

AI Agent Orchestration for Business Solutions
To download this as a free PDF eBook and explore many others, please visit the AugVation webstore:
Introduction
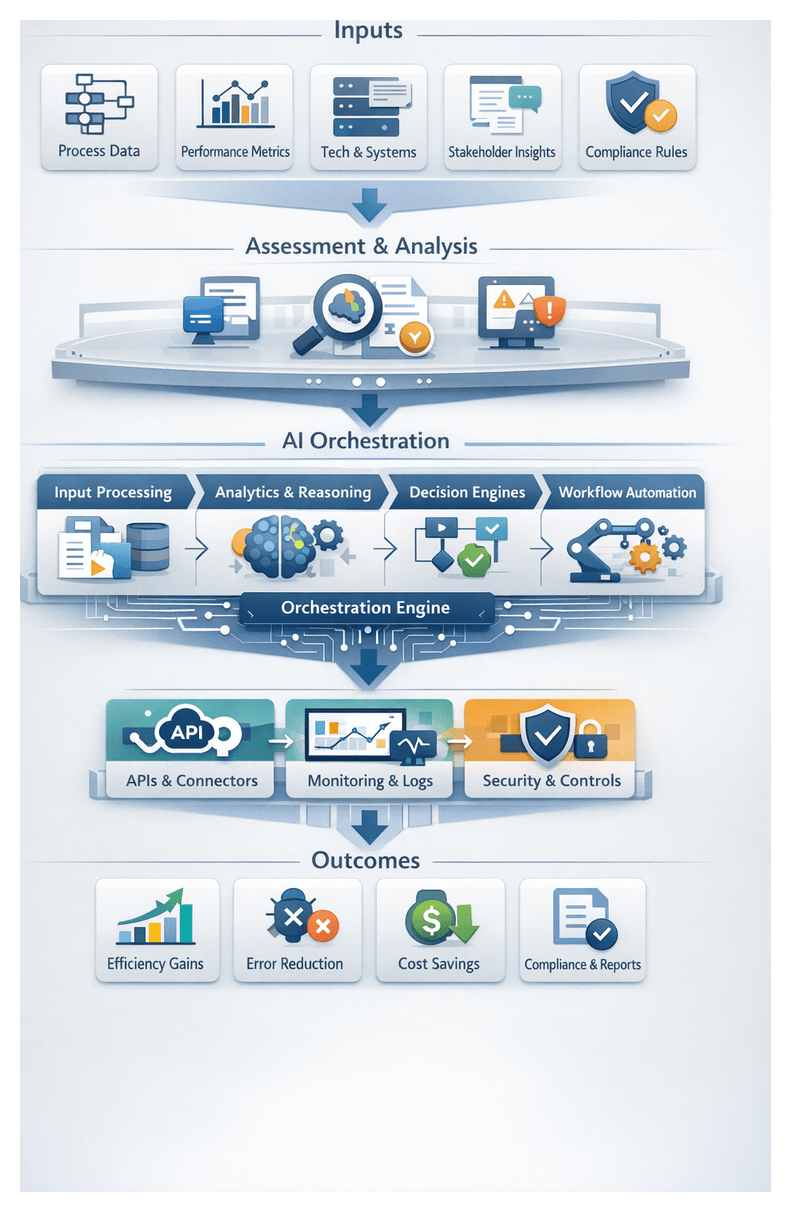
Understanding Core Automation Challenges
The first phase of any AI-driven orchestration strategy focuses on diagnosing the fundamental obstacles that impede efficiency, reliability, and scalability. By mapping existing workflows, pinpointing manual touchpoints, and uncovering technology constraints, teams establish a clear baseline from which to design targeted automation interventions. This rigorous assessment ensures that resources address root causes—such as process fragmentation, data inconsistencies, and governance gaps—rather than superficial symptoms.
Purpose of the Assessment
- Document end-to-end processes, including manual tasks, system handoffs, decision gateways, and exception paths.
- Quantify operational pain points by analyzing cycle times, error rates, rework frequencies, and compliance incidents.
- Evaluate automation readiness by reviewing data quality, process documentation standards, and the integration maturity of existing applications.
- Define clear objectives and success metrics—such as throughput increases, cost reductions, or customer satisfaction improvements—that align with strategic priorities.
- Engage stakeholders across business, IT, risk, and compliance functions to validate findings and secure executive sponsorship for the initiative.
Inputs Required
- Process Artifacts: Detailed maps, swimlane diagrams, standard operating procedures, and any legacy automation scripts offering insight into current task flows.
- Performance Data: Historical dashboards, reports, and logs from ERP, CRM, or custom applications capturing throughput, delays, and exception volumes.
- Technology Inventory: An itemized catalog of systems, databases, integration platforms, APIs, and middleware, including data formats and access methods.
- Stakeholder Feedback: Interviews and surveys with process owners, frontline operators, compliance officers, and IT support teams to capture qualitative insights on pain points and improvement goals.
- Exception Logs and Audit Records: Incident reports, customer complaints, and regulatory findings that highlight systemic weaknesses and risk exposures.
- Regulatory Frameworks: Documentation of relevant standards, governance policies, data privacy mandates, and audit requirements guiding workflow design.
Prerequisites and Success Conditions
- Executive Sponsorship: Demonstrable commitment from senior leadership, including budget approval, governance oversight, and cross-functional alignment.
- Cross-Functional Team: A structured project team with business analysts, IT architects, data engineers, compliance specialists, and change managers.
- Secure Access: Authorized connectivity to systems, databases, APIs, and file repositories, supported by data governance and security clearances.
- Documentation Standards: Agreed formats and notation conventions (BPMN, value stream mapping, flowcharts) to ensure consistency and clarity.
- Baseline Metrics: Established performance benchmarks and qualitative user feedback to measure the impact of subsequent automation.
- Change Management Plan: Communication and training strategies to prepare stakeholders for process automation and foster adoption.
- Risk Mitigation Framework: Identification of potential risks—such as data integrity issues or integration failures—and predefined mitigation plans.
With these elements in place, organizations can transition from discovery to design, confident that they understand both the operational landscape and the governance requirements necessary for scalable AI-driven workflows.
Imperative for Structured Orchestration
Point solutions, one-off scripts, and siloed automations often deliver short-term gains but fail to scale without a cohesive orchestration framework. Structured orchestration unifies dispersed automation efforts, enforces consistency, and provides end-to-end visibility across complex, multi-system workflows. By imposing a formal workflow blueprint, enterprises reduce technical debt, strengthen governance, and ensure reliable performance as processes evolve.
Limitations of Ad Hoc Automation
- Lack of Visibility — Fragmented tools and scripts operate without a centralized dashboard, obscuring performance trends and bottleneck identification.
- Inconsistent Error Handling — Custom retry logic and undocumented failure modes lead to silent errors, manual firefighting, and data corruption.
- Siloed Knowledge — Sparse or outdated documentation forces teams to reverse-engineer solutions when issues arise, increasing support overhead.
- Deployment Drift — Version mismatches and evolving APIs break integrations; without governance, corrective patches are applied unevenly.
- Governance Gaps — Security and compliance teams lack centralized oversight, complicating audit readiness and policy enforcement.
Core Attributes of Structured Orchestration
- Workflow Blueprint — A detailed map of activities, decision points, and exit conditions, ensuring predictable execution paths.
- Central Coordination Engine — A dedicated orchestration platform triggers tasks, manages dependencies, and enforces sequencing.
- Reusable Components — Standardized connectors, templates, and agent interfaces accelerate development and maintain consistency.
- Dynamic Scaling — The orchestration layer adapts to volume changes, branching logic, and resource constraints through load balancing.
- Auditability — Integrated logging, metrics collection, and dashboards deliver real-time insights into performance and compliance.
- Governance Controls — Role-based access, approval gates, and policy checks embedded in workflows safeguard sensitive operations.
Interactions Across Systems and Stakeholders
Structured orchestration coordinates:
- AI Agents performing tasks such as document extraction, predictive scoring, or natural language understanding.
- Enterprise Applications supplying data and events via APIs, message queues, or file transfers.
- Human Participants reviewing exceptions, making approvals, and providing critical judgments.
- Orchestration Services handling task scheduling, routing logic, and state management.
- Monitoring Tools capturing execution logs and alerting on anomalies.
Measurable Benefits
- Scalability — Extend standardized workflows across new geographies and business units without proliferating custom code.
- Reliability — Centralized error handling and retry policies minimize failure rates and downtime.
- Transparency — Unified dashboards and audit trails provide stakeholders with clear visibility into process health.
- Compliance — Embedded security and governance controls support regulatory requirements.
- Agility — Reusable components accelerate new automation deployments.
- Maintainability — A cohesive orchestration layer simplifies version control, testing, and change management.
Leading platforms illustrate how AI agents, enterprise systems, and human workflows can be integrated under a unified orchestration layer to deliver consistent, auditable outcomes at scale.
Positioning AI Agents Within the Workflow Framework
AI agents are specialized actors within orchestrated workflows, responsible for tasks ranging from data ingestion to decision execution. Defining their roles, integration interfaces, and governance mechanisms ensures that each agent contributes reliably to end-to-end process objectives.
Mapping Agent Roles to Functional Layers
Agents can be categorized by the layer in which they operate:
- Input Processing Agents ingest and normalize raw inputs—scanning documents, parsing unstructured text, and validating data accuracy.
- Analytic and Reasoning Agents apply machine learning models, statistical analyses, or rule engines to generate insights such as predictive scores or risk assessments.
- Decisioning Agents interpret analytic outputs against business rules and context to recommend actions, trigger human reviews, or invoke downstream processes.
- Orchestration and Coordination Agents oversee the workflow, monitor task statuses, manage retries, and enforce transactional integrity.
Integrating Data Connectivity and System Interfaces
- API Gateways and RESTful Services provide standardized endpoints for agent invocation, with versioning and schema validation to support upgrades.
- Message Queues and Streaming leverage platforms such as Apache Kafka or Amazon Kinesis to decouple producers and consumers and buffer data spikes.
- Database Connectors and Data Lakes supply agents with secure access to structured repositories, warehouses, or lakehouse architectures.
- Authentication and Authorization employ OAuth, API keys, or token-based security with least-privilege principles and secret rotation policies.
Orchestrating Decision Logic: Rule-Based Versus AI-Driven
Decision gateways may implement:
- Rule-Based Logic for deterministic, auditable checks—compliance thresholds, eligibility rules, and binary conditions.
- AI-Driven Logic utilizing services such as OpenAI or Google Cloud AI to handle ambiguous inputs, classify text, or predict outcomes.
Hybrid architectures combine both approaches—routing high-risk exceptions to human review based on model confidence scores and applying fallback rules to ensure continuity.
Designing Seamless Inter-Agent Handovers
Formal handovers define the contract between agents, specifying:
- Structured payloads (JSON or protocol buffers) with explicit fields and metadata.
- Quality thresholds—minimum confidence scores, completeness checks, and validation rules.
- Versioning schemes and schema evolution paths to maintain backward compatibility.
- Error handling protocols—retry logic, exception queues, and escalation workflows for validation failures.
Balancing Synchronous and Asynchronous Operations
Workflows often mix:
- Synchronous Calls for user-facing interactions—chatbots, approval portals—requiring low latency and clear error messaging. Prebuilt APIs like Microsoft Azure Cognitive Services deliver sub-second responses.
- Asynchronous Flows for batch analytics, data enrichment, and long-running ML tasks. Agents publish events or use work queues, enabling orchestrators to monitor and trigger downstream steps upon completion.
Embedding Governance, Security, and Monitoring
Governance is woven into each orchestrated workflow:
- Access Controls enforce role-based permissions at API and infrastructure layers.
- Audit Logging captures agent activations, input parameters, and decisions in centralized repositories to support GDPR, SOC 2, and other compliance mandates.
- Performance Monitoring tracks throughput, error rates, and resource utilization; dashboards and alerting agents detect anomalies in real time.
Leveraging Orchestration Infrastructure
- Workflow Engines such as Apache Airflow define task graphs, manage parallelism, and persist execution state.
- Container Platforms like Docker and Kubernetes package agents for consistent runtime environments and auto-scaling.
- Service Meshes secure and observe service-to-service communication with circuit breaking and resilience patterns.
- Configuration Services centralize parameters and feature flags, enabling dynamic adaptation without redeployment.
Outputs, Dependencies, and Handoffs
At the culmination of the introductory phase, stakeholders receive a comprehensive package of artifacts that crystallize the project’s strategic rationale, technical assumptions, and governance framework. These deliverables pave the way for detailed design and implementation.
Key Outputs and Deliverables
- Challenge Assessment Summary: A report detailing critical pain points, process bottlenecks, data quality gaps, and manual intervention hotspots.
- Orchestration Imperative Statement: A strategic memorandum explaining the shortcomings of ad hoc automations and the necessity for a formal orchestration framework.
- AI Agent Role Matrix: A mapping of agent types—such as conversational assistants, document intelligence engines, and analytics agents—to specific tasks. For example, an IBM Watson document processing engine for invoice extraction or a cognitive assistant for customer triage.
- Solution Blueprint Overview: A layered narrative and visual outline of the end-to-end orchestration strategy, from objective definition through monitoring and continuous improvement.
- Scope Definition and Assumptions: Documentation of in-scope processes, excluded systems, data readiness levels, and preliminary technology stack considerations.
Dependencies and Input Requirements
- Executive and Process Owner Interviews: Scheduled sessions to validate strategic goals, pain point assessments, and success metrics.
- Process Documentation Access: Existing SOPs, flowcharts, policy manuals, and legacy scripts to inform current-state mapping.
- Data Maturity Audit: Preliminary profiling of datasets to evaluate completeness, quality, metadata availability, and governance controls.
- Technology Landscape Inventory: A comprehensive list of CRM, ERP, document repositories, RPA tools, and AI services for integration planning.
- Governance and Compliance Guidelines: References to industry regulations, security policies, and audit frameworks shaping workflow constraints.
- Stakeholder Alignment Workshops: Working sessions where cross-functional teams endorse assessments, refine assumptions, and agree on the high-level blueprint.
Handoff Mechanisms to Detailed Design
- Introduction Stage Sign-Off Packet: A versioned digital package containing all deliverables, stored in the project repository for traceability.
- Transition Workshop: A facilitated meeting to review outputs, confirm priorities, assign leads for Chapter 1 tasks, and schedule data-gathering activities.
- Data and Process Inventory Template: A standardized schema—spreadsheet or database—for capturing process maps, data sources, input formats, and initial success metrics.
- Roles and Responsibilities Matrix: An updated RACI chart defining ownership for each deliverable and upcoming design tasks.
- Traceability Log: A living document capturing key decisions, assumption changes, and risk items, ensuring transparency as the project progresses.
- Governance Gateway Approval: Formal sign-off by the steering committee or governance board, certifying that the introduction phase meets quality, compliance, and strategic alignment criteria.
By delivering structured outputs, securing necessary inputs, and embedding robust handoff protocols, organizations establish a disciplined foundation for subsequent chapters—starting with defining business objectives and use cases—thereby reducing risk and accelerating time to value in AI-driven orchestration initiatives.
Chapter 1: Defining Business Objectives and Use Cases
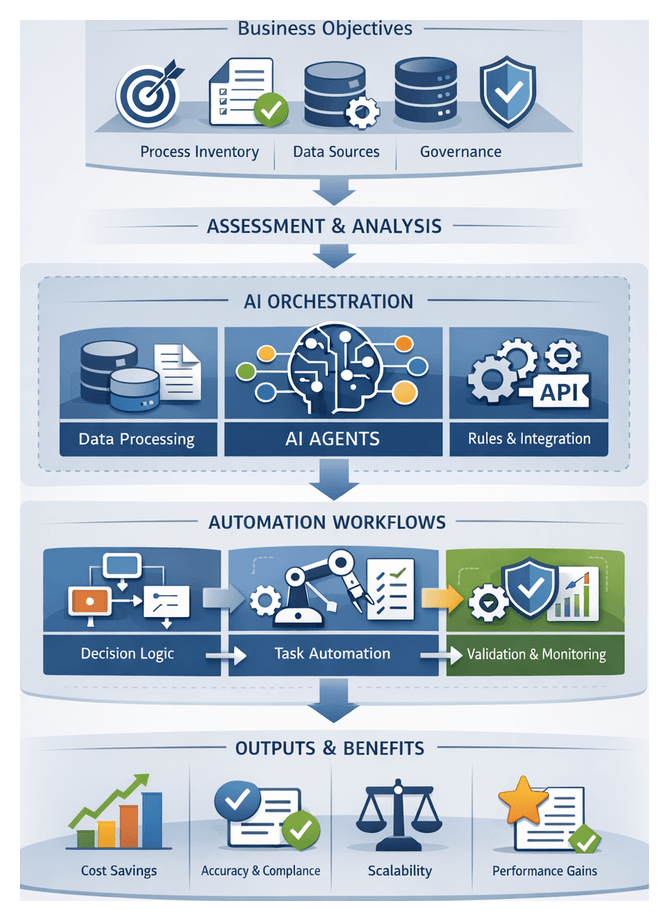
Establishing Foundational Inputs and Process Prioritization
Purpose and Industry Context
Laying the groundwork for AI-driven workflow automation begins with identifying high-impact business processes and defining the requisite inputs for successful execution. In complex enterprise environments—characterized by dispersed data silos, legacy systems, and evolving customer demands—targeted automation ensures that resources focus on initiatives aligned with strategic objectives. By cataloging existing workflows, evaluating baseline performance, and securing stakeholder commitments, organizations mitigate the risk of low-value pilots and set clear metrics for measuring return on investment.
Leading firms employ systematic methods—such as process mining, lean management, and value stream analysis—augmented by specialized to map and score candidate processes against business goals. This structured approach avoids ad hoc deployments and ensures that automation efforts leverage AI capabilities where they deliver maximum benefit.
Key Benefits of Focusing on High-Value Processes
- Accelerated ROI through rapid cost savings and productivity gains in high-effort or high-error areas.
- Stronger stakeholder buy-in as early wins demonstrate tangible value in functions like order processing or invoice reconciliation.
- Enhanced risk management by validating compliance controls in well-defined processes.
- Greater scalability potential via standardized inputs and repeatable patterns suited for AI agent orchestration.
- Alignment with strategic imperatives—whether top-line growth or cost optimization—reinforcing executive support.
Essential Inputs and Prerequisites
- Business Objectives Documentation: Clear articulation of targets, such as revenue growth, customer satisfaction, or cost reduction.
- Comprehensive Process Inventory: Registry of workflows, owners, system dependencies, documented procedures, and performance metrics.
- Baseline Performance Data: Quantitative measures—cycle times, error rates, throughput—enabling objective comparison.
- Data Availability Assessment: Audit of required data sources, formats, quality standards, access permissions, and integration points.
- Executive Sponsorship and Governance: Steering committees and sponsors to ensure resource allocation and compliance oversight.
- Technology Capability Review: Inventory of existing automation tools, AI platforms, and middleware to identify compatibility and gaps.
- Cross-Functional Teams: Collaboration across IT, operations, compliance, and business units for end-to-end accountability.
Conditions for Success
- Established data governance framework covering stewardship, quality controls, and lineage tracking.
- Process transparency via documented maps or process mining tools to uncover hidden variants.
- Consensus on prioritization criteria—impact, complexity, risk—among departmental leaders.
- Clear understanding of current automation maturity to build on existing investments.
- Change management readiness with communication and training plans to support adoption.
- Defined success metrics, including time savings, error reduction, scalability potential, and financial impact.
Process Identification Activities
- Process Mapping Workshops: Facilitate sessions with owners and frontline staff using tools such as Lucidchart or Microsoft Visio to capture workflows, decision points, variations, and exceptions.
- Data Readiness Assessment: Leverage profiling techniques and services like Google Cloud Dataflow to validate data accessibility, accuracy, and consistency.
- Value-Effort Scoring: Apply a matrix to weigh volume, cost, error rates, and strategic relevance against integration complexity and data preparation requirements.
- Risk and Compliance Review: Engage compliance officers to document privacy, audit trail, and encryption requirements for regulated processes.
- Technology Compatibility Analysis: Evaluate connectors and middleware needed for platforms such as Adobe Document Services, ABBYY FlexiCapture, and Azure Cognitive Services.
- Alignment Workshops: Confirm that prioritized processes map to executive KPIs and that necessary data sources, SMEs, and technology components are in place or road-mapped.
Articulating Workflow Actions and Sequences
Concept and Importance
Transitioning from high-level objectives to detailed task sequences creates the blueprint for AI agent orchestration. A well-defined workflow map ensures that tasks, decision criteria, data handoffs, and exception paths are transparent and aligned with business requirements. This clarity prevents isolated automation, uncovers dependencies and bottlenecks, and provides the reference for configuring orchestration engines and AI agents.
Scope Definition and Role Identification
Begin by delineating workflow boundaries—trigger events and final deliverables. Identify all participants:
- Human stakeholders such as business analysts and compliance officers.
- AI agents for language understanding, predictive analytics, anomaly detection, and document processing.
- Enterprise systems including CRM databases, ERP modules, document repositories, and messaging queues.
Define responsibilities, inputs, outputs, and access constraints for each role, informing permissions and exception-handling protocols.
Modeling Process Flows
- Identify core tasks from trigger to outcome.
- Sequence tasks logically, indicating dependencies.
- Define parallel branches for concurrent activities like validation and enrichment.
- Model decision points with conditions based on data values, confidence scores, or policy rules.
- Document loops and retries for quality checks, approvals, and error recovery.
This exercise uncovers hidden dependencies and informs resource allocation, scheduling, and performance expectations.
System and Agent Interactions
- Specify data formats and schemas (JSON, XML, CSV).
- Document API endpoints, message queue topics, and file paths.
- Define authentication and authorization methods such as OAuth scopes or certificates.
- Outline error handling strategies for timeouts, validation failures, and exceptions.
- Establish latency and throughput requirements to meet SLAs.
Codifying these details reduces integration risk and ensures reliability.
Transparency, Monitoring, and Improvement
- Centralized monitoring dashboards for real-time visibility into workflow stages, pending tasks, and throughput metrics.
- Event streaming and logging in standardized formats to record actions, decisions, and data transformations.
- Lineage tracking metadata linking outputs to original inputs, model versions, and configurations.
- Automated notifications and alerts for SLA breaches or anomalies.
These practices support rapid issue diagnosis, compliance demonstration, and iterative optimization.
Tools and Techniques
- BPMN for standardized depiction of workflows and message flows.
