI assistants
Logs are stored in append-only ledgers or blockchain-backed databases. An API endpoint supports retrieval by audit tools. For external reporting, adapters transform validated packages into XML, XBRL, or proprietary schemas and transmit via secure channels. Connectors include SFTP, OAuth-authenticated regulator APIs, and robotic process automation tools such as UiPath and WorkFusion. Acknowledgment receipts are ingested back, linking regulator responses to the audit trail.
Human Collaboration and Performance Monitoring
A human-in-the-loop portal allows compliance officers to review exceptions, annotate rule interpretations, override risk scores, and document justifications. Role-based access ensures only authorized personnel perform critical actions. Once exceptions are resolved, the workflow hands off the validated package to final review.
Monitoring services collect metrics on validation throughput, exception rates, mean time to resolution, and resource utilization. Real-time dashboards and AI-driven anomaly detectors identify bottlenecks or rule inefficiencies, triggering alerts and informing periodic performance reports.
AI-Driven Risk Scoring and Regulation Checks
Artificial intelligence enhances risk assessment and regulatory validation by automating rule interpretation, scoring transactions, and surfacing context-rich exceptions. This continuous, adaptable approach addresses the volume, velocity, and complexity of modern financial data.
Key AI Capabilities
- Machine Learning Risk Models: Supervised and unsupervised techniques generate transaction-level and portfolio-level risk scores.
- Natural Language Processing: Engines parse regulatory texts, extract rule definitions, and map requirements to system attributes.
- Knowledge Graphs: Semantic networks represent relationships among accounts, instruments, counterparties, and regulations.
- Real-Time Monitoring Agents: Autonomous agents observe data streams, apply risk models, and trigger exceptions within seconds.
- Explainability and Audit Engines: Components generate human-readable justifications and capture model inputs, outputs, and logic.
Data Foundations and AI Architecture
AI systems rely on unified, high-quality data sources:
- Financial ledgers and subledger feeds
- Transaction histories and market data feeds
- Counterparty metadata and regulatory documents
- Operational metrics and exception logs
The architecture typically comprises:
- Rule Ingestion Layer: NLP pipelines ingest updates via Thomson Reuters Regulatory Intelligence and IBM Watson Discovery.
- Knowledge Graph Layer: Semantic frameworks built on Neo4j link rules to financial entities.
- Feature Engineering Layer: Automated pipelines compute indicators via DataRobot and Azure Machine Learning.
- Model Training Layer: Classifiers developed with SAS Visual Investigator and Google Cloud AI Platform.
- Inference and Monitoring Layer: Deployed models process live transactions with oversight by Dataiku or Palantir Foundry.
- Explainability Layer: LIME or SHAP frameworks generate narrative explanations and feed into audit logs.
Roles of AI Agents and Integration
- Regulation Parsing Agent: Extracts clauses and applicability from policy texts, triggering update workflows.
- Risk Scoring Agent: Computes and normalizes risk scores, enriching results with explainability metadata.
- Policy Enforcement Agent: Compares scores to thresholds and initiates escalations.
- Anomaly Detection Agent: Applies unsupervised algorithms to surface novel risk scenarios.
- Knowledge Graph Navigator: Identifies multi-regulation implications based on semantic relationships.
- Explainability Agent: Compiles regulatory references, feature contributions, and historical context into audit dossiers.
These agents integrate seamlessly with the broader compliance workflow, consuming validated data and rule sets, and feeding detailed risk assessments into compliance reports and review portals.
Benefits and Best Practices
- Scalability: Continuous, real-time risk monitoring across global operations.
- Adaptability: Rapid rule updates via NLP-driven ingestion.
- Consistency: Uniform application of thresholds, minimizing human error.
- Explainability: Transparent model logic for governance and audits.
- Speed: Accelerated close cycles through instant risk assessments.
- Proactivity: Early identification of emerging risk scenarios.
- Data Governance: Define ownership, quality standards, and access controls.
- Model Governance: Document lifecycles, performance metrics, and retraining triggers.
- Regulatory Alignment: Maintain traceability between clauses and system logic.
- Explainability Standards: Ensure stakeholder-appropriate explanations.
- Operational Monitoring: Continuous drift detection and retraining workflows.
- Human Oversight: Retain expert review for high-risk exceptions.
Compliance Reports and Audit Trail Outputs
Upon completion of validations, the system generates compliance reports and audit trails that underpin regulatory transparency and audit readiness.
Report Composition
- Regulatory Submission Reports aligned with IFRS, GAAP, and Basel III
- Exception and Anomaly Reports detailing policy breaches
- Risk Assessment Summaries produced by AI engines
- Control Effectiveness Dashboards summarizing adherence rates and remediation actions
Audit Trail Architecture
- Immutable Log Records with timestamps, identifiers, and cryptographic signatures
- Metadata Enrichment capturing data sources, rule versions, and AI model details
- Cross-Stage Linkage referencing ingestion, transformation, and analytics logs
- Searchable Indexes optimized for rapid retrieval via services like IBM Watson OpenScale
Dependencies and Handoff
- Regulatory Reference Libraries from internal and external providers
- Transformation and Validation Metadata from cleansing stages
- Analytics and Risk Scores from AI-powered agents
- Temporal and Version Controls for consistency across systems
Final compliance dossiers and audit manifests are delivered to collaborative review via secure message queues, task orchestration APIs, versioned storage references, and automated alerts highlighting high-risk exceptions. This handoff ensures that evidence is comprehensive, accessible, and ready for human review and secure distribution.
Chapter 8: Collaborative Review and Approval Workflow
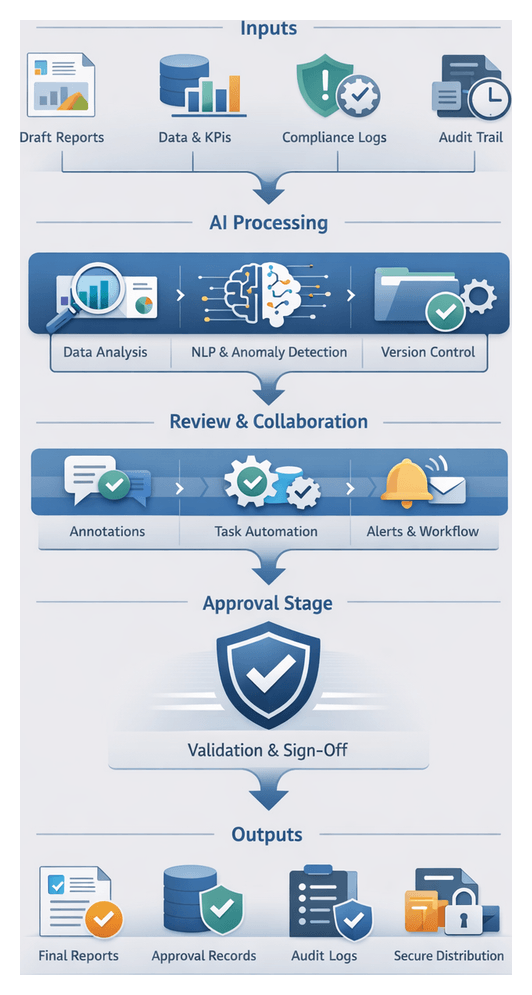
Review Stage Purpose and Submission Inputs
The collaborative review and approval stage represents the convergence of automated reporting outputs with structured human oversight. In financial reporting for banking and finance organizations, this stage validates narratives, data visualizations, and compliance controls generated by upstream AI-driven workflows. By embedding human-in-the-loop processes, the review stage mitigates residual automation risks, preserves transparent audit trails, and establishes accountability for final sign-off. This integration of operational efficiency with governance imperatives accelerates close cycles while maintaining rigorous internal and regulatory compliance.
Specialized teams—finance, risk management, internal audit, and external advisors—must align on a single authoritative report. The review stage orchestrates this alignment through structured interfaces for annotating drafts, resolving queries, and capturing approval decisions. Domain experts refine narrative tone, verify assumptions, and confirm regulatory disclosures. Integrated AI-driven alerting and collaboration agents enhance visibility, monitor overdue tasks, summarize outstanding comments, and escalate bottlenecks. The outcome is a structured, efficient, and auditable approval process that bridges automated intelligence with human expertise.
- Draft Report Package: Assembled narrative, tables, charts, and compliance disclosures in preliminary layouts, produced by the dynamic report assembly engine and formatted for both PDF and online dashboards.
- Analytical Output Summaries: Underlying data sets, KPIs, trend analyses, and anomaly reports generated by AI-powered analytics, referenced by reviewers to validate assertions and metrics.
- Compliance Exception Logs: Lists of flagged regulatory or policy exceptions with descriptions, severity scores, and remediation recommendations to guide assessment.
- Audit Trail Metadata: Time-stamped records of automated and manual actions—version changes, comments, and approval events—supporting tamper-evident tracking for audits.
- Version Control References: Identifiers for baseline and subsequent document versions, enabling automated comparison of changes, highlighted additions, and redactions.
- Reviewer Roster and Roles: Stakeholder assignments and approval hierarchies sourced from identity and access management systems, ensuring role-based permissions.
- Annotation and Collaboration Artifacts: Templates for in-document comments, issue tickets, and workflows, often integrated with platforms to facilitate seamless stakeholder dialogue.
