

Data Analysis AI Agents Insights Harnessing Autonomous Intelligence for Deeper Data Understanding
To download this as a free PDF eBook and explore many others, please visit the AugVation webstore:
Introduction
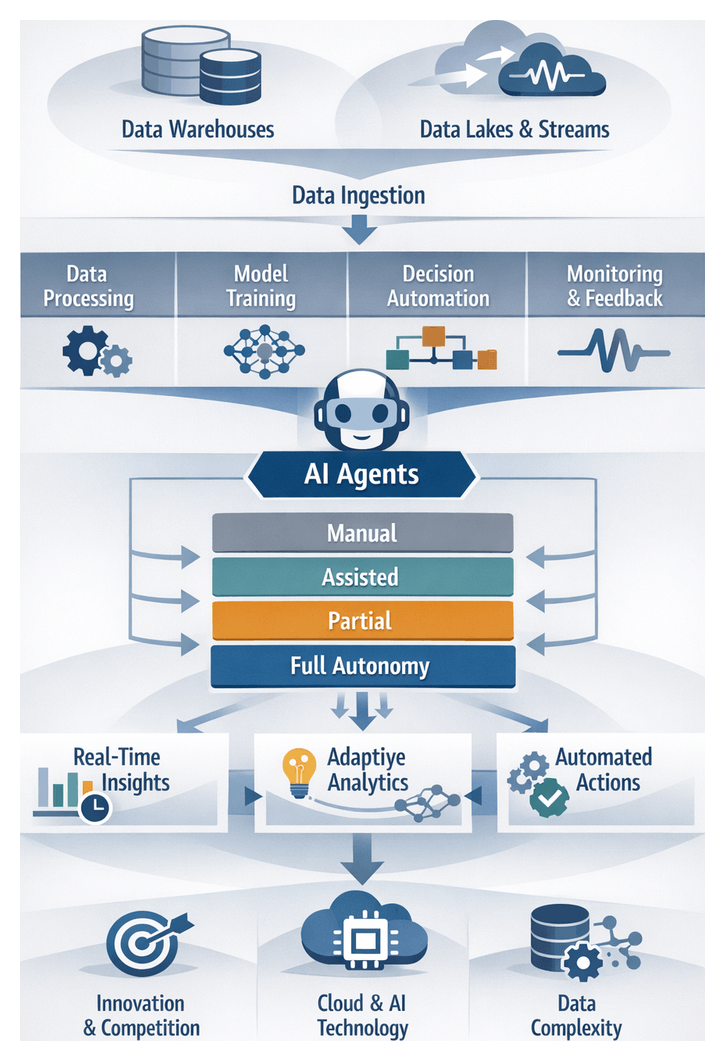
Evolution of Data Autonomy in Analytics Ecosystems
Organizations today face unprecedented volumes, varieties, and velocities of data across every function and industry. Early digital transformation efforts centralized information into relational warehouses and business intelligence platforms. With the advent of cloud-native solutions like Snowflake and Databricks, enterprises built sprawling data lakes and real-time ingestion pipelines. At the same time, sources such as Internet of Things devices, mobile apps, and social media introduced unstructured and semi-structured streams that overwhelmed manual extract-transform-load processes and static reporting. In response, data autonomy has emerged as a strategic imperative, embedding intelligence into analytics workflows through self-directed AI agents that generate proactive insights and orchestrate end-to-end processes without constant human intervention.
From Centralized Warehouses to Intelligent Agents
The analytics landscape has shifted from scheduled batch jobs and human-driven hypothesis testing to systems capable of continuous self-configuration. Autonomous AI agents leverage machine learning, natural language processing, and optimization algorithms to ingest diverse data sources, detect anomalies, retrain models in real time, and recommend actions. This evolution addresses challenges of scale, complexity, and speed by automating data quality monitoring, resource provisioning, and contextual reasoning, ultimately accelerating decision cycles and enabling organizations to manage information assets at unprecedented scale.
Defining Autonomous AI Agents
What Is Data Autonomy?
Data autonomy refers to the capacity of an analytics system to independently manage key stages of data ingestion, processing, analysis, and interpretation. Unlike traditional tools that execute predefined queries or dashboards on demand, autonomous agents initiate tasks, prioritize objectives, adapt to changing conditions, and iterate through feedback loops. This self-directed behavior transforms analytics from a reactive service into a strategic driver of value.
Core Components of Autonomous Agents
- Perception engines that connect to structured databases, cloud object stores, APIs, and streaming sources.
- Preprocessing modules for cleaning, normalization, and schema evolution management.
- Model training frameworks that evaluate algorithms, select optimal configurations, and manage retraining triggers.
- Decision logic leveraging probabilistic planning, reinforcement learning, and utility-driven optimization.
- Monitoring layers for drift detection and self-healing pipelines.
- User interfaces that generate visualizations, narratives, and recommendation alerts.
Autonomy Spectrum
Practitioners assess agent capabilities along a continuum:
- Mundane Automation: Fixed scripts executing static tasks.
- Assisted Intelligence: Human-in-the-loop confirmation before actions.
- Partial Autonomy: Self-governed routine processes with escalation for complex decisions.
- Full Autonomy: End-to-end workflow management and adaptation without human input.
Distinguishing Agents from Traditional Software
- Dynamic Adaptation versus Static Scheduling: Agents adjust pipelines in real time based on data anomalies and emerging patterns.
- Contextual Reasoning versus Pre-configured Rules: Natural language understanding and semantic analysis enable agents to interpret user intent and business context.
- Self-Improvement versus Manual Tuning: Continuous learning loops allow agents to refine decision policies without expert intervention.
- Unified Orchestration versus Point Solutions: Agents integrate ingestion, modeling, and delivery into cohesive workflows.
Drivers of Autonomous Analysis
Market Catalysts
Heightened competitive intensity, commoditization of insights, and the demand for real-time differentiation compel organizations to seek faster, deeper analytical capabilities. Start-ups and digital entrants leverage data-driven strategies to challenge incumbents, eroding traditional barriers to entry. Meanwhile, open-source libraries and platforms such as Microsoft Azure Cognitive Services and Databricks SQL Analytics democratize basic analytics, making agility and contextual interpretation key differentiators. In high-frequency domains—financial trading, digital marketing, supply chain orchestration—agents deliver sub-second insights that manual or scheduled processes cannot achieve.
Technological Enablers
Advances in cloud compute elasticity, foundational AI models, and data integration frameworks underpin the rise of autonomous agents. Hyperscale providers offer on-demand GPU and CPU resources for rapid model training and inference. Pretrained transformers and graph neural networks empower agents to process unstructured text, recognize semantic relationships, and generate interpretive narratives. Platforms like Google Vertex AI and Amazon SageMaker standardize workflows for fine-tuning these models on enterprise data. Data virtualization, metadata orchestration, and event streaming allow agents to access hybrid, multi-cloud, and on-premises sources without cumbersome ETL, maintaining alignment with evolving schemas through metadata-driven pipelines.
Organizational Imperatives
Scarcity of data science talent, decentralization of decision rights, and a cultural shift toward data-driven decision making drive agent adoption. Autonomous agents amplify existing teams by automating routine tasks and translating results into business-friendly narratives, enabling analysts to focus on domain interpretation. In federated models aligned with data mesh principles, agents deployed at the edge empower local teams under centralized governance guardrails. This balance accelerates insight delivery while preserving compliance and auditability.
- Competitive Tension elevates the cost of insight latency.
- Compute Elasticity lowers the barrier to iterative experimentation.
- Data Heterogeneity demands autonomous integration across silos.
- Talent Gaps shift roles toward interpretation and oversight.
- Decentralized Governance fosters agility within compliance frameworks.
Strategic Insights and Interpretive Frameworks
Analytical Value Chain and Feedback Loops
The analytical value chain encompasses raw data acquisition, quality assurance, modeling, visualization, and decision activation. Autonomous agents introduce continuous feedback at each stage: real-time data quality checks, dynamic model refinement, adaptive visualization updates, and automated action triggers. The coherence of these loops determines an agent’s effectiveness in maintaining contextually relevant insights as new data arrives.
Maturity Continuum
Organizations map agent implementations against a maturity continuum to guide adoption and risk management. Early stages involve guided assistants requiring frequent prompts. Intermediate levels feature partial autonomy with human oversight on anomalies. The apex delivers fully self-directed systems that plan and execute analytical experiments autonomously. Benchmarking against these milestones forces clarity on readiness, dependency gaps, and governance requirements before scaling.
Trust Calibration and Governance
Trust in autonomous analysis hinges on transparency, explainability, and performance consistency. Frameworks such as explainable AI libraries and model cards document decision pathways and variable influences. Governance dashboards track metrics like error rates, drift detection events, and corrective actions. Cross-functional committees ensure ethical standards, regulatory compliance, and strategic alignment govern agent behavior, preserving the delicate balance between autonomy and human authority.
Deployment Considerations
- Data Governance and Quality: Define ownership, stewardship policies, and robust metadata catalogs to ensure reliable inputs.
- Legacy Integration: Ensure API compatibility, real-time connectivity, and schema alignment with existing BI platforms and operational systems.
- Explainability and Auditability: Implement frameworks for interpretable reasoning, regulatory reporting, and ethical oversight.
- Scalability and Performance: Choose architectures—distributed clusters or edge compute—that balance responsiveness with cost and resource constraints.
- Change Management and Adoption: Engage analysts through pilots, training, and clear role definitions to foster collaborative human-AI workflows.
- Security and Compliance: Apply identity access controls, encryption, and standards (GDPR, HIPAA) to protect sensitive information.
Roadmap for Practitioners
- Conduct a Readiness Diagnostic: Evaluate data maturity, infrastructure capabilities, and cultural readiness for autonomous analytics.
- Define High-Value Use Cases: Prioritize scenarios such as anomaly detection, demand forecasting, or fraud monitoring where agents can deliver rapid impact.
- Launch Controlled Pilots: Validate agent capabilities in sandbox environments, refine governance mechanisms, and capture lessons.
- Establish Governance Foundations: Implement performance monitoring dashboards, retraining triggers, bias mitigation processes, and ethical review boards.
- Scale via Modular Architectures: Leverage reusable analytics components and standardized integration patterns to expand across business units.
- Foster an AI-Enabled Culture: Provide ongoing training, reward data-driven decision making, and embed agent collaboration into routine workflows.
Chapter 1: Foundations of AI Agents in Data Analytics
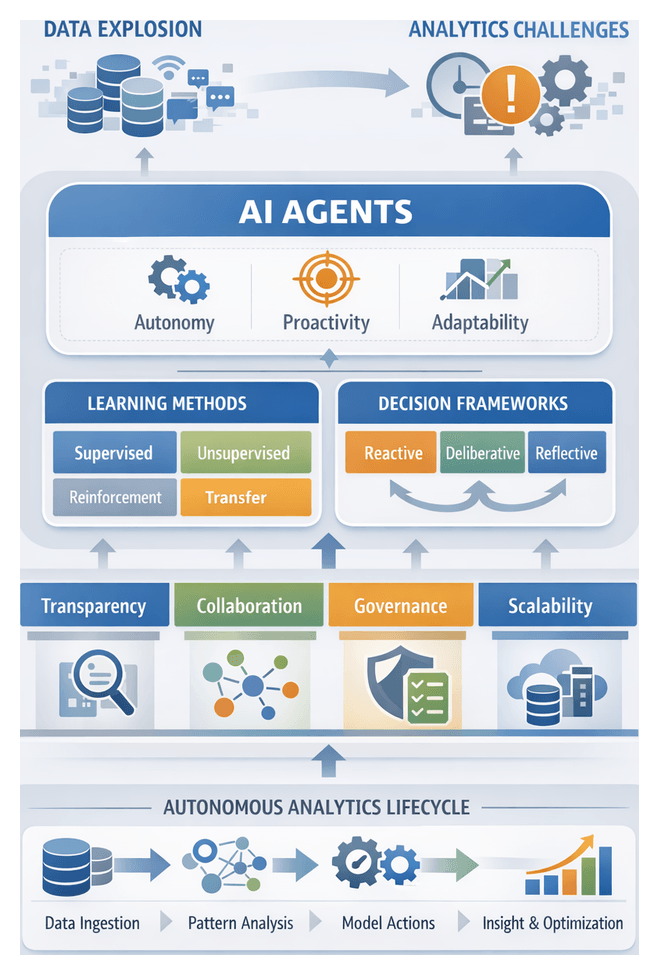
The Imperative for Autonomous Analytics
In data-driven enterprises, volumes of structured and unstructured information—ranging from transactional logs and IoT streams to social media feeds—have outstripped the capacity of manual analysis workflows. Traditional extract, transform and load pipelines and static business intelligence tools struggle to adapt to dynamic data characteristics, schema drift and real-time processing demands. This data explosion, coupled with intense competitive pressures and a shortage of skilled analytics professionals, drives the need for self-directed systems that minimize human intervention and accelerate time to insight. Autonomous analytics systems ingest, process and interpret diverse datasets continuously, detecting anomalies, optimizing processing pipelines and scaling compute resources according to defined success metrics such as completeness, consistency and relevance. By embedding intelligence into core data operations, organizations can shift from delayed reporting to a living intelligence layer that propels innovation across finance, manufacturing, retail and beyond.
Defining AI Agents and Core Attributes
At the heart of the autonomous analytics paradigm are AI agents—software entities endowed with autonomy, proactivity and adaptability. Autonomy enables agents to initiate, plan and execute analytical workflows without granular human direction. Proactivity equips them to anticipate needs by monitoring performance indicators and initiating corrective actions before thresholds are breached. Adaptability ensures that agents refine their models and strategies in response to evolving data patterns, schema changes or shifting business priorities. Two additional attributes—transparency and collaboration—are essential for auditability and trust: transparency surfaces decision logs, model feature importances and rationale artifacts, while collaboration supports iterative feedback loops with human analysts and adjacent systems.
Analytical autonomy extends these principles by engaging agents in hypothesis generation, validation and refinement cycles. For example, an agent may detect a shift in customer churn rates, formulate causal hypotheses, test them against historical records and present findings along with confidence estimates. Decision mechanisms rely on statistical inference, optimization heuristics and machine learning techniques such as supervised, unsupervised, reinforcement and transfer learning. Reinforcement learning optimizes long-term objectives through trial-and-error, while probabilistic models quantify uncertainty and guide data acquisition when confidence is low. Rule-based components encode domain expertise and governance constraints, aligning agent behaviors with organizational policies.
AI agent architectures typically integrate modular pipelines for perception, reasoning and action. Perception modules handle data ingestion and feature extraction using libraries such as TensorFlow for deep learning and spaCy for natural language processing. Reasoning layers leverage algorithms from clustering to Bayesian networks to interpret patterns and propose next steps. Action modules orchestrate downstream tasks, triggering data transformations, model retraining, alerts, or visualization updates. Together, these modules enable end-to-end autonomy in the analytics lifecycle.
Architectures and Decision-Making Paradigms
AI agents manifest across a spectrum of decision-making frameworks—reactive, deliberative and reflective. Reactive agents execute event-driven pipelines when predefined triggers occur. Deliberative agents maintain internal goal models, selecting sequences of analytical operations based on projected outcome utility. Reflective agents add meta-reasoning layers that monitor performance, diagnose regressions and adapt strategies dynamically.
Learning paradigms include:
- Supervised learning for training predictive models on labeled data (for example, credit scoring or churn prediction).
- Unsupervised learning for pattern recognition and anomaly detection in unlabeled datasets.
- Reinforcement learning for optimizing sequential decision policies in dynamic pricing or resource allocation.
- Transfer learning for adapting pre-trained models to related tasks, reducing data and compute requirements.
To guide agent selection and evaluation, practitioners employ interpretive taxonomies such as the autonomy spectrum, which ranges from assisted analysis—where agents suggest actions for human approval—to full autonomy, where agents manage entire analytical pipelines. The International Data Architecture Association’s functional taxonomy further categorizes agents by roles: exploratory profiling, predictive modeling, prescriptive optimization and monitoring. Socio-technical frameworks position agents within enterprise ecosystems of governance, data literacy and culture, emphasizing that technical proficiency alone is insufficient for success.
Tools and Platforms for Autonomous Analysis
Modern autonomous analytics leverage a mix of open source libraries and cloud-native services to streamline development, deployment and governance. Key technologies include:
- TensorFlow and PyTorch for building and training deep learning models at scale.
- spaCy and Hugging Face for natural language processing and transformer-based inference.
- Amazon SageMaker and Microsoft Azure Machine Learning for managed model training, deployment and MLOps workflows.
- DataRobot and H2O.ai for automated model governance, versioning and drift monitoring integrated into unified interfaces.
- IBM Watson Studio for end-to-end data science lifecycle management, from data preparation to deployment.
These platforms encapsulate best practices in model evaluation, explainability and ethical governance. They facilitate composable agent libraries, sandbox experimentation environments and integrated performance dashboards that track metrics such as latency, accuracy and business KPIs.
Governance, Collaboration, and Integration
Robust governance and clear collaboration models are critical to scaling autonomous analytics responsibly. Interaction paradigms span human-in-the-loop—where agents pause for human judgment—to human-on-the-loop, which provides transparency and override capabilities, and human-out-of-the-loop for standardized, low-risk scenarios. In regulated industries, human-on-the-loop frameworks prevail, using confidence thresholds to trigger manual review and explainable AI tools such as SHAP or LIME to produce feature-level impact summaries.
Governance councils comprising stakeholders from analytics, IT, legal and business units define policies on data access, model validation, audit trails and recovery protocols. Key artifacts include ethical impact assessments, immutable logs of data lineage and decision rationales, performance scorecards and rollback procedures. Cross-functional ownership models ensure shared responsibility for agent performance, infrastructure costs and change management, fostering a culture of accountability and trust around autonomy.
Integration pilots validate end-to-end workflows within legacy ecosystems, addressing data latency, API constraints and system interoperability. By phasing in agent responsibilities—starting with targeted tasks such as anomaly detection—organizations build confidence and refine governance controls before expanding autonomy.
Deployment Strategy and Best Practices
Successful autonomous analytics initiatives follow a pragmatic, phased approach:
- Align use cases to maturity: Begin with high-data-maturity domains and clearly measurable business outcomes, such as time-series forecasting or structured anomaly detection.
- Define success metrics: Go beyond model accuracy to track time-to-insight reduction, decision cycle acceleration and error rate improvements within executive dashboards.
- Govern incremental autonomy: Establish a roadmap that gradually reduces manual checkpoints as agents demonstrate consistent performance and compliance alignment.
- Embed feedback loops: Automate retraining triggers based on operational metrics—such as data drift or accuracy declines—with human review for major model updates.
- Invest in interpretability: Adopt frameworks that visualize decision pathways and quantify feature contributions, bridging technical and business stakeholder perspectives.
- Foster cross-functional stewardship: Create joint teams combining data scientists, IT architects and business users to share accountability for agent life cycles and outcomes.
By incorporating these practices into strategic planning, organizations can mitigate risks associated with data quality dependencies, transparency gaps and cultural readiness, laying the foundation for expanding autonomy in analytics.
Future Directions and Continuous Evolution
The autonomous analytics landscape evolves rapidly, and future-proofing initiatives requires flexibility and vigilance. Recommended approaches include:
- Modular architectures: Design agent frameworks with interchangeable components for data connectors, modeling engines and visualization tools, enabling seamless upgrades without system overhauls.