- Flowcharting software with swimlanes and layered diagrams.
- Collaborative platforms for real-time co-authoring of process maps.
- Version control with Git to track changes and support continuous delivery.
- Built-in workflow editors and monitoring modules in AI orchestration platforms.
Aligning AI Agent Roles with Strategic Objectives
Defining Strategic Objectives and Metrics
Translate organizational ambitions into discrete objectives—such as reducing cycle times by X percent, improving first-contact resolution, enhancing data accuracy, or increasing lead conversion. Pair each objective with measurable KPIs, for example a five-minute average handle time or a 10 percent reduction in invoice exceptions.
Cataloguing Agent Capabilities
Construct a capability matrix for AI agent types:
- NLP Agents—OpenAI or Google Cloud AI.
- Document Intelligence—Azure Cognitive Services or IBM Watson.
- Analytics and Predictive Modeling—Amazon SageMaker or Databricks.
- RPA Bots—UiPath or Automation Anywhere.
Score each agent against strategic objectives to prioritize deployment.
Mapping Agents to Workflow Stages
- Data Ingestion: Use document intelligence agents to extract invoice details, reducing manual errors by 80 percent.
- Validation and Enrichment: Deploy analytics agents to cross-check values against historical trends.
- Decision Support: Leverage NLP chatbots for dynamic stakeholder interaction and case updates.
- Execution and Reporting: Employ RPA bots to post transactions in ERP systems and update dashboards.
Governance and Accountability
- Define ownership for agent performance, maintenance, and versioning.
- Establish reporting cadences for agent-level KPIs and exception volumes.
- Specify escalation criteria for low confidence scores or anomaly rates.
Integrating Supporting Systems
- Centralized data repositories for consistent access and audit trails.
- MLOps and CI/CD pipelines—Kubeflow or Prefect—for model lifecycle management.
- Workflow orchestrators such as Apache Airflow to coordinate agent executions.
- Identity and access management frameworks for secure, least-privilege access.
Driving Continuous Improvement
- Monitor throughput, accuracy, and exception metrics in real time.
- Retrain models or adjust parameters to address performance declines.
- Rebalance workloads between agents and human operators for optimal efficiency.
- Identify new use cases where agents can be repurposed for additional value.
Defining Deliverables and Process Handoffs
Core Deliverables
Each use case definition should yield:
- Business Case Document outlining objectives, benefits, risks, and strategic alignment.
- Use Case Canvas capturing scope, actors, data inputs, decision points, and success metrics.
- Process Flow Diagram with swimlanes, branching logic, and agent interactions.
- Data Inventory and Schema Definitions cataloging sources, field formats, and permissions.
- Metrics Framework listing KPIs, SLAs, and targets for accuracy, throughput, and latency.
- RACI Matrix assigning roles and responsibilities.
Deliverable Standards and Quality Gates
Enforce consistent templates and naming conventions to facilitate peer review and reuse. Implement quality gates—completeness checks, stakeholder sign-offs, and policy validations—using automation platforms like UiPath or Microsoft Power Automate to trigger workflows and approvals.
Dependency Mapping
Map relationships between:
- Cross-functional teams, data stewards, legal, and AI specialists.
- Systems and data sources including CRM, ERP, data warehouses, and third-party APIs.
- AI agents requiring upstream preprocessing or human validation.
- Technology stack elements such as middleware, message queues, and monitoring tools.
Visualize dependencies with matrices or graphs in platforms.
Handoff Protocols
Define trigger conditions and handshake mechanisms—for example, validated dataset availability or performance thresholds—that initiate downstream tasks. Specify machine-readable schemas and API contracts (JSON Schema, OpenAPI) to minimize integration friction. Embed SLAs for latency and error rates, and outline review cycles with automated notifications and audit logs for end-to-end accountability.
Tools and Templates for Management
- Jira or Asana for use case templates, task assignments, and approval workflows.
- Confluence or SharePoint for document repositories and version histories.
- Git and GitHub for managing schemas, API contracts, and configuration files.
- Slack or Microsoft Teams with integrated bots for handoff notifications.
Governance and Compliance Integration
- Policy references for GDPR, HIPAA, and industry regulations.
- Risk assessment templates for data sensitivity and AI bias.
- Access control matrices ensuring segregation of duties.
- Automated audit trails capturing version changes, reviewer comments, and approvals.
Transparency and Accountability Practices
- Checklist-driven sign-off templates detailing required artifacts and approvals.
- Automated notifications for handoff initiation, review, and completion.
- Version control tags and change logs summarizing updates.
- Stakeholder dashboards providing real-time visibility into deliverable status and SLA compliance.
- Periodic audits to identify process gaps and standardization opportunities.
Chapter 2: Data Collection and Preprocessing
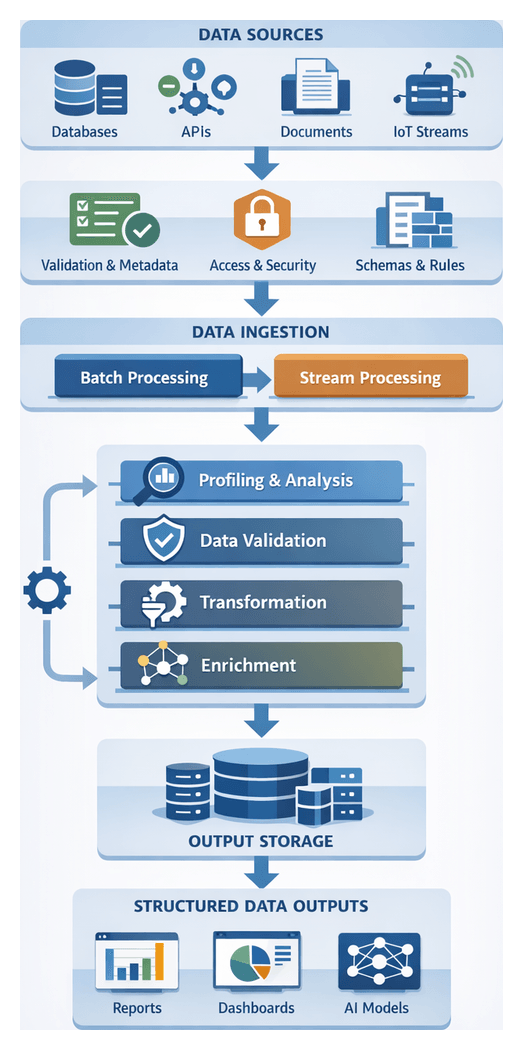
Preparing and Ingesting Quality Data Inputs
The foundation of any AI-driven workflow is high-quality, consistent data. This stage identifies all relevant sources, applies initial validation rules, and records metadata and lineage to ensure transparency and governance. By defining clear objectives—consolidating transactional databases, document repositories, IoT feeds, external APIs and more—and enforcing completeness, accuracy and timeliness checks, organizations reduce downstream errors and accelerate time to value.
Key Inputs and Prerequisites
- Source System Definitions: A catalog of enterprise data warehouses, document management systems, object stores and third-party APIs.
- Data Schemas and Formats: Relational schemas, JSON or CSV layouts that describe field names, types and constraints.
- Business Glossaries and Ontologies: Domain taxonomies and code lists that ensure consistent interpretation across teams.
- Quality and Compliance Rules: Thresholds for required fields, acceptable value ranges and regulatory mandates (for example, GDPR or HIPAA).
- Access Credentials and Connectivity: Secure tokens, API keys, network gateways and compute resources sized for ingestion workloads.
- Stakeholder Alignment: Roles for data owners, stewards and IT operations, plus documented governance policies and SLAs for latency and error handling.
- Metadata Capture Mechanisms: Automated lineage, timestamp and transformation logging for audit readiness.
Ingestion Strategies
Choosing between batch and streaming ingestion depends on use-case requirements for freshness, volume and cost.
- Batch Ingestion: Aggregates data on a fixed schedule—hourly, daily or weekly—and processes large volumes in bulk. Common tools include Databricks, AWS S3 and Azure Data Factory.
- Stream Ingestion: Captures events in real time to support immediate insights and automated responses. Architectures often leverage Apache Kafka, AWS Kinesis or Google Cloud Storage with Pub/Sub.
Tools and Platforms for Data Collection
- ETL Platforms: Talend, Informatica provide connectors, workflows and quality components.
- Cloud Data Services: Azure Data Lake, Amazon Redshift, BigQuery offer scalable storage and metadata management.
- API Gateways: MuleSoft, Kong simplify secure access to web services.
- Data Catalog and Governance: Alation, Collibra automate metadata harvesting, lineage tracking and policy enforcement.
Orchestrating Data Cleansing and Transformation
This stage converts heterogeneous raw inputs into reliable, standardized datasets ready for AI processing. An orchestration engine sequences profiling, validation, transformation and enrichment tasks, ensuring traceability and governance at each step and delivering a structured output for modeling or analytics agents.
Core Components and Workflow Sequence
- Ingestion Layer: Interfaces that capture new data from file stores, databases and APIs.
- Profiling Service: Tools such as Trifacta or open-source libraries like Pandas profiling detect patterns, nulls and outliers.
- Validation Engine: Rule-based systems that enforce data types, ranges and referential integrity.
- Transformation Modules: Bulk normalization, aggregation and schema mapping via AWS Glue or Azure Data Factory.
- Enrichment Agents: AI-driven services such as DataRobot Paxata augment records with external reference data or predictive features.
- Orchestration Engine: A workflow manager that sequences tasks, handles retries and maintains audit logs.
- Output Repository: A data mart or staging area where cleansed datasets are stored and cataloged.
Typical Action Flow
- Trigger ingestion on schedule or file arrival.
- Invoke profiling service and generate a quality report.
- Execute validation rules; route failures to exception queues.
- Apply normalization, type casting and schema alignment.
- Call enrichment agents to append reference data or compute features.
- Run post-transformation checks to confirm standardization.
- Aggregate results into the output store and notify consumers.
- Produce audit logs and data lineage metadata.
Data Profiling and Validation
Profiling AI agents analyze distributions, null frequencies and pattern deviations to guide validation. Tools such as Great Expectations and TensorFlow Data Validation automate rule generation and anomaly detection. Rule-based engines enforce schema conformance, uniqueness and referential integrity, diverting violations for automated or manual remediation.
Transformation and Enrichment Integration
Standardization includes upper-casing codes, normalizing dates and mapping source schemas to target models using platforms like Informatica or Talend. AI agents hosted on Google Cloud Dataflow perform imputation and feature engineering. Natural language processing agents extract structured fields from unstructured text. Orchestration handles API calls, rate limits and error retries for seamless automation.
AI-Driven Validation and Enrichment Roles
Specialized AI agents enforce quality gates and enrich records with contextual features. By embedding validation and enrichment into the orchestration layer, teams maintain traceability, accelerate insights and improve decision accuracy.
Validation Agents
- Schema Conformance: Verifying field types, lengths and required attributes.
- Anomaly Detection: Identifying outliers, data drift or sudden distribution shifts with statistical and ML techniques.
- Uniqueness and Referential Integrity: Detecting duplicates or orphaned records using fuzzy matching and foreign-key checks.
- Completeness Checks: Flagging missing values and triggering imputation or exception workflows.
Validation agents integrate with Apache Airflow or Prefect to schedule checks post-ingestion and quarantine suspect batches until issues are resolved.
Enrichment Agents
- Entity Resolution: AI models link disparate records into unified profiles.
- Metadata Tagging and Classification: Using the OpenAI API or TensorFlow NLP pipelines to label text and generate semantic embeddings.
- Geospatial Enrichment: Converting addresses to coordinates and appending demographic data.
- Feature Engineering: Generating rolling averages, risk scores and derived metrics via AWS SageMaker Feature Store.
- Third-Party Data Integration: Appending firmographics, credit ratings or market indicators from external APIs.
Metadata and Governance Systems
- Data Cataloguing: Platforms like Azure Purview and Collibra store metadata, track lineage and enable business-glossary search.
- Policy Enforcement Engines: Automating privacy, retention and masking rules for compliance.
- Audit Logging: Recording every validation check, enrichment step and steward approval to support regulatory audits.
Delivering Structured Outputs and Handoffs
Finalizing the preprocessing stage involves producing well-defined output artifacts, formalizing data contracts with downstream consumers and establishing handoff mechanisms that preserve integrity and traceability.
Output Specifications and Formats
- File Formats: JSON, CSV, Apache Parquet or Avro chosen for schema complexity, compression and compatibility.
- Schema Definitions: Documents that list field names, types, allowed ranges and nullability.
- Partitioning Strategy: Organizing by date, region or business unit to optimize query performance.
- Metadata Enrichment: Attaching record counts, timestamps and lineage identifiers to outputs.
- Versioning Rules: Embedding semantic version numbers or timestamps for reproducibility and rollback.
Data Contracts and Dependency Mapping
- Consumption Points: AI agents, data warehouses, BI tools or enterprise applications that ingest the dataset.
- Refresh Cadence: Real-time streams, micro-batches or nightly full refreshes.
- Error Boundaries: Acceptable missing or anomalous record rates and escalation paths.
- Access Controls: Role-based permissions and encryption requirements for sensitive fields.
Quality Assurance and Validation Checks
- Structural Tests: Ensuring outputs match declared schemas with no extra or missing columns.
- Completeness Checks: Verifying record counts and required partitions.
- Referential Integrity: Confirming foreign-key relationships resolve correctly.
- Value Range Assertions: Detecting out-of-bounds values or unexpected null patterns.
- Duplicate Detection: Removing repeated records based on primary or composite keys.
Handoff Mechanisms and Triggering Conditions
- Event-Driven Messaging: Emitting messages to brokers when new data is available.
- API Notifications: Posting webhooks to registered endpoints for on-demand fetch.
- Scheduled Pulls: Downstream processes query object stores or catalogs for new versions.
- File System Watches: Monitoring paths for appearance of files matching naming conventions.
- Orchestration Workflows: Progressing tasks only when prior outputs pass quality gates.
Governance, Traceability and Audit Trails
- Lineage Metadata: Capturing source systems, transformation versions and operator identifiers.
- Processing Metrics: Logging job runtimes, record counts and validation outcomes.
- Immutable Artifacts: Archiving raw and transformed outputs in write-once storage.
- Audit Queries: Providing searchable interfaces for compliance reporting and investigations.
Integration into Downstream Workflows
- Model Training Pipelines: Consuming feature tables for retraining and batch inference.
- Real-Time Inference Engines: Fetching lookup tables and normalization parameters for live predictions.
- Reporting and Visualization: Loading dimensional tables into BI platforms for dashboards.
- Operational Applications: Importing reference data into CRM, ERP or order management systems.
Error Handling, Retry Logic and Scalability
- Automatic Retries: Configurable backoff and retry limits for failed tasks.
- Partial Reloads: Selective reprocessing of affected partitions instead of full pipeline restarts.
- Manual Intervention Gates: Pausing workflows and notifying stakeholders when failures exceed thresholds.
- Fallback Datasets: Using cached versions of previous outputs when fresh data is unavailable.
- Distributed Storage and Asynchronous Delivery: Leveraging object stores, message queues and partition pruning to scale throughput and minimize contention.
By rigorously preparing, cleansing, validating and enriching data, then delivering structured outputs with formal contracts and handoff mechanisms, organizations create a resilient, transparent and scalable foundation for all downstream AI and business processes.
Chapter 3: Selecting and Configuring AI Agents
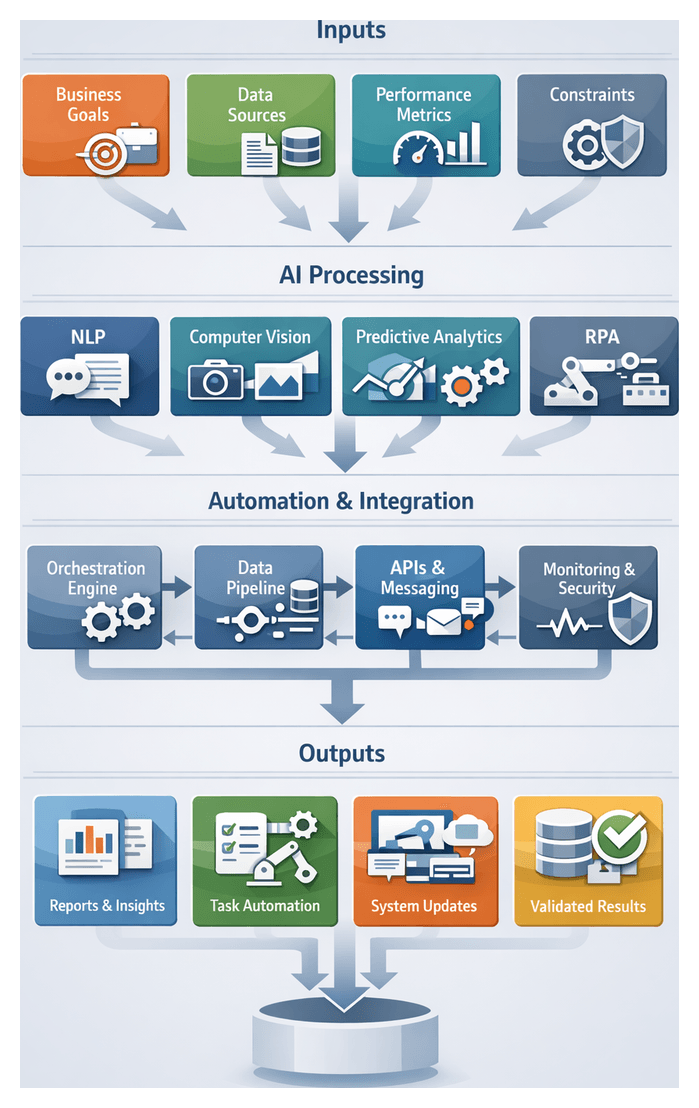
Defining Agent Selection Criteria and Inputs
Establishing clear selection criteria and input specifications creates the foundation for a reliable, scalable AI agent orchestration solution. Organizations articulate business objectives and technical requirements to guide the choice of AI agents, ensure data integrity, and confirm compatibility with existing systems. A structured approach reduces risk, avoids rework, and accelerates deployment.
The objectives of this phase are:
- Clarify functional requirements by translating business goals into precise AI capabilities.
- Ensure data readiness through profiling of sources, formats, and quality metrics.
- Align technical constraints including infrastructure, integration points, and compliance mandates.
- Standardize evaluation via a reproducible framework comparing cost, performance, security, and support.
Successful agent selection relies on four key input categories:
- Business Objectives and Use Cases – Defined goals such as automating invoice approval, extracting customer insights, or routing support tickets.
- Data Characteristics – Profiles of volume, variety, velocity, veracity, formats, error rates, and update frequencies.
- Performance Targets – Benchmarks for accuracy, response time, throughput, and cost per transaction aligned to SLAs.
- Integration and Deployment Constraints – Connectivity requirements, API standards, deployment models, and regulatory obligations.
Before evaluating agents, teams must satisfy key prerequisites:
- Use Case Definition Complete – Documented workflows with decision points, input/output artifacts, roles, and KPIs.
- Data Inventory and Quality Assessment – Cataloged repositories, formats, error rates, and governance policies.
- Technology Stack Overview – Middleware, API gateways, connectivity diagrams, and security frameworks.
- Stakeholder Alignment – Consensus on risk profiles, data usage guidelines, and rollout strategies.
- Budget and Timeline Constraints – License costs, resource projections, and milestone dates for proof-of-concept and full rollout.
With these conditions met, define a weighted scoring model across dimensions such as:
- Capability Fit
- Performance under realistic workloads
- Scalability for volume and concurrency
- Security, compliance, and certifications
- Ease of integration via SDKs and APIs
- Total cost of ownership
- Vendor support and community engagement
This objective framework enables comparison of solutions like Amazon SageMaker, Hugging Face document extraction, or conversational models powered by OpenAI GPT-4. Once agents are shortlisted, specify precise inputs including data schemas, context window limits, preprocessing rules, error handling protocols, and security controls. Documenting these specifications in standardized templates ensures seamless configuration of input pipelines and validation of data conformity before runtime.
Establishing the Imperative for Structured Orchestration
Fragmented, ad hoc automation initiatives often lead to coordination gaps, data silos, and unpredictable outcomes. To scale AI-driven workflows reliably, organizations must adopt structured orchestration frameworks that deliver end-to-end visibility, traceability, and governance.
Common failures of point solutions include:
- Lack of Coordination across disparate scripts and bots.
- Limited Visibility into multi-stage process health.
- Inconsistent Outcomes due to varied error-handling logic.
- Fragmented Governance bypassing enterprise policies.
Structured orchestration defines how tasks flow among AI agents, humans, and legacy systems. Core interaction patterns include:
- Sequential Processing where each stage waits for completion signals.
- Parallel Execution of independent tasks with coordinated aggregation.
- Event-Driven Triggers that activate stages based on data events or manual approvals.
- Conditional Routing using decision gateways on model outputs or business rules.
- Feedback Loops that refine processes using performance metrics or user input.
Embedding governance controls at each transition enforces:
- Role-Based Access Controls for initiation, modification, and approval.
- Approval Gates for compliance reviews or managerial sign-offs.
- Audit Trails capturing inputs, outputs, and decision criteria.
- Policy Enforcement to reject or quarantine data violating standards.
Defining end-to-end workflow objectives ensures alignment with business goals. Typical metrics include throughput targets, latency requirements, accuracy thresholds, compliance ratios, and resource utilization levels.
Roles in the orchestration ecosystem include:
- Orchestration Engine – Central conductor enforcing sequencing and dependency rules via tools such as UiPath Orchestrator.
- AI Agents – Specialized for tasks like language understanding, vision inspection, or predictive scoring.
- Human Operators – Intervene at approval gates, resolve exceptions, and provide feedback.
- Enterprise Systems – Source and sink data through standardized APIs, keeping CRM, ERP, and repositories synchronized.
- Monitoring and Analytics Services – Aggregate logs and metrics, with platforms like DataRobot generating alerts and dashboards.
Modern architectures leverage event-driven integration and centralized state stores to decouple components, react instantly to data changes, and maintain process state. Robust error-handling patterns such as automated retries, fallback paths, escalation workflows, and compensation transactions preserve continuity. Continuous measurement of stage-level throughput, error rates, resource consumption, and user satisfaction enables dynamic optimization and iterative refinement of orchestration logic.
Mapping AI Capabilities and Integration Roles
AI agents provide diverse capabilities that must be aligned to workflow tasks and supported by integration systems. Understanding each function and its supporting infrastructure is essential for a cohesive solution.