Prerequisites and Conditions
- Identity and Access Management: Robust IAM frameworks—integrated with Microsoft Azure AD or Okta—provision reviewer accounts and enforce least-privilege access.
- Review Platform Integration: Collaboration platforms or document management systems connected via APIs to host artifacts, track annotations, and manage versions.
- Workflow Orchestration and Notifications: Automated triggers initiate review tasks when upstream stages complete, with notification rules across email, messaging apps, or dashboards.
- Template and Style Guide Availability: Centralized access to branding guidelines, tone lexicons, and regulatory disclosure templates, linked to report assembly tools for consistency.
- Data Freeze and Change Control: Locking of data inputs at handoff, with post-freeze adjustments following documented change control protocols and re-approval requirements.
- Immutable Audit Environment: Secure, append-only logs capturing all actions to support compliance reporting and forensics.
- SLAs and Escalation Protocols: Defined turnaround times, permitted review cycles, and escalation pathways to senior executives when deadlines risk delay.
Annotation and Version Control Flow
Annotation and version control form the backbone of collaborative review, ensuring each comment, edit, and resolution is captured for traceability and audit readiness. Stakeholders interact with draft reports to provide contextual remarks, while AI-driven agents route annotations, suggest corrections, and enforce versioning policies. This coordinated flow delivers a seamless, compliant review cycle.
Annotation Process Overview
Once analytics outputs, narratives, and compliance checks converge into a draft report, the following AI-enhanced sequence unfolds:
- Distribute Review Packages: Links to the report draft and supporting materials are sent to designated reviewers based on roles and permissions.
- Enable Inline Commenting: Secure interfaces allow reviewers to highlight, comment, and markup specific paragraphs, charts, or tables.
- Capture Metadata: Each annotation is tagged with reviewer identity, timestamp, context tags (risk, compliance, narrative), and references to regulations.
- Suggest Automated Resolutions: AI agents detect common issues—terminology inconsistencies or style deviations—and propose corrective actions.
- Assign Action Items: Critical annotations generate workflow tasks with deadlines and assigned parties, tracked by the orchestration engine.
Version Control Coordination
Maintaining a coherent edit history is essential. The system applies these mechanisms:
- Snapshot Creation: Each review iteration triggers a snapshot of content, annotations, and metadata.
- Change Tracking: Deltas between snapshots are recorded, logging additions, deletions, and modifications at granular levels.
- Conflict Detection: AI agents identify conflicting edits by comparing contexts and recommended text changes.
- Merge Assistance: Side-by-side views highlight differences, and natural language models suggest optimal merged versions in line with style and compliance rules.
- Approval Gates: Consolidated versions lock in changes, update the version number, and notify stakeholders of readiness for sign-off.
System Interactions and Integrations
- Document Management API: Authenticated endpoints for uploading drafts, retrieving snapshots, and storing annotation metadata, logged for audit.
- Workflow Engine Connector: Triggers tasks when annotations reach severity thresholds and escalates overdue items.
- AI Collaboration Agent: Integrates with NLP models to analyze annotations, retrieve style guides, and historic resolution patterns from knowledge bases.
- Notification Service: Sends alerts via email, messaging platforms, or in-app notifications for pending actions and updates.
- Audit Logging Service: Consolidates logs from API requests, annotation submissions, merge operations, and approval transitions.
Two-way synchronization with external platforms preserves a single source of truth:
- Link Synchronization: Updated report links propagate to collaboration workspaces.
- Comment Ingestion: External annotations import back into the central repository, preserving metadata.
- Task Alignment: Workflow engine tasks mirror tickets in project boards, ensuring cross-team coordination.
AI Facilitation of Collaboration and Alerts
Advanced AI agents transform manual coordination into a dynamic, intelligent workflow. Through natural language processing, machine learning, and event-driven orchestration, these agents take on critical roles in task assignment, progress monitoring, alert generation, and contextual insight delivery.
Task Orchestration
- Automated Assignment: AI engines route report sections to qualified reviewers based on profiles, expertise, and historical performance.
- Load Balancing: Models predict reviewer capacity from calendars and workloads, dynamically reallocating tasks to prevent delays.
- Priority Scheduling: High-criticality items—such as compliance checklists or material variance explanations—are fast-tracked for review.
Intelligent Notifications and Alerts
- Anomaly Detection Alerts: AI agents flag discrepancies—conflicting comments, missing data sources, outdated references—and notify stakeholders.
- Deadline Reminders: Time-aware engines send escalating alerts via in-app notifications, Microsoft Teams, or SMS as tasks near due dates.
- Escalation Protocols: Overdue tasks automatically escalate to supervisors or compliance officers to maintain momentum.
Contextual Insight Delivery
- Automated Summaries: Natural language generation with OpenAI GPT-4 condenses analyses into concise bullet points highlighting variances and risks.
- Sentiment Analysis: Microsoft Azure Cognitive Services or IBM Watson Natural Language Understanding evaluate comment tone and urgency for prioritization.
- Regulatory Reference Linking: AI knowledge graphs map sections to IFRS or SEC rules, providing contextual links during review.
- Trend Comparison Insights: Machine learning modules surface historical and peer benchmarks within the review interface.
Platform Integrations
- Messaging Connectors: AI agents send interactive notifications to Slack GPT or Microsoft Teams for in-context approvals.
- Document Collaboration: Intelligent assistants monitor Google Docs changes and trigger downstream validation checks.
- Enterprise Workflow Platforms: AI-orchestrated tasks embed within ServiceNow or Jira, auto-populating tickets with metadata and direct action links.
Technologies and Continuous Improvement
- NLP Engines: Models fine-tuned on financial corpora extract entities, sentiment, and regulatory terms from unstructured text.
- ML Orchestration: Platforms like Kubeflow or MLflow manage deployment, versioning, and inference of task-routing and anomaly-detection models.
- Event-Driven Middleware: Brokers such as Apache Kafka or Azure Event Grid handle real-time streams, triggering AI workflows on defined events.
- Audit Logging and IAM: Immutable logs capture AI actions, while secure authentication ensures data privacy.
- Performance Telemetry and Feedback: Dashboards track review metrics; user ratings refine NLP and classification models through retraining pipelines.
Approval Outputs and Handover to Distribution
Upon final sign-off, the workflow produces definitive artifacts ready for secure delivery. These outputs encapsulate approvals, version histories, and compliance records, establishing a solid foundation for distribution.
Key Outputs
- Signed-Off Report Documents: Finalized reports in PDF, interactive dashboard, and spreadsheet formats, bearing digital signatures or electronic approval stamps for non-repudiation.
- Approval Metadata: Structured data files capturing reviewer identities, timestamps, approval statuses, and residual comments for audit trails.
- Version-Controlled Artifacts: Stored in repositories—such as Git or Workiva—with full change histories for rollback or audits.
- Compliance and Exception Logs: Documented exceptions, waivers, and manual overrides with remediation details for risk officers’ review.
- Handover Trigger Files: Machine-readable messages that instruct downstream systems to initiate secure distribution workflows.
Dependencies and Preconditions
- Complete narrative, charts, tables, and compliance attestations must be integrated without unresolved content blocks.
- All designated reviewers must have submitted explicit approvals or escalations, verified by the workflow engine.
- Audit trail completeness in version control systems—such as Workiva or Git—ensures reconstructable decision paths.
- Final regulatory clearances—Sarbanes-Oxley attestations, GDPR reviews, Basel III disclosures—must be closed with no open exceptions.
Integration with Distribution Orchestration
- Event-Driven Triggers: “reportApproved” events emitted to Azure Logic Apps or AWS Step Functions initiate packaging and encryption routines.
- API-Based Handover: RESTful calls to distribution platforms include artifact references, approval metadata, recipient lists, and encryption keys, standardized via AgentLink AI connectors.
- Workflow Continuation Tokens: Correlation IDs persist through distribution, enabling end-to-end monitoring and status reporting.
Governance and Traceability
- Audit Trail Consolidation: Central repositories aggregate logs from review, version control, and sign-off processes, providing auditors a unified view.
- Chain of Custody Records: Detailed custody logs document system and individual interactions with artifacts at each stage.
- Tamper-Proof Signatures: PKI or blockchain anchors detect post-distribution modifications and trigger alerts.
- Retention Policies: Automated classification engines tag artifacts with retention schedules, enforced by platforms like Microsoft Purview.
Key Tool Integrations and Automation Points
- Workiva Collaboration Platform: Integrates version control, approvals, and compliance tracking with API hooks to detect sign-offs and extract artifacts.
- UiPath Secure Handover Bots: RPA bots package finalized reports into encrypted containers and upload to secure portals, feeding logs back to governance repositories. Visit for more.
- DocuSign eSignature Integration: Embeds legally binding signature fields into reports and returns signed documents with certificates. Visit for details.
Metrics for Handover Effectiveness
- Handover Latency: Time elapsed between final approval and distribution initiation; low latency indicates seamless integration.
- Transfer Success Rate: Percentage of hand-off events that trigger downstream workflows without human intervention.
- Exception Rate: Frequency of errors or manual interventions—missing artifacts or failed API calls—highlighting workflow improvement areas.
- Audit Query Resolution Time: Average time to respond to audit queries regarding approval artifacts, reduced by effective traceability controls.