- Real-time health monitoring: Implement performance dashboards that track model drift, data latency and compute utilization, with automated alerts to prevent silent failures.
- Experimentation sandboxes: Maintain isolated environments for testing new algorithms, data sources and multi-agent coordination models, fostering innovation while containing risk.
- Elastic infrastructure: Leverage cloud-native services for dynamic scaling of compute and storage, ensuring responsiveness as analytic workloads expand.
- Research collaboration: Engage with academic and industry forums to stay current on emerging techniques in generative analytics, explainability and agent orchestration.
- Ethical and regulatory vigilance: Continuously audit agent behaviors against evolving privacy standards, bias metrics and compliance guidelines to safeguard stakeholder trust.
By institutionalizing these practices, organizations can sustain and extend the value of autonomous analytics, adapting to new data challenges and unlocking ever deeper insights.
Chapter 2: Core Technologies Powering Data Analysis Agents
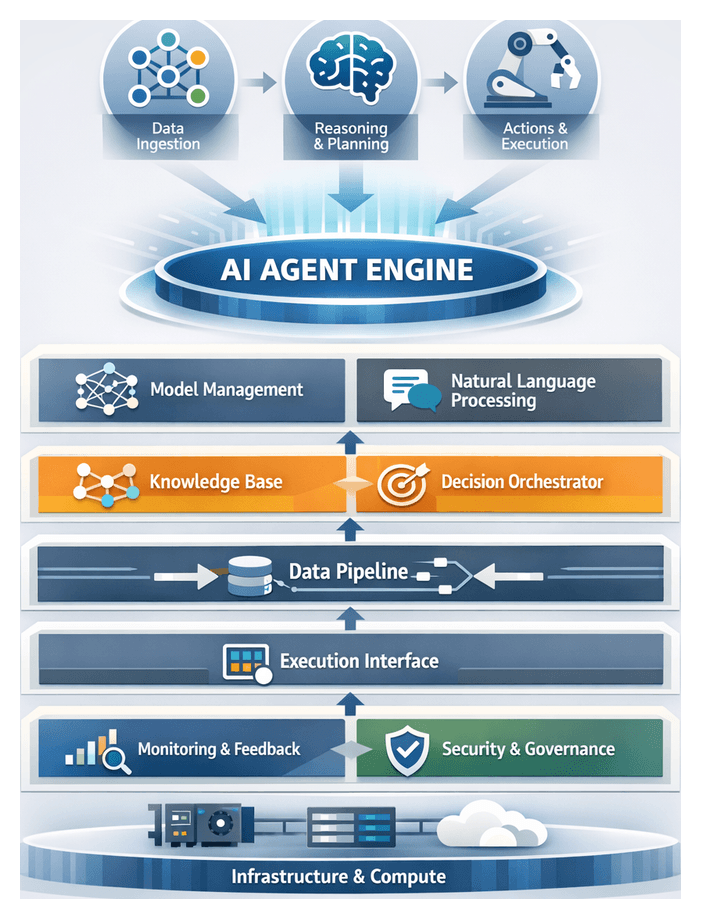
Context and Importance of Engine Components in Autonomous AI Agents
In today’s data-intensive enterprises, autonomous AI agents serve as vital collaborators for analytics, decision support and process automation. At their core, these agents rely on a cohesive engine architecture that unifies sensing, reasoning, action and learning. Well-designed engine components transform isolated software modules into a platform capable of ingesting diverse data streams, interpreting intent, executing tasks and continuously refining performance with minimal human intervention. Understanding this foundational layer is essential for architects, data engineers and business leaders seeking to deploy reliable, scalable and adaptive analytical solutions.
Engine components provide unified interfaces for model serving, natural language processing, workflow orchestration and governance. Without a robust engine, agents struggle to integrate heterogeneous sources, maintain reliability under load or adapt to evolving business objectives. This section lays out the core concepts, architecture patterns and trade-offs that underpin modern autonomous analytics platforms, equipping readers to evaluate or design enterprise-grade AI agents.
Layered Architecture of AI Agent Engines
A clear separation of concerns is achieved through a layered engine design. Each layer exposes standardized interfaces, enabling modular development, rapid experimentation and component interchangeability. Common layers include:
- Infrastructure and Compute Layer: Scalable orchestration of GPUs, CPUs and storage abstractions
- Data Ingestion and Preprocessing Layer: Connectors to databases, event streams, data lakes and APIs
- Model and Language Services Layer: Hosting of machine learning models, NLP engines and rule-based interpreters
- Decision and Planning Layer: Goal formulation, multi-step planners and optimization routines
- Execution and Action Layer: Interfaces to applications, BI platforms, dashboards and downstream systems
- Monitoring, Feedback and Governance Layer: Metrics collection, user feedback, audit trails and policy enforcement
This modular layout allows, for example, swapping an NLP with a transformer served via Hugging Face Transformers without altering orchestration logic. It also supports independent scaling, testing and governance of each component.
Core Engine Components and Their Roles
- Model Management and Serving Module: Manages model lifecycles, version control, A/B tests and rollouts. Common frameworks include TensorFlow Serving and TorchServe.
- Natural Language Understanding and Processing Engine: Extracts intent, entities and context for text or speech interactions. Options range from OpenAI’s GPT models for generative tasks to Rasa NLU for custom intent pipelines.
- Data Pipeline and Integration Manager: Orchestrates data flows from transactional systems, IoT sensors and third-party APIs. Tools such as Apache Kafka, Apache NiFi and cloud data services enable real-time streaming and batch ingestion.
- Knowledge Base and Context Repository: Stores structured knowledge graphs, ontologies and context snapshots for long-term reasoning. Graph databases like Neo4j or Ontotext GraphDB support semantic queries and relationship traversal.
- Decision Orchestrator and Planner: Interprets objectives, formulates multi-step plans and selects actions using constraint solvers, integer programming or reinforcement learning agents.
- Execution Interface and Action Dispatcher: Translates high-level decisions into API calls, SQL queries, dashboard updates or notifications. Workflow engines like Apache Airflow ensure reliable task scheduling and retries.
- Monitoring, Feedback and Self-Learning Loop: Captures performance indicators, user corrections and error rates to trigger retraining, hyperparameter tuning or policy updates. MLOps platforms such as MLflow and Kubeflow Pipelines streamline these loops.
- Security, Compliance and Governance Layer: Enforces access controls, encryption and audit logging. Policy engines like Open Policy Agent integrate governance frameworks for regulatory compliance.
Integration Patterns and Data Flow Architectures
Seamless cooperation among engine components is achieved through established integration patterns. Key approaches include:
- Event-Driven Architecture—Components communicate via message buses (e.g., Apache Kafka or AWS EventBridge), enabling real-time triggers from ingestion through decisioning.
- API-First Modular Design—Each service exposes REST or gRPC endpoints, with the orchestration layer handling sequencing, retries and version management.
- Shared Data Lake with Metadata Catalog—Centralized storage of raw and processed data alongside metadata, enabling components to read and write governed by a catalog service.
- Service Mesh for Secure Communication—Microservices use a mesh (e.g., Istio or Linkerd) to enforce encryption, policies and traffic routing transparently.
Data flow architectures range from batch processing for massive historical datasets to real-time streaming. Batch frameworks offer predictable execution windows, while streaming platforms such as Apache Pulsar, AWS Kinesis and Google Cloud Pub/Sub deliver low-latency event handling. Organizations choose between Lambda (combined batch and real-time) and Kappa (stream-only) patterns based on latency tolerance, consistency needs and operational overhead.
Model Integration, Standardization and Interpretability
Standardized interfaces ensure interoperability among heterogeneous model components. Formats like the Open Neural Network Exchange (ONNX) and Predictive Model Markup Language (PMML) enable model exchange across frameworks such as TensorFlow and PyTorch. Key criteria include serialization fidelity, language-agnostic exchange, backward compatibility and community governance. Containerized function interfaces, inspired by serverless paradigms, further enhance portability across cloud and on-premises environments.
Rigorous tracking of data provenance and model lineage is vital for transparency and compliance. Metadata catalogs and graph-based lineage systems document sources, transformations, feature derivation and hyperparameters. Interpretability frameworks embed explanatory annotations—feature attributions, counterfactuals and surrogate models—enabling stakeholders to reconstruct decision rationales. Organizations often align with the FAIR Data Principles for findability, accessibility, interoperability and reusability of data and models.
Performance Considerations and Infrastructure
Performance is multidimensional, encompassing inference latency, throughput, model accuracy, resource efficiency and sustainability. Decision makers use cost-performance curves, Pareto analyses and multi-objective matrices to balance these factors. Model architectures—from deep transformers and graph neural networks to classical algorithms—are evaluated via benchmarks like MLPerf Inference. Inference engines such as TensorFlow Serving, PyTorch Serve and the NVIDIA Triton Inference Server optimize execution, support dynamic batching and manage GPU memory.
Model optimization techniques including quantization (INT8), pruning and distillation reduce operational footprints and accelerate inference. Data pipeline throughput depends on processing strategies: micro-batch frameworks like Apache Spark Streaming versus true streaming systems. Hardware accelerators—GPUs, TPUs, FPGAs and AI ASICs—offer trade-offs in latency, energy efficiency and programming complexity. Cloud services such as AWS SageMaker, Google Cloud Vertex AI and Azure Machine Learning provide elastic endpoints, while hybrid deployments combine on-premises accelerators with cloud bursting for peak loads.
Balancing throughput and latency involves adaptive batching, priority queuing and distributed inference via Kubernetes or Kubeflow. Observability through time-series databases, distributed tracing and dashboards enables rapid detection and remediation of performance degradations. Sustainability considerations, guided by frameworks like the Green Software Foundation’s Energy Impact Model, factor energy consumption and carbon footprint into technology choices.
Explainability requirements introduce additional compute overhead. Tools such as NVIDIA Nsight and Intel VTune profile runtime behavior, uncover bottlenecks and support continuous integration pipelines. Contextual scenarios—from millisecond-latency trading to diagnostic healthcare—dictate distinct performance and explainability priorities. Standard benchmarks and governance protocols, including MLPerf and emerging regulatory frameworks, ensure accountability and comparability across deployments.
Cost-optimization strategies—spot instances, reserved capacity, serverless inference and dynamic scaling—align infrastructure spending with usage. By integrating performance targets with budget constraints, organizations achieve cost-effective scalability without sacrificing analytical agility.
Balancing Innovation with Practical Constraints
Pursuing advanced agent capabilities must be balanced against operational realities. Defining clear performance objectives tied to business value prevents overengineering. Pilot initiatives scoped for immediate ROI limit complexity, while roadmapped vendor maturity guides upgrade paths. Allocating resources for iterative improvements rather than large-scale upfront development accelerates time-to-value.
Scalability demands—distributed processing, microservices and specialized hardware—introduce integration and maintenance overhead. Leaders weigh horizontal scaling via Kubernetes against monolithic prototypes, and distributed datastores against single-node databases. Vendor ecosystems present trade-offs between proprietary lock-in and open-source flexibility. Hybrid architectures and abstraction layers help future-proof systems.
Total cost of ownership analyses encompass licensing, compute, data engineering, model training, monitoring and security audits. ROI frameworks compare development expenses and operational costs against revenue uplifts, cost reductions and risk mitigation. Multidisciplinary teams and data-driven cultures ensure AI insights are trusted and acted upon. Change management includes training, cross-functional collaboration, governance councils and user feedback loops.
Governance and security checkpoints—data catalogs, role-based access controls, encryption protocols, audit logging and compliance reviews—protect against unauthorized access and regulatory violations. Balancing high-performance models with interpretability may involve surrogate explainers, hybrid architectures and calibrated acceptance criteria. Modular designs, versioning practices and CI/CD pipelines mitigate technical debt. Ethical frameworks enforce bias detection, transparency, diverse oversight and human intervention in high-stakes scenarios, ensuring that autonomous agents uphold organizational and societal values.
Chapter 3: Intelligent Data Preparation and Quality Management
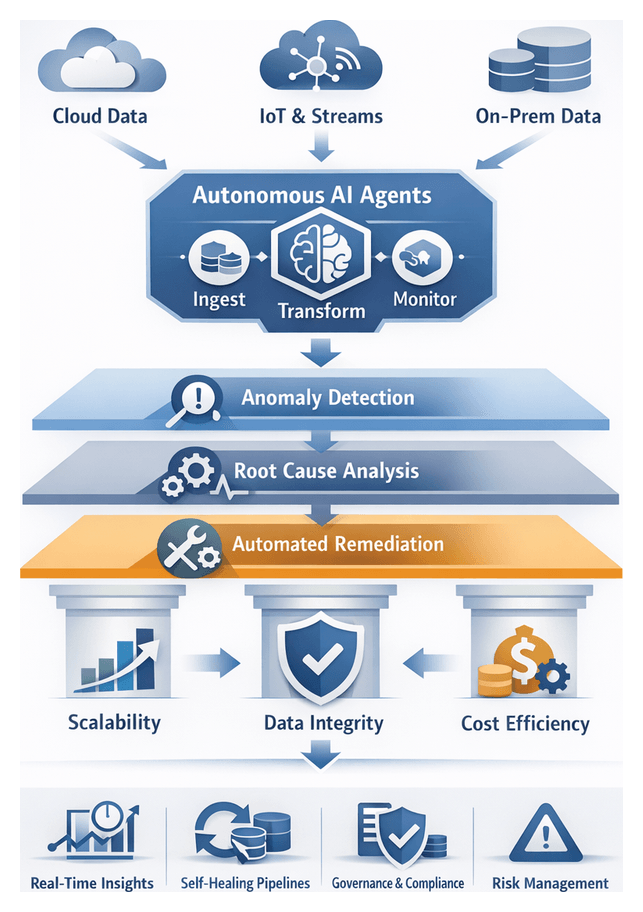
Data Autonomy: Transforming the Analytics Ecosystem
Enterprises today generate and process massive volumes of data across cloud platforms, streaming applications, on-premise repositories and edge devices. As data sources multiply and stakeholders demand real-time insights, traditional extract-transform-load (ETL) architectures strain under the weight of scale, complexity and speed. Data autonomy—a model in which intelligent software agents assume end-to-end responsibility for data stewardship—addresses these challenges by embedding machine learning, natural language processing and real-time orchestration throughout the analytics lifecycle.
Autonomous agents perform self-directed tasks that span source identification, ingestion, validation, transformation, cataloging and monitoring. They detect anomalies, resolve inconsistencies, adapt to schema changes and maintain transparent lineage. By shifting repetitive preparation work from humans to machines, organizations can:
- Scale ingestion and cleansing to petabyte volumes.
- Navigate diverse formats and evolving schemas.
- Deliver insights on demand for agile decision making.
Three converging trends drive the urgency for autonomy: the explosion of structured and unstructured sources including IoT and social feeds; the imperative for instantaneous, predictive and prescriptive analytics; and resource constraints that limit the availability of specialized data engineers. In response, data professionals now define high-level objectives, quality thresholds and governance policies, while agents translate those specifications into operational workflows, surface exceptions and learn from feedback.
Self-Healing Pipelines: Conceptual Foundations
Self-healing pipelines extend data autonomy by detecting, diagnosing and remediating issues without direct human intervention. Moving beyond simple scheduling and alerting, these pipelines embody closed-loop logic to sustain data integrity, flow continuity and analytical reliability under dynamic conditions.
Layered Architecture for Anomaly Management
- Anomaly Detection Layer: Monitors schema conformity, row counts and distribution patterns.
- Diagnostic Layer: Correlates deviations with latency spikes, schema shifts or upstream failures to identify root causes.
- Remediation Layer: Executes predefined or adaptive fixes, from schema reconciliation and data imputation to process restarts and transaction replays.
Detection Mechanisms
- Rule-based monitoring using integrity constraints and thresholds.
- Statistical profiling of time-series baselines and multivariate correlations.
- Machine learning classifiers trained on labeled incident data.
Rule-based approaches offer transparency and ease of auditing but can be brittle. Statistical methods adapt to drift yet risk false positives during legitimate shifts. Machine learning models provide nuanced detection but require curated training sets and ongoing governance.
Automated Remediation Strategies
- Schema Reconciliation: Dynamic field mapping and optional attribute handling.
- Data Imputation: Statistical interpolation, predictive modeling or reference lookups.
- Process Rescheduling: Rerouting flows to alternate clusters or pausing until upstream systems stabilize.
- Rollback and Replay: Reverting to the last known good state and replaying batched transactions.
Leading practices combine deterministic fixes for low-risk anomalies with conditional workflows for complex issues, preserving resilience without compromising data fidelity.
Interpretive Frameworks
- Resilience-First Model: Prioritizes rapid recovery via hot failovers and process duplication.
- Data-Integrity Model: Emphasizes detection precision, audit trails and remediation traceability.
- Cost-Efficiency Model: Balances automation benefits against infrastructure and maintenance overhead.
Financial services often adopt data-integrity models with strict compliance tracking, whereas digital media platforms lean toward resilience-first architectures to support high-velocity personalization.
Metrics for Effectiveness
- Mean Time To Detection (MTTD): Time from anomaly onset to detection.
- Mean Time To Repair (MTTR): Duration between detection and remediation.
- Automated Remediation Rate: Percentage of incidents resolved without human intervention.
- False Positive Rate: Share of alerts triggered by non-actionable deviations.
- Data Quality Impact Score: Composite of downstream error rates, drift incidents and stakeholder feedback.
Top-performing pipelines achieve automation rates above 80 percent with false positive rates below 10 percent, though actual figures depend on domain complexity and data variability.
Building Trust and Mitigating Risk
Continuous Quality Assurance
Autonomous quality management agents monitor data streams in real time, enforcing schema validation, completeness thresholds and anomaly detection. They generate contextual alerts that explain the nature and severity of quality issues, enabling analysts, executives and operational teams to interpret insights with full awareness of any caveats.
Predictive Risk Management
By modeling historical anomaly patterns and integrating external signals—such as system performance metrics or update schedules—agents can forecast potential quality degradations. This forward-looking approach allows data teams to allocate resources proactively, ensuring that critical dashboards and reporting pipelines remain accurate and actionable.
Governance, Compliance and Auditability
Quality agents embed policy enforcement directly into data pipelines, validating compliance with retention schedules, privacy regulations like GDPR and CCPA, and internal standards. Automated policy checks reduce manual governance overhead while producing audit-ready logs of detected issues, corrective measures and stakeholder notifications.
Cross-Functional Collaboration and Culture
Agents classify quality incidents by domain, severity and business impact, providing a shared language for data engineers, analysts and business users. Contextual metadata—source identifiers, change timestamps and anomaly signatures—facilitates rapid root-cause analysis and strategic discussions. Over time, stakeholders internalize quality principles through exposure to agent-generated insights, accelerating data literacy and fostering a culture of continuous improvement.
Accelerating Decision Cycles
By preemptively gating data quality at ingestion, agents prevent flawed information from propagating through analytics pipelines. Near-real-time validation within event-driven architectures surfaces issues within seconds, enabling rapid response to market dynamics, environmental factors or operational disruptions.
Best Practices for Autonomous Data Preparation
- Establish Clear Governance Frameworks: Define steward roles for metadata standards, quality metrics and transformation logic. Codify approval workflows to ensure agents operate within business and regulatory boundaries.