Core AI capabilities include:
- Natural Language Processing
- Computer Vision
- Predictive Analytics and Machine Learning
- Robotic Process Automation
- Conversational AI and Virtual Assistants
- Knowledge Graph and Semantic Reasoning
NLP Agent Functions
NLP agents perform text analysis, entity extraction, sentiment detection, and document understanding. They convert unstructured content into structured data using techniques such as tokenization and named entity recognition. Common engines include OpenAI API and TensorFlow models.
Computer Vision Agent Functions
Vision agents interpret images and video for object detection, optical character recognition, and quality inspection. Scalable deployments leverage TensorFlow with orchestration on Kubernetes.
Predictive Analytics and ML Agents
These agents analyze historical data to forecast trends and generate probability scores. Pipelines often use Apache Airflow for orchestration, with models built in TensorFlow and real-time scoring via Apache Kafka.
Robotic Process Automation Agents
RPA agents automate rule-based tasks across applications without code changes to legacy systems. Platforms such as UiPath and Automation Anywhere provide low-code design environments. Integration with NLP or vision agents enables end-to-end automation of both cognitive and structured steps.
Conversational AI and Virtual Assistants
Conversational agents manage multi-turn dialogues using NLP and context tracking. Solutions like Google Dialogflow and IBM Watson Assistant integrate with back-end APIs to process service requests within user conversations.
Supporting systems facilitate communication, data flow, and governance:
Orchestration Platform Responsibilities
Orchestration engines coordinate task sequencing, retries, and dependency tracking. Tools include Apache Airflow and Camunda.
Data Integration and Pipeline Systems
Platforms such as MuleSoft, Dell Boomi, and Informatica handle schema mapping, quality checks, and batch or streaming ingestion.
Messaging, Event Streaming and API Gateways
Decoupled communication relies on Apache Kafka, RabbitMQ, or AWS EventBridge, while API gateways such as Kong and AWS API Gateway enforce security and protocol translation.
Monitoring, Logging and Feedback Agents
Operational visibility is provided by agents collecting metrics and traces, visualized in dashboards via Prometheus and Grafana.
Security, Compliance and Governance Agents
Security gateways and policy engines such as Open Policy Agent enforce access controls, encryption, and audit logging across workflows.
Error Handling, Recovery and Resilience Strategies
Define retry policies, fallback routes, dead-letter queues, and confidence-score thresholds to route low-confidence results to human review. Patterns like circuit breakers and back-pressure controls prevent cascading failures.
Ensuring Scalability and Performance Efficiency
Container orchestration on Kubernetes enables auto-scaling and health checks of AI services. Performance testing guides capacity planning to maintain throughput and latency targets.
Version Control, Model Management and Deployment Pipelines
Frameworks such as MLflow manage model artifacts, metadata, and versioning. CI/CD pipelines automate testing and deployment of new agent configurations across environments.
Strategic Alignment of Capabilities and Roles
A task-to-agent mapping matrix clarifies responsibilities, reduces overlap, and supports governance. Continuous review of performance and resource utilization drives iterative refinement and sustained business value.
Specifying and Managing Agent Outputs
Defining clear output specifications is critical for seamless handoffs in AI orchestration. Outputs must include content structure, format, and metadata to enable automated validation, routing, and integration into downstream systems.
Output Format Standards and Protocols
- JSON for nested structures and web service integration.
- XML for schema-validated exchanges in enterprise service buses.
- CSV for tabular exports and analytics workflows.
- Binary Formats such as Protocol Buffers and Avro for high-throughput serialization.
Data Schema and Metadata Requirements
- Field Definitions specifying names, types, ranges, and cardinality.
- Schema Versioning for backward compatibility and controlled migrations.
- Provenance Metadata including agent IDs, model versions, and timestamps.
- Quality Metrics such as confidence scores and error flags.
Identifying Dependencies and Input-Output Mapping
- Input-Output Matrices linking agent outputs to downstream inputs.
- Conditional Dependencies that trigger alternative paths based on output values.
- Data Transformation Rules for field renaming, type conversions, and filtering.
Designing Handoff Interfaces
- Transport Mechanisms including RESTful APIs, message queues, event streams, or direct database writes.
- Authentication and Security using API tokens, OAuth2, mutual TLS, and encryption.
- Error Handling via retry policies, dead-letter queues, and alert thresholds.
- Timeouts and SLAs to enforce performance objectives.
Ensuring Reliable Handoffs and Continuity
- Idempotency Controls to safely process repeated messages.
- Stateful Checkpointing for resuming long-running processes.
- Circuit Breakers and Back-off Strategies to protect downstream systems.
- Monitoring and Alerting on success rates, latencies, and error volumes.
Versioning and Change Management
- Semantic Versioning for interface updates and compatibility.
- Schema Evolution Policies to add, deprecate, and migrate fields.
- Canary Deployments and A/B Testing for gradual rollouts.
- Documentation and Change Logs to inform developers and stakeholders.
Validation and Monitoring of Agent Outputs
- Schema Validation using automated validators to enforce format and types.
- Quality Gates with rules on confidence scores and error rates.
- Operational Dashboards aggregating throughput, latency, and quality metrics.
- Feedback Loops integrating human-in-the-loop review to improve future accuracy.
By standardizing output formats, enforcing schema and metadata contracts, and implementing reliable handoff interfaces with robust validation and monitoring, organizations ensure that AI agent outputs integrate smoothly into complex workflows. This rigor underpins resilient, scalable, and maintainable AI-driven solutions that consistently deliver business value.
Chapter 4: Designing the Workflow Architecture
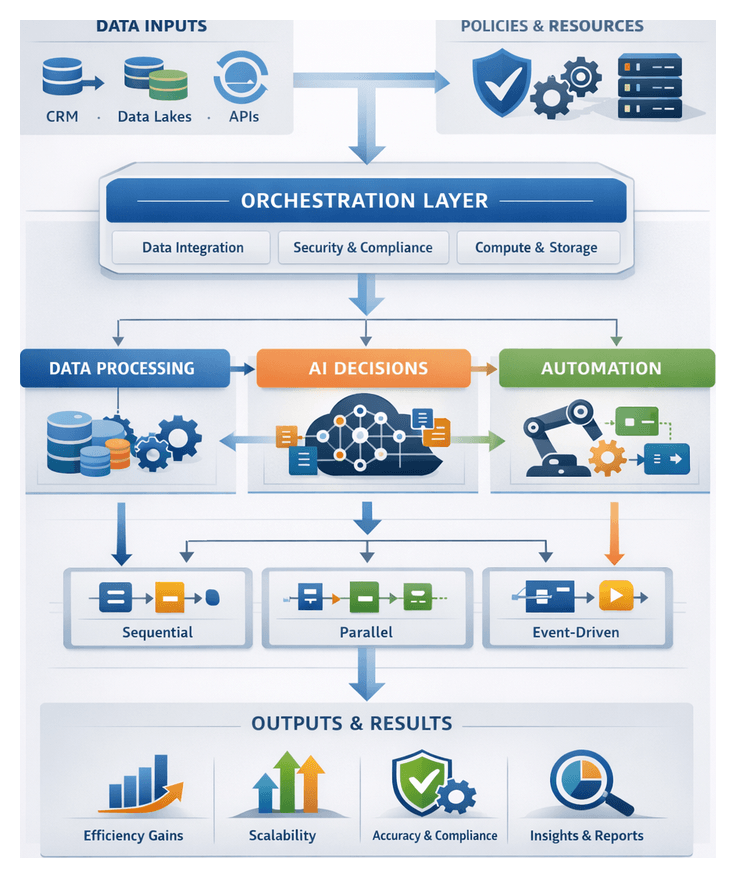
Establishing Workflow Objectives and Data Inputs
Designing an AI-driven orchestration framework begins with clearly defining workflow objectives and assembling a comprehensive blueprint of data inputs. Objectives translate strategic imperatives—such as reducing operational costs or accelerating time-to-market—into concrete performance targets. Common objective categories include:
- Efficiency gains: streamline manual processes, eliminate redundant tasks, and reduce end-to-end cycle times through automation.
- Reliability and consistency: enforce standardized procedures, minimize error rates, and maintain data integrity across all execution paths.
- Scalability: architect systems that accommodate growth in transaction volumes, new business lines, or geographic expansion without significant redesign.
- Transparency and auditability: embed logging and monitoring at decision points to provide end-to-end visibility into data transformations and agent interactions.
- Compliance adherence: incorporate regulatory requirements—such as GDPR, HIPAA, or SOX—into workflow logic and validation gates from the outset.
Establishing these objectives requires collaboration among executive sponsors, process owners, data engineers, and IT architects. Stakeholder workshops capture desired outcomes, map success metrics—like percentage reduction in manual handoffs or error rates—and define acceptable performance thresholds. Documented use cases and key performance indicators (KPIs) ensure that design decisions remain aligned with business strategy.
Concurrently, teams must identify all data inputs that feed the orchestration layer. Data sources often span enterprise systems such as CRM, ERP, HR platforms, cloud data lakes, and external feeds including market data or social media streams. To create a robust data input catalog:
- Inventory all systems: list each source system, database, API, or file repository that provides process-critical information.
- Define schemas and formats: record field-level metadata, message protocols, file types (CSV, JSON, XML), and document structures.
- Assess accessibility: determine whether direct queries, RESTful APIs, message brokers, event streams, or batch file transfers are required.
- Evaluate quality and lineage: profile data for completeness, consistency, and accuracy, and trace its origin to establish trust levels.
- Estimate frequency and volume: forecast data arrival patterns, throughput requirements, peak loads, and latency tolerances.
Early profiling of data inputs mitigates integration risks by revealing transformation requirements, potential cleansing needs, and capacity constraints. It also informs decisions about infrastructure provisioning and network bandwidth.
Defining prerequisites and operational conditions is equally important. Before agent orchestration can commence, teams must ensure:
- Compute and storage provisioning: secure adequate CPU, memory, GPU, and disk resources for data ingestion, model training, and inference workloads.
- Security and compliance controls: implement identity and access management policies, encryption for data in transit and at rest, and audit logging mechanisms.
- Data governance and stewardship: assign ownership of data domains, establish versioning protocols, and define retention and archival policies.
- Service-level agreements: validate availability, throughput, and latency commitments for internal and external APIs, middleware, and third-party services.
- Model readiness: confirm that AI models have undergone rigorous training, validation, performance benchmarking, and bias testing according to organizational standards.
With objectives and prerequisites established, the next step is to set initial parameters and constraints that govern workflow execution. These settings may include:
- Performance thresholds: acceptable ranges for response times, throughput, error rates, and model confidence scores.
- Resource quotas: limits on CPU, memory, or GPU usage per agent or service tier to prevent resource contention.
- Timeout and retry policies: rules for handling failed or delayed operations, including retry intervals, backoff strategies, and escalation pathways.
- Concurrency limits: maximum number of parallel tasks or threads allowed for each orchestration node.
- Data retention rules: duration for which intermediate artifacts, logs, and transaction records are preserved before archival or deletion.
Finally, cross-functional validation workshops map objectives to data inputs and parameters, review prerequisite fulfillment, perform risk assessments for data quality and integration dependencies, and secure stakeholder buy-in. This alignment process transforms high-level goals into a concrete, traceable design blueprint that informs subsequent agent orchestration and implementation activities.
Agent Sequence Orchestration
Defining how AI agents are activated, sequenced, and coordinated is critical for end-to-end process automation. Sequence orchestration ensures that data flows smoothly, decisions occur at the right time, and systems interact without manual intervention. The design involves mapping activation flows, specifying triggers, selecting coordination patterns, and implementing robust synchronization and error handling.
Mapping Activation Flows
A comprehensive activation flow map documents each agent’s inputs, outputs, and logical dependencies. This map should:
- Visualize end-to-end logic: from data ingestion and preprocessing to analytics, decision, and action agents.
- Identify parallelism opportunities: determine which agents can run concurrently without data conflicts.
- Highlight decision gateways: specify conditional branches for exceptions, escalations, or alternate paths.
Collaborative modeling sessions using BPMN tools or low-code workflow designers help align process architects, data engineers, and AI specialists. These sessions result in swimlane diagrams, sequence flows, and state transition diagrams that serve as reference blueprints for implementation.
Designing Trigger Conditions
Triggers define when agents execute. Common types include:
- Event-Driven Triggers initiated by messages on a queue or event bus. For example, a document ingestion agent runs when a new file is uploaded to a repository.
- Time-Based Triggers scheduled at fixed intervals or via cron expressions, ideal for batch analytics or periodic synchronization.
- State-Change Triggers activated when specific data attributes hit predefined thresholds, such as inventory levels or credit utilization rates.
- User-Action Triggers invoked by user requests or API calls for on-demand processing.
Clear trigger semantics and validation logic ensure that preconditions are met before execution, reducing errors and enhancing predictability.
Coordination Patterns
Three primary coordination patterns guide agent interaction:
- Sequential Coordination agents run in a fixed order, suitable for linear workflows where each step depends on prior outputs.
- Parallel Coordination agents execute concurrently on independent tasks or data partitions, improving throughput with synchronization points to merge results.
- Publish-Subscribe Coordination agents subscribe to events published by upstream producers, decoupling components and enabling dynamic topology changes.
Hybrid approaches often combine these patterns, governed by conditional gateways that route execution dynamically based on runtime data.
Implementing Event-Driven Architecture
Event-driven architectures decouple agent interactions and support scalable, responsive workflows. Organizations can leverage platforms such as Apache Kafka, AWS EventBridge, and Azure Event Grid. In this model, agents publish events upon completion or failure, and downstream agents subscribe to relevant event types. This approach reduces direct dependencies, supports dynamic scaling, and simplifies the introduction of new agent types without modifying existing producers.
Synchronization and Dependency Management
Managing complex dependencies and synchronization involves techniques such as:
- State Machines modeled with services like AWS Step Functions or Azure Logic Apps, defining each step, transitions, and error handling behaviors.
- Distributed Locks and Semaphores managed through systems like Redis or ZooKeeper to prevent race conditions when agents update shared resources.
- Barrier Synchronization pausing parallel tasks at barrier points until all participants complete, useful for batch aggregation or synchronized model ensembles.
Explicit dependency metadata allows orchestration engines to optimize scheduling, minimize idle time, and regulate backpressure when downstream systems become saturated.
Error Handling and Retry Mechanisms
A resilient orchestration framework anticipates and mitigates failures with:
- Retry Policies configured with exponential backoff and jitter to handle transient errors gracefully.
- Compensation Workflows that reverse partial updates or rollback transactions when a later stage fails irrecoverably.
- Dead-Letter Queues for isolating events that exhaust retry attempts, enabling manual inspection and remediation without blocking the main event stream.
- Alerting and Escalation to notify operators or trigger alternative processing paths when error thresholds are breached.
Documenting error classifications, expected recovery behaviors, and escalation paths ensures that the orchestration layer remains transparent and maintainable as the agent ecosystem evolves.
AI Decision Point Coordination
Orchestrating AI-driven decisions requires integrating machine learning models, deterministic business rules, and human oversight into a unified decision layer. This coordination layer ensures that each decision point receives appropriate inputs, executes with the required logic, and hands off results to downstream systems or agents, with human intervention only when necessary.
Embedding Business Rules and AI Models
Decision workflows often combine:
- Rule Engines for deterministic policies, thresholds, and approvals.
- Machine Learning Models for probabilistic predictions, confidence scoring, and anomaly detection.
- Human-in-the-Loop Checks for high-risk or ambiguous cases.
For example, a loan underwriting process may reject incomplete applications via rules, call an AI model hosted on AWS SageMaker to predict default risk, and route borderline cases to human analysts. This layered approach balances consistency, speed, and accuracy.
Data Pipelines and System Orchestration
Reliable decision coordination depends on well-architected data pipelines that deliver structured and unstructured inputs to AI agents. Patterns include:
- Event-Driven Pipelines using Apache Kafka to publish data changes and trigger model evaluations in real time.
- Batch ETL Jobs that aggregate features for scheduled inference runs.
- Real-Time APIs that supply contextual data to conversational agents powered by Google Cloud AI Platform.
Orchestration engines coordinate these pipelines, enforcing data contract versioning, handling retries, and monitoring performance metrics and SLAs.
Middleware and Event-Driven Frameworks
Middleware abstracts protocol differences between REST, gRPC, and messaging, manages secure credentials and tokens, routes outputs to appropriate consumers, and load-balances inference requests. Event-driven services such as AWS EventBridge and Azure Event Grid enable low-latency, scalable event routing and decoupled architectures.
Consistency, Traceability, and Monitoring
Transparent decision making requires capturing:
- Input Data Snapshots at each decision node.
- Model Versions, Hyperparameters, and Training Data Lineage.
- Decision Outcomes, Confidence Scores, and Applied Business Rules.
- Audit Metadata including Timestamps, Agent or User IDs, and Exception Flags.
Centralized dashboards—such as IBM Watson OpenScale—aggregate logs and metrics, enabling trend analysis, drift monitoring, and governance reporting. This data supports continuous improvement of decision models and processes.
Leveraging AI Orchestration Platforms
Specialized platforms provide low-code designers, prebuilt connectors for CRM, ERP, and document management, policy templates for approvals and guardrails, and monitoring consoles. An examples includes OpenAI APIs integrated via custom connectors. Standardizing on a unified orchestration layer reduces integration complexity and accelerates time-to-value.
Agent Roles and Collaboration
Different AI agents fulfill specialized functions within decision workflows:
- Analytics Agents analyze numeric or time-series data for forecasting, anomaly detection, and scoring.
- Natural Language Agents interpret unstructured text, extract intent, sentiment, and entities from documents, emails, or chat messages.
- Document Processing Agents convert PDFs, images, and scanned forms into structured records via OCR, classification, and extraction models.
- Recommendation Agents generate personalized suggestions and content rankings using collaborative filtering or deep learning.
These agents collaborate at decision points, feeding results into a central decision engine or state machine, which then routes outcomes to downstream systems or human reviewers as needed.
Best Practices for Decision Point Management
- Modularize agents by function to allow independent updates, testing, and scaling.
- Implement canary deployments to test new models on a small subset of traffic before full rollout.
- Define escalation paths for decisions below confidence thresholds, routing them to secondary models or human experts.
- Automate model retraining with feedback loops that use outcome data to schedule training jobs on platforms like Azure Cognitive Services.
- Regularly audit and refactor business rules to prevent conflicts, redundancies, or coverage gaps as policies evolve.
Deliverables and Handoff Protocols
The culmination of the design phase is a comprehensive set of deliverables and handoff protocols that guide development, integration, and governance. These artifacts ensure clarity on scope, data requirements, execution flow, and compliance obligations.
Core Deliverables
- Process Specification Documents containing narrative descriptions, swimlane diagrams, sequence flows, and data flow diagrams that define each workflow step, decision gateway, and agent interaction.
- Data Contract Definitions with formal schemas (JSON Schema, XML Schema Definition, Avro) specifying field metadata, validation rules, sample payloads, and versioning conventions.
- Dependency Matrix tabulating each component—AI agents, rule engines, external APIs, data stores—including upstream and downstream dependencies, execution order, and failure impact classifications.
- Handoff Protocols detailing API endpoints, HTTP methods, URL patterns, request/response schemas, message broker topics, file transfer conventions, timeout thresholds, retry policies, and error codes.
- Governance and Compliance Checklist specifying security controls (TLS 1.2 , AES-256), IAM policies, audit logging requirements, data masking rules, regulatory mappings (GDPR, HIPAA, SOX), and stewardship responsibilities.
Mapping Dependencies and Resiliency
Dependency mapping involves:
- Component Identification assigning unique identifiers to agents, rule modules, external systems, and human tasks, categorized by functional domain.
- Input and Output Cataloging defining exact data elements each component consumes and produces, referencing data contracts and sample payloads.
- Execution Sequencing specifying logical order or timestamp dependencies, trigger conditions, and concurrency constraints.
- Failure Impact Assessment classifying potential failures as transient or terminal, and linking each to error handling patterns like retry, compensate, or escalate.
- Resiliency Planning identifying critical path components, specifying high availability configurations, load-balancing strategies, backup agents, and alternative data sources.
Formal Handoffs and Control Gates
- API-Based Handoffs for synchronous interactions: define REST or gRPC endpoints, authentication schemes, and contract tests.
- Event-Driven Handoffs for asynchronous integrations: specify event topics, payload schemas, retention policies, and consumer group configurations using platforms like Apache Kafka or AWS EventBridge.
- File Exchange Handoffs for batch workflows: outline directory structures, naming conventions, transfer protocols (FTP, SFTP), checksum or digital signature procedures, and polling schedules.
- Human Task Handoffs for manual approvals: integrate with business process management suites like Camunda or Apache Airflow, specifying user interfaces, access controls, SLA timers, and escalation rules.
- Control Gates and Validation embedding automated checks at each handoff for schema compliance, data integrity, threshold validations, and business rule assertions, with defined error notifications and rollback procedures.
Versioning and Change Management
Workflows must adapt over time. Formal versioning and change management processes include:
- Semantic Versioning applies MAJOR.MINOR.PATCH conventions to data contracts, incrementing versions based on compatibility impacts.
- Component Release Cycles define branching strategies, release windows, and CI/CD pipelines for automated integration and end-to-end testing.
- Impact Assessment Workflows engage a change review board to evaluate proposed modifications, update dependency matrices, and revise compliance checklists prior to production rollout.
Tooling and Best Practices
Effective execution relies on integrated toolchains for design, documentation, and governance. Recommended tools include:
- Workflow Modeling with BPMN editors such as the Camunda Modeler to design, version, and export process diagrams.
- API Documentation using Swagger/OpenAPI or Postman to publish interactive specifications and generate client libraries.
- Event Schema Registries like Confluent Schema Registry to manage Avro, JSON, or Protobuf schemas and enforce compatibility rules.
- Policy-as-Code Frameworks such as Open Policy Agent (OPA) or enterprise GRC platforms for automated compliance checks and policy enforcement.
By delivering comprehensive specifications, mapping all dependencies, and defining rigorous handoff and compliance protocols, teams create a scalable, reliable, and auditable foundation for AI-powered workflows. This robust design phase bridges the gap to development and deployment, ensuring smooth implementation and continuous optimization.