Chapter 9: Secure Distribution and Access Management
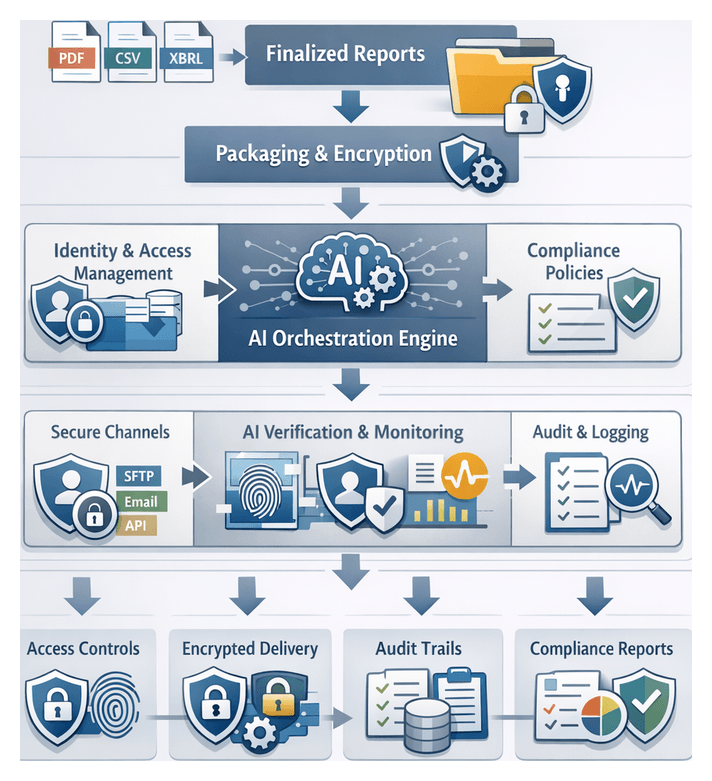
Distribution Stage Security and Objectives
The distribution stage is the culminating link in an end-to-end automated financial reporting workflow. Its purpose is to deliver finalized, compliance-approved financial reports securely to authorized internal and external stakeholders. In regulated finance and banking environments, preserving confidentiality, integrity, and availability during transmission is non-negotiable. A robust distribution workflow transforms assembled report packages into encrypted, policy-enforced deliverables, orchestrates their secure delivery, and generates comprehensive audit trails to satisfy both internal governance and external regulatory requirements.
The primary objectives of this stage are to:
- Ensure secure delivery of financial reports to authorized recipients in accord with organizational policies and regulatory mandates.
- Enforce encryption standards and access controls to prevent unauthorized disclosure of report contents, both in transit and at rest.
- Authenticate and verify recipient identities using multi-factor mechanisms and AI-driven risk assessments.
- Produce tamper-proof audit logs and traceability records demonstrating compliance with frameworks such as GDPR, SOX, FINRA, and SEC regulations.
- Support multiple distribution channels—secure email, SFTP, APIs, messaging systems, and secure portals—while maintaining a consistent security posture.
- Integrate seamlessly with upstream workflow stages, ensuring only approved and compliance-cleared artifacts are distributed.
Delivery Workflow and Access Orchestration
The delivery workflow orchestrates packaging, encryption, routing, and access control into a unified sequence of actions. It coordinates report assembly engines, encryption services, messaging buses, identity providers, and audit loggers to enforce compliance policies, manage distribution preferences, and maintain end-to-end traceability.
Packaging and Encryption Sequence
After report assembly produces finalized deliverables—PDF documents, data extracts (CSV or XBRL), metadata files, and assets—the orchestrator invokes a packaging module. Files are grouped into secure containers, compressed, and tagged with metadata (report date, version, recipient IDs) that drive downstream access policies and audit records.
An encryption service is then called via API. Common implementations include:
- Unified encryption and key management.
- AWS Key Management Service for envelope encryption with customer-managed keys.
- Azure Key Vault for HSM integration and role-based key access.
- HashiCorp Vault for on-premise secrets management and dynamic key rotation.
The orchestrator supplies encryption context—algorithm choices (AES-256, RSA-2048), key identifiers, and digital signature parameters. The service returns an encrypted container and a cryptographic signature, which the orchestrator validates to guarantee data integrity and non-repudiation.
Channel Routing and Protocol Management
With encryption complete, the orchestrator selects the distribution channel based on recipient profiles. Supported protocols include:
- Secure File Transfer Protocol (SFTP)
- Encrypted email delivery using S/MIME or PGP
- RESTful API calls to client applications or partner portals
- Publish/subscribe messaging via Apache Kafka or RabbitMQ
- HTTPS-based secure portals with token authentication
The orchestrator retrieves connection details from a channel registry—hosts, ports, credentials, routing rules—and establishes sessions in parallel or sequence, aligned with SLA requirements. Real-time monitoring tracks transfer status; retry logic with exponential backoff handles transient failures, and critical errors trigger automated alerts to operations teams with contextual diagnostics.
Integration with Identity and Access Management
Ensuring that only authorized users decrypt and view reports requires tight integration with identity platforms such as Okta, Azure Active Directory, or Ping Identity. When recipients access reports—via portal, API, or email link—their identity tokens are validated. High-sensitivity report classes can enforce multi-factor authentication, and attribute-based access control evaluates contextual factors such as time, geolocation, and device posture before releasing decryption keys.
Secure portals generate single-use, time-bound URLs embedding encrypted context. Portal proxies validate access tokens, retrieve encrypted packages from object stores or file shares, and stream decrypted content to clients without persisting intermediates on disk.
Monitoring, Auditing, and Error Remediation
Each workflow action emits audit events to centralized logging and monitoring platforms like Splunk, Elastic Stack, or Azure Monitor. Recorded events include package creation, encryption operations, channel session status, authentication events, and user access attempts. These logs feed dashboards and automated alerts that detect anomalies—unexpected access patterns, repeated failures, or irregular volume spikes—and provide evidence of compliance during audits.
Error handling follows a structured remediation workflow:
- Encryption Errors: Retry with fresh key context or trigger key rotation in the secrets manager.
- Transfer Failures: Reroute to alternate endpoints or notify administrators via email, SMS, or collaboration platforms.
- IAM Policy Conflicts: Route exception requests to compliance officers for manual override.
- Integrity Violations: Quarantine affected packages, alert security operations, and initiate re-issuance.
All remediation actions are recorded in the audit trail. AI-driven analytics surface recurring error patterns and recommend workflow optimizations to reduce manual interventions.
Scalability and Cross-System Coordination
To meet peak distribution loads, the orchestrator scales horizontally using stateless microservices, auto-scaling compute clusters, and message buses. Caching of IAM tokens and encryption contexts with defined TTL controls, along with intelligent load balancing, ensures sub-minute latency for critical deliveries.
Strict API contracts, standardized message schemas (JSON or Avro), and robust error-handling protocols coordinate dependencies among:
- Report assembly engines
- Secrets management services
- Identity providers
- Messaging and file transfer infrastructure
- Monitoring and SIEM platforms
AI-Driven Identity Verification and Continuous Monitoring
AI technologies augment traditional authentication with identity proofing, adaptive risk scoring, and behavioral analytics, strengthening confidentiality and auditability across the distribution pipeline. These AI agents integrate with IAM and SIEM systems to authenticate users, detect anomalies in real time, and adapt access policies dynamically.
Identity Proofing with Document and Biometric Analysis
New or infrequent users undergo AI-powered identity proofing before receiving access privileges. Solutions from Jumio and Onfido leverage computer vision and OCR to validate government IDs, detect security features, and extract data fields. Biometric engines perform liveness checks—blink detection, head movement analysis—and match facial features to document photos, establishing a cryptographic binding between user identities and encryption keys.
Adaptive Authentication and Risk Scoring
AI-powered risk engines evaluate contextual signals—geolocation, device fingerprint, access history, network attributes—and assign risk scores using supervised learning models. Conditional access policies then adjust authentication requirements:
- Low-risk: Standard multi-factor authentication
- Medium-risk: Step-up challenges such as one-time passcodes or biometric re-verification
- High-risk: Automatic blocking or human review escalation
This adaptive approach, supported by platforms like Okta and Azure Active Directory conditional access, balances security with user experience.
Behavioral Analytics for Continuous Monitoring
Behavioral biometrics models establish usage baselines by analyzing mouse movements, typing cadence, scroll patterns, and download behavior. Unsupervised learning algorithms cluster activity sequences to detect anomalies—rapid page navigation, unusual download volumes, or atypical device usage—and trigger automated responses such as session throttling, re-authentication prompts, or access token revocation. Incident tickets are generated in SIEM platforms such as IBM QRadar for further investigation.
Integration and Continuous Model Training
AI identity and monitoring services synchronize risk attributes into IAM directories and feed alerts to SIEM platforms. Continuous training pipelines ingest labeled data—fraud cases, false positive feedback, behavior changes—to refine detection models. Feedback loops from compliance reviews and support interactions calibrate risk thresholds and improve user experience, ensuring the system adapts to evolving threat landscapes.
Secure Report Access, Traceability, and Handoff Protocols
At the endpoint of distribution, generating comprehensive access and traceability records provides the forensic evidence needed for audits, regulatory reviews, and continuous security monitoring. Standardized, machine-readable artifacts ensure seamless ingestion by analytics systems and long-term archives.