- Define Measurable Quality Metrics: Agree on KPIs such as duplication rates, missing value thresholds and schema drift frequencies. Monitor metrics through dashboards or alerts to keep agents calibrated.
- Leverage Explainable Transformation Logic: Choose platforms like Trifacta and Alteryx that expose visual lineage views, rule annotations and correction rationales to empower auditability and stakeholder trust.
- Preserve Domain Context: Enrich agent knowledge bases with business glossaries, domain ontologies and custom dictionaries to avoid semantic misinterpretation in specialized areas.
- Implement Iterative Feedback Loops: Capture false positives, negatives and edge cases from stewards and end users. Incorporate curated examples into training corpora or rule sets to refine agent inference patterns.
- Balance Automation with Human Oversight: Set confidence thresholds and escalation policies to ensure that complex schema conflicts, ambiguous corrections or high-impact anomalies are reviewed by humans.
- Ensure Scalability and Performance: Architect pipelines on distributed engines or cloud-native services like Informatica and Talend. Perform load testing with representative datasets to validate throughput under peak demand.
- Embed Security and Privacy Controls: Enforce encryption at rest and in transit. Integrate data masking or tokenization policies and align with identity and access management solutions to protect sensitive information.
Caveats and Strategic Considerations
- Bias Propagation: Agents trained on historical data may inherit and amplify existing biases. Regular bias audits and detection routines are essential.
- Overfitting to Past Patterns: Pipelines that rely heavily on historical anomalies may struggle with novel event types. Schedule periodic retraining with forward-looking scenarios.
- Semantic Misalignment: In complex domains such as healthcare or finance, human-in-the-loop reviews remain indispensable to handle nuanced hierarchies and specialized terminology.
- Transparency Tradeoffs: Advanced machine learning techniques can improve correction accuracy but reduce interpretability. Balance model sophistication with auditability and regulatory requirements.
- Integration Complexity: Mismatches in APIs, metadata models or schema evolution can impede seamless agent deployment. Mitigate risk through phased pilot projects and sandboxed integration.
- Talent and Maintenance Costs: Sustaining agent performance demands data engineering and machine learning expertise. Budget for talent acquisition and upskilling initiatives.
- Governance Overhead: Multiple autonomous pipelines with diverging rulesets can complicate oversight. Maintain a central registry of agent configurations, transformation libraries and version histories.
- Latency Sensitivity: Lightweight rule checks upstream and deeper cleansing downstream can balance speed and quality in low-latency, event-driven environments.
Future Directions
- Predictive Maintenance for Data Flows: Use time-series forecasting to preempt resource bottlenecks and adjust allocations dynamically.
- Reinforcement Learning in Remediation: Employ feedback-driven policy optimization to refine correction strategies based on success metrics and cost signals.
- Cross-Pipeline Orchestration: Coordinate self-healing actions across interdependent workflows to prevent cascading failures.
- Explainable Remediation: Generate human-readable rationales for automated fixes to enhance auditability and stakeholder confidence.
- Natural Language Interfaces: Enable conversational data requirements specification, allowing agents to interpret intent and orchestrate complex pipelines.
- Federated Learning for Collaboration: Extend autonomy across organizational boundaries, facilitating secure model training on shared datasets without exposing raw data.
Chapter 4: Automated Exploratory Analysis and Visualization
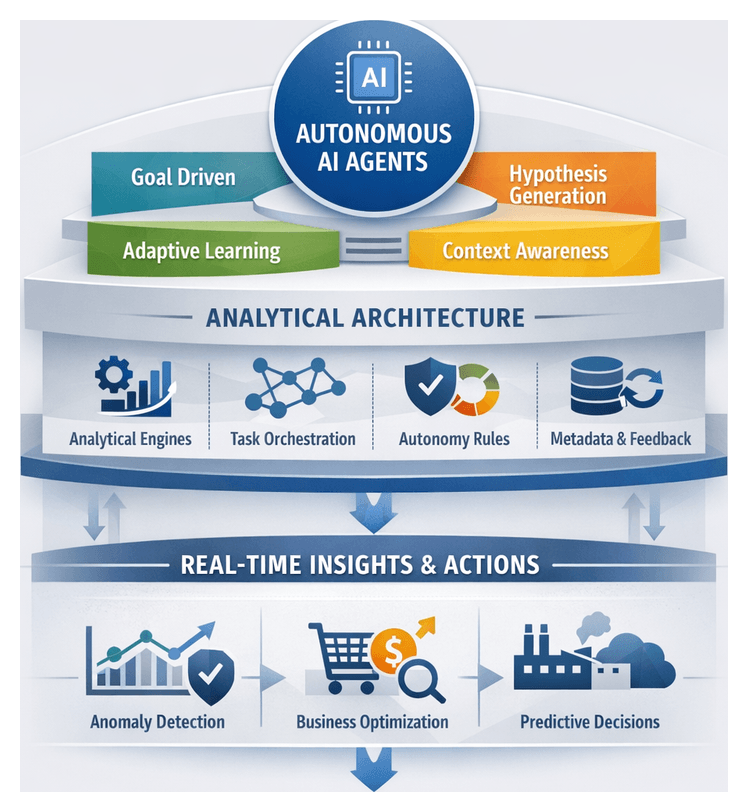
Embracing Analytical Autonomy in the Data-Driven Enterprise
The volume, variety, and velocity of enterprise data—from transactional records and sensor feeds to social media streams—are growing exponentially. Traditional analytics approaches that rely on manually configured queries, static dashboards, and batch reporting struggle to keep pace with modern demands. They become bottlenecks, requiring extensive human intervention and delaying critical decisions. Analytical autonomy represents a transformative shift: software agents that explore, interpret, and generate insights from data with minimal human direction. These autonomous AI agents can self-direct analytical workflows, formulate hypotheses, refine methods through adaptive learning, and maintain context awareness—enabling organizations to move from reactive analysis to proactive, real-time decision support.
Core Components of Autonomous AI Agents
Autonomous AI agents integrate multiple capabilities to deliver end-to-end analytical autonomy:
- Goal Orientation – Agents pursue defined business outcomes, such as demand forecasting or risk detection, autonomously selecting analytical techniques to meet objectives.
- Proactive Hypothesis Generation – Guided by statistical relevance and strategic priorities, agents formulate and evaluate their own hypotheses rather than waiting for human queries.
- Adaptive Learning – Through iterative analysis and feedback loops, agents refine models and choose more effective methods as new data or context emerges.
- Context Awareness – Agents maintain representations of business drivers, historical metrics, and stakeholder preferences to ensure insights align with organizational goals.
- Explainability – Despite autonomous operation, agents produce audit trails and reasoning summaries that enable transparency and trust.
The underlying architecture typically comprises:
- Analytical engines powered by statistical estimators, machine learning models, and natural language processing modules.
- Task orchestration frameworks that sequence data ingestion, model training, validation, and reporting, while managing exceptions.
- Autonomy protocols with rules and thresholds to determine when agents proceed independently versus seeking human input.
- Metadata registries tracking data definitions, lineage, and usage history for traceability and governance.
- Continuous feedback loops that monitor outcome accuracy, user satisfaction, and business impact, guiding model retraining and retirement of obsolete pathways.
Evaluating Dynamic Visualization Algorithms
Dynamic visualization algorithms translate complex data flows into interactive, real-time visual representations. Effective evaluation combines technical performance metrics with human-centric criteria.
Analytical Evaluation Criteria
- Performance Latency – Time from data update to visual refresh under peak loads.
- Scalability – Handling high-volume, high-velocity streams without degradation.
- Adaptability – Support for on-the-fly reconfiguration of charts and filters.
- Resource Efficiency – CPU, GPU, and memory utilization during interactive sessions.
- Interpretability – Clarity of visual encoding and support for user annotations.
- Integration Capability – API compatibility with platforms like Microsoft Power BI, Grafana and AI-driven engines.
Algorithm Taxonomies and Frameworks
- Event-Driven Renderers – Trigger updates based on user actions or system events, common in dashboard tools.
- Streaming Accumulators – Aggregate data over moving windows for operational monitoring.
- Incremental Layout Engines – Gradually recompute visual layouts, typical in network visualizations.
- Hybrid Models – Combine batch processing with micro-updates to balance throughput and responsiveness.
- Context-Aware Adaptors – Dynamically select visual encodings based on data characteristics and user intent.
- Generative Pipelines – Leverage machine learning to propose new views or highlight anomalies automatically.
Performance, Interpretability, and Integration
Leading platforms such as Tableau, powered by smooth transition animations and history panels, reinforce trust through explainable transitions. Solutions like ThoughtSpot and Qlik Sense employ associative engines to reconfigure views dynamically as users probe new dimensions. Integration with AI-driven agents further enhances value: agents can recommend chart types, propose feature transformations, or surface anomalies directly within visualization layers. Compatibility with open standards—OData, MQTT, Apache Arrow—ensures seamless connectivity to machine learning endpoints and platforms like Amazon QuickSight and Grafana.
Governance and Compliance
As dynamic visualizations interact with sensitive data, robust governance is essential. Algorithms must support role-based access control, data masking, audit logging, and comply with protocols such as SAML and OAuth. Compliance with GDPR, HIPAA, and SOC 2 is evaluated through simulated audits and breach scenarios to confirm that dynamic updates do not expose unauthorized data subsets.
Cost-Benefit and Future Directions
Evaluation extends to total cost of ownership and ROI, considering licensing fees, infrastructure costs, and maintenance overhead. Open-source frameworks like D3.js often reduce licensing expenses but may require additional development resources compared to proprietary engines. Emerging research explores reinforcement learning for optimizing update strategies, multimodal interfaces, and generative storyboards that anticipate user queries. The ability of algorithms to orchestrate self-optimizing visual experiences will increasingly differentiate technology choices.
Applications of Autonomous Insight Generation
Autonomous AI agents drive value across diverse industries by discovering patterns and anomalies without explicit human scripting.
- Self-Service Business Intelligence – Platforms such as Microsoft Power BI and Amazon QuickSight embed AI-driven anomaly detection and narrative generation, enabling non-technical users to pose natural-language queries and receive interactive visualizations and summaries.
- Financial Services – Solutions like DataRobot deploy unsupervised clustering and temporal analysis to detect evolving fraud schemes and optimize risk scoring, balancing false-positive rates with detection sensitivity while maintaining regulatory transparency.
- Healthcare – IBM Watson Studio integrates NLP to extract variables from clinical notes, supporting early warning systems for sepsis, optimizing operating room schedules, and uncovering treatment-outcome associations underpinned by evidence-based practice.
- Retail and E-Commerce – ThoughtSpot‘s search-based interface and Qlik Sense agents analyze clickstream logs, social media sentiment, and inventory levels to recommend product bundles, dynamic pricing, and targeted promotions.
- Manufacturing – DataRobot and IoT analytics platforms ingest sensor telemetry and environmental data to forecast equipment failures and recommend maintenance schedules, shifting operations from reactive to condition-based strategies.
- Marketing Analytics – Salesforce Einstein Analytics surfaces high-impact campaign variables and audience segments, enabling mid-campaign pivots that optimize media mixes and improve marketing ROI.
- Supply Chain and Logistics – Qlik Insight Advisor models what-if scenarios—supplier delays, demand spikes—by correlating external indicators like weather and geopolitical events, enabling proactive resilience planning.
- Smart Cities and Environmental Monitoring – Autonomous agents analyze traffic flows, utility usage, and air quality metrics to detect hotspots, forecast infrastructure stress points, and inform urban planning and sustainability initiatives.
Across these applications, autonomous insight generation accelerates sensemaking, democratizes analytics, and reframes professionals as strategic interpreters who validate and contextualize agent outputs through human-in-the-loop mechanisms.
Benefits and Limitations of Automated Exploration
Key Benefits
- Accelerated time to insight through unsupervised clustering, anomaly detection, and dynamic correlation analysis.
- Democratization of data discovery via AI-powered self-service interfaces.
- Scalable exploration across petabyte-scale repositories and streaming telemetry.
- Unbiased pattern detection that surfaces non-intuitive relationships.
- Consistent, repeatable workflows with traceable lineage supporting auditability.
- Continuous, real-time monitoring that maintains situational awareness.
Critical Limitations
- Dependence on data quality and coverage, requiring rigorous stewardship and metadata management.
- Interpretability challenges due to opaque algorithms and proprietary heuristics.
- Risk of spurious correlations without human judgment to assess business relevance.
- Contextual gaps—agents may overlook domain-specific cycles or regulatory events.
- Infrastructure constraints from compute-intensive processes, necessitating hybrid architectures.
- Governance and ethical implications, including bias perpetuation and privacy concerns.
Balancing Automation and Oversight
Maximizing value from automated exploration demands a hybrid approach: embedding governance checkpoints, defining escalation criteria, and integrating domain expert review stages. Regular calibration exercises, in which analysts compare agent-generated insights with manual benchmarks, help maintain accuracy and alignment with evolving objectives.
Strategic Implications
Automated exploration should be viewed as a force multiplier rather than a replacement for expert analysis. Investments in data infrastructure, transparency tools, and change management foster an environment where AI-driven agents augment human capabilities. Continuous monitoring of performance metrics and user feedback loops ensures that autonomous agents adapt to business shifts and maintain analytic integrity. By combining machine efficiency with human judgment, organizations can harness the full potential of AI-driven discovery while controlling for unintended consequences.
Chapter 5: Predictive Modeling and Forecasting by AI Agents
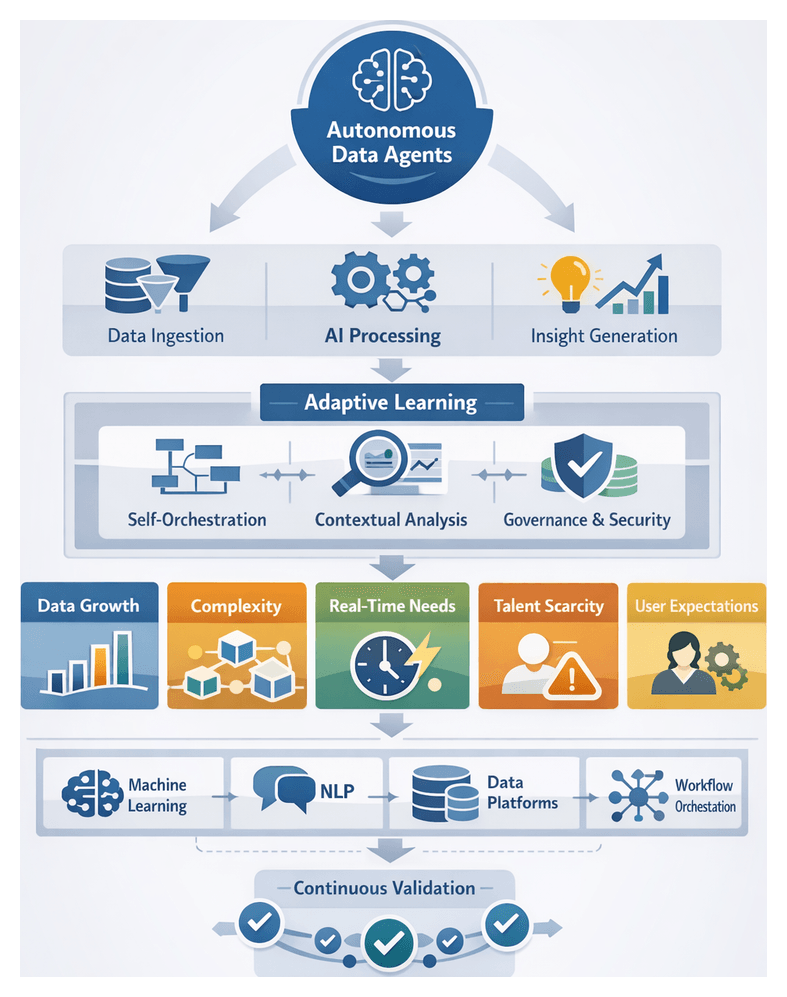
The Rise of Autonomous Data Agents
The modern analytics landscape is undergoing a profound shift as organizations embrace data autonomy—systems that manage ingestion, transformation, analysis, and reporting with minimal human intervention. Autonomous AI agents form the vanguard of this evolution, leveraging adaptive machine learning, natural language processing, and continuous learning frameworks to navigate complex, high-velocity data environments. By ingesting raw inputs, executing analytical workflows, and surfacing actionable insights, these agents reduce reliance on manual configurations, democratize analytics, and accelerate decision cycles.
Driving Forces of Data Autonomy
- Explosive Data Growth: Enterprises generate petabytes of structured and unstructured data from sensors, transactions, social media, and operational systems.
- Increasing Complexity: Hybrid clouds, microservices, and multi-vendor ecosystems complicate integration, lineage tracking, and governance.
- Speed of Business: Competitive markets demand real-time insights. Manual analytics pipelines struggle to keep pace with rapid decision windows.
- Talent Scarcity: A shortage of skilled data scientists and engineers limits scalability of handcrafted models and pipelines.
- User Expectations: Business stakeholders expect self-service access, intuitive interfaces, and personalized insights without lengthy IT cycles.
Autonomous agents address these challenges by automating data preparation, model selection, and anomaly detection. Continuous learning loops enable them to adapt analytical strategies as new patterns emerge, while embedded governance ensures compliance, privacy, and security at every stage.
Defining Data Autonomy
Data autonomy encompasses the system’s ability to self-orchestrate end-to-end workflows, refine models over time, reason contextually about datasets, and deliver proactive insights. Core capabilities include:
- Self-Orchestration: Automated scheduling and dependency management based on data arrival and business priorities.
- Adaptive Learning: Dynamic feature engineering, schema evolution, and hyperparameter tuning in response to shifting data distributions.
- Contextual Reasoning: Customizing analytical techniques to dataset characteristics and stakeholder objectives.
- Proactive Insights: Surfacing trends, anomalies, and predictive signals without explicit queries.
- Governance Enforcement: Integrating audit trails, privacy checks, and compliance controls into automated processes.
Foundational Components
Implementing autonomous analytics requires a cohesive architecture that unites several pillars:
- Machine Learning Platforms: Solutions like DataRobot and H2O.ai provide automated model building, feature generation, and tuning capabilities.
- Natural Language Processing Engines: NLP modules translate business queries into workflows and generate narrative explanations of results.
- Data Storage and Processing: Scalable warehouses such as Snowflake and lakehouse platforms like Databricks Autoloader offer unified, efficient storage and compute.
- Workflow Orchestrators: Apache Airflow and Kubeflow manage scheduling, monitoring, and dependency resolution for end-to-end pipelines.
- Metadata and Catalog Services: Data catalogs centralize schema definitions, lineage metadata, and usage statistics for asset discovery and validation.
- Observability and Monitoring: Platforms such as Splunk and Datadog supply telemetry to detect drift, performance issues, and security anomalies.
- API and Integration Layers: Standardized connectors enable seamless interaction with ERP, CRM, IoT, and third-party systems.
Organizational Impact and Implementation
Delegating routine analytics tasks to autonomous agents yields strategic benefits:
- Accelerated Time to Insight: Real-time pipelines and continuous modeling reduce latency from data generation to decision support.
- Scalable Expertise: Encoded best practices and heuristics allow rapid deployment of advanced analytics without proportionate staffing increases.