Chapter 5: Integration with Enterprise Systems
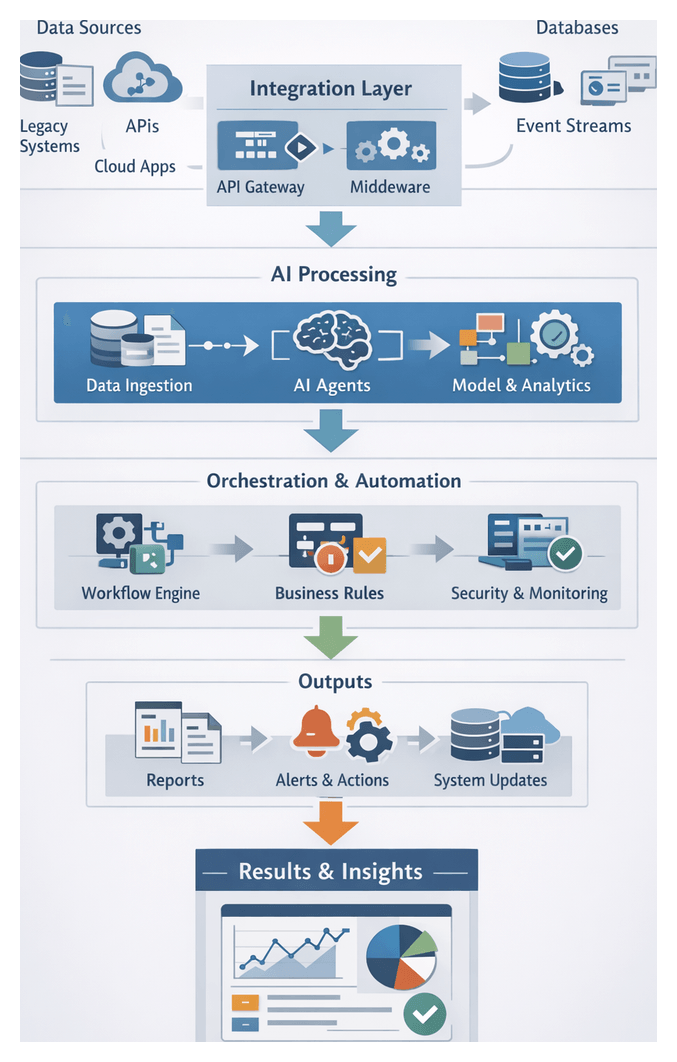
Background and Purpose of Enterprise Integration
In today’s digital transformation landscape, enterprises leverage AI-driven automation to optimize decision-making and customer experience. However, realizing the full potential of intelligent agents requires seamless integration with both legacy and modern systems. Transitioning from monolithic architectures to API-led microservices promotes reuse, scalability and agility—replacing brittle point-to-point connections with standardized interfaces. Early articulation of integration requirements prevents costly refactoring and enables parallel innovation among business, IT and AI specialists.
Hybrid cloud architectures further complicate integration, as on-premises databases, private cloud services and public cloud applications must coexist under consistent security and performance policies. Integration planning must address network latency, data sovereignty and governance across environments. Establishing clear parameters at the outset ensures reliable data exchange, maintains compliance and supports AI-driven workflows at enterprise scale.
Defining Integration Scope and Interfaces
System Inventory and Data Endpoints
Effective integration begins with a comprehensive inventory of systems, APIs and data sources:
- Application landscape documentation, including vendor names, versions and deployment models.
- API specifications and service contracts for REST endpoints, SOAP operations and payload schemas.
- Data dictionaries or metadata catalogs detailing field definitions and business rules.
- Authentication mechanisms such as OAuth tokens, API keys, SAML assertions or JSON Web Tokens.
- Network topology diagrams, firewall rules and VPN requirements.
- Service level agreements specifying throughput, latency and availability targets.
Streaming and event-driven sources—such as Apache Kafka or corporate event buses—require definitions of topic schemas, retention policies and consumer groups. Callback URLs, webhook configurations and queue endpoints support asynchronous workflows, while idempotency protocols and retry policies guard against duplicate processing.
Prerequisites: Security, Network and Compliance
Before integration work begins, teams must establish:
- Service accounts with least-privilege access and secure token vaults for credentials.
- Identity federation or single sign-on with providers like Okta.
- Encryption in transit and at rest to protect sensitive data flows.
- Firewall rules, dedicated virtual private clouds and load-balancing configurations for high availability.
- Compliance checks for data residency, audit logging and industry mandates such as GDPR, HIPAA or SOX.
Staging and sandbox environments enable connectivity testing, capacity planning and failover simulations, ensuring that integration channels can handle production loads and recover gracefully from component failures.
Alignment with Business Objectives
Integration endpoints must support key workflow goals, for example:
- Real-time synchronization between CRM systems—such as Salesforce—and AI customer service agents.
- Batch or streaming ingestion from ERP platforms like SAP S/4HANA into predictive analytics agents.
- Document retrieval from Microsoft SharePoint for AI-driven content classification.
- Event triggers from Apache Kafka to initiate AI agent workflows.
Pilot integrations with representative endpoints validate performance, data transformations and security policies—informing the broader integration roadmap and refining data mappings and error-handling logic before enterprise-wide deployment.
Endpoint Interfaces and Data Contracts
Each integration point requires a defined data contract that specifies:
- Operation definitions, including HTTP verbs, URI templates and input parameters.
- Payload structures with field-level definitions, data types and validation rules.
- Response codes and error payload formats to support exception handling.
- Asynchronous patterns such as publish-subscribe or request-reply.
- Schema versioning strategies for backward compatibility.
Publishing API documentation to a developer portal—with sample requests, sandbox credentials and interactive consoles—facilitates contract-driven development. Tools like Swagger Codegen or OpenAPI Generator can scaffold stubs and client libraries, while CI/CD pipelines and semantic versioning ensure stable interfaces for AI agents.
Tooling for Enterprise Integration
Common integration platforms and middleware include:
- MuleSoft Anypoint Platform for API-led connectivity and reusable assets.
- Dell Boomi AtomSphere for low-code integration flows and pre-built connectors.
- IBM App Connect for event-driven and API integrations.
- Azure Logic Apps for serverless orchestration.
- Apache Camel and Spring Integration for code-centric routing and transformation.
Selection criteria include connector availability, security standard support, scalability, monitoring features and total cost of ownership. Commercial suites offer enterprise support and connectors, while open-source frameworks reduce licensing costs but may require more internal expertise.
Middleware Workflows and API Orchestration
Role of Middleware
The middleware layer orchestrates data flows, API calls and business logic across enterprise systems and AI agents. By abstracting connectivity, providing transformations and managing transactional integrity, it decouples AI services from core applications and enforces consistent validation rules before and after agent execution. Centralized logging, distributed tracing and security policies ensure traceability and governance.
Orchestration Models and Patterns
Key middleware patterns include:
- Request-Response: Synchronous API calls for low-latency tasks.
- Publish-Subscribe: Asynchronous messaging via brokers for long-running AI processes.
- Choreography: Event-driven handlers coordinating actions without a central orchestrator.
- Central Orchestration: Defined workflows with sequence control, error handlers and compensation transactions.
API Gateway and Management
An API gateway consolidates endpoints, enforces security and provides traffic management:
- Authentication and authorization using OAuth 2.0 or JWT.
- Rate limiting, throttling and IP whitelisting.
- Request transformation, such as XML-to-JSON conversion.
- Centralized logging for audit trails and performance metrics.
Integration Workflow Sequence
- An upstream system issues a request to the API gateway.
- The gateway applies validation and routes to the orchestrator.
- The orchestrator invokes AI agents via REST or gRPC.
- Agents process inputs—such as document text or transaction data—and return results.
- The orchestrator applies transformations, merges context and triggers subsequent tasks or publishes messages to queues.
- For asynchronous flows, workers resume when agents complete processing.
- Final results are compiled and returned through the gateway or pushed to target systems.
Error Handling and Reliability
Resilient orchestration employs:
- Retry policies with exponential back-off for transient failures.
- Circuit breakers to halt calls to failing endpoints.
- Compensation transactions for rollback on partial failures.
- Dead-letter queues for messages that exhaust retries.
- Automated alerts for threshold breaches via tools like PagerDuty or Opsgenie.
Observability and Monitoring
End-to-end visibility is achieved through:
- Distributed tracing with correlation IDs across gateway, orchestrator and agents.
- Metrics and dashboards for request rates, latencies and error counts.
- Log aggregation via the ELK Stack or Apache NiFi.
- Health checks, endpoint pings and self-healing mechanisms.
AI Agent Roles within Integrated Workflows
Agent Responsibilities
Clear role definitions prevent task overlap and ensure accountability:
- Data Ingestion Agents capture, validate and normalize raw inputs.
- Processing Agents execute domain-specific logic—text extraction, image recognition or computations.
- Decision Agents apply models or rule engines for recommendations and risk assessments.
- Orchestration Agents manage task sequences, enforce SLAs and handle retries.
- Audit Agents collect logs and metrics for monitoring and compliance.
- User Interface Agents facilitate human-agent collaboration via chatbots or dashboards.
Core AI Capabilities
Key AI functions enhance workflow efficiency:
- Natural Language Understanding: Interprets unstructured text, extracts entities and classifies intent.
- Computer Vision: Analyzes images or video for pattern detection and compliance verification.
- Predictive Analytics: Forecasts outcomes—customer churn, demand or maintenance windows.
- Recommendation Engines: Personalize suggestions using collaborative or content-based filtering.
- Anomaly Detection: Flags deviations in transactions, network traffic or operations metrics.
- Robotic Process Automation: Automates rule-based tasks against legacy systems without APIs.
Supporting Infrastructure
- Data Lakes and Warehouses centralize historical and real-time data.
- Message Brokers and Event Buses enable asynchronous communication.
- API Gateways secure and expose agent endpoints.
- Orchestration Engines coordinate multi-step workflows and decision logic.
- Model Serving Platforms host and version AI models with resource management and A/B testing.
- Monitoring and Logging Services aggregate operational data for alerting and analysis.
- Security Frameworks enforce data privacy, access controls and audit trails.
Integration Patterns and Handoffs
Standardized patterns ensure seamless agent interactions:
- Pipeline Choreography: Agents subscribe to events, process messages and publish results.
- Central Orchestration: Engines invoke agents in sequence with branching and compensation logic.
- Service Mesh: Secure, observable service-to-service communication.
- API Composition: Gateways aggregate multiple agent responses into unified payloads.
- Batch Processing: Scheduled agent runs on data snapshots with aggregated outputs.
Defining input/output contracts with schemas, SLAs and error protocols minimizes integration friction and accelerates time to value.
Cohesion and Traceability
Maintain governance and visibility through:
- Correlation Identifiers for cross-system tracing.
- Process Metadata capturing timestamps, agent versions and decision rationales.
- Health Checks and Heartbeats for proactive failure detection.
- Dynamic Configuration Management for on-the-fly tuning and rapid rollback.
- Governance Dashboards displaying throughput, error rates and resource utilization.
Delivered Data Streams and System Handovers
Output Schema and Serialization
Consistent output schemas and serialization formats—JSON, XML, Avro or Parquet—are foundational. Key practices include:
- Defining mandatory and optional fields with types, constraints and validation rules.
- Including metadata—agent ID, timestamp, workflow version and latency—for auditing.
- Using schema registry services—for example, with Apache Kafka—to manage compatibility.
- Documenting compression mechanisms such as Gzip for large payload optimization.
Delivery Patterns
- Real-time streaming via webhooks, message queues or publish-subscribe channels.
- Near-real-time micro-batches grouping records in short intervals to balance latency and throughput.
- Scheduled batch transfers—hourly, nightly or weekly—using SFTP, FTP or bulk API calls for legacy systems.
Capture SLAs for latency, throughput and error rates, aligning metrics with business expectations.
Dependency Management and Sequencing
- Track task statuses in orchestration engines and trigger handoffs only when prerequisites are satisfied.
- Use barrier synchronizations for parallel branches, ensuring convergence before payload packaging.
- Define timeout and retry policies for missing inputs, with escalation or fallback logic.
- Annotate dependency lineage in payload metadata for provenance and recomputation.
System Interfaces and Handoff Protocols
Formalize handoff contracts covering:
- Transport mechanisms: RESTful APIs, gRPC, Kafka topics, RabbitMQ exchanges or file drops.
- Authentication: OAuth tokens, mutual TLS certificates, API keys or service principals.
- Endpoint details: URI patterns, HTTP methods and header conventions.
- Queue/topic naming and partitioning for message-based handoffs.
- File naming, directory structures and checksum validation for SFTP.
Error Handling and Fallbacks
- Immediate retries with exponential backoff for transient failures.
- Dead-letter queues or quarantine storage for messages exhausting retries.
- Alternate delivery channels—secondary queues or batch file transfers.
- Automated alerts via PagerDuty or Opsgenie when failures exceed thresholds.
Detailed logs of error contexts, response codes and payload samples facilitate root-cause analysis.
Security, Compliance and Monitoring
- Encrypt data in transit with TLS 1.2 and apply field-level encryption or tokenization using HSMs or cloud KMS.
- Enforce IAM policies to restrict publish/consume permissions.
- Implement audit logging—recording requester identity, timestamps, checksums and delivery outcomes for GDPR, HIPAA or SOX compliance.
- Conduct penetration tests and vulnerability scans on integration points.
- Instrument delivery processes to capture throughput, latency, success rates, queue depth and consumer lag.
- Use distributed tracing tools—Jaeger or Zipkin—to visualize end-to-end context propagation.
Governance and Continuous Improvement
- Apply semantic versioning to output schemas and APIs, negotiating supported versions via schema registries.
- Announce deprecation timelines and provide migration guides for fields or endpoints.
- Enforce formal review processes for changes to handoff contracts.
- Validate new implementations with automated contract tests.
Iterative refinement—based on stakeholder feedback, performance metrics and error trends—ensures delivered streams remain aligned with evolving business needs and technical landscapes.
Chapter 6: Automating Task Execution and Decision Flows
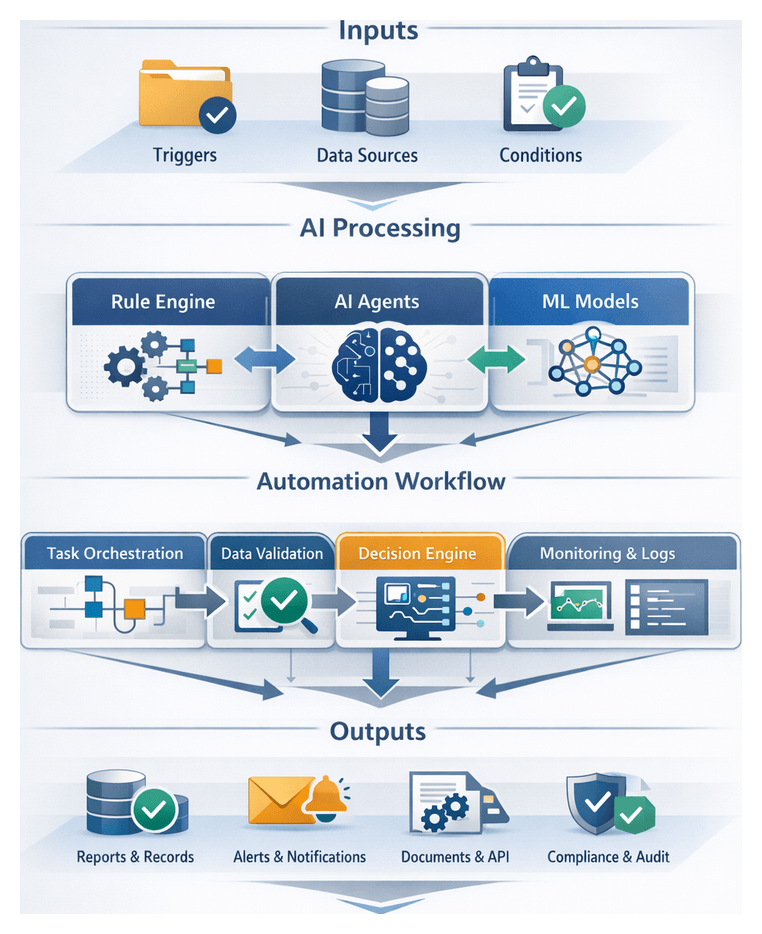
Defining Automation Goals and Input Conditions
Establishing clear objectives and precise input conditions is the foundation of any successful automation initiative. By articulating the purpose, scope, triggers, and data requirements of automated tasks, organizations align technical implementations with strategic imperatives and ensure reliable execution across complex environments.
Purpose and Scope
Automation replaces manual, repetitive activities with predefined logic and AI-driven decision making to reduce cycle times, minimize errors, ensure compliance, and improve resource utilization. Appropriate scoping focuses on high-volume processes with well-documented inputs and outputs, avoiding edge cases that demand extensive human judgment. A well-defined scope delivers:
- Operational consistency across teams and regions
- Predictable throughput and service-level adherence
- Scalability to handle variable workloads without added headcount
- Data-driven insights into performance and bottlenecks
- Seamless integration points with CRM, ERP, and document repositories
Example: In accounts payable automation, scope may include invoice data extraction, three-way matching, and payment scheduling, with exceptions routed according to predefined criteria.
Identifying Triggers
Triggers define when automation begins. They fall into three categories:
- Event-based: Actions such as file uploads, message arrivals, or webhooks initiate workflows.
- Schedule-based: Timers or cron expressions launch processes at regular intervals.
- Conditional: Data thresholds or rule violations, for example, inventory levels falling below reorder points.
Implement triggers using integration platforms or orchestration engines such as AWS Step Functions or Microsoft Power Automate to balance responsiveness with resource efficiency.
Data Requirements and Preprocessing
Precise data definitions prevent failures due to incomplete, misformatted, or stale inputs. Key considerations include:
- Source connectivity: Verify permissions for databases, document stores, and APIs.
- Schema and formats: Define field mappings, data types, and value ranges. Follow ISO 8601 for dates and standardize numeric precision.
- Validation rules: Automate anomaly detection and quality scoring with tools like DataRobot.
- Preprocessing: Cleanse inputs by trimming whitespace, normalizing text case, and resolving encoding issues.
- Latency requirements: Distinguish between sub-minute data for real-time tasks and daily refresh cycles for batch reports.
Example: Mortgage workflows require OCR processing of documents and confidence thresholds before automated underwriting proceeds.
Infrastructure and Environment
Automation depends on a stable technical environment. Prerequisites include:
- Compute and orchestration: Provision virtual machines, containers, or serverless functions and use platforms such as Kubernetes for scalability.
- Network and security: Establish secure connections via VPNs or service meshes. Manage secrets with HashiCorp Vault and enforce IAM policies.
- Compliance and audit logging: Capture execution traces and decision outputs for regulated industries.
- Dependency management: Version libraries, SDKs, and AI frameworks, including OpenAI APIs.
Stakeholder Alignment and Governance
Engage process owners, IT, legal, and compliance teams early to define decision rights, change management procedures, risk assessments, and escalation protocols. Form a steering committee or center of excellence to oversee input specifications and approve governance criteria.
Success Metrics and Validation
Define metrics to validate performance against strategic goals:
- Accuracy: Percentage of tasks completed without human intervention.
- Throughput: Instances processed per time unit.
- Latency: Duration from trigger to completion against SLOs.
- Error rates: Frequency of exceptions requiring manual resolution.
- Compliance: Adherence to regulatory controls and audit success rates.
Example: Insurance claims automation targets 95 percent accuracy in data extraction, routing low-confidence cases to human review.
Rule and Agent Action Sequencing
Automated workflows rely on synchronized sequences of rule evaluations and AI agent activations to manage complex process variations and maintain governance. Rules encapsulate explicit business logic, while AI agents perform tasks such as language comprehension, document classification, and predictive analytics. Mapping these components ensures predictable, auditable execution paths and robust exception handling.
Core Sequencing Components
- Rule engine: Evaluates conditions to determine the next action or agent assignment.
- Orchestration layer: Coordinates task scheduling and invokes agents with the correct payload.
- AI agents: Execute discrete functions, e.g., OpenAI GPT-4 for language tasks.
- Message bus or event queue: Decouples producers from consumers via platforms like Apache Kafka or RabbitMQ.
- Monitoring and logging: Capture each evaluation and outcome using Prometheus and Grafana.
- Error handlers: Trigger fallback rules, notifications, or manual reviews upon failures.
Interaction Patterns
- Synchronous calls: Immediate feedback for low-latency decisions, suitable for UI validations.
- Asynchronous messaging: Event publication and agent pull models for long-running tasks.
- Chained execution: Multi-step pipelines where agent outputs feed subsequent rules.
- Parallel branching: Concurrent agent processing with result aggregation before advancing.
Sequencing Best Practices
- Define clear entry and exit criteria for each sequence segment to streamline handoffs.
- Modularize rules into reusable sets for maintainability.
- Implement version control for rules and agent configurations to enable rollback.
- Adopt circuit breakers to suspend downstream calls when error thresholds are exceeded.
- Enable dynamic routing of agents based on performance metrics or contextual factors.
- Log contextual metadata, including timing, decision rationale, and resource usage.
Coordination and Handoffs
- Event-driven: Rule engines emit named events that agents subscribe to, promoting asynchronous scaling.
- Direct invocation: Orchestration layer calls agent APIs upon rule evaluations for deterministic processing.
- Stateful context: Maintain shared context objects carrying inputs and intermediate results.
- Checkpoint and resume: Persist checkpoints in durable storage to recover from failures without restarting entire sequences.
Governance and Traceability
- Audit trails: Log every rule evaluation and agent response with timestamps and identities.
- Policy gates: Embed approval steps for high-risk transactions or sensitive data access.
- Dashboarding: Aggregate metrics like rule hit rates and exception frequencies for performance monitoring.
- Feedback loops: Integrate manual override data to refine rules and retrain models.
Tool Considerations
- Rule management: Drools and IBM Operational Decision Manager.
- Orchestration engines: Apache Airflow and AWS Step Functions.
- Event brokers: Apache Kafka and RabbitMQ.
- AI agent platforms: OpenAI GPT-4.
- Monitoring: Prometheus and Grafana.
Integrating AI Decision Engines and Logic
Intelligent decision orchestration combines AI decision engines, machine learning models, and rule-based systems to convert insights into automated actions. This logic layer centralizes decision-making, ensuring adaptability, explainability, and alignment with business policies.
Decision Engine Roles
A decision engine evaluates inputs against rules and models to determine actionable outcomes. Its responsibilities include:
- Aggregating data from agents, user inputs, and external systems.
- Applying structured business rules and decision tables.
- Invoking AI models for predictions or classifications.
- Generating outputs as API calls, notifications, or instructions.