Output Artifacts
- Access Log Files: Timestamped records of user and system requests with identity, report ID, channel, and geolocation.
- Traceability Manifests: Documents mapping report versions, batches, and delivery channels to recipient lists.
- Audit Trail Exports: Aggregated summaries in CSV, JSON, or XML aligned with governance frameworks.
- Metadata Indexes: Registries of checksum values, encryption key identifiers, and token exchanges.
- Encryption and Key Usage Logs: Records of cryptographic operations, key rotations, and decryption events.
Dependencies and Data Sources
- Identity and Access Management (Okta, Azure Active Directory, LDAP directories)
- Encryption Key Vaults (AWS Key Management Service, Azure Key Vault)
- Orchestration Engines
- Network and Gateway Proxies (SFTP servers, HTTPS gateways, API proxies)
- Compliance Policy Repositories
- Time Synchronization Services (NTP servers)
Handoff to Continuous Monitoring
- Event Streaming to SIEM: Real-time feeds into platforms like Microsoft Azure Sentinel via webhooks or pub/sub channels.
- Dashboard Ledger Updates: Publishing traceability manifests and metadata indexes to monitoring dashboards.
- API Consumption: Secure REST endpoints allow monitoring agents to pull audit records on demand.
- Scheduled Batch Exports: Nightly exports of access logs to secure storage for offline analytics and model retraining.
- Notification Triggers: Alerts signaling availability of new traceability data for scheduled analysis.
AI-Enhanced Visibility and Long-Term Archiving
- Behavioral Baseline Modeling: Machine learning models analyze historical logs to establish normal usage patterns and flag deviations.
- Automated Anomaly Flagging: AI listeners surface bulk downloads, repeated authentication failures, and other high-risk events.
- Causal Attribution: NLP agents correlate log metadata into coherent incident narratives for rapid triage.
- Immutable Storage and Archiving: Append-only storage or blockchain-backed ledgers ensure tamper resistance; retention policies automate lifecycle management.
- Indexed Search and Retrieval: Metadata indexes enable fast querying of archived records for audit and investigation.
Data Privacy, Masking, and Continuous Improvement
Traceability records often contain sensitive personal information. Field-level encryption, anonymization, and pseudonymization protect personally identifiable data, while role-based policies control access to unmasked archives. Masking processes themselves are logged to maintain end-to-end visibility into data privacy transformations.
By feeding rich access logs and traceability artifacts into continuous monitoring and iterative improvement frameworks, organizations cultivate a feedback-driven security posture. Analytics teams and AI agents leverage these records to refine distribution workflows, optimize policies, and anticipate emerging threats, ensuring a resilient, compliant, and operationally efficient financial reporting ecosystem.
Chapter 10: Continuous Monitoring and Iterative Improvement
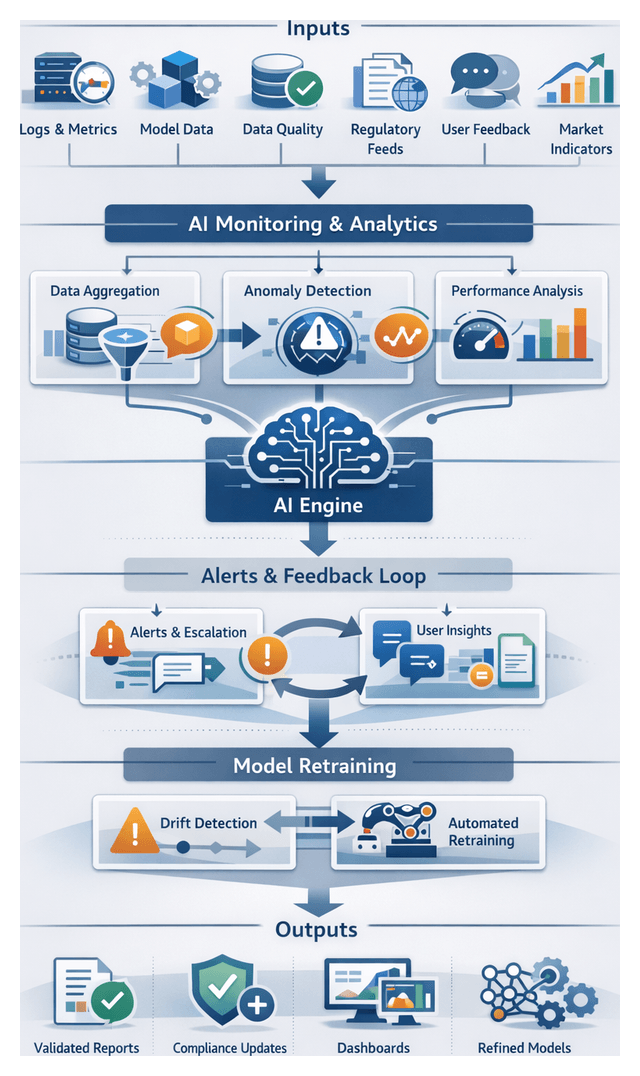
Monitoring Stage Objectives and Scope
The monitoring stage establishes a continuous feedback loop that transforms automated financial reporting into a self-improving process. Its goals are to maintain data integrity, measure workflow performance, assess AI model efficacy, capture end-user satisfaction and detect compliance deviations in real time. By defining clear objectives—such as tracking schema changes, monitoring job runtimes, evaluating prediction accuracy and gathering qualitative feedback—finance organizations gain a holistic view of the reporting pipeline’s operational health and can swiftly initiate corrective actions when thresholds are breached.
Inputs and Prerequisites for Effective Monitoring
Effective monitoring hinges on comprehensive inputs from diverse system components and stakeholder interactions, as well as foundational prerequisites that ensure data capture is accurate, actionable and secure.
- Workflow Orchestration Logs: Emitted by platforms such as Apache Airflow, capturing task schedules, execution statuses and retry events.
- Model Tracking Metadata: Stored in MLflow or similar registries, including version identifiers, training parameters, deployment timestamps and performance metrics.
- System Telemetry and Infrastructure Metrics: Collected via Prometheus, Datadog or Splunk Metrics, reporting CPU, memory, disk I/O and network throughput for capacity planning and bottleneck detection.
- Data Quality Dashboards: Generated by validation frameworks to surface missing values, schema mismatches, anomaly scores and upstream source availability across ERP systems, trading platforms and market feeds.
- Regulatory Reference Feeds: Structured updates from bodies such as FASB or international regulators, ensuring generated disclosures align with the latest accounting standards and taxonomy changes.
- User Feedback Channels: Qualitative input from finance teams, auditors and executives via collaboration platforms and issue-tracking systems, capturing clarification requests and narrative suggestions.
- Report Consumption Analytics: Metrics on view counts, export frequencies and time-to-first-insight from report portals or dashboards to guide format and delivery improvements.
- External Market Indicators: Data such as volatility indices, credit spreads and macroeconomic statistics that influence financial models and support proactive recalibration.
Key prerequisites include standardized instrumentation and logging frameworks adhering to open telemetry, established baseline performance metrics for anomaly detection, a centralized model registry for version control (for example, MLflow’s Model Registry), configured feedback submission workflows, robust security and access controls, integrated alerting and notification mechanisms, a formalized regulatory change management process and clear governance with defined ownership for monitoring oversight and incident response.
Performance Metrics and Feedback Workflow
The feedback workflow translates raw monitoring data and user observations into actionable insights through a structured sequence:
- Data Aggregation: Monitoring agents collect telemetry from ingestion, transformation, analytics and narrative stages, normalizing it in a time-series database or data lake.
- Feature Extraction: Computation of KPIs—such as average ingestion latency, anomaly flag rates, narrative revision counts and model inference throughput—on a scheduled basis.
- Anomaly Detection: Application of statistical thresholds and machine learning detectors to identify deviations, for example a surge in cleansing exceptions or drop in narrative acceptance.
- Feedback Correlation: Alignment of user feedback (ratings, comments, approval delays) with system metrics to isolate root causes of quality or performance issues.
- Escalation and Notification: Automatic alerting via email, chatops or incident management systems when thresholds are breached, assigning tasks to data engineers, ML specialists or finance operators.
- Action Tracking: Ticketing of each remediation effort, linking anomalies to updated models, rules or configurations and capturing closure statuses.
This coordinated workflow ensures rapid issue identification, clear ownership of corrective actions and continuous alignment with regulatory requirements and business priorities.
Drift Detection and Automated Model Retraining
Over time, shifts in market conditions, regulatory updates or transactional behaviors can degrade model performance. The system employs advanced AI and statistical methods to detect drift—changes in input distributions (data drift), in relationships between inputs and targets (concept drift) or in upstream processes (pipeline drift)—and to trigger automated retraining workflows.
Monitoring frameworks such as MLflow and Kubeflow log feature statistics, model predictions and performance metrics in real time. AI agents then apply methods including Population Stability Index, Kullback-Leibler Divergence, autoencoder-based anomaly detection and ensemble detectors such as DDM (Drift Detection Method) or ECDD (Early Concept Drift Detection). Integrating business rules—such as new lease accounting triggers under IFRS 16—enhances precision by incorporating domain expertise into drift logic.