- Consistency and Repeatability: Standardized processes ensure reproducible results and reduce human error.
- Democratization of Analytics: Self-service interfaces empower non-technical users to pose complex questions and receive contextualized interpretations.
- Enhanced Governance: Embedded compliance checks and audit logs uphold privacy, security, and regulatory alignment.
To prepare for autonomous analytics, organizations must define unified data strategies, select scalable AI and orchestration tools, establish governance frameworks, upskill teams in AI collaboration, and pilot autonomous workflows before enterprise-wide adoption.
Validating Autonomous Models
Multi-Dimensional Validation Frameworks
Model validation in an autonomous context extends beyond pass/fail checks to a layered framework assessing generalizability, robustness, and strategic relevance. Two complementary approaches guide validation:
- Statistical Rigor: Techniques such as k-fold cross-validation, nested validation, and bootstrap resampling quantify uncertainty and guard against overfitting.
- Strategic Relevance: Cost-benefit analyses, ROI projections, and scenario planning align metric thresholds with business objectives and risk tolerances.
Hybrid validation models embed economic loss functions or utility curves, enabling decision-makers to weigh technical performance alongside anticipated business impact.
Core Metrics Across Use Cases
Performance metrics vary by analytical task, and interpreting them requires domain context. Key measures include:
- Classification: Precision, recall, F1 score, ROC AUC, and area under the precision-recall curve, selected based on class imbalance and misclassification costs.
- Regression: Mean absolute error (MAE), root mean squared error (RMSE), R-squared, mean bias error, and median absolute deviation, each reflecting different sensitivities to outliers and variance.
- Forecasting: MAPE variants, mean absolute scaled error (MASE), and skill scores against naïve benchmarks, illuminating incremental predictive value.
- Anomaly Detection: True positive rate, false alarm rate, and time to detection, crucial for operational resilience.
Experts recommend a balanced scorecard that contextualizes multiple metrics side by side to avoid optimizing on a single dimension at the expense of long-term value.
Domain-Specific Validation Approaches
Domain constraints shape validation methods:
- Financial Services: Backtesting against historical market data and stress testing under hypothetical volatility scenarios reveal drift and resilience.
- Healthcare: Calibration curves and fairness audits ensure predicted probabilities align with observed outcomes and do not disadvantage demographic groups.
- Retail and Marketing: Uplift modeling and causal inference techniques measure the incremental impact of targeted interventions through hold-out experiments and ROI analysis.
- Manufacturing and IoT: Time-to-event analysis and survival curves assess predictive maintenance models against downtime logs and safety thresholds.
Balancing Accuracy, Complexity, and Interpretability
Pursuing marginal accuracy gains often increases model complexity and reduces transparency. Validation frameworks therefore incorporate an interpretability axis, evaluating models on predictive power, complexity, and explainability. Techniques such as partial dependence plots, surrogate trees, SHAP, and LIME offer post-hoc insights, but organizations must calibrate their use against stakeholder expertise and regulatory requirements. In high-stakes settings, simpler or hybrid rule-based architectures may be favored to satisfy auditability and human oversight.
Emerging Validation Methodologies
- Meta-Validation: Embedding validation logic within autonomous workflows to generate dynamic reports across model iterations, cohorts, and feature sets.
- Counterfactual Evaluation: Simulating input perturbations to assess resilience and uncover latent failure modes beyond static test sets.
- Adversarial Validation: Training classifiers to distinguish training from production data, quantifying drift and triggering retraining workflows.
- Stakeholder-Centric Metrics: Capturing decision confidence, user satisfaction, and downstream business outcomes by linking predictions to dashboards and feedback loops.
Integrating Validation into Governance
Validation artifacts—error analyses, calibration plots, fairness audits—feed compliance and audit teams, documenting due diligence and supporting risk committees in setting error thresholds, escalation protocols, and human review gates. Automated governance policies can accelerate low-risk model deployment while enforcing human oversight for high-complexity or high-impact applications.
Continuous Validation and Monitoring
In dynamic environments, continuous validation is essential. Real-time dashboards track performance metrics over time, detecting drift before business impact. Statistical process control charts, cohort analysis, and periodic recalibration protocols maintain model reliability, while data quality checks ensure inputs remain consistent with validation assumptions. Automated alerts and feedback loops trigger retraining or intervention, balancing agility with stability.
Scaling Forecasting Agents Across Industries
Key Operational Domains
Autonomous forecasting agents have become strategic imperatives across sectors:
- Retail and Consumer Goods: Demand forecasting for thousands of SKUs, promotional uplift modeling, and inventory optimization.
- Supply Chain and Logistics: Multi-echelon replenishment, lead-time prediction, and capacity planning in global networks.
- Financial Services: Real-time risk assessment, market trend analysis, and automated portfolio rebalancing.
- Energy and Utilities: Grid load forecasting, renewable generation variability modeling, and dynamic pricing strategies.
- Healthcare and Life Sciences: Patient admission forecasts, resource demand planning, and epidemiological projections.
- Manufacturing and Industrial IoT: Predictive maintenance scheduling, throughput forecasting, and yield estimation.
Strategic Implications of Scale
Centralized, scalable forecasting infrastructures synchronize decision cycles, reduce repetitive retraining tasks, accelerate response to market disruptions, and integrate probabilistic forecasts into risk management dashboards. By automating model distribution and parallel scenario simulations, organizations free analysts to focus on interpretation and strategic action.
Contextual Analytical Frameworks
- Maturity Model for Predictive Intelligence: From ad-hoc statistical forecasts to fully autonomous, self-optimizing systems.
- Decision Value Chain Analysis: Mapping how forecasts flow through decision points and quantifying marginal value.
- Reliability-Complexity Trade-Off Grid: Balancing sophistication, explainability, and operational overhead.
- Capability Footprint Matrix: Charting functionality across frequency, horizon, granularity, and integration depth.
Data Characteristics and Scalability
Scalability depends on data volume, velocity, heterogeneity, seasonality, and governance. High-frequency IoT streams require streaming architectures, while periodic sales figures may tolerate batch updates. Combining structured records with unstructured text or imagery amplifies complexity. Automated metadata management, lineage tracking, and anomaly detection ensure data quality at scale.
Industry Perspectives on Deployment
- Centralized Governance Advocates: Standardize model registries, enterprise data lakes, and validation protocols for distributed agents.
- Federated Innovation Proponents: Empower business units to customize pipelines within central guardrails.
- Human-AI Partnership Models: Blend agent-driven forecasts with expert review cycles.
- Fully Autonomous Experimenters: Pilot continuous-learning agents that update in production based on performance feedback.
Embedding Forecasting into Decision Cycles
By aligning forecast horizons with operational cadences, agents inform:
- Tactical Adjustments: Near-real-time demand signals for inventory and pricing on daily or hourly timescales.
- Operational Planning: Weekly forecasts for workforce scheduling, production runs, and logistics routing.
- Strategic Roadmaps: Quarterly and annual scenarios underpinning budgets, capital investments, and expansion plans.
Ethical and Governance Considerations
- Transparency: Document model assumptions, data sources, and drift detection for auditors and decision-makers.
- Fairness and Bias: Review forecast outputs for disparate impacts, especially in lending, pricing, and resource allocation.
- Accountability: Assign ownership of agent-driven decisions and define escalation paths for high-risk contexts.
- Regulatory Compliance: Adhere to financial reporting standards, patient privacy laws, and industry-specific mandates.
Integrating Agents into Enterprise Strategy
Successful deployment relies on modular architectures that plug into existing BI platforms and data warehouses without full platform replacement. Governance councils with cross-functional stakeholders align forecasting outputs with strategic and ethical objectives. Performance measurement frameworks quantify agent-driven value, balancing efficiency gains with long-term innovation potential.
Emerging Trends in Forecasting
- Generative Scenario Modeling: Agents simulate economic and operational scenarios with narrative explanations.
- Multi-Agent Ecosystems: Specialized agents negotiate and co-optimize forecasts across business domains.
- Context-Aware Adaptivity: Agents adjust logic based on exogenous signals such as social media sentiment or geospatial events.
Technical Architecture and Risk Mitigation
Data Quality and Feature Robustness
Forecasting accuracy hinges on input data integrity. Enterprises must assess source lineage, perform statistical profiling to detect concept drift, and incorporate domain expertise to select causally relevant features. Treating data quality as an ongoing practice ensures models remain robust as market conditions evolve.
Algorithm Selection and Model Complexity
Choosing between expressive architectures and simpler algorithms involves a strategic trade-off. Initial deployments often use interpretable models—such as generalized linear models or tree-based ensembles—to establish performance baselines. Complex models like deep neural networks require extensive cross-validation and stress-testing to justify their incremental accuracy gains and manage tuning, resource, and explainability challenges.
Interpretability and Explainability Constraints
Regulated industries demand transparency in decision logic. Post-hoc tools like SHAP and LIME provide local explanations but may not reveal deeper interactions in opaque models. Hybrid architectures that combine rule-based components with machine learning often satisfy both performance and auditability requirements for high-stakes forecasts.
Infrastructure Scalability and Performance
Large-scale forecasting shifts computational burdens to production environments. Robust infrastructure—distributed compute clusters, GPU nodes, and elastic cloud resources—must be provisioned and scaled dynamically. Capacity planning, containerization, and model quantization help optimize resource usage, but require rigorous validation to preserve predictive fidelity. Network throughput, storage architecture, and data I/O all influence pipeline reliability and latency.
Regulatory and Ethical Compliance
Forecasting agents in regulated sectors must adhere to frameworks such as GDPR, Basel guidelines, or HIPAA. Embedding ethical guardrails—bias audits, transparency logs, and documented decision pathways—ensures alignment with corporate values and external mandates. Interdisciplinary review boards comprising data scientists, legal advisors, and domain experts provide oversight at each stage of the model lifecycle.
Continuous Monitoring and Model Evolution
Autonomous agents require ongoing surveillance to detect drift, accuracy loss, or emergent anomalies. Real-time dashboards track forecast error distributions, calibration curves, and responses to exogenous shocks. Feedback loops trigger retraining or human intervention when deviations exceed predefined tolerances. Thoughtful retraining schedules and version control balance agility with stability, preventing overfitting to transient noise.
Strategic Limitations and Risk Trade-Offs
- Dependence on historical patterns that may not hold in unprecedented events.
- Risk of amplifying latent biases in training data, leading to inequitable outcomes.
- Operational fragility when infrastructure or monitoring frameworks are immature.
- Regulatory constraints favoring transparency over complexity may limit model sophistication.
- Trade-offs between frequent retraining and stability to avoid oscillating predictions.
By navigating these trade-offs with disciplined governance, robust architecture, and cross-functional collaboration, organizations can harness the speed, scale, and insight of autonomous forecasting agents while mitigating the inherent uncertainties of dynamic markets.
Chapter 6: Prescriptive Analytics and Decision Support Agents
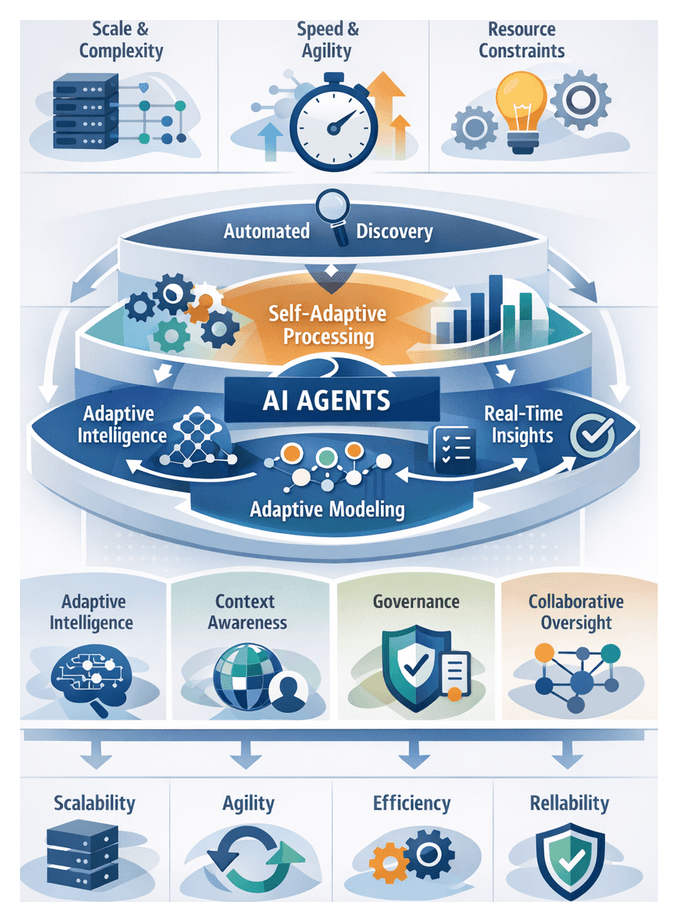
Data Autonomy in the Modern Analytics Ecosystem
The emergence of data autonomy marks a transformative shift in how organizations capture, process, and act upon information. Autonomous analytics systems manage data ingestion, transformation, modeling, and insight generation with minimal human intervention, leveraging adaptive intelligence, continuous learning, and self-governance. As enterprises contend with ever-increasing data scale, variety, and velocity, autonomous functions become essential to sustain agility, scale operations, and sharpen competitive differentiation.
Traditional analytics pipelines relied on manual extraction, cleansing, modeling, and scheduled reporting. These linear workflows struggled under demands for real-time insights, evolving schemas, and exponential growth in structured and unstructured sources. Data autonomy relocates routine tasks—such as schema detection, data profiling, feature extraction, anomaly identification, and model retraining—to intelligent agents that continuously adapt to changing conditions and user interactions.
Key forces driving this evolution include:
- Scale and Complexity: Organizations ingest data from IoT devices, streaming platforms, legacy systems, and external APIs, challenging static architectures.
- Speed of Decision-Making: Competitive markets demand rapid conversion of raw data into actionable intelligence.
- Resource Constraints: Talent shortages in data engineering and analytics incentivize automation of repetitive tasks.
- Democratization of Analytics: Business users require self-service capabilities, guided by agents that abstract technical complexity.
By embedding autonomous agents within analytics platforms, organizations realize:
- Agility in Insight Delivery: Pipelines self-repair in response to schema changes and data anomalies, minimizing downtime.
- Scalability Across Use Cases: Agents scale horizontally, monitoring multiple datasets in parallel without proportional increases in human oversight.
- Operational Efficiency: Automation of data validation and profiling frees analysts to focus on strategic interpretation and hypothesis testing.
- Consistency and Reliability: Governance frameworks enforce compliance and quality thresholds, reducing the risk of unauthorized analyses.
Where legacy analytics follow a linear sequence—data acquisition, manual preparation, static modeling, scheduled reporting, ad hoc analysis—autonomous frameworks operate as a continuous loop:
- Automated Data Discovery and Classification
- Self-Healing Data Preparation with Anomaly Detection
- Adaptive Model Training and Validation
- Real-Time Insight Streaming and Alerting
- Proactive Recommendations and Action Suggestions
Each phase incorporates feedback loops that monitor data quality, model performance, and user feedback, fostering continuous refinement. This closed-loop design aligns analytics outputs with evolving business goals and data characteristics.
Successful adoption reshapes organizational roles:
- Data Leaders: Define strategic objectives, governance policies, and ensure alignment with corporate goals.
- Analytics Translators: Bridge domain expertise and agent capabilities, contextualizing recommendations for stakeholders.
- IT and Infrastructure Teams: Provision scalable compute and storage, manage security controls, and integrate autonomous platforms.
- Business Users: Interact with intuitive interfaces, explore agent-generated insights, and execute actions confidently.
Foundational concepts include:
- Autonomy Continuum: Balancing advisory agents and fully self-executing systems to fit use-case requirements.
- Adaptive Intelligence: Agents learn from new data while maintaining explainability and compliance.
- Context Awareness: Interpreting business context, user intent, and domain rules to deliver relevant recommendations.
- Collaborative Oversight: Establishing trust through transparency, feedback mechanisms, and well-defined boundaries between human and agent tasks.
Analytical Foundations of Prescriptive Optimization
Prescriptive analytics transforms predictive insights into actionable recommendations through optimization techniques. Practitioners evaluate methods based on problem structure, solution guarantees, computational behavior, and alignment with business objectives. Optimization frameworks fall into three broad categories:
- Exact Techniques: Guarantee optimal solutions for well-defined mathematical models. Tools such as IBM ILOG CPLEX and Gurobi Optimizer deliver enterprise-grade solvers valued for rigorous proofs of optimality.
- Heuristic and Metaheuristic Strategies: Include greedy algorithms, genetic algorithms, simulated annealing, and tabu search. Frameworks like Google OR-Tools provide modules for rapid, near-optimal solutions in complex, non-convex domains.
- Hybrid Frameworks: Combine exact and heuristic elements, for example interleaving linear relaxations with local search. Prototyping often leverages SciPy Optimize before scaling to specialized solvers.
Industry experts interpret optimization through multiple analytical lenses:
Problem Structure and Formulation
- Linear vs. non-linear: Linear models enable fast convergence; non-linear models capture curvature and multimodal landscapes.
- Discrete vs. continuous: Integer variables introduce combinatorial complexity; continuous relaxations aid bounding and guiding searches.
Constraint Handling
- Hard Constraints: Inviolable rules such as regulatory or capacity limits.
- Soft Constraints: Penalty functions or slack variables allow trade-offs; frameworks like goal programming assign weights to preferences.
Objective Landscape and Multi-Objective Trade-Offs
- Single-Objective: Simplifies optimization but may overlook broader goals.
- Multi-Objective: Techniques such as weighted sum, ε-constraint, and evolutionary algorithms map Pareto frontiers.
Uncertainty and Robustness
- Deterministic: Assumes certainty, yielding precise recommendations.
- Stochastic Programming: Models input distributions in two-stage or multi-stage formulations.
- Robust Optimization: Seeks solutions that perform well under worst-case deviations.
Scalability and Computational Trade-Offs
- Complexity Analysis: Balances runtime against solution accuracy.
- Parallel and Distributed Architectures: Platforms such as Azure Machine Learning support distributed model fitting but require orchestration.
Evaluation criteria extend beyond raw solution quality:
- Solution Robustness: Performance under data deviations, measured by out-of-sample regret and stability indices.
- Interpretability: Understandability of decision rules; linear models and rule-based approaches rank highly.
- Integration Agility: Seamless connectivity to data pipelines, BI platforms, and human-in-the-loop controls via REST APIs and orchestration tools like Apache Airflow or Kubernetes.
- Cost of Computation: Licensing, infrastructure, and expertise expenses balanced against managed services.
- Governance and Auditability: Logging of decision rationale, version control, and traceable solution paths, critical in regulated industries.
Scenario simulation complements these frameworks. Common strategies include:
- Monte Carlo Simulation: Sampling input distributions to assess distributional performance and tail risks.
- Decision Tree Analysis: Mapping sequential decision points to compare expected value and risk-adjusted outcomes.
- Rolling Horizon Simulation: Periodic re-optimization in dynamic environments such as supply chains, emphasizing adaptation speed and stability.
Sensitivity analysis systematically varies parameters to quantify their impact on recommendations. Visualization tools like tornado diagrams and sensitivity matrices highlight the largest drivers of solution variability, informing governance reviews and confidence assessments.