- Ensuring traceability by logging each decision step.
Machine Learning Integration
Embedding ML models adds predictive and prescriptive capabilities. Integration requires:
- Model serving: Deploy inference endpoints with Amazon SageMaker or Azure Cognitive Services.
- Feature management: Use Databricks Feature Store to maintain consistency between training and production.
- Version control: Track models and experiments with MLflow or Weights & Biases.
- Latency optimization: Select appropriate hardware accelerators and implement caching.
- Drift detection: Monitor data distribution shifts and retraining triggers.
Rule-Based Systems
Rule engines enforce deterministic policies, compliance requirements, and exception handling:
- Decision modeling: Adopt DMN standards for decision tables and requirements diagrams.
- Authoring environments: Enable business analysts to manage rules via low-code tools like Drools and Camunda.
- Priority management: Define rule ordering and conflict resolution strategies.
- Exception workflows: Configure human-in-the-loop escalations when inputs fall outside valid ranges or model confidence is low.
Hybrid Orchestration Architectures
Combine microservices, rule engines, and inference services under an orchestration framework for modularity and scalability:
- Orchestration engines: IBM watsonx Orchestrate or Zeebe drive workflow execution.
- Microservices: Deploy decision components independently for targeted scaling.
- Event-driven triggers: Use Apache Kafka or Confluent Kafka and Airbyte for data ingestion.
- Transaction management: Implement retry, compensation, and rollback mechanisms for consistency.
Supporting Infrastructure
- API gateways: Manage authentication and routing for decision services.
- Security: Enforce encryption and access controls with Okta and Palo Alto Networks.
- Observability: Centralize logs and metrics using Datadog or Prometheus.
- Configuration management: Ensure consistent deployments via Terraform and Ansible.
Design Best Practices
- Separate concerns: Isolate rules, models, and orchestration logic into distinct modules.
- Explainability: Log inputs, evaluations, and model outputs to provide human-readable justifications.
- Automated testing: Implement unit tests for rules, integration tests for workflows, and model validation tests.
- Version control: Manage artifacts through source control with rollback capabilities.
- Performance tuning: Profile workflows, cache outcomes, and batch inference requests.
- Governance processes: Establish approval workflows for rule and model changes.
Task Outputs, Routing and Governance
Defining and managing automated task outputs ensures seamless consumption by downstream systems, reliable handoffs, and compliance with governance policies.
Output Formats and Quality Criteria
Automated tasks produce various artifacts:
- Structured records: JSON, XML, or CSV for database ingestion.
- Document artifacts: PDF or Word via template engines.
- Message payloads: Avro or Protobuf dispatched to event buses.
- Visual dashboards: Charts in tools like Tableau or Datadog.
- Notifications: Email, SMS, or in-app alerts.
Quality and validation criteria include schema compliance, completeness checks, consistency rules, performance benchmarks, and auditability metadata.
Dependency Mapping and Preconditions
Map upstream dependencies and enforce preconditions to prevent race conditions and cascading failures:
- Data lineage: Link output fields to source data and transformations.
- Service requirements: Document API endpoints, authentication, and rate limits.
- Approval gates: Identify human sign-offs before proceeding.
- Model readiness: Confirm AI models are loaded and within performance thresholds.
- Timing constraints: Manage batch windows and SLA deadlines.
Enforcement techniques include conditional branching, real-time validation calls, semaphore locks, retry and backoff policies, and health check monitors.
Routing and Handoff Mechanisms
Outputs are routed to consumers through message‐driven or API‐driven patterns:
- Event buses: Publish events to Apache Kafka or Amazon EventBridge.
- Message queues: Enqueue payloads in RabbitMQ or Azure Service Bus.
- Webhooks: HTTP callbacks for immediate notifications.
- ESB platforms: MuleSoft for protocol translation and routing.
- RESTful APIs: Expose endpoints for fetching and pushing results.
- GraphQL and gRPC: Support flexible queries and low-latency calls.
- Middleware: Zapier and ServiceNow for cross-application orchestration.
Escalation Paths and Exception Handling
Define classification and handling of deviations from ideal flows:
- Validation failures: Missing fields or failed checks.
- Service errors: Timeouts or error codes from external systems.
- Model confidence alerts: Low confidence triggering human review.
- Concurrency conflicts: Locking issues from simultaneous tasks.
Automated incident handling involves:
- Alerting: Notifications via Slack or Microsoft Teams.
- Ticket creation: ServiceNow or Jira Service Management.
- Escalation rules: Role-based routing to on-call engineers or process owners.
- Fallback procedures: Alternative endpoints or manual interventions.
- Resolution workflows: Triage, root cause analysis, and closure documentation.
Governance Artifacts and Audit Logs
Maintain audit trails and compliance reports:
- Execution logs: Task start and end times, agent IDs, and status codes.
- Data change records: Immutable snapshots or diffs.
- Decision rationale: Model inputs and confidence scores.
- Approval histories: Manual intervention timestamps and user IDs.
- Routing metadata: Source, destination, and timestamps.
Generate regulatory reports for GDPR, HIPAA, or SOX, implement retention and archival policies, enforce role-based access controls, and visualize governance metrics in Splunk or Datadog dashboards.
Integration Examples
Financial Reconciliation: An AI agent compares invoices and bank transactions, produces a CSV report, publishes it to a secure SFTP server, and notifies the accounting system via REST API. Discrepancies trigger email alerts and ServiceNow tickets, with audit logs capturing decision thresholds.
Customer Support Triage: A natural language agent classifies support emails, outputs labels and priority scores to a message queue, and auto-assigns tickets in Jira. Low-confidence cases generate Slack alerts. All interactions are logged for analysis in Datadog.
Supply Chain Exception Management: A transportation AI predicts delays, outputs JSON notices to MuleSoft for routing, and triggers SMS notifications. Critical alerts create ServiceNow incidents. Governance dashboards in Splunk display exception metrics.
These artifacts, routing confirmations, and exception records feed into monitoring and feedback mechanisms, ensuring seamless continuity across the automation landscape.
Chapter 7: Monitoring Performance and Feedback Mechanisms
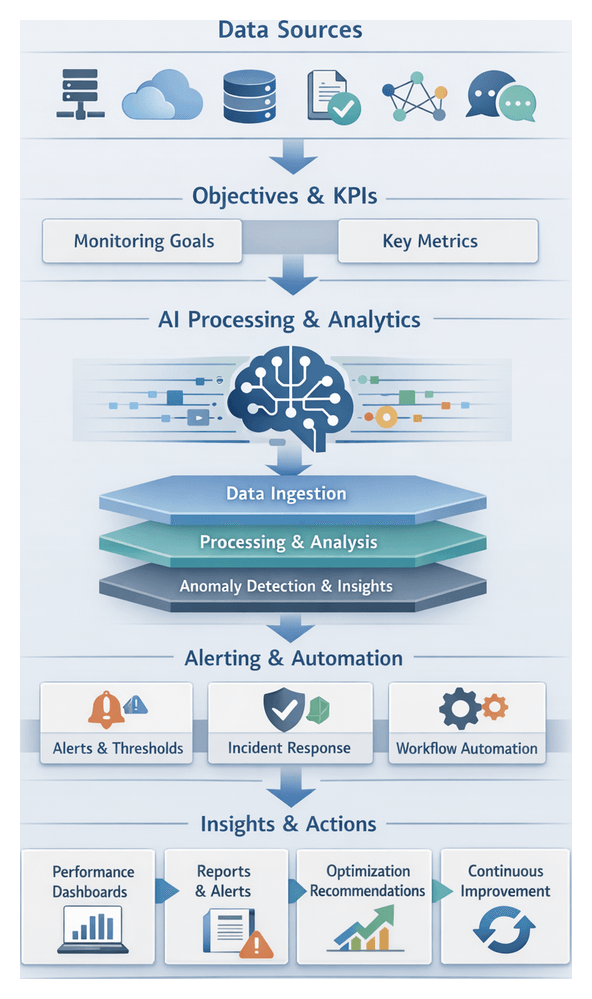
Monitoring Objectives and Data Sources
Effective monitoring begins by translating strategic goals into measurable criteria and identifying the data inputs required to track them. Clear objectives ensure transparency, accountability, and agility in AI agent orchestration, enabling early detection of failures, performance degradation, and opportunities for continuous refinement.
Defining Monitoring Objectives
Monitoring objectives align business priorities with technical metrics. Objectives should be Specific, Measurable, Achievable, Relevant, and Time-bound. Typical dimensions include:
- Operational Reliability: Ensuring agent availability, minimizing downtime, and detecting bottlenecks.
- Performance Efficiency: Measuring response times, throughput rates, and resource utilization.
- Quality Assurance: Tracking error rates, data integrity, and output accuracy.
- User Experience: Assessing satisfaction levels, interaction relevance, and latency.
- Compliance and Security: Monitoring access controls, data handling, and policy adherence.
Example objective: “Reduce average AI agent response time for invoice processing to under 500 ms within the next quarter.”
Establishing Key Performance Indicators
KPIs operationalize objectives by specifying metrics, data sources, thresholds, and reporting cadences. Common KPIs include:
- Agent Availability Rate: Percentage of time agents can process requests.
- Task Success Rate: Ratio of error-free completions to total tasks.
- Mean Time to Detect (MTTD): Time to identify degradations or failures.
- Mean Time to Resolution (MTTR): Time to remediate incidents.
- Throughput per Second: Transactions processed per second.
- Data Quality Score: Composite of completeness, consistency, and validity.
- User Satisfaction Index: Aggregated end-user feedback ratings.
Define alert thresholds to avoid false negatives and alert fatigue, for example, task success rate below 98 percent or CPU utilization above 80 percent for five minutes.
Prerequisites for Effective Monitoring
Establishing a solid foundation prevents blind spots and data inconsistencies. Essential prerequisites are:
- Instrumentation Framework: Deploy SDKs or agents that emit structured logs, metrics, and traces. Adopt OpenTelemetry standards.
- Baseline Performance Profiles: Capture historical data to define normal variability.
- Data Pipeline and Storage: Use streaming platforms like Apache Kafka or Redis Streams, and store telemetry in time-series databases such as InfluxDB.
- Access Control and Compliance: Implement role-based access controls and encryption to meet regulations like GDPR or HIPAA.
- Time Synchronization: Synchronize clocks via NTP across all services.
- Naming Conventions and Taxonomy: Standardize metric labels and log schemas for easy querying.
Identifying and Cataloguing Data Sources
A comprehensive monitoring solution aggregates data from multiple sources to deliver a 360-degree view:
- Application and Agent Logs: Structured JSON logs with timestamps, error codes, and metadata.
- System and Infrastructure Metrics: CPU, memory, disk I/O, network throughput from hosts, containers, and cloud services.
- Distributed Traces: End-to-end spans capturing request journeys across agents.
- Business Process Metrics: Counts and gauges for events like orders processed or inquiries handled.
- External System Logs and APIs: Integration performance data from CRM, ERP, or payment gateways.
- User Interaction Data: Session logs, chat transcripts, clickstreams, and feedback ratings.
- Security and Audit Logs: Authentication attempts, policy enforcement, and access records.
- Incident and Alert Histories: Tickets, notifications, and root cause analyses for trend forecasting.
Data Integration and Quality Controls
Governed ingestion ensures data integrity and usability:
- Schema Validation: Use JSON Schema validators to detect drift.
- Filtering and Sampling: Exclude non-critical logs and apply deterministic sampling for traces.
- Timestamp Normalization: Convert to UTC for correlation while retaining original values for audit.
- Data Enrichment: Add contextual metadata such as version, region, or tenant.
- Back-pressure Handling: Buffer and retry to prevent data loss during spikes.
- Retention and Archiving: Define tiered policies for raw, aggregated, and archival storage.
Aligning Data Sources to Objectives
Map each data field to its corresponding KPI and dashboard widget. Produce a monitoring matrix that specifies:
- Data source, collection interval, and aggregation windows.
- Alert conditions and severity levels tied to thresholds.
- Ownership and escalation paths for each metric.
Example: An “Invoice Processing Latency” KPI may combine span durations from distributed traces with queue depth metrics from messaging systems.
Collaboration and Governance
Monitoring frameworks require cross-disciplinary collaboration:
- Monitoring Lead or SRE Engineer: Designs architecture and configures alerts.
- Data Engineer: Implements telemetry pipelines and quality controls.
- AI Ops Specialist: Tunes models and refines instrumentation.
- Business Stakeholder or Product Owner: Validates alignment with strategic goals.
- Security and Compliance Officer: Oversees privacy, security, and regulatory adherence.
Governance bodies should review frameworks, data access protocols, and alert thresholds at regular intervals to retire obsolete metrics and incorporate new requirements.
Performance Tracking and Alert Workflows
A defined workflow captures, processes, and acts upon performance data in real time, integrating event sources, analytics agents, and notification channels to enable rapid detection and response.
Event Capture and Logging
Instrument all handoff points to emit structured events aligned to KPIs:
- Define event schemas for latency, error rates, and utilization.
- Use logging libraries that emit JSON logs with metadata: agent ID, workflow stage, request ID, timestamp, and user context.
- Route logs to centralized collectors via Fluentd or Logstash.
- Redact or hash sensitive fields to ensure privacy.
Real-Time Monitoring Pipelines
- Ingestion Layer: Stream data through Apache Kafka or AWS Kinesis.
- Transformation Layer: Normalize and enrich events using frameworks like Apache Flink or Apache Spark Structured Streaming.
- Metric Extraction: Convert events into time-series metrics; compute percentiles for latency and error ratios.
- Storage and Indexing: Persist metrics in Prometheus, InfluxDB, or Elasticsearch.
- Visualization: Create dashboards in Grafana or Datadog.
Embed analytics agents within pipelines for dynamic threshold adjustments, anomaly detection, and adaptive sampling.
Alert Generation and Routing
Define a structured alerting workflow:
- Alert Conditions: Threshold-based (e.g., CPU 80 percent) and anomaly-based (e.g., sudden throughput drop).
- Prioritization: Assign severity levels based on SLA impact and customer experience.
- Notification Channels: Integrate with PagerDuty, Opsgenie, or Slack.
- Escalation Policies: Time- or condition-based escalation chains to second-level responders.
- Automated Remediation: Trigger self-healing actions such as scaling nodes, restarting containers, or rolling back deployments.
Feedback Triggers and Corrective Actions
Embed mechanisms to drive continuous improvement:
- Incident Postmortems: Auto-trigger documentation requests after major incidents.
- Adaptive Threshold Tuning: Use analytics agents to adjust thresholds based on historical data.
- Agent Retraining Signals: Flag performance regressions for retraining in platforms like TensorFlow Extended.
- Optimization Recommendations: Suggest workflow redesigns or parallelization opportunities.
- Governance Handovers: Route summaries and proposals to teams via ServiceNow.
Coordination and Tool Integrations
Ensure seamless collaboration across systems and teams:
- Unified Event Bus: Central messaging for agents and services to subscribe to the same streams.
- Role-Based Access: Tailor dashboard visibility by role.
- Cross-Team Playbooks: Document responsibilities for incident response and remediation.
- Integration Contracts: Standardize API schemas and message formats.
- Human-in-the-Loop Checkpoints: Approval gates before automated actions in production.
Best Practices
- Start with a Minimum Viable Monitoring Pipeline: Focus on critical services before expanding coverage.
- Define Clear Ownership: Assign monitoring champions for dashboards and alert policies.
- Review Alert Fatigue: Track volumes and false positives to refine rules.
- Conduct Periodic Drills: Simulate failures to validate end-to-end readiness.
- Embed Documentation: Include correlation IDs and remediation steps in alerts.
Analytics Agents and Feedback Loops
Analytics agents transform raw telemetry into actionable insights, powering proactive management through anomaly detection, predictive forecasting, and prescriptive recommendations.
Role of Analytics Agents
- Data Aggregation: Consolidate metrics and logs into a unified model.
- Anomaly Detection: Surface deviations using statistical and machine learning methods.
- Correlation Analysis: Link symptoms across application, network, and database layers.
- Predictive Insights: Forecast capacity constraints or quality regressions.
- Recommendations: Prescriptive actions such as parameter tuning or resource reallocation.
Types of Analytics Agents and Key Capabilities
Real-Time Telemetry Agents
- Ingest streams via Apache Kafka or AMQP.
- Apply threshold rules or ML models for immediate alerts.
- Integrate with Prometheus.
Log Analytics Agents
- Parse structured and unstructured logs with NLP.
- Correlate events with distributed traces.
- Leverage the ELK Stack.
Predictive Capacity Agents
- Forecast compute and storage demands.
- Generate auto-scaling policies.
- Collaborate with MLflow.
Root Cause Analysis Agents
- Perform causal inference on multivariate data.
- Recommend configuration adjustments.
- Interface with Datadog or New Relic.
Business Impact Agents
- Translate technical metrics into revenue and customer impact.
- Prioritize incidents by customer-facing severity.
- Feed executive dashboards with summaries and recommendations.
Integration with Observability Systems
Analytics agents subscribe to telemetry pipelines that include:
- Instrumentation: Code and infrastructure probes emit metrics and events.
- Collection: Sidecars or SDKs gather telemetry from containers and services.
- Transport: Message buses or log shippers forward data to central repositories.
- Storage: Persist time-series data and archive logs.
- Visualization: Expose dashboards for real-time and historical analysis.
Best practices:
- Standardize metric names and units.
- Tag metrics with metadata: environment, ownership, and version.
- Implement backpressure controls to handle data spikes.
- Encrypt telemetry in transit and at rest.
Continuous Feedback Loop Mechanisms
A feedback loop closes the cycle from prediction to corrective action:
- Continuous Evaluation: Compare model outputs against ground truth and business outcomes.
- Automated Notification: Dispatch alerts when performance deviates.
- Retraining Triggers: Launch retraining via MLflow or Kubeflow Pipelines.
- Configuration Adjustment: Recommend parameter tuning for learning rates, batch sizes, or concurrency limits.
- Governance Checkpoints: Approval gates before retraining or redeployment.
Closed-Loop Orchestration
Event-Driven Triggers
- Use messaging topics or webhooks to notify the orchestration engine of anomalies.
- Ensure idempotent processing to avoid duplicate actions.
Policy-Driven Actions
- Map detected conditions to remediation workflows.
- Leverage policy engines for complex decision logic.
Auditability and Traceability
- Log each feedback event, recommendation, and execution outcome.
- Integrate governance libraries for version control and approval histories.
Human-in-the-Loop Integration
- Include manual reviews for high-risk actions in regulated environments.
- Provide interfaces for data scientists and business users to inspect recommendations.
- Scalability and Resilience
- Deploy analytics agents in container clusters to handle variable workloads.
- Implement retry and fallback strategies to maintain continuity.
Reporting Outputs and Iteration Handoffs
Reporting delivers insights on throughput, accuracy, latency, and exceptions. Iteration handoffs formalize the transition from monitoring to continuous improvement, ensuring that findings drive workflow enhancements, agent tuning, and data preprocessing.
Report Artifacts and Deliverables
- Interactive Dashboards: Live visualizations of key metrics in Splunk, Grafana, or Datadog.
- KPI Scorecards: Periodic summaries via Power BI or Tableau.
- Anomaly and Exception Logs: Detailed records of outliers, errors, and resolutions.
- Trend Analysis Reports: Historical comparisons to detect seasonality or degradation.
- Feedback Summaries: Aggregated user and stakeholder observations.
- Governance and Audit Dossiers: Access logs, change histories, and approval records.
Dependencies and Version Management
Accurate reporting relies on consistent pipelines, schemas, and templates. Embed metadata in each report header to identify:
- Workflow definition and agent configuration versions.
- Data pipeline revisions and transformation scripts.
- Analytical model versions used for metrics.
- Dashboard and template versions with custom visualizations.
Version tags and checksums accelerate root-cause investigations and preserve audit trails.
Handoff Protocols and Stakeholder Alignment
Define structured handoff processes to ensure timely delivery of insights:
- Recipient Mapping: Assign report consumers such as process owners, data scientists, IT operations, security officers, and executives.
- Delivery Channels: Use email, secure file shares, BI portals, or collaboration platforms like Microsoft Teams or Slack.
- Frequency and Timing: Align cadences with decision rhythms, e.g., daily KPI scorecards or immediate anomaly digests.
- Review and Acknowledgment: Embed sign-off steps for automated or manual approvals.
- Escalation Paths: Predefine chains for critical deviations to notify executive sponsors and risk teams.
Continuous Improvement and Iteration Cycles
- Insight Extraction: Analyze anomalies, trends, and feedback to identify enhancements.
- Prioritization and Backlog Management: Score potential changes by impact and effort for inclusion in the improvement backlog.
- Experiment Design: Formulate hypotheses and plan A/B tests or sandbox trials for impactful changes.
- Configuration Updates: Commit approved changes to version control and stage in development environments.
- Validation and Rollout: Execute regression tests, pilot deployments, and performance validation before production release.
- Monitoring and Reassessment: Apply the same reporting framework post-deployment to verify improvements and detect side effects.
This cyclical approach embeds continuous improvement into AI orchestration, driving resilience, efficiency, and alignment with evolving business objectives.
Chapter 8: Ensuring Security, Governance, and Compliance
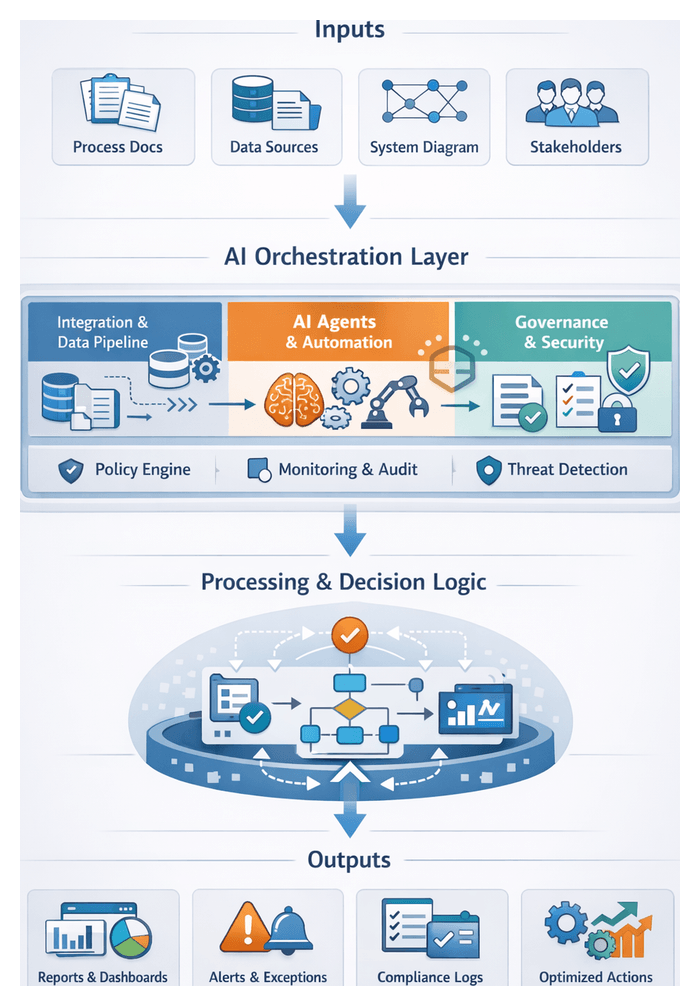
Diagnosing Core Automation Challenges
In modern enterprises, the drive to automate multi-step processes using AI agents aims to boost efficiency, reduce errors, and accelerate decisions. Yet many initiatives falter due to fragmented systems, poor data quality, unclear ownership, and insufficient governance. A systematic analysis of these challenges enables organizations to align stakeholders, prioritize remediation, and prepare for a scalable AI orchestration strategy.