When drift thresholds are exceeded, an automated retraining pipeline invokes:
- Data Snapshot Selection: Retrieval of representative historical and recent data batches, versioned via tools like TensorFlow Data Validation and MLflow Tracking.
- Feature Engineering Update: Recalculation of derived metrics in feature stores to reflect observed data shifts.
- Model Recalibration: Distributed training workflows with hyperparameter tuning powered by SageMaker Hyperparameter Tuning to optimize model variants.
- Performance Validation: Backtesting and benchmark evaluations to verify accuracy and compliance before deployment.
- Canary Deployment: Controlled rollout on a subset of live data to compare outputs against staging models.
- Full Promotion: Replacement of production models with retrained versions, supported by rollback plans.
CI/CD platforms such as IBM Watson OpenScale and Kubeflow automate packaging, testing and deployment while maintaining audit trails. Metadata catalogs like Databricks Unity Catalog capture lineage across data sources, feature transformations and model versions. Post-deployment, AI operations platforms adjust monitoring sensitivity based on observed stability or volatility, completing an iterative feedback loop that preserves model integrity and governance.
Process Refinements and Updated Workflow Outputs
Insights from monitoring and drift detection yield refinements across connectors, cleansing rules, mapping logic, analytic models, narrative templates and report layouts. Each refinement produces versioned artifacts that feed back into upstream stages, ensuring controlled evolution of the reporting ecosystem.
- Retrained AI models with serialized binaries, updated feature definitions and validation reports.
- Revised transformation and mapping rules—chart of accounts associations, classification thresholds and normalization parameters—captured as configuration files or rule-engine scripts.
- Enhanced narrative templates with updated content blocks, compliance checks and language model fine-tuning parameters.
- Versioned pipeline specifications for orchestration engines—DAGs in Apache Airflow or pipelines in Kubeflow—reflecting new tasks, dependencies and schedules.
- Comprehensive change logs and impact assessments documenting rationale, test results and approval records.
- Updated dashboards and alert configurations for early detection of regressions.
Each artifact relies on dependencies such as monitoring data stores, Git repositories housing transformation scripts and templates, model registries like MLflow, orchestration engines and compliance frameworks. Refinements pass through validation gates—unit and integration tests, back-testing, domain expert reviews and security assessments—before automated handoffs to downstream systems. Model artifacts are published to the registry, configuration updates trigger CI/CD pipelines, templates are versioned in the NLG engine and pipeline definitions deploy via orchestration APIs. Documentation portals record change logs and approval artifacts, preserving audit readiness.
By embedding governance—unique change identifiers, immutable audit logs, metadata tagging and archival of superseded artifacts—organizations maintain traceability and accountability. Updated connectors, cleansing workflows, transformation pipelines, scoring sequences and narrative generation processes reenter the workflow, completing a continuous improvement cycle that accelerates reporting accuracy, shortens close cycles and fortifies compliance posture in an evolving market landscape.
Conclusion
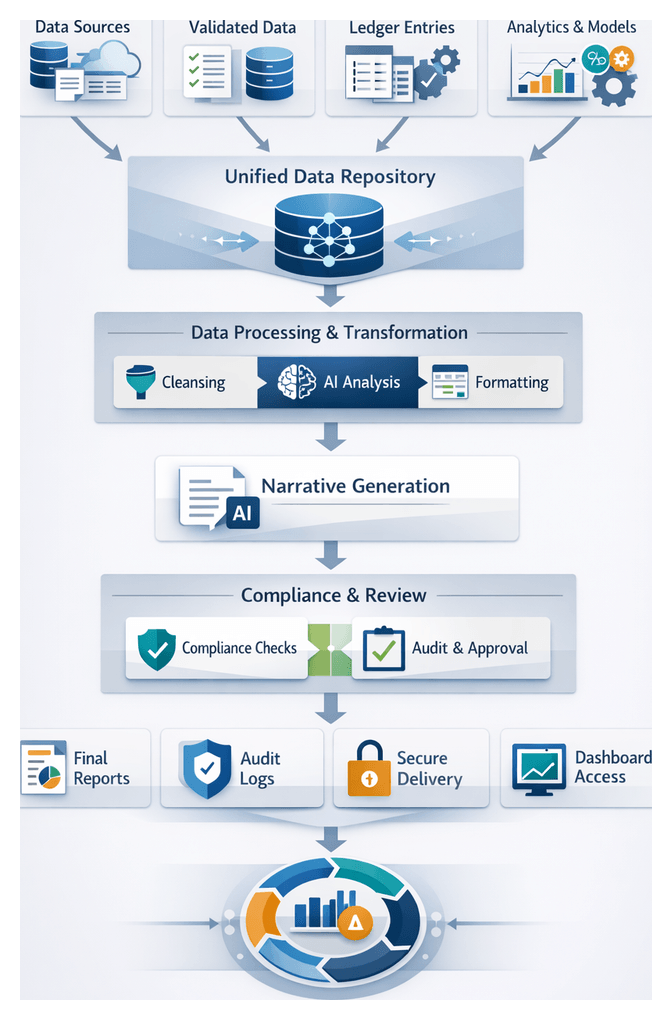
Workflow Recap from Data to Distribution
An end-to-end AI-driven financial reporting workflow demands transparency, traceability, and alignment with organizational objectives. The recap stage consolidates all outputs and artifacts—from raw data ingestion through cleansing, transformation, analytics, narrative generation, assembly, compliance checks, review, and distribution—into a unified checkpoint. This structured convergence ensures data integrity, confirms adherence to regulatory and internal policies, and prepares comprehensive documentation for governance and audit readiness, without introducing new transformations or analyses.
Key inputs for this stage include:
- Unified Data Repository with timestamped source references and data lineage metadata
- Validated Datasets bearing quality metrics, error correction logs, and enrichment annotations
- Structured Ledger Outputs mapped to standard chart of accounts and regulatory classifications
- Analytical Insights and Metrics such as anomaly alerts, trend forecasts, key performance indicators, model versioning, and confidence scores
- Narrative Drafts generated by natural language engines and tagged for context, tone, and disclosure requirements
- Assembly Templates and Layouts reflecting branding guidelines and multi-format readiness
- Compliance Documentation including rule validation reports, risk scores, exception logs, and audit trails
- Review and Approval Logs capturing annotations, version histories, sign-off timestamps, and reviewer comments
- Distribution and Access Records detailing encryption metadata, access controls, delivery timestamps, and authentication events
- Monitoring Feedback Summaries consolidating performance metrics, user feedback, and model drift indicators
Prerequisites for executing the recap stage include finalized outputs from all prior phases, formal sign-offs and change-control approvals, consistent version control and metadata tagging, comprehensive audit trails, resolution of critical exceptions, and availability of stakeholder representatives for alignment on quality metrics and readiness.
Stakeholder deliverables are tailored to each audience:
- Finance Leadership receives executive summaries of cycle times, error rates, and risk exposure.
- Regulatory and Compliance Teams review detailed audit trails and exception logs.
- Operational Managers assess throughput metrics, resource utilization, and bottlenecks.
- IT and Data Governance personnel validate data lineage, metadata consistency, and security adherence.
- External Auditors examine evidence sets supporting each reporting element.
- Business Analysts leverage consolidated insights to inform strategic initiatives.
Analytical benefits of the recap stage extend beyond artifact aggregation:
- Quantitative Assessment of Workflow Performance through comparative cycle-time and error-rate analyses.
- Risk Exposure Visualization highlighting recurring exception types and compliance vulnerabilities.
- Continuous Improvement Insights with data-driven recommendations for refining AI models and validation rules.
- Enhanced Audit Readiness via pre-packaged evidence sets and reconciliation reports.
- Strategic Decision Support using high-level dashboards and narrative briefs for executive leadership.
Efficiency and Accuracy Benefits Realized
AI-driven automation transforms the financial close cycle by orchestrating ingestion connectors, cleansing agents, transformation engines, analytics modules, narrative generators, compliance controls, and distribution workflows in a unified pipeline. Connectors invoke APIs on schedule, normalize schema variations, and load data into a centralized repository monitored by AI agents. Machine learning–driven anomaly detectors and rules-based filters ensure data quality before transformation engines convert raw ledger entries into structured formats aligned with accounting standards.
Analytics frameworks select models, engineer features, and execute batch or real-time scoring. By centralizing model orchestration in a platform such as DataRobot, organizations eliminate manual deployment delays and maintain continuous integration of new scoring code. Natural language generation engines from platforms like IBM Watson assemble compliant narrative drafts with domain-tuned language models. Report assembly algorithms merge charts, tables, and text into branded templates optimized for multiple formats, with AI agents validating final outputs against style guides.
Integrated compliance controls run in parallel, validating regulatory requirements and capturing every interaction in centralized audit logs. Exceptions route automatically to compliance officers, while human reviewers use embedded annotation tools and version control systems to resolve queries. Secure distribution modules package reports into encrypted containers, enforce role-based access controls, and deliver outputs through portals or email, with continuous monitoring agents generating traceability logs.
Collectively, these orchestrated interactions yield:
- Accelerated Close Cycles: Compressing financial close from weeks to days or hours.
- Reduced Manual Effort: Eliminating spreadsheet reconciliations, copy-paste errors, and manual publishing tasks.