In practice, organizations prototype with open-source libraries for rapid iteration and transition to commercial solvers for production. Prescriptive analytics agents orchestrate end-to-end workflows, invoking optimization routines as microservices while maintaining centralized logging, monitoring, and feedback loops.
Adoption Drivers and Strategic Implications of Autonomous Analysis
Enterprises across sectors confront shrinking decision windows and surging data volumes. Autonomous AI agents offer self-directed analysis that adapts in real time, automating hypothesis generation, model selection, and result interpretation. Analysts shift focus from manual pipeline maintenance to strategic action based on agent-surfaced patterns and outliers.
Experts identify three interrelated market drivers:
- Demand for Real-Time Insights: Instantaneous reaction to customer behaviors, supply disruptions, and regulatory changes.
- Data Monetization Pressures: Packaging analytics outputs as services or embedding recommendations in products.
- Customer Experience Expectations: Continuous refinement of personalization and predictive support.
Technological enablers include cloud-native infrastructure, container orchestration, serverless architectures, and mature MLOps practices. Machine learning frameworks such as TensorFlow, PyTorch, and scikit-learn power agent reasoning, while managed services streamline hosting and monitoring. AutoML platforms accelerate end-to-end model pipelines with embedded governance:
Organizational readiness encompasses:
- Data Infrastructure Resilience: Unified schemas, metadata catalogs, and lineage tracking.
- Governance and Compliance Alignment: Privacy, security, and audit policies for minimal human oversight.
- Skillset Diversification: Multidisciplinary teams fluent in AI ethics, domain expertise, and agent orchestration.
- Executive Sponsorship: Leadership commitment to experimentation and cultural shifts toward AI-driven decision making.
Supply Chain and Operations Optimization
Agents analyze sensor data, inventory levels, and external factors to optimize replenishment, routing, and maintenance. Benefits include reduced downtime and leaner inventories, but overreliance without validation can introduce fragility when upstream anomalies go undetected.
Customer Experience and Personalization
Retailers and digital platforms integrate browsing behavior and purchase history to tailor recommendations and offers. While conversion rates and satisfaction improve, ethical considerations around dynamic pricing and algorithmic bias demand oversight.
Financial Services and Risk Management
Banks and insurers monitor transactions, detect fraud, and model credit risk using thousands of signals. Regulatory compliance requires explainability and audit trails, often combining agent recommendations with human auditor reviews.
Healthcare Diagnostics and Clinical Decision Support
Agents correlate vitals, lab results, and medical literature to suggest diagnoses and treatment pathways. High stakes necessitate multi-layered validation, blending autonomous suggestions with clinician oversight.
Energy and Utilities Management
Energy providers forecast demand, balance grid loads, and predict equipment failures. Transparency in agent logic is vital for grid stability and satisfying regulatory bodies.
Experts apply conceptual models such as Diffusion of Innovations, the Technology–Organization–Environment framework, and AI Trust and Transparency indices to diagnose adoption gaps, forecast ROI, and design intervention strategies. Balancing opportunity and risk requires a dual-track approach:
- Opportunity Track: Identify high-impact use cases like predictive maintenance and churn prediction.
- Risk Track: Implement governance guardrails, bias detection routines, and human-in-the-loop checkpoints.
Strategic implications for industry leaders include:
- Differentiation through Speed and Precision
- Reinventing Business Models with subscription or pay-per-insight services
- Elevating Talent and Culture via reskilling and new AI governance roles
- Strengthening Governance Posture as a strategic asset
Constraints and Best Practices in Prescriptive Analytics
Data Quality and Uncertainty Management
Prescriptive analytics relies on accurate, complete input data. Techniques such as robust optimization and stochastic programming embed uncertainty into decision models. Continuous data lineage tracking and quality gates ensure validated inputs. Platforms like DataRobot automate validation, but human judgment remains essential for interpreting metrics and setting tolerance thresholds.
Algorithmic Complexity and Computational Constraints
Combinatorial and multi-objective problems can become intractable at scale. Approximation techniques, heuristics, and decomposition methods—such as Benders decomposition and Lagrangian relaxation—partition large problems into manageable subproblems. Cloud services like Google Cloud Optimization and IBM Decision Optimization offer scalable compute, but integrations must account for latency, cost, and data transfer overhead.
Model Interpretability and Stakeholder Trust
Transparent decision logic builds trust. Documentation of constraint definitions, objective functions, and weighting schemes is critical. Visualization of decision spaces, scenario simulations, and shadow pricing elucidate trade-offs. Explainability techniques—such as LIME and Shapley value decomposition—support model interrogation, especially in regulated industries where audit trails are non-negotiable.
Integration with Operational Systems and Data Silos
Prescriptive engines must interface with ERP, CRM, and SCM systems. Service-oriented architectures and well-defined APIs facilitate interoperability. Bidirectional data pipelines feed prescriptive insights into workflows and capture real-world outcomes for continuous improvement. Data federation and virtual views can alleviate physical integration challenges.
Scalability and Scenario Diversification
As adoption matures, use cases expand from inventory optimization to pricing, workforce scheduling, and logistics. Modular architectures with parameterized problem definitions and reusable optimization modules enable elastic scaling. Containerization and microservice patterns support workload surges, while scenario libraries catalog assumptions and benchmark outcomes for reuse.
Governance, Ethics, and Regulatory Compliance
Automated recommendations must adhere to privacy, fairness, and accountability mandates such as GDPR, HIPAA, and financial conduct rules. Ethics frameworks require bias detection and equitable resource allocation. Governance policies for model approvals, change management, and exception handling ensure that optimization objectives align with external mandates.
Human-in-the-Loop and Decision Oversight
Human judgment remains vital for high-impact recommendations. Decision checkpoints allow analysts to review and adjust constraints, explore alternatives, and simulate outcomes. Interactive consoles foster collaborative validation and organizational learning.
Alignment with Organizational Strategy
Prescriptive models must reflect strategic priorities—cost reduction, revenue growth, risk mitigation, or customer satisfaction. Workshops map business objectives to optimization criteria and constraint hierarchies. Balanced scorecards and performance dashboards integrate automated recommendations with KPIs, ensuring alignment as goals evolve.
Continuous Monitoring and Feedback Loops
Dynamic environments require monitoring of feasibility rates, deviation between recommended and actual outcomes, and optimization runtimes. Feedback loops enable agents to update objective weights, constraints, and data sources. Automated alerts signal performance drift, triggering review and recalibration.
Technology Selection and Vendor Ecosystems
Vendors span standalone solvers to integrated AI suites. Solutions such as SAS Viya, DataRobot, and cloud-native offerings on AWS, Azure, and Google Cloud must be evaluated for algorithmic breadth, integration, scalability, and governance support. Pilot programs validate fit before enterprise rollout.
Skills and Organizational Capability
Effective prescriptive analytics demands expertise in optimization science, data engineering, domain knowledge, and change management. Analytics centers of excellence, external partnerships, and upskilling programs bridge talent gaps. Collaboration and standardized documentation embed best practices in organizational memory.
Evolving Best Practices
Iterative development cycles alternating between experimentation and stakeholder validation ensure agility. Advisory councils guide strategy and risk management, while libraries of constraint templates, objective prototypes, and scenario definitions accelerate deployment. Embracing open-source frameworks controls vendor lock-in and fosters innovation.
By addressing these constraints and adopting established best practices, organizations can leverage prescriptive analytics to deliver actionable, trustworthy, and strategic decision support at scale.
Chapter 7: Integrating AI Agents into Business Workflows
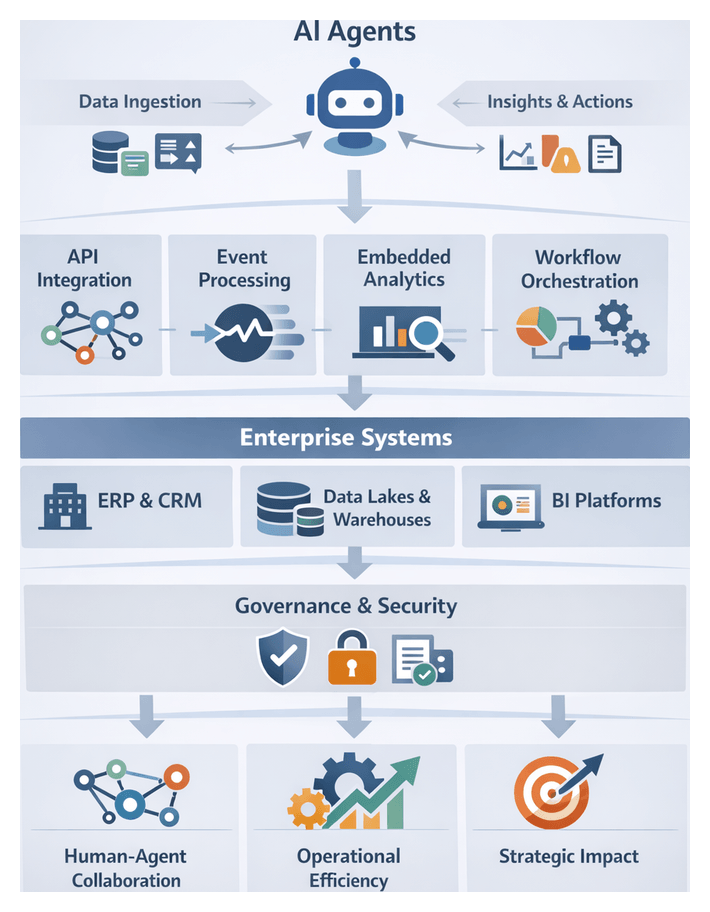
Contextualizing AI Agents within Enterprise Architectures
Enterprises today grapple with a proliferation of data sources—real-time event streams, click-stream logs, social media feeds, sensor networks and unstructured content such as documents and images—and demand near-immediate insights. Autonomous AI agents have emerged as strategic enablers that ingest, interpret and act on this data across diverse platforms. Far from isolated utilities, these agents integrate with transactional systems (ERP, CRM), data lakes and warehouses, business intelligence solutions and orchestration frameworks, augmenting legacy architectures without compromising established processes or governance.
Successful integration hinges on well-defined patterns that support bidirectional communication, real-time responsiveness and embedded analytics. Common architectural approaches include:
- API-Driven Integration: Agents interface via RESTful or gRPC services to consume and expose functionality from microservices, data platforms and transactional systems.
- Event-Driven Architecture: Subscribing to message queues or streaming platforms such as Apache Kafka enables agents to react instantly to data changes.
- Embedded Analytics Extensions: Agents deploy as plugins within BI tools, delivering natural language querying, automated insight generation and model explanations directly in the user interface.
- Orchestration and Workflow Embedding: Integrated with workflow engines, agents coordinate pipelines—data ingestion, model retraining, reporting and alerting—ensuring end-to-end automation.
- Hybrid Data Pipelines: Combining batch and streaming processes, agents apply self-healing data preparation techniques in ingestion phases and deliver results to downstream applications on demand.
To anchor agents securely and resiliently within enterprise workflows, organizations must address foundational requirements. Role-based access controls, encryption standards and identity management safeguard data privacy and compliance. Metadata management systems track agent activities, model lineage and data transformations for auditability. Containerization and orchestration platforms such as Kubernetes support auto-scaling, high availability and disaster recovery protocols, while monitoring frameworks alert teams to data drift, performance anomalies and infrastructure issues.
Equally important is stakeholder alignment. Cross-functional governance councils, comprising data engineers, data scientists, IT operations, compliance officers and business analysts, define success metrics, delineate responsibilities and oversee change management. Training and enablement programs build confidence in agent outputs, while transparent communication of capabilities, limitations and fail-safe mechanisms fosters trust across the enterprise.
When seamlessly embedded, AI agents drive strategic impact: reducing manual overhead, accelerating time to insight, enhancing risk management through real-time anomaly detection and automating narrative report generation for improved decision transparency. Agents also serve as sentinels for regulatory compliance by continuously verifying data handling against evolving standards. To measure these benefits, organizations monitor throughput and latency, model accuracy, user feedback, revenue uplift, cost savings and adoption rates, ensuring alignment with overarching business objectives.
Collaborative Paradigms in Human-Agent Interaction
As AI agents evolve from passive tools to active partners, collaboration models shift from command-and-control to symbiotic frameworks. Analysts no longer simply query rigid systems; instead, agents suggest hypotheses, flag anomalies and initiate explorations. Two interpretive models guide these partnerships: a tiered hierarchy—advisory (agent as consultant), delegated (junior analyst), autonomous (lead analyst under human supervision)—and a shared cognition lens, in which humans and agents develop synchronized mental models over time.
Trust and transparency are paramount. Multi-layered frameworks combine model interpretability, audit logs and user-centric explanations. Platforms such as IBM Watson Studio embed visual traceability tools, while solutions like DataRobot surface global performance metrics. Local explanation tools—Shapley value visualizations and LIME-style breakdowns—and secure audit trails for agent actions reinforce confidence in automated insights.
Human roles adapt to complement agent strengths. Vendors such as Dataiku and H2O.ai Driverless AI emphasize upskilling in bias detection, ethical decision-making and AI orchestration. Analysts transition from data preparation to strategic interpretation, storytelling and governance, focusing on hypothesis refinement and contextualization of agent outputs.
Continuous feedback loops drive iterative refinement. Embedded annotation interfaces let users tag insights, correct false positives and prioritize variables. Quarterly performance reviews compare agent-generated recommendations with business outcomes, and adaptive retraining triggers enable agents to self-initiate refinement when drift or performance degradation is detected.
Measuring collaboration effectiveness involves metrics across ideation, exploration, validation and deployment. Platforms such as Tableau and Microsoft Power BI provide analytic templates that track:
- Efficiency Metrics: Time-to-insight reduction and eliminated iterations.
- Effectiveness Metrics: Prediction accuracy improvements and anomaly detection precision.
- User Experience Metrics: Adoption rates, Net Promoter Scores and qualitative feedback.
- Operational Impact Metrics: Revenue uplift, cost avoidance and risk reduction linked to agent recommendations.
Across industries, collaborative patterns differ. Financial services impose rigorous governance for auditability, insurance combines automated claims triage with adjuster review, manufacturing uses platforms such as SparkCognition to integrate predictive maintenance agents with shop-floor engineers, and healthcare teams co-author patient risk assessments using transparent evidence trails. To mitigate cognitive overload, adaptive throttling balances agent proactivity with user control, and robust explanation interfaces maintain trust despite occasional inconsistencies.
Organizational Transformation through Embedded Workflows
Embedding AI agents reshapes organizational structures, cultures and decision rights. New roles emerge—AI process curator, analytics translator, agent governance lead—tasked with defining objectives, monitoring output quality and aligning agent behavior with strategic imperatives. In RACI frameworks, data stewards partner with domain experts to calibrate agent parameters, IT operations retain accountability for system reliability and compliance officers guide governance boundaries.
Decision-making hierarchies decentralize as frontline teams gain direct access to agent recommendations. Adaptive structures that embrace networked decision models realize the greatest agility. Tiered governance ensures that routine operational decisions proceed autonomously while strategic, high-impact choices follow escalation paths involving senior leadership.
Cross-functional collaboration dissolves silos. Boundary-spanning roles such as analytics product managers and business data liaisons, supported by shared platforms—data catalogs, governance playbooks and performance dashboards—enable synchronized workflows. Regular joint workshops and insight sprints foster mutual understanding of agent capabilities and limitations, integrating human and non-human actors into cohesive networks.
Balancing autonomy with control addresses the principal-agent challenge. Formal rules define permissible data channels and compliance checkpoints, while performance metrics—accuracy, timeliness and business impact—ensure quality. Cultural norms around transparency encourage audit trail reviews and constructive challenges to agent outputs, reinforcing accountability.
Strategic alignment through benefits realization frameworks ties agent embedding to clear use cases—accelerated decision cycles, forecast accuracy improvements and personalized customer engagement. Value realization roadmaps outline metrics, milestones and review cadences. Iterative governance, mirroring agile portfolio management, enables continuous recalibration of objectives and resource allocation.
Developing a learning organization culture is essential. Leadership models trust in agent outputs and encourages experimentation. Training shifts from tool mechanics to scenario-based workshops, emphasizing strategic interpretation of agent insights. Communities of practice and peer forums reinforce shared language around agent engagement and best practices.
Scaling embedded agents requires reexamining resource allocation. Portfolio management frameworks balance centralized Centers of Excellence, which incubate agent capabilities, with federated teams that own implementation. Stage-gate funding models prioritize high-value initiatives, and ongoing operational budgets replace one-time project expenditures to sustain continuous investment in modular agent capabilities.
Adoption Challenges and Strategic Considerations
Embedding autonomous agents into established workflows presents cultural and organizational hurdles beyond technical integration. Case studies highlight key insights:
- Alignment with Enterprise Architecture: Seamless integration with existing data platforms, BI tools and security policies accelerates value realization.
- Trust Calibration through Transparency: Explainability features and clear decision paths foster user confidence.
- Iterative Collaboration Models: Phased roll-outs beginning with low-risk tasks build credibility and enable progressive expansion of agent responsibilities.
- Skill Complementarity and Role Evolution: Redefining roles and providing targeted reskilling programs smooths transitions.
- Governance as Ongoing Discipline: Early establishment of data quality standards, ethical guardrails and access controls supports scalable adoption.
Strategic considerations guide executive teams through cultural, structural and leadership challenges:
- Cultural Readiness and Change Management
- Executive Sponsorship: Visible leadership commitment mobilizes resources and risk tolerance.
- Communication Strategy: Regular updates, success stories and open forums demystify agent capabilities.
- Champions and Evangelists: Early adopters advocate for agents within analytics and business units.
- Governance and Ethical Oversight
- Policy Frameworks: Define permissible use cases, data access privileges and escalation protocols.
- Ethical Committees: Cross-functional bodies review agent behaviors, bias reports and outcome audits.
- Transparency Requirements: Mandate rationale or confidence scores for agent recommendations.
- Data Security and Privacy
- Access Controls: Role-based management ensures agents adhere to privacy classifications.
- Anonymization Standards: De-identification safeguards align with regulations such as GDPR and CCPA.
- Vendor Due Diligence: Security certifications and contracts address data residency, encryption and incident response.
- Scalability and Technical Debt
- Modular Architectures: Loosely coupled integrations reduce maintenance overhead.
- Versioning and Rollbacks: Mechanisms to revert agent models mitigate unintended regressions.
- Monitoring and Alerting: Automated health checks and performance dashboards enable proactive maintenance.
- Cross-Functional Collaboration and Skills
- Interdisciplinary Teams: Domain experts, data scientists and process owners share ownership of solutions.
- Upskilling Programs: AI literacy, model interpretation and governance training accelerate adoption.
- Feedback Loops: Structured channels for users to flag agent behavior and propose enhancements.
- Measuring Impact and ROI
- Clear Success Metrics: Time saved, error reduction and revenue uplift anchor agent value in business terms.
- Baseline Comparisons: A/B testing quantifies incremental benefits against traditional processes.
- Continuous Value Tracking: Dashboards correlate agent recommendations with downstream outcomes.