Common Obstacles
- Process Fragmentation: Workflows spanning functions and regions lack end-to-end visibility, complicating accurate mapping and value identification.
- Data Quality and Consistency: Silos, inaccuracies, and missing standards undermine AI reliability and necessitate extensive exception handling.
- Technical Integration Gaps: Legacy systems without modern APIs require fragile custom connectors or screen scraping.
- Ambiguous Ownership: Undefined roles delay responses to failures and hamper continuous improvement.
- Change Management Deficits: Neglecting training and communication fosters resistance and underutilization.
- Governance and Compliance Risks: Uncontrolled data flows, lack of auditability, and policy violations expose organizations to financial and reputational harm.
Prerequisites and Required Inputs
Before designing workflows and configuring agents, assemble:
- Process Documentation: Current maps, standard procedures, and exception logs outlining steps and decision points.
- Performance Metrics: Baseline indicators—processing time, error rates, throughput, cost per transaction—for impact measurement.
- Data Inventory: Catalog of sources, formats, access methods, ownership, covering databases, data lakes, documents, and emails.
- System Architecture Diagrams: IT landscape views highlighting APIs, middleware, and security controls.
- Stakeholder Alignment: A cross-functional team of business leads, IT architects, data stewards, and compliance officers guiding decisions.
- Technology Audit: Assessment of existing automation tools, AI platforms, and monitoring solutions to identify consolidation opportunities.
- Regulatory and Policy Requirements: Documentation of legal, industry, and internal standards governing privacy, security, and governance.
Conditions for Success
Key organizational and technical conditions include:
- Executive Sponsorship: Senior leadership mandate and budget for collaboration and change management.
- Process Stability: Mature, standardized processes minimizing risk of frequent changes during automation.
- Data Governance Framework: Policies and roles for quality, stewardship, and access control ensuring reliable AI inputs.
- Technical Foundation: An integration layer or enterprise service bus supporting API orchestration, messaging, and secure data exchange.
- Skilled Resources: Teams with expertise in process analysis, AI development, integration, and change management.
- Continuous Improvement Culture: Feedback mechanisms, performance monitoring, and iterative workflows driving incremental value.
Embedding Governance and Policy Controls
Scalable AI deployments must integrate governance workflows to ensure compliance with organizational rules, regulations, and internal policies. Formalized policy enforcement throughout AI-driven processes delivers consistency, transparency, risk mitigation, and supports expansion without ad hoc rework.
Governance Workflow Objectives
- Pre-screen all data access, transformation, and decision steps against relevant policies.
- Maintain a tamper-proof record of policy evaluations and approvals.
- Provide real-time visibility into governance status for technical and business stakeholders.
- Enable exception handling to manage violations without halting critical operations.
Key Governance Components
- Policy Repository: Central store of rules, SLAs, and approval criteria managed by compliance teams.
- Policy Engine: Decision service evaluating requests against repository rules, returning pass/fail indicators.
- Approval Gateways: Automated or human-in-the-loop checkpoints for high-risk transactions.
- Cloud-Native Enforcement: Integrations with services such as Azure Policy to apply governance at the platform level.
- Audit Logger: Immutable ledger recording policy evaluations and decisions, using platforms like Splunk or Elastic Security.
- Notification Service: Alerts stakeholders of pending approvals, exceptions, or breaches.
Workflow Integration and Enforcement
Policy controls are integrated at touchpoints within the orchestration engine, which:
- Invokes the policy engine when AI agents request data or actions.
- Receives compliance decisions and routes tasks accordingly—proceed, request approval, or trigger exceptions.
- Logs each decision with timestamp, actor identity, and correlation ID for traceability.
Actor and System Roles
- Compliance Officer: Defines policies, approves updates, and reviews audit reports.
- Policy Engine Service: Interfaces via REST or gRPC to enforce rules.
- Orchestration Engine: Coordinates agents, invokes checks, and routes tasks.
- AI Agents: Tag transactions with policy metadata and adhere to enforcement directives.
- Approval Managers: Resolve flagged items and document rationales.
- Audit Logger: Captures governance events for analysis and reporting.
Real-Time Compliance and Exception Handling
Critical workflows demand low-latency policy evaluation using in-memory caches or distributed engines. Pre-execution hooks prevent prohibited actions, while post-execution validations detect unauthorized changes. Exception management classifies violations, automates minor remediations, routes notifications, escalates unresolved issues, and documents justifications for auditing.
Reporting and Continuous Improvement
- Dashboards summarizing policy evaluations, approvals, and exceptions.
- Compliance scorecards tracking adherence trends across units.
- Automated bulletins for high-priority incidents.
- Integration with tools such as Tableau or Power BI for executive reporting.
Security Agent Responsibilities and Integration
Security agents and services form a critical layer ensuring data integrity, confidentiality, and availability. These agents automate classification, privacy preservation, threat detection, and cryptographic controls across AI workflows.
Data Protection and Privacy
- Classification agents using natural language processing to identify and mask PII.
- Anonymization agents applying differential privacy for safe model training.
- Data retention agents enforcing deletion or archival based on configurable lifecycles.
Authentication and Access Control
- Agents analyze contextual factors—user behavior, device, geolocation—to trigger adaptive multi-factor authentication.
- Credential management services integrate with identity providers to issue, rotate, and revoke tokens or certificates.
- Access policy engines determine permissions for agent and system interactions.
- Behavioral analytics solutions like Darktrace detect anomalous login attempts and lateral movements.
Threat Detection and Response Orchestration
Security orchestration combines detection agents and automated response:
- Log aggregation agents such as Splunk normalize events for real-time correlation.
- Anomaly detection agents use unsupervised learning to flag suspicious activities.
- Response agents quarantine endpoints, revoke access, or roll back AI outputs as needed.
Encryption, Secure Transmission, and Key Management
- At-rest encryption via services like AWS Key Management Service or HashiCorp Vault, with automated key rotation.
- In-transit encryption using TLS or IPSec across hybrid environments.
- Key lifecycle agents automate certificate renewal and revocation to prevent expired credentials from disrupting workflows.
Integration Patterns for Security Services
- Policy-as-code repositories storing declarative security policies queried by agents at runtime.
- SIEM platforms centralizing threat intelligence for AI-driven response orchestration.
- Service mesh architectures enforcing authentication and encryption at the infrastructure layer for all agent communications.
- Feedback loops where threat insights inform AI model retraining and anomaly scoring adjustments.
- Comprehensive audit trails capturing every decision and enforcement action for forensic and compliance purposes.
Audit Outputs, Reporting, and Escalation
Upon completing governance and security workflows, organizations generate audit artifacts that document system behaviors, policy adherence, and incidents, providing the foundation for oversight and continuous improvement.
Audit Deliverables
- Detailed Audit Logs with timestamps, actor identifiers, configuration changes, and metadata for forensic analysis.
- Compliance Summary Reports mapping metrics to frameworks such as GDPR, HIPAA, or SOC 2.
- Exception and Incident Records documenting violations with classification and root-cause references.
- Role-Based Access Reports enumerating user and agent privileges, changes, and approvals.
- Traceability Matrices linking business requirements and governance rules to system configurations and agent behaviors.
Stakeholder Reporting and Distribution
- Executive Dashboards visualizing compliance trends, risk exposures, and strategic incidents.
- Operational Reports delivering real-time alerts and exception details to security operations centers.
- Audit Compliance Packages bundling raw logs, policy definitions, enforcement evidence, and signed attestations for external auditors.
- Governance Memos summarizing findings, remediation plans, and policy recommendations for committees and boards.
- Agent Performance Summaries reporting on AI accuracy, throughput, and policy adherence for operations teams.
Escalation Protocols
- Triggers: Configurable conditions such as repeated access failures or policy breaches initiate alerts.
- Notification Channels: Email, SMS, webhooks, and collaboration tools selected by urgency and audience.
- Response Workflows: Defined tasks and handoff criteria for analysts, compliance officers, and AI ops teams.
- SLAs: Response and resolution targets for incident severities guiding team prioritization.
- Escalation Paths: Hierarchical routes advancing issues from frontline responders to senior management or regulators.
Integration Dependencies
- Data Ingestion Services stream events from application logs, authentication systems, and agent outputs into the audit pipeline.
- Policy Enforcement Engines annotate logs with rule identifiers and evaluation outcomes.
- Orchestration Layer provides context on task sequences, agent identities, and workflow transitions.
- Reporting Platforms consume audit artifacts for dashboards and compliance packages.
- Incident Management Systems ingest alerts and escalate issues based on predefined workflows.
By diagnosing core challenges, embedding governance and security controls, and formalizing audit outputs and escalation processes, organizations establish a resilient foundation for AI agent orchestration. This integrated approach ensures compliance, mitigates risks, and fosters trust in automated business processes.
Chapter 9: Scaling and Optimizing Agent Ecosystems
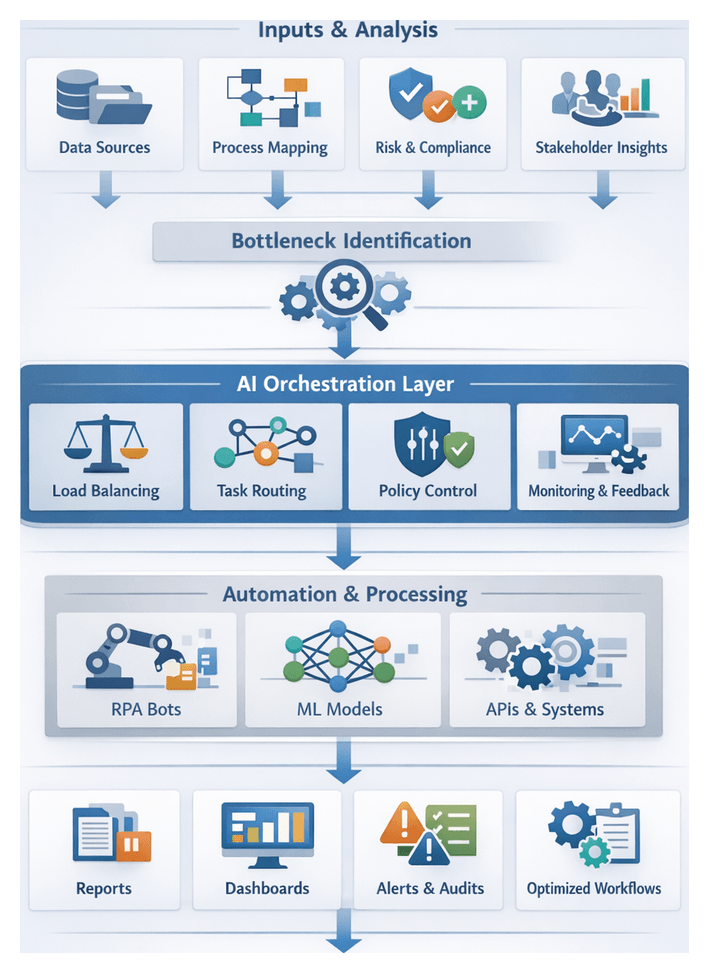
Assessing Core Automation Challenges
A disciplined assessment of core automation challenges establishes the foundation for effective AI-driven orchestration. Organizations begin by examining why past automation initiatives underperformed and identifying bottlenecks that impede end-to-end workflow efficiency. This purpose-built analysis delivers clarity on scope, resource needs, and governance requirements, enabling stakeholders to align automation objectives with strategic goals, prioritize interventions, and set realistic performance expectations.
Operational Pain Points
Multi-step processes often span disparate systems, teams, and decision nodes, introducing delays, errors, and compliance risks. Key pain points include:
- Data Silos and Inconsistent Formats leading to manual reconciliation and error-prone entries
- Unclear Ownership and Accountability causing stalled approvals and dropped tasks
- Latency in Manual Handoffs from email queues, paper-based approvals, and verbal instructions
- Rule Complexity and Maintenance with proliferating business rules in spreadsheets or legacy systems
- Lack of Real-Time Visibility preventing early detection of bottlenecks
- Compliance and Audit Gaps exposing organizations to regulatory fines
- Scalability Limits of Manual Tasks resulting in backlogs during peak periods
Prerequisites and Essential Inputs
Before detailed analysis, ensure the following prerequisites and data sources are in place:
- Executive Sponsorship and Alignment for cross-functional cooperation
- Process Documentation Baseline including maps, SOPs, and system diagrams
- Data Maturity Evaluation auditing quality, availability, and lineage
- Stakeholder Engagement Plan involving process owners, IT, compliance, and end users
- Technology Inventory of existing platforms such as UiPath and Automation Anywhere
- Risk and Compliance Framework covering data privacy, audit logging, and change management
- Baseline Performance Metrics capturing cycle times, error rates, and throughput
- Process Execution Logs from workflow engines, RPA bots, and ticketing systems
- Stakeholder Interviews and Workshops with frontline operators and IT specialists
- System and API Documentation for ERP, CRM, and custom applications
- Compliance and Audit Records highlighting areas of non-conformance
- Performance Dashboards and KPIs on throughput, cost per transaction, and satisfaction scores
- Data Quality Assessments identifying anomalies such as missing fields or inconsistent taxonomies
- Technology Roadmap and Budget Constraints defining feasible scope for pilots
Analytical Framework and Outcomes
Challenges are scored against business impact, technical feasibility, regulatory urgency, time to value, and resource availability. This prioritization yields:
- A ranked list of core automation obstacles with quantified metrics
- Validated prerequisites and resource requirements for pilot and scaled rollouts
- Defined stakeholder responsibilities and governance checkpoints
- Baseline measurements for comparative post-implementation analysis
With a clear view of pain points and prerequisites, teams can transition confidently from problem identification to solution design.
Load Balancing and Task Orchestration Workflow
Scaling AI agent ecosystems requires a robust orchestration layer that handles request admission, intelligent routing, and feedback-driven refinement. Incoming tasks—such as document analysis or predictive scoring—enter through an API gateway, undergo authentication and validation, and are logged for traceability.
Coordination between Load Balancers and Orchestration Engines
- Health Probes and Heartbeats: Load balancers issue HTTP or gRPC probes to agent endpoints, removing unresponsive instances from the pool
- Metrics Exchange: Agents emit telemetry to systems like Prometheus or Amazon CloudWatch. The orchestration engine uses these metrics to trigger scaling events
- Policy Enforcement: Auto scaling policies—implemented via AWS Auto Scaling, Azure Autoscale, or Google Cloud’s Autoscaler—provision or terminate instances based on thresholds or AI-driven forecasts
- Version Routing: During rolling upgrades, tasks route to updated agent versions only after health checks pass
Dynamic Task Routing and Queuing
Message brokers such as RabbitMQ or Apache Kafka classify tasks by type—batch, real-time inference, or human-in-the-loop—and assign priority tiers. Fairness algorithms allocate concurrency slots based on queue depth and SLAs, ensuring time-sensitive requests are processed ahead of low-priority jobs.
- Classification: Front-end agents inspect metadata to determine queue assignment
- Enqueueing: Tasks publish to topic exchanges or partitions labeled by priority
- Consumption: Worker agents subscribe and a rate limiter governs throughput
- Acknowledgment: Agents send success or failure signals, triggering retries or dead-letter routing
Actor Interactions and State Management
- API Gateway: Handles OAuth 2.0 or JWT authentication and input schema validation
- Service Mesh: Technologies like Istio enforce mutual TLS, load balancing, and observability
- State Store: Key-value stores such as Redis maintain session context and feature caches
- Metadata Catalog: Agents publish model version, processing time, and input characteristics for audit and analytics
- External Systems: Results hand off to CRM or ERP platforms via APIs or message exchanges
Monitoring, Feedback, and Failure Handling
Real-time metrics on latency, error rates, and utilization feed into alerting frameworks like PagerDuty or Slack. Automated remediation playbooks restart agents or rebalance queues to maintain SLAs. Guardrails include:
- Graceful Degradation disabling non-critical features under resource constraints
- Retry Policies with exponential backoff and dead-letter queues for persistent errors
- Transaction Reconciliation orchestrating compensating updates for partial failures
- Incident Escalation invoking on-call engineers and business stakeholders
Container Orchestration Integration
Platforms like Kubeflow Pipelines, Ray Serve, and Prefect expose declarative APIs for workflow definitions, scaling policies, and self-healing. Native autoscaling—such as Kubernetes Horizontal Pod Autoscaler—aligns resource allocation with dynamic load patterns.
Human-in-the-Loop Collaboration
Operators use dashboards to adjust scaling policies, approve manual interventions, and review dead-letter queues. This oversight ensures automated decisions reflect business priorities and risk tolerances, fostering trust in the ecosystem.
Ensuring SLA Compliance
- Rate Limiting to throttle incoming requests under high load
- Graceful Queue Spillover redirecting excess traffic to batch windows
- SLA Monitoring tracking percentile-based latency and availability
- Capacity Forecasting using historical patterns and external signals
Agent Provisioning, Management, and Auto Scaling
Managing a dynamic ecosystem of AI agents across cloud, edge, and on-premise environments demands automated provisioning, continuous monitoring, and predictive scaling. Integrating AI-based forecasting with orchestration platforms ensures responsiveness while optimizing costs.
Agent Provisioning and Lifecycle Management
- Demand Forecasting: Machine learning models analyze workload patterns and external factors to inform pre-emptive scaling
- Configuration Templating: Infrastructure as code tools generate standardized deployment artifacts optimized by AI-driven tuning
- Self-Healing Mechanisms: AI anomaly detection monitors health metrics and triggers automated restarts or replacements
Container orchestrators such as Kubernetes and virtualization platforms integrate with CI/CD pipelines for blue-green or canary deployments. AI agents validate new versions through regression testing before full roll-out.
Auto Scaling Architectures
- Metric Collection Services: Tools like Prometheus gather telemetry, with AI engines detecting trends and anomalies
- Scaling Controllers: AWS Auto Scaling, Azure Autoscale, and Google Cloud’s Autoscaler enact scaling based on thresholds or forecasts
- Policy Engines: Encode business logic around cost ceilings, availability, and compliance, with AI agents adjusting parameters dynamically
- Queue and Messaging Systems: Apache Kafka and RabbitMQ buffer requests and balance loads, optimized by AI techniques
Monitoring and Adaptive Scaling
- Predictive Alerting uses time series forecasting to anticipate threshold breaches
- Root Cause Analysis applies AI diagnostics to logs and metrics to identify issues
- Feedback Loops train models on historical performance data for improved forecasts
- Adaptive Thresholding adjusts trigger points based on context such as seasonality or batch schedules
Role of Orchestration Platforms
- Kubernetes with Horizontal and Vertical Pod Autoscalers integrating custom metrics adapters
- Service meshes like Istio enabling A/B testing and gradual rollouts
- Workflow orchestrators such as Apache Airflow and Prefect scheduling batch jobs and optimizing task placement
Governance and Compliance
- Policy Enforcement ensuring scaling actions comply with data residency, budgets, and approved instance types
- Audit Trail Generation logging every scaling decision and configuration change
- Access Controls integrating role-based permissions with orchestration APIs
Best Practices
- Define Clear Objectives for performance, cost, and availability
- Implement Phased Rollouts using canary deployments and staged scaling
- Monitor Continuously and Refine scaling policies with AI analytics
- Automate Governance Checks within CI/CD pipelines
- Document and Share Insights on scaling performance and policy updates
Scaled Outputs, Versioning, and Handoffs
As AI agent deployments expand, systems must aggregate individual responses into standardized deliverables—predictions, metrics, logs, enriched artifacts, and reports—adhering to agreed schemas and serialization formats such as JSON, Parquet, or protocol buffers. Clear versioning and artifact management preserve traceability across the ecosystem.