- Improved Data Quality: Enforcing integrity through machine learning anomaly detection and rules-based validation.
- Enhanced Auditability: Centralized logs and traceable AI workflows supporting audits.
- Scalable Operations: Elastic scaling of modular AI services for peak workloads.
- Consistent Compliance: Embedded regulatory checks ensuring adherence to latest standards.
- Seamless Collaboration: Synchronized human and machine tasks reducing review bottlenecks.
- Secure Delivery: Automated encryption, identity verification, and access monitoring.
Orchestration platforms provide unified dashboards for workflow monitoring, real-time error handling, and capacity planning. Automated feedback loops capture confidence scores and route low-confidence tasks to human experts, feeding annotations back into training datasets to continuously improve AI performance and trust.
Strategic Impact of AI-Driven Reporting
Embedding AI at every stage of the reporting workflow elevates financial reports from static deliverables to dynamic decision-support artifacts. Continuous analytics and narrative generation deliver near-real-time visibility into performance indicators, liquidity positions, capital adequacy, and risk exposures. By reducing latency, finance teams collaborate with treasury, risk management, and commercial functions to run scenario simulations and stress tests on demand, fostering a data-driven decision culture.
Enhancing Risk Management and Regulatory Resilience
Machine learning risk-scoring models flag deviations, quantify exposures, and identify concentration risks across portfolios. Automated compliance controls apply complex rule sets—from Basel III requirements to local accounting standards—generating standardized exception reports with full audit trails. Institutions demonstrate end-to-end transparency during regulatory inquiries, minimizing penalties and reputational risk.
Driving Operational Agility and Scalability
Modular AI architectures scale processing capacity elastically, eliminating the need for headcount expansion during peak periods. Rapid deployment of new connectors and self-learning normalization models enable finance teams to incorporate alternative data sources—such as digital assets or market sentiment feeds—without extending close cycles or introducing bottlenecks.
Optimizing Costs and Resource Allocation
Automating repetitive tasks and reducing error-remediation costs yield significant savings. Data validations, anomaly checks, and narrative drafting shift from labor-intensive manual work to AI-supervised workflows, freeing teams for strategic analysis and performance optimization.
Strengthening Competitive Differentiation and Innovation
Timely, accurate disclosures foster trust among investors, regulators, and customers. AI-driven reporting enables on-demand reports and client-facing analytics, unlocking new services such as real-time portfolio updates and liquidity forecasts. Reusable AI components support bespoke reporting for structured transactions or sustainability disclosures, and aggregated insights inform product development and strategic partnerships.
Elevating Transparency and Stakeholder Trust
Detailed audit trails document every decision, transformation, and review step. Version control logs, annotation histories, and exception justifications accompany final reports, ensuring defensibility and traceability. Regulators and auditors gain access to machine-readable compliance reports, reducing validation times and setting new benchmarks for accountability.
Strategic benefits include accelerated decision cycles, enhanced risk management, scalable architectures, reduced costs, competitive differentiation, innovation platforms, and strengthened stakeholder trust, positioning finance teams as forward-looking strategists.
Future Adaptability and Solution Reuse
A modular AI-driven reporting architecture provides a foundation for continuous innovation. Well-defined artifacts produced at each stage encapsulate logic, metadata, and configuration in reusable form:
- Data Connector Templates: Parameterized configurations for ERP, trading system, market feed, and external table integrations, cloneable for new sources.
- Cleansing and Validation Rule Sets: Versioned libraries articulating anomaly thresholds, standardization formats, and enrichment routines.
- Transformation Mappings and Knowledge Graph Schemas: Externalized mapping tables and graph definitions for chart of accounts, taxonomies, and inter-entity relationships.
- Analytical Model Artifacts: Exported machine learning models (ONNX or PMML) with feature pipelines, drift monitors, and retraining triggers.
- Natural Language Generation Templates: Disclosure libraries organized by report type, audience, and compliance requirement, supporting multi-language variations.
- Report Layout and Style Guides: Modular design assets and rendering instructions for PDF, web, and dashboard outputs.
Dependencies for successful extension include orchestration engines (such as Apache Airflow or Kubernetes schedulers), cloud platforms (for example, Microsoft Azure AI or Google Cloud AI Platform), identity and access management, centralized regulatory and taxonomy registries, stable machine learning frameworks, and semantic metadata services like FIBO. A dependency matrix with version tracking and automated checks ensures compatibility before deployment.
Handoff mechanisms integrate artifacts into new use cases:
- API-Driven Artifact Registry: RESTful endpoints for discovery, retrieval, and version negotiation.
- Containerized Deployment Packages: Docker containers or Helm charts encapsulating dependencies and runtime requirements.
- Configuration Management Modules: Infrastructure-as-code (Terraform or Ansible) orchestrating provisioning of connectors, rule engines, and model endpoints.
- Event-Driven Integration Patterns: Standardized events on enterprise buses (for example, Apache Kafka) triggering downstream workflows.
- Documentation and Training Kits: Guides, code samples, and test datasets accompanying each artifact for rapid onboarding.
These capabilities accelerate time to market for new report types, ensure consistent application of enterprise standards, and reduce configuration drift. By treating artifacts as first-class deliverables with clear metadata, dependencies, and integration contracts, organizations maintain a robust, agile AI-driven reporting solution capable of adapting to evolving market demands and regulatory landscapes.
Appendix
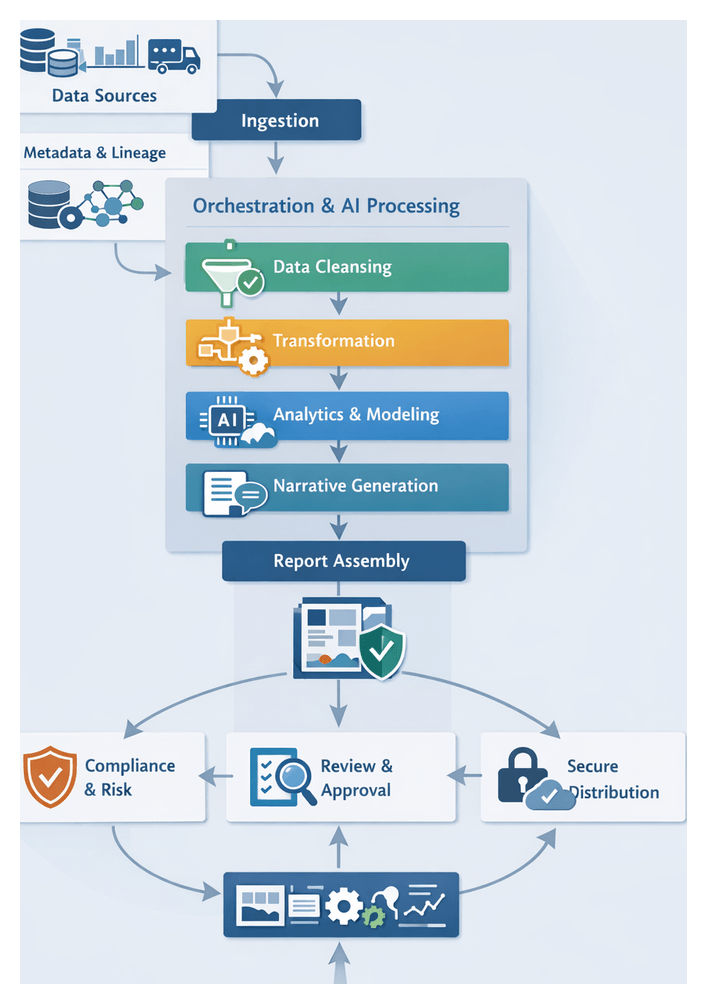
General Workflow Concepts
Automated financial reporting relies on structured workflows that combine automated and manual tasks across stages.
A workflow sequences data collection, validation, transformation, analysis and distribution, enforcing dependencies, schedules and audit logging for repeatability.
The orchestration engine—for example Apache Airflow—coordinates task scheduling, error handling and notifications.
AI agents apply machine learning, natural language processing or rule logic autonomously to tasks such as anomaly detection, schema mapping or narrative generation.
A metadata catalog stores dataset definitions, descriptions, lineage and quality metrics to support governance and discovery.
Data lineage tracks origins and transformations, ensuring traceability from source systems to report outputs for compliance.
Key stages in the data pipeline include:
- Ingestion: Connectors extract raw data from ERP platforms, trading systems or market feeds. API orchestration manages REST, SOAP or proprietary interfaces, handling authentication, retries and logging. A unified data repository preserves original schemas and supports downstream normalization. AI-driven schema discovery detects schema drift and updates registries. Incremental ingestion captures only new or changed records via watermarks or change data capture.
- Cleansing and Preprocessing: Automated data profiling computes statistics on null rates, distributions and cardinality to inform quality checks. Anomaly detection models—such as isolation forests or autoencoders—identify outliers. Imputation fills missing values with statistical or predictive methods. Standardization harmonizes dates, scales and labels. Records failing validation enter an exception queue for steward review.
- Transformation: Raw codes align to standardized hierarchies through chart of accounts mapping. Knowledge graphs represent entity relationships and support semantic enrichment. Entity resolution reconciles duplicates via fuzzy matching or graph traversal. Transactions are tagged by regulatory classification rules or supervised models. The transformed ledger contains standardized general ledger entries and currency conversions.