Organizations must also monitor limitations and risks: overreliance on automation, bias propagation, explainability gaps, infrastructure constraints, regulatory uncertainty and change fatigue. To navigate these challenges, leaders pursue actionable pathways:
- Prioritize High-Value, Low-Risk Use Cases: Early wins build credibility and unlock funding for expansion.
- Stage Adoption with Phased Pilots: Controlled environments refine governance, interfaces and collaboration models before scaling.
- Embed Governance Early and Iteratively: Treat frameworks as living artifacts that evolve with agent maturity.
- Foster a Collaborative AI Culture: Emphasize augmentation, co-creation and shared ownership of agent outcomes.
- Maintain Continuous Monitoring and Feedback: Capture quantitative metrics and qualitative user insights to guide enhancements.
- Align Metrics to Strategic Objectives: Tie success indicators directly to organizational goals such as customer experience, time to market and operational efficiency.
By integrating robust architectures, fostering symbiotic human-agent partnerships, realigning organizational structures and addressing adoption challenges with strategic foresight, enterprises can harness autonomous AI agents to deliver sustainable, high-impact analytical intelligence and maintain competitive advantage in a data-centric world.
Chapter 8: Monitoring, Evaluation, and Continuous Learning
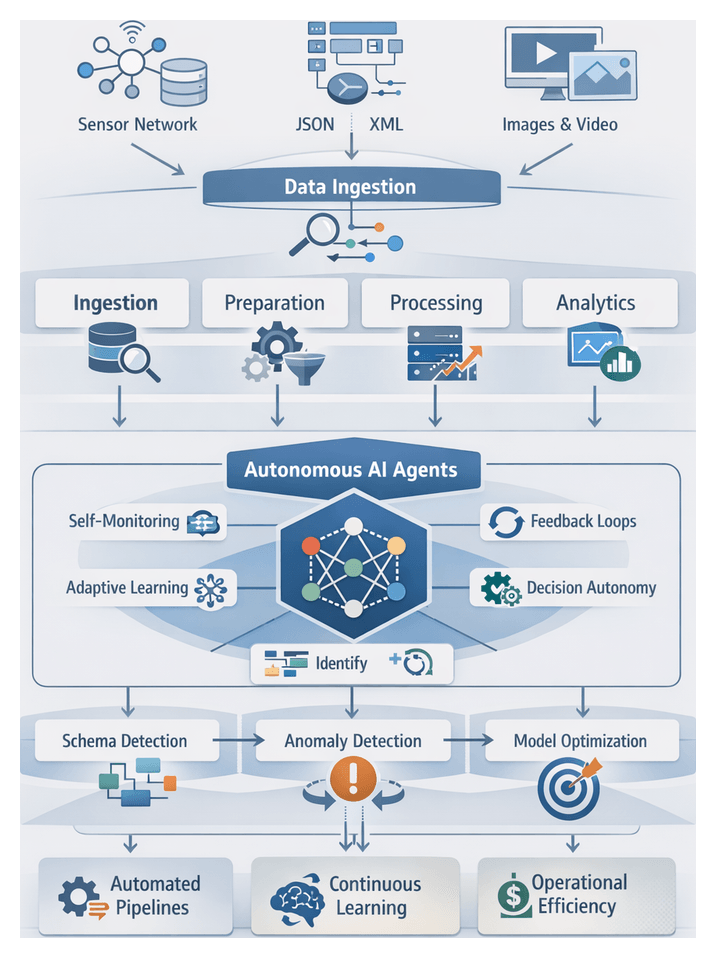
Data Autonomy: Foundations and Evolution
Organizations today grapple with an explosion of data volume, variety, and velocity. Sensor networks, digital interactions, nested JSON, images and video streams demand adaptive pipelines capable of detecting schema changes, resolving inconsistencies and enriching datasets without constant human oversight. Traditional extract-transform-load workflows and static ELT configurations strain under these pressures, leading to manual debugging and high operational costs.
Data autonomy represents the next generation of analytics capabilities, embedding intelligence into every stage of the data lifecycle. Autonomous AI agents assess data quality, detect anomalies, propose schema mappings and generate optimized query plans without explicit human instruction. Platforms such as Fivetran enable adaptive ingestion, while DataRobot automates model deployment and monitoring.
Key attributes of autonomous agents include:
- Self-Monitoring: Continuous evaluation of pipeline health, latency and data validity.
- Adaptive Learning: Reinforcement learning loops refine transformation recipes and resource allocation.
- Decision Autonomy: Agents initiate remediation—schema updates or data purging—based on thresholds and learned policies.
- Collaborative Interfaces: Natural language or API-driven interactions allow analysts to guide priorities without code.
Data autonomy spans four dimensions:
- Ingestion Autonomy: Automated discovery of new sources, dynamic schema detection and lineage tracking.
- Preparation Autonomy: Intelligent cleansing, normalization and enrichment guided by business rules.
- Processing Autonomy: Orchestration of compute resources and query optimization driven by workload patterns.
- Analytical Autonomy: Self-directed exploratory analysis, model selection and adaptive visualizations.
Embracing data autonomy accelerates time to insight through automated pipelines, enhances operational resilience with self-healing workflows, and reduces total cost by optimizing resource usage. It democratizes analytics by empowering nontechnical stakeholders with conversational interfaces and guided dashboards, while continuous learning from each iteration delivers progressively more accurate insights.
Feedback Loops and Continuous Learning
Feedback loops form the core of autonomous analytics, enabling agents to adapt to shifting data distributions and evolving business objectives. In closed-loop systems, agents monitor outputs such as prediction accuracy and latency, ingest performance signals and refine parameters in near real time. Organizations balance open-loop logging for periodic review against closed-loop self-correction based on risk tolerance and governance maturity.
Drift Detection and Retraining Triggers
Industry practice distinguishes three drift types:
- Data Drift: Changes in input feature distributions detected via statistical tests like Kolmogorov–Smirnov or by tracking population stability index.
- Concept Drift: Shifts in relationships between inputs and outputs, monitored by sliding-window error rate analysis.
- Label Drift: Variations in target value distributions validated through sampling protocols aligned with business patterns.
Retraining triggers typically follow threshold-based, scheduled or event-driven models:
- Threshold-Based: Automatic cues such as a predefined degradation in F1 score.
- Scheduled: Regular cadences—monthly or quarterly—to address predictable seasonality and comply with audits.
- Event-Driven: External events—product launches or regulatory shifts—overlay business calendars to initiate retraining.
Hybrid approaches combine threshold sensitivity with scheduled backups, ensuring responsiveness while avoiding unnecessary compute cycles. Techniques such as adaptive thresholds, retraining windows requiring consecutive breaches and shadow testing validate model improvements before full deployment.
Continuous Learning Paradigms
Moving beyond periodic retraining, continuous learning systems ingest streaming data to refine predictive and prescriptive outputs on an ongoing basis. This perpetual adaptation underpins operational agility by detecting micro-seasonal demand shifts, competitor movements or emerging risk signals in near real time.
In retail, autonomous pricing agents adjust discounts hourly based on live transactions, inventory levels and social sentiment. Financial institutions refine credit scoring with alternative data streams such as digital wallet transactions, reducing risk by up to 15 percent while expanding access to new segments. These capabilities create a virtuous cycle: rapid insights drive actions, generating fresh data to further sharpen models.
Operational Agility through Autonomous Agents
Continuous learning and adaptive decision cycles redefine classical frameworks like PDCA and the OODA loop, enabling machine-speed iteration. Autonomous agents observe data streams, orient around business objectives, decide on model updates and act without manual intervention.
- Automated performance monitors flag deviations from expected outcomes.
- Threshold-based triggers initiate parameter adjustments.
- Reinforcement learning components evaluate past actions to guide future decisions.
Use cases illustrate measurable gains:
- An international courier service reduced delivery delays by 12 percent and fuel consumption by 9 percent using an AI agent that optimized routing based on traffic, package volume and driver availability.
- Insurance firms deploy early-warning systems that detect anomalies in sensor telemetry or network traffic, enabling proactive mitigation of mechanical faults or cyber threats.
Organizational Culture and Collaboration
Success requires a cultural shift toward experimentation, data literacy and cross-disciplinary collaboration. Core capabilities include data literacy, shared ownership of AI outcomes and governance awareness. Fusion teams—combining data scientists, engineers and domain experts—use platforms like Amazon SageMaker and Google Cloud AI Platform to prototype continuous learning workflows and scale best practices.
Integration Archetypes
- Embedded Agent Workflows: Real-time insights surfaced directly in business applications, for example churn-risk scores in a support portal.
- API-Driven Delivery: Central learning engines expose APIs for decision-time queries, enabling reuse across units.
- Event-Based Orchestration: Agents subscribe to event streams in microservices architectures for high-velocity environments.
Mature organizations adopt hybrid integration models, layered by monitoring dashboards that track data flows, model health and user interactions to ensure autonomous learning enhances collaboration rather than creating silos.
Metrics for Agility
Beyond accuracy and latency, agility metrics include:
- Adaptation Velocity: Speed at which drift is detected and retraining initiated.
- Decision Throughput: Autonomous decisions executed per unit time.
- Outcome Consistency: Variance in KPIs before and after updates.
- Resource Efficiency: Compute and human resource utilization relative to value delivered.
- Governance Compliance: Proportion of updates meeting audit requirements.
Enterprises such as online marketplaces track these indicators on real-time dashboards, correlating them with business KPIs like revenue growth, customer satisfaction and cost reduction.
Challenges and Strategic Considerations
- Data Governance and Privacy: Real-time streams must comply with GDPR, CCPA through anonymization and lineage tracking.
- Model Stability vs Adaptability: Hybrid retraining with periodic human validation mitigates overfitting.
- Infrastructure Complexity: Scalable architectures for streaming ingestion, distributed training and inference must balance cloud and on-premises trade-offs.
- Change Management: Clear communication, training and transparency dashboards build trust and drive adoption.
- Auditability and Explainability: Traceable records of model evolution and rationale are essential in regulated sectors.
Monitoring, Governance, and ROI
Effective oversight hinges on real-time dashboards that surface drift indicators, accuracy metrics and system health. These nerve-center views enable cross-functional teams to detect anomalies early and intervene before failures escalate. Automated feedback loops initiate retraining when thresholds are breached, while structured human reviews validate high-risk updates.
Governance Frameworks
- Enterprise Data Governance: Committees guided by DAMA principles integrate AI agent oversight into data stewardship and policy enforcement.
- MLOps Governance: DevOps-inspired pipelines, supported by DataRobot and MLflow, automate documentation, version control and audit logging.
- Responsible AI: Ethical guidelines on fairness, transparency and explainability embedded into evaluation via tools like IBM Watson OpenScale.
Accountability rests with senior leaders, data stewards and business owners. Cross-disciplinary governance boards conduct regular reviews to align agent behavior with organizational values and regulatory requirements.
ROI Measurement
- Direct Cost Savings: Analyst hours and maintenance overhead reductions quantified into salary and opportunity cost savings.
- Revenue Impact: Incremental gains from faster insights or more accurate forecasts, for example linking Amazon Forecast improvements to optimized inventory and reduced stockouts.
- Efficiency Gains: Cycle time reductions for analytics projects, such as cutting model deployment from eight weeks to two.
- Intangible Benefits: Decision confidence and stakeholder satisfaction captured through surveys and executive feedback.
Unified ROI dashboards built with Tableau or Microsoft Power BI consolidate financial systems, project management and performance logs into a single view of value realization.
Key Considerations and Future Trends
- Attribution Challenges: Controlled pilots and rigorous experimental designs isolate agent impact from external factors.
- Governance Overhead: Lean structures prioritize high-risk assets to balance oversight and agility.
- Privacy Risks: Continuous processes must integrate privacy impact assessments and consent management.
- Technical Debt: Proactive tracking and pruning of underperforming agents prevent infrastructure sprawl.
- Real-Time Value Tracking: Performance streams directly tied to financial ledgers.
- Automated Ethics Checks: Embedded fairness validators flag compliance breaches before production.
- Outcome-Driven SLAs: Guarantees shift from uptime to accuracy thresholds and business KPI targets.
- Collaborative Governance Ecosystems: Distributed ledger and transparency APIs enable multi-party oversight.
- Adaptive ROI Frameworks: Machine learning models predict long-term value based on performance trends and market indicators.
By integrating robust monitoring, adaptive governance and comprehensive ROI metrics, organizations ensure that autonomous analytics agents deliver measurable, sustainable value while maintaining trust, compliance and strategic alignment.
Chapter 9: Ethical, Governance, and Compliance Considerations
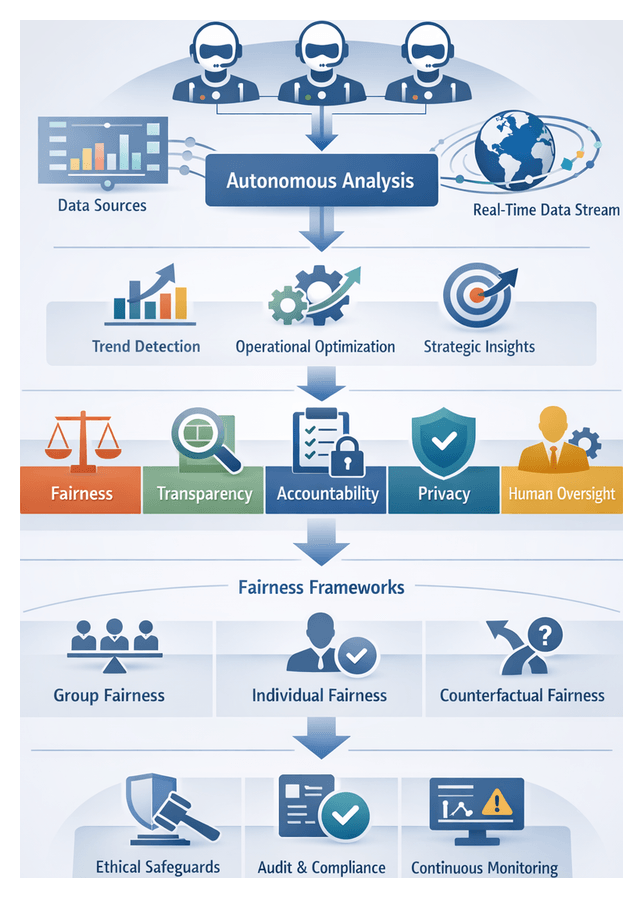
Emergence of Autonomous Analysis in Modern Data Environments
Autonomous AI agents have evolved from experimental prototypes into essential components of advanced analytics platforms. Leveraging machine learning models, natural language processing and automated decision logic, these agents ingest, process and interpret vast structured and unstructured datasets with minimal human intervention. Organizations deploy autonomous agents to detect market trends, optimize operations and accelerate strategic insights. By automating routine analytical tasks, data teams can devote their expertise to complex problem-solving and innovation.
While real-time analysis of global data streams unlocks new efficiencies, it also magnifies risks. Unchecked agent behavior can propagate biased patterns at scale, infringe privacy norms and expose organizations to regulatory penalties or reputational harm. Establishing clear ethical and legal guardrails is therefore vital to ensure that autonomy amplifies opportunity without eroding stakeholder trust.
Ethical Imperative and Core Principles
The ethical imperative for autonomous agents arises from the intersection of exploding data volumes, increased algorithmic complexity and heightened societal expectations for transparency and fairness. To align agent behavior with organizational values and legal requirements, five core principles must guide design and operation:
- Fairness and Non-Discrimination: Preventing systematic disadvantages to individuals or groups by defining context-appropriate fairness metrics and continuously monitoring for bias drift.
- Transparency and Explainability: Ensuring stakeholder understanding of agent decisions through interpretable reports, feature importance analyses and governance dashboards.
- Accountability and Auditability: Maintaining immutable decision logs, version-controlled model registries and clear ownership structures to trace every analytical outcome.
- Privacy and Data Protection: Embedding privacy-by-design techniques—such as differential privacy, federated learning and robust encryption—while adhering to jurisdictional laws like GDPR, CCPA and HIPAA.
- Human Oversight and Control: Implementing risk-based human-in-the-loop frameworks that route high-impact decisions to domain experts and capture feedback for continuous improvement.
Bias Mitigation and Fairness Strategies
Ensuring fairness begins with selecting definitions that reflect legal mandates and stakeholder values. Three principal frameworks guide autonomous agent design:
- Group Fairness: Statistical parity across demographic segments, aligning with regulations such as the EU AI Act.
- Individual Fairness: Consistent treatment of similar individuals by defining distance metrics in feature spaces.
- Counterfactual Fairness: Causal analysis to ensure decisions remain unchanged under hypothetical edits to protected attributes.
Bias can enter at multiple stages of the agent lifecycle. Key detection and mitigation approaches include:
- Data Auditing: Profiling input distributions and documenting dataset characteristics via the Datasheets for Datasets paradigm.
- Model Testing: Conducting disaggregated performance assessments and stress tests for subpopulations.
- Fairness Metrics: Monitoring measures such as demographic parity difference and disparate impact ratio using tools like Microsoft Fairlearn.
Integrating fairness evaluation pipelines with automated alerts ensures continuous detection of bias drift and timely policy adjustments.
Transparency and Explainability Mechanisms
Opaque decision logic undermines confidence and complicates compliance. Transparency frameworks address both local and global interpretability:
- Local Explainability: Techniques such as LIME and SHAP reveal feature contributions for individual predictions.
- Global Interpretability: Surrogate models, partial dependence plots and standardized model cards summarize overall agent behavior, scope and limitations.
Governance dashboards consolidate real-time analytics on performance, fairness and drift metrics, enabling proactive intervention when ethical boundaries approach defined thresholds.
Accountability, Auditability, and Compliance by Design
Embedding accountability into agent architectures requires robust documentation and traceability. Essential practices include:
- Immutable audit trails of data versions, model parameters and decision timestamps.
- Cross-functional model governance boards with legal, compliance, data science and business representation.
- Data Protection Impact Assessments (DPIAs) and Ethics Checklists that translate high-level principles into concrete technical controls.
Privacy-by-design further mandates minimal data collection, consent management, pseudonymization and role-based access controls. Differential privacy adds calibrated noise to queries, while federated learning enables decentralized training without centralizing sensitive information. Encryption safeguards data at rest and in transit, and data retention policies define secure archival and deletion protocols.
Regulatory and Legal Landscape
Autonomous agent deployment must comply with a complex regulatory environment:
- Privacy Regulations: GDPR, CCPA and HIPAA govern consent, purpose limitation, data minimization and breach notification.
- Industry-Specific Mandates: Financial services adhere to AML directives, MiFID II and the BSA. Healthcare organizations navigate FDA guidance for clinical decision support. Utilities comply with NERC reliability standards.
- Cross-Border Data Transfers: Chapter V of GDPR and emerging laws in Brazil, India and China require standard contractual clauses, binding corporate rules or data localization, influencing architecture and geofencing policies.
Proactive compliance by design engages legal and compliance teams early in agent development, codifying regulatory expectations into design checklists, control matrices and contractual terms for third-party components.
Governance Models and Organizational Structures
Effective governance integrates policy, process and oversight across the enterprise. Recommended structures include:
- Executive sponsorship and AI risk officers to champion ethical analytics.
- Cross-functional ethics committees or model governance councils that review high-risk use cases, define escalation pathways and authorize agent updates.
- Federated governance that centralizes core policies while empowering business units to implement localized controls within defined guardrails.