Versioning and Artifact Management
- Model and Agent Version Control using registries like MLflow to track metadata and lineage
- Container Images stored in registries with semantic tags reflecting build metadata
- Infrastructure as Code artifacts—Terraform or AWS CloudFormation templates—versioned alongside workflow definitions
- Governance Metadata embedding version identifiers, checksums, and environment tags in every artifact
Handoff Mechanisms
- Message Brokers and Event Streams—Apache Kafka or cloud event buses—ensure high-volume delivery
- RESTful and gRPC APIs with versioned endpoints and schema validation for synchronous interactions
- Batch File Transfers staging outputs in object storage for periodic ETL ingestion
- Database and Data Warehouse Writes employing change data capture and idempotent upserts
Dependency Mapping and Impact Analysis
- Catalog agent outputs alongside consumer endpoints
- Annotate dependencies with contracts, schema versions, and SLAs
- Maintain change logs and conduct impact simulations for version upgrades
- Automated tests and schema validation frameworks to detect breaking changes
Operational Considerations
- Monitoring delivery success rates, queue depths, latencies, and error codes with end-to-end tracing via OpenTelemetry
- Error Handling using dead-letter queues, exponential backoff retries, and circuit breakers
- Security and Compliance enforcing encrypted transit, API authentication, and least-privilege access
- Audit Trails capturing handoff events and artifact modifications for regulatory reviews
Chapter 10: Delivering Insights and Continuous Improvement
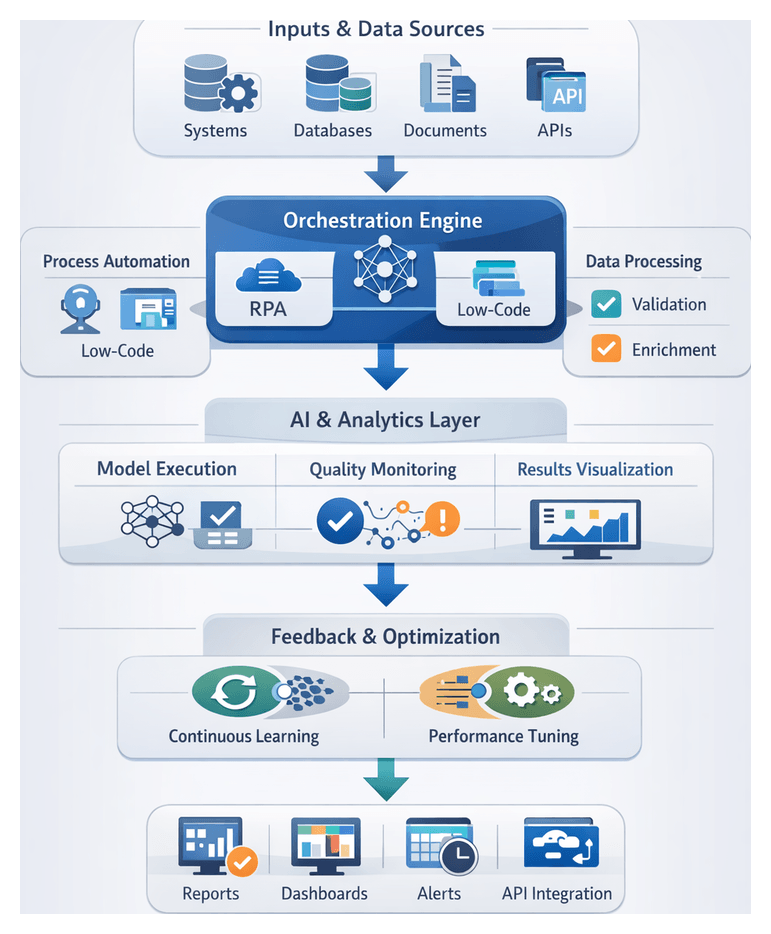
Addressing Core Automation Challenges
In today’s business landscape, organizations leverage a variety of automation technologies—ranging from robotic process automation platforms such as UiPath and Automation Anywhere to low-code integration services like Zapier. Yet without a cohesive orchestration framework, these point solutions often result in fragmented workflows, data inconsistencies, and invisible bottlenecks. A structured AI agent orchestration strategy is essential to overcome these challenges, ensure consistency, and scale reliable end-to-end processes.
Typical Obstacles in Workflow Automation
- Process Fragmentation: Disconnected tasks across legacy systems and departmental silos cause manual handoffs and hidden delays.
- Undefined Decision Criteria: Embedded human judgment and tribal knowledge make it difficult to codify rules or model triggers.
- Poor Data Quality: Inaccurate or inconsistent inputs undermine AI models and amplify downstream errors.
- Integration Complexity: Heterogeneous CRMs, ERPs, and custom databases require bespoke connectors and robust error handling.
- Lack of Transparency: Isolated automation tools obscure transaction paths, hindering debugging, audits, and tuning.
- Scalability Constraints: Single-tenant bots and homegrown scripts fail under increased volume without elastic orchestration.
- Cultural Resistance: Perceived threats to roles can lead to workarounds and incomplete adoption.
Prerequisites for Analysis
Before designing an orchestration framework, teams must gather inputs and establish conditions that yield actionable outcomes:
- Process Documentation: Detailed maps, flowcharts, and standard operating procedures capturing decision points and exceptions.
- Technology Inventory: A registry of automation tools, RPA bots, AI models, scripts, and integration platforms.
- Data Source Catalog: Metadata on system schemas, quality metrics, update frequencies, and ownership.
- Stakeholder Interviews: Insights from process owners, IT, compliance, and end users on failure modes and workarounds.
- Performance Metrics: Historical data on cycle times, error rates, and resource utilization to quantify automation gaps.
- Governance Requirements: Policies, audit logs, and regulatory obligations shaping acceptable practices.
- Executive Sponsorship and Cross-Functional Alignment: Visible leadership commitment and shared accountability across business and IT.
- Technical Infrastructure: Sandbox environments for prototyping without impacting production.
- Skilled Resources and Change Management: Process analysts, AI specialists, and communication plans to drive adoption.
Expected Outcomes
Upon completion of the core challenges analysis, organizations will have:
- A prioritized list of process bottlenecks, data issues, and integration gaps.
- Documented automation assets and interdependencies for a holistic landscape view.
- Defined success criteria and metrics for continuity, reliability, and scalability.
- A clear roadmap and resource requirements for formal AI agent orchestration design.
Orchestrated Analytics for Actionable Insights
Transforming raw data into strategic intelligence requires a coordinated analytics workflow. By orchestrating AI agents—from data profiling bots to advanced model runners—organizations ensure reproducibility, governance, and accelerated time to insight. Each stage is governed by defined triggers, data contracts, and interfaces to preserve workflow integrity.
Sequence of Analytical Activities
- Initiation and Scheduling: Orchestration engines such as Apache Airflow or DataRobot MLOps manage scheduled or event-driven triggers.
- Data Validation and Enrichment: AI agents perform schema checks, anomaly detection with Splunk, external reference joins, and feature engineering.
- Model Execution: Statistical analysis with R or NumPy, predictive modeling using TensorFlow or PyTorch, optimization via Gurobi, and NLP services like Azure Cognitive Services.
- Quality Assurance: Real-time checks via monitoring tools such as Datadog or New Relic, with automated alerts and corrective workflows.
- Visualization and Reporting: ETL agents prepare data for dashboards in Microsoft Power BI or Tableau, and narrative summaries generated by Automated Insights Wordsmith.
- Delivery: Insights distributed via dashboards, reports, or APIs with logged receipts for compliance.
Roles and System Coordination
A robust analytics workflow involves:
- Data Engineers: Configure pipelines and maintain data lakes.
- Data Scientists: Develop models, tune hyperparameters, and interpret outputs.
- AI Orchestration Services: Manage dependencies, triggers, and failure recovery.
- Business Analysts: Define KPIs and review insights.
- Security and Compliance Teams: Enforce governance policies and audit logs.
Coordination is achieved through message queues, event buses, or API gateways. Each event carries metadata and digital signatures to ensure end-to-end integrity and support forensic analysis.
Best Practices
- Modularize pipelines into reusable components.
- Version control code, configuration, and schemas.
- Implement observability with detailed logs, metrics, and traces.
- Automate rollback and retry strategies.
- Enforce role-based access controls.
- Continuously validate model performance against production data.
- Incorporate stakeholder feedback into successive iterations.
Integrating AI Models with Continuous Feedback
Advanced AI models—predictive, prescriptive, generative, and reinforcement learning—drive insights and recommendations. Embedding structured feedback loops ensures these models remain accurate, reliable, and aligned with business objectives as conditions evolve.
Predictive and Prescriptive Models
Predictive algorithms estimate future states such as demand forecasts or churn probabilities. Prescriptive models build on these forecasts to recommend optimal actions through optimization and simulation techniques. Common use cases include supply chain routing, pricing strategies, and next-best actions.
Generative Models and Reinforcement Learning
Generative AI, including GANs and large language models, enables data augmentation, scenario testing, and content synthesis. Reinforcement learning agents optimize sequential decisions—dynamic pricing, logistics routing, and campaign strategies—via feedback on rewards and penalties.
Feedback Loop Mechanisms
- Automated Monitoring: Dashboards track performance, data drift, and system health.
- Alerting Services: Notifications flag anomalies, threshold breaches, or degraded accuracy.
- Annotation Interfaces: Experts validate outputs and label edge cases.
- Retraining Pipelines: Orchestrated workflows ingest validated feedback, rebuild features, and redeploy updated models.
Supporting MLOps Systems
- Feature Stores: Centralized repositories for versioned feature data.
- MLOps Platforms: Amazon SageMaker, Kubeflow, MLflow.
- Model Registries: Catalogs tracking versions, metadata, and performance.
- Logging and Visualization: Datadog, Grafana.
- Orchestration Engines: Apache Airflow for scheduling retraining and deployments.
Roles and Responsibilities
- Data Engineers: curate feature pipelines and ensure data quality.
- ML Engineers: implement training pipelines and integrate monitoring hooks.
- Data Scientists: design experiments and interpret metrics.
- Domain Experts: review edge cases and validate compliance.
- DevOps and IT Operations: provision infrastructure and configure CI/CD.
- Business Stakeholders: define success criteria and guide alignment.
Managing Drift and Enhancing Learning
- Drift Detection: Use statistical tests to flag changes in data distributions and model relationships.
- Response Automation: Trigger retraining, update feature logic, or adjust hyperparameters.
- Active and Online Learning: Prioritize labeling of uncertain samples and update models in real time.
- Transfer Learning: Fine-tune pre-trained base models with lower learning rates and validate against holdout sets.
Industry Scenarios and Compliance
Feedback strategies must address domain-specific requirements:
- Financial Services: Integration with regulatory reporting and explainability frameworks.
- Healthcare: Rigorous annotation protocols and clinical expert reviews.
- Manufacturing: Sensor-based anomaly calibration and threshold adjustments.
- Retail: Hourly A/B testing and rapid recommendation updates.
- Security and Compliance: Encrypt feedback data, enforce role-based access, maintain audit logs in systems like Splunk, and apply retention policies under GDPR or HIPAA.
Delivering Insights and Enabling Continuous Improvement
Structured deliverables translate analytical outputs into actionable formats. Seamless handoff processes and governance mechanisms ensure that insights drive measurable change and continuous improvement.
Report Deliverables
- Interactive Dashboards: Real-time metrics in Power BI or Tableau with drill-down and role-based views.
- Executive Summaries: Slide decks or PDFs highlighting key insights and strategic recommendations.
- Analytical Appendices: Detailed tables, methodological notes, and validation results for audit and compliance.
- Data Feed Exports: JSON, CSV, or Parquet outputs for integration with CRM, ERP, or custom systems.
Dependencies and Handoff Processes
- Data Quality Assurance: Automated profiling by agents to flag anomalies.
- Model Validation: Performance thresholds, confusion matrices, and back-testing results as formal inputs.
- Infrastructure Availability: Scalable BI platforms with defined SLAs.
- Security Clearance: Encryption, access controls, and data masking under GDPR or HIPAA.
- Integration Connectivity: APIs and middleware to systems like Salesforce with authentication and error handling.
- Publishing to BI Portals: Automated refresh and access management via directory services.
- Dissemination of Executive Packages: Distribution managed through tools like DocuSign with version control and approval tracking.
- API-Driven Data Push: RESTful calls using OpenAPI standards with retry logic.
- Feedback Loop Integration: Stakeholder comments captured via embedded forms or Jira and routed to analytics teams.
- Governance and Audit Trail: Logging of report access and actions in SIEM platforms such as Splunk.
Continuous Improvement Triggers and Governance
- Threshold Exceedance Alerts: AI agents initiate root-cause investigations when metrics cross limits.
- Periodic Performance Reviews: Scheduled drift assessments and retraining triggers.
- Stakeholder Feedback Cycles: NLP agents categorize survey inputs and generate feature requests.
- Approval Workflows: Data stewards, compliance officers, and executive sponsors sign off on final artifacts.
- Key Performance Handbacks: Insights integrated into operational dashboards, strategic planning tools, and model retraining pipelines.
- Handoff Effectiveness Metrics: Adoption rates, action completion ratios, outcome alignment scores, and feedback resolution times.
Conclusion
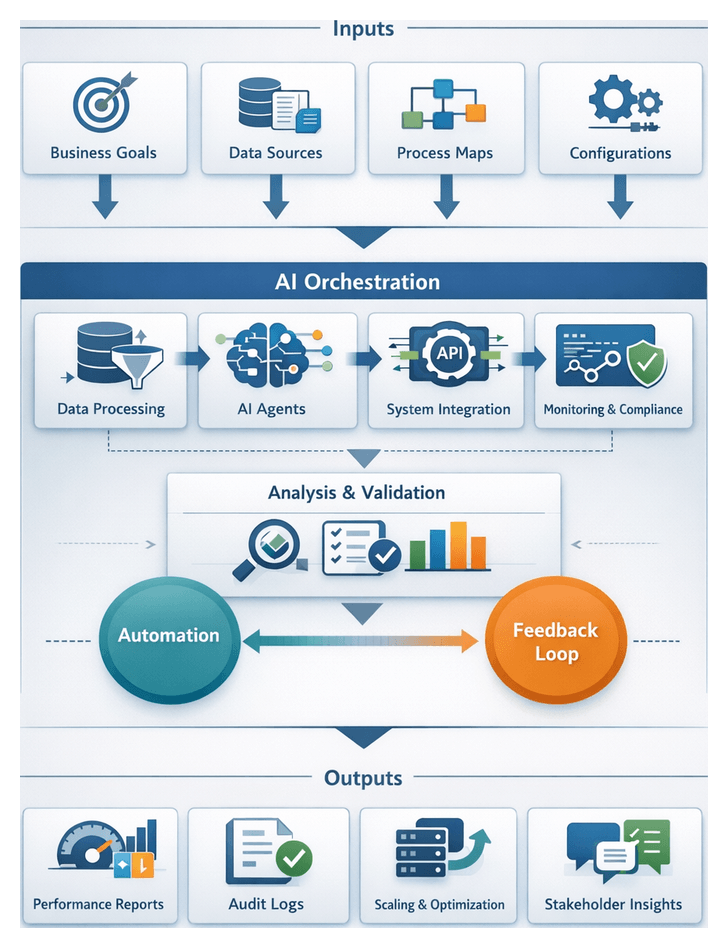
Integrated Workflow Recap and Deliverables
In the final stage of the orchestration framework, the integrated workflow recap consolidates all artifacts, performance metrics and stakeholder feedback into a unified narrative. By applying observability principles to AI-driven processes, this recap ensures transparency, auditability and readiness for operational handoff. It validates that each phase—from business objectives and data preprocessing to agent configuration, system integration and performance monitoring—has been executed as intended and aligns with success criteria.
Key objectives of this stage include:
- Confirming completion and documentation of every workflow action
- Aggregating process maps, data quality reports, agent configurations and integration schemas into a cohesive summary
- Verifying that performance thresholds for latency, accuracy and throughput are met
- Establishing a baseline for reporting, compliance and iterative improvement
Success depends on assembling the following deliverables:
- Business Objectives Documentation such as use case definitions, KPIs and success criteria
- Process Maps and Sequence Diagrams capturing agent handoffs, decision gateways and data flows
- Data Quality Reports detailing cleansing, enrichment and validation results
- Agent Configuration Records listing model versions, parameter settings and runtime schedules
- Integration Schemas and API Specifications including OpenAPI or GraphQL contracts
- Automation Logs and Rule Documentation with audit trails and execution histories
- Monitoring Dashboards and Alert Logs covering throughput, latency and anomaly detections
- Governance and Compliance Records such as access logs, approval evidence and policy checklists
- Scaling and Load Reports with capacity planning and auto-scaling event logs
- Stakeholder Feedback and Change Requests capturing end-user insights and backlog items
Strict entry criteria ensure that the recap reflects a stable, accessible and approved system. Prerequisites include finalized deliverables for all workflow stages, resolved data validation errors, satisfied performance thresholds, governance sign-off, infrastructure stability over multiple cycles, documented change management actions and active stakeholder engagement.
Structured recap sessions bring together process owners, data scientists, IT operators and compliance officers. Facilitated workshops review process diagrams, live demonstrations of agent behaviors and Q&A discussions to confirm readiness. Outcomes are recorded in version-controlled repositories and integrated with ticketing systems to track remediation tasks as needed.
An analytical evaluation benchmarks quantitative metrics—such as precision, recall, throughput and error rates—against target values, while qualitative feedback assesses usability and alignment with business logic. Trade-offs between throughput and interpretability are surfaced, risks are cataloged in a living register, and readiness scores guide deployment decisions.
The consolidated recap report includes an overview of deliverables by stage, a gap analysis with corrective actions, a readiness index and recommendations for deployment, scaling or further refinement. This artifact underpins executive approvals, change control processes and the post-deployment optimization roadmap.
Best practices for an effective recap:
- Plan recap templates and review agendas during project kickoff
- Maintain centralized, version-controlled artifact storage
- Use a standardized scoring framework for both technical and business dimensions
- Engage cross-functional teams in active review sessions
- Automate data collection for dashboards and reports
- Formalize approval workflows with digital sign-offs
Efficiency and Reliability Gains
As AI agent orchestration matures, organizations achieve measurable efficiency improvements and reliability enhancements. The orchestration layer automates routine tasks, enforces formal handoffs and integrates real-time monitoring with automated remediation to deliver predictable performance across complex workflows.
Streamlining Task Execution
Automated triggers replace manual status checks, enabling agents to execute in parallel or sequence based on dependencies. Concurrent execution of data enrichment and document classification tasks reduces cycle times, while dynamic task routing adapts to resource availability, cutting end-to-end processing latency and improving utilization.
Formalized Handoff Validation
Each agent submits outputs against standardized schemas enriched with metadata, confidence scores and validation timestamps. The orchestration engine enforces:
- Schema validation checks on payload structure and mandatory fields
- Confidence thresholds to determine human review or automated retries
- Audit logs capturing every handoff event for traceability and rollback
Coordinating Agents and Enterprise Systems
The orchestration platform synchronizes AI agents with enterprise applications using asynchronous message queues, RESTful API calls and event-driven webhooks. This standardization ensures decoupled scaling, low-latency decisions and robust error handling across heterogeneous environments.
Real-Time Monitoring and Automated Remediation
A dedicated monitoring agent aggregates telemetry data—processing times, error rates, resource metrics—from all components. Dashboards surface live metrics, while alert rules trigger:
- Latency thresholds that redistribute tasks to alternative compute nodes
- Error flags that rollback and requeue failed transactions
- Resource exhaustion warnings that activate auto-scaling
Feedback Integration and Continuous Improvement
User feedback, expert reviews and exception analyses feed back into workflow definitions, rule sets and model retraining loops. In-application review interfaces, performance surveys and automated failure pattern detection guide incremental tuning to accelerate both speed and accuracy gains.
Measuring Gains with Key Performance Indicators
Common KPIs track:
- Average processing time reduction per transaction
- Decrease in manual intervention rates and labor hours
- Throughput increases measured in tasks per hour
- Error rate reductions compared to pre-orchestration baselines
Coordinated Governance and Collaboration
Role-based access controls, automated policy enforcement and approval gates ensure that only authorized changes occur. Audit trails capture decisions for regulatory review. Unified interfaces and cross-functional workshops align IT and business teams on performance insights, automation priorities and outcome impacts.
Scalable Architecture and User Adoption
Containerized microservices on Kubernetes and serverless functions on AWS Lambda support independent scaling of agents. Load balancers and auto-scaling policies maintain responsiveness under peak loads. As reliability and efficiency improve, end users trust automated workflows, reducing support tickets and enabling staff to focus on strategic work.
Proactive Maintenance
Routine health checks of agent performance, configuration audits and seasonal workload simulations detect capacity or model drift issues before they impact service levels. Continuous integration pipelines roll out updates with minimal downtime, preserving efficiency and reliability over time.
Business Impact and Innovation
Beyond operational gains, orchestrated AI workflows deliver strategic value by generating insights, enabling innovation and unlocking new revenue opportunities. By integrating decision support, predictive analytics and automated feedback loops, enterprises can adapt swiftly to market changes and differentiate through AI-driven services.
AI-Driven Decision Support
Orchestrated agents generate continuous insights for strategic decisions:
- Predictive Analytics Agents forecast demand and risks through historical and real-time data pattern analysis
- Prescriptive Analytics Agents simulate scenarios and recommend optimal actions for resource allocation and pricing
- Recommendation Engines personalize offerings by adjusting suggestions based on user profiles and context
- Scenario Simulation Agents enable “what-if” analyses under varying market or regulatory conditions
Competitive Differentiation
AI-driven orchestration fosters:
- Personalized customer experiences delivered at scale through real-time journey analysis
- Dynamic pricing and promotions that adjust automatically to demand and inventory signals
- Accelerated innovation cycles powered by generative AI for rapid prototyping
- Operational resilience via real-time anomaly detection and remediation workflows
Growth and New Opportunities
Orchestrated workflows enable:
- Market expansion analysis by segmentation agents identifying underserved segments
- Optimized cross-sell and up-sell campaigns via propensity modeling agents
- Development of new AI-driven services such as subscription analytics and predictive maintenance
- Partnership ecosystems facilitated by data exchange and integration agents
Supporting Systems for Innovation
Key platforms that underpin business impact include:
- MLOps Platforms such as Amazon SageMaker and DataRobot for model training, deployment and governance
- Business Intelligence Tools like Tableau and Power BI for interactive dashboards and ad hoc analysis
- API Orchestration Gateways ensuring secure, low-latency communication between agents and systems
- Knowledge Management Systems capturing feedback and domain expertise for continuous learning loops
- Workflow Automation Engines coordinating tasks, approvals and exceptions with auditability
Illustrative Case Studies
- Retail Supply Chain Optimization: Predictive agents forecast SKU demand and automate replenishment via logistics APIs, reducing stockouts by 20 percent and carrying costs by 15 percent.
- Financial Services Fraud Detection: Real-time anomaly detection agents monitor transactions and trigger compliance workflows only on risk thresholds, cutting fraud losses by 30 percent with minimal customer friction.
- Energy Sector Predictive Maintenance: Condition-monitoring agents on turbine sensors drive prescriptive maintenance scheduling, reducing unplanned downtime by 40 percent.
- Healthcare Personalized Care Plans: Recommendation engines tailor patient treatment pathways in real time, improving recovery rates and lowering readmission rates.
Foundational Outputs and Handoff Mechanisms
A production-ready orchestration framework delivers a set of standardized artifacts, dependency mappings and handoff protocols that enable governance, reuse and rapid scaling.