- Analytics and Modeling: A feature store holds engineered variables for model consumption. A model registry—managed via tools like MLflow—records model versions, metadata and performance. Batch scoring applies predictive models on scheduled compute clusters (e.g., Apache Spark), while real-time inference uses streaming frameworks such as Apache Flink. Concept drift detection triggers retraining pipelines.
- Narrative Generation: Natural language generation engines convert structured data into human-readable commentary. A template library defines approved structures and compliance clauses. Prompt engineering guides transformer-based models (for example GPT-4) to enforce tone and coverage. Transition phrases ensure coherence, while compliance annotations embed regulatory flags.
- Report Assembly: Placeholders within templates bind text, charts and tables. A template engine—such as Adobe InDesign Server or headless HTML frameworks—applies styling and layouts. A design asset repository ensures brand consistency. Responsive layouts adapt for print, PDF, web or mobile. Visual consistency checks use AI-driven image comparison.
- Compliance and Risk Management: Rule engines encode policies into executable logic. Risk scoring models quantify compliance or operational risk. An immutable audit trail records every transformation, model run and approval. Identity and access management systems enforce authentication and authorization. Drift detection monitors changes in data or model behavior.
- Secure Distribution: Reports are packaged in encryption envelopes managed by key management services (KMS). Access logs record authentication events and decryption operations. Behavioral analytics detect anomalous access patterns. Secure handover tokens authorize time-bound decryption. Distribution channels include SFTP, secure email, APIs and portals.
- Continuous Improvement: Monitoring dashboards aggregate metrics on data quality, model performance and system health. Feedback loops integrate user insights to refine processing rules, retrain models and update templates. Canary deployments validate changes on subsets of workflows. Versioning strategies track workflow artifacts. Drift retraining pipelines automate data snapshotting, feature regeneration, model training and deployment.
AI Capabilities by Workflow Stage
This mapping aligns AI roles, technologies and illustrative products to each stage of the reporting lifecycle. Architects can use this blueprint to select tools and design resilient workflows.
Stage 1: Data Ingestion and Integration
- AI Roles: Connector orchestration, schema discovery, self-healing retries, initial normalization
- Key Technologies: ML-driven schema inference, rule engines for protocol selection
- Illustrative Products: MuleSoft Anypoint Platform, Informatica Intelligent Cloud Services
- Purpose: Automate endpoint configuration, detect schema drift, reduce manual setup and errors
Stage 2: Data Cleansing and Preprocessing
- AI Roles: Anomaly detection, missing-value imputation, format standardization, feedback-driven rule refinement
- Key Technologies: Unsupervised clustering, autoencoders, data profiling
- Illustrative Products: Great Expectations, Amazon Deequ, DataRobot Automated Data Quality
- Purpose: Identify outliers early, enforce completeness, minimize manual exceptions
Stage 3: Intelligent Data Transformation
- AI Roles: Semantic enrichment, knowledge-graph inference, probabilistic classification, entity resolution
- Key Technologies: Knowledge graphs, transformer-based classification, rule engines
- Illustrative Products: Neo4j Graph Database, OpenRules
- Purpose: Automate chart of accounts mapping, regulatory categorization, intercompany eliminations
Stage 4: AI-Powered Analytics and Insight Generation
- AI Roles: Time-series forecasting, anomaly scoring, risk pre-scoring, feature orchestration
- Key Technologies: ARIMA, gradient-boosted trees, deep learning, real-time stream scoring
- Illustrative Products: DataRobot, Prophet by Facebook, AWS SageMaker
- Purpose: Produce KPI forecasts, detect outliers quickly, generate confidence scores for narratives
Stage 5: Automated Narrative Generation
- AI Roles: Contextual template selection, data binding, tone enforcement, compliance validation
- Key Technologies: Transformer-based NLG, prompt engineering, domain fine-tuning
- Illustrative Products: OpenAI GPT-4, IBM Watson NLG, Arria NLG
- Purpose: Generate consistent disclosures, embed regulatory statements, adhere to style guidelines
Stage 6: Dynamic Report Assembly and Formatting
- AI Roles: Enforcing style guidelines, binding placeholders to relevant data, adapting pagination to fit content seamlessly, and conducting visual consistency checks to ensure a polished final product.
- Key Technologies: Computer vision, constraint-based layout engines, PDF/HTML rendering APIs
- Illustrative Products: Adobe InDesign Server, Figma with AI plugins
- Purpose: Ensure brand compliance, optimize readability across formats, minimize manual formatting
Stage 7: Compliance and Risk Management Controls
- AI Roles: NLP rule ingestion, risk-score computation, exception triage, audit log generation
- Key Technologies: NLP for rule extraction, supervised risk classifiers, knowledge graphs for policy mapping
- Illustrative Products: IBM OpenPages, Thomson Reuters Regulatory Intelligence, Collibra Policy Engine
- Purpose: Automate policy checks, surface compliance breaches, generate tamper-proof audit trails
Stage 8: Collaborative Review and Approval
- AI Roles: Task routing, sentiment analysis, automated reminders, conflict detection
- Key Technologies: NLP for comment summarization, graph-based dependency resolution, real-time alerting
- Illustrative Products: Slack GPT integration, Jira or ServiceNow bots
- Purpose: Streamline review, reduce bottlenecks, maintain versioned audit logs
Stage 9: Secure Distribution and Access Management
- AI Roles: Document and biometric identity proofing, adaptive authentication, behavioral anomaly detection
- Key Technologies: OCR and computer vision, ML-driven risk scoring, continuous behavioral analytics
- Illustrative Products: Okta Adaptive MFA, AWS KMS, Onfido Identity Verification
- Purpose: Enforce secure delivery, validate identities, log access events
Stage 10: Continuous Monitoring and Iterative Improvement
- AI Roles: Drift detection, anomaly monitoring, feedback correlation, automated retraining triggers
- Key Technologies: PSI and KL divergence tests, autoencoder anomaly detectors, MLOps pipelines
- Illustrative Products: MLflow, Kubeflow Pipelines, Prometheus and Grafana
- Purpose: Maintain model accuracy, optimize pipelines, incorporate feedback and regulatory changes
Workflow Variations and Edge Cases
Real-world reporting must handle deviations from ideal flows. The following patterns and controls ensure resilience and compliance.
Ad Hoc Sources and Late Arrivals
- Dynamic ingestion triggers detect one-off uploads via file-watch and events. AI agents classify file types and infer schemas.
- Versioned repositories capture delta changes and reconcile with existing records using change data capture.
- Orchestrators pause downstream stages on missing feeds, resume automatically when thresholds are met. Anomaly detection flags delays and suggests fallbacks.
Multi-Entity Consolidation
- Entity profiles in MDM store account mappings, currency settings and hierarchies. AI agents validate conformity.
- Matched-pair detection and clustering algorithms automate intercompany eliminations.
- Drill-down support enables navigation from consolidated figures to source details via metadata links.
Regulatory Taxonomy Changes
- Automated schema discovery compares new taxonomies to baselines and generates mapping suggestions.
- Versioned taxonomy management allows parallel processing under legacy and new schemas, embedding version metadata.
- Decision platforms update rule engines programmatically and validate with scenario-based test suites.
Manual Adjustments and Overrides
- Quarantine workflows route flagged entries to a manual adjustment queue with secure interfaces and rationale logging.
- Multi-level approval gates enforce sign-offs for material overrides, recording metadata for reconciliation.
- Reconciliation routines integrate manual corrections and offer “what-if” simulations before final acceptance.
Connector Failures and System Outages
- Automated retries with exponential backoff and fallback endpoints ensure self-healing connectivity.
- Rate-limit monitoring auto-throttles extraction rates and alerts stewards as quotas near thresholds.
- Graceful degradation allows non-critical processes to continue with warnings. AI imputations fill temporary gaps.
Real-Time vs Batch Processing
- Lambda architectures maintain batch and speed layers, merging outputs in a serving layer for unified views.
- Pub/sub triggers feed streaming microservices. Idempotent processing handles duplicates and ordering.
- Distributed locks and concurrency controls prevent resource conflicts. Lag monitoring triggers dynamic scaling.
High-Volume Spikes
- Autoscaling pools for connectors, compute clusters and databases handle peaks. Pre-warming aligns to calendar triggers.
- Priority queues sequence critical feeds. Dead-letter queues capture non-critical jobs for off-hour retries.
- Backpressure strategies throttle producers and buffer adaptively to prevent data loss.
Unstructured Document Ingestion
- OCR confidence scoring quarantines low-confidence extracts for manual review. AI suggests alternate engines.
- Human-in-the-loop interfaces enable annotators to correct text and tables, feeding model retraining.
- Template-based extraction routes known formats to rule-based mappers guided by classification agents.
Localization and Multi-Language Support
- Internationalization frameworks externalize labels into language packs. AI-powered translation engines ensure domain accuracy.
- Locale settings apply date, number and currency formats at assembly. Bi-directional templates and multi-byte encodings are tested.
- Jurisdiction-specific disclosures are embedded based on metadata. AI validates local compliance clauses.
Cross-Currency Translations
- Fallback exchange rates or manual overrides apply when feeds fail. Anomaly detectors flag out-of-range rates for verification.