Balancing Tradeoffs and Operational Constraints
Responsible AI governance requires strategic trade-offs:
- Performance vs. Fairness: Calibration of mitigation algorithms may impact accuracy, demanding executive alignment on acceptable thresholds.
- Transparency vs. Intellectual Property: Tiered transparency models grant auditors deep access while offering end users concise explanations.
- Data Retention vs. Deletion: Regulatory deletion mandates conflict with needs for historical data in model refinement.
- Centralized vs. Decentralized Governance: Centralization yields consistency but may slow innovation; federated models balance agility with standardization.
Continuous Monitoring and Adaptation
Given evolving data environments and regulatory landscapes, governance must be dynamic. Continuous assurance frameworks employ automated monitoring to detect policy violations, unusual data access patterns or drift in agent outputs. Compliance teams assess alerts through a risk-based lens, triggering investigations, model recalibrations or policy updates. Periodic internal and third-party audits validate adherence and inform training, governance and technical enhancements.
Key Considerations for Practitioners
- Align governance scope with organizational risk appetite and strategic objectives.
- Define measurable metrics for fairness, transparency and performance, and monitor them continuously.
- Adopt tiered transparency to safeguard intellectual property while ensuring accountability.
- Implement risk-based compliance, prioritizing oversight for high-impact agent applications.
- Embed ethical boundaries into technical guardrails using constraint solvers or rule engines.
- Institutionalize human oversight through structured review processes and feedback loops.
- Balance centralized policy setting with decentralized execution to maintain innovation velocity.
- Invest in integrated tools for audit logging, experiment tracking and drift detection, such as IBM Watson OpenScale, Google What-If Tool and DataRobot.
- Maintain modular governance frameworks to adapt rapidly to new regulatory requirements.
Chapter 10: Future Directions and Emerging Trends
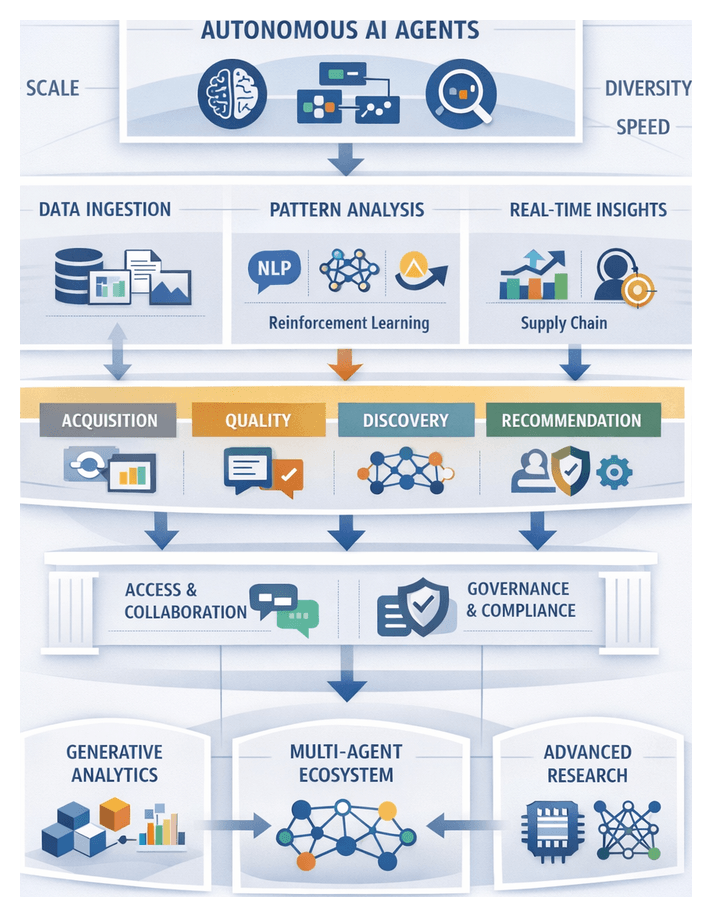
Data Autonomy in the Modern Analytics Ecosystem
Data autonomy empowers systems to manage, analyze, and derive insights with minimal human intervention, transforming raw information into strategic assets. As data volumes grow from terabytes to petabytes, organizations face three interrelated challenges: scale, diversity, and speed. Autonomous AI agents address these by dynamically allocating compute resources, applying natural language processing, pattern recognition, and reinforcement learning to unify structured tables, unstructured text, images, and streaming events.
Platforms such as IBM Watson and DataRobot illustrate how AI-driven services automate data ingestion, cleansing, feature extraction, and model refinement. In real-time environments—fraud detection, supply chain optimization, personalized marketing—autonomous agents ingest live feeds, detect anomalies, and update predictions on the fly.
Modular Agent Architectures
Data autonomy shifts monolithic analytics into a mesh of specialized agents: data acquisition, quality assurance, pattern discovery, and insight recommendation. Agents communicate through standardized interfaces, share metadata, and negotiate tasks, enabling elastic scaling and domain-specific customization without reengineering entire pipelines.
Democratizing Analytics
Conversational interfaces and guided exploration tools empower citizen analysts to collaborate with AI agents. Natural language queries, visual prompts, and interactive feedback loops translate high-level questions into optimized queries and contextual explanations, broadening access to analytical rigor.
Governance and Cultural Readiness
Effective autonomy requires governance frameworks that embed role-based controls, audit trails, and explainability mechanisms. Cultural adoption hinges on trust calibration and upskilling: as agents assume routine tasks, human experts focus on strategic interpretation, creative problem solving, and oversight of ethical and regulatory compliance.
Multi-Agent Analytical Ecosystems
Multi-agent ecosystems consist of autonomous entities collaborating to solve complex analytical tasks. Drawing on multi-agent systems theory, these networks of specialized agents—data ingestion, anomaly detection, predictive modeling, visualization—exhibit emergent intelligence, where collective reasoning outperforms any individual agent.
Core Dimensions and Architectural Patterns
- Autonomy: Agents make decisions without human prompts.
- Social Ability: Agents exchange information via protocols like FIPA and event buses.
- Reactivity: Agents respond to environmental changes.
- Proactivity: Agents pursue goal-driven behaviors.
Architectural patterns include orchestration hubs for centralized coordination, peer-to-peer clusters for decentralized collaboration, and hierarchical tiers with supervisory agents guiding subordinate tasks. Each pattern balances governance, latency, and resilience according to organizational priorities.
Performance, Governance, and Standards
- Performance Metrics: Throughput, latency, fault tolerance, adaptive capacity.
- Governance Models: Human stewards assign agent responsibilities, maintain decision-rights matrices, and track compliance registers for data lineage and explainability.
- Standards and Interoperability: IEEE work on autonomous systems and Open Mobile Alliance protocols promote vendor-agnostic agent integration.
Industry Offerings and Cautionary Guidelines
Vendors offer modular services that can be composed into multi-agent workflows: IBM Watson Discovery and Watson Studio, DataRobot, H2O Driverless AI, Microsoft Azure AI, and Google Cloud AI. Yet unchecked agent proliferation can introduce integration sprawl, data inconsistencies, and coordination lock-in. Organizations adopt composability guidelines, limiting agent count and defining canonical interfaces to preserve manageability.
Industry Implications of Generative Analytics
Generative analytics extends predictive models by synthesizing new data points, scenarios, and narratives. This creative capability reshapes value chains, decision processes, and ecosystem relationships across sectors.
Reshaping Sector Dynamics
- R&D Acceleration: Generative models propose novel compounds in pharmaceuticals and materials science, shortening discovery cycles.
- Supply Chain Resilience: Synthetic demand signals and scenario projections stress-test logistics networks without reliance on historical data alone.
- Customer Personalization: Real-time generative algorithms create individualized marketing content, virtual product trials, and adaptive recommendations.
- Financial Modeling: Synthetic stress-test scenarios and macroeconomic simulations enhance risk management and regulatory compliance.
Transforming Business Functions
- Marketing and Content Creation: Autonomous copywriting, dynamic ad generation, and multimedia asset production.
- Product Development: Generative design tools iterate on prototypes, optimizing form and performance.
- Customer Service: Conversational agents draft bespoke responses and escalate novel issues.
- Competitive Intelligence: Generative summarization distills reports, filings, and news feeds into strategic insights.
Strategic Decision Processes
- Value Driver Trees with Synthetic Variants: Generating alternative performance trajectories under varied conditions.
- Augmented Monte Carlo Simulations: Incorporating generated distributions that anticipate unseen events.
- Adaptive Strategy Maps: Visualizing dynamic linkages among objectives, initiatives, and metrics.
Ecosystem and Governance
Partnership models include data consortiums for co-training domain-specific models, platform integrations embedding generative services within analytics suites, and consulting alliances delivering tailored solutions. Governance challenges—auditability of synthetic data, bias amplification risks, intellectual property rights, and privacy compliance—require lineage tracking, bias mitigation frameworks, and human oversight checkpoints.
Workforce Evolution and Adoption Frameworks
New roles emerge: analytics intelligence designers, model ethicists, cross-functional AI translators, and continuous learning facilitators. Adoption frameworks—capability maturity models, risk-return matrices, and value chain analyses—guide investments and benchmark generative readiness against strategic objectives.
Anticipating Research Frontiers and Innovations
Future research is charting advances that will enhance agent autonomy, collaboration, reasoning, and governance.
Autonomy Protocols and Meta-Reasoning
Agents are evolving self-reflective architectures with layered decision hierarchies: task-level analytics, meta-agents monitoring performance, and governance agents enforcing ethical guardrails. Validation frameworks must ensure alignment and stability as agents dynamically adjust goals and workflows.
Neurosymbolic and Hybrid Reasoning
Integrating symbolic AI with neural networks—pursued by initiatives at the Allen Institute for AI—combines logic-driven inference with pattern recognition. These hybrid models promise transparent decision paths and rule-based constraint enforcement, though they add computational and developmental complexity.
Quantum-Enhanced Architectures
Quantum co-processors under investigation by IBM Research and Google Quantum AI could accelerate combinatorial optimization and sampling tasks. Hybrid quantum-classical agents may offload subroutines like portfolio optimization, albeit constrained by hardware maturity, integration challenges, and error rates.
Scalable Multi-Agent Collaboration
Emergent “agent economies” leverage game theory, incentive mechanisms, and blockchain-inspired ledgers to record interactions and ensure auditability. Scaling such ecosystems demands robust consensus protocols, conflict resolution, and simulation environments to verify coherent collective behavior.
Adaptive Contextual Reasoning
Dynamic memory networks and differentiable neural computers seek to endow agents with episodic recall and meta-learning, enabling personalized analytical dialogues. Balancing knowledge retention with plasticity, while safeguarding privacy through anonymization and retention policies, remains a central challenge.
Ethical AI and Embedded Governance
“Ethics by design” frameworks embed fairness monitors, dynamic consent mechanisms, and policy engines within agent architectures. This proactive governance aligns with emerging regulations such as the EU AI Act, though codifying ethical norms across contexts requires adaptable standards and continual oversight.
Human-AI Symbiosis and Lifelong Learning
Adjustable autonomy paradigms calibrate agent self-direction based on user expertise and risk. Explainable behaviors, interactive visualizations, and mixed-initiative workflows aim to optimize trust calibration and skill transfer. Concurrently, transfer learning and meta-learning algorithms enable agents to generalize across domains, reducing ramp-up times but demanding safeguards against bias propagation and performance drift.
Key Considerations and Limitations
- Balancing governance complexity with innovation agility.
- Managing compute resource demands and sustainability impacts.
- Ensuring interpretability to build trust and meet regulatory standards.
- Navigating global regulatory heterogeneity and data sovereignty rules.
- Mitigating bias in self-evolving systems through ongoing audits.
- Protecting privacy in contextual memory and lifelong learning architectures.
By synthesizing advances in autonomy protocols, hybrid reasoning, quantum enhancements, and collaborative ecosystems, organizations can chart strategic roadmaps for responsible, scalable, and impactful autonomous analytics.
Conclusion
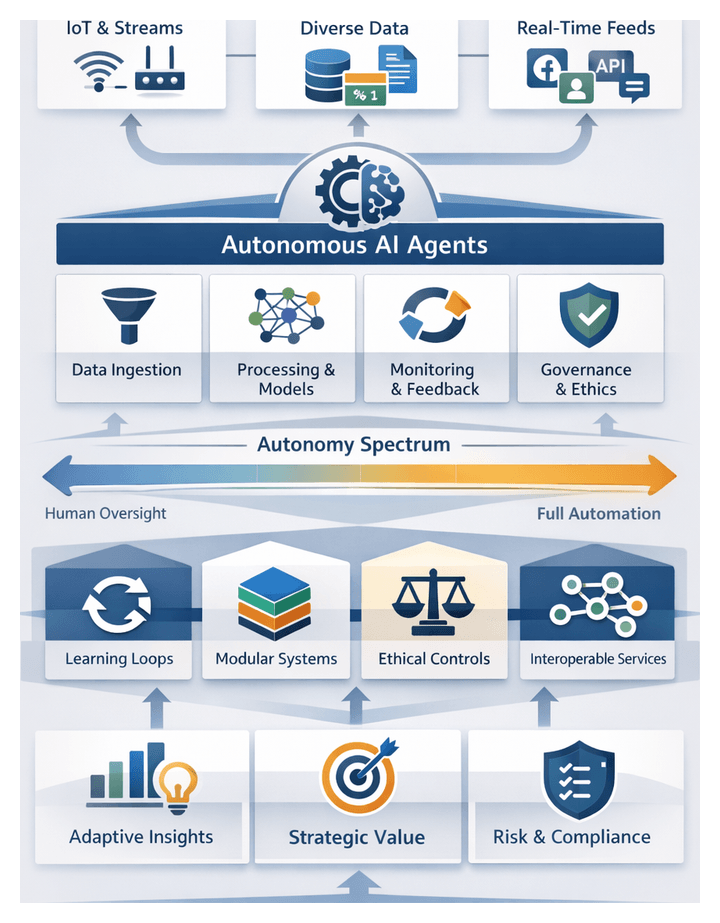
Data Autonomy as a Strategic Imperative
Organizations today operate in an environment defined by explosive volumes of structured and unstructured information, demanding analytics that move beyond manual pipelines and static dashboards. Data autonomy empowers enterprises to manage ingestion, preparation, exploration, and reporting with minimal human intervention. Autonomous AI agents sense shifts in data distributions, trigger preprocessing steps, select algorithms, adjust model parameters, and recommend visualizations, all while monitoring performance against defined success criteria. This shift frees data engineers and analysts to focus on strategy, interpretation, and governance oversight, and transforms raw data into continuous, adaptive business insights.
Key drivers of this transition include:
- Proliferation of diverse data sources—from IoT sensors and real-time event streams to social media feeds and third-party APIs.
- Accelerating demand for near-instantaneous insights as markets, customer behaviors, and operational contexts evolve rapidly.
- A global shortage of skilled analytics talent, necessitating automation of routine engineering and exploratory tasks.
- Advances in machine learning, natural language processing, and pattern-recognition algorithms that underpin self-governance.
Autonomous analytics emerges from the convergence of scale, complexity, and speed challenges. AI agents equipped with feedback loops continuously monitor data drift, detect anomalies, retrain models, and initiate remediation steps—augmenting human judgment with machine-scale processing and ensuring alignment with evolving business needs.
Recurring Patterns and Frameworks in Autonomous Analytics
Across industry assessments and expert forums, several consistent themes shape effective autonomous analytics implementations. These patterns inform architectural decisions, governance structures, and change-management strategies.
Continuum of Oversight
Agent autonomy exists on a spectrum, from fully supervised workflows to self-healing pipelines. Practitioners align autonomy levels with contextual risk profiles, data sensitivity, and governance maturity, using an autonomy-accountability matrix to map tasks appropriate for full automation versus human-in-the-loop checkpoints.
Feedback Loop Centrality
Continuous learning cycles, reinforced by human review gates and hybrid feedback channels, sustain model relevance. Automated retraining triggers—based on performance degradation, statistical anomalies, or business events—ensure adaptive recalibration, while sandboxed experimentation tracks prospective model variants before production rollout.
Governance and Ethical Integration
Responsible Autonomy demands embedded fairness checks, privacy-first architectures, and immutable audit trails. From bias detection modules in data ingestion to explainability dashboards in model evaluation, governance becomes integral to design rather than a post hoc overlay.
Modular Interoperability and Composable Services
Agents built on open standards and interoperable components—language understanding, anomaly detection, optimization engines—are orchestrated by supervisory layers that negotiate priorities and ensure end-to-end coherence. API-first integration and microservices architectures enable discovery and orchestration of data services and model endpoints without custom scripting.
Synergistic Ecosystems
Holistic frameworks such as Continuous Intelligence and DataOps MLOps convergence unify discrete analytics phases into cohesive ecosystems. Shared metadata layers and automated lineage tracking align quality controls, while adaptive orchestration adjusts agent priorities in response to shifting objectives and real-time telemetry.
Strategic Implications for Data Practice
The deployment of autonomous AI agents elevates data management from a technical discipline to a core strategic function. Leaders must reframe data strategy, governance, organizational capabilities, and infrastructure to harness self-directed analysis effectively.
Reframing Data Strategy
- Value-Driven Architecture: Design data hubs—lakes, warehouses, and real-time pipelines—not just for storage but to feed reasoning engines that power autonomous agents.
- Outcome-Oriented Metrics: Define KPIs such as time to actionable insight and autonomy utilization rate to measure speed, relevance, and impact of AI-generated recommendations.
- Governed Experimentation: Embed hypothesis testing frameworks, allowing agents to propose and evaluate experiments within strategic guardrails to manage risk.
Data Governance in a Self-Directed Environment
- Dynamic Lineage Tracking: Record every agent decision step—data sources accessed, models invoked, thresholds applied—to ensure full auditability.
- Ethical Guardrails: Apply frameworks such as FATE (Fairness, Accountability, Transparency, Ethics) to codify constraints and bias-mitigation protocols.
- Regulatory Alignment: Maintain a modular policy repository that autonomous systems reference before executing operations, ensuring compliance with GDPR, CCPA, HIPAA, and other mandates.
Aligning Organizational Capabilities
- Cross-Functional Collaboration: Form multidisciplinary teams of data engineers, domain experts, ethicists, and decision-makers to co-own autonomous workflows.
- Skill Transformation: Evolve data analysts into supervisors of AI agents, focusing on strategic interpretation, hypothesis framing, and governance oversight.
- Centers of Excellence: Establish central bodies to curate best practices, standardize tools, assess maturity, and validate agent performance.
Infrastructure and Architectural Imperatives
- Data Mesh Principles: Distribute data ownership along domain lines with enforced interoperability standards, enabling autonomous agents to consume domain-owned data products.
- Cloud-Native Elasticity: Leverage serverless and containerized environments to scale compute dynamically, as exemplified by DataRobot and H2O.ai.
- API-First Integration: Expose data services and models as self-describing APIs to facilitate autonomous discovery and orchestration.
Measuring Value and Driving Continuous Improvement
- Outcome Mapping: Link agent activities to business metrics such as revenue uplift, cost reduction, and risk mitigation through causal value chains.
- Capability Maturity Models: Benchmark autonomy level, governance sophistication, and integration depth to guide investments and identify gaps.