Key Deliverables
- Process orchestration diagrams in BPMN or JSON workflow models capturing agent interactions and data transformations
- Agent configuration manifests describing model versions, security credentials and resource settings
- API specifications and interface contracts expressed as OpenAPI or GraphQL schemas
- Data schemas, validation rules and test payloads integrated into CI/CD pipelines
- Governance documentation including audit log templates, policy checklists and regulatory mappings
- Performance baselines and benchmarking reports detailing throughput, latency and error rates
- User guides and operational runbooks for deployment, monitoring and incident response
Dependencies and Integration Points
Maintaining a formal dependency matrix is critical. Major dependencies include:
- Data Services such as Snowflake or Amazon Redshift for raw and preprocessed data storage
- AI Model Repositories like MLflow or Amazon SageMaker Model Registry
- Integration Middleware such as MuleSoft or IBM API Connect
- Identity and Access Management systems like Active Directory or Okta for RBAC enforcement
- Infrastructure Platforms including Kubernetes and AWS Lambda for compute and scaling
- Monitoring and Observability tools like Prometheus, Grafana and Datadog
- Security Controls such as HashiCorp Vault and Open Policy Agent
Handoff Protocols
Clear handoff mechanisms define how outputs transition between agents, systems or human operators. Common patterns include:
- Message queue transfers via Apache Kafka or RabbitMQ with enforced schemas
- RESTful API calls through AWS API Gateway or Azure API Management secured by OAuth2 or mutual TLS
- Shared storage paths on Amazon S3 or Google Cloud Storage with event-driven notifications
- Database handovers via staging tables and change data capture pipelines
- Event-driven notifications through Slack or Microsoft Teams for manual review alerts
Essential elements of each protocol include data contracts with machine-readable schemas, SLAs for latency and throughput, error handling and retry policies, semantic versioning strategies and operational playbooks documenting monitoring, escalation and recovery procedures.
Key Takeaways for Ongoing Excellence
- Standardized artifacts and handoff protocols accelerate onboarding of new teams
- Dependency mappings streamline change management and impact analysis
- Reusable templates and containerized deployments support agile scaling
- Embedded governance and audit mechanisms ensure continuous compliance
- Modular APIs and workflow definitions enable rapid innovation across use cases
By rigorously formalizing workflows, deliverables, dependencies and handoff mechanisms, organizations establish a resilient orchestration ecosystem that drives predictable performance, regulatory confidence and sustained innovation.
Appendix
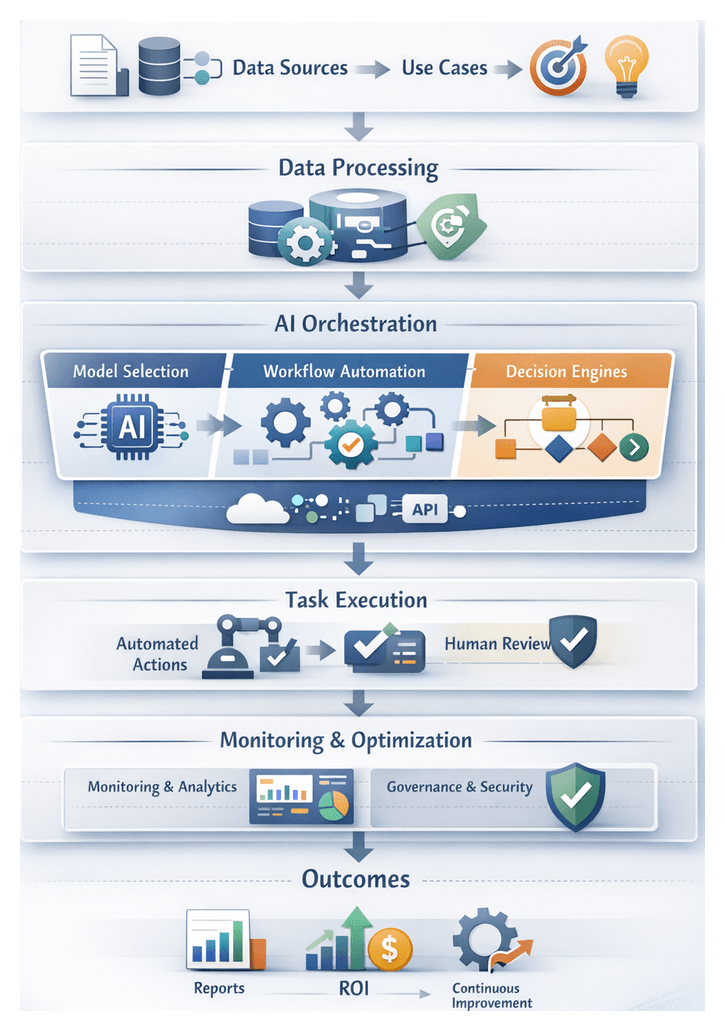
Purpose and Scope
This appendix provides a practical blueprint for aligning AI-driven orchestration concepts, capabilities, and tools to each phase of an end-to-end automated workflow. It empowers architects and engineering teams to select appropriate AI functions, plan integration touchpoints, enforce governance, and measure business impact.
Building on the structured approach of defining use cases, designing workflows, and continuous improvement, this section consolidates key terminology, maps AI capabilities to workflow stages, examines industry variations and edge cases, and catalogs leading platforms and services for AI agent orchestration.
Glossary of Key Terms
- Agent: A software component—ranging from AI models to rule-based scripts—that performs specific actions or decisions within an automated workflow.
- Agent Orchestration: Coordinated sequencing and management of multiple agents to execute a business process end to end, ensuring inputs and handoffs are reliable.
- BPMN (Business Process Model and Notation): A standardized graphical notation for mapping workflows, decision gateways, and interactions between business and technical stakeholders.
- Containerization: Packaging agents and dependencies into isolated containers for consistent deployments and scalable orchestration on platforms such as Kubernetes.
- Data Drift: Changes in input data distributions over time that can degrade model performance, detected by monitoring agents to trigger retraining or workflow adjustments.
- Data Lineage: The documented history of data transformations and flows, supporting traceability, compliance audits, and root-cause analysis.
- Data Pipeline: Automated sequences that ingest, cleanse, transform, and load data for downstream agents, enforcing quality gates and schema validations.
- Decision Gateway: Workflow nodes where business rules, AI outputs, or policy engines determine branching logic, parallel flows, or exception paths.
- Exception Handling: Procedures for managing errors or failures, including retries, human-in-the-loop interventions, or escalation workflows.
- Event-Driven Architecture: A design pattern in which agents communicate by publishing and subscribing to events on message buses such as Apache Kafka or RabbitMQ.
- Feature Store: A centralized repository for engineered features used in training and inference, ensuring consistency across development and production.
- Governance Workflow: Embedded policies, approvals, and audit controls enforced at critical handoff points within automated processes.
- Human-in-the-Loop: Mechanisms that route tasks to human operators when agent confidence falls below thresholds or policy exceptions arise.
- Integration Middleware: Software that mediates communication, data transformation, and protocol translation between agents and enterprise systems, such as MuleSoft Anypoint Platform.
- Model Registry: A system tracking AI model versions, metadata, performance metrics, and deployment history for reproducibility and governance, exemplified by MLflow.
- Orchestration Engine: The central platform defining workflow logic, scheduling agent activations, handling errors, and enforcing dependencies, with examples including Camunda and Apache Airflow.
- Policy Engine: Services that evaluate governance rules against workflow events, such as Open Policy Agent.
- Quality Gates: Validation checkpoints that assess data, model outputs, or system states before advancing workflows.
- Service Mesh: Infrastructure layers like Istio or Linkerd that manage service-to-service communication, security, and observability in distributed agent ecosystems.
- Workflow Definition: Declarative specifications of tasks, dependencies, agent activations, and handoff criteria serving as a single source of truth for orchestration engines.
Mapping AI Capabilities to Workflow Stages
1. Defining Business Objectives and Use Cases
Key AI Capabilities:
- Process Mining Agents analyzing event logs to identify high-value automation candidates.
- Recommendation Engines scoring and ranking use cases by strategic impact.
- NLP Agents extracting requirements and success criteria from stakeholder interviews.
Agent Roles and Outputs:
- Use-Case Scoring Agent provides a prioritized list of automation candidates with ROI estimates.
- Requirement Extraction Agent delivers structured canvases mapping objectives to data inputs.
2. Data Collection and Preprocessing
Key AI Capabilities:
- Data Profiling Agents for anomaly detection and schema inference.
- Text Extraction Agents performing OCR and structured field extraction.
- Feature Engineering Agents deriving predictive variables and enrichment scores.
Agent Roles and Outputs:
- Validation Agent generates data quality reports highlighting missing or inconsistent records.
- Enrichment Agent outputs normalized, tagged datasets ready for model consumption.
3. Selecting and Configuring AI Agents
Key AI Capabilities:
- Model Recommendation Agents matching process requirements to candidate AI services from platforms such as OpenAI, Google Cloud AI Platform, and Azure Cognitive Services.
- Parameter Tuning Agents using Bayesian optimization for hyperparameter selection.
- Integration Validation Agents testing API compatibility and security compliance.
Agent Roles and Outputs:
- Selection Agent produces a scored matrix of AI agent types aligned to objectives.
- Configuration Agent delivers deployable parameter sets and interface definitions.
4. Designing the Workflow Architecture
Key AI Capabilities:
- Workflow Modeling Agents generating BPMN diagrams from logical step definitions.
- Dependency Mapping Agents identifying data and service interdependencies.
- Decision Gateway Agents codifying conditional logic and branching rules.
Agent Roles and Outputs:
- Architecture Agent outputs a detailed sequence flow with swimlane assignments for AI and human actors.
- Data Lineage Agent produces graphs tracing output fields back to source systems and transformations.
5. Integration with Enterprise Systems
Key AI Capabilities:
- API Discovery Agents scanning registries to catalog endpoints and data contracts.
- Protocol Translation Agents converting message formats between REST, SOAP, and messaging queues.
- Security Policy Agents enforcing OAuth scopes, encryption standards, and compliance rules.
Agent Roles and Outputs:
- Connector Agent generates code stubs and configuration templates for each interface.
- Security Validation Agent delivers compliance reports confirming policy adherence.
6. Automating Task Execution and Decision Flows
Key AI Capabilities:
- Rule Processing Engines applying business logic alongside AI model outputs.
- Orchestration Agents managing synchronous and asynchronous task scheduling, retries, and fallbacks.
- Human-in-the-Loop Agents surfacing low-confidence cases to subject matter experts.
Agent Roles and Outputs:
- Execution Agent logs each task invocation, timing, and result for audit and SLA tracking.
- Escalation Agent generates work items for manual review upon predefined error conditions.
7. Monitoring Performance and Feedback Mechanisms
Key AI Capabilities:
- Anomaly Detection Agents identifying deviations in throughput, latency, and error rates.
- Predictive Alerting Agents forecasting capacity constraints and recommending scaling actions.
- Analytics Agents correlating performance metrics with business KPIs for holistic insight.
Agent Roles and Outputs:
- Monitoring Agent publishes real-time dashboards with drift indicators and SLA compliance stats via platforms like Grafana and Prometheus.
- Feedback Agent captures stakeholder inputs and model feedback for integration into retraining pipelines.
8. Ensuring Security, Governance, and Compliance
Key AI Capabilities:
- Policy Enforcement Agents executing compliance rules at each workflow gate.
- Threat Detection Agents analyzing logs for suspicious patterns using tools such as Splunk.
- Audit Logging Agents recording immutable trails of data access, decisions, and configuration changes.
Agent Roles and Outputs:
- Governance Agent produces compliance scorecards aligned to regulatory frameworks.
- Security Agent delivers incident reports with root-cause analysis and remediation recommendations.
9. Scaling and Optimizing Agent Ecosystems
Key AI Capabilities:
- Autoscaling Prediction Agents forecasting workload peaks and provisioning resources via services like AWS Auto Scaling.
- Load Balancing Agents distributing requests across agent clusters based on health metrics.
- Cost Optimization Agents analyzing usage patterns and recommending resource right-sizing.
Agent Roles and Outputs:
- Scaling Agent generates automated scaling policies and alerts for capacity planning.
- Optimization Agent produces reports on cost versus performance trade-offs.
10. Delivering Insights and Continuous Improvement
Key AI Capabilities:
- Insight Generation Agents synthesizing data into narratives and actionable recommendations.
- Recommendation Systems proposing next steps or corrective actions.
- Learning Agents integrating new feedback, retraining models, and redeploying updates automatically.
Agent Roles and Outputs:
- Reporting Agent distributes executive briefings, operational alerts, and strategic dashboards.
- Iteration Agent orchestrates subsequent cycles of data collection, model retraining, and workflow refinement based on performance outcomes.
Industry Variations and Edge Case Considerations
Financial Services
Requirements include immutable audit trails, real-time compliance checks against sanction lists, and secure integration with core banking systems via middleware like MuleSoft. Custom governance agents enforce policy gates prior to high-risk transactions and automate regulatory reporting.
Healthcare
Compliance with HIPAA and FDA guidelines demands de-identification of patient data, fine-grained access controls, and integration with EMR systems via HL7 or FHIR. Orchestration frameworks must support conditional policy overrides for emergency care and maintain clinical audit trails.
Manufacturing
Orchestration spans inventory management, predictive maintenance, and quality inspection. Variations include integration with SCADA and IoT platforms, edge-device computer vision agents, and time-series data pipelines for high-volume telemetry. Frameworks buffer tasks locally during network partitioning and reconcile data upon restoration.
Retail
Agents ingest customer behavior from web, mobile, and in-store kiosks via event streaming platforms such as Apache Kafka. Recommendation engines integrate with CRM systems like Salesforce. Workflows adapt to peak traffic during sales events and employ fallback rules when personalization services are unavailable.
Edge Case Scenarios
- Model Drift: Analytics agents monitor feature distributions and model accuracy. When drift occurs, orchestration engines trigger retraining pipelines in MLOps platforms such as MLflow and quarantine anomalous data.
- Rare Event Detection: Unsupervised anomaly detection agents identify unusual patterns. The orchestration layer escalates via incident management tools like PagerDuty and activates contingency workflows.
- Exception Paths and Fallbacks: Alternative workflows route low-confidence outputs to human specialists or simpler rule-based parsers to prevent process blockage.
Mitigation Strategies and Architectural Patterns
- Modular Agent Design: Single-purpose agents simplify substitution and targeted scaling.
- Policy-Driven Configuration: Centralized policy repositories enforced at runtime via engines like Open Policy Agent.
- Event-Driven Triggers: Message brokers decouple agents, enabling asynchronous scaling and fault isolation.
- Idempotent Actions: Safely retryable agent operations facilitate automated recovery.
- Human-in-the-Loop Gates: Review steps for high-risk or low-confidence outputs balance speed with oversight.
- Canary Releases: Gradual deployment of new agent versions with A/B testing to validate performance before full rollout.
- Adaptive Thresholds: Analytics agents dynamically tune validation rules and routing thresholds based on real-time usage patterns.
- Global Scalability: Multi-region deployment with data partitioning rules honoring sovereignty laws and optimizing local response times.
AI-Driven Tools and Platforms
AI Agent Platforms
- OpenAI: Provides advanced large language models such as GPT-4 for natural language understanding, generation, and conversational interfaces.
- Google Cloud AI Platform: A managed service for training, deploying, and managing machine learning models at scale with built-in pipelines and version control.
- Azure Cognitive Services: A collection of pretrained AI models hosted by Microsoft for speech, vision, language, and decision-making workloads.
- IBM Watson: A suite of AI services and tools for natural language processing, document understanding, and predictive analytics in enterprise environments.
- Amazon SageMaker: A fully managed service that enables data scientists and developers to build, train, and deploy machine learning models with integrated MLOps capabilities.
- Databricks: Provides a unified data analytics platform with collaborative notebooks, delta lake storage, and machine learning lifecycle management.
- DataRobot Paxata: Offers enterprise AI and machine learning automation with data cleaning, enrichment, and feature engineering modules.
Document Processing Tools
- Adobe Document Services: Cloud APIs for PDF generation, document conversion, and content extraction with robust OCR capabilities.
- ABBYY FlexiCapture: A platform for intelligent document processing, extracting structured data from unstructured documents using machine learning and rules.
Robotic Process Automation Platforms
- UiPath: A leading RPA platform with low-code design tools, process mining capabilities, and an orchestrator for managing digital workers.
- Automation Anywhere: Provides enterprise-grade bots, integrated analytics, and an automation cloud for scalable RPA deployments.
Workflow Orchestration Tools
- Apache Airflow: An open-source workflow scheduler that defines tasks as code, manages dependencies, and visualizes execution DAGs.
- AWS Step Functions: A serverless orchestration service for coordinating distributed microservices and AWS Lambda functions using state machines.
- Azure Logic Apps: A cloud service for creating automated workflows to integrate apps, data, and services via prebuilt connectors.
- Camunda: A workflow and decision automation platform supporting BPMN, DMN, and CMMN standards for complex process orchestration.
- Prefect: A modern workflow orchestration tool for data and ML pipelines with dynamic mapping and robust retries.
Data Integration and ETL Platforms
- Talend: Provides an open-source ETL and data integration suite with built-in data quality components and connectors.
- Informatica: A leading data integration platform offering ETL, data governance, and master data management capabilities.
- Azure Data Factory: A fully managed data integration service for ETL, ELT, and data movement in hybrid environments.
- AWS Glue: A serverless ETL service with data cataloging, job scheduling, and built-in transformations.
- MuleSoft Anypoint Platform: Enables API-led connectivity and reusable integration assets across on-premises and cloud systems.
- Dell Boomi AtomSphere: A low-code integration platform for building and managing APIs, workflows, and data pipelines.
- Apache NiFi: An open-source data flow tool for routing, transformation, and system mediation logic.
- Apache Camel: A lightweight integration framework implementing enterprise integration patterns in Java.
Data Storage and Catalog Tools
- Amazon S3: Object storage service for scalable data lakes, with lifecycle policies and event notifications.
- Azure Data Lake: A scalable data storage and analytics service for big data workloads.
- Google Cloud Storage: Offers unified object storage with global availability and high durability.
- Databricks Feature Store: A centralized repository for sharing and managing ML features across teams.
- Alation: A data catalog solution for metadata management, data lineage, and governance.
- Collibra: A data governance and stewardship platform focused on metadata management and policy enforcement.
Event Streaming and Messaging Platforms
- Apache Kafka: A distributed streaming platform for high-throughput, fault-tolerant event processing.
- RabbitMQ: A general-purpose message broker supporting multiple messaging protocols.
- AWS Kinesis: Real-time data streaming service for collecting, processing, and analyzing data at scale.
- Azure Event Hubs: A big data streaming platform and event ingestion service.
- Azure Event Grid: A serverless event routing service for uniform event consumption at scale.
- AWS EventBridge: A serverless event bus for application integration with SaaS partners and AWS services.
Monitoring and Observability Tools
- Prometheus: An open-source system monitoring and alerting toolkit optimized for cloud-native environments.
- Grafana: A multi-platform dashboard and graph editor for time-series analytics and monitoring data.
- Datadog: Provides full-stack observability with metrics, traces, and logs in a unified platform.
- New Relic: An observability platform offering application performance monitoring and synthetic testing.
- Splunk: A data-to-everything platform for searching, monitoring, and analyzing machine-generated data.
API Management and Integration Platforms
- Kong: An open-source API gateway and microservice management layer with plugin architecture.
- AWS API Gateway: A fully managed service for creating, monitoring, and securing APIs at scale.
- Google Cloud Apigee: A platform for developing and managing APIs with built-in analytics and developer portals.
- MuleSoft Anypoint Platform (also serves as an API manager): Unifies API design, security, and lifecycle management.
Model Management and MLOps Tools
- MLflow: An open-source platform for managing the end-to-end machine learning lifecycle, including experiment tracking and model registry.
- Weights & Biases: A tool for experiment tracking, dataset versioning, and collaborative model development.
- Kubeflow Pipelines: A Kubernetes-native platform for orchestrating ML workflows and managing deployments.
- Prefect: Supports MLOps workflows with dynamic task mapping and robust failure handling for training and serving.
Security and Identity Management Tools
- HashiCorp Vault: Manages secrets, encryption keys, and access policies for secure data handling.
- AWS Key Management Service (KMS): Provides encryption key creation, management, and auditing in AWS.
- Google Cloud Key Management Service: Centralized management of encryption keys and cryptographic operations.
- Okta: An identity and access management service that supports single sign-on, MFA, and lifecycle management.
- Azure Active Directory: A cloud-based identity provider for access management and authentication across Microsoft services and custom apps.
Collaboration and Incident Management Tools
- Jira: A ticketing and issue tracking system widely used for managing development and operational workflows.
- Opsgenie: An incident response orchestration platform that routes alerts to on-call teams with escalation policies.
- PagerDuty: A digital operations management tool for real-time incident alerting and on-call scheduling.
- ServiceNow: An enterprise IT service management platform that streamlines incident, problem, and change management.
- Slack: A collaboration hub where automated notifications, incident updates, and team discussions converge.
- Microsoft Teams: Provides chat, meetings, and integration points for automated alerts and report distributions.
Additional Resources and References
- JSON Schema: A specification for JSON-based data validation and contract enforcement.
- OpenAPI Specification: A standard for defining RESTful APIs, enabling code generation and interactive documentation.
- BPMN Modeler: Tools for designing and exporting Business Process Model and Notation diagrams.
- OpenTelemetry: A unified standard for collecting distributed traces and metrics across microservices.
- Kubernetes: The leading container orchestration platform for deploying and scaling microservices.
- Terraform: An infrastructure as code tool for provisioning and managing cloud resources.
The AugVation family of websites helps entrepreneurs, professionals, and teams apply AI in practical, real-world ways—through curated tools, proven workflows, and implementation-focused education. Explore the ecosystem below to find the right platform for your goals.
Ecosystem Directory
AugVation — The central hub for AI-enhanced digital products, guides, templates, and implementation toolkits.
Resource Link AI — A curated directory of AI tools, solution workflows, reviews, and practical learning resources.
Agent Link AI — AI agents and intelligent automation: orchestrated workflows, agent frameworks, and operational efficiency systems.
Business Link AI — AI for business strategy and operations: frameworks, use cases, and adoption guidance for leaders.
Content Link AI — AI-powered content creation and SEO: writing, publishing, multimedia, and scalable distribution workflows.
Design Link AI — AI for design and branding: creative tools, visual workflows, UX/UI acceleration, and design automation.
Developer Link AI — AI for builders: dev tools, APIs, frameworks, deployment strategies, and integration best practices.
Marketing Link AI — AI-driven marketing: automation, personalization, analytics, ad optimization, and performance growth.
Productivity Link AI — AI productivity systems: task efficiency, collaboration, knowledge workflows, and smarter daily execution.
Sales Link AI — AI for sales: lead generation, sales intelligence, conversation insights, CRM enhancement, and revenue optimization.
Want the fastest path? Start at AugVation to access the latest resources, then explore the rest of the ecosystem from there.