- Configurable real-time or end-of-day rate selection by cutoff. Variance analysis captures both sets for narratives.
- Round-trip translation checks reconcile back to base currency. AI suggests adjustments when residuals exceed tolerances.
Data Privacy and Redaction
- AI-based PII detection masks sensitive fields per jurisdictional policies. Redaction rules support GDPR, CCPA and local laws.
- Consent tracking enforces deletion or anonymization upon withdrawal. Audit logs capture policy applications per record.
- Secure preview interfaces mask PII at display time and log access to sensitive segments for additional review.
User Feedback and Configuration Drift
- Embedded feedback forms and helpdesk integrations capture structured surveys and issue reports.
- AI agents correlate feedback with specific templates or models, flagging items for review and version updates.
- Continuous integration pipelines validate refined configurations in sandbox environments before live rollout.
Disaster Recovery and Rollback
- Cross-region replication of data lakes and orchestration engines with DNS failover ensures automatic failover.
- Tagged releases for schemas, models and pipelines enable rapid rollback via infrastructure as code.
- Regular disaster recovery drills and AI-driven post-failover monitoring verify functional integrity and alert stakeholders.
AI Tools and Additional Resources
AI-Driven Tools Referenced
- MuleSoft Anypoint Platform: A unified integration platform that provides connectors, API management and orchestration for data ingestion across heterogeneous systems.
- Informatica Intelligent Cloud Services: A cloud data integration suite offering connectors, data quality and metadata management for large-scale data pipelines.
- Datadog: A monitoring and observability platform that collects metrics, logs and traces to provide real-time dashboards and anomaly detection.
- Splunk: A data platform for collecting, searching and analyzing machine-generated events, logs and metrics, used for monitoring and incident investigation.
- ServiceNow: An IT service management and workflow automation platform that handles incident tickets, change requests and process orchestration.
- Apache Airflow: An open-source workflow orchestrator that defines and schedules data pipelines as directed acyclic graphs.
- Prefect: A workflow management system that enables orchestration of data and ML workflows with dynamic task mapping and real-time monitoring.
- Great Expectations: An open-source data validation framework for defining, executing and documenting data quality expectations.
- Amazon Deequ: A data quality library built on Apache Spark for defining and measuring data validation metrics at scale.
- DataRobot: A machine learning platform that automates model building, feature engineering and deployment for predictive analytics.
- Databricks: A unified analytics platform powered by Apache Spark for data engineering, machine learning and collaborative notebooks.
- Google Cloud Dataflow: A fully managed streaming and batch data processing service based on Apache Beam, for large-scale ETL and analytics.
- Snowflake: A cloud data warehouse platform offering scalable storage, compute and data sharing capabilities.
- Azure Data Lake Storage: A scalable, secure data lake for big data analytics and machine learning workloads on Microsoft Azure.
- Azure Data Factory: A cloud ETL service for orchestrating data movement and transformation across on-premises and cloud sources.
- AWS Glue: A serverless data integration service that provides ETL capabilities and a data catalog for discovery.
- MLflow: An open-source platform for managing the ML lifecycle, including experiment tracking, model registry and deployment.
- H2O.ai: An automated machine learning platform offering model training, validation and interpretation for structured data.
- Dataiku: A collaborative data science platform that automates end-to-end analytics workflows and MLOps.
- Palantir Foundry: An enterprise data management and analytics platform that integrates disparate data sources for analysis and collaboration.
- TensorFlow: An open-source machine learning framework for building and deploying neural network models.
- PyTorch: A deep learning library supporting dynamic computation graphs and rapid prototyping of ML models.
- Apache Kafka: A distributed event streaming platform for building real-time data pipelines and streaming applications.
- Confluent: A streaming data platform built on Kafka that adds management, connectors and stream processing capabilities.
- NGINX: A web server and API gateway used to manage, secure and route HTTP/HTTPS traffic for integration endpoints.
- Kong: An open-source API gateway and service mesh for managing and securing microservices.
- Tableau: A business intelligence tool for interactive data visualization, dashboard creation and ad-hoc analysis.
- Microsoft Power BI: A suite of analytics tools for building interactive reports and dashboards with Excel integration.
- Control-M: A workload automation platform for scheduling, monitoring and managing critical batch jobs.
- AutoSys: An enterprise job scheduling system that automates tasks across heterogeneous environments.
- Kubernetes: A container orchestration system for automating deployment, scaling and management of containerized applications.
- Docker: A platform for building, sharing and running applications in lightweight containers to ensure consistency across environments.
- AWS KMS: A managed service for creating and controlling encryption keys used to secure data across AWS services.
- Azure Key Vault: A cloud service for securely storing and managing keys, secrets and certificates.
- HashiCorp Vault: An open-source secrets management tool for dynamic credential issuance and data encryption.
- Okta: An identity and access management platform providing SSO, MFA and lifecycle management.
- Auth0: An identity platform for authentication and authorization, supporting multiple protocols and social logins.
- ServiceNow ITSM: A service management suite that automates incident, change and problem management workflows.
- UiPath: A robotic process automation platform for automating repetitive, rule-based tasks across systems.
- Adobe InDesign Server: A document composition engine for high-fidelity print and digital publication layouts.
- Canva Magic Design: An AI-powered design assistant that automates layout creation and brand adaptation for multi-format outputs.
- Adobe Sensei: Adobe’s AI and machine learning framework powering intelligent features in Creative Cloud applications.
- Bynder: A digital asset management platform for storing, organizing and distributing brand assets.
- Adobe Experience Manager: A content management system for creating and delivering digital experiences across channels.
- Lokalise AI: A translation management platform that uses machine learning to automate localization workflows.
- Smartling: A translation automation platform for managing multilingual content localization and quality assurance.
Additional Context and Resources
The following resources and reference materials provide supplementary context on regulatory frameworks, standards and best practices relevant to AI-driven financial reporting.
- International Financial Reporting Standards (IFRS): Accounting standards issued by the International Accounting Standards Board governing global financial disclosures.
- Financial Accounting Standards Board (FASB): The US organization responsible for establishing Generally Accepted Accounting Principles (US GAAP).
- Basel Committee on Banking Supervision: Provides global regulatory standards for capital adequacy and risk management in banking.
- Sarbanes-Oxley Act (SOX): US federal law that mandates internal controls and audit requirements for public companies.
- General Data Protection Regulation (GDPR): EU regulation on data privacy and protection influencing data handling practices.
- Payment Card Industry Data Security Standard (PCI DSS): Standards governing security of payment card transactions and data.
- XBRL International: The global consortium that develops and promotes the eXtensible Business Reporting Language for digital business reporting.
- World Bank Data Catalog: A repository of global economic, financial and development indicators for contextual analysis.
- Organisation for Economic Co-operation and Development (OECD): Publisher of guidelines on tax, risk and governance frameworks.
- International Organization for Standardization (ISO): Developer of international standards including ISO 9001 for quality management and ISO 27001 for information security.
- SWIFT Standards: Messaging and data standards for secure financial messaging between banks.
- Financial Industry Regulatory Authority (FINRA): US self-regulatory organization overseeing broker-dealer compliance.
- European Banking Authority (EBA): EU authority providing regulatory technical standards and guidelines for banking supervision.
- Network Time Protocol (NTP): Protocol for clock synchronization across networked systems, critical for timestamp accuracy.
- Blockchain Technology: Distributed ledger technology for immutable audit trails and data integrity.
- OpenTelemetry: A vendor-neutral framework for instrumenting, generating and collecting distributed traces and metrics.
- Financial Data Federation Guidelines: Best practice documents for federating financial data across disparate systems. (Contact industry consortium for latest guidance)
- AI Ethics Guidelines: Principles and frameworks from bodies such as the European Commission’s High-Level Expert Group on AI.
- DevOps and MLOps Best Practices: Industry-recognized practices for continuous integration, delivery and monitoring of data and ML pipelines.
The AugVation family of websites helps entrepreneurs, professionals, and teams apply AI in practical, real-world ways—through curated tools, proven workflows, and implementation-focused education. Explore the ecosystem below to find the right platform for your goals.
Ecosystem Directory
AugVation — The central hub for AI-enhanced digital products, guides, templates, and implementation toolkits.
Resource Link AI — A curated directory of AI tools, solution workflows, reviews, and practical learning resources.
Agent Link AI — AI agents and intelligent automation: orchestrated workflows, agent frameworks, and operational efficiency systems.
Business Link AI — AI for business strategy and operations: frameworks, use cases, and adoption guidance for leaders.
Content Link AI — AI-powered content creation and SEO: writing, publishing, multimedia, and scalable distribution workflows.
Design Link AI — AI for design and branding: creative tools, visual workflows, UX/UI acceleration, and design automation.
Developer Link AI — AI for builders: dev tools, APIs, frameworks, deployment strategies, and integration best practices.
Marketing Link AI — AI-driven marketing: automation, personalization, analytics, ad optimization, and performance growth.
Productivity Link AI — AI productivity systems: task efficiency, collaboration, knowledge workflows, and smarter daily execution.
Sales Link AI — AI for sales: lead generation, sales intelligence, conversation insights, CRM enhancement, and revenue optimization.
Want the fastest path? Start at AugVation to access the latest resources, then explore the rest of the ecosystem from there.