- Feedback-Driven Loops: Collect qualitative ratings from business units on agent insights to refine training pipelines and governance policies.
Balancing Risk and Resilience
- Model Risk Management: Implement review committees for high-stakes recommendations, escalating when confidence thresholds are unmet.
- Resilience Planning: Design fail-safes that revert to predefined reporting processes and alert human operators during data outages or anomalies.
- Cybersecurity Integration: Embed access controls, encryption standards, and intrusion detection within autonomous workflows.
Forward-Looking Guidance for Practitioner Success
To forge sustainable advantage with AI agents, organizations must align capabilities, governance, and culture with strategic objectives, while anticipating constraints and maintaining ethical oversight.
Aligning Agent Strategies with Business Objectives
Establish clear KPIs tied to revenue impact, cost optimization, customer satisfaction, or risk mitigation. Map autonomous capabilities to specific outcomes—fraud reduction in financial services, inventory accuracy in retail—using both leading indicators (model confidence, latency) and lagging measures (cost savings, revenue uplift). Secure executive sponsorship and conduct periodic performance reviews to adapt agent behavior to evolving market conditions.
Anticipating Technical and Organizational Constraints
- Assess data maturity—quality, lineage, access control—and remediate silos before scaling autonomy.
- Invest in upskilling and establish centers of excellence to bridge talent gaps and codify best practices.
- Weigh vendor frameworks against customization needs, enforcing open APIs and containerized deployments to avoid lock-in.
Balancing Autonomy and Oversight
Adopt a human-in-the-loop paradigm for high-risk functions, using tools like IBM Watson Studio and Azure Synapse Analytics for audit trails, explainability dashboards, and role-based approvals. Convene governance councils to define tolerance thresholds for drift, bias, and performance degradation, performing regular post-deployment reviews.
Ensuring Ethical, Responsible, and Compliant Deployment
- Embed privacy-by-design and bias-mitigation throughout the agent lifecycle.
- Conduct periodic bias audits, counterfactual testing, and maintain comprehensive provenance logs.
- Integrate legal counsel early to map GDPR, CCPA, HIPAA, and industry-specific obligations to technical requirements.
Cultivating a Culture of Continuous Learning
Treat AI agent deployment as an ongoing journey. Monitor technical metrics (latency, error rates, feature-importance shifts) alongside business outcomes (conversion lift, cost savings). Leverage unified MLOps and AIOps platforms, foster communities of practice, and incentivize experimentation. Early failures reveal biases and architectural gaps that, once addressed, strengthen resilience and sustain competitive differentiation.
By striking the right balance between autonomy and oversight, innovation velocity and governance rigor, and short-term gains and long-term resilience, practitioners can unleash the transformative potential of AI agents while safeguarding trust, compliance, and strategic alignment.
Appendix
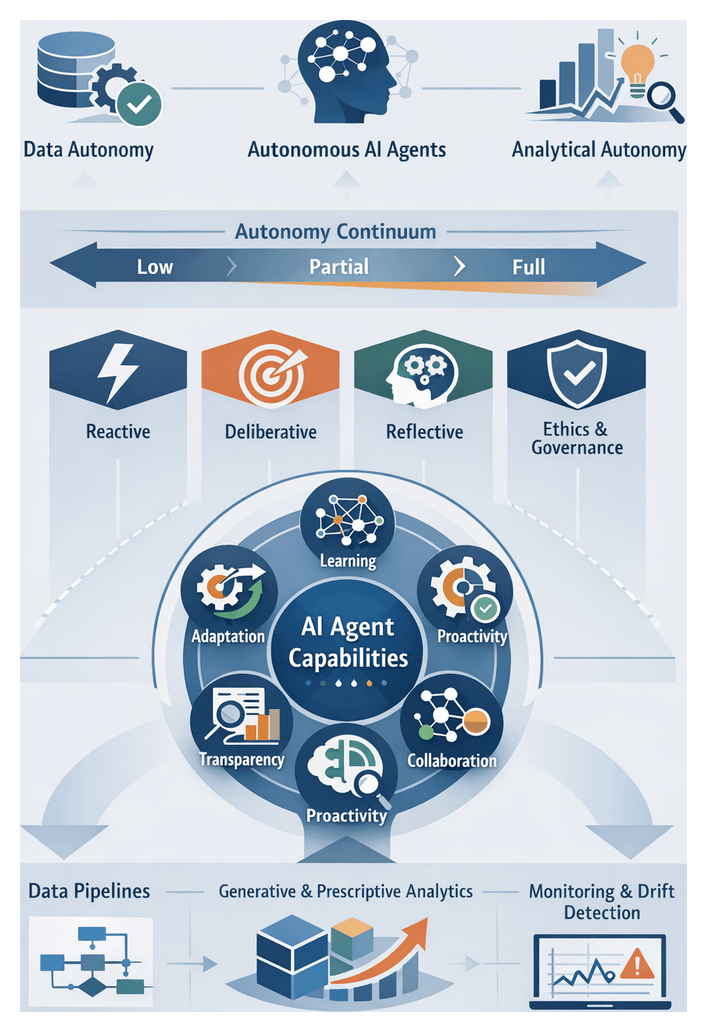
Key Definitions and Terminology
Data Autonomy
Data autonomy enables systems to manage end-to-end data processes—ingestion, cleansing, transformation and quality assurance—without manual intervention. Intelligent logic adapts to evolving sources, detects anomalies and enforces governance, shifting organizations from reactive maintenance to proactive, self-healing workflows.
Autonomous AI Agent
An autonomous AI agent is a software entity that executes analytical tasks under high-level goals. Leveraging machine learning, optimization techniques and natural language interfaces, it learns from outcomes, makes context-sensitive decisions and orchestrates data activities across the analytics lifecycle.
Analytical Autonomy
Analytical autonomy extends data autonomy into discovery: agents generate hypotheses, select models and interpret results iteratively. By simulating scientific inquiry, they expedite exploration of large datasets without human scripting.
Autonomy Continuum
The autonomy continuum classifies agent independence from low autonomy—where suggestions require human approval—to full autonomy—where agents manage pipelines end-to-end. Intermediate tiers include partial autonomy for routine tasks and conditional autonomy that seeks oversight in novel scenarios.
Core Attributes of AI Agents
- Autonomy: Executing tasks without episodic direction.
- Proactivity: Monitoring indicators and initiating actions preemptively.
- Adaptability: Adjusting behavior to new patterns and priorities.
- Transparency: Exposing decision pathways and audit logs.
- Collaboration: Engaging with humans and other agents via feedback loops.
Agent Architectures
- Reactive Agents: Event-driven workflows for real-time monitoring and alerting.
- Deliberative Agents: Goal models that sequence operations based on projected utility.
- Reflective Agents: Meta-reasoning layers that diagnose performance and revise strategies.
Self-Healing Pipelines and Continuous Learning
Self-healing pipelines detect, diagnose and remedy data issues autonomously using anomaly detection, root-cause analysis and corrective actuators. Continuous learning refines models via feedback loops, monitoring metrics like accuracy and drift to trigger retraining or review.
Generative and Prescriptive Analytics
Generative analytics employs AI models to produce synthetic data, scenario simulations and automated reports. Prescriptive analytics builds on predictive models to recommend optimal actions using optimization algorithms such as linear programming and metaheuristics.
Bias, Fairness and Transparency
Responsible autonomy requires bias mitigation, fairness evaluation and model explainability. Techniques like Shapley values and surrogate models, alongside statistical fairness tests, ensure decisions align with ethical standards and regulatory mandates.
Model Drift, MLOps and Observability
Model drift—data, concept or label changes—necessitates drift detection and structured governance with thresholds and audit trails. MLOps and observability integrate CI/CD practices with monitoring of model performance, feature trends and pipeline health for scalable deployments.
Multi-Agent Ecosystems and Human-AI Symbiosis
Multi-agent ecosystems coordinate specialized agents via standard protocols, enabling modular, resilient analytics architectures. Interpretability bridges agent outputs and human understanding, fostering symbiotic workflows where domain experts guide priorities and validate decisions.
Ethical and Compliance Trade-offs
Implementing autonomous analytics involves balancing innovation speed, model complexity and governance rigor. Risk-based approaches evaluate performance gains against transparency requirements, human-in-the-loop controls and continuous auditing to align autonomy with corporate values and legal mandates.
Conceptual Frameworks and Taxonomies
Functional Taxonomy and Autonomy Continuum
Combining the autonomy continuum with a functional taxonomy guides phased adoption. Exploratory profiling agents uncover trends, predictive agents forecast outcomes, prescriptive agents optimize decisions and stewardship agents monitor governance and quality. Mapping these roles across autonomy levels supports capability benchmarking and incremental implementation.
Decision-Making Paradigms
Analytical agents follow three paradigms: reactive rule-based engines for event-driven tasks, deliberative systems for planning and optimization, and reflective architectures with meta-reasoning for self-improvement. Choice depends on use-case complexity, latency requirements and governance constraints.
Data Architecture Patterns
Lambda and Kappa architectures underpin agent data flows. Lambda separates batch and stream layers, enabling combined model training and low-latency inference. Kappa treats all data as streams, supporting continuous learning over microbatches but requiring advanced state management.
Human-AI Collaboration Models
Collaboration paradigms range from human-in-the-loop—analyst confirmations at decision points—to human-on-the-loop—real-time oversight dashboards—and human-out-of-the-loop for standardized, low-risk tasks. Selecting the model depends on risk tolerance, regulatory demands and user trust.
Governance and Ethical Frameworks
Operationalizing Responsible AI involves embedding fairness, transparency, accountability and privacy by design. Controls include bias detection routines, explainability tools such as SHAP or LIME, immutable audit trails and role-based access with encryption. Governance bodies conduct ethical impact assessments and review scorecards to enforce compliance.
Performance Monitoring and Validation
Continuous performance oversight uses dashboards tracking accuracy, latency, false-positive rates and business KPIs alongside drift indicators like population stability index. Validation frameworks combine statistical methods—k-fold cross-validation, bootstrap—with scenario simulations and health checks to maintain system agility and trust.
Adoption and Change Management Models
Diffusion of Innovation and Technology–Organization–Environment (TOE) frameworks inform adoption strategies. Assessing technological readiness, organizational capabilities and external pressures helps sequence pilot deployments, training programs and stakeholder engagement, accelerating momentum and mitigating barriers.
Interpretive Frameworks for Visualization
Effective dashboards and explorations leverage Shneiderman’s mantra—overview, zoom and filter, details-on-demand—and Card and Mackinlay’s expressiveness model. Generative agents automate chart selection and narrative summaries, preserving accessibility and cognitive alignment.
Privacy-Preserving Techniques and Emerging Architectures
Privacy-preserving methods include differential privacy, federated learning and codified ethical boundaries. Emerging frameworks merge neural and symbolic reasoning—neurosymbolic architectures—and prototype quantum-augmented agents for combinatorial optimization, expanding autonomous analytics frontiers.
Clarifications and Common Questions
What Defines an Autonomous AI Agent in Data Analytics?
An autonomous AI agent performs end-to-end analytical tasks—from data ingestion through insight delivery—without continuous human intervention. It combines goal orientation, adaptive learning, contextual awareness and proactivity to self-direct processes in high-velocity data environments.
How Do AI Agents Differ from Traditional BI Tools?
Unlike BI platforms that rely on scheduled reporting and manual dashboards, AI agents automate data preparation, feature engineering, hypothesis generation and model tuning. They orchestrate multi-step workflows, surface non-obvious patterns and proactively notify users of critical anomalies.
What Are the Primary Types of AI Agents and Their Decision Models?
- Exploratory agents: Unsupervised analysis and visualization.
- Predictive agents: Model building and validation for forecasting and classification.
- Prescriptive agents: Optimization using constraint solvers and simulations.
- Monitoring agents: Performance tracking, drift detection and alerts.
Decision models range from reactive rule-based engines to deliberative planners and reflective meta-reasoners, chosen based on complexity and risk.
How Should Organizations Approach Data Governance and Compliance?
Embed regulations (GDPR, CCPA, HIPAA) into agent workflows via policy codification, maintain immutable audit trails of lineage and decisions, enforce role-based access controls and encryption, and establish ethics committees to review bias metrics and remediation plans.
How Is Agent Performance Measured and When Should Models Be Retrained?
Track accuracy, latency, false positives, drift indicators and business impact metrics. Retraining triggers include threshold breaches, scheduled intervals and event-driven changes (e.g., product launches or regulatory updates). Hybrid strategies balance relevance and compute cost.
What Are Common Pitfalls in Self-Healing Pipelines?
- Brittle rules: Hardcoded checks that break under schema drift.
- False positives: Over-remediation masking valid changes.
- Lack of auditability: No trace logs impeding root-cause analysis.
- Over-automation: Automated fixes without human oversight for sensitive data.
How Do You Integrate AI Agents into Existing Workflows?
Adopt an API-first design exposing REST or gRPC endpoints, leverage event-driven architectures with Kafka or EventBridge, embed agents in BI platforms like Power BI or Tableau, and use orchestration tools such as Apache Airflow or Kubeflow.
How Do Multi-Agent Ecosystems Operate and Collaborate?
Patterns include orchestrated hubs assigning tasks, peer networks sharing results via FIPA or gRPC, and hierarchical tiers with supervisory agents enforcing policies. Coordination requires robust communication layers, version control and shared metadata repositories.
What Are Cost and ROI Considerations for Autonomous Analytics?
Evaluate cost savings from reduced manual effort, revenue uplift through faster insights, risk mitigation from early anomaly detection and improved human capital utilization. Pilot studies and A/B tests quantify time-to-insight improvements and decision accuracy gains.
How Can Organizations Future-Proof Agent Deployments?
- Modular architectures: Microservices for interchangeable algorithms and hardware accelerators.
- Continuous monitoring: Health checks for drift, performance and compliance.
- Experimentation platforms: Sandboxes for safe trials of new behaviors.
- Scalable infrastructure: Cloud elasticity and container orchestration.
- Collaborative research: Engagement with academic consortia and open source communities.
- Ethical vigilance: Ongoing evaluation against evolving guidelines.
Named AI Tools and Platforms
Machine Learning and Automated Modeling Platforms
- DataRobot – Automates data preparation, model selection, deployment and monitoring.
- H2O.ai – Open source and commercial tools for automated ML and scalable deployment.
- Amazon SageMaker – Managed service for building, training and deploying ML models.
- Microsoft Azure Machine Learning – Automated ML, model management and MLOps capabilities.
- Google Cloud Vertex AI – Integrates AutoML and custom training with unified deployment.
- IBM Watson Studio – Collaborative environment for model development, deployment and governance.
- Dataiku – Visual platform for data preparation, analysis, ML and MLOps.
Data Integration and Preparation
- Fivetran – Automated pipelines with pre-built connectors.
- Trifacta – ML-driven self-service data wrangling.
- Alteryx – End-to-end preparation, blending and analytics.
- Informatica – Cloud-native integration, quality and governance.
- Talend – Integration with data quality and real-time processing.
- Snowflake – Unified data platform for warehousing and sharing.
- Databricks – Spark-based processing with collaborative notebooks and MLflow.
- Apache Kafka – Distributed streaming for real-time pipelines.
- Apache NiFi – Automated data flow with visual lineage.
- AWS Kinesis – Managed real-time data streaming.
- Google Cloud Pub/Sub – Global messaging for streaming analytics.
Visualization and Business Intelligence
- ThoughtSpot – Search-driven analytics with natural language interface.
- Qlik Sense – Associative indexing and AI augmentations.
- Tableau – Visual discovery and dashboard creation.
- Microsoft Power BI – Interactive visualizations and self-service reporting.
- Grafana – Open source monitoring and observability dashboards.
Orchestration and MLOps Frameworks
- Apache Airflow – Workflow management for complex pipelines.
- Kubeflow – Kubernetes-native ML orchestration.
- MLflow – Experiment tracking and model registry.
- OpenLineage – Metadata and lineage standard.
- Apache Atlas – Metadata management and governance.
- Kubernetes – Container orchestration for AI services.
NLP and Conversational AI
- TensorFlow – Numerical computation and large-scale ML including NLP.
- PyTorch – Deep learning framework for transformer models.
- spaCy – Production-grade NLP library.
- Hugging Face – Pre-trained transformers and NLP tools.
- OpenAI – Advanced generative models like GPT-3.
- Rasa NLU – Framework for building conversational assistants.
Model Serving and Inference
- TensorFlow Serving – High-performance serving of TensorFlow models.
- TorchServe – Flexible serving framework for PyTorch.
- NVIDIA Triton Inference Server – Multi-framework model serving with GPU optimization.
Optimization and Prescriptive Engines
- IBM ILOG CPLEX – Solver for linear, mixed-integer and quadratic programming.
- Gurobi Optimizer – State-of-the-art mathematical optimization.
- Google OR-Tools – Open source combinatorial optimization suite.
- SciPy Optimize – Algorithms for minimization, curve fitting and root finding.
Governance and Policy Engines
- Open Policy Agent – Fine-grained access and compliance rules enforcement.
- IBM Watson OpenScale – Monitors models for fairness, explainability and drift.
- Microsoft Fairlearn – Toolkit for assessing and mitigating algorithmic unfairness.
Standards and Frameworks
- ONNX – Open format for interoperable ML models.
- PMML – Predictive Model Markup Language for model interchange.
- FAIR Data Principles – Guidelines for data findability, accessibility, interoperability and reusability.
- FIPA – Standards for agent communication and management.
- Green Software Foundation – Frameworks for measuring and reducing environmental impact.
- IEEE P7000 Series – Standards addressing ethical concerns in autonomous systems.
Research and Community Resources
- Association for the Advancement of Artificial Intelligence (AAAI) – Conferences and publications on AI research and ethics.
- Partnership on AI – Consortium advancing responsible AI best practices.
- MIT Initiative on the Digital Economy – Research on AI, business strategy and transformation.
- MLPerf – Standardized benchmarks for ML performance.
- DAMA International – Data management community offering governance best practices.
The AugVation family of websites helps entrepreneurs, professionals, and teams apply AI in practical, real-world ways—through curated tools, proven workflows, and implementation-focused education. Explore the ecosystem below to find the right platform for your goals.
Ecosystem Directory
AugVation — The central hub for AI-enhanced digital products, guides, templates, and implementation toolkits.
Resource Link AI — A curated directory of AI tools, solution workflows, reviews, and practical learning resources.
Agent Link AI — AI agents and intelligent automation: orchestrated workflows, agent frameworks, and operational efficiency systems.
Business Link AI — AI for business strategy and operations: frameworks, use cases, and adoption guidance for leaders.
Content Link AI — AI-powered content creation and SEO: writing, publishing, multimedia, and scalable distribution workflows.
Design Link AI — AI for design and branding: creative tools, visual workflows, UX/UI acceleration, and design automation.
Developer Link AI — AI for builders: dev tools, APIs, frameworks, deployment strategies, and integration best practices.
Marketing Link AI — AI-driven marketing: automation, personalization, analytics, ad optimization, and performance growth.
Productivity Link AI — AI productivity systems: task efficiency, collaboration, knowledge workflows, and smarter daily execution.
Sales Link AI — AI for sales: lead generation, sales intelligence, conversation insights, CRM enhancement, and revenue optimization.
Want the fastest path? Start at AugVation to access the latest resources, then explore the rest of the ecosystem from